达摩院ICCV'25|无需预训练,端到端解析全切片图像!Pixel-Mamba重塑计算病理分析
作者|巢汉青,阿里巴巴达摩院算法专家
引言
全切片图像(WSI)是病理诊断的核心载体,但其超大尺寸与复杂的多尺度结构为AI分析带来了巨大挑战。现有方法多依赖两阶段流程或受限于注意力机制的计算瓶颈,难以兼顾效率与全局上下文建模。本文提出 Pixel-Mamba —— 一种全新的端到端WSI分析框架,实现从像素级输入到切片级预测的高效、统一建模。
Pixel-Mamba 结合 Mamba 架构的线性复杂度序列建模能力,引入 区域融合(Region Fusion)与 词元扩展(Token Expansion)机制,在保留空间结构的同时动态聚合冗余信息,并逐步构建从细胞到组织的层次化表征。通过基于区域的锯齿扫描序列化,模型在不破坏局部连续性的前提下处理原始像素流,有效平衡了局部归纳偏置与长程依赖。

研究背景与挑战
-
研究背景
组织病理学是诊断和表征多种疾病的金标准,全切片图像(WSIs)提供了直接影响临床决策的见解。随着WSIs的广泛应用,AI驱动的计算病理学在生存预测、癌症亚型分类和分子改变检测等任务中取得了显著进展,为精准医疗提供了强大支持。
-
当前挑战
WSIs尺寸巨大(常见50,000×50,000像素),给深度学习模型带来两大挑战:一是计算效率问题,单张WSI可能包含数千万像素,使用常见的深度学习模型来达到端到端训练变得非常困难;
