Python数据分析常用库Pandas(一)
要准备的数据文件olympics.csv链接:https://pan.baidu.com/s/1Iygq4Ssf_hf_U3jpBLXKvw提取码:b0ye复制这段内容后打开百度网盘手机App,操作更方便哦Summer Olympic medallists 1896 to 2008 - IOC COUNTRY CODES.csv链接:https://pan.baidu.c...
要准备的数据文件
-
olympics.csv
链接:https://pan.baidu.com/s/1Iygq4Ssf_hf_U3jpBLXKvw
提取码:b0ye
复制这段内容后打开百度网盘手机App,操作更方便哦 -
Summer Olympic medallists 1896 to 2008 - IOC COUNTRY CODES.csv
链接:https://pan.baidu.com/s/1VgHtkWWpSf7TkQsxtfGqNw
提取码:5d1n
复制这段内容后打开百度网盘手机App,操作更方便哦
一.DataFrames和Series
import pandas as pd
# 读取准备的数据文件
# read_csv接收两个参数:'data/olympics.csv':要读取的文件路径、skiprows:读取跳过文件的行数
oo = pd.read_csv('data/olympics.csv',skiprows=4)
1.DataFrames
- 全部读进来的数据(太多截不全)
- 选取大于一个列的数据(太多截不全)
2.Series
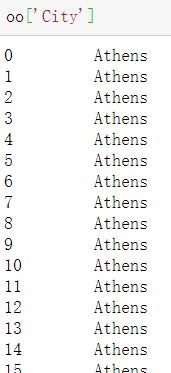
- 一列数据(太多截不全)
