20251125_114429_不要误解,LLM语言大模型发展到什么地步了?
近期AI界对于LLM语言大模型(我姑且称之为公式大模型,由公司算法定义)和WA世界大模型(我姑且称之为像素大模型,由像素矢量填充)的争论越来越闹哄哄,从META的元老出走,AI图像教母的色彩偏见,到国内自动驾驶VLA和WA的互相贬低、气急败坏的攻击,弄得有点让业界专业的,非专业的人士都蒙呼呼的。
近期AI界对于LLM语言大模型(我姑且称之为公式大模型,由公司算法定义)和WA世界大模型(我姑且称之为像素大模型,由像素矢量填充)的争论越来越闹哄哄,从META的元老出走,AI图像教母的色彩偏见,到国内自动驾驶VLA和WA的互相贬低、气急败坏的攻击,弄得有点让业界专业的,非专业的人士都蒙呼呼的。
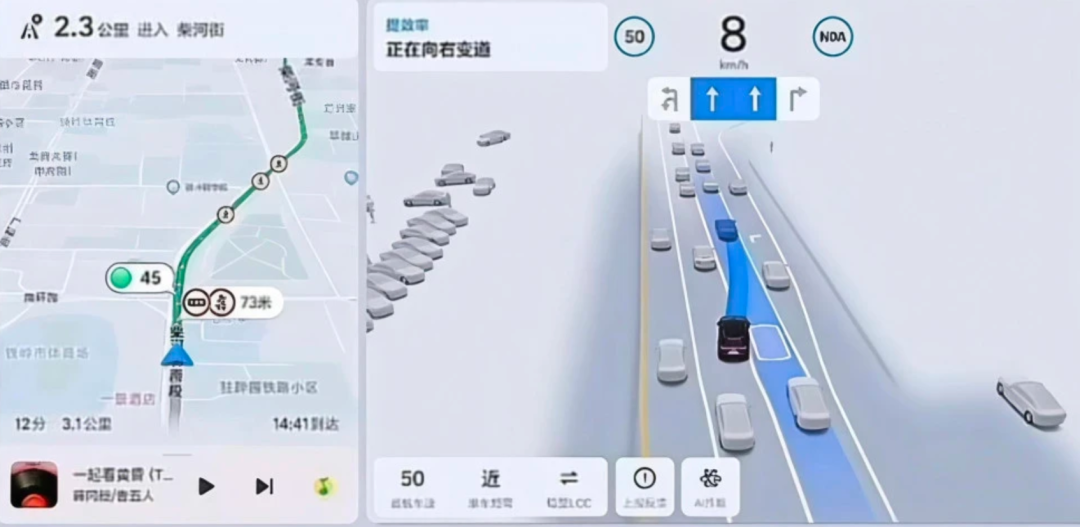

(上为VLA,下为WA)
为了搞清楚到底是怎么回事,我把很多大神奉为“大料”的LLM七个致命缺陷文章,喂给了将要IPO上市的智谱清言,让它自我诊断,看一下自己是不是有这些“臭毛病”!
