【Java数据结构与算法】第10-14章
/测试一把中序线索二叉树的功能//二叉树,后面我们要递归创建, 现在简单处理使用手动创建//测试中序线索化//测试: 以10号节点测试System.out.println("10号结点的前驱结点是 =" + leftNode);//3System.out.println("10号结点的后继结点是=" + rightNode);//1//当线索化二叉树后,不能再使用原来的遍历方法。
·
第10章 树结构的基础部分
10.1 二叉树
10.1.1 为什么需要树这种数据结构
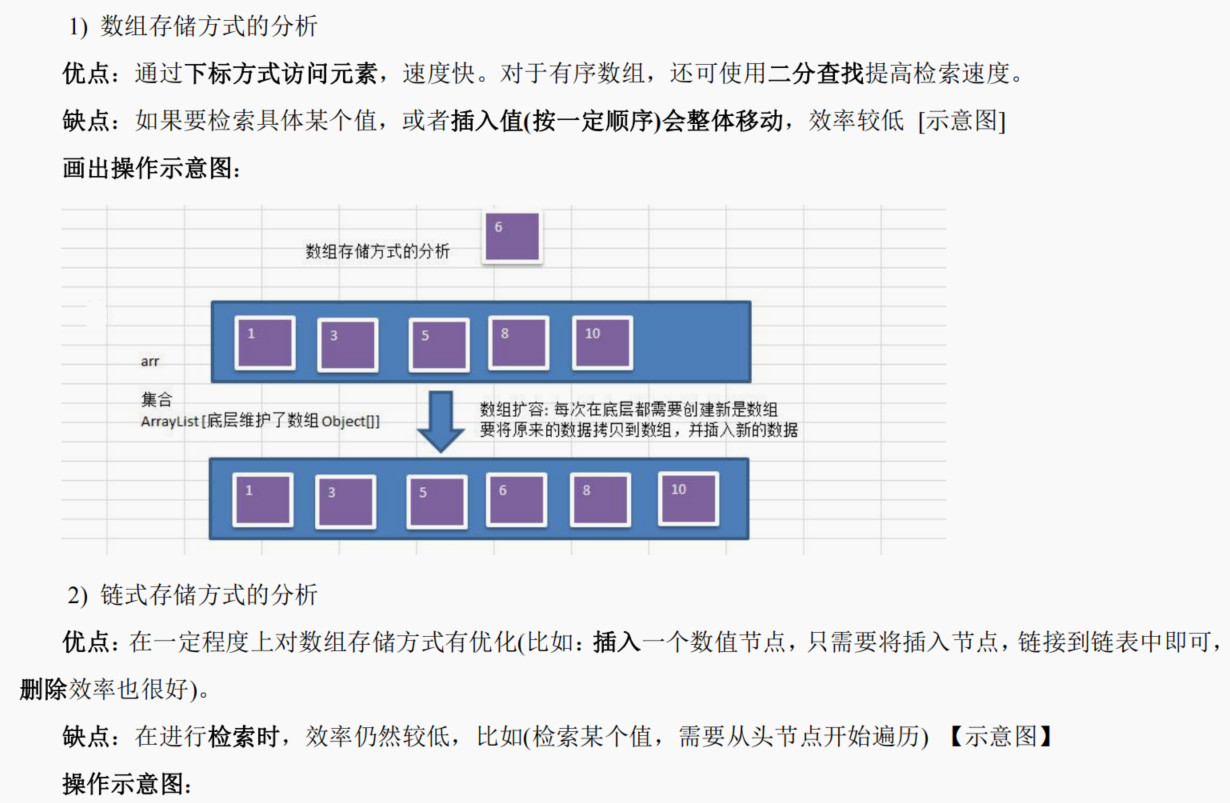
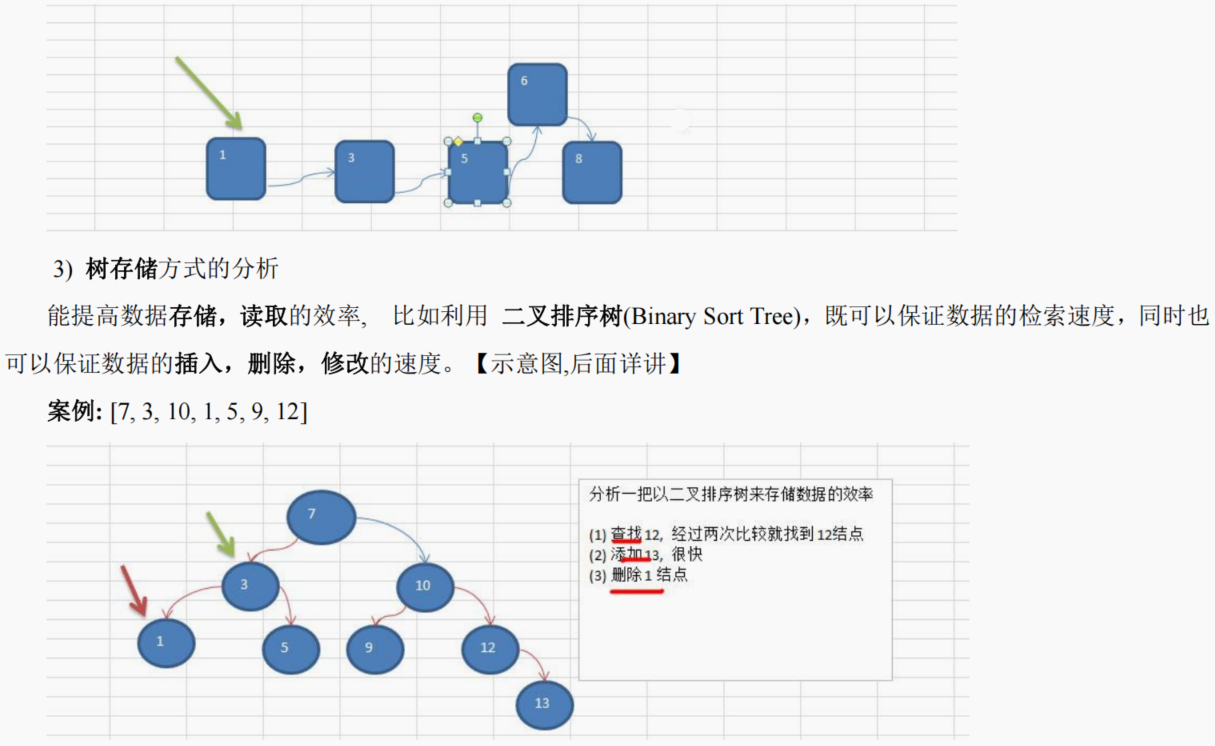
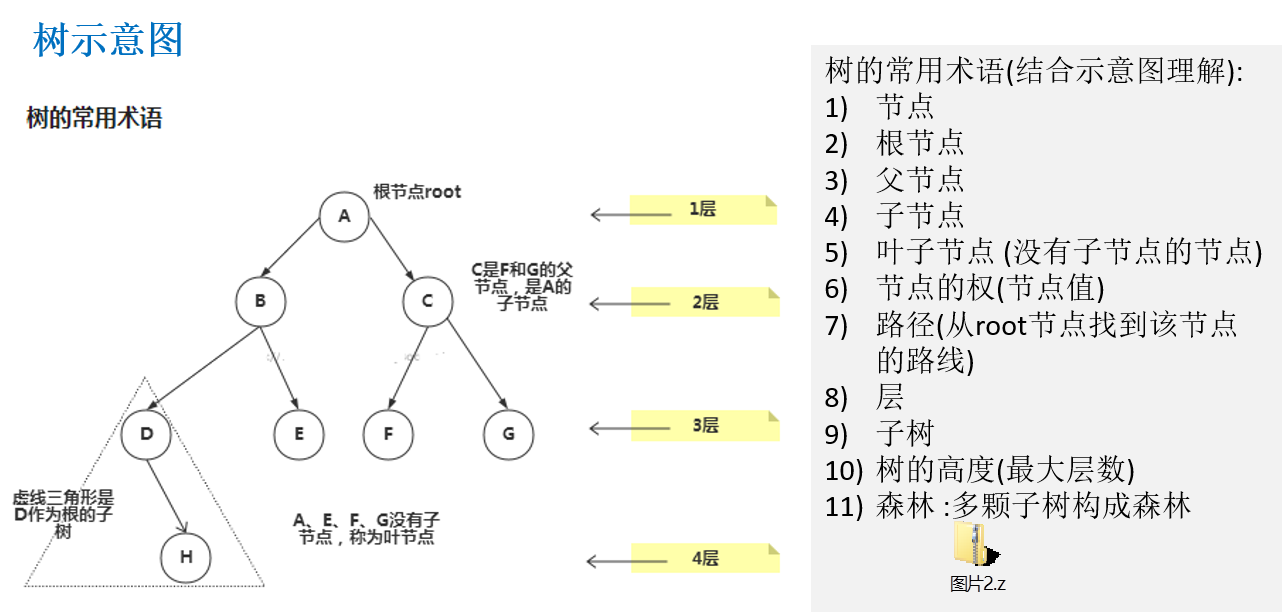
10.1.2 树示意图
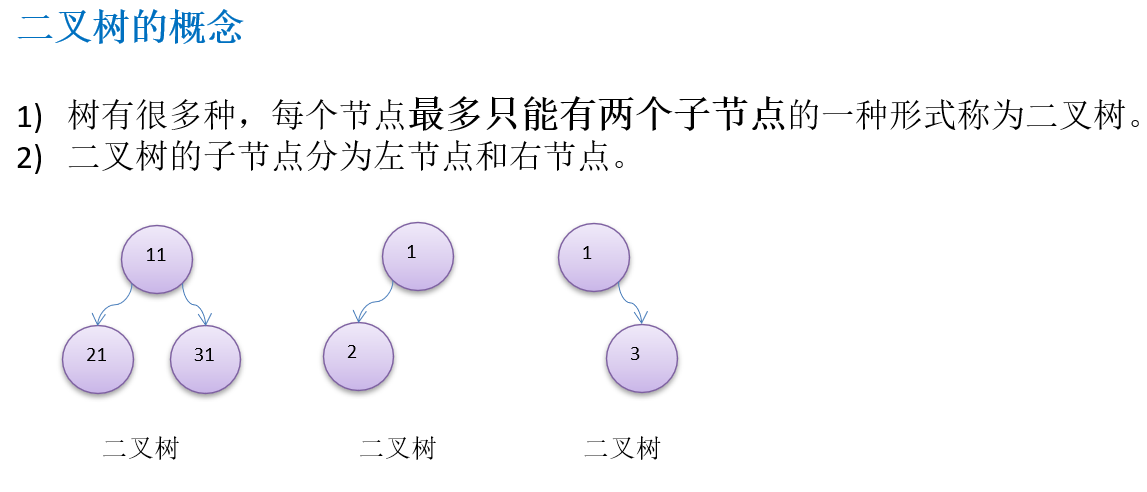
10.1.3 二叉树的概念
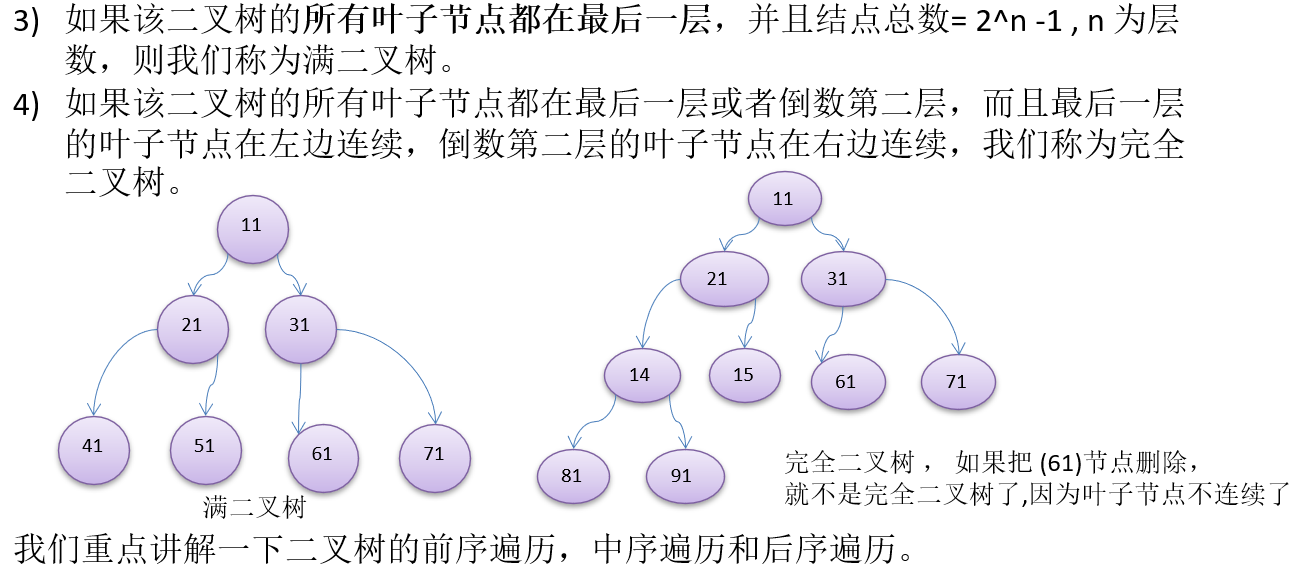
10.1.4 二叉树遍历的说明

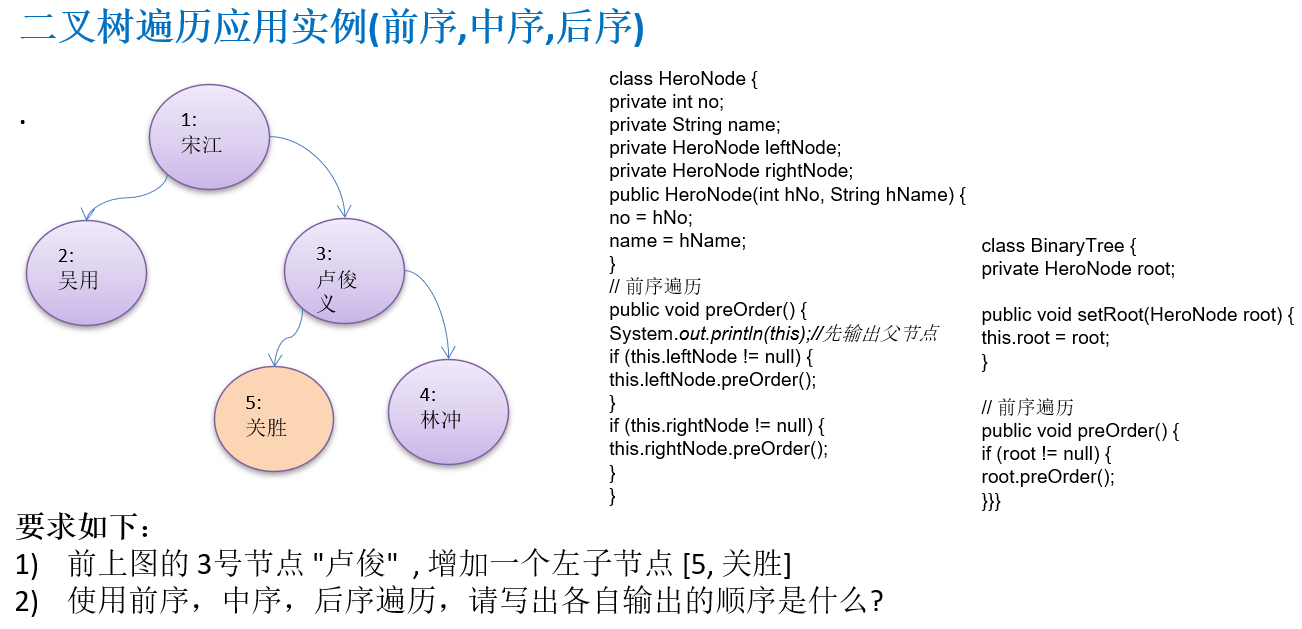
10.1.5 二叉树遍历应用实例(前序,中序,后序)

10.1.6 二叉树-查找指定节点

思路图解

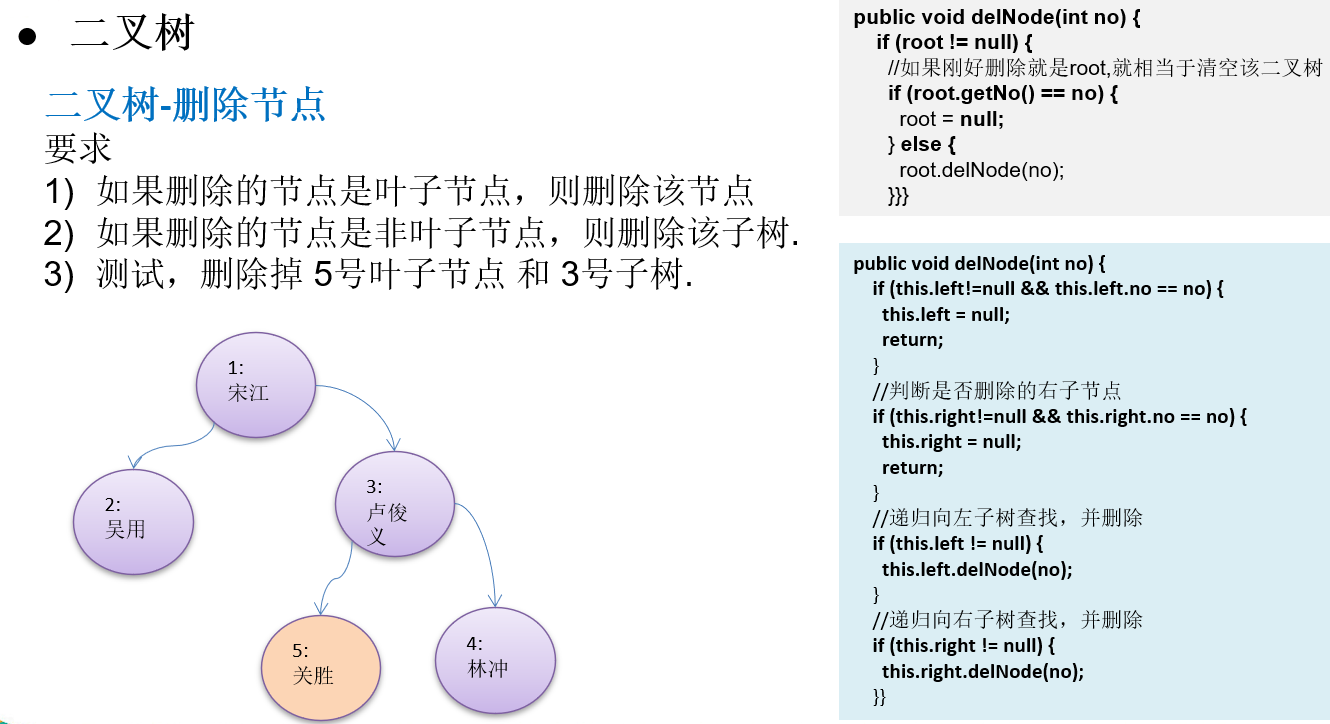
10.1.7 二叉树-删除节点
package com.atguigu.tree;
public class BinaryTreeDemo {
