【MySQL】数据库基本知识
本文摘要:文章系统介绍了数据库知识体系,首先阐述了文件存储的局限性及数据库的必要性。主体内容分为三部分:一是主流数据库分类,包括关系型(MySQL、Oracle等)和非关系型(MongoDB、Redis等)的特点与适用场景;二是MySQL基础操作,涵盖连接服务、库表关系及CRUD操作;三是MySQL技术细节,包括架构、SQL分类(DDL/DML/DCL)及存储引擎特性对比。重点分析了InnoDB等
目录
一、 为什么要有数据库?
为什么不用文件存储数据算了,还弄个数据库呢?
文件保存数据有以下缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
针对上述问题,数据库诞生了,它能更有效的进行数据管理,数据库的知识水平也成了程序员的重要素质之一。
二、常见主流数据库
1.关系型数据库(SQL)
关系型数据库基于表格模型,支持 SQL 查询,适合结构化数据存储,强调数据一致性。
- MySQL:开源免费的轻量型关系型数据库,兼容性强、部署维护简单。核心用于中小型应用、互联网项目,是 Web 开发的首选数据库之一。
- PostgreSQL:功能全面的开源关系型数据库,支持复杂查询、JSON 数据类型和自定义扩展。稳定性和扩展性突出,适合企业级应用、数据仓库和科研场景。
- Oracle:商业闭源的企业级关系型数据库,性能强劲、安全性高,支持大规模数据处理和高并发。常用于金融、政府、电信等核心业务系统,收费较高。
- SQL Server:微软推出的商业关系型数据库,易用性强、与 Windows 生态深度兼容。适合.NET 技术栈的企业应用,在中小型企业中应用广泛。
2.非关系型数据库(NoSQL)
非关系型数据库不依赖表格模型,灵活易扩展,适合非结构化 / 半结构化数据,侧重高并发和海量数据存储。
- MongoDB:文档型 NoSQL 数据库,以 JSON 格式存储数据,无需预设 schema。灵活度高、扩展便捷,适合电商商品管理、内容平台、物联网等场景。
- Redis:内存型 NoSQL 数据库,读写速度极快,支持字符串、哈希、列表等多种数据结构。核心用作缓存、会话存储、消息队列,提升应用响应速度。
- Cassandra:分布式列存储 NoSQL 数据库,高可用、高扩展,支持跨区域部署。适合海量数据存储(如日志、用户行为数据),能应对高并发写入场景。
- Elasticsearch:搜索引擎型 NoSQL 数据库,基于 Lucene 构建,擅长全文检索和数据分析。常用于日志分析、商品搜索、舆情监控等需要快速查询的场景。
三、MySQL基础
MySQL是以,以下皆为Linux系统下的MySQL相关操作,安装方式网上已有很多教程,这里不再赘述。
1.连接服务器
mysql -h 127.0.0.1 -P 3306 -u root -p相关选项含义:
- mysql:MySQL 数据库的客户端程序,用于启动与 MySQL 服务器的交互终端(执行 SQL 语句、管理数据库等)。
- -h 127.0.0.1:-h 是 --host 的缩写,用于指定要连接的 MySQL 服务器的主机地址或 IP。这里 127.0.0.1 是本地回环地址,表示连接本机的 MySQL 服务器(也可用 localhost 代替)。
- -P 3306:-P 是 --port 的缩写(注意是大写 P,小写 p 是密码相关参数),用于指定 MySQL 服务器的端口号。这里 3306 是 MySQL 的默认端口(若服务器未修改默认端口,此参数可省略)。
- -u root:-u 是 --user 的缩写,用于指定登录 MySQL 服务器的用户名。这里 root 是 MySQL 的超级管理员用户(拥有最高权限)。
- -p:-p 是 --password 的缩写,用于指定登录密码。这里单独使用 -p 时,执行命令后会提示用户输入密码(输入时密码不显示,更安全);若写成 -p123456 则直接在命令中携带密码(不推荐,易泄露)。
成功安装MySQL并启动服务后,可以用上面的命令连接MySQL服务。
2. 服务器,数据库,表关系
- 所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多
- 个数据库,一般开发人员会针对每一个应用创建一个数据库。
- 为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
数据库服务器、数据库和表的关系如下:
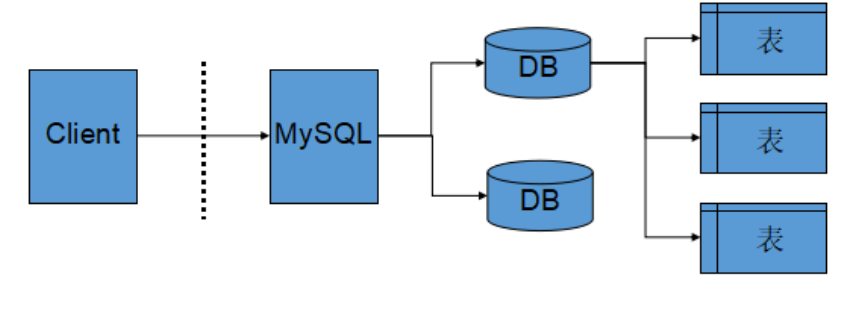
注:DB即database(数据库)
可以看到MySQL服务器中维护着各种数据库,数据库中维护着各种表,而客户端访问服务器对数据进行操作。
3. 基本使用
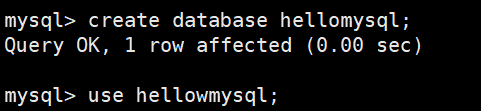
- 创建数据库
create database hellomysql;- 使用数据库
use hellomysql;- 创建数据库表
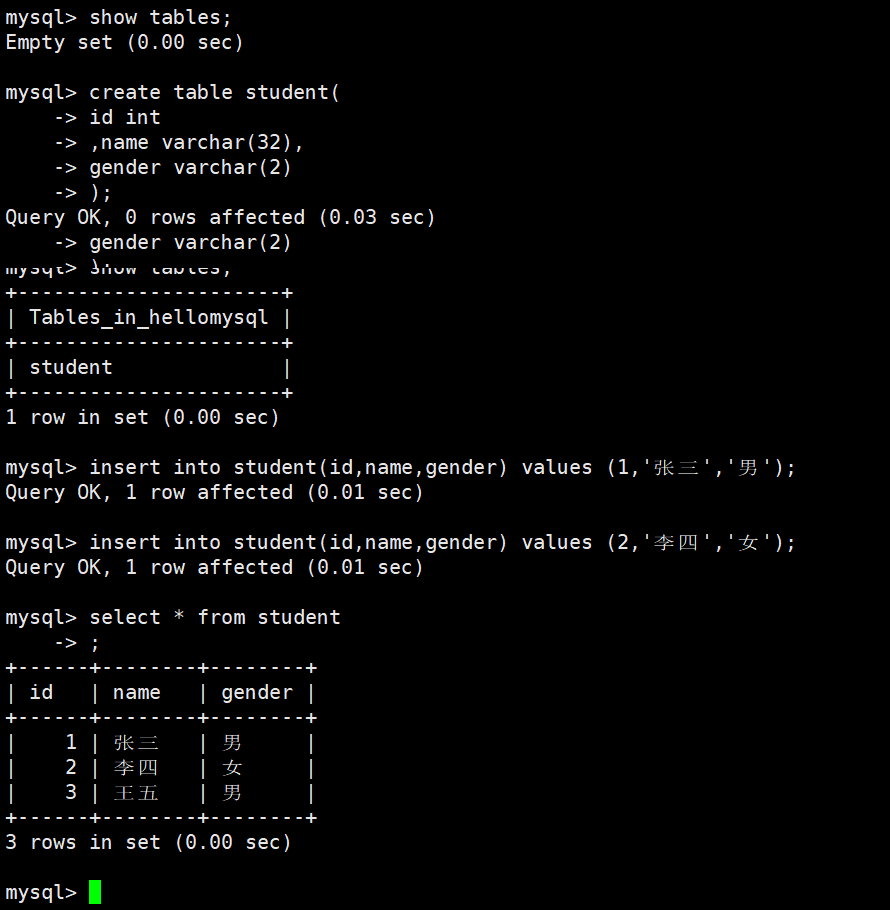
create table student(
id int,
name varchar(32),
gender varchar(2)
);- 表中插入数据
insert into student (id, name, gender) values (1, '张三', '男');
insert into student (id, name, gender) values (2, '李四', '女');