二是表征学习问题,大尺寸图像天然包含丰富多尺度信息。例如,与良好预后相关的三级淋巴结构(TLS)仅覆盖约0.05mm²,但其分析需要考虑高达1cm²的区域,这样的尺度差异相当于完整看见一个人的同时,看清他的指甲盖。而且由于肿瘤异质性和稀疏分布的特性,要求模型综合考虑广泛的上下文。
因此,分析WSI要求模型平衡局部归纳偏置(local inductive bias)与长程依赖(long-range depandencies),同时管理层次化、多尺度结构。
目前常见的解决方案是两阶段方法(a):首先将WSI分割为固定大小的图像块(如256×256像素),使用预训练编码器提取特征,然后通过多实例学习(MIL)进行聚合得到切片级预测。然而,这种两阶段方法在效率和表征学习上仍存在明显局限:首先,将WSI分割为小块导致局部和全局特征被分开处理,破坏了多尺度信息的流动;其次,虽然计算上可行,但无法有效整合不同尺度的特征,使得模型难以捕捉从细胞层面到组织层面的完整病理信息。
近年来已有一些工作尝试改变,采用端到端改进方法(如LongViT, b),但由于WSI中存在大量token且注意力机制高度修剪,仍然无法有效建模长程依赖,导致性能受限。这些局限使得现有的WSI分析方法难以实现真正高效、全面的病理分析。为了推进这些问题的解决,我们提出了Pixel-Mamba模型(c)。
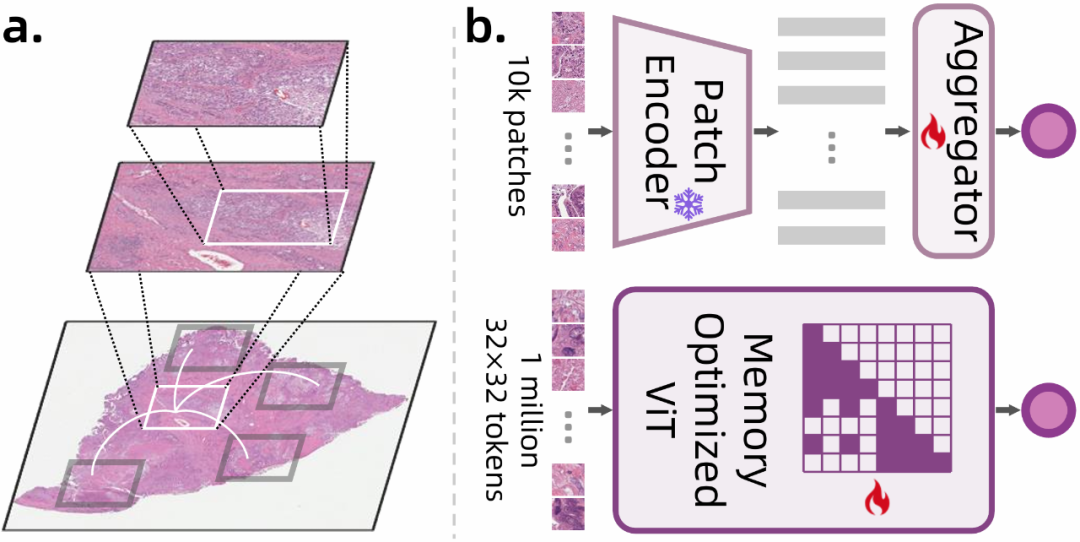