public static void main(String[] args) {
//先需要创建一颗二叉树
BinaryTree binaryTree = new BinaryTree();
//创建需要的结点
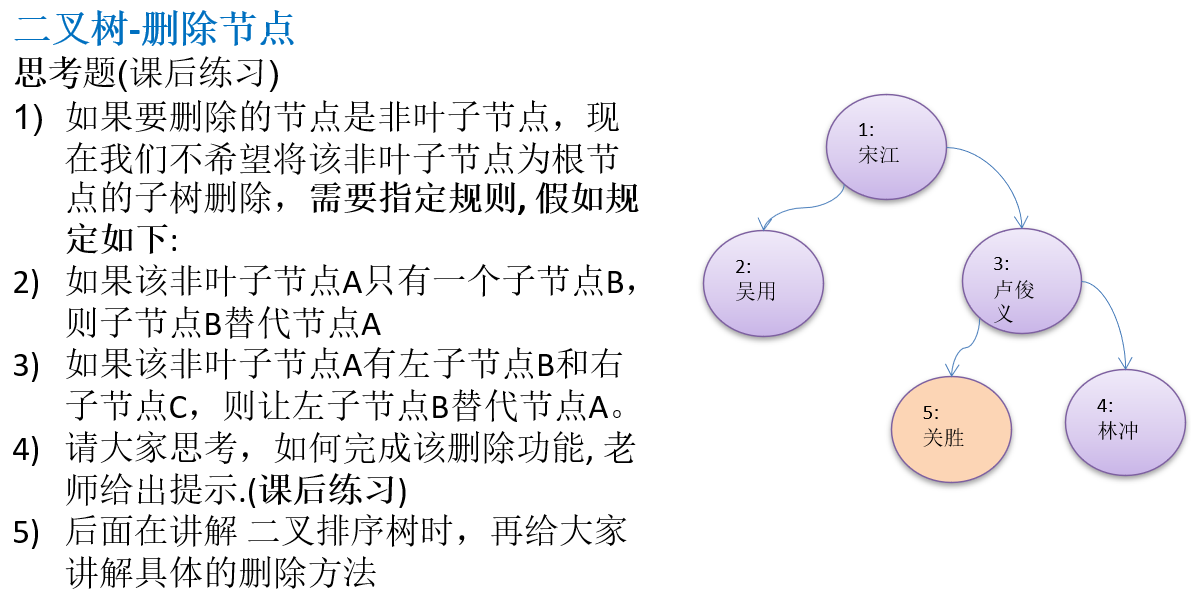
HeroNode root = new HeroNode(1, "宋江");
HeroNode node2 = new HeroNode(2, "吴用");
HeroNode node3 = new HeroNode(3, "卢俊义");
HeroNode node4 = new HeroNode(4, "林冲");
HeroNode node5 = new HeroNode(5, "关胜");
//说明,我们先手动创建该二叉树,后面我们学习递归的方式创建二叉树
root.setLeft(node2);
root.setRight(node3);
node3.setRight(node4);
node3.setLeft(node5);
binaryTree.setRoot(root);
//测试
// System.out.println("前序遍历"); // 1,2,3,5,4
// binaryTree.preOrder();
//测试
// System.out.println("中序遍历");
// binaryTree.infixOrder(); // 2,1,5,3,4
//
// System.out.println("后序遍历");
// binaryTree.postOrder(); // 2,5,4,3,1
