【VLA(一)】CogACT 3D-CAVLA (CoT RoI) Evo-0 (VGGT) SpatialActor(Raw Depth&Pre-trained Depth Exper)
CogACT与3D-CAVLA:机器人视觉-语言-动作模型的创新突破 CogACT提出了一种解耦架构的VLA模型,通过分离认知(VLM)与动作(DiT)模块,采用扩散模型处理连续动作空间,并创新性地提出自适应动作集成算法,显著提升了动作精度和多模态处理能力。实验表明,增加动作模块参数比单纯扩大VLM更有效。 3D-CAVLA则针对VLA模型在未见任务中的泛化问题,通过整合3D深度感知、思维链推理和
文章目录
- 1. CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation【Synergizing 协同增效】
- 2. 3D-CAVLA: Leveraging Depth and 3D Context to Generalize Vision-Language Action Models for Unseen Tasks
- 3. Evo-0: Vision-Language-Action Model with Implicit Spatial Understanding
- 4. SpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation 【Disentangled 解耦】
1. CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation【Synergizing 协同增效】
1. 核心摘要 (Executive Summary)
CogACT 是一种新型的视觉-语言-动作(VLA)模型。与 RT-2 或 OpenVLA 等将动作视为离散语言Token进行自回归预测的模型不同,CogACT 认为高层语义规划(认知)与底层运动控制(动作)存在模态差异。
核心创新点:
- 架构解耦:利用 VLM 进行语义理解生成“认知特征(Cognition Feature)”,利用 Diffusion Transformer (DiT) 作为专用动作解码器。
- 动作建模:采用扩散过程处理动作的连续性、多模态分布及时间相关性,而非简单的离散化(Quantization)或回归。
- 自适应集成:提出自适应动作集成(Adaptive Action Ensemble, AAE)算法,在推理阶段动态加权历史预测,避免多模态动作平均导致的轨迹平滑问题。
- Scaling Law:发现动作模组的参数量与任务成功率呈对数线性关系,且相比于单纯增加 VLM 参数,增加动作模组参数更具性价比。
2. 离散化回归方法的问题 (Problem Statement)
当前 VLA 模型(如 RT-2, OpenVLA)通常复用 VLM 的 Transformer 架构,将连续的机器人动作空间(如 7-DoF)离散化为 Token ID。
现有方法的局限性:
- 精度损失:简单的离散化无法捕捉高精度的操作需求 。
- 模态错配:语言是高度压缩的离散符号,而动作是连续、高频且具有多模态分布(Multimodal Distribution)的信号 。
