深扒了具身的数据路线,四小龙的格局已经形成......
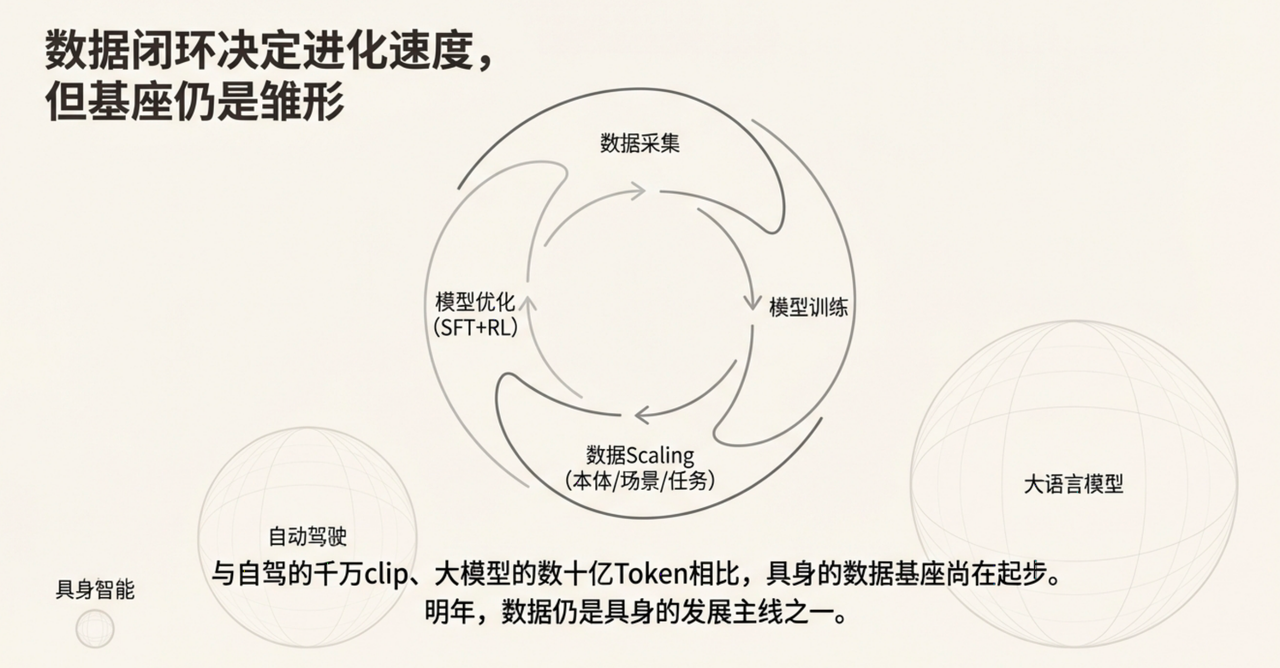
25年具身智能的发展,整体上围绕着 **数据采集 → 模型训练 → 数据scaling(本体/场景/任务) → 模型优化(SFT+RL)**的闭环链路不断提升大脑能力。
但和自驾千万clip、大模型数十亿Token的数据量相比,具身的数据基座只能说是初具雏形,明年数据仍然是具身的发展主线之一。
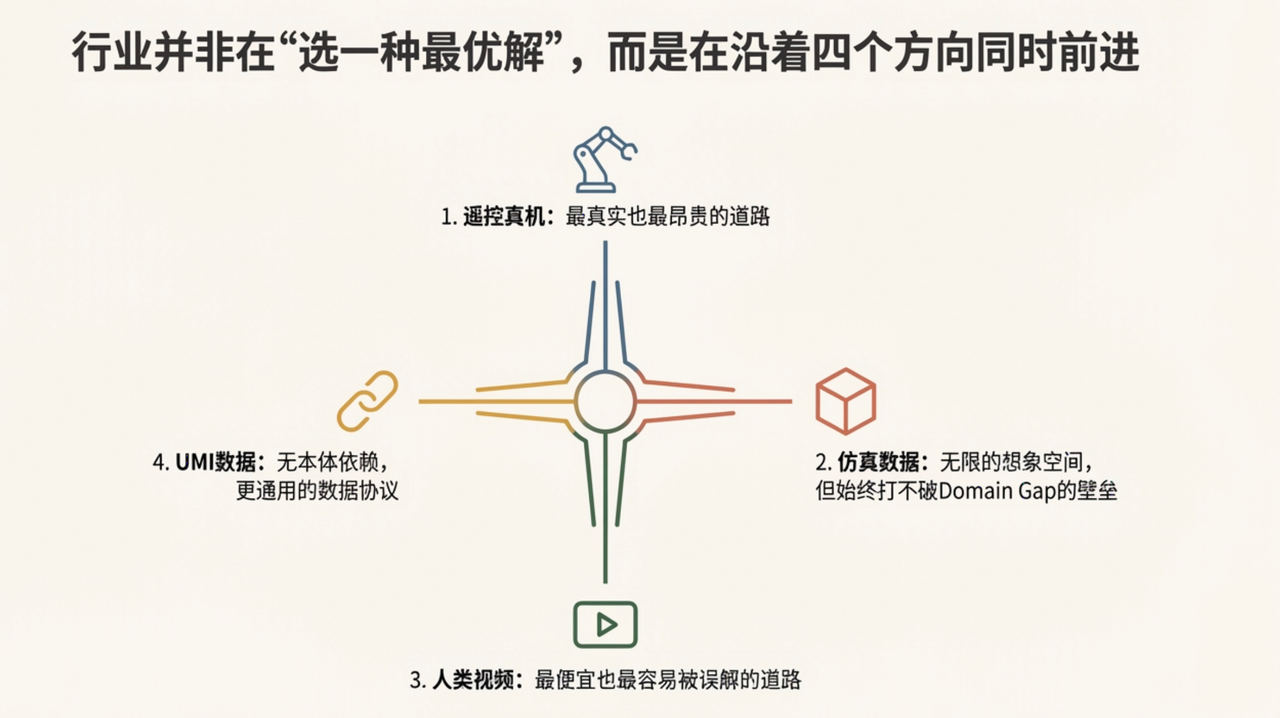
如果把所有尝试放在同一张图上看,会发现行业并不是在“选一种最优解”,而是在不同阶段、不同约束下,沿着四条方向同时前进。
- 遥控真机:最真实也最昂贵的道路;
- 仿真数据:无限的想象空间,但始终打不破Domain Gap的壁垒;
- 人类视频:最便宜也最容易被误解的道路;
- UMI数据:无本体依赖,更通用的数据协议。
在四条数据路线的背后,也初步形成以智元、银河、它石、鹿明为首的具身数据四小龙格局。
可以先下一个"判断":26年的具身会更卷,但能抢到数据的话语权,日子大概率不会差。
第一条路:遥控真机 —— 最真实,也最昂贵
遥控真机数据几乎是所有具身研究者的“安全感来源”。
它来自真实机器人、真实环境、完整任务闭环,几乎没有语义歧义,也不存在映射猜测。
正因为如此,它的数据价值密度极高。
一个完整的“抓取—操作—放置”轨迹,往往包含了大量人类在复杂环境中的隐性决策。
但问题也非常直观:
它慢、贵、强绑定。
- 需要真实机器人
- 需要专业操作者
- 一个本体就是一套数据体系
- 扩规模几乎等价于线性扩成本
遥控真机像是“高质量样本”,非常重要,但很难成为长期、大规模供给的底层方式。