//前序遍历
//前序遍历的次数 :4
// System.out.println("前序遍历方式~~~");
// HeroNode resNode = binaryTree.preOrderSearch(5);
// if (resNode != null) {
// System.out.printf("找到了,信息为 no=%d name=%s", resNode.getNo(), resNode.getName());
// } else {
// System.out.printf("没有找到 no = %d 的英雄", 5);
// }
//中序遍历查找
//中序遍历3次
// System.out.println("中序遍历方式~~~");
// HeroNode resNode = binaryTree.infixOrderSearch(5);
// if (resNode != null) {
// System.out.printf("找到了,信息为 no=%d name=%s", resNode.getNo(), resNode.getName());
// } else {
// System.out.printf("没有找到 no = %d 的英雄", 5);
// }
//后序遍历查找
//后序遍历查找的次数 2次
// System.out.println("后序遍历方式~~~");
// HeroNode resNode = binaryTree.postOrderSearch(5);
// if (resNode != null) {
// System.out.printf("找到了,信息为 no=%d name=%s", resNode.getNo(), resNode.getName());
// } else {
// System.out.printf("没有找到 no = %d 的英雄", 5);
// }
//测试一把删除结点
System.out.println("删除前,前序遍历");
binaryTree.preOrder(); // 1,2,3,5,4
binaryTree.delNode(5);
//binaryTree.delNode(3);
System.out.println("删除后,前序遍历");
binaryTree.preOrder(); // 1,2,3,4
}
}
//定义BinaryTree 二叉树
class BinaryTree {
private HeroNode root;
public void setRoot(HeroNode root) {
this.root = root;
}
//删除结点
public void delNode(int no) {
if(root != null) {
//如果只有一个root结点, 这里立即判断root是不是就是要删除结点
if(root.getNo() == no) {
root = null;
} else {
//递归删除
root.delNode(no);
}
}else{
System.out.println("空树,不能删除~");
}
}
//前序遍历
public void preOrder() {
if(this.root != null) {