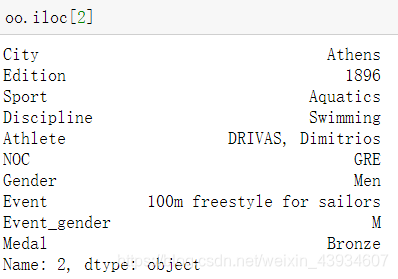
- 一行数据
- 小结:
- 多组数据是DataFrame类型
- 只有一行或一列数据是Series类型
二.数据输入与验证
1.pandas输入属性
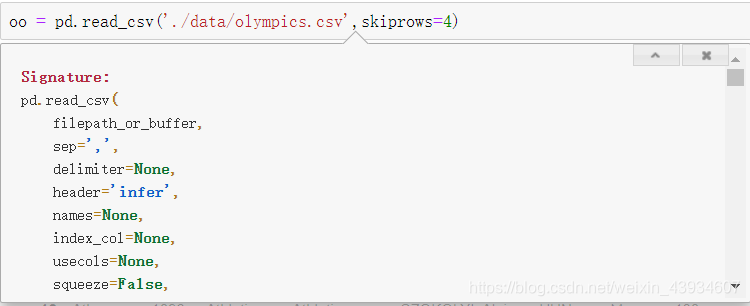
# 一般只设置路径 如果读入数据开头不是表的开始 就要用skiprows跳过开头几行
pd.read_csv('./data/olympics.csv',skiprows=4)
- 如果要查看.read_csv()的详细属性 可以用在参数的括号里用 “Shift+Tab” 查看
2.Shape属性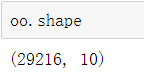
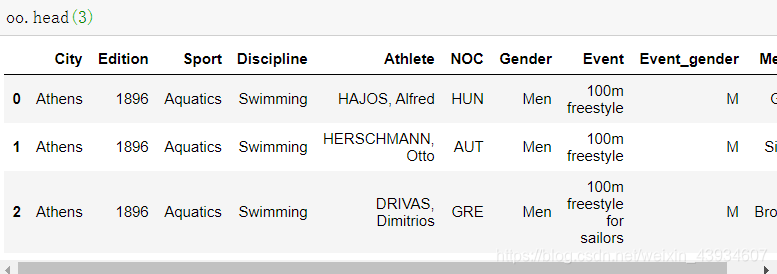
3.head和tail
- head(n):读取开头的前n个数据 默认5个
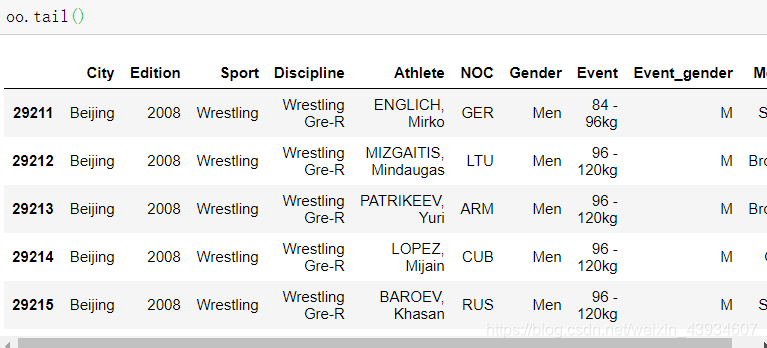
- tail(n):读取结尾的后n个数据 默认5个
4.info方法
- 输出pands读取数据的每个字段的属性
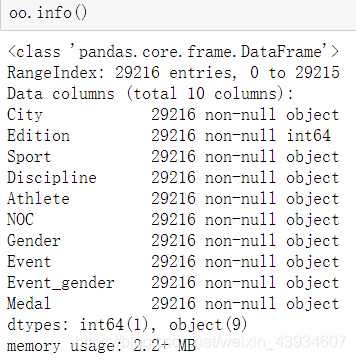
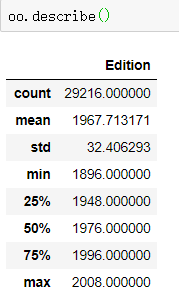
5.describe方法
- 读取出数字属性(int64、float64…)的统计特性
三.基本数据分析
1.数据频率统计-value_counts方法
- 不指定其他参数
# 计算Edition(比赛年份)每个不同值得出现频率 默认降序排序 # oo.Edition 和 oo['Edition']等价 # 之后还以连续调用,比如 oo.Edition.value_counts().head(3) oo.Edition.value_counts()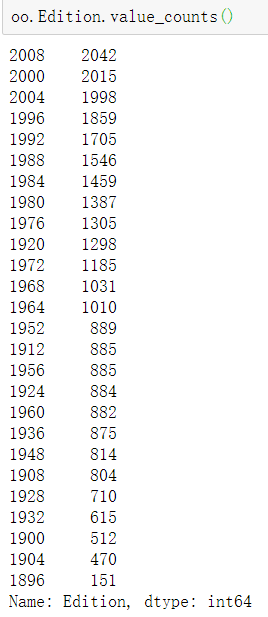
- 指定部分参数
