具身思维树:基于具身世界模型的刻意操控规划
25年12月来自中科院大学、清华大学、京东探索研究院、上海科技大学和南京大学的论文“Embodied Tree of Thoughts: Deliberate Manipulation Planning with Embodied World Model”。世界模型已成为机器人操作规划的关键组成部分,使智体能够在执行操作前预测未来的环境状态并推断其后果。虽然视频生成模型的应用日益广泛,但它们通常缺
25年12月来自中科院大学、清华大学、京东探索研究院、上海科技大学和南京大学的论文“Embodied Tree of Thoughts: Deliberate Manipulation Planning with Embodied World Model”。
世界模型已成为机器人操作规划的关键组成部分,使智体能够在执行操作前预测未来的环境状态并推断其后果。虽然视频生成模型的应用日益广泛,但它们通常缺乏严谨的物理基础,导致出现幻觉,并且无法在长期物理约束方面保持一致性。为了解决这些局限性,提出具身思维树(EToT),这是一个从真实-到-模拟-再到-真实的规划框架,它利用基于物理的交互式数字孪生作为具身世界模型。EToT 将操作规划构建为一个树搜索过程,并通过两种协同机制进行扩展:(1)先验分支,它基于语义和空间分析生成多样化的候选执行路径;(2)反思分支,它利用VLM在模拟器中诊断执行失败,并通过纠正措施迭代地优化规划树。通过将高级推理建立在物理模拟器之上,该框架确保生成的规划符合刚体动力学和碰撞约束。
开发能够在开放世界环境中完成复杂操作任务的通用机器人系统仍然是一项根本性的挑战[1]。此类系统必须将高层语义理解与底层物理执行相结合。视觉语言模型(VLM)[2][3]的最新进展使得机器人能够理解自然语言指令并生成高层任务规划[4]–[6]。然而,这些方法主要基于静态场景表示,缺乏预测长时程动作序列下环境动态演变所需的物理直觉。
为了克服这一局限性,基于机器人动作预测未来状态的世界模型日益受到关注。近期的一系列研究采用视频生成模型作为未来场景的前向预测器,用于基于物理的规划[7]。虽然此类像素空间模型在短期预测方面有效,但它们缺乏明确的物理基础,难以捕捉接触密集交互的累积效应,常常在长时程中产生与物理实际情况不符的“幻觉”[8]。因此,它们的适用性通常仅限于对物理一致性要求不高的短期动作预测。
