开源项目实战学习之YOLO11:12.1 ultralytics-models-sam-blocks.py源码
开源项目实战学习之YOLO11:12.1 ultralytics-models-sam-blocks.py源码
·
👉 点击关注不迷路
👉 点击关注不迷路
👉 另外,前些天发现了一个巨牛的AI人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。感兴趣的可以点击相关跳转链接。
ultralytics-models-sam
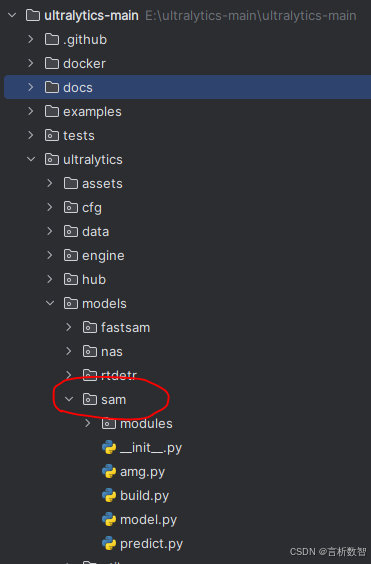
- blocks.py:
- 定义模型中的各种模块结构 ,如卷积块、残差块等基础构建模块。
- decoders.py:
- 用于实现模型的解码部分,在很多架构中负责将特征映射转换为期望的输出形式,比如图像分割中的分割结果输出。
- encoders.py
- 实现模型的编码部分,主要作用是对输入数据(如图像)进行特征提取和编码,将原始数据转换为更抽象的特征表示 。
- memory_attention.py:
- 涉及注意力机制相关代码,注意力机制用于让模型在处理数据时聚焦于重要部分,此文件可能结合记忆相关机制,提升模型对关键信息的捕捉和利用能力。
sam.py:- 和
Segment Anything Model(分割一切模型)相关,核心代码文件,用于整合模型整体架构、定义模型初始化及前向传播等关键逻辑。
- 和
- tiny_encoder.py:
- 轻量级或简化版的编码器实现,适用于对计算资源要求较高或需要快速处理的场景。
- transformer.py:
- 实现Transformer架构相关代码,Transformer基于自注意力机制,在自然语言处理和计算机视觉等领域广泛应用,此文件可能定义Transformer的层结构、多头注意力机制等内容 。
- utils.py:
- 通常存放各种工具函数,如数据预处理函数、模型训练和推理过程中的辅助函数等,用于提升代码复用性和开发效率。
1.sam-modules-init.py
# 模块功能:作为包的入口文件,定义对外暴露的核心类与接口
# 用途:其他模块/用户通过 `from 包名 import *` 时,仅能访问 `__all__` 中声明的对象
# 设计原则:明确公共接口边界,避免内部实现类被意外导入,提升模块的可维护性
# 从当前包的 model 子模块导入核心类 SAM
# SAM(Segment Anything Model):本包的核心分割模型类,负责初始化模型权重、前向推理等底层操作
from .model import SAM
# 从当前包的 predict 子模块导入预测器相关类
# Predictor:基础预测器类,提供通用的图像分割预测功能(如单点/多点提示输入)
# SAM2Predictor:SAM 模型的增强版预测器,支持更复杂的提示类型(如框提示、掩码提示)或优化推理流程
# SAM2VideoPredictor:视频场景专用预测器,针对视频连续帧分割优化(如时间一致性处理、跨帧提示传播)
from .predict import Predictor, SAM2Predictor, SAM2VideoPredictor
# 定义模块公共接口:当使用 `from 包名 import *` 时,仅导出以下对象
# 类型:元组(推荐)或列表,元组更符合“不可变接口”的设计意图
__all__ = ("SAM", "Predictor", "SAM2Predictor", "SAM2VideoPredictor")
2.sam-modules-blocks.py
- 2.1 DropPath:随机深度正则化模块
class DropPath(nn.Module):
"""
实现训练阶段的随机深度正则化(Stochastic Depth)
作用:在训练时以一定概率跳过残差路径,缓解深层网络过拟合
"""
def __init__(self, drop_prob=0.0, scale_by_keep=True):
"""
Args:
drop_prob (float): 路径丢弃概率(训练时生效,0.0表示禁用)
scale_by_keep (bool): 是否通过保留概率缩放输出(保持期望一致性)
"""
super().__init__()
self.drop_prob = drop_prob
self.scale_by_keep = scale_by_keep
def forward(self, x):
"""
前向传播逻辑:
1. 训练阶段:根据drop_prob随机丢弃路径
2. 推理阶段:直接返回输入(随机深度仅在训练时生效)
"""
if self.drop_prob == 0.0 or not self.training:
return x
keep_prob = 1 - self.drop_prob
# 生成伯努利分布随机数(保持维度一致)
random_tensor = x.new_empty((x.shape[0],) + (1,)*(x.ndim-1)).bernoulli_(keep_prob)
if self.scale_by_keep:
random_tensor.div_(keep_prob) # 缩放以保持期望一致
return x * random_tensor
- 2.2 MaskDownSampler:掩码下采样与嵌入模块
class MaskDownSampler(nn.Module):
"""
掩码下采样模块:
功能:将输入掩码(H,W)逐步下采样并嵌入到高维特征空间
应用场景:图像分割任务中处理低分辨率掩码输入
"""
def __init__(
self,
embed_dim=256, # 目标嵌入维度(输出通道数)
kernel_size=4, # 卷积核尺寸(用于下采样)
stride=4, # 卷积步长(决定下采样率)
padding=0, # 卷积填充
total_stride=16, # 总下采样率(需满足stride^num_layers = total_stride)
activation=nn.GELU, # 激活函数
):
"""
构建多级下采样路径:
1. 计算下采样层数(num_layers = log2(total_stride)/log2(stride))
2. 逐层使用stride²倍通道扩展的卷积层(模拟像素重组)
3. 最后通过1x1卷积映射到embed_dim
"""
super().__init__()
num_layers = int(math.log2(total_stride) // math.log2(stride))
assert stride**num_layers == total_stride, "总下采样率需为stride的幂次"
self.encoder = nn.Sequential()
mask_in_chans = 1 # 输入掩码通道数固定为1
for _ in range(num_layers):
# 通道数按stride²扩展(等效于将stride×stride像素合并为一个特征点)
mask_out_chans = mask_in_chans * (stride ** 2)
self.encoder.append(nn.Conv2d(mask_in_chans, mask_out_chans,
kernel_size, stride, padding))
self.encoder.append(LayerNorm2d(mask_out_chans)) # 空间维度归一化
self.encoder.append(activation())
mask_in_chans = mask_out_chans
# 最后映射到目标嵌入维度
self.encoder.append(nn.Conv2d(mask_out_chans, embed_dim, kernel_size=1))
def forward(self, x):
"""
Args:
x (Tensor): 输入掩码 (B, 1, H, W)
Returns:
(Tensor): 嵌入后的特征 (B, embed_dim, H/total_stride, W/total_stride)
"""
return self.encoder(x)
- 2.3 CXBlock:ConvNeXt风格卷积块
class CXBlock(nn.Module):
"""
ConvNeXt改进块:
结构:深度卷积 + 层归一化 + 逐点卷积(MLP) + 残差连接
设计特点:
- 深度卷积提取空间特征
- 层归一化替代批量归一化(提升训练稳定性)
- 逐点卷积增强非线性表达
"""
def __init__(
self,
dim, # 输入通道数
kernel_size=7, # 深度卷积核尺寸
padding=3, # 卷积填充(保持空间尺寸)
drop_path=0.0, # 随机深度概率
layer_scale_init=1e-6, # 层缩放初始化值(激活前特征缩放)
use_dwconv=True # 是否使用深度卷积(False为标准卷积)
):
super().__init__()
# 深度卷积(groups=dim为深度卷积,groups=1为标准卷积)
self.dwconv = nn.Conv2d(dim, dim, kernel_size, padding=padding,
groups=dim if use_dwconv else 1)
self.norm = LayerNorm2d(dim) # 对通道维度归一化
# 逐点卷积(使用线性层实现1x1卷积,兼容NCHW和NHWC格式)
self.pwconv1 = nn.Linear(dim, 4*dim) # 扩展层
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4*dim, dim) # 压缩层
# 层缩放(可选,提升模型表达能力)
self.gamma = nn.Parameter(layer_scale_init * torch.ones(dim)) if layer_scale_init > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0 else nn.Identity()
def forward(self, x):
"""
前向流程:
NCHW格式输入 -> 深度卷积 -> 层归一化 -> 转为NHWC -> 逐点卷积 -> 激活 -> 逐点卷积 -> 层缩放 -> 转回NCHW -> 残差连接
"""
input = x
x = self.dwconv(x) # 空间特征提取
x = self.norm(x) # 归一化
x = x.permute(0, 2, 3, 1) # NCHW -> NHWC(适配线性层)
x = self.pwconv1(x) # 扩展通道
x = self.act(x)
x = self.pwconv2(x) # 压缩通道
if self.gamma is not None:
x = self.gamma * x # 层缩放
x = x.permute(0, 3, 1, 2) # NHWC -> NCHW
return input + self.drop_path(x) # 残差连接
- 2.4
SAM2TwoWayAttentionBlock:双向注意力块(扩展版)
class SAM2TwoWayAttentionBlock(TwoWayAttentionBlock):
"""
扩展的双向注意力块:
功能:
1. 稀疏输入(查询)的自注意力
2. 稀疏->密集(查询->图像)的交叉注意力
3. 稀疏输入的MLP特征变换
4. 密集->稀疏(图像->查询)的交叉注意力(反向交互)
"""
def __init__(
self,
embedding_dim: int, # 嵌入维度(通道数)
num_heads: int, # 注意力头数
mlp_dim: int = 2048, # MLP隐藏层维度
activation: Type[nn.Module] = nn.ReLU, # MLP激活函数
attention_downsample_rate: int = 2, # 注意力计算时的下采样率
skip_first_layer_pe: bool = False # 是否跳过第一层位置编码(用于初始化)
):
super().__init__(embedding_dim, num_heads, mlp_dim, activation,
attention_downsample_rate, skip_first_layer_pe)
# 新增稀疏输入的MLP块(增强特征表达)
self.mlp = MLP(embedding_dim, mlp_dim, embedding_dim, num_layers=2, act=activation)
def forward(self, sparse, dense):
"""
Args:
sparse (Tensor): 稀疏输入(查询) (B, N, C)
dense (Tensor): 密集输入(图像特征) (B, C, H, W)
Returns:
(Tensor, Tensor): 更新后的稀疏和密集特征
"""
# 1. 稀疏输入自注意力
sparse = super().self_attn(sparse)
sparse = self.norm1(sparse)
# 2. 稀疏->密集交叉注意力(查询引导图像特征更新)
dense = super().cross_attn_token_to_image(sparse, dense)
dense = self.norm2(dense)
# 3. 稀疏输入MLP变换
sparse = self.mlp(sparse)
sparse = self.norm3(sparse)
# 4. 密集->稀疏交叉注意力(图像特征反馈查询)
sparse = super().cross_attn_image_to_token(dense, sparse)
sparse = self.norm4(sparse)
return sparse, dense
-2.5 RoPEAttention:旋转位置编码注意力
class RoPEAttention(Attention):
"""
带旋转位置编码(RoPE)的注意力模块:
优势:通过复数旋转编码位置信息,避免绝对位置编码的泛化性问题
"""
def __init__(
self,
*args,
rope_theta=10000.0, # 位置编码温度参数
rope_k_repeat=False, # 是否重复查询位置编码以匹配键长度(用于跨注意力)
feat_sizes=(32, 32), # 特征图尺寸(w, h),用于预计算频率
**kwargs,
):
super().__init__(*args, **kwargs)
self.rope_theta = rope_theta
self.rope_k_repeat = rope_k_repeat
# 预计算频率矩阵(轴向位置编码)
self.freqs_cis = compute_axial_cis(dim=self.internal_dim//self.num_heads,
theta=rope_theta, end_x=feat_sizes[0], end_y=feat_sizes[1])
def forward(self, q: Tensor, k: Tensor, v: Tensor, num_k_exclude_rope=0) -> Tensor:
"""
前向传播逻辑:
1. 投影查询/键/值
2. 分离注意力头
3. 应用旋转位置编码(仅对键和查询有效)
4. 计算缩放点积注意力
"""
q = self.q_proj(q)
k = self.k_proj(k)
v = self.v_proj(v)
q = self._separate_heads(q, self.num_heads) # (B, N, H, C/h) -> (B, H, N, C/h)
k = self._separate_heads(k, self.num_heads)
v = self._separate_heads(v, self.num_heads)
# 动态调整频率矩阵尺寸(适应不同分辨率输入)
h, w = int(math.sqrt(q.shape[2])), int(math.sqrt(q.shape[3]))
if self.freqs_cis.shape[-2:] != (h, w):