- 概率建模缺失:简单的回归头(如 LSTMs)忽略了动作的概率性质;简单的 Token 预测难以处理同一指令下的多种可行轨迹。
CogACT 通过类比人类大脑皮层结构(视觉皮层、语言皮层与运动皮层的功能分区),主张将“大脑”(VLM)与“小脑/脊髓”(Action Module)分离。
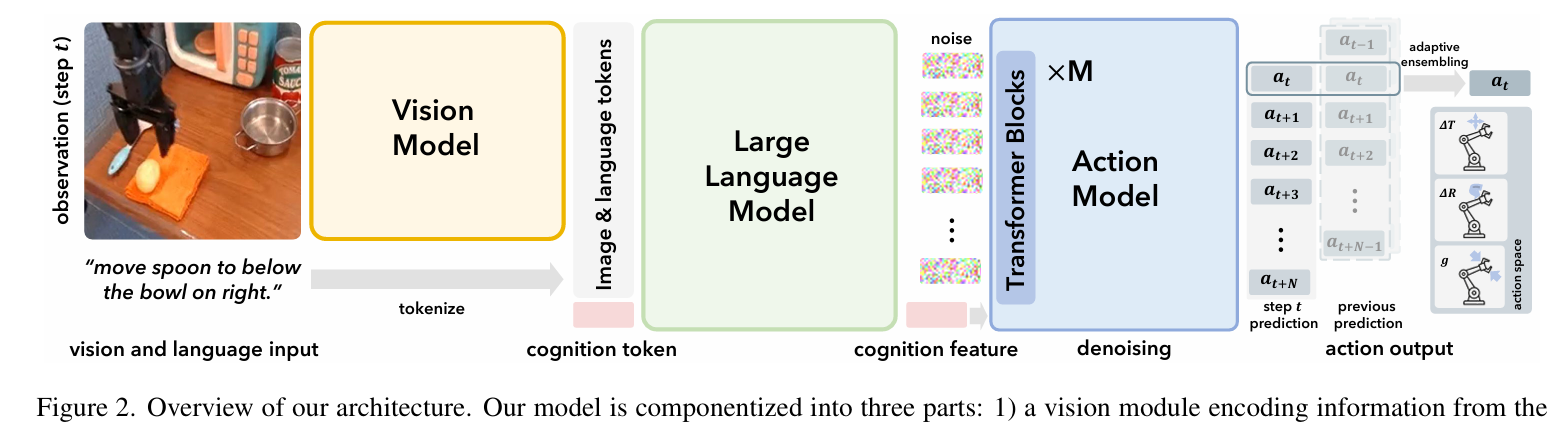
3. 技术方法论 (Methodology)
CogACT 采用端到端训练的组件化架构,包含三个主要模块:
3.1 模型架构
-
视觉模块 (Vision Module):
- 采用 DINOv2 和 SigLIP 双编码器。
- 输出特征拼接后投影为视觉 Token 序列 V = { v 1 , . . . , v N v } \mathcal{V}=\{v_1, ..., v_{N_v}\} V={v1,...,vNv}。
-
语言/认知模块 (Language/Cognition Module):
- Backbone: Llama-2 (7B) 。
- 输入: 语言指令 Token T \mathcal{T} T + 视觉 Token V \mathcal{V} V + 一个可学习的 Cognition Token c c c 。
- 输出: 对应 c c c 的输出特征 f t c f_t^c ftc,该特征浓缩了当前时刻的感知与规划信息,作为动作生成的 Condition。
-
动作模块 (Diffusion Action Module):
- Backbone: Diffusion Transformer (DiT) 。
- 输入: 认知特征 f t c f_t^c ftc(作为 Condition Token)、噪声动作序列、时间步编码。
- 预测: 当前动作 a t a_t at 及未来 N N N 步动作 ( a t , . . . , a t + N ) (a_t, ..., a_{t+N}) (at,...,at+N)(默认 N = 15 N=15 N=15)。
- 动作空间: 7-DoF (3平移 + 3旋转 + 1夹爪) 。
3.2 训练目标 (Training Objective)
模型进行端到端训练(VLM 部分参数也参与更新),损失函数为预测噪声与真实噪声的 MSE:
L M S E = E ϵ ∼ N ( 0 , 1 ) , i ∣ ∣ ϵ ^ i − ϵ ∣ ∣ 2 \mathcal{L}_{MSE} = \mathbb{E}_{\epsilon \sim \mathcal{N}(0,1), i} || \hat{\epsilon}^i - \epsilon ||_2 LMSE=Eϵ∼N(0,1),i∣∣ϵ^i−ϵ∣∣2
其中 ϵ ^ i \hat{\epsilon}^i ϵ^i 是 DiT 在第 i i i 步去噪时的预测噪声。
3.3 推理算法:自适应动作集成 (Adaptive Action Ensemble)
针对 Action Chunking 和传统 Temporal Ensemble (TE) 的不足(即可能对属于不同 Mode 的动作进行加权平均,导致不合理的动作),CogACT 提出了基于相似度的自适应加权。
算法逻辑:
最终执行动作 a ^ t \hat{a}_t a^t 是当前观测的预测 a t ∣ o t a_t|o_t at∣ot 与历史观测预测 a t ∣ o t − k a_t|o_{t-k} at∣ot−k 的加权和:
a ^ t = ∑ k = 0 K w k a d a ⋅ ( a t ∣ o t − k ) ∑ k = 0 K w k a d a \hat{a}_t = \frac{\sum_{k=0}^{K} w_k^{ada} \cdot (a_t|o_{t-k})}{\sum_{k=0}^{K} w_k^{ada}} a^t=∑k=0Kwkada∑k=0Kwkada⋅(at∣ot−k)
权重 w k a d a w_k^{ada} wkada 计算如下 :
w k a d a = exp ( α ⋅ CosineSimilarity ( a t ∣ o t , a t ∣ o t − k ) ) w_k^{ada} = \exp(\alpha \cdot \text{CosineSimilarity}(a_t|o_t, a_t|o_{t-k})) wkada=exp(α⋅CosineSimilarity(at∣ot,at∣ot−k))
4. 结论
优势:
- 架构合理性:将 VLM 作为“认知压缩器”而非“动作执行器”,利用 Diffusion Model 处理低层控制,符合机器人控制系统的分层设计原则。
- 数据效率与性能:证明了在 7B 级别的 VLM 基础上,通过增强 Action Module(即使仅增加 ~300M 参数),可以获得超越 55B VLM 的控制效果。
- 工程落地价值:Adaptive Ensemble 算法简单有效,且 CogACT 在推理时仅需缓存少量历史预测,计算开销增加有限。
可能的局限与思考:
- 推理速度:虽然 DiT 性能强大,但扩散模型的迭代去噪过程(论文中使用了 10 步 DDIM)相比于简单的 Token 预测或 MLP 回归,推理延迟可能会略高,这在极高频控制场景下需要考量。
- Cognition Token 的瓶颈:整个 VLM 的信息仅通过一个
cognition token传递给 DiT,这是否会成为复杂长序列推理任务的信息瓶颈,值得进一步探讨。
2. 3D-CAVLA: Leveraging Depth and 3D Context to Generalize Vision-Language Action Models for Unseen Tasks
1. 核心摘要 (Executive Summary)
本研究针对现有视觉-语言-动作模型(VLA)在处理未见任务(Unseen Tasks)时泛化能力不足的问题,提出了 3D-CAVLA 模型。该模型在 OpenVLA-OFT 的架构基础上,通过整合思维链(Chain-of-Thought, CoT)推理、3D 深度感知以及任务导向的感兴趣区域(ROI)检测,显著增强了机器人的场景理解与逻辑规划能力。
2. 研究背景与动机 (Motivation)
2.1 现有挑战
- VLA 的局限性:当前的 VLA 模型(如 OpenVLA)通常将 RGB 图像和语言指令作为输入,在训练过的分布内任务上表现优异(成功率约 95%)。然而,这些模型缺乏对未见任务的详细行为分析,泛化能力较差。