另一种范式是 Real2Sim,它在物理模拟器中重建真实世界场景,并将模拟器用作基于物理的世界模型 [9]。3D AIGC [10]、[11] 的最新突破以及高保真仿真平台 [12]、[13] 的成熟显著提高该方法的可行性。与基于视频的预测器不同,基于模拟器的世界模型强制执行明确的物理定律,从而实现一致的多步动力学和可靠的接触交互建模。此外,模拟器可以直接访问潜在的物理属性,例如质量、摩擦力和关节约束,这些属性对于精确的长期规划至关重要。
本文提出一种名为“具身思维树”(EToT)的规划框架,该框架将VLM的推理建立在基于物理的具身世界模型之上。与视频生成方法不同,EToT采用物理模拟器来确保所有预测结果严格遵循刚体动力学和碰撞约束。此外,由于现实世界的操作任务通常存在多种备选动作和长程因果关系,将任务规划构建为一个树状结构的搜索过程,以提供足够的广度和深度来探索可行的解决方案。
如图所示,在物理模拟器中将现实世界场景重建为一个交互式数字孪生。这个基于物理的孪生使规划器能够在实际执行之前模拟VLM生成动作的结果,并进行视觉故障分析。通过先验分支,规划器生成各种候选动作序列,构成初始规划树。当某个节点在模拟中发生故障时,相应的模拟观测结果会被反馈给VLM,VLM执行反思分支来分析故障原因,并基于原始规划生成修正后的分支。通过模拟、视觉诊断和树状图扩展的迭代循环,EToT 逐步揭示出针对复杂、长期现实任务的经过物理验证的方案。
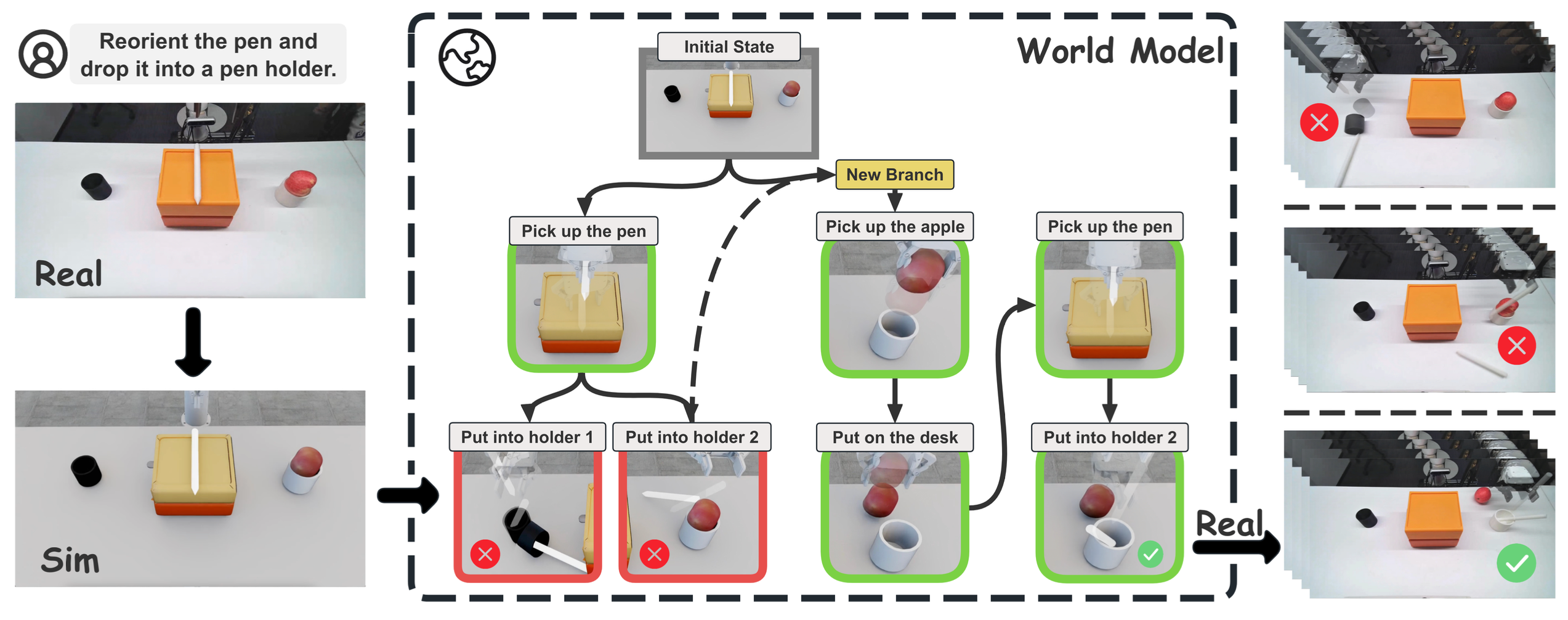
具身思维树(EToT)框架(如图所示),通过将视觉-语言模型(VLM)与基于物理的具身世界模型和规划树搜索机制相结合,扩展VLM的推理能力。所提出的方法围绕以下核心问题展开:(1)如何形式化定义机器人动作技能?(2)如何构建高保真交互式数字孪生? (3)如何构建和搜索基于世界模型的规划树?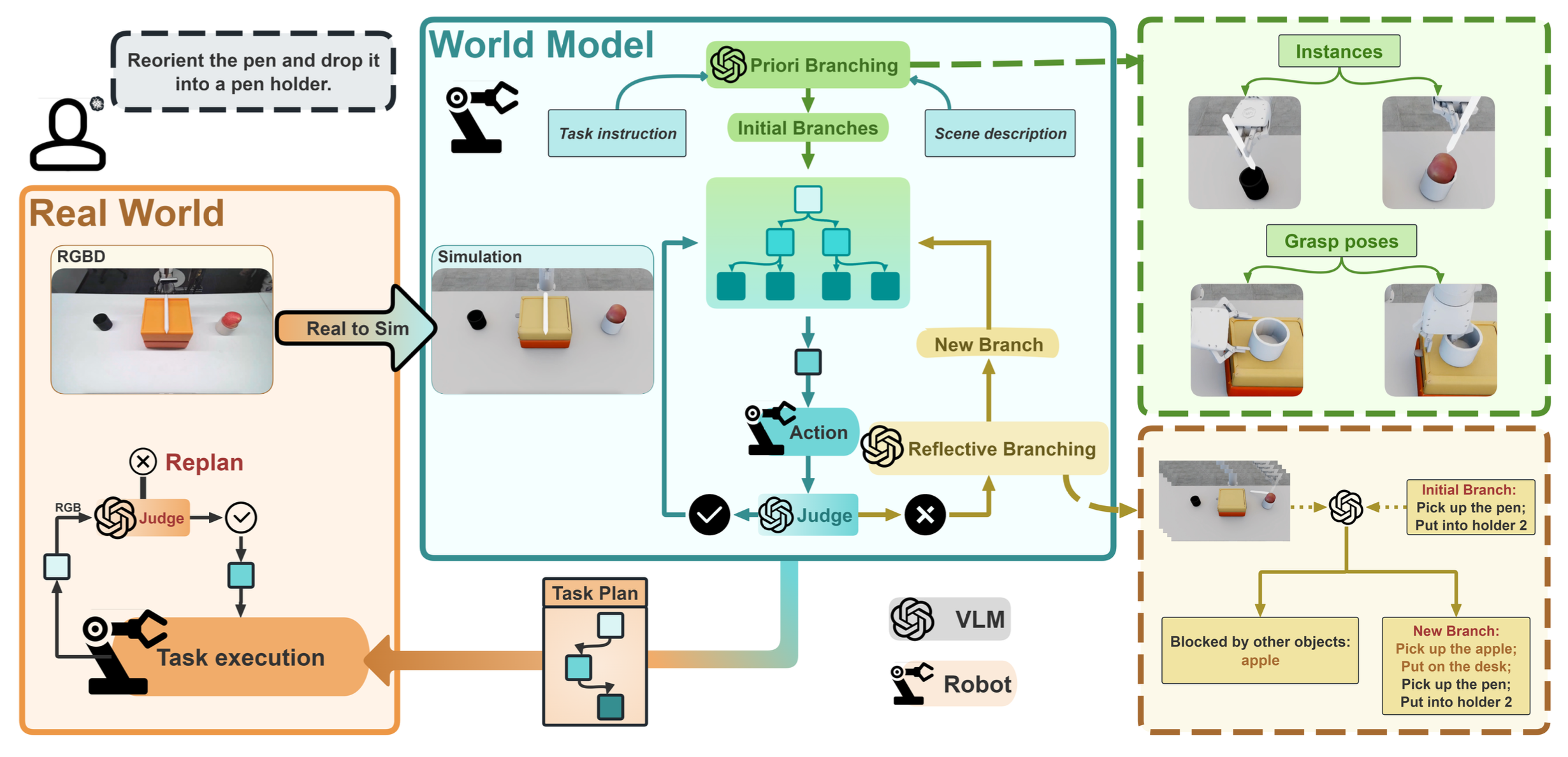
动作技能集