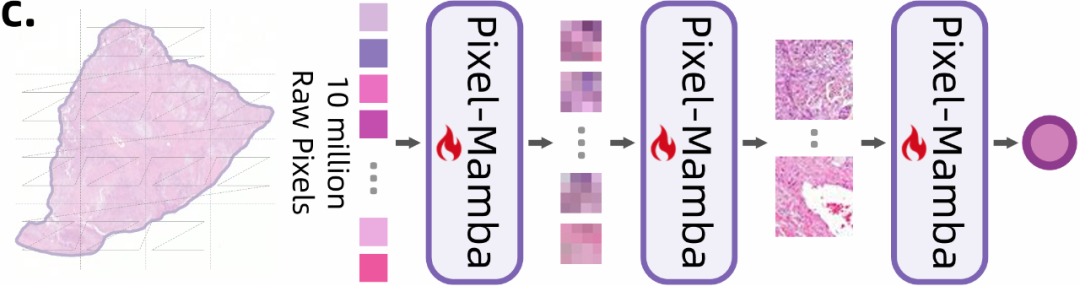
挑战与现有方法Pixel-Mamba

方法
Pixel-Mamba框架包含三个核心阶段:WSI序列化、Pixel-Mamba网络和下游任务头。在序列化阶段,WSI被转换为像素级词元作为输入。网络部分取CNN与Mamba之所长,CNN金字塔结构引入局部归纳偏置,Mamba模块建模长程依赖。
具体来说,Pixel-Mamba通过三大关键组件解决计算与表征挑战:Mamba模块(线性计算复杂度,确保全局上下文建模)、区域融合模块(迭代合并相似标记,显著减少冗余)和词元扩展机制(逐步聚合像素标记为更大空间标记,结合Mamba模块在每个层次同时捕获局部特征与建模长程依赖)。最终,Pixel-Mamba生成统一的切片级表示,支持端到端学习,无需病理特定预训练即可达到或超越现有病理基础模型性能。
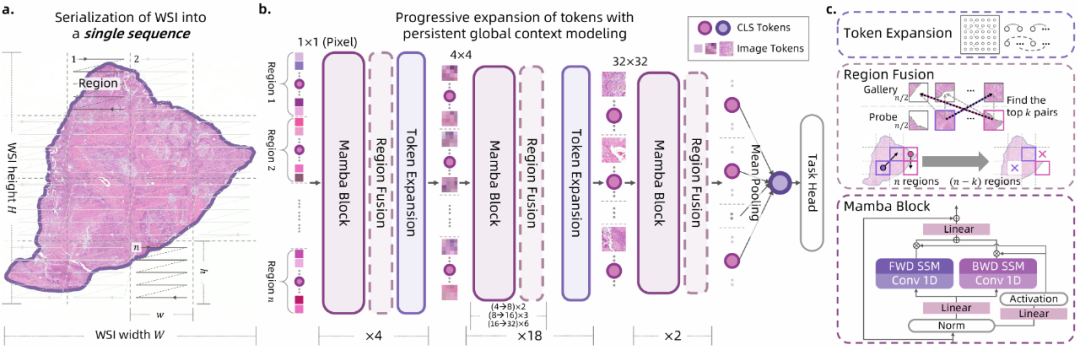
Pixel-Mamba整体架构图
-
WSI序列化
Pixel-Mamba将WSI转换为像素级标记作为输入,与传统方法(如ViT将图像分割为固定大小的块)不同,它从每个像素开始,初始时使用1×1像素级标记。为确保相邻像素在序列中保持空间接近性,采用基于区域的锯齿扫描方法,将图像划分为多个区域,每个区域内部进行锯齿扫描并插入CLS标记,有效保留空间信息(见上图a)。
-
Region Fusion 区域融合
