Learning by Watching: Physical Imitation ofManipulation Skills from Human Videos论文学习
先通过 MUNIT 模型(无监督图像翻译)把人类演示视频逐帧转化为机器人视角的视频 —— 翻译后的视频可能有视觉伪影,缺少结构化关键信息,无法直接用于训练;接着用 Transporter 模型从翻译后的机器人视频中提取关键点轨迹(比如机器人末端、物体中心的运动轨迹);最后用这些轨迹作为强化学习的训练目标,让机械臂的关键点轨迹与目标轨迹尽可能一致,从而学会操作技能。经过上述训练,我们就得到了能准确提
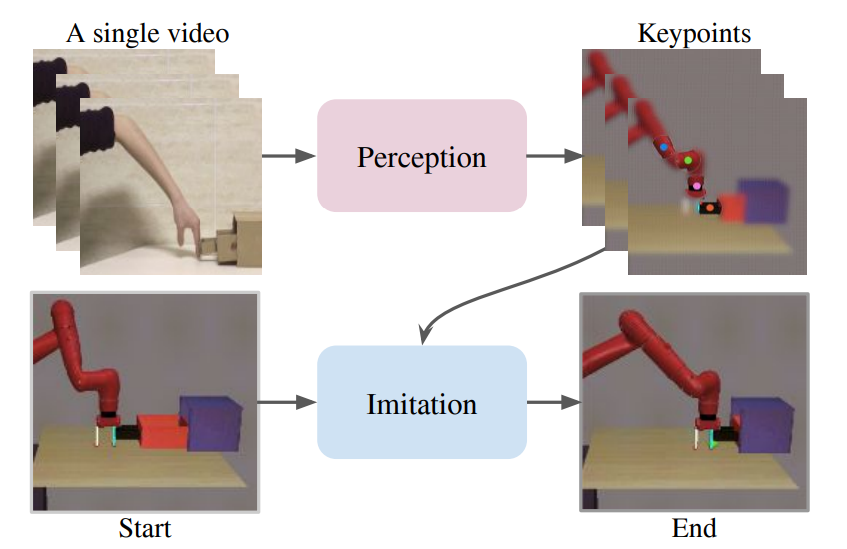
这篇论文主要的工作也是要研究如何用人类演示视频来训练机器人。先通过 MUNIT 模型(无监督图像翻译)把人类演示视频逐帧转化为机器人视角的视频 —— 翻译后的视频可能有视觉伪影,缺少结构化关键信息,无法直接用于训练;接着用 Transporter 模型从翻译后的机器人视频中提取关键点轨迹(比如机器人末端、物体中心的运动轨迹);最后用这些轨迹作为强化学习的训练目标,让机械臂的关键点轨迹与目标轨迹尽可能一致,从而学会操作技能。
那么Transpoprter模型是怎么弄出来的呢?为什么我们可以以一个无监督的方式训练出来一个Transporter模型?具体流程是这样:
- 取机器人视频的相邻两帧 x1(前一帧)和 x2(当前帧),先用视觉特征提取器 Φ 提取两帧的特征图 Φ(x1)、Φ(x2);再用关键点检测器 Ψ 生成两帧的关键点坐标,并基于坐标生成高斯热图 HΨ(x1)、HΨ(x2)—— 这两个热图用来标记两帧中 “模型认为的关键区域”(一开始 Ψ 不够精准,需要通过训练优化)。
- 基于热图做特征迁移:以 x1 的特征图 Φ(x1) 为基础,保留其非关键区域的特征,同时把关键区域的特征替换成 x2 的关键区域特征,得到迁移后的特征图Φ^(x1,x2);再用重建网络 R 把这个特征图还原成图像x2^,并和真实的 x2 对比。
- 若 Ψ 提取的关键点是准确的,还原后的x2^会和真实 x2 高度相似,二者的差异(重建损失Ltransporter)就小;若关键点提取错误,差异会变大 —— 模型通过这个损失反向优化 Ψ,直到能精准提取机器人视频中的关键区域。
经过上述训练,我们就得到了能准确提取关键信息的 Transporter 模型,其核心组件 Ψ 就是我们用来提取关键点轨迹的工具。
这个Transpoprter模型是用来提取关键点轨迹的,是论文的novelty之一,但是流程中还用到了一个MUNIT 模型,这个模型是怎么来的呢?:
MUNIT 模型(Multimodal Unsupervised Image-to-Image Translation,多模态无监督图像翻译模型)是论文中用来解决 “人类视频→机器人视频” 转换的核心工具 —— 它能在没有成对训练数据(比如 “人类做动作 A” 和 “机器人做动作 A” 的一一对应视频帧)的情况下,把一个领域(人类域)的图像 / 视频,翻译成另一个领域(机器人域)的图像 / 视频,同时保留核心动作逻辑(比如 “推方块” 的动作本质)。
我们用 “通俗类比 + 技术拆解” 的方式,把它讲清楚:
一、先明确 MUNIT 的核心目标
论文中,MUNIT 要解决的问题是:把 “人类操作视频帧”(比如人用手推方块),翻译成 “机器人操作视频帧”(机器人爪子推方块)—— 要求:
- 动作逻辑不变(推方块的方向、目标位置一致);
- 外观风格符合机器人域(比如背景是机器人工作台、执行者是机械臂,不是人的手);
- 不需要人工标注 “人类动作对应机器人动作”(无监督)。
二、MUNIT 的核心创新:把图像 “拆成两部分”
MUNIT 能实现无监督跨域翻译,关键是它的核心思想 ——图像表征解耦:把一张图像的信息拆成两个独立部分,分别处理后再重组,既保证 “动作不变”,又保证 “风格适配”。
1. 两个核心组件(解耦后的两部分)
| 组件 | 作用(通俗理解) | 技术定义 | 跨域特性 |
|---|---|---|---|
| 内容码(Content Code) | 记录 “图像里的核心逻辑 / 动作”(比如 “推方块”) | 由内容编码器 \(E^c\) 提取,是域不变的(Domain-Invariant) | 人类域和机器人域共享同一个内容编码器,确保动作逻辑一致 |
| 风格码(Style Code) | 记录 “图像的外观 / 风格”(比如 “是人还是机器人”“背景是什么”) | 由风格编码器 \(E^s\) 提取,是域特定的(Domain-Specific) | 人类域和机器人域各有一个风格编码器,确保风格符合目标域 |
类比理解
比如一张 “人推方块” 的图:
- 内容码 = “有一个方块,被一个物体(手)朝右推”(核心动作逻辑);
- 风格码 = “执行者是人的手,背景是桌面,颜色偏暖”(外观风格)。
MUNIT 要做的就是:把 “人类的风格码” 换成 “机器人的风格码”,再和原来的 “推方块” 内容码重组,得到 “机器人推方块” 的图 —— 动作不变,风格变了。
三、MUNIT 的无监督训练流程(怎么学会翻译?)