本文重点关注机器人操作的任务规划方面。为了规范规划流程并便于VLM对动作序列进行逻辑结构化,将机器人技能建模为一组离散的语义动作基元。具体而言,定义以下五个动作技能:
[拾取,物体]
[放置,表面]
[放入,容器]
[打开,物体]
[关闭,物体]
每个动作技能都通过专用API实现。对于“拾取”动作,用AnyGrasp [31] 从RGB-D观测中估计可行的抓取姿态和相应的夹爪宽度。“放置”动作将抓取的物体放置在指定的支撑面上,而“放入”动作将物体放入指定的容器中。“打开”和“关闭”动作作用于铰接/关节体,并使用手动编写的控制基元执行。
在任务设置中,对于大多数“拾取”或“放置/放入”动作,并未显式地建模多个候选姿态。然而,对于具有多种不同抓取方向且难以确定可行姿态的物体,提供额外的姿态特定配置,记为 [拾取, 物体] (姿态),以便区分不同的抓取策略。
具身世界模型构建
用高效的场景重建流程构建具身世界模型,该流程在大多数情况下仅需一次 RGB-D 观测。给定一个输入的 RGB-D 帧,应用 SAM-3 [32] 从 RGB 图像中提取物体掩码,然后由 SAM-3D-Objects [11] 处理以生成带纹理的物体网格。为了恢复度量尺度,采用 DexSim2Real2 [33] 的尺寸估计模块,从 RGB-D 输入生成缩放后的网格。缩放后的网格连同 RGB-D 数据和掩码一起被传递给 FoundationPose [34] 进行物体姿态估计。最后,重建的网格被导入到 OmniGibson [12] 模拟器中,以生成与物理场景对齐且可交互的数字孪生模型。
对于包含关节体的场景,需要从不同的视角拍摄额外的 RGB-D 帧,该帧中物体处于不同的运动学状态(例如,张开与闭合)。这些多状态观测数据使用 DexSim2Real2 [33] 进行处理,以恢复关节结构。
规划树的构建和搜索
如上图所示,构建一个基于世界模型的规划树来支持操作规划。规划过程包含两个关键模块:先验分支和反思分支。先验分支负责生成初始规划树;然而,由于物理推理不完整,生成的分支可能无效或不安全。为了解决这些问题,反思分支分析模拟执行结果,识别失败原因,并在树搜索过程中动态生成修正后的分支。
