(五)pandas-修改数据
pandas修改数据可以通过以下几种方式:1、通过切片定位到数据位置,然后直接赋值2、mask/where 两个函数3、replace函数4、apply函数。
·
pandas修改数据可以通过以下几种方式:
1、通过切片定位到数据位置,然后直接赋值
2、mask/where 两个函数
3、replace函数
4、apply函数
以下图df为例:
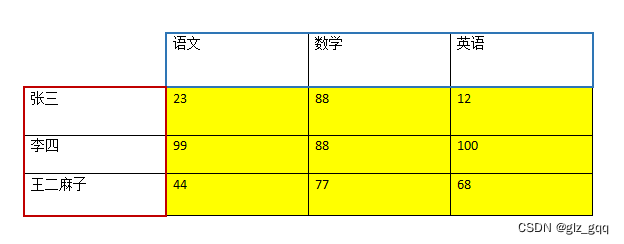
1、切片方式
切片方式用于通过下标/标签直接定位到指定位置,然后修改数据
import numpy
import pandas as pd
scores = [23, 88, 12], [99, 88, 100], [44, 77, 68], [44, 77, 68]
df = pd.DataFrame(scores, index=['张三', '李四', '王五', "赵六"], columns=['语文', '数学', '英语'])
# 将张三的语文成绩改为100
df["语文"]["张三"] = 100
df.iloc[0, 0] = 100
df.loc["张三", "语文"] = 1002、mask/where函数
mask()和where()参数相同,作用相反
mask()会把条件成立的数据改为替换数据
where()会把条件不成立的数据改为替换数据
mask()和where()是通过遍历数据源,把符合条件的数据替换为指定数据
import numpy
import pandas as pd
scores = [23, 88, 12], [99, 88, 100], [44, 77, 68], [44, 77, 68]
df = pd.DataFrame(scores, index=['张三', '李四', '王五', "赵六"], columns=['语文', '数学', '英语'])
# 把大于80的语文成绩都改成100
df["语文"].mask(df["语文"] > 80, 100, inplace=True)
# 把小于80的语文成绩都改成100
df["语文"].where(df["语文"] > 80, 100, inplace=True)3、replace函数
replace()函数的功能很全面,用法很多,这里只是简单介绍一下,详细了解最好查看官网文档
import numpy
import pandas as pd
scores = [23, 88, 12], [99, 88, 100], [44, 77, 68], [44, 77, 68]
df = pd.DataFrame(scores, index=['张三', '李四', '王五', "赵六"], columns=['语文', '数学', '英语'])
# 将所有人的语文成绩是23的改成90
df.replace({"语文": {
23: 90
}}, inplace=True)
# 将所有成绩中的77改成99
df.replace(77, 99, inplace=True)
# 将王五的44分都替换成90分
df.loc["王五"].replace(44, 90, inplace=True)4、apply函数
把df的每一行/列应用到指定的函数之上
def apply(self,
func: (...) -> Any | str | list[(...) -> Any | str] | dict[Hashable, (...) -> Any | str | list[(...) -> Any | str]],
axis: Literal["index", "columns", "rows"] | int = 0,
raw: bool = False,
result_type: Literal["expand", "reduce", "broadcast"] | None = None,
args: tuple = (),
**kwargs: Any)
把dataframe拆分成一个个的Series,然后依次以Series作为参数来调用func
func:
· 应用的函数,固定接收一个Series作为第一个参数,若有其他参数可通过args和kwargs传递
axis:
· 控制是按行还是列来拆分
0 or 'index': 按列来拆分
1 or 'columns': 按行来拆分import pandas as pd
def modify_score(df):
# 把所有人的语文都改成100分
df["语文"] = 100
scores = [23, 88, 12], [99, 88, 100], [44, 77, 68], [44, 44, 44]
df = pd.DataFrame(scores, index=['张三', '李四', '王五', "赵六"], columns=['语文', '数学', '英语'])
df.apply(modify_score, axis=1)
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)