this.root.preOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
//中序遍历
public void infixOrder() {
if(this.root != null) {
this.root.infixOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
//后序遍历
public void postOrder() {
if(this.root != null) {
this.root.postOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
//前序遍历
public HeroNode preOrderSearch(int no) {
if(root != null) {
return root.preOrderSearch(no);
} else {
return null;
}
}
//中序遍历
public HeroNode infixOrderSearch(int no) {
if(root != null) {
return root.infixOrderSearch(no);
}else {
return null;
}
}
//后序遍历
public HeroNode postOrderSearch(int no) {
if(root != null) {
return this.root.postOrderSearch(no);
}else {
return null;
}
}
}
//先创建HeroNode 结点
class HeroNode {
private int no;
private String name;
private HeroNode left; //默认null
private HeroNode right; //默认null
public HeroNode(int no, String name) {
this.no = no;
this.name = name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode getLeft() {
return left;
}
public void setLeft(HeroNode left) {
this.left = left;
}
public HeroNode getRight() {
return right;
}
public void setRight(HeroNode right) {
this.right = right;
}
@Override
public String toString() {
return "HeroNode [no=" + no + ", name=" + name + "]";
}
//递归删除结点
//1.如果删除的节点是叶子节点,则删除该节点
//2.如果删除的节点是非叶子节点,则删除该子树
public void delNode(int no) {
//思路
/*
* 1. 因为我们的二叉树是单向的,所以我们是判断当前结点的子结点是否需要删除结点,而不能去判断当前这个结点是不是需要删除结点.
