【第二十九】文献阅读
这篇文献的主要研究目的是如何让机器人通过一句开放式的语言指令,在从未见过的复杂情况自主识别并导航到目标旁研究人员采用MANO模型表示手部,该模型由手部形状参数和手腕姿态参数构成:θ为手指旋转、β为形状特征,旋转r和平移t为手腕姿态参数给定任务描述T、视觉预测Vk(包含RGB帧Ik和深度帧Dk)和手部参数hk,目标预测是未来l帧的手部姿态。
目录
摘要
Abstract
一、《MAG-Nav: Language-Driven Object Navigation Leveraging Memory-Reserved Active Grounding》
1、研究目的
这篇文献的主要研究目的是如何让机器人通过一句开放式的语言指令,在从未见过的复杂情况自主识别并导航到目标旁
2、相关工作
提出基于视角的主动接地方法,使机器人能够主动调整自身位置以获取更具信息量的视觉观测,通过提升输入数据质量增强 VLM 性能——这一过程模拟了人类为清晰感知物体而调整视角的行为
引入历史记忆回溯机制,模拟人类记忆召回过程,支持系统跨时间重新评估不确定观测结果,实现复杂环境下的上下文感知决策与跨任务知识迁移
提供全面的实验验证,包括仿真基准测试(如 HM3D 数据集)与四足机器人真实场景部署,充分证明了所提方法的鲁棒性、泛化能力与实用价值
公开代码以促进后续研究,推动嵌入式视觉 - 语言导航领域的可复现性发展
3、研究方法
所有的研究都是在MAG-Nav系统框架下进行的,我来简单介绍一下该框架的工作流程,系统首先利用大语言模型从用户的语言指令中提取目标类别和相关地表类别,同时,视觉语义感知模块处理机器人的视觉输入,然后根据记忆保留式主动接地来寻找目标物品并导航到其身旁
3.1、视觉记忆单元
基于当前观测,构建视觉记忆单元,检测到的目标和地表标用边界框标记,边界框为唯一标识符。为了获取目标和地标的边界框,该文章利用开放词汇检测模型预测当前图像中的边界框,检测完成后,在边界框左上角标注唯一标识符,生成标注图像,为后面接地提供视觉提示
3.2、物体记忆单元
为了获取标注图像中每个物体的完整3D信息,研究人员采用无关分割模型以获取这些物体对应的掩码合集,将每个提取的掩码输入视觉特征提取器(CLIP)得到视觉描述符号,同时利用掩码内的深度值进行计算获取相机坐标系下的3D坐标,并转化至世界坐标系,最终得到点云及其对应的单位归一化语义特征向量。
3.3、记忆更新
若标注图像引入新的目标物体,则将该视觉记忆单元判定为关键帧,检测到的每个物体,通过与记忆物体进行相似度对比,若相似度超过一定阈值,我们则将与最相似的物体进行关联,若没有,则将其视为新实体加入记忆物体中,并且将当前帧添加到视觉记忆当中
4、记忆保留式主动接地
首先我们需要理解接地是什么意思,接地是自然语言处理和多模态人工智能领域的一个基本概念,接地是将抽象、符号化的信息与现实世界中的具体实体或感知数据建立联系和对应关系的过程
记忆保留式主动接地利用生成式VLM的理解能力和机器人的移动性,将接地过程分为三个过程:基于VLM的初始接地、基于视角的主动接地和基于记忆的保留接地
4.1、初始接地阶段
将当前的标注图像和原始图像作为视觉提示,语言描述作为文本提示,将标注图像的边界框和原始图像的上下文关系输入VLM,确定哪个标注候选物体与文本描述的对象最匹配,之后VLM输出该候选匹配对象的边界框数字,从而精确定位目标物体的位置
4.2、基于视角的主动接地
在初始阶段,机器人对目标物体的观测是具有随机性,有时并非观测目标的最优角度,可能无法提供目标的完整信息,进而影响VLM接地质量,对此,研究人员将视角优化问题定义为多目标离散化问题,目标函数的定义如下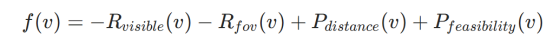
该函数用于评估机器人在某个侯选的观测位置,目标是最小化f,从而实现寻找到目标物体的最佳观测距离,公式由四部分组成,两个奖励项(前边的负号代表希望最大化)和两个惩罚项(前边的正号是希望最小化),从左到右分别是可见性奖励、视野奖励、距离惩罚和可行性惩罚
可见性奖励主要奖励从位置V能看到目标物体的程度,所以越大越好