区域融合模块在每一层网络中识别并合并具有相似特征的区域,从而显著减少冗余信息。具体而言,区域融合首先计算相邻区域之间的特征相似度,然后根据预设的相似度阈值或区域数量限制,将高度相似的区域合并为一个代表区域。通过这种机制,区域融合不仅大幅降低了计算复杂度,还保留了区域内的空间信息不受破坏,使处理超大尺寸WSIs(如50,000×50,000像素)成为可能。
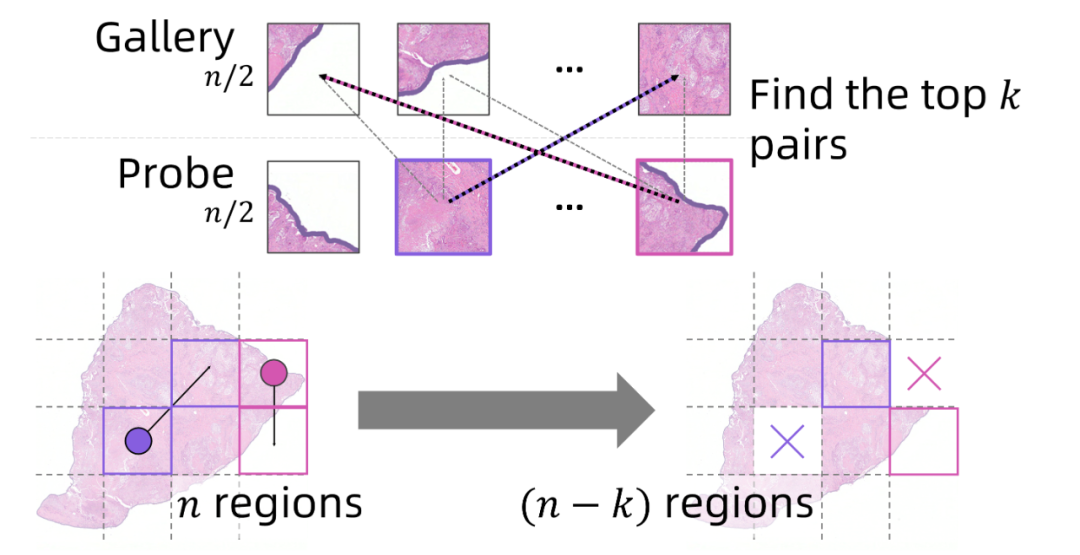
Region Fusion
-
Token Expansion 词元扩展
词元扩展机制是Pixel-Mamba网络的另一项关键创新,它通过逐步扩大标记的感受野,为网络注入局部归纳偏置。该机制从1×1像素级标记开始,以渐进方式将相邻的像素标记聚合为更大的空间标记(如2×2、4×4、8×8,最终达到32×32),形成一个从细粒度到粗粒度的层次化表示。在每个扩展阶段,词元扩展不仅有效捕获了局部归纳偏置(如细胞组合形成血管等局部结构),还通过与Mamba模块的协同工作建模长程依赖(如肿瘤异质性与稀疏分布的远距离关系)。
这种渐进式扩展过程确保了在每个层次上都能同时处理局部细节和全局上下文,解决了WSI分析中"从细胞到组织"的多尺度信息整合难题。词元扩展与区域融合的结合,使Pixel-Mamba能够在保持高内存效率的同时,全面捕捉WSI中丰富多尺度的病理信息,为后续的病理分析任务提供高质量的表示。