2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将this.left = null; 并且就返回(结束递归删除)
3. 如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将this.right= null ;并且就返回(结束递归删除)
4. 如果第2和第3步没有删除结点,那么我们就需要向左子树进行递归删除
5. 如果第4步也没有删除结点,则应当向右子树进行递归删除.
*/
//2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将this.left = null; 并且就返回(结束递归删除)
if(this.left != null && this.left.no == no) {
this.left = null;
return;
}
//3.如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将this.right= null ;并且就返回(结束递归删除)
if(this.right != null && this.right.no == no) {
this.right = null;
return;
}
//4.我们就需要向左子树进行递归删除
if(this.left != null) {
this.left.delNode(no);
}
//5.则应当向右子树进行递归删除
if(this.right != null) {
this.right.delNode(no);
}
}
//编写前序遍历的方法
public void preOrder() {
System.out.println(this); //先输出父结点
//递归向左子树前序遍历
if(this.left != null) {
this.left.preOrder();
}
//递归向右子树前序遍历
if(this.right != null) {
this.right.preOrder();
}
}
//中序遍历
public void infixOrder() {
//递归向左子树中序遍历
if(this.left != null) {
this.left.infixOrder();
}
//输出父结点
System.out.println(this);
//递归向右子树中序遍历
if(this.right != null) {
this.right.infixOrder();
}
}
//后序遍历
public void postOrder() {
if(this.left != null) {
this.left.postOrder();
}
if(this.right != null) {
this.right.postOrder();
}
System.out.println(this);
}
//前序遍历查找
/**
*
* @param no 查找no
* @return 如果找到就返回该Node ,如果没有找到返回 null
*/
public HeroNode preOrderSearch(int no) {
System.out.println("进入前序遍历");
//比较当前结点是不是
if(this.no == no) {
return this;
}
//1.则判断当前结点的左子节点是否为空,如果不为空,则递归前序查找
//2.如果左递归前序查找,找到结点,则返回
HeroNode resNode = null;
if(this.left != null) {
resNode = this.left.preOrderSearch(no);
}
if(resNode != null) {//说明我们左子树找到
