达摩院EMNLP'25|提出“创意链”,让大模型像人类一样生成科研灵感
作者|李龙 阿里巴巴达摩院算法工程师
摘要
浙江大学和阿里巴巴达摩院的研究者们提出了一项名为创意链(Chain of Ideas,CoI)的创新研究。他们将文献组织成链的形式,引导模型像人类一样进行研究思考。基于 CoI,研究者们构建了一个智能体——CoI Agent。这个智能体能够通过输入一个文章主题或一篇论文,自动生成科学创意并设计对应实验。
目前项目论文、代码、Demo 均已经上线,CoI 的 Demo 现在每天生成几百个研究 Ideas,可能未来会有基于 CoI 生成 Idea 的论文发表,欢迎持续关注。
-
论文标题:Chain of Ideas: Revolutionizing Research in Novel Idea Development with LLM Agents
-
论文链接:https://arxiv.org/abs/2410.13185
-
Github链接:https://github.com/DAMO-NLP-SG/CoI-Agent
-
Demo链接:https://huggingface.co/spaces/DAMO-NLP-SG/CoI_Agent

序言
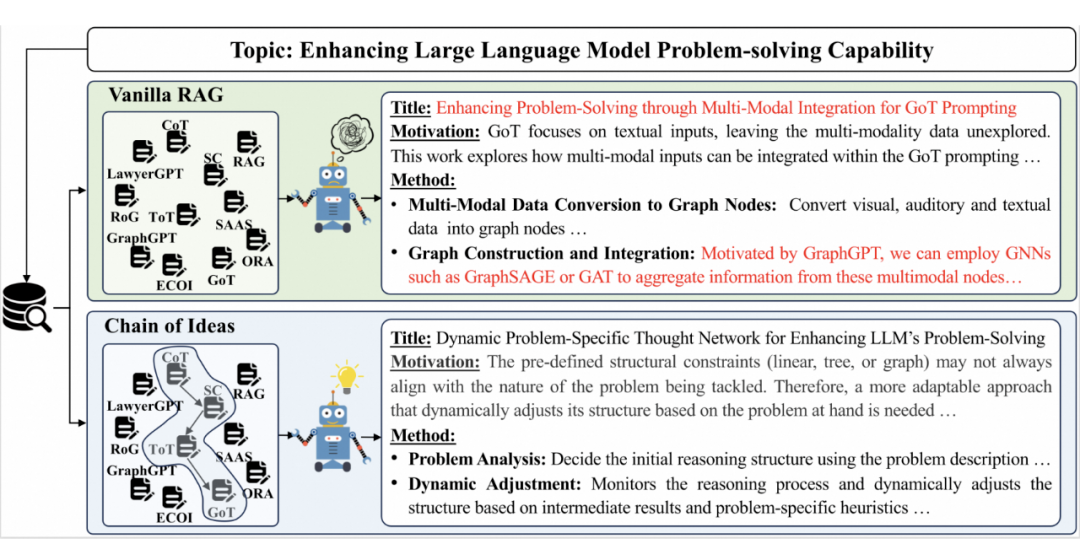
图1. CoI与传统方法的区别
传统的方法通常是围绕一个研究主题,检索大量相关文献,并将这些文献的知识作为提示词输入到大型语言模型中。
