生物统计学(biostatistics)学习笔记(四)统计推断(已知样本推总体)
第四章统计推断(已知样本推总体)文章目录第四章统计推断(已知样本推总体)假设检验的原理与方法样本方差的同质性检验样本平均数的假设检验参数估计上一章我们讨论了已知总体的时候样本的特征,即抽样分布。本章我们来讨论已知样本的时候如何推断总体的特征,主要任务是分析差异产生的原因,是随机误差导致的,还是一些处理效应导致的。假设检验的原理与方法假设检验(hypothesis test):也叫显著性检验(sig
第四章统计推断(已知样本推总体)
上一章我们讨论了已知总体的时候样本的特征,即抽样分布。
本章我们来讨论已知样本的时候如何推断总体的特征,主要任务是分析差异产生的原因,是随机误差导致的,还是一些处理效应导致的。
假设检验的原理与方法
假设检验(hypothesis test):也叫显著性检验(significance test),是根据总体的理论分布和小概率原理,对未知或不完全知道的总体提出两种彼此对立的假设,然后由样本的实际结果,经过一定的计算,做出在一定概率意义上应该接受哪种假设的推断。
假设检验的步骤
1. 提出假设
零假设(null hypothesis)也称无效假设,是指处理效应没有产生真实的差异,即差异都是随机误差导致的。
备择假设(alternative hypothesis),是指处理效应产生了真实的差异。
2. 确定显著水平
显著水平(significance level)是人为规定的小概率界限,用α表示,常用取值是0.05或0.01,特殊情况时也可以取其他值。
α也是假阳性发生的概率,及I型错误的发生率
3. 计算统计数与相应的概率
在假定零假设正确的前提下,选择恰当的抽样分布相关公式计算标准化后的统计数,然后查表找到对应的概率累积函数值。
4. 推断是否接受假设
推断的基础是小概率原理,即认为小概率事件在一次抽样试验中几乎是不可能发生的
双尾检验和单尾检验

| 零假设 | 备择假设 | |
|---|---|---|
| 差值等于0 | 差值不等于0 | u**<- u α 2 \frac{u{_α}}{2} 2uα和u> u α 2 \frac{u{_α}}{2} 2uα两个区域,所以叫双尾检验** |
| 差值大于0 | u**> u α u_α uα区域**,单尾检验 | |
| 差值小于0 | u**<- u α u_α uα区域**,单尾检验 | |
| 单尾检验灵敏度高,一般用单尾 |
假设检验的两类错误

I型错误,也常称为α错误,弃真错误或假阳性错误。发生概率α
II型错误,也常称为β错误,取伪错误或假阴性错误。概率与两个总体的分布情况有关,也与显著水平α有关
如何减少II型错误:
(1)α越大,β越小(不可取)
(2)两个μ的差值越大,β越小(比如采用更有效的药物)
(3)备择曲线的σ值越小,β越小(样本越集中)
(4)为了少犯β错误,增加样本容量是最有效的办法
样本方差的同质性检验
方差的同质性(又称方差齐性,homogeneity of variance),就是指各个总体的方差是相同的
•方差同质性检验就是要从各样本的方差来判断其总体方差是否相同。
| 比较一个样本所属总体的方差与参考总体的方差有无显著差异 | 比较两个样本所属总体的方差与参考总体的方差有无显著差异 |
|---|---|
| 卡方检验 | F检验 |
一、比较一个样本所属总体的方差与参考总体的方差有无显著差异,使用卡方检验
例题•已知正常农田铅浓度的方差0.065(μg/g)2,某农田经抽样8份,测定其铅浓度的方差0.15(μg/g)2,问该农田铅浓度的方差与正常农田是否相同。
•(1)零假设两者铅浓度的方差无差别,即某农田的铅浓度的方差正常。
•(2)显著性水平α取0.05
•(3)计算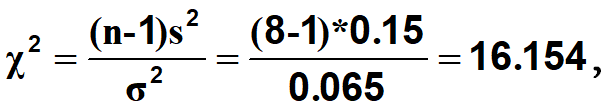
• df=n-1=7时,卡方检验右尾检验的拒绝区是卡方大于14.07,16.154落在拒绝区内。
•(4) 结论:拒绝零假设,认为两者铅浓度的方差有显著差别,且该农田铅浓度的方差高于正常值。
二、 比较两个样本所属总体的方差与参考总体的方差有无显著差异,使用F检验
例题•小麦品种甲抽样10次,其千粒重的方差是22.933,小麦品种乙抽样10次,其千粒重的方差是2.933,问两个品种的千粒重的方差是否相同。
•(1)零假设两者千粒重的方差无差别。
•(2)显著性水平α取0.05。
•(3)计算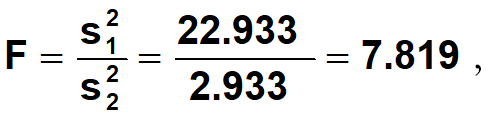
• df1=n-1=9,df2=n-1=9时,F检验右尾检验的拒绝区是F>3.18,7.819落在拒绝区内。
•(4) 结论:拒绝零假设,认为两者千粒重的方差有显著差别,且品种甲的方差高于品种乙。
样本平均数的假设检验
| 一个样本平均数的假设检验总结 | 两个样本平均数的假设检验总结 |
|---|---|
| 比较样本所属总体和参考总体的平均数,且参考总体的方差已知,用u检验 | 比较两个样本所属总体的平均数,且两个总体的方差已知,用u检验 |
| 比较样本所属总体和参考总体的平均数,且参考总体的方差未知,用t检验,但在样本容量较大(≥30)时,t检验和u检验几乎没有区别 | 比较两个样本所属总体的平均数,且两个总体的方差未知,但在两个样本容量都较大(≥30)时,可以用u检验简化计算 |
| 比较两个样本所属总体的平均数,且两个总体的方差未知,样本容量较小时应使用t检验,可以分成三种情况:方差相等,样本容量相等或两者均不相等 | |
| 对于成对数据,其实可以转化成一个样本平均数的假设检验,服从df=n-1的t分布,当n足够大时,可以简化为u检验。 |
参数估计
参数估计是指由样本结果对总体参数在一定概率水平下所做出的估计。
其实,参数估计就是统计推断相反的运算过程;
统计推断是已知μ,求u或t的值;
参数估计就是已知u或t,求μ的值。
例题•测得某批25个小麦样本的平均蛋白质含量为14.5%。
•(1)正常小麦的蛋白质含量为14%,标准差为2.50%,请问该样本是否正常?
•(2)求该批蛋白质含量的95%置信区间。
•(1) 零假设该样本蛋白质含量等于14%,备择假设该样本蛋白质含量不等于14%。
•显著性水平α取0.05
•标准化计算
•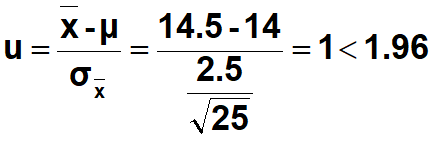
接受零假设,该样本与正常小麦样本无差别
•(2) 求95%置信区间,即
•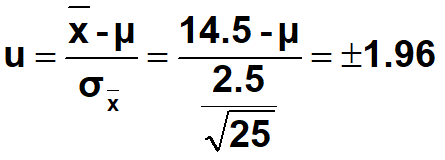
•经计算可得μ=13.52或15.48。
•即该批蛋白含量的95%置信区间为13.52%~15.48%(区间估计),也可以写成14.5±0.98(点估计)。
•显然这个区间包括了14%,从另一个角度验证了上一小题的结论是正确的。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)