insert into student (id, name, gender) values (3, '王五', '男');- 查询表中的数据
select * from student;4. 操作示例
如果使用非root用户创建database失败,可以登录root用户后使用以下命令为用户赋予权限:
GRANT CREATE ON *.* TO 'username'@'host';也可以暂时使用root用户进行学习,后续我会讲解用户管理相关内容。
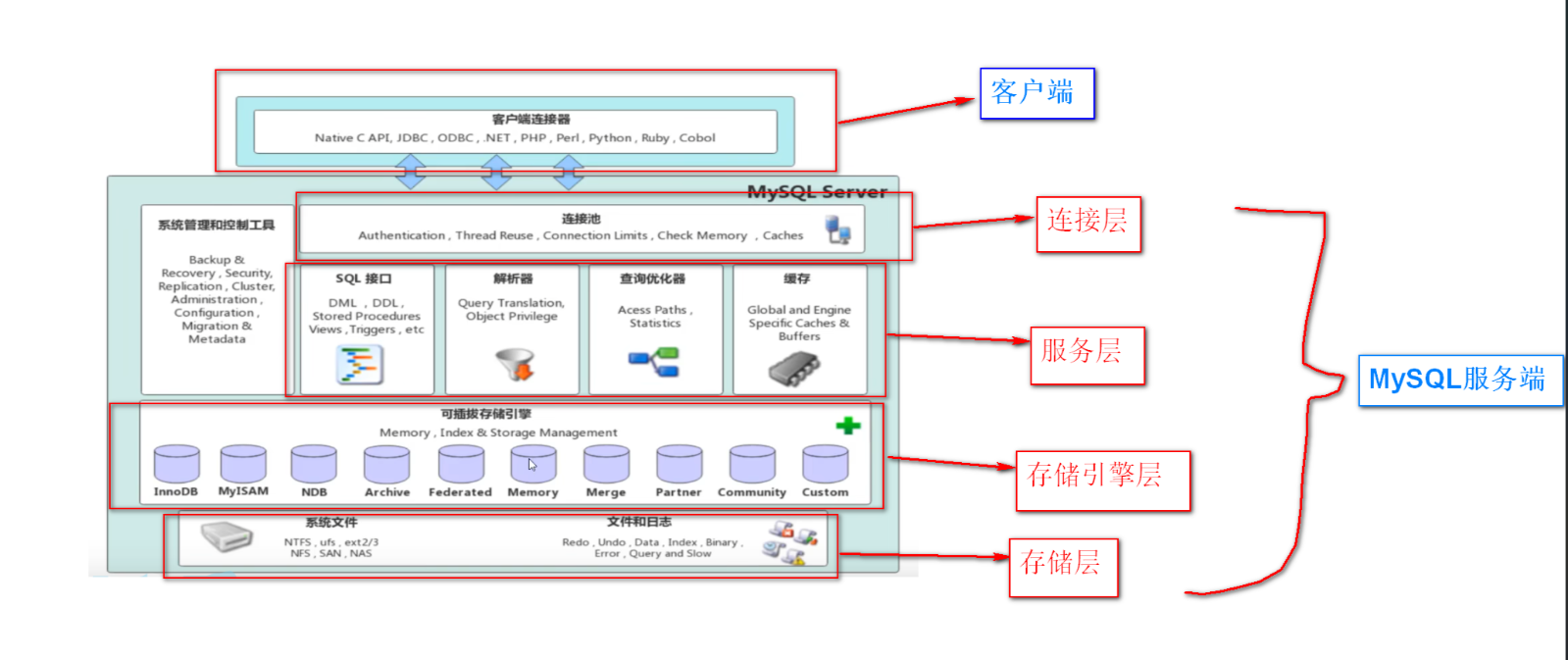
5. MySQL架构
6. SQL分类
- DDL【data definition language】 数据定义语言,用来维护存储数据的结构
- DML【data manipulation language】 数据操纵语言,用来对数据进行操作
- DCL【Data Control Language】 数据控制语言,主要负责权限管理和事务
7. 存储引擎
存储引擎是:数据库管理系统如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
MySQL的核心就是插件式存储引擎,支持多种存储引擎。
可以通过该命令查看存储引擎:
show engines;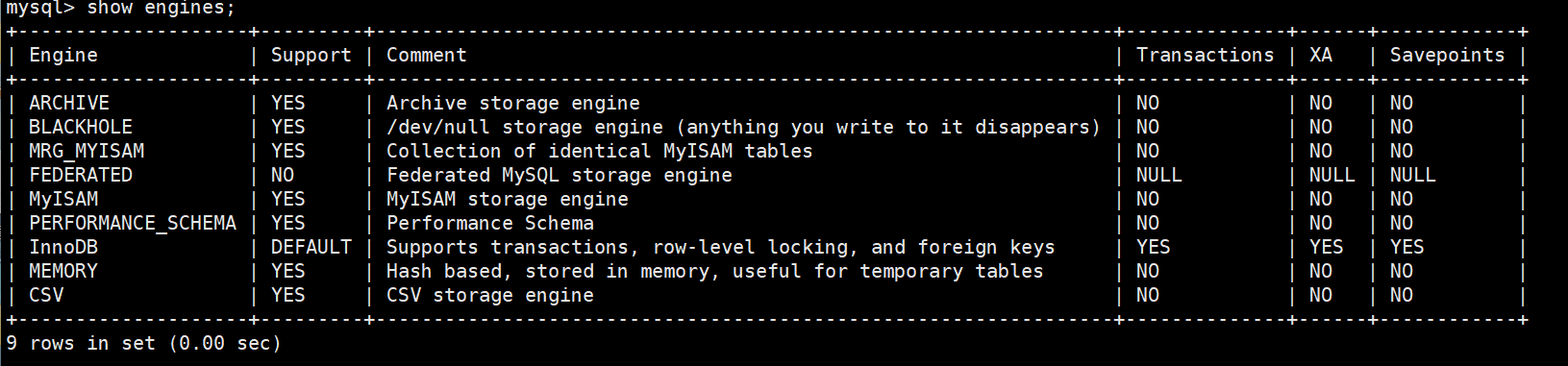
以下是 MySQL 主流存储引擎的核心特性对比表(基于 MySQL 8.0 及 2025 年最新实践):
| 特性 | InnoDB(默认) | MyISAM | Memory | Archive | NDB Cluster | ColumnStore | RocksDB |
|---|---|---|---|---|---|---|---|
| 事务支持 | ✅ ACID 兼容 + 分布式事务(X/Open XA) | ❌ 非事务型 | ❌ 无事务支持 | ❌ 非事务型 | ✅ 分布式事务(弱一致性)dev.mysql.com | ❌ 非事务型 | ❌ 仅支持单行事务 |
| 锁粒度 | ✅ 行级锁 + MVCC(高并发) | ❌ 表级锁(读多写少场景) | ❌ 表级锁(内存操作) | ✅ 行级锁(仅插入时) | ✅ 行级锁(自动分片)dev.mysql.com | ❌ 表级锁(批量操作) | ✅ 行级锁(基于 LSM-Tree) |
| 索引类型 | 聚簇 B + 树索引(主键索引存储数据) + 全文索引(MySQL 5.6+) + 空间索引 | 非聚簇 B + 树索引 + 全文索引(原生支持) | Hash/BTree(等值查询快,范围查询慢) | ❌ 不支持索引(全表扫描) | 哈希索引 + BTree(分布式索引)dev.mysql.com | 列存储索引(OLAP 优化) | LSM-Tree(写入优化,随机读弱) |