- 模态缺失:多数 VLA 仅依赖 2D RGB 图像,缺乏处理复杂几何形状和空间推理所需的深度信息 。
- 推理缺失:现有模型通常直接从输入映射到输出,缺乏中间推理步骤,难以像人类一样将新任务分解为已知的子步骤。
2.2 研究目标
本研究旨在通过增强空间感知(3D Depth)和上下文理解(CoT + ROI),提升 VLA 模型在未见任务中的鲁棒性和适应性 。
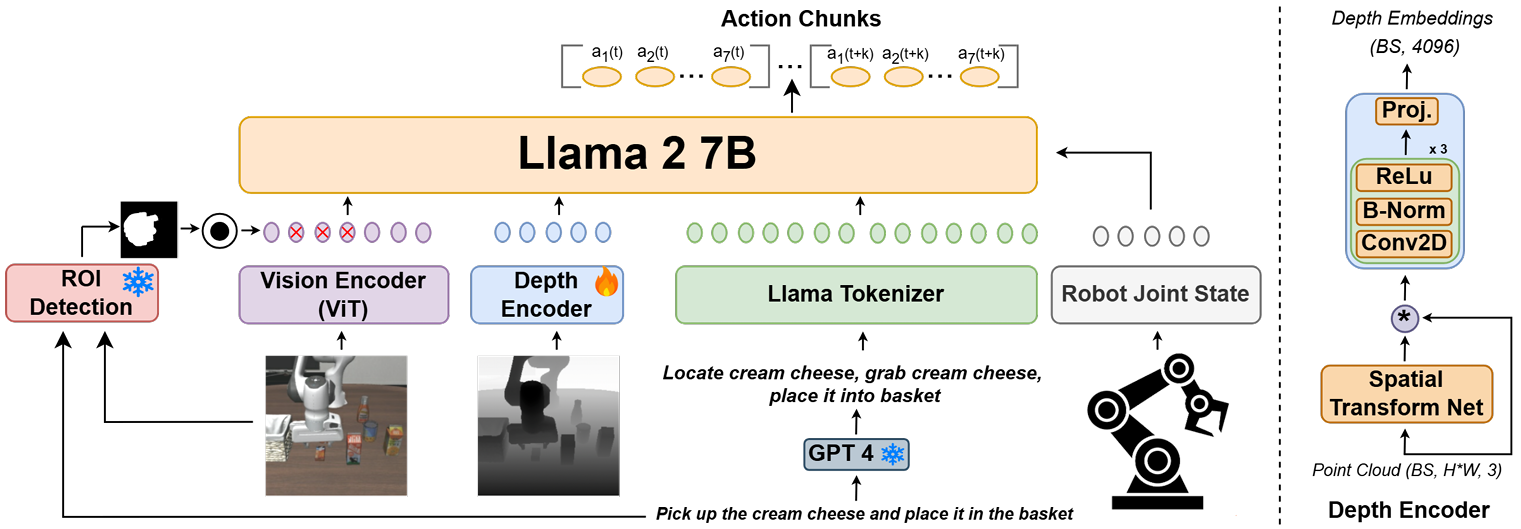
3. 方法论 (Methodology)
3D-CAVLA 建立在 OpenVLA-OFT 的架构之上,后者是一个基于 Llama 2 7B 的高效微调 VLA 模型。3D-CAVLA 引入了三个关键模块来改进输入模态和特征提取:
3.1 思维链叙述指令 (Chain-of-Thought Narrative Instructions)
- 原理:模拟人类学习过程,即利用已有的操作经验来解决新任务。
- 实现:使用 GPT-4 将简单的任务指令(如“将橙子放入篮子”)分解为一系列具体的、基于物理直觉的子步骤(如“定位橙子”、“从中心抓取”、“移动到篮子上方”、“放入篮子”)。
- 作用:这种分解使得模型能够识别出未见任务中包含的已知子技能(如抓取、放置),从而通过组合已知技能来解决未知问题 。

3.2 深度特征集成 (Integrating Depth Features)
- 深度编码器:引入了一个轻量级(约 1M 参数)的可训练深度编码器,灵感源自 PointNet。
- 处理流程:
- 利用相机内参将深度图转换为 3D 点云 ( P ∈ R B × H × W × 3 P \in \mathbb{R}^{B \times H \times W \times 3} P∈RB×H×W×3) 。
- 通过空间变换网络(Spatial Transform Net)处理点云,使其具有空间不变性。
- 经过卷积层(Conv2D)、批归一化(BatchNorm)和 ReLU 激活后,投影到与 LLM 输入维度匹配的嵌入空间。
- 融合:深度嵌入与视觉、语言及本体感觉信息进行拼接(Concatenation)。
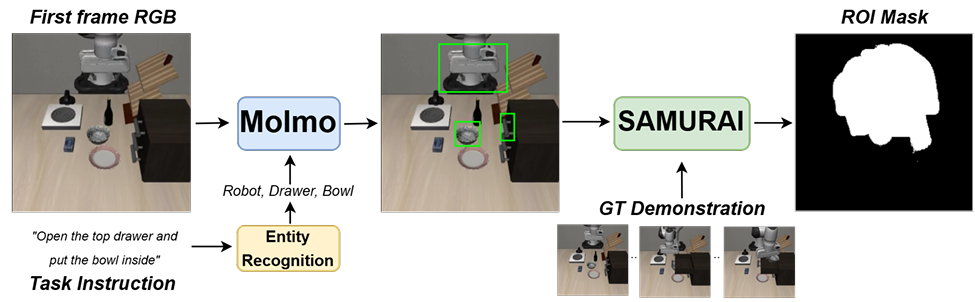
3.3 任务感知感兴趣区域检测 (Task Aware ROI Detection)
- 目的:解决未见任务中干扰物较多的问题,引导模型关注与任务相关的视觉区域。
- 管线 (Pipeline):
- 实体识别:解析任务指令,提取目标物体。
- 物体检测:使用 Molmo 生成目标物体的边界框。
- 物体跟踪:使用 SAMURAI 估计物体移动的图像区域,生成二进制掩码(Mask)。
- 训练策略:为了防止过度依赖掩码并保留必要的背景上下文,训练过程中仅有 25% 的概率使用该 ROI 掩码进行特征池化。
4. 消融研究 (Ablation Studies)
为了验证各组件的有效性,作者在 LIBERO 基准上进行了消融实验:
| 变体模型 | 平均成功率 | 关键发现 |
|---|---|---|
| 3D-CAVLA (完整) | 98.1% | 综合性能最优 |
| w/o CoT (无思维链) | 97.5% | 去除 CoT 后,长程任务(Long)性能下降明显 (96.1% -> 94.8%),证实 CoT 对长序列规划有益。 |