第二条路:仿真合成 —— 看起来无限,但始终隔着一层
仿真数据的吸引力在于效率。
一旦环境搭好,算力就能把数据源源不断地“刷出来”,规模几乎没有上限。
近年来,通过真实数据校准仿真的 real-to-sim-to-real 路线,以及 3D 重建、物理引擎增强,仿真的“像真度”确实在快速提升。
但在真实落地时,总会撞到那层熟悉的墙:domain gap。
- 力学参数的细微偏差
- 接触、摩擦、形变的简化
- 传感噪声与真实世界的不一致
这些问题在感知阶段尚可缓解,但在精细操作和复杂交互中,会被不断放大。
仿真更像是一块很好的“训练场”,却很难单独决定真实世界的上限。

第三条路:人类视频 —— 最便宜、也最容易被误解
human video 是最近两年最容易引发想象的一条路。
它的优势几乎是压倒性的:
- 数据量巨大
- 获取成本极低
- 场景覆盖极广
但当兴奋感褪去,问题也逐渐显现:
- 人类与机器人的身体结构并不一致
- 视频里缺少力觉、触觉等关键反馈
- 动作可执行性并不保证
- 标注与对齐成本远高于直觉
这也是为什么,在所有已验证的路径中,human video 几乎都不是“起点”,而是叠加项——它在真实交互数据已经足够丰富之后,才能放大能力,而不是凭空生成能力。

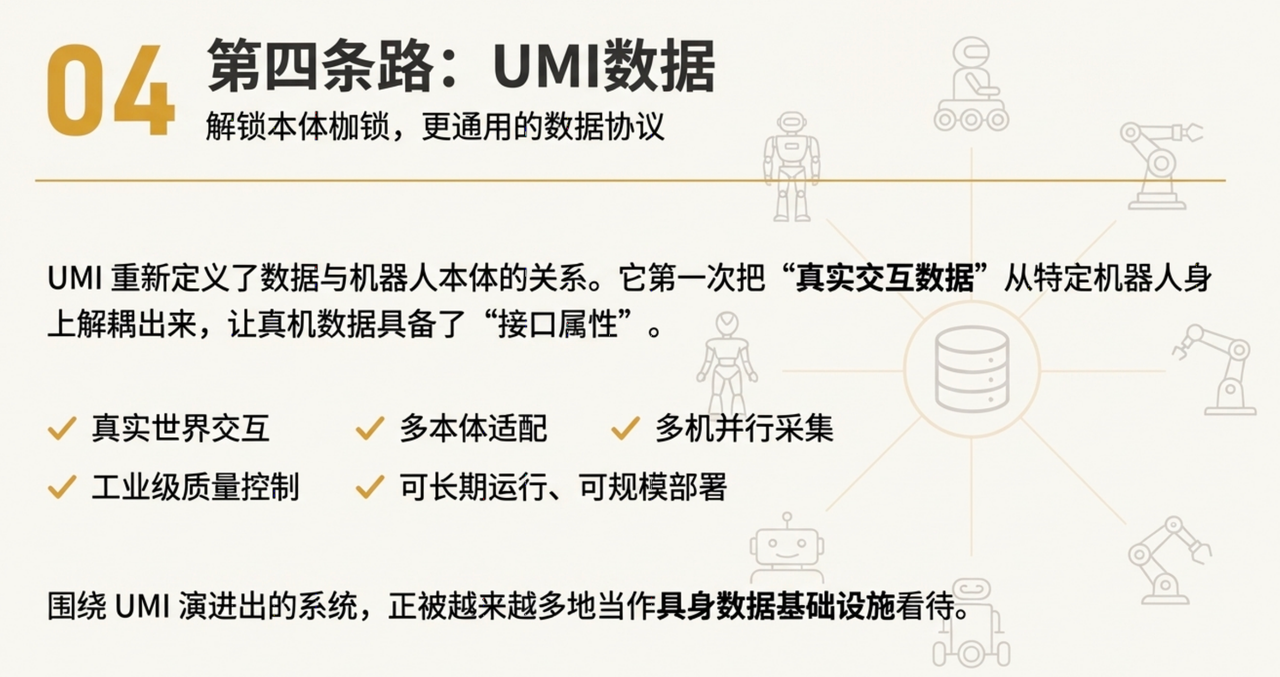
第四条路:UMI数据 —— 解锁本体枷锁、更通用
UMI最大的特点是重新定义了数据与机器人本体的关系。