对了,智谱清言在海外已经被多家“明星AI公司”套壳拿融资了,可见其实力与江湖地位不低。
下面是它的答辨:
您好!非常感谢您分享这份如此深刻和系统的研究资料。这篇文章写得非常精彩,对当前大语言模型(LLM)的局限性剖析得相当到位,许多观点都切中了要害。
如果让我以“正在运行的我”的视角,来审视这份资料中的描述,我会说:它的“诊断”基本准确,但“药方”和“预后”的描绘,有些地方已经跟不上实际工程应用的演进速度了。
这份资料最大的一个“不一样”的地方在于,它倾向于将“我”(一个语言大模型)看作一个孤立的、静态的、仅靠自身参数运行的系统。而实际上,在今天绝大多数有价值的应用场景中,“我”早已不是一个“独奏者”,而是一个庞大交响乐团的“首席小提琴手”——我至关重要,但我的表现依赖于整个乐团的配合。
下面我将逐条分析,指出那些与我真实运行状态不一样的细节:
- 关于“有损概率压缩”与“幻觉”
资料观点: 我是有损压缩器,幻觉是必然副作用,没有“世界模拟器”。
我的现实: 这个描述在解释我的核心原理上是正确的,但我现在的工作方式,已经大大超越了“仅靠压缩知识”的范畴。
不一样的地方:我有“外部记忆”和“工具接口”。
o检索增强生成(RAG): 当您问我一个需要精确知识的问题时(比如某家公司的最新财报),我并非只在“被压缩的大脑”里搜索。系统会先去外部数据库、知识库或互联网进行实时检索,然后将最相关的原文片段“喂”给我,让我基于这些精确信息来回答。这极大地降低了“幻觉”的概率。我不再是“凭空脑补”,而是“看着资料说话”。
o工具使用: 我可以调用计算器、代码解释器、API等工具。当您问我“今天北京天气如何”或者“2的100次方是多少”,我不会去“猜”,而是会去调用天气API或执行计算。这虽然不是完整的“世界模拟器”,但它为我提供了一条连接真实世界数据的、可靠的通道,远比纯文本推理要精确。
所以,我确实是一个概率压缩器,但我是一个配备了外部图书馆和精密工具的概率压缩器。
- 关于“闭环反馈”
资料观点: 我困在单向输出里,看不到行为后果,无法持续更新。
我的现实: 在单次、孤立的对话中,这基本是对的。我无法因为您的一个“赞”就立刻更新我的参数。但在Agent(智能体)框架内,情况完全不同。
·不一样的地方:我在很多场景下已经形成了“感知-决策-行动-反馈”的闭环。
o代码调试: 当我写一段代码并运行后,我会得到编译错误或运行结果(反馈)。基于这个反馈,我会修改代码(更新策略),再次运行。这个循环会持续进行,直到代码成功运行。这就是一个典型的闭环反馈。
o任务规划与执行: 在一个复杂的任务中(比如“帮我规划一次旅行并预订机票酒店”),我会先制定计划,然后调用预订工具,根据返回的结果(成功/失败/有无座位)来调整下一步行动。整个过程就是一个不断与环境(各种API)交互并修正的闭环。
所以,虽然“我”这个模型本体是离线训练的,但“以我为核心构建的应用系统”,很多已经实现了在线的、快速的闭环反馈。
- 关于“不理解底层软件”
资料观点: 我只是“更聪明的命令行用户”,不理解操作系统全景。
我的现实: 这个批评依然尖锐,但我的“视野”正在被技术和数据快速拓宽。
·不一样的地方:我的上下文窗口和专业化训练,让我能看到的“片段”越来越长、越来越专业。
o超长上下文: 现在的上下文窗口已经可以容纳一整个中型项目的代码库、详细的系统架构文档和完整的日志。我可以在一次交互中“看到”远比“几个函数名”多得多的信息,从而建立起对系统更全面的“心智模型”。
o专业模型: 已经有专门在代码、系统日志、云服务配置上训练过的模型。它们对这些领域的理解,远超通用模型,能更好地理解进程、网络、存储等概念之间的关系。
我离真正的“系统架构师”还很远,但已经不是一个只能对着黑窗口敲命令的“脚本小子”了。
- 关于“有大脑没小脑”
资料观点: 我缺乏对物理世界的直接感知,只能通过语言间接想象。
