【论文自动阅读】WMPO: World Model-based Policy Optimization for Vision-Language-Action Models
本文提出WMPO框架,通过构建像素级视频生成世界模型,让视觉-语言-动作(VLA)模型无需与真实环境交互,就能进行在线强化学习(RL),解决了现有VLA模型依赖模仿学习、真实环境RL样本效率低的问题,还能实现自我修正等新兴行为。
快速了解部分
基础信息:
- 题目:WMPO: World Model-based Policy Optimization for Vision-Language-Action Models
- 时间年月:2025年11月
- 机构名:Hong Kong University of Science and Technology、ByteDance Seed
- 3个英文关键词:Vision-Language-Action (VLA) Models、World Model、Reinforcement Learning (RL)
1句话通俗总结本文干了什么事情
本文提出WMPO框架,通过构建像素级视频生成世界模型,让视觉-语言-动作(VLA)模型无需与真实环境交互,就能进行在线强化学习(RL),解决了现有VLA模型依赖模仿学习、真实环境RL样本效率低的问题,还能实现自我修正等新兴行为。
研究痛点:现有研究不足 / 要解决的具体问题
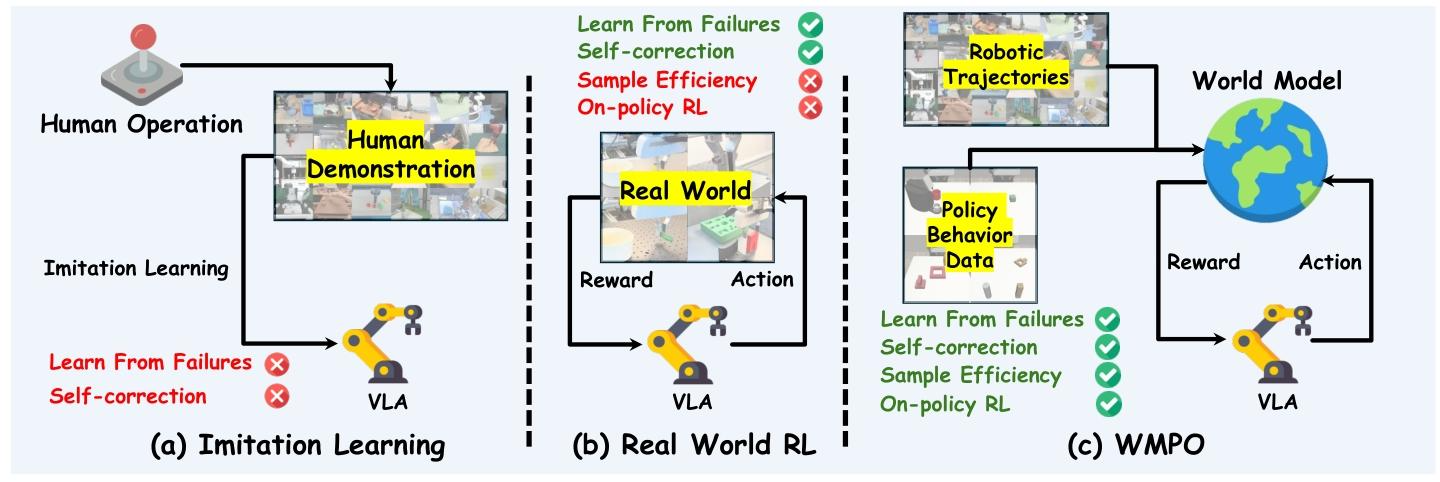
- VLA模型的模仿学习局限:现有VLA模型多依赖人类示范的模仿学习,遇到训练中未见过的“分布外状态”时易出错,且无法从失败中学习和自我修正。
- 真实环境RL的样本效率低:直接在真实机器人上做强化学习需要数百万次交互,成本高、不安全且耗时,样本效率极差。
- 现有世界模型的适配问题:多数经典基于模型的RL用抽象 latent 空间世界模型,与VLA模型基于真实图像的预训练特征不匹配,无法充分利用VLA的视觉理解能力;且短视域预测难定义准确奖励,易出现“奖励欺骗”。
- 泛化与 scalability 不足:依赖人类干预的RL方法需持续监督,难以规模化;依赖模拟器的RL方法构建精准模拟器成本高,泛化到真实场景能力弱。
核心方法:关键技术、模型或研究设计(简要)
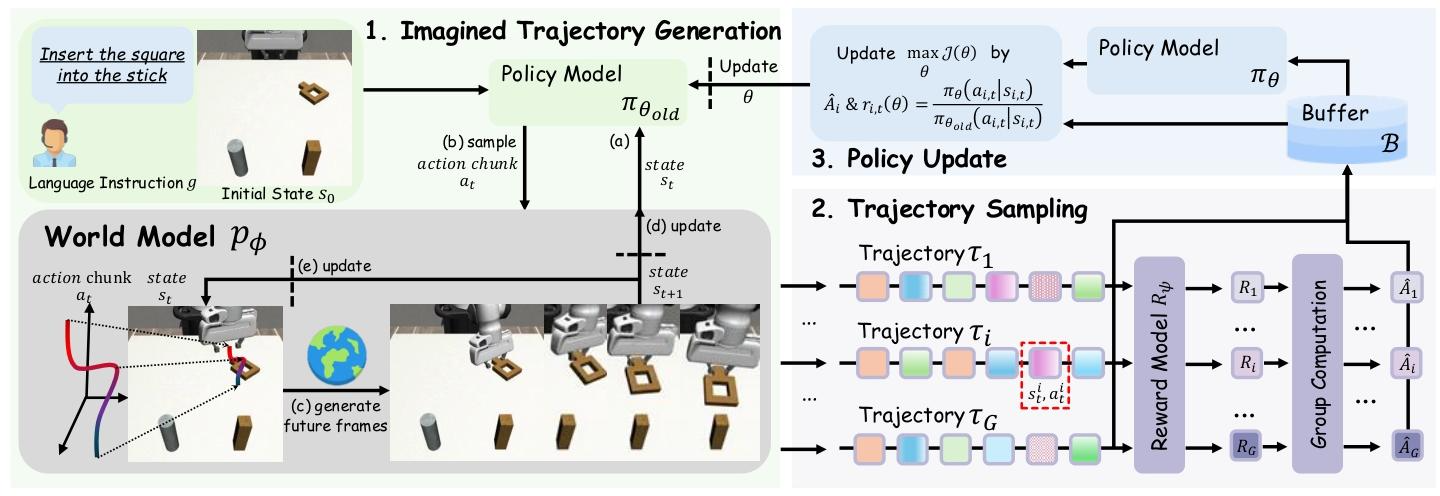
- 像素级视频生成世界模型:基于视频扩散模型(如OpenSora改造),在像素空间生成轨迹,匹配VLA预训练特征,避免latent空间 mismatch。
- 政策行为对齐(Policy Behavior Alignment):用政策自身收集的少量真实轨迹微调世界模型,解决专家示范与政策轨迹的分布不匹配,更好模拟失败场景。
- 片段级自回归视频生成:生成完整任务轨迹,而非短视域片段,支持基于结果的可靠奖励分配,同时用“噪声帧条件”和“帧级动作控制”解决视觉失真与动作-帧错位。
- 轻量奖励模型:基于VideoMAE构建二分类奖励模型,判断轨迹任务成败,避免复杂奖励设计与奖励欺骗。