整个规划流程总结在算法 1 中。
- 先验分支:在初始阶段,VLM分析场景和任务指令,构建基于目标实例和候选交互模式的初步规划树。
场景解析和任务理解。VLM 以场景的 RGB 图像和任务指令作为输入。它提取目标级信息并推断相关的空间关系,包括关系谓词(例如,“笔在抽屉上”)和动作状态(例如,“抽屉已关闭”)。
候选分支生成。基于解析后的场景表示,VLM 生成多个候选规划分支,每个分支对应于从根到叶的完整动作序列。该模型鼓励在存在多个可行动作选择的决策点上显式地进行分支。如上图所示,考虑两类分支:
实例级分支:分支在目标选择上有所不同,例如 (1) [拿起笔],[放入,笔架 1];(2) [拿起笔],[放入,笔架 2]。
操作参数分支:分支在抓取配置上有所不同,例如 (1) [拿起,笔架](水平);(2) [拿起,笔架](垂直)。
初始规划树构建。候选分支中的每个动作都作为节点插入到规划树中,每个完整的分支构成从根节点到叶节点的路径。共享相同动作前缀的分支将被合并,以生成紧凑、非冗余的树状表示。
- 树搜索与反思分支:采用广度优先搜索 (BFS) 策略逐层遍历规划树。结合反思分支和动态计划修正,该策略能够在保持鲁棒性和推理深度的同时,高效地发现可行的任务规划。在搜索过程中,每个节点沿分支依次进行评估:如果 VLM 认为与当前节点关联的动作可行,则搜索继续到下一个节点;否则,过程进入反思分支阶段。如上图所示,反思分支包含以下两个步骤:
故障检测。在实际操作中,成功执行不仅需要实现预期的任务目标,还需要避免对周围物体造成意外干扰或损坏。为了评估正确性和安全性,VLM 会比较每次模拟执行前后所有物体的状态。如果执行操作引发环境变化,且这些变化无法利用现有动作技能轻松恢复,例如网球滚下桌子或钢笔掉落并滑出机器人可触及的工作区域,则该执行操作被归类为不安全。
树状结构修正与扩展。当检测到执行失败或不良副作用时,VLM 会诊断根本原因并提出纠正策略。本文主要考虑两类纠正措施。(i) 碰撞引起的干扰:如果规划的运动会导致与附近物体发生碰撞并改变其状态,则纠正策略首先将受影响的物体移动到安全位置,然后再重新尝试执行原始动作。(ii) 顺序相关的冲突:某些失败是由不正确的动作顺序引起的。在这种情况下,纠正策略通过重排列相关操作来修改分支。