self.freqs_cis = compute_axial_cis(dim=self.internal_dim//self.num_heads,
theta=self.rope_theta, end_x=w, end_y=h)
# 应用旋转编码(仅对有效键部分编码)
num_k_rope = k.size(2) - num_k_exclude_rope
q, k_rope = apply_rotary_enc(q, k[:, :, :num_k_rope],
freqs_cis=self.freqs_cis, repeat_freqs_k=self.rope_k_repeat)
k = torch.cat([k_rope, k[:, :, num_k_rope:]], dim=2) # 拼接未编码的键(如CLS token)
# 标准注意力计算
attn = (q @ k.transpose(-2, -1)) / math.sqrt(self.internal_dim // self.num_heads)
attn = torch.softmax(attn, dim=-1)
out = attn @ v
return self._recombine_heads(out)
- 2.6
PositionEmbeddingSine:正弦位置编码
class PositionEmbeddingSine(nn.Module):
"""
正弦位置编码:
原理:通过不同频率的正弦/余弦函数编码绝对位置
优势:可泛化至任意分辨率,位置关系具有周期性
"""
def __init__(
self,
num_pos_feats, # 位置特征数(总维度=2*num_pos_feats)
temperature=10000, # 控制频率的温度参数
normalize=True, # 是否归一化位置到[0, 2π]
scale=None # 归一化后的缩放因子(默认2π)
):
super().__init__()
self.num_pos_feats = num_pos_feats // 2 # 每个维度(x/y)的特征数
self.temperature = temperature
self.normalize = normalize
self.scale = scale or (2 * math.pi) # 标准正弦曲线周期
def forward(self, x: torch.Tensor):
"""
Args:
x (Tensor): 输入特征图 (B, C, H, W)
Returns:
(Tensor): 位置编码 (B, 2*num_pos_feats, H, W)
"""
h, w = x.shape[-2], x.shape[-1]
# 生成网格坐标(归一化到[0,1])
y_grid = torch.arange(h, device=x.device).view(1, h, 1).repeat(1, 1, w) / h
x_grid = torch.arange(w, device=x.device).view(1, 1, w).repeat(1, h, 1) / w
if self.normalize:
# 归一化到[0, scale](默认0~2π)
y_grid = y_grid * self.scale
x_grid = x_grid * self.scale
# 计算不同频率的正弦/余弦值
dim_t = torch.arange(self.num_pos_feats, device=x.device, dtype=torch.float32)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats) # 频率数组
# 位置编码公式:pos = [sin(x/λ), cos(x/λ), sin(y/λ), cos(y/λ)]
pos_x = x_grid[:, :, :, None] / dim_t # (H, W, C)
pos_y = y_grid[:, :, :, None] / dim_t
pos_x = torch.cat([pos_x[..., 0::2].sin(), pos_x[..., 1::2].cos()], dim=-1)
pos_y = torch.cat([pos_y[..., 0::2].sin(), pos_y[..., 1::2].cos()], dim=-1)
pos = torch.cat([pos_y, pos_x], dim=-1).permute(0, 3, 1, 2) # 转为NCHW格式
return pos
- 关键设计模式注释总结:
-
- 残差连接:几乎
所有块(CXBlock、Block、MultiScaleBlock)都使用残差连接,缓解深层网络梯度消失问题
- 残差连接:几乎
-
- 归一化层:大量使用
LayerNorm2d(空间维度归一化)而非BatchNorm,提升训练稳定性和对小批量数据的鲁棒性
- 归一化层:大量使用
-
- 分块处理:Window Partition/Unpartition实现局部窗口注意力,降低计算复杂度(如Block中的window_size参数)
-
- 位置编码:支持
正弦编码、随机编码、旋转编码(RoPE)等多种方式,适应不同任务需求
- 位置编码:支持
-
- 多尺度机制:MultiScaleBlock通过窗口划分和查询池化,实现对不同尺度特征的高效建模
-

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)