然而,这种方法存在一个显著的问题:尽管这些文献都围绕着同一主题,但它们的内容往往杂乱无章,就像是在分叉路口给模型指了多个方向,导致模型难以判断哪条路是正确的,也不清楚如何深入研究。这不仅容易让研究浅尝辄止,还可能使模型陷入混乱、停滞不前。
为了克服这一挑战,研究者们提出了一种新的知识注入方式——创意链(CoI)。CoI 的核心思想是更有效地组织外部知识,使大型语言模型能够模仿人类的思考方式。通过这种方式,模型不仅能够理解文献的表面信息,还能深入挖掘其背后的逻辑和联系,从而更准确地指导研究的方向。

具体方法
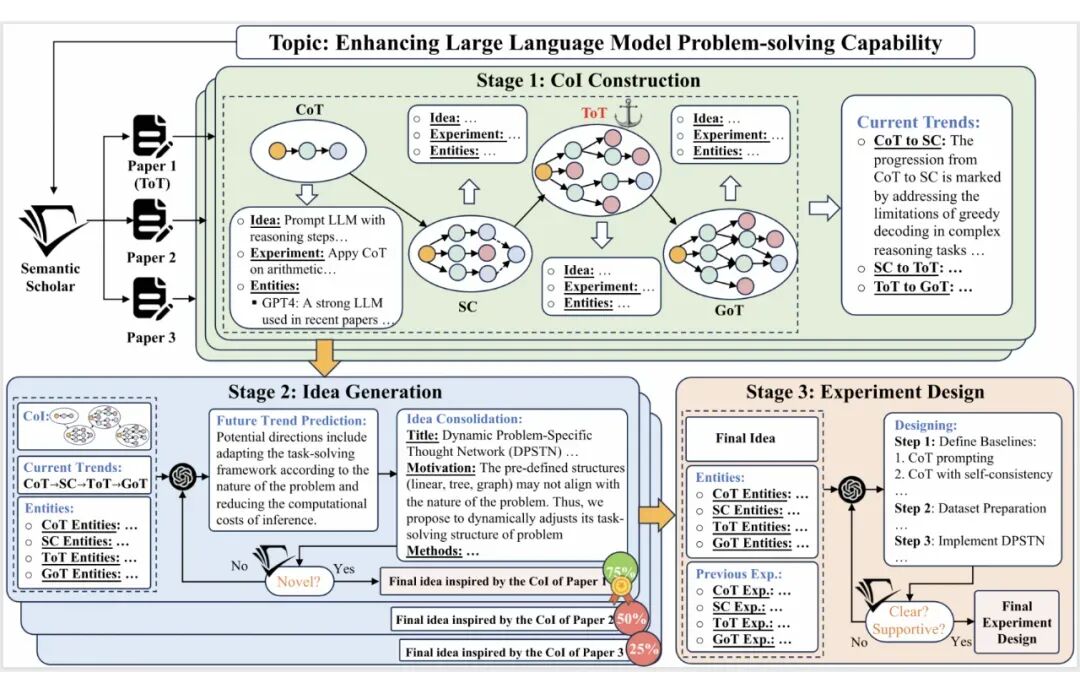
图2. CoI 的主要原理
具体过程如图 2 所示,从特定研究主题出发检索 n 篇相关文献,将它们分别作为 n 条创意链的锚点。接着,向前追溯引用这些文献的文章,精选出与主题最相关、与原论文直接关联的文献,作为链的下一个节点。这个过程不断重复,直到无法找到更多相关文献。
同样,我们也向后追溯被该文章引用的文献,直到文献链达到合理长度。通过这种方式,我们构建了一条条论文链,每一条都是对特定研究主题的深入剖析。
利用大型语言模型,我们从这些链中提取关键思想形成了 CoI,它反映了人类研究过程中的清晰脉络,帮助语言模型分析论文间的递进关系,预测未来的研究方向,并最终提出创新的创意。
这种方法极大地降低了大型语言模型在处理复杂文献时的困难。通过比较 n 条链生成的 n 个创意,我们选择胜率最高的作为最终创意,以减少低质量链的影响。
研究者们进一步指导大型语言模型,根据提出的创意和过去的实验,设计新的实验。由于创意基于 CoI 生成,理想情况下是过去方法的延伸,可以复用旧的实验设计,包括基线和测试指标,有效避免了模型在设计实验时的幻觉问题。