- 在线RL优化(GRPO):在世界模型生成的“想象轨迹”上用Group Relative Policy Optimization(GRPO)做在线政策优化,提升样本效率与性能。
深入了解部分
相比前人创新在哪里
- 首次实现VLA模型的“全像素空间在线RL”:前人世界模型多在latent空间,本文用像素级世界模型,完美衔接VLA的图像预训练知识,首次验证高保真世界模型用于规模化VLA RL的可行性。
- 政策行为对齐解决分布不匹配:前人世界模型多依赖专家示范(如Open X-Embodiment),缺乏失败场景模拟;本文用政策自身轨迹微调世界模型,更真实捕捉政策行为(包括失败),提升轨迹模拟可信度。
- 片段级自回归生成解决长视域问题:前人短视域预测难定义奖励,本文通过自回归生成完整任务轨迹,结合噪声帧条件与帧级动作控制,实现稳定长视域(数百帧)轨迹生成,避免视觉失真。
- 兼顾样本效率与泛化/终身学习:相比真实环境RL(样本效率低)、人类干预RL(难规模化),本文无需真实环境交互,样本效率大幅提升;同时支持终身学习(交替更新VLA政策与世界模型)和跨场景泛化(抗空间/背景/纹理干扰)。
- 在线RL优于离线方法:前人VLA RL多用电离线方法(如DPO),存在价值估计偏差;本文用GRPO在线RL,性能更优且支持政策持续探索新行为。
解决方法/算法的通俗解释,以及具体做法
通俗解释
把机器人的“虚拟训练环境”(世界模型)做得和真实世界一样(像素级),先让这个虚拟环境“学习”大量机器人操作数据,再用待优化的机器人政策(VLA模型)自己跑少量真实轨迹,进一步校准虚拟环境,确保虚拟环境能准确模拟政策的所有行为(包括成功和失败)。之后,让政策在这个虚拟环境里反复“想象”执行任务(生成轨迹),用一个简单模型判断“想象任务”成败(奖励),再根据奖励调整政策,直到政策在虚拟环境里表现变好——整个过程不用碰真实机器人,却能让政策学会自我修正、高效完成任务。
具体做法
-
世界模型构建与微调
- 预训练:用Open X-Embodiment(数百万机器人轨迹)预训练基于OpenSora改造的视频扩散模型,将原3D VAE替换为SDXL的2D VAE,保留细粒度运动细节,避免时间失真。
- 微调(政策行为对齐):用基础VLA政策(如OpenVLA-OFT)收集128-1280条真实轨迹,微调预训练世界模型,使其适配政策的(状态-动作)分布,能模拟失败场景。
- 长视域优化:训练时给条件帧加扩散噪声(50/1000步),提升对不完美条件的鲁棒性;扩展AdaLN块,在帧级注入动作信号与扩散时间嵌入,实现动作-帧精准对齐。
-
奖励模型训练
- 数据构建:成功轨迹的末尾片段作为正样本,成功轨迹的中间片段、失败轨迹的任意片段作为负样本,平衡正负样本比例。
- 模型与训练:用VideoMAE编码器+线性头,以二元交叉熵损失训练,推理时用滑动窗口计算轨迹各片段成功率,超过阈值则判定轨迹成功。
-
政策优化(GRPO)
- 想象轨迹生成:从真实环境采样初始状态,让当前政策(π_θ_old)与世界模型交替交互,生成一组(G个)想象轨迹。
- 动态采样:丢弃全成功或全失败的轨迹组,确保批次内轨迹奖励有差异,避免梯度消失。
- 政策更新:用GRPO优化目标(移除KL正则化,降低内存消耗),根据新/旧政策的概率比、轨迹归一化优势更新政策参数,迭代此过程直到收敛。