视野奖励主要奖励目标物体在机器人视野中占据的大小,肯定是越大越好
距离惩罚主要惩罚的是位置V与目标之间的不合适距离,研究人员希望距离偏距越小,惩罚越小
可行性惩罚主要惩罚的是不可到达或位于障碍上的观测点,主要排除的是不可行点
4.3、基于记忆的保留接地
在探索导航阶段,主动接地能有效缓解因视角带来的初始接地错误,但实际上受复杂环境和语言描述模糊影响,即使在主动阶段,依旧有识别不精准的情况存在。
与前两个接地阶段不同,保留接地阶段不再依赖当前观测,而是利用视觉记忆中的关键观测识别目标。具体来说,就是从视觉记忆的所有关键帧中均匀采样N个关键帧,然后将这些标注图像按照编号输入VLM中去,VLM输出标注图像的序列号和边界框的数字标识符,最终,从物体记忆中获取目标物体的空间坐标,机器人直接导航到该坐标。
该方法主要模拟的是人类的回想功能,在记忆中寻找到最有可能的目标,再去判断是否为目标物体。
二、《OAM:Object-Aware Memory and Vision-Language Models for Zero-Shot Object Navigation》
1、研究目的
该论文主要的是OAM,OAM是一款零样本目标导航框架,让智能体在完全未知的环境下,仅通过自然语言指令,自主导航并精确定位目标物体,其核心应用场景包括灾害救援,家庭服务等,无需针对具体环境或目标进行专门训练,具备极强的泛化能力
2、相关工作
提出OAM框架,通过短时间记忆回顾性检索历史观测,并利用视觉语言模型进行语义匹配,突破单帧观测的局限
引入目标级语义聚焦机制,实现边界点与目标语义的高效匹配,提升复杂环境下的决策质量
无需任务特定训练,利用预训练模型的常识知识,适配从未见过的环境和目标物体,提升原本零样本的泛化能力
3、方法
OAM由三个主要模块组成,分别为感知模块、探索模块、导航模块,三个模块的工作流程为:首先,感知模块以 RGB 图像、深度图和位姿信息为输入,构建占据栅格地图、提取边界点并生成边界地图,同时将智能体的观测序列存储为历史记忆。探索模块基于视野覆盖范围和空间距离过滤每个边界点的历史观测,然后利用目标检测器从图像中提取目标斑块,将其输入视觉语言模型计算相似度分数,该分数反映每个边界的语义相关性。最后选择最具价值的边界点,导航模块规划路径并执行导航,更新观测输入。
3.1、感知模块
首先是边界地图构建
每个时间步,智能体接收RGB图像、深度图和当前位姿,通过将深度数据投影到全局坐标系,得到环境的局部3D结构,然后将信息整合到全局2D占栅格地图Mocc,地图内会将元素分为障碍物、自由单元、未知单元。为构建地图,首先识别Mocc中所有自由单元,并将至少一个未知邻居的单元标记为边界候选点。为了减少冗余,采用空间聚类将相邻边界分组,从中提取代表性点形成离散边界集
然后是时空记忆
类比人类的习惯,面对潜在目标位置时,人类通常会回忆该区域之前见过的物品——这种能力类似于短时间记忆。受此认知机制启发,研究人员设计时空记忆缓冲模块,缓存智能体近期访问位置的视觉和几何信息,实现边界点的语义感知。该模块维护一个长度为 M 的先进先出(FIFO)观测队列:
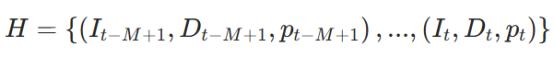
I为RGB图像、D为深度图像,p为位姿。该观测历史具有时间连续性和空间锚定性,形成轻量级短时感知记忆,作为后续 PathMatcher 语义评分模块的输入
3.2、探索模块
首先先看斑块匹配器
斑块是计算机视觉与图像处理中的一个关键概念,即为两幅图像中相似的小区域
获得候选边界集后,斑块匹配器为每个边界点分配与任务相关的语义价值。通过将当前导航目标与从历史观测中提取的语义斑块进行比较,该模块估算每个边界导向目标物体的可能性
然后是目标斑块提取
从选定的历史观测中识别语义相关的目标区域,该模块提取相应的图像区域作为斑块,然后将其存放在一个斑块集里
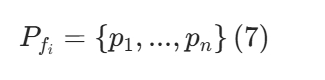
其中每个pj是与fi空间相关且具有潜在语义意义的图像区域,用于后续匹配和推理
3.3、语义边界