| w/o Depth (无深度) | 97.4% | 去除深度信息导致整体性能下降最大,证明 3D 特征对策略学习至关重要。 |
| + TA-ROI (仅ROI) | 97.2% | 在已知任务上强制使用 ROI 导致性能微跌。原因可能是 ROI 掩码滤除了某些必要的背景上下文(如抽屉把手被检测到但抽屉本体被过滤)。 |
5. 结论与未来展望 (Conclusion)
5.1 结论
3D-CAVLA 通过将问题从 2D 转换为 3D,并结合高级推理(CoT)和注意力引导(ROI),成功提升了 VLA 模型的几何感知和零样本泛化能力 。实验证明,深度信息和推理分解是弥补 VLA 泛化鸿沟的关键因素。
5.2 局限性
- ROI 的双刃剑效应:在已知任务中,过度依赖 ROI 可能会导致丢失必要的环境上下文信息,从而略微降低性能。
- 泛化瓶颈:尽管有提升,但在未见任务上的绝对成功率(45.2%)仍不理想,表明简单的微调和模态增加还不足以完全解决泛化问题。
3. Evo-0: Vision-Language-Action Model with Implicit Spatial Understanding
1. 核心摘要 (Executive Summary)
本研究针对现有视觉-语言-动作(VLA)模型在精确空间理解方面的局限性,提出了一种名为 Evo-0 的新型架构 。
- 核心痛点:现有的 VLA 模型主要基于 2D 图像-文本对进行预训练,缺乏 3D 监督,导致其难以捕捉物理世界交互所需的精确几何和空间关系 。
- 解决方案:Evo-0 不依赖额外的深度传感器或显式的深度估计模型,而是通过引入预训练的视觉几何基础模型(Visual Geometry Foundation Model, VGFM)——具体为 VGGT,来隐式地将 3D 几何先验注入到 VLA 模型中 。
2. 研究动机与背景 (Motivation)
2.1 现有 VLA 模型的局限性
目前的 VLA 模型(如 OpenVLA, π 0 \pi_0 π0)虽然在语义理解和泛化方面表现出色,但存在严重的空间理解瓶颈 。
- 数据缺失:VLM 的预训练目标主要是 2D 图像与文本对齐,且微调用的机器人数据集通常只包含 RGB 观测,缺乏 3D 信息。
- 泛化差:实证研究表明,仅依靠视觉输入的 VLM 在解释 3D 结构时泛化能力较差。
2.2 显式 3D 方法的弊端
为了解决上述问题,之前的方法尝试引入显式的 3D 输入(如点云或深度图)。但这带来了新的挑战:
- 硬件依赖:需要额外的深度传感器,限制了部署灵活性。
- 噪声干扰:如果使用深度估计模型,有缺陷的深度预测会引入噪声,影响可靠性。
2.3 Evo-0 的切入点
Evo-0 旨在弥合纯 2D 输入模型与显式 3D 感知模型之间的差距。它利用在大规模 2D-3D 配对数据上训练的空间编码器(VGGT),从 RGB 图像中提取几何特征,在不需要深度传感器的情况下增强 VLA 的空间理解能力。
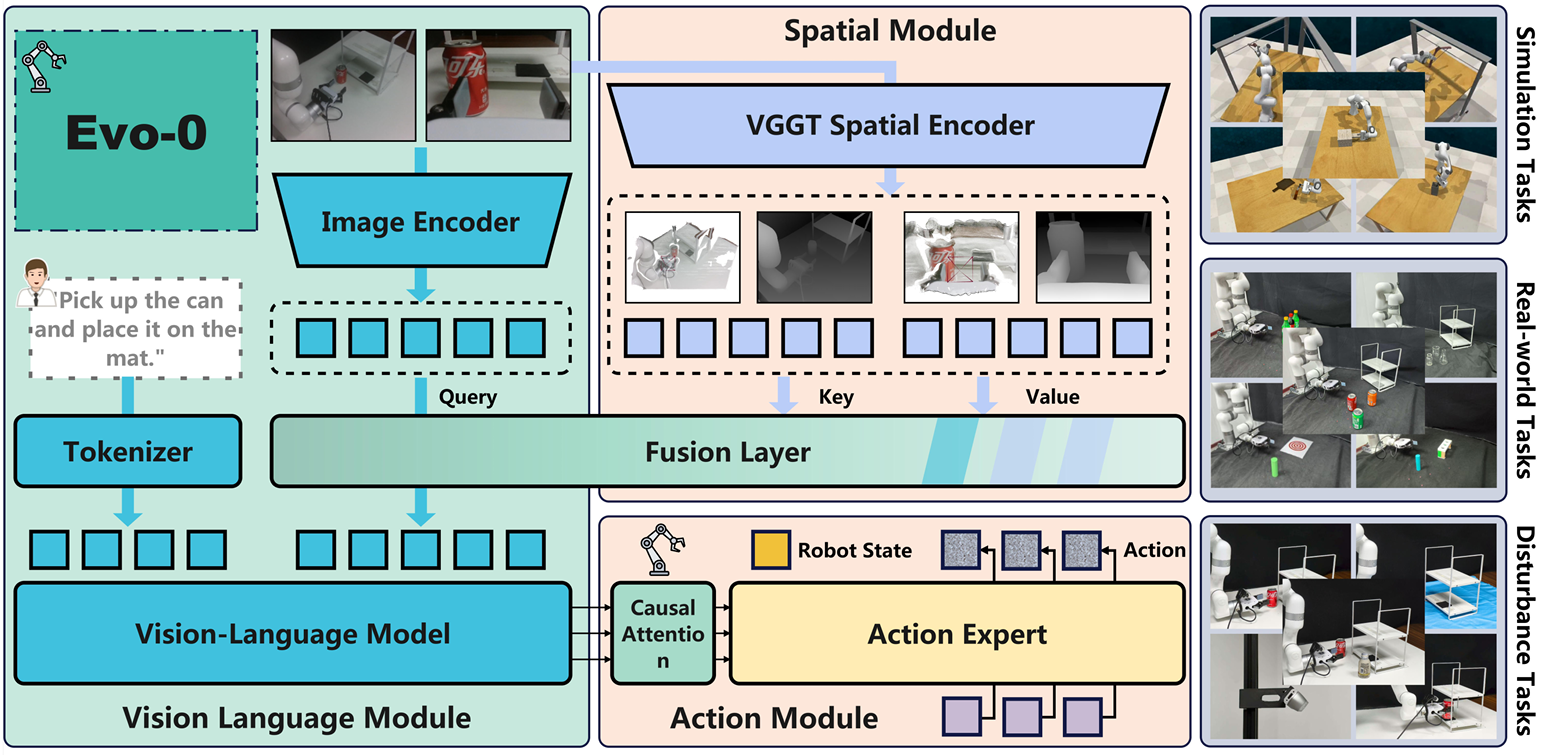
3. 技术方法 (Methodology)
Evo-0 的架构基于最先进的开源 VLA 模型 π 0 \pi_0 π0 构建,并集成了一个轻量级的融合模块。