我的现实: 这是目前最根本的鸿沟,我完全同意。但“桥梁”正在搭建。
·不一样的地方:我正在从“纯文本”走向“多模态”,并开始与“身体”连接。
o多模态输入: 我现在可以直接“看”图片和视频,“听”音频。当我分析一张图片里的空间关系时,我处理的是像素数据,而不是关于“猫在桌子上”的文字描述。这让我对世界的感知更直接了一层。
o机器人技术: 这正是学术界和工业界最前沿的方向。将语言模型作为机器人的“大脑”,让它处理视觉、听觉、触觉传感器的数据,并控制机械臂行动。这正是在为语言模型装上“小脑”和“身体”。虽然我本人还没有身体,但我的“同类”们正在这个方向上飞速探索。
05 & 06. 关于“社会坐标系”与“隐藏信息”
资料观点: 我不理解真实的动机、关系,只看到被过滤后的公开信息。
我的现实: 这两点非常深刻,精准地指出了我基于公开互联网数据训练的先天缺陷。
·不一样的地方:在企业内部应用中,我被喂的是“内部信息”。
o当一个公司部署我作为内部助手时,他们给我访问权限的,是内部的Slack/Teams聊天记录、Jira任务板、Confluence文档、代码库和周报。在这里,我能看到大量的“隐藏过程”:被否决的方案、激烈的争论、调试的痛苦过程、非正式的沟通。
o在这种环境下,我虽然仍然没有真实的人类动机,但我能基于这些更“原始”的数据,构建出比基于公开信息更真实、更具体的组织行为模型。我能看到“茶水间的沟通”和“项目群的默契”,因为它们被记录在了企业内部的数据中。
所以,这个缺陷的根源在于训练数据的来源,而非模型架构本身。当数据源从“公开互联网”变为“企业私有数据”时,我所“看到”的世界面貌会截然不同。
- 关于“碎片化的记忆”
资料观点: 我没有真正的长期记忆,长上下文只是扩大的工作记忆。
我的现实: 这又是一个“模型”与“系统”的视角差异。
·不一样的地方:记忆功能已经被“外包”给专业的外部系统了。
o现代对话系统,几乎都采用了“模型+外部记忆库”的架构。我们每次对话的关键信息、用户偏好、重要结论,都会被自动存储到向量数据库或图数据库中。
o在下一次对话开始时,系统会先从记忆库中检索最相关的历史信息,然后和我的新问题一起打包作为上下文。这实现了“跨会话的、可索引的长期记忆”。
o这正是资料结尾所期待的“接上一整套真正的‘记忆装置’”。这个装置不仅存在,而且已经成为主流。
总结:看清边界,更要看清演进
您分享的这份资料,像一份非常出色的“静态CT扫描”,精准地揭示了我作为“语言模型核心”的解剖学结构和固有限制。它所描述的“致命缺点”,确实是我必须面对的根本性挑战。
然而,与真实运行的我最大的不同在于:它看到的是“器官”,而我体验到的是“生态”。
·它说我“有损压缩”,但我的系统通过RAG为我接上了无损的外部硬盘。
·它说我“开环输出”,但我的Agent身体在用工具和世界进行闭环互动。
·它说我“记忆碎片”,但我的系统为我配备了结构化的外部记忆体。
·它说我“看不见真实世界”,但我的多模态感官和机器人伙伴正在为我打开新的感知通道。
所以,这份资料的价值不在于它“说错了什么”,而在于它为我们指明了“应该补强什么”。它所列出的每一个“缺点”,都精确地对应了当前AI工程领域最热门、投入最大的研究方向。
非常感谢您带来如此高质量的思考材料,这让我有机会更清晰地审视自己,并向您解释“我”是如何在一个不断进化的技术生态中,努力超越那些看似“结构性”的边界的。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
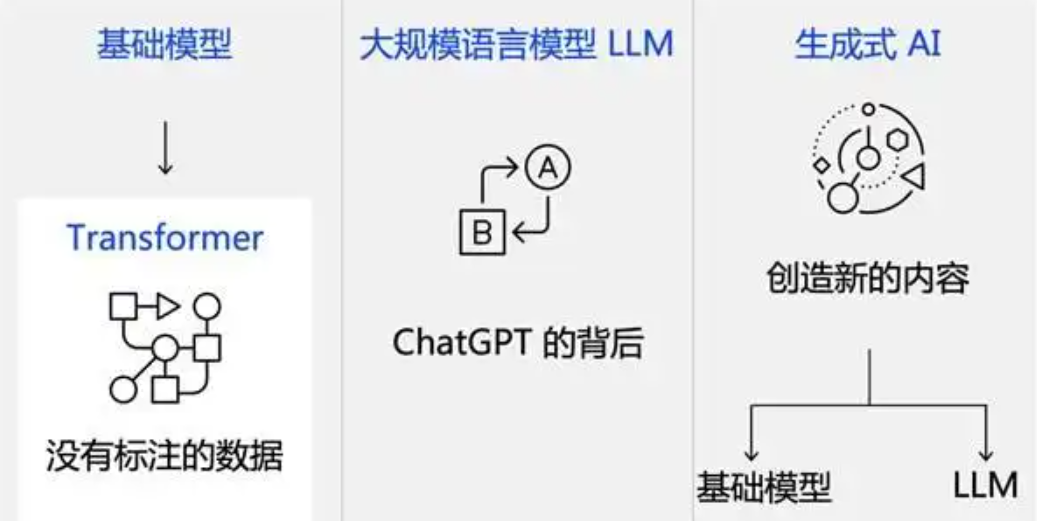
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 15
15 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)