# ascending:是否升序排序(默认False)、dropna:是否忽略为空的参数 oo.Gender.value_counts(ascending=True,dropna=False)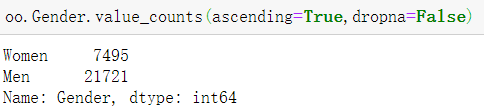
2.数据排序-sort_values方法
- 根据一个属性排序
# 根据运动员名字排序 默认升序 # 也等价于 oo.sort_values(by='Athlete') oo.Athlete.sort_values()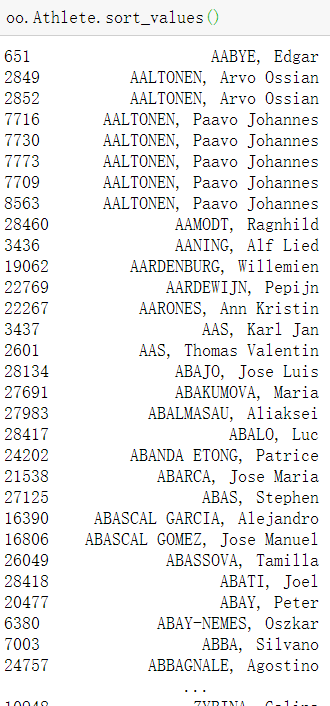
- 指定多个属性
#先根据Edition(比赛年份)排序 如果相同再根据Athlete(运动员名字)排序 oo.sort_values(by=['Edition','Athlete'])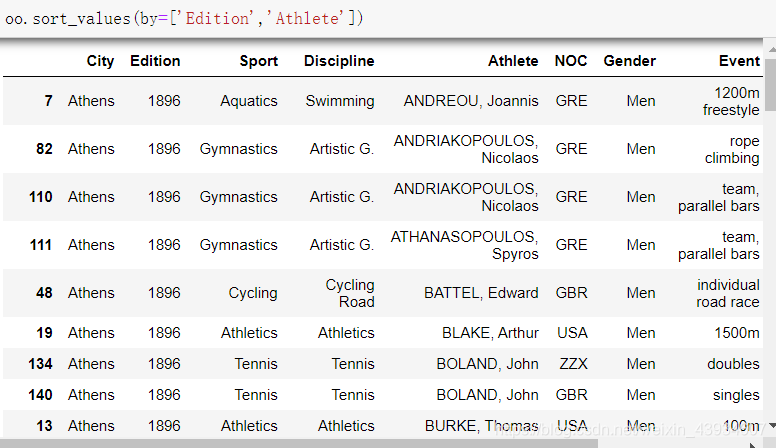
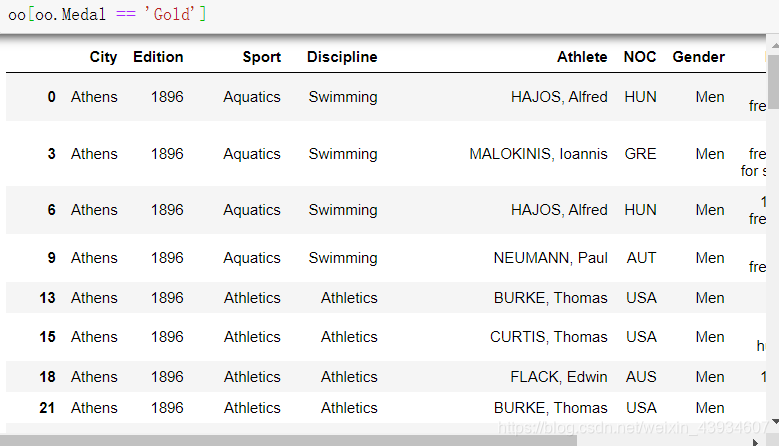
3.布尔值索引快速筛选数据
# 获得oo中 Medal(比赛获得的奖牌)是Gold(金牌)的数据
# 也可以有多个条件用'&'、'|' 拼接, 如:oo[ ( ) & ( ) | ( ) ]
oo[oo.Medal == 'Gold']

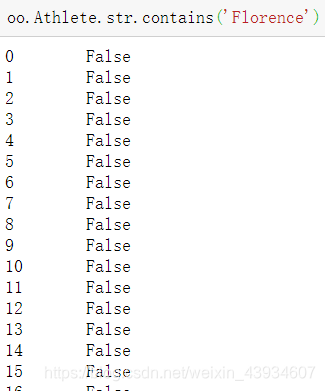
4.字符串处理–模糊查询
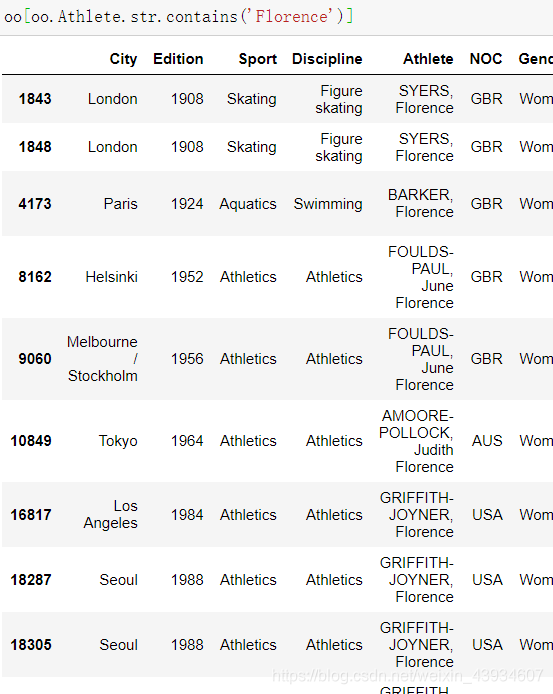