3.1 核心组件
-
基座模型 ( π 0 \pi_0 π0):采用 PaliGemma 作为视觉语言主干,结合基于流匹配(Flow-Matching)的动作专家模块。
-
空间编码器 (VGGT):
- Evo-0 提取 VGGT 最后一层的 3D Token ( t 3 D t_{3D} t3D),这些 Token 包含深度感知上下文和跨视图的空间对应关系。
使用 Visual Geometry Grounded Transformer (VGGT) 作为空间编码器。
VGGT 是一个 VGFM,在大规模数据上训练用于从多视图 2D 输入重建 3D 结构。
3.2 融合机制 (Fusion Layer)
为了将 VGGT 的几何特征注入 VLA,作者设计了一个轻量级的融合器(Fuser):
- 交叉注意力 (Cross-Attention):融合器包含一个单层交叉注意力层。
- Query ( Q Q Q):来自 VLM 视觉编码器的 2D 视觉 Token ( t 2 D t_{2D} t2D)。
- Key ( K K K) & Value ( V V V):来自 VGGT 的 3D Token ( t 3 D t_{3D} t3D)。
- 计算过程:
Q = t 2 D W Q , K = t 3 D W K , V = t 3 D W V Q = t_{2D}W_Q, \quad K = t_{3D}W_K, \quad V = t_{3D}W_V Q=t2DWQ,K=t3DWK,V=t3DWV
t i = softmax ( Q i ( K i ) ⊤ d ) V t^i = \text{softmax}\left(\frac{Q^i(K^i)^\top}{\sqrt{d}}\right)V ti=softmax(dQi(Ki)⊤)V
通过这种方式,模型利用 2D 语义特征去查询相关的 3D 几何特征,生成空间增强的视觉表示。
3.3 训练策略
- 冻结参数:为了保持计算效率并保留 VLM 的预训练知识,冻结 VLM 的核心参数。
- 微调参数:仅微调融合器模块、LoRA 层以及动作专家(Action Expert)。
4. 总结与评价
4.1 核心贡献
- 提出了 Evo-0,一种即插即用(plug-and-play)的模块化方法,通过隐式注入 3D 几何先验增强 VLA。
- 证明了利用在大规模 2D-3D 数据上预训练的 VGGT 可以替代昂贵的深度传感器或不稳定的深度估计模型。
- 在仿真和真机实验中验证了该方法在精细操作任务上的显著优势。
4.2 潜在限制
- 推理延迟:引入 VGGT 增加了计算开销,导致推理 FPS 降低约 40%。
- 依赖性:模型的空间理解能力上限受限于 VGGT(或其他 VGFM)的重建质量。
4.3 结论
Evo-0 成功展示了通过隐式几何表示增强 VLA 空间理解的可行性和有效性。它在保持 RGB 输入便捷性的同时,显著提升了机器人在复杂、精细任务中的操作能力和鲁棒性,为通用机器人的发展提供了一种高效的新思路。
4. SpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation 【Disentangled 解耦】
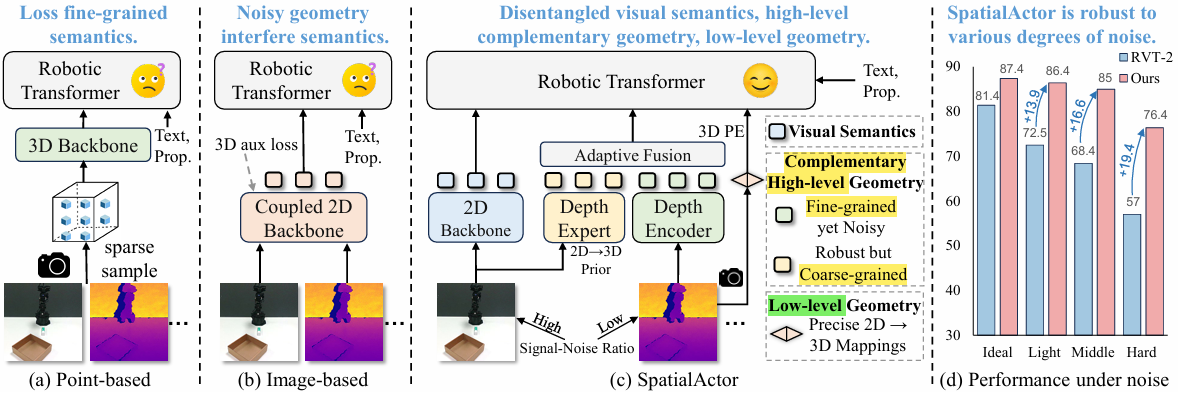