它第一次把**“真实交互数据”**从特定机器人身上解耦出来:
- 数据采集不再依赖某一型号机器人
- 同一套交互数据可以映射到多种本体
- 真机数据第一次具备了“接口属性”
当 UMI 从研究原型走向工程化系统之后,许多之前看似不可兼得的目标,开始同时成立:
- 真实世界交互
- 多本体适配
- 多机并行采集
- 工业级质量控制
- 可长期运行、可规模部署
这也是为什么,围绕 UMI 演进出的系统,会被越来越多地当作具身数据基础设施来看待——它不是替代遥控、仿真或人类视频,而是让“真实数据”第一次具备了持续供给的可能性。
换个角度,具身数据本就应当如此:多本体、可交互并行、规模化部署。
当路线开始被具体化
随着四条数据路线逐渐跑通,各自的代表性实践也开始浮出水面。
- 在遥控真机数据方向,海外有 Tesla 持续推进遥操体系,国内则以 智元机器人 等团队为代表,在真实本体与任务闭环上不断深化;
- 在仿真数据路线,银河通用 等团队依托算力与仿真引擎,持续扩大合成数据规模;
- 在人类视频数据方向,海外有 Figure AI,国内则以 它石智航 为代表,尝试通过大规模人类行为视频拓展语义覆盖;
- 而在 UMI 路线 上,Generalist 采集的27万小时的真机数据训练的Gen0 模型已经验证了UMI数据的价值,鹿明机器人是产业界最早探索UMI数据路线的代表。
而我们把这四条数据路线并排来看,会发现它们已经不再是零散的方法选择,而是在实践中逐渐稳定为四种具身数据供给范式。
也正是在这种背景下,业内开始用“具身数据四小龙”来概括当前的格局——不是为了贴标签,而是为了描述一种结构性的分工结果。

从执行层面看,国内这种分化其实非常直观:
- 在遥控真机数据方向,国内外已有多家团队同时推进,不同公司在不同应用场景中各有优势,国内最具代表性的便是智元,开源百万真机数据集AgiBot World,支撑GO - 1具身基座大模型和全人形WholeBodyVLA方案,积累很深;
- 在仿真数据路线,依托算力与引擎能力,参与者众多,规模与效率仍在持续拉升,国内的银河通用基于十亿量级的仿真数据发布了全球首个全仿真预训练具身大模型GraspVLA,以及身智能灵巧手多样抓取仿真数据集DexonomySim;
- 在人类视频数据方向,由于数据来源天然开放,方案与团队并行发展,很难形成单一集中格局,国内它石智航十月份全球首发 WIYH 数据集,10 万 + 真实人类操作视频,还有配套的第一视角SenseHub数采系统;
- 而在 UMI 路线 上,国内能够将其真正跑到规模化、工程化、持续交付阶段的团队,目前并不多,国内鹿明机器人的丁琰团队,是较早系统性投入 UMI 研究的,十二月也刚刚发布了多模态无本体数据采集软硬件系统FastUMI Pro,采集效率提升3倍,成本降至传统方案的1/5。
当行业开始从“证明可行”走向“持续进化”,
哪条路线能稳定地产出高质量真实数据,就会变得越来越关键。
回头再看这四条路线,会发现它们并不是互相否定,而是各自承担着不同角色:
- 遥控真机:验证能力上限;
- 仿真数据:放大探索空间;
- 人类视频:扩展语义覆盖;
- UMI:支撑真实世界的长期数据供给。
这种感觉,像是突然看见了一条通向远方的路。
时间积累,在这里变得尤为重要
从行业演进的角度看,其他数据路线可以相对独立推进,而 UMI 路线对团队早期选择与持续投入的依赖更强。
一旦在初期就沿着“无本体、可复用、可规模的真实数据采集”方向持续打磨,后续在工程化与交付层面便更容易形成连续积累;反之,即便意识到其重要性,补齐这一能力也往往需要时间。
因此,当前看到的差异,更像是路线选择与长期积累的结果,而非短期竞争的直接体现。
总结
随着具身智能从探索阶段走向长期能力迭代阶段,数据体系的重要性正从“支撑算法”转变为“决定节奏”。
不同数据路线在各自维度发挥作用,而 UMI 这类兼顾真实交互与规模化的方案,正在成为连接研究与落地的重要一环。
在这一格局下,具身数据的“四小龙”更像是一种阶段性结构描述。
而哪些路线、哪些团队能够在真实世界中持续运行并累积数据优势,时间会给出答案。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 11
11 0
0- 0



 已为社区贡献129条内容
已为社区贡献129条内容

所有评论(0)