# 获得oo中 Athlete(运动员名字)包含"Florence" 的数据
oo[oo.Athlete.str.contains('Florence')]
5.筛选要的属性
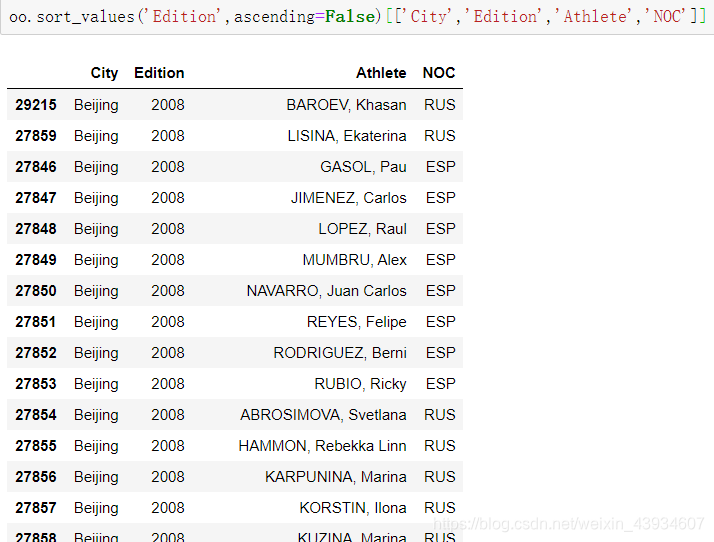
# 根据Edition(年份)取得频率的降序排序之后 只保留指定的属性
oo.sort_values('Edition',ascending=False)[['City','Edition','Athlete','NOC']]
四.数据索引
1.索引概述
- 默认索引:每一行数据前面的数字

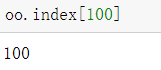
- 通过元素个数获取索引的值
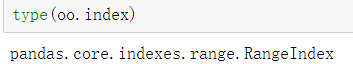
- 索引类型
2.数据索引的设置方式
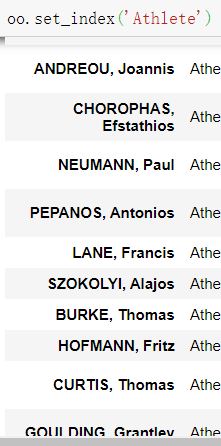
#用set_index 此时返回一个Athlete索引的pandas 但并没有修改自身
oo.set_index('Athlete')
#要是想改变自身的索引而不是返回一个改变之后的新的数据 那么设置属性inplace=True
oo.set_index('Athlete',inplace=True)

3.索引复位
#必须设置inplace=True 不然返回一个复位过的 自身并没改变
oo.reset_index(inplace=True)

4.按索引排序数据
#给oo设置索引后但没设置inplace 所以返回一个新的对象
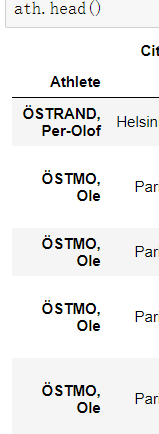
ath = oo.set_index('Athlete')