1. 核心问题陈述 (Problem Statement)
现有的机器人操作主流方法主要分为两类,均存在明显缺陷:
- 基于点云的方法 (Point-based):如 PerAct 等,显式表征 3D 几何,但受限于稀疏采样(Sparse Sampling),导致细粒度语义丢失。
- 基于图像的方法 (Image-based):如 RVT,将 RGB 和 Depth 输入 2D Backbone。这种方式将语义和几何信息在特征空间中纠缠在一起,导致模型对 深度噪声(Depth Noise) 极度敏感。现实世界中微小的深度噪声可能导致严重的性能下降 。
此外,现有方法往往关注高层几何结构,忽略了对精确交互至关重要的低层空间线索(Low-level spatial cues) 。
2. 方法论 (Methodology)
SpatialActor 的核心思想是 “解耦” (Disentanglement):
- 模态解耦:将语义(Semantics)与几何(Geometry)分离处理,避免跨模态干扰 。
- 几何分解:将几何信息进一步分解为“高层几何表征”和“低层空间线索”。
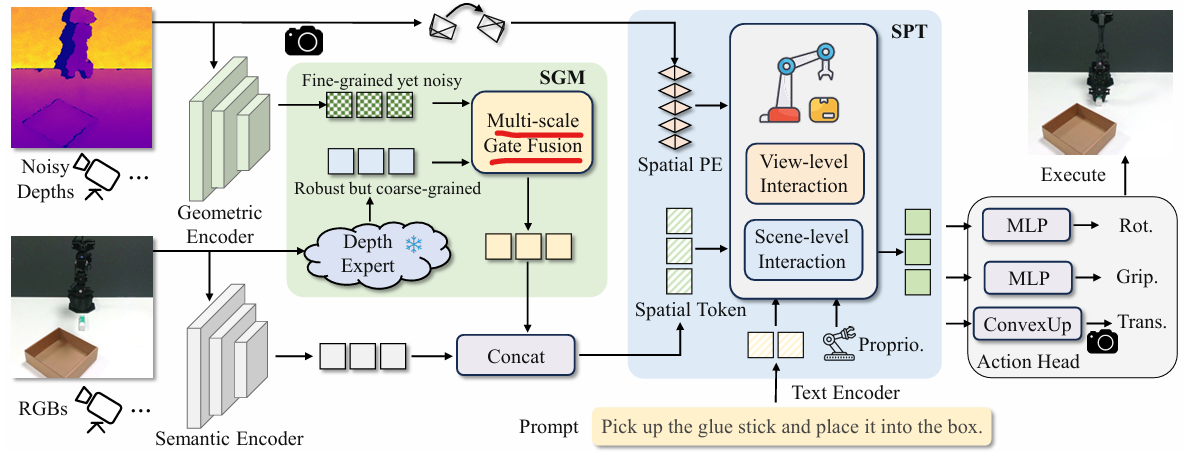
2.1 整体架构
模型的输入定义为 X = { I v , D v } v = 1 V , P , L X=\{I^{v},D^{v}\}_{v=1}^{V},P,L X={Iv,Dv}v=1V,P,L,包含多视角 RGB 图像 I I I、深度图 D D D、本体感知 P P P 和语言指令 L L L 。
- 语义流:使用 CLIP 提取 I v I^v Iv 和 L L L 的语义特征 F s e m v F_{sem}^v Fsemv 和文本特征 F t e x t F_{text} Ftext。
- 几何流:通过下述的 SGM 模块处理深度信息。
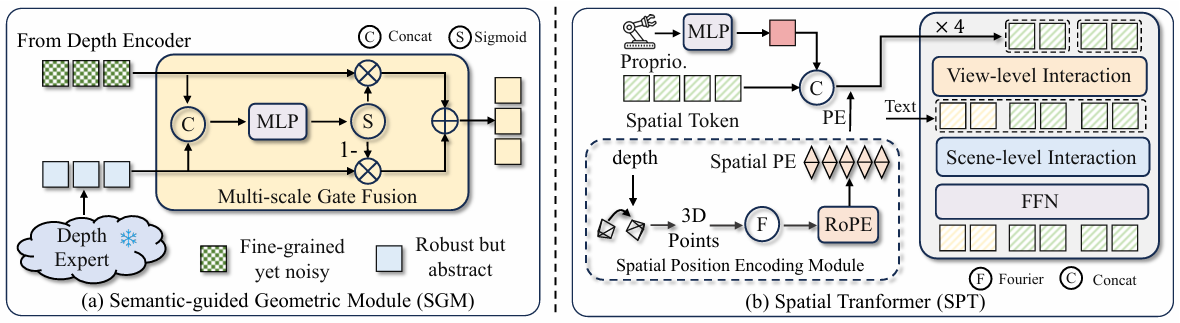
2.2 语义引导的几何模块 (Semantic-guided Geometric Module, SGM)
该模块旨在解决原始深度图噪声大与预训练深度模型细节不足的矛盾。它融合了两种互补的几何来源 :
- Fine-grained yet Noisy: 原始深度图 D v D^v Dv 通过一个深度编码器(ResNet-50)提取特征 F g e o v F_{geo}^v Fgeov。保留了细节但含有噪声 。
- Robust but Coarse: 使用冻结的大规模预训练深度估计专家(Depth Anything v2)从 RGB 图像推断几何先验 F ^ g e o v \hat{F}_{geo}^v F^geov。具有高鲁棒性但较为粗糙 。
自适应融合机制 (Adaptive Gating Fusion):
通过一个门控机制(Gating Mechanism)自适应地融合上述两个特征,公式如下:
G v = σ ( M L P ( C o n c a t ( F ^ g e o v , F g e o v ) ) ) G^{v}=\sigma(MLP(Concat(\hat{F}_{geo}^{v},F_{geo}^{v}))) Gv=σ(MLP(Concat(F^geov,Fgeov)))