基于前人的哪些方法
- VLA模型基础:基于OpenVLA-OFT([24]),这是一种开源VLA模型,通过并行解码预测离散动作令牌,本文将其作为基础政策进行微调与优化。
- 强化学习算法:借鉴Group Relative Policy Optimization(GRPO,[30]),这是一种适用于稀疏奖励场景的在线RL算法,此前用于语言模型优化,本文首次将其适配到VLA模型的世界模型RL中;同时对比了离线RL方法DPO([28])、经典RL方法PPO([29])。
- 世界模型基础:基于视频生成模型OpenSora([35])的扩散骨干,改造VAE模块以适配机器人细粒度交互;参考扩散世界模型([31,32])的像素级保真思路,避免latent空间抽象化问题。
- 数据与预训练:世界模型预训练依赖Open X-Embodiment([21])数据集,这是一个大规模机器人交互数据集,提供多样化的机器人操作示范;奖励模型基于VideoMAE([39])的自监督预训练编码器,提升视频特征提取能力。
- 动作参数化:参考VLA模型的动作离散化思路([2,24]),将连续动作离散为256个bin,便于政策预测与RL优化。
实验设置、数据、评估方式
实验设置
- 模拟环境:Mimicgen模拟平台([23]),选择4个细粒度操纵任务:Coffee_D0(咖啡制作)、StackThree_D0(三物体堆叠)、ThreePieceAssembly_D0(三部件组装)、Square_D0(方块插入杆)。
- 真实环境:Cobot Mobile ALOHA机器人平台,任务为“方块插入杆”(方块与杆间隙仅5mm,难度高)。
- 基础政策:用OpenVLA-OFT,在每个模拟任务上用300条专家轨迹做模仿学习微调;真实环境任务用200条高质量专家示范微调。
- 对比方法:
- 基线:基础政策(仅模仿学习);
- RL基线:在线GRPO(直接在真实/模拟环境收集轨迹更新)、离线DPO(用政策轨迹构建偏好数据集优化)。
数据
- 世界模型预训练数据:Open X-Embodiment([21]),数百万条跨机器人、跨任务的交互轨迹。
- 世界模型微调与奖励模型训练数据:基础政策收集的真实轨迹,模拟环境用128/1280条,真实环境用128条。
- 评估数据:模拟环境每个任务测试128个不同初始状态;真实环境每个模型测试30次任务。
评估方式
- 核心指标:任务成功率(%),衡量政策完成任务的能力。
- 样本效率:对比相同轨迹预算(128/1280条)下不同方法的成功率提升幅度。
- 新兴行为分析:视觉观察政策是否出现“自我修正”(如碰撞后调整姿态)、“高效执行”(成功轨迹长度更短)。
- 泛化能力:评估3种干扰场景的成功率:
- 位置干扰(杆位置随机)、背景干扰(桌面背景替换)、纹理干扰(底座颜色/材质替换)。
- 终身学习能力:迭代收集128条真实轨迹→用WMPO优化政策→再收集轨迹,观察成功率随迭代次数的提升趋势。
提到的同类工作
1. Vision-Language-Action (VLA) Models 类