#用索引 给每条数据排序 同样要设置inplace覆盖自身
# Athlete是运动员名字 英文单词按首字母排序 其他字符排最后
ath.sort_index(inplace=True)

#指定排序方式 默认升序 所以英文字母倒叙排序的话 最后面单词的首字母会是其他字符
ath.sort_index(inplace=True,ascending=False)
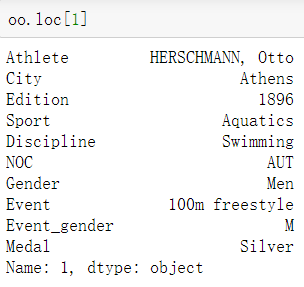
5.loc数据行索引
- 通过索引取一条数据
- 通过索引取多条数据
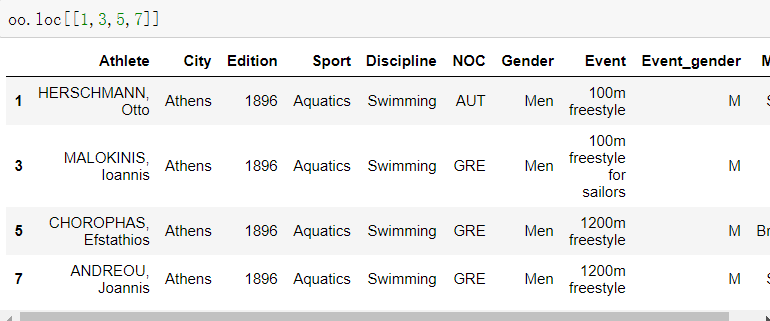
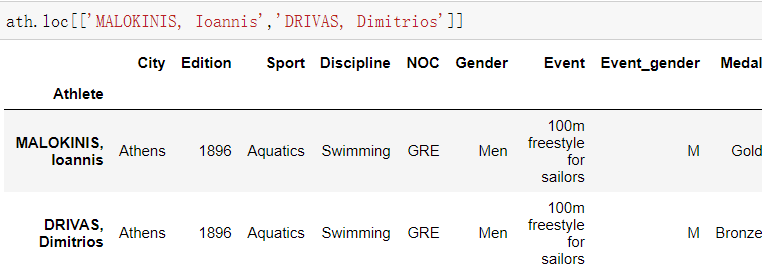
- 如果索引不是默认索引 取法相同
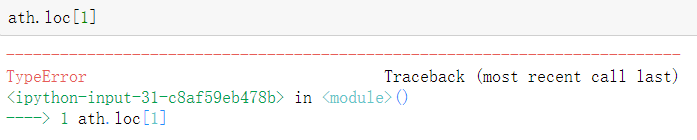
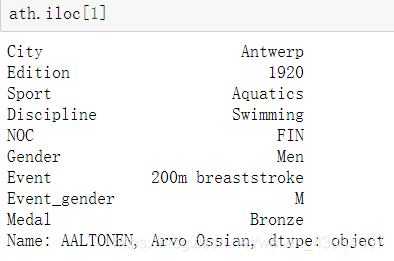
6.iloc索引
- 这个根据索引取值是取指定条数的数据 并不是上面那个的索引 无法修改
- 和loc的区别
- 取多条数据(前闭后开)
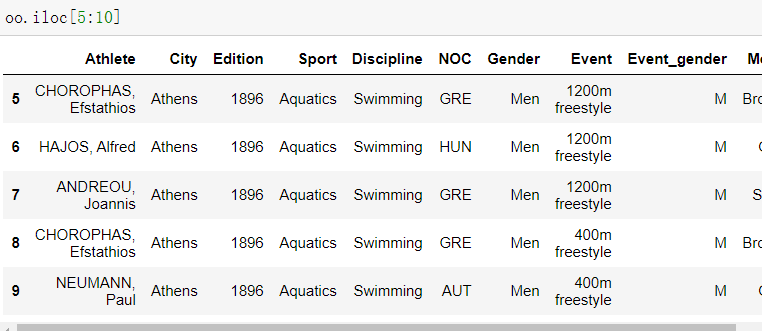
补充:
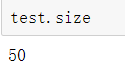
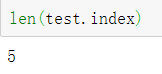
如果要求数据的条数可以通过索引的个数来求 不可以用pandas的对象.size 来求
#test应该是5条 数据就是上面的数据
test=oo.iloc[5:10]

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)