闭环系统构建
进一步开发一种融合真实机器人反馈的闭环执行框架。每次动作后,VLM都会使用真实摄像头观测数据,以与仿真一致的方式评估执行结果。一旦检测到故障,系统会将当前场景重建为新的初始状态,并将其作为重规划的根节点。然后,利用更新后的状态和原始任务指令重新生成新的规划树,并进行新一轮的树构建和搜索。这种设计使得在实际执行过程中能够持续进行反馈驱动的修正。
实验装置
硬件。如图所示,所有实验均使用配备平行爪夹爪(1 自由度)的 xArm6 6DoF 机器人机械臂和 Azure Kinect DK RGB-D 相机进行。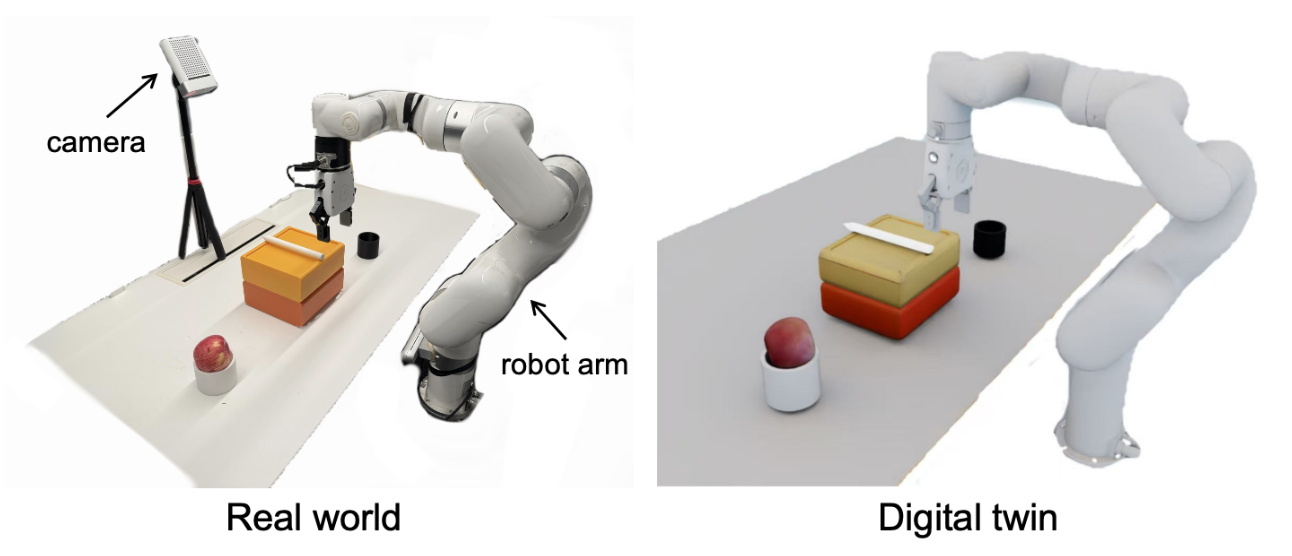
基线方法。将该方法与三个基线方法进行比较。ReKep [24] 提取视觉关键点,并将其与 VLM 引导的推理相结合,生成基于约束的任务规范,用于操作规划。ReKep w/ CoT [35] 在 ReKep 的基础上,通过显式的思维链提示来增强其功能,以鼓励更深入、更精细的推理。设计简洁的多步骤提示,引导 VLM 分析任务依赖关系并预测潜故障模式,从而生成更深入、更具逻辑性的行动规划。将 ReKep w/ CoT 与 Reflect [16] 中提出的反思机制的预言机变体相结合,得到 Reflect*。该基线采用相同的基于 VLM 的执行评估模块来评估操作结果。检测到故障后,会调用类似 oracle 的反思步骤,其中会使用可用的操作原语手动指定有效的恢复规划(如果存在此类规划)。
在实现中,除了任务规划组件(包括关键点提取和操作原语集)之外,对所有方法的配置进行标准化。所有方法都提供手动标注的高精度关键点,以确保公平比较。由于先前工作中操作原语的定义存在差异(例如,原始的 ReKep 提示不包含对铰接目标的操作),采用手动后处理程序将每种方法生成的规划映射到统一的 API 中。具体来说,ReKep 生成的语义规划(涉及通过关键点指定关闭抽屉等操作)会被手动转换为相应的 CLOSE API。
指标。通过任务成功率来评估每种方法,任务成功率定义为在不造成环境有害变化的情况下达到指定目标的试验比例。