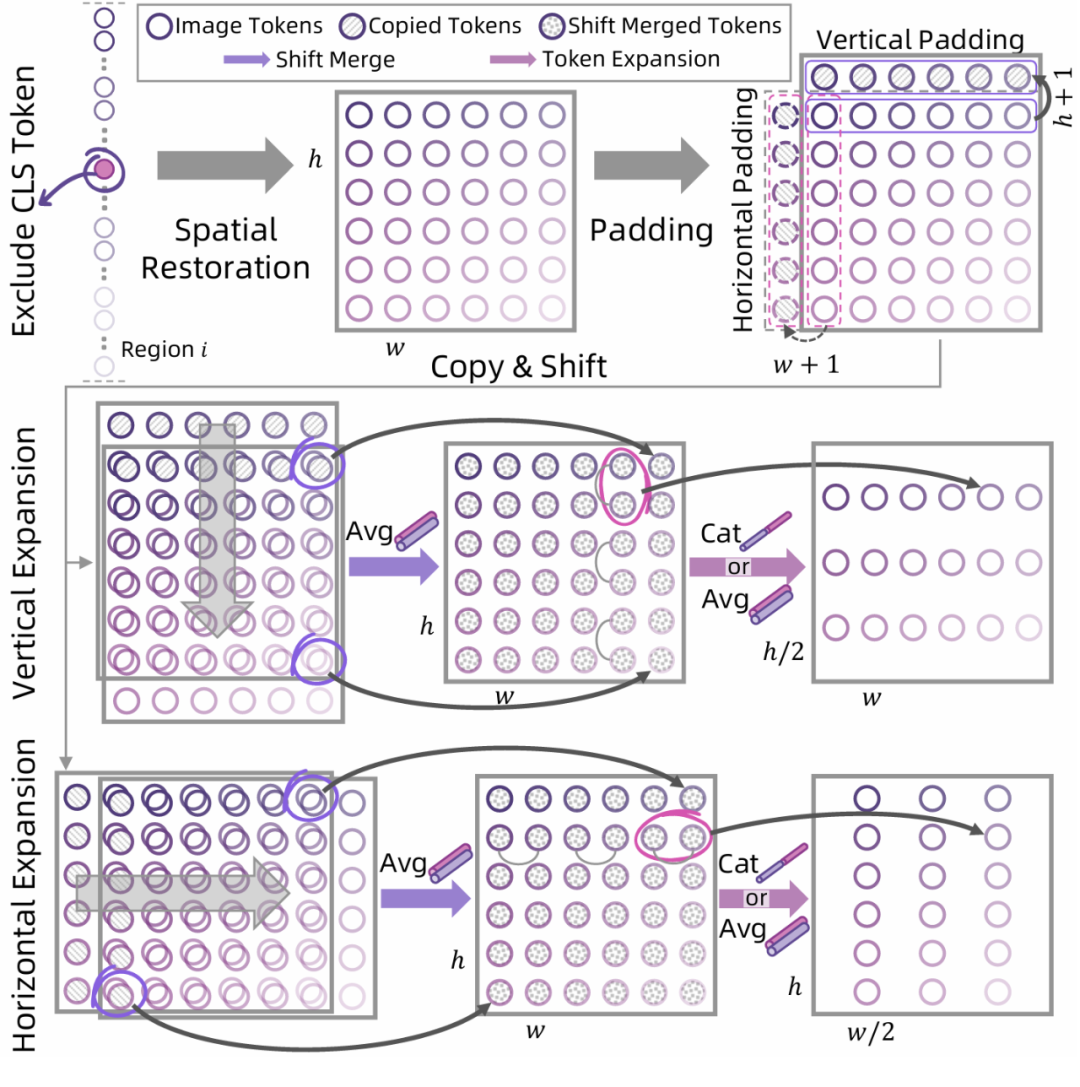
Token Expansion

实验结果
Pixel-Mamba在多个benchmarking中表现出色,实现了与最先进的基础模型相当甚至更好的性能,而这些基础模型通常是在数百万WSIs或WSI-文本对上预训练的。
此外,Pixel-Mamba无需任何病理特定预训练即可达到如此水平,大幅降低了模型部署和训练的门槛。实验表明,该方法在保持高精度的同时,计算效率比传统两阶段方法显著提升,为临床应用提供了切实可行的解决方案。
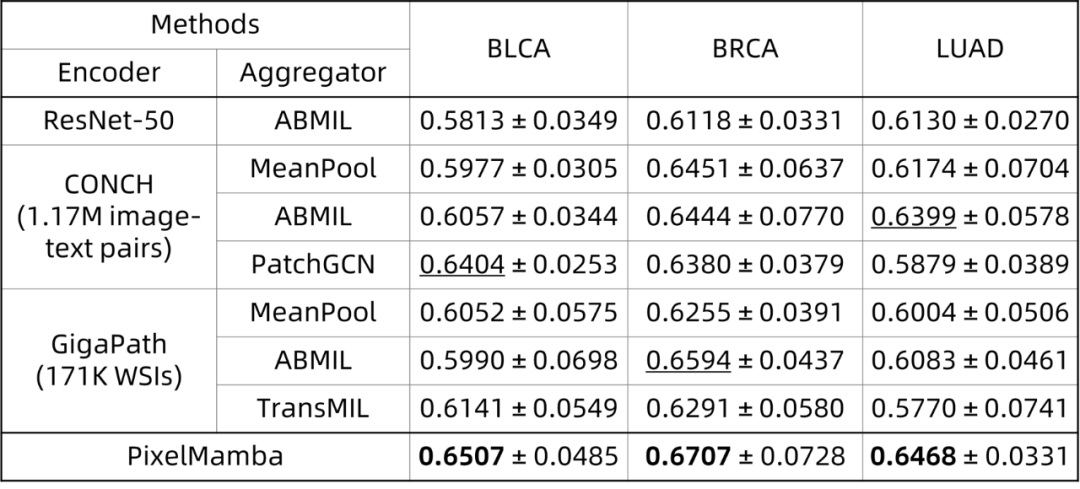
TCGA数据集多个任务结果
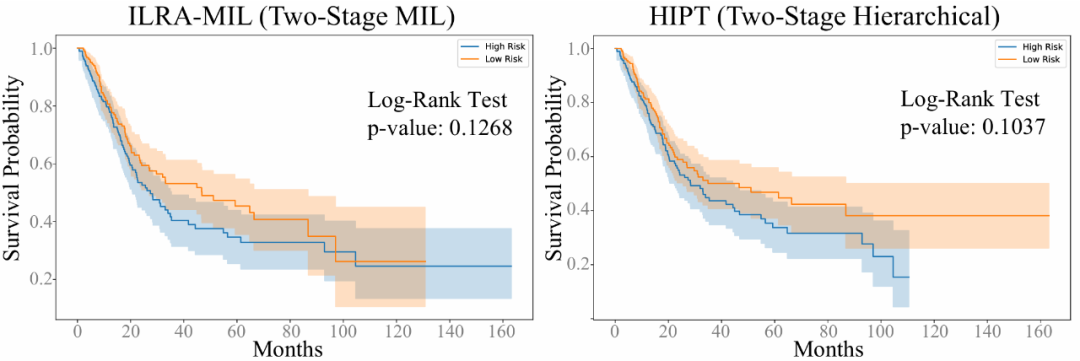
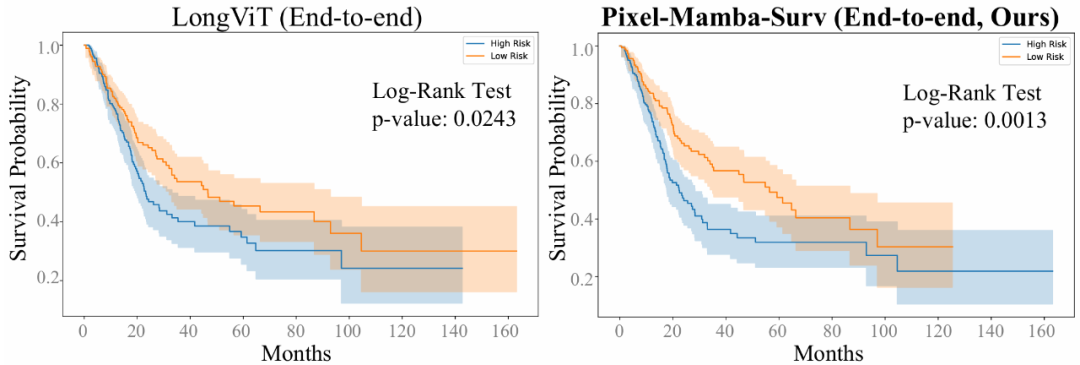
膀胱癌预后任务中可有效区分高低危人群

结论
Pixel-Mamba通过融合Mamba模块与区域融合、词元扩展策略,打开了WSI端到端训练的大门。在没有经过病理预训练的情况下比肩SOTA大模型水平,体现出了端到端训练在病理图像分析中的重要性。这一成果有望推动AI辅助病理诊断的广泛应用,为精准医疗提供更强大的技术支持。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献124条内容
已为社区贡献124条内容

所有评论(0)