训练的核心是 “让模型学会‘拆’(解耦内容和风格)和‘拼’(重组内容和目标域风格)”,不需要成对数据,只需要:
- 源域数据:人类视频帧(包括目标任务视频 + 少量人类随机动作视频);
- 目标域数据:机器人随机动作视频(无需专家示范,低成本获取)。
具体训练步骤(结合论文中的损失函数):
1. 第一步:编码(拆内容和风格)
对任意一张人类域图像 x(源域)和机器人域图像 y(目标域):
- 提取人类图像的内容码 \(c_x = E_X^c(x)\)、风格码 \(s_x = E_X^s(x)\);
- 提取机器人图像的内容码 \(c_y = E_Y^c(y)\)、风格码 \(s_y = E_Y^s(y)\);(注:\(E_X^c\) 和 \(E_Y^c\) 是同一个共享的内容编码器,\(E_X^s\) 和 \(E_Y^s\) 是各自独立的风格编码器)。
2. 第二步:生成(拼内容和目标风格)
- 人类→机器人翻译:用人类的内容码 \(c_x\) + 机器人的风格码 \(s_y\),通过机器人域生成器 \(G_Y\) 生成翻译图 \(\hat{y} = G_Y(c_x, s_y)\)(期望 \(\hat{y}\) 是 “机器人做人类动作” 的图);
- 机器人→人类翻译:用机器人的内容码 \(c_y\) + 人类的风格码 \(s_x\),通过人类域生成器 \(G_X\) 生成翻译图 \(\hat{x} = G_X(c_y, s_x)\)(反向翻译,用于验证一致性)。
3. 第三步:用损失函数 “打分”,优化模型
模型通过 “损失” 判断翻译效果,反向调整编码器和生成器的参数,直到翻译效果达标。论文中用了 5 类损失,核心是 3 类:
- 对抗损失(\(L_{GAN}\)):让翻译图 “以假乱真”。比如翻译后的机器人图 \(\hat{y}\),要让 discriminator(判别器)分不清它是 “真实的机器人图” 还是 “翻译出来的机器人图”—— 确保风格符合目标域;
- 图像重建损失(\(L_{rec}^{image}\)):让 “拆了再拼” 能还原原图。比如用人类的内容码 \(c_x\) + 人类的风格码 \(s_x\) 重组,生成的图要和原图 x 几乎一样 —— 确保内容和风格没拆错、没拼错;
- 内容 / 风格重建损失(\(L_{rec}^c, L_{rec}^s\)):让翻译后的图能还原原始内容 / 风格。比如把人类图翻译成机器人图 \(\hat{y}\) 后,再用机器人的内容编码器提取 \(\hat{y}\) 的内容码,要和原始人类图的内容码 \(c_x\) 一致 —— 确保动作逻辑没丢失。
总结训练逻辑
模型通过 “编码→生成→损失反馈” 的循环,学会:
- 内容编码器:不管是人类图还是机器人图,都能提取出 “动作逻辑”(比如推、拉、抓);
- 风格编码器:分别捕捉人类和机器人的外观特征;
- 生成器:把 “源域内容” 和 “目标域风格” 精准重组,生成高质量翻译图。
四、MUNIT 为什么适合论文的任务?(对比其他翻译模型)
论文中提到,之前的方法(比如 CycleGAN)也能做无监督图像翻译,但 MUNIT 有两个关键优势:
- 多模态输出:同一人类动作,能生成多个不同风格的机器人动作(比如不同角度的机械臂姿态),增加数据多样性,利于后续训练;
- 内容 - 风格解耦更彻底:CycleGAN 容易出现 “动作变形”(比如人类推方块的方向,翻译后机器人推的方向变了),而 MUNIT 因为单独提取内容码,能更好地保留核心动作逻辑,减少翻译后的视觉伪影。
五、通俗总结 MUNIT 的作用(结合论文流程)
MUNIT 就像一个 “视频风格转换器”:
- 输入:人类做 “推方块” 的视频帧;
- 处理:拆出 “推方块” 的核心动作(内容码),扔掉 “人的手、人类背景” 的风格,换上 “机械臂、机器人工作台” 的风格;
- 输出:机器人做 “推方块” 的视频帧 —— 动作和人类一致,外观符合机器人场景,且不需要人工标注 “人对应机器人” 的成对数据。
正是因为 MUNIT 能高效解决 “人机域差距”,后续的 Transporter 模型才能在翻译后的机器人视频上,精准提取关键点轨迹,为强化学习提供结构化的训练目标。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)