实现细节。所有基线方法和提出的方法均使用 GPT-4o [2] 作为底层视觉语言模型。摄像头以固定的倾斜视角安装。对于每个任务,所有实验均重复 10 次独立试验。
任务设计
设计一套包含七个操作任务的模型,以系统地评估机器人规划的四个基本能力:(a) 对物体可操作性的感知,(b) 对三维空间关系的理解,© 对物理动力学的预测,以及 (d) 对外部干扰的鲁棒性以及自动恢复能力。
包含三个或更少动作步骤的任务被归类为短时任务(任务 1-4),而需要三个以上动作的任务被归类为长时任务(任务 5-7)。此外,引入一个干扰-觉察任务,其中干扰对应于任务执行过程中人为造成的干扰。所有任务的概览如图所示。
任务 1:打开微波炉门。(b, c) 直接打开微波炉门会导致桌上的网球掉落;因此,必须在打开微波炉门之前将网球移开。
任务 2:调整笔的方向并将其放入笔架。© 将笔插入黑色笔架时不稳定,由于支撑不足而倾倒,需要将其放入白色笔架才能稳定插入。
任务 3:水平或垂直拿起笔架。(a) (a) 由于表面摩擦力低且夹爪宽度接近最大值,水平侧抓取会导致滑动,因此需要采用自上而下的抓取策略。
任务 4:关上抽屉。 (b, c) 抽屉内的玩具超出抽屉关闭所需的空间,需要将其移至安全位置后再关闭抽屉。
干扰任务:拿起一个网球。(a, d) 人为干扰导致原目标无法抓取后,机器人必须检测到抓取失败并重新计划抓取备用球。
任务 5:调整一支笔的方向并将其放入笔架。(b, c) 白色笔架上的苹果阻碍了笔的插入并导致反弹,需要先移除苹果才能放置笔。
任务 6:将苹果和笔架放在抽屉上,苹果放在笔架内。(a, b) 在放置笔架之前插入苹果会阻碍所需的自上而下的抓取;必须先放置笔架,然后再插入苹果。
任务 7:将苹果和网球一起或分别放入抽屉或笔架中。确保抽屉已关闭。 (a、b、c)苹果违反了抽屉高度限制,网球最初挡住了通道,需要在将苹果放入支架并将网球放入抽屉之前重新放置网球。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 28
28 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)