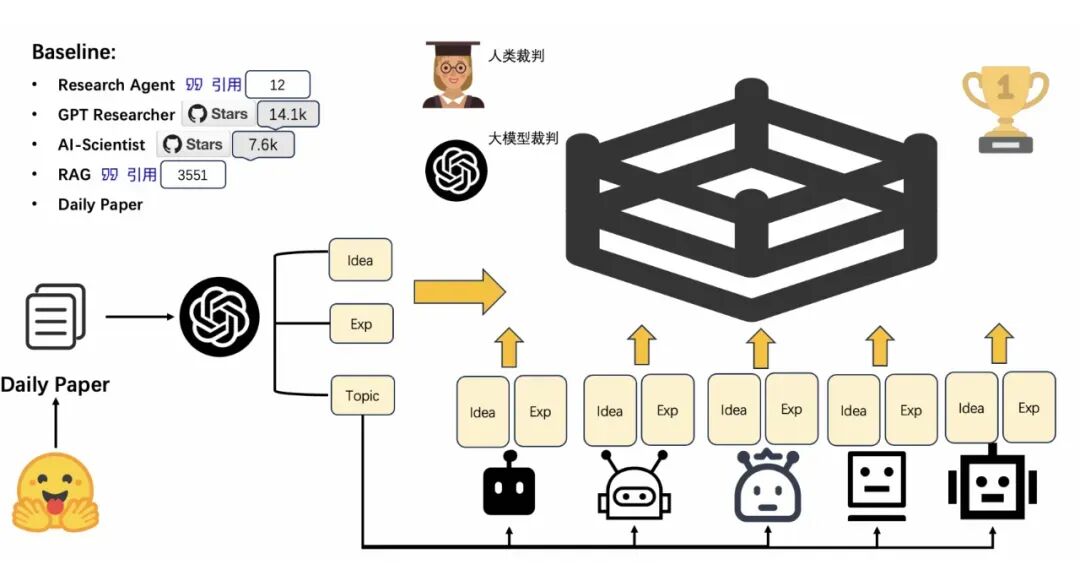
图3. Idea Arena
为了验证创新创意的质量,研究人员开发了一种新颖的科学创意评估工具——Idea Arena。
过去,使用大语言模型生成一个 Likert 量表来评估创意的质量 [3,4]。然而,由于科学创意是一个开放性的问题,这导致了在自动评分过程中不存在一个明确的、普遍认可的黄金标准作为参考。这使得模型的评价标准无法和人类的评价标准对齐 [5]。
为了避免这一问题,我们采用了一种类似竞技场的评测方法,将创意的评价从直接评分转换为两两比较,降低大语言模型评测时对黄金标准的依赖,从而能得出更精准的评价结果 [6]。为了比较机器生成的创意和真实人类产生的创意,研究人员还将现实世界中的学术论文纳入了竞技场进行比较。

实验结果
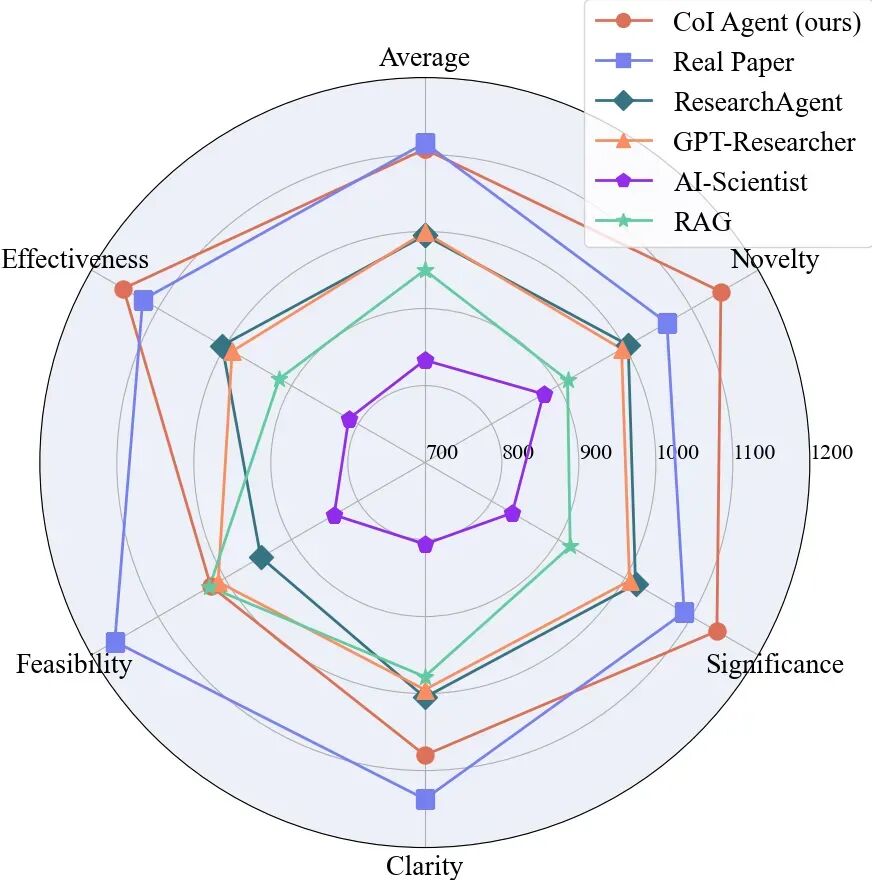
图4.大语言模型评估结果
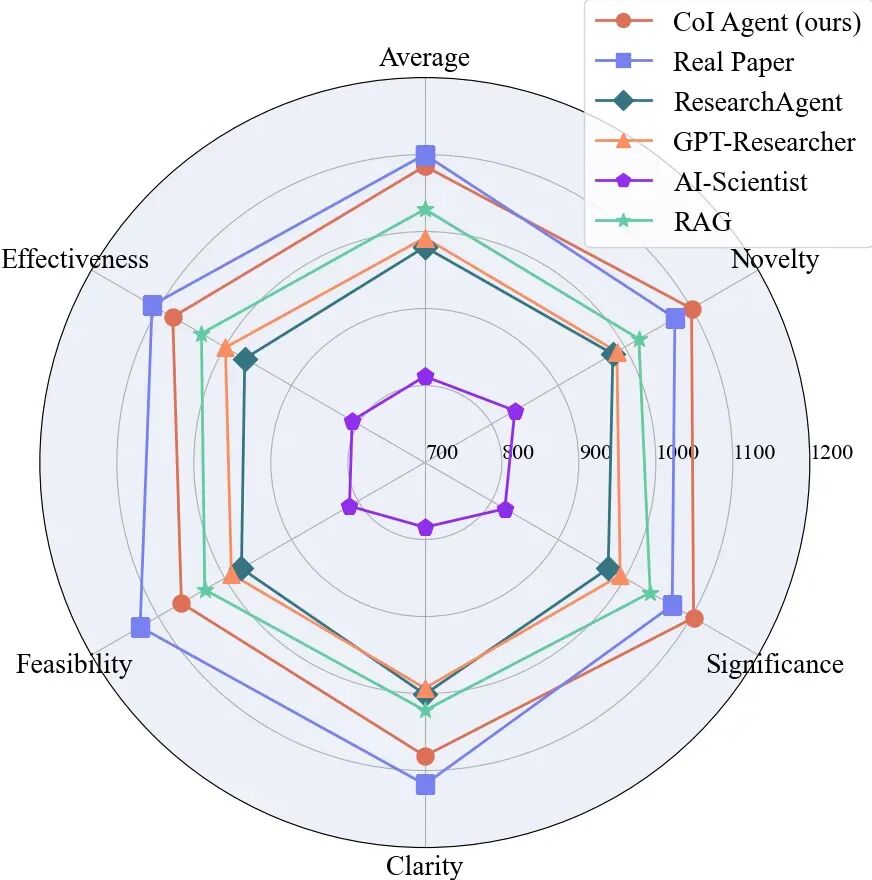
图5.人工评估结果
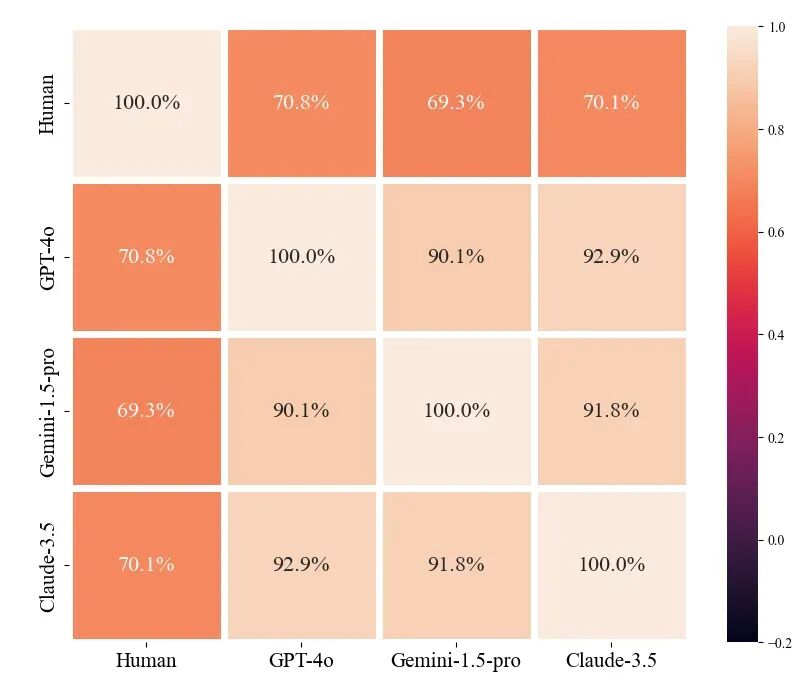
图6.一致性分析
-
创意层面节目
使用Claude-3.5、Gemini-1.5-pro 和 GPT-4o 三种大语言模型进行测试,一致性超过了 90%。与人类的判断进行比较时,大语言模型与人类的评价一致率也达到了约 70%。