F f u s e _ g e o v = G v ⊙ F g e o v + ( 1 − G v ) ⊙ F ^ g e o v F_{fuse\_geo}^{v}=G^{v}\odot F_{geo}^{v}+(1-G^{v})\odot\hat{F}_{geo}^{v} Ffuse_geov=Gv⊙Fgeov+(1−Gv)⊙F^geov
其中 σ \sigma σ 为 Sigmoid 激活函数, ⊙ \odot ⊙ 为逐元素乘法。门控 G v G^v Gv 学习在保留可靠细节的同时抑制噪声 。
2.3 空间 Transformer (Spatial Transformer, SPT)
为了捕获低层空间线索,SPT 将 3D 空间信息直接编码进 Transformer 的 Token 中。
- 3D 坐标映射:利用相机内外参 ( K v , E v ) (K^v, E^v) (Kv,Ev) 将像素坐标 ( x ′ , y ′ ) (x', y') (x′,y′) 和深度 d d d 投影为机器人坐标系下的 3D 点 [ x , y , z ] [x, y, z] [x,y,z]。
- 3D 旋转位置编码 (3D Rotary Positional Encoding, RoPE):
不同于常见的 1D/2D 编码,SpatialActor 对 x , y , z x, y, z x,y,z 轴分别应用 RoPE。频率设定为 ω k = λ − 2 k / d \omega_{k}=\lambda^{-2k/d} ωk=λ−2k/d,其中 λ = 10000 \lambda=10000 λ=10000 。
特征变换公式为:
T = H ⊙ c o s p o s + r o t ( H ) ⊙ s i n p o s T = H \odot cos_{pos} + rot(H) \odot sin_{pos} T=H⊙cospos+rot(H)⊙sinpos
这种编码方式赋予了 Token 明确的 3D 空间索引,促进了空间交互。 - 层次化交互 (Hierarchical Interaction):
- View-level: 处理单视图内部的空间关系。
- Scene-level: 聚合跨视图和语言指令的信息。
2.4 动作头 (Action Head)
使用轻量级的解码器 (ConvexUp) 生成 2D 热力图以预测平移 (Translation),并通过 MLP 回归旋转 (Rotation, discretized Euler angles) 和夹爪状态 。
3. 总结与分析
SpatialActor 的成功主要归功于其对表征解耦的深入设计。它没有简单地将 RGB-D 视为一个整体,而是认识到:
- RGB 提供高信噪比的语义。
- Raw Depth 提供精细几何但含噪。
- Pre-trained Depth Expert 提供鲁棒几何但粗糙。
通过 SGM 动态融合后两者,并利用 SPT 中的 3D RoPE 显式编码空间关系,该模型在保持高精度的同时,显著提升了对现实世界噪声的抵抗力。这对于从仿真(Sim)到真机(Real)的迁移具有重要意义。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)