机器学习特征选择:包装法
如果我们此时追求的是最大化降低模型的运行时间,我们甚至可以直接选择50作为特征的数目,这是一个在缩减了94%的特征的基础上,还能保证模型表现在90%以上的特征组合,不可谓不高效。在修剪的集合上递归的重复该过程,直到最终到达所需数量的要选择的特征,区别于嵌入法每次都是用全部特征来进行训练和建模,因此包装法需要的计算成本位于嵌入法和过滤法中间。注意,在这个图中的“算法”,指的不是我们最终用来导入数据的
包装法也是一个特征选择和算法同时进行的方法,与嵌入法非常相似,它也是依赖算法自身的coef属性和feature_importance属性来完成特征选择。但不同的是,我们往往使用一个目标函数来帮助我们选取特征,而不是自己输入某个评估指标或统计量的阈值。包装法在初始特征集上训练评估器,并且通过coef属性或feature_importance属性获得每个特征的重要性。然后,从当前的一组特征中修剪最不重要的特征。在修剪的集合上递归的重复该过程,直到最终到达所需数量的要选择的特征,区别于嵌入法每次都是用全部特征来进行训练和建模,因此包装法需要的计算成本位于嵌入法和过滤法中间。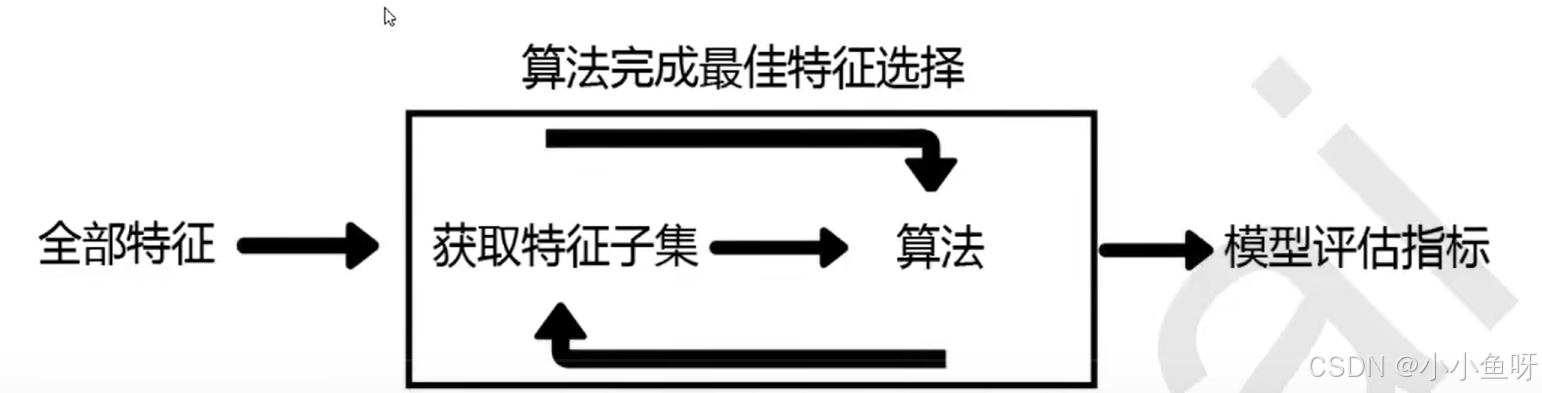
注意,在这个图中的“算法”,指的不是我们最终用来导入数据的分类或回归算法(即不是随机森林),而是专业的数据挖掘算法,即我们的目标函数。这些数据挖掘算法的核心功能就是选取最佳特征子集。
最典型的目标函数是递归特征消除法(Recursive feature elimination,简写为RFE)。它是一种贪婪的优化算法旨在找到性能最佳的特征子集。它反复创建模型,并在每次迭代时保留最佳特征或剔除最差特征,下一次迭代时它会使用上一次建模中没有被选中的特征来构建下一个模型,直到所有特征都耗尽为止。然后,它根据自己保留或剔除特征的顺序来对特征进行排名,最终选出一个最佳子集。包装法的效果是所有特征选择方法中最利于提升模型表现的,它可以使用很少的特征达到很优秀的效果。除此之外,在特征数目相同时,包装法和嵌入法的效果能够匹敌,不过它比嵌入法算得更快,虽然它的计算量也十分庞大,不适用于太大型的数据。相比之下,包装法是最高效的特征选择方法。
参数estimator是需要填写的实例化后的评估器,n_feature_to_select是想要选择的特征个数,step表示每次迭代中希望移除的特征个数。除此之外,RFE类有两个很重要的属性,.support_:返回所有的特征的是否最后被选中的布尔矩阵,以及.ranking_返回特征的按数次迭代中综合重要性排名。类feature_selection.RFECV会在交叉验证循环中执行RFE以找到最佳数量的特征,增加参数cv,其他用法都和RFE一摸一样。
from sklearn.feature_selection import RFE
RFC_=RFC(n_estimators=10,random_state=0)
selector=RFE(RFC_,n_features_to_select=340,step=50).fit(x,y)
selector.support_.sum()
#40
selector.ranking_
x_wrapper=selector.transform(x)
cross_val_score(RFC_,x_wrapper,y,cv=5).mean()
#0.9390对超参数n_feature_to_select进行画学习曲线
score=[]
for i in range(1,751,50):
x_wrapper=RFE(RFC_,n_features_to_select=i,step=50).fit_transform(x,y)
once=cross_val_score(RFC_,x_wrapper,y,cv=5).mean()
score.append(once)
plt.figure(figuresize=[20,5])
plt.plot(range(1,751,50),score)
plt.xticks(range(1,751,50))
plt.show()
明显能够看出,在包装法下面,应用50个特征时,模型的表现就已经达到了90%以上,比嵌入法和过滤法都高效很多。我们可以放大图像,寻找模型变得非常稳定的点来画进一步的学习曲线(就像我们在嵌入法中做的那样)。如果我们此时追求的是最大化降低模型的运行时间,我们甚至可以直接选择50作为特征的数目,这是一个在缩减了94%的特征的基础上,还能保证模型表现在90%以上的特征组合,不可谓不高效。
同时,我们提到过,在特征数目相同时,包装法能够在效果上匹敌嵌入法。试试看如果我们也使用340作为特征数目,运行一下,可以明显感觉到,包装法的运行速度更快。其效果和嵌入法相差不多,在更小的范围内使用学习曲线,我们也可以将包装法的效果调得很好,大家可以去试试看。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)