| 数据持久化 | ✅ 磁盘存储 + 事务日志(Redo/Undo) | ✅ 磁盘存储(.frm/.MYD/.MYI) | ❌ 内存存储(重启丢失) + 可选持久化内存(PMEM 技术) | ✅ 磁盘存储(压缩格式.arz) | ✅ 分布式磁盘存储(多副本)dev.mysql.com | ✅ 磁盘存储(列式压缩) | ✅ 磁盘存储(LSM-Tree 结构) |
| 存储容量 | 64TB(单表) | 256TB(云存储扩展) | 2TB(内存限制) | 理论无上限(压缩比 10-15:1) | 64TB(集群)dev.mysql.com | 1PB(列式存储压缩) | 无明确上限(依赖磁盘) |
| 适用场景 | 通用场景(金融、电商、订单),高并发读写 + 事务强一致性 | 读多写少(日志分析、报表) + 全文检索 | 临时数据、缓存(如购物车、实时统计) + 内存充足场景 | 历史数据归档(日志、监控数据) + 写入密集 | 分布式高可用(金融交易、电信) + 自动故障转移dev.mysql.com | 数据仓库、实时分析(OLAP) + 列查询优化 | 写入密集型(物联网、时序数据) + 高吞吐量 |
| 典型性能 | 随机写:3 万 TPS,顺序读:50 万 QPS | 随机读:5 万 TPS,插入:1 万 TPS | 内存操作:微秒级响应 | 插入:10 万 TPS,查询:全表扫描慢 | 分布式读:20 万 QPS,写:15 万 TPSdev.mysql.com | 列查询:比 InnoDB 快 10 倍 | 写入:20 万 QPS,随机读:1 万 QPS |
| 其他特性 | 外键约束 + 自适应哈希索引 + 压缩表(InnoDB 8.1+) | 压缩表(只读) + 快速表修复 | 固定长度行存储 + 内存碎片优化 | 数据压缩(zlib) + 仅支持 INSERT/SELECT | 自动分片 + 多活架构 + 跨云部署 | 实时聚合(SUM/COUNT) + 冷热数据分离 | 冷热数据分层 + 低延迟写入 |
说明:
- InnoDB 的主导地位:自 MySQL 5.5 起成为默认引擎,功能持续增强(如分布式事务、空间索引),覆盖 90% 以上生产场景。
- MyISAM 的现状:仍支持但逐步被边缘化,系统表已不再使用,未来可能被移除。
- Memory 的新特性:2025 年新增持久化内存(PMEM)支持,可通过硬件实现数据落盘但成本较高。
- 新兴引擎趋势:ColumnStore 和 RocksDB 在特定场景(OLAP、物联网)表现突出,但需根据业务需求评估兼容性。
- 云原生支持:InnoDB 和 NDB 原生支持 K8s 集成,Memory 和 ColumnStore 可容器化部署。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)