研究者采用视觉语言模型BLIP-2估算每个边界点与自然语言描述的目标物体之间的相似度分数,本文在此基础上,避免对整幅图像进行冗余处理
对于每个斑块,利用自然语言构建为文本提示描述导航目标,将斑块和文本输入 BLIP-2 计算余弦相似度分数: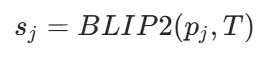
为获得每个边界点fi的整体语义分数,对其所有关联斑块的相似度分数取平均值
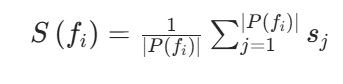
最后,选择语义分数最高的边界点作为下一个探索目标:
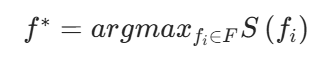
其中 F 是当前检测到的所有边界点的集合
该方法就是利用视觉语言模型进行记忆的匹配,通过自然语言的输入,探索目标物体,并且能够从历史观测数据中识别目标语义的物品,显著提升了模型的逻辑推理能力
3.4、探索模块
系统在占据栅格的地图上采用快速行进法(FMM)规划从智能体位置到边界点的无碰撞路径,并指导导航,若找到目标,则任务成功并中止,若没有找到,则系统重新评估分数,选择新目标,并重复该过程。
三、《MEgoHand: Multimodal Egocentric Hand-Object Interaction Motion Generation》
1、研究目的
这篇文章主要研究的是,在第一人称视角下,由于视角不稳定、自遮挡、透视畸变和运动噪声等问题,第一视角手-物运动生成仍然存在挑战,所以本文提出了EgoHand,一种多模态框架,能够基于第一视角RGB图像、文本信息和初始手部姿态,生成合理的手部交互动作
2、相关工作
提出首个将视觉语言模型用于第一视角手-物交互运动先验推断的框架,结合单目深度模块实现与物体无关的空间推理
设计标准化数据预处理,通过逆MANO重定向网络和虚拟RGB-D渲染器统一姿态表示并生成对齐深度图,构建包含335万帧、2.4万次交互和1200个物体的多模态数据集
MEgoHand在多个域内和跨基准测试中超越基线模型,显著降低运动误差,展现出优异的细粒度关节运动建模能力和稳健泛化性
3、方法
3.1、问题的定义
研究人员采用MANO模型表示手部,该模型由手部形状参数和手腕姿态参数构成:
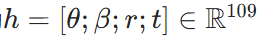
θ为手指旋转、β为形状特征,旋转r和平移t为手腕姿态参数
给定任务描述T、视觉预测Vk(包含RGB帧Ik和深度帧Dk)和手部参数hk,目标预测是未来l帧的手部姿态
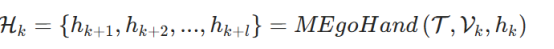
3.2、MEgoHand的双层架构
稍早的方法都比较依赖物体预先定义的信息,对于从未见过的物体,泛化能力很差,并且第一人称视角下,相机晃动严重、自遮挡干扰,导致信息误差很大,为此,MEgoHand提出双层架构,分为高层模块和低层模块。高层模块利用视觉语言模型从视觉感知、任务理解和意图 - 行为对齐中推断运动先验,并通过单目深度估计器将 RGB 图像编码为密集深度表示,增强手 - 物关系的空间理解,无需依赖物体特定先验;低层模块通过基于 DiT 的流匹配策略生成细粒度手部轨迹,有效建模时间不确定性并确保运动连续性,同时采用时间正交滤波解码策略减轻第一视角相机运动引发的观测噪声
3.3、数据集整合
早期的数据集,仅提供由可穿戴传感器捕获的三维手部关节位置,而非 MANO 参数,且 21 个手部关键点的世界坐标系坐标无法直接作为 MEgoHand 的输入或运动生成的监督信号。为此,引入逆 MANO 重定向网络ϕ,从关节坐标中恢复 MANO 参数
很多数据集只有RGB图,没有深度图,但深度编码器的有效训练需要来自同一第一视角的配对RGB-D数据,为此研究者设计了虚拟RGB-D渲染器,合成与RGB帧对齐的深度图
通过逆 MANO 重定向和虚拟 RGB-D 渲染,构建包含 335 万 RGB-D 帧、2.4 万次交互轨迹、覆盖 1200 个物体的多模态数据集,本文仅考虑右手运动

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)