- Rt-2([1]):首个将web知识迁移到机器人控制的VLA模型,基于预训练视觉-语言模型(VLM)微调,依赖大规模示范数据。
- OpenVLA([2]):开源VLA模型,通过离散动作令牌预测实现通用操纵,仍基于模仿学习,无法从失败中学习。
- π0.5([3]):强调开放世界泛化的VLA模型,优化视觉-语言-动作的对齐,但未引入RL提升鲁棒性。
- OpenVLA-OFT([24]):本文用的基础模型,通过并行解码优化动作预测速度与成功率,核心仍为模仿学习。
2. Reinforcement Learning for VLA Models 类
- 人类干预RL([8,9,26]):在政策陷入不可恢复状态时提供人类纠正信号,降低探索成本,但需持续监督,难以规模化。
- 模拟/真实环境RL([10,11,27]):直接在模拟(如VLA-RL、SimpleVLA-RL)或真实环境用PPO/DPO/GRPO优化VLA政策,避免人类干预,但样本效率低,模拟器构建成本高。
3. World Models 类
- Latent空间世界模型([16,17,18]):如RSSM等,在抽象 latent 空间学习动态,效率高但轨迹抽象,与VLA预训练特征不匹配。
- 扩散世界模型([31,32]):强调像素级保真,适用于高斯政策RL,但未适配VLA模型,难以模拟机器人-物体细粒度交互。
- 大规模视频世界模型([12,13]):如Cosmos、Genie 3,跨领域泛化能力强,但用于机器人时存在分布不匹配,无法准确复现政策轨迹。
和本文相关性最高的3个文献
-
[21] Open X-Embodiment Collaboration. Open X-Embodiment: Robotic learning datasets and RT-X models. 2023.
- 相关性:本文世界模型的核心预训练数据来源,提供了数百万条跨机器人、跨任务的交互轨迹,为世界模型掌握基础物理动态与机器人操作知识奠定基础;若无此数据集,世界模型难以具备大规模泛化能力。
-
[30] Zhihong Shao, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. 2024.
- 相关性:本文采用的核心RL算法(GRPO)来源于此文献,该文献首次提出GRPO并验证其在语言模型稀疏奖励场景下的稳定性与 scalability;本文将GRPO适配到VLA模型的世界模型RL中,是实现高效在线政策优化的关键。
-
[24] Moo Jin Kim, et al. Fine-tuning vision-language-action models: Optimizing speed and success. 2025.
- 相关性:本文的基础VLA政策(OpenVLA-OFT)来源于此文献,该模型通过并行解码优化动作预测速度与成功率,是本文所有实验的“基准政策”;世界模型的微调、RL优化均围绕该模型展开,是实验验证的核心基础。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 8
8 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)