最后,综合人类专家和大型语言模型的评估结果,研究者们发现 CoI Agent 在多个维度上都比其他方法有显著提升,其表现已经接近真实人类论文的水平。特别是在新颖性和重要性这两个方面,CoI Agent 甚至已经稳定超越了现实世界中的论文。
尽管在可行性方面还有所欠缺,这主要是因为真实论文必须经过实验验证才能发表,而生成的创意尚未经过这样的检验,但这样的进步仍然展示了大型语言模型的潜力。
-
验设计层面结果
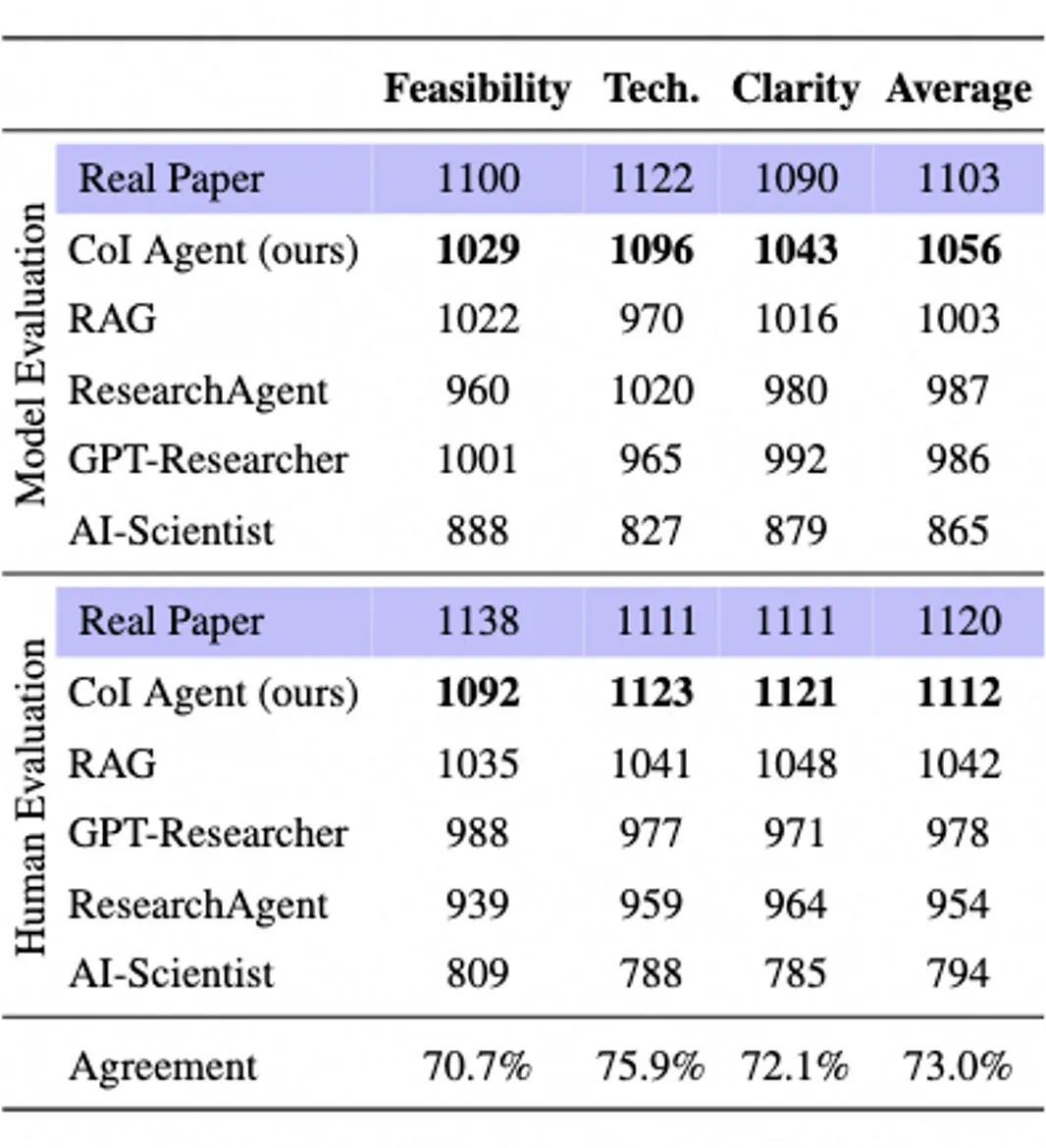
图7.实验设计评估结果
在实验层面,CoI Agent 同样表现出色,并且在专家的评估中接近了真实人类论文的水平。这验证了 CoI Agent 的生成质量,并证明了这种创意链构造方式的合理性。
-
消融实验结果
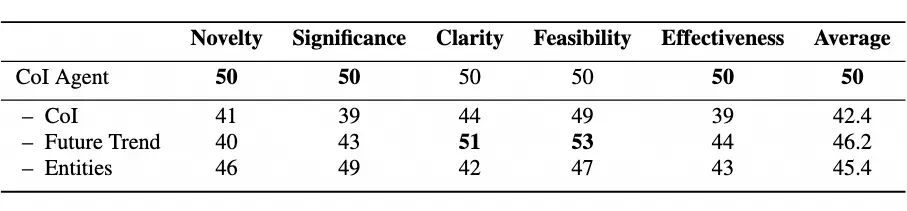
图8. 消融实验结果
如图 8 显示,每个组件对生成质量都有影响。当研究人员将 CoI 替换为 RAG,而保持其他部分不变时,生成的创意在新颖性、重要性和有效性这三个指标上都出现了明显下降,这说明了 CoI 这种文献组织方式的有效性。
因为大型语言模型缺乏对潜在前瞻性创意的洞察,所以去除未来趋势预测会降低新颖性。省略实体信息也会降低清晰度和有效性,使得生成的创意会更加抽象,缺乏特定概念的支持。这突出了实体信息在提升创意的清晰性和实际相关性方面的价值。
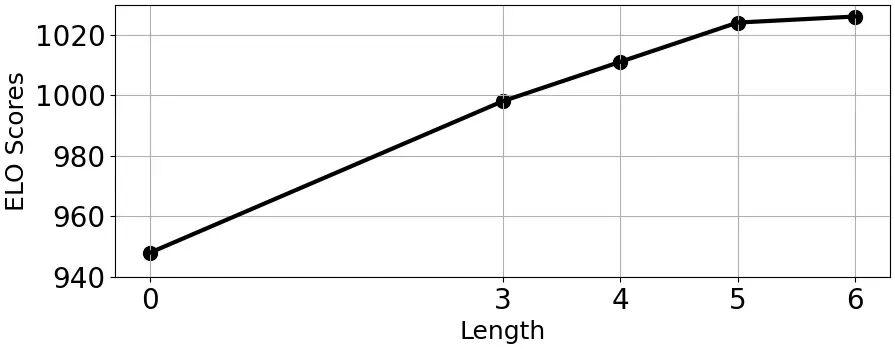
图9.创意链长度分析
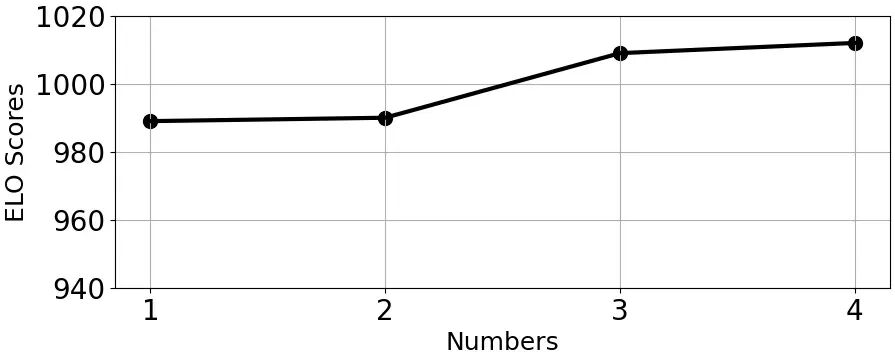
图10.创意链数量分析
为了深入探究创意链的各个变量对生成质量的影响,研究人员还对链的长度和数量进行了分析实验,实验结果如图 9、图 10 所示。
为了更好地探究链的长度的影响,研究人员将 CoI 替换为 RAG,检索 5 篇相关文献作为链长度为 0 的特殊情况(其他部分与原方法一致)。
实验结果表明,链的长度与生成创意的质量有明显的正相关关系。这说明较长的 CoI 能够提供更可靠和全面的洞察,反映当前研究领域内的发展趋势,从而使大型语言模型能够更好地把握未来的发展趋势。当长度达到 5 之后,生成的创意质量开始趋于平稳。这一饱和点表明,这个长度足以捕捉相关趋势,而额外的文献提供的帮助不再明显。
在链的数量方面,类似于多次采样、优中选优。因此,增加分支数量与创意质量会表现出正相关。然而,不同分支数量之间的 ELO 评分差异较小。这一现象可能归因于生成多个链主要有助于降低任何单一CoI 表现不佳的影响。

生成样例

图11. 生成样例
图 11 展示了一个由 CoI Agent 生成的创意示例,以及应用大语言模型进行科学研究相关的 5 篇递进性论文,并将它们组成了一条发展路径。
通过分析每篇论文的研究趋势,它认为当前应该解决的问题是创意生成的多样性和新颖性。因此,引入了进化算法并利用选择、交叉、变异和迭代这四个步骤来解决这些问题。可以看到,这个推理过程非常自然,不仅仅是简单地融合过去的文献,进行方法的拼接,而是真正提出了针对痛点的解决方案。

总结
CoI Agent 通过将创意组织为链条结构,提供了一种有前景且简明的解决方案,有效地反映了特定研究领域内的渐进发展。它帮助大语言模型理解当前的研究进展,从而增强它们的创意能力。
然而,正如研究者们所观察到的,生成的创意虽然在创新性上能力突出,但通常在可行性方面存在不足,这与目前的最新研究一致 [7]。如果能够让智能体自主进行实验,并根据实验结果来完善创意和实验设计,那么我们就能实现一个完整的科研循环。
这样的循环是实现自动化科研创新的关键。这也是本文研究者们希望在未来继续探索和深入研究的方向。通过这样的方法,我们不仅能够生成创新的创意,还能确保这些创意在实践中的可行性,从而推动科研的自动化和创新。
[1] Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks[J]. Advances in Neural Information Processing Systems, 2020, 33: 9459-9474.
[2]https://www.linkedin.com/feed/update/urn:li:activity:7252935332797583360/
[3] Baek J, Jauhar S K, Cucerzan S, et al. Researchagent: Iterative research idea generation over scientific literature with large language models[J]. arXiv preprint arXiv:2404.07738, 2024.
[4] Lu C, Lu C, Lange R T, et al. The ai scientist: Towards fully automated open-ended scientific discovery[J]. arXiv preprint arXiv:2408.06292, 2024.
[5] Zheng L, Chiang W L, Sheng Y, et al. Judging llm-as-a-judge with mt-bench and chatbot arena[J]. Advances in Neural Information Processing Systems, 2023, 36: 46595-46623.
[6]Zhao, Ruochen, et al. 'Auto Arena of LLMs: Automating LLM Evaluations with Agent Peer-battles and Committee Discussions.'arXiv preprint arXiv:2405.20267 (2024).
[7]Si, Chenglei, Diyi Yang, and Tatsunori Hashimoto. 'Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers.'arXiv preprint arXiv:2409.04109 (2024).

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献124条内容
已为社区贡献124条内容

所有评论(0)