return resNode;
}
//1.左递归前序查找,找到结点,则返回,否继续判断,
//2.当前的结点的右子节点是否为空,如果不空,则继续向右递归前序查找
if(this.right != null) {
resNode = this.right.preOrderSearch(no);
}
return resNode;
}
//中序遍历查找
public HeroNode infixOrderSearch(int no) {
//判断当前结点的左子节点是否为空,如果不为空,则递归中序查找
HeroNode resNode = null;
if(this.left != null) {
resNode = this.left.infixOrderSearch(no);
}
if(resNode != null) {
return resNode;
}
System.out.println("进入中序查找");
//如果找到,则返回,如果没有找到,就和当前结点比较,如果是则返回当前结点
if(this.no == no) {
return this;
}
//否则继续进行右递归的中序查找
if(this.right != null) {
resNode = this.right.infixOrderSearch(no);
}
return resNode;
}
//后序遍历查找
public HeroNode postOrderSearch(int no) {
//判断当前结点的左子节点是否为空,如果不为空,则递归后序查找
HeroNode resNode = null;
if(this.left != null) {
resNode = this.left.postOrderSearch(no);
}
if(resNode != null) {//说明在左子树找到
return resNode;
}
//如果左子树没有找到,则向右子树递归进行后序遍历查找
if(this.right != null) {
resNode = this.right.postOrderSearch(no);
}
if(resNode != null) {
return resNode;
}
System.out.println("进入后序查找");
//如果左右子树都没有找到,就比较当前结点是不是
if(this.no == no) {
return this;
}
return resNode;
}
}思路图解
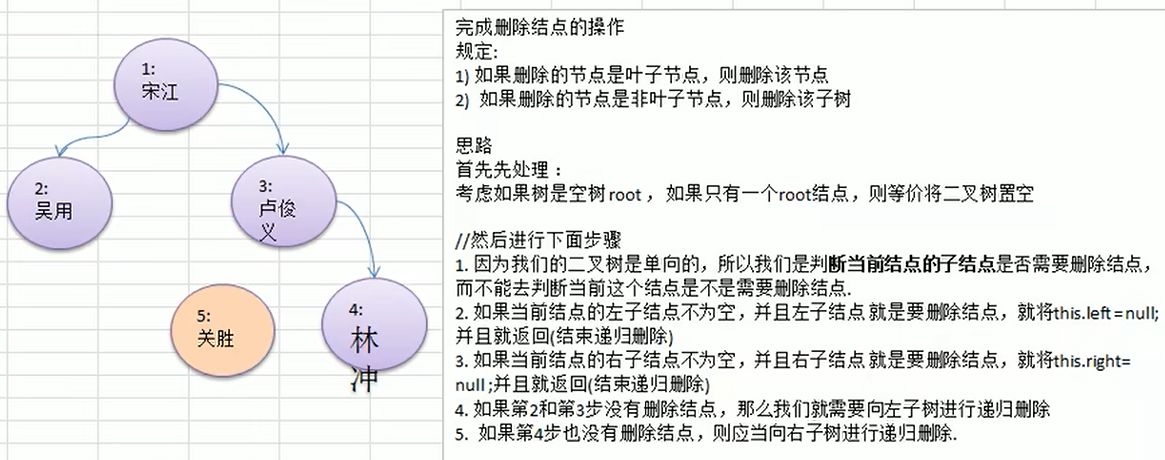
10.1.8 二叉树-删除节点(课后练习)
10.2 顺序存储二叉树
10.2.1 顺序存储二叉树的概念
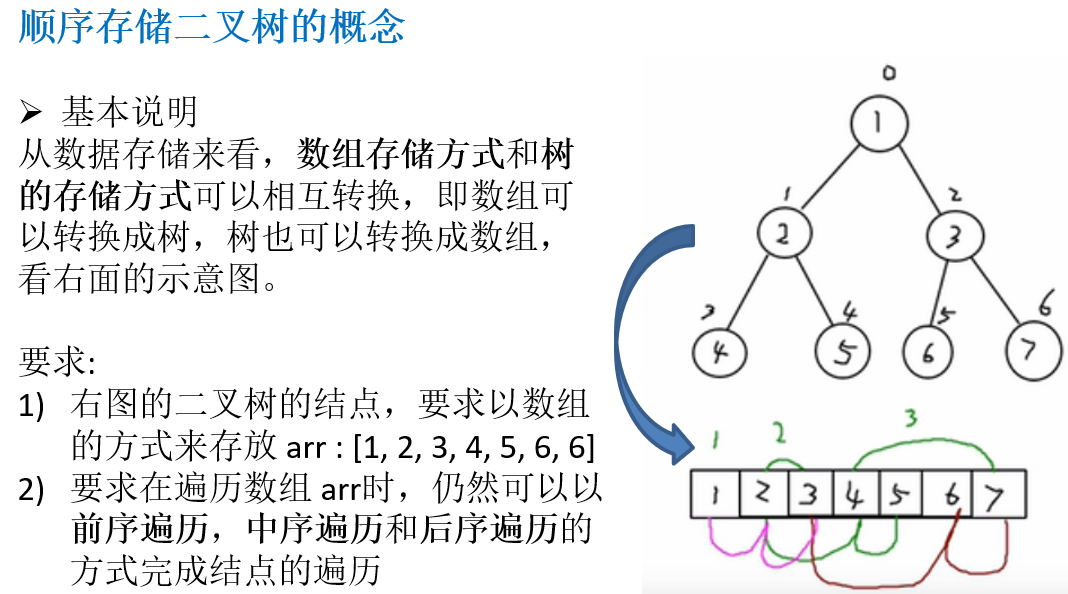

10.2.2 顺序存储二叉树遍历

package com.atguigu.tree;
public class ArrBinaryTreeDemo {
public static void main(String[] args) {
int[] arr = { 1, 2, 3, 4, 5, 6, 7 };
//创建一个 ArrBinaryTree
ArrBinaryTree arrBinaryTree = new ArrBinaryTree(arr);
arrBinaryTree.preOrder(); // 1,2,4,5,3,6,7
}
}
//编写一个ArrayBinaryTree, 实现顺序存储二叉树遍历
class ArrBinaryTree {
private int[] arr;//存储数据结点的数组
public ArrBinaryTree(int[] arr) {
this.arr = arr;
}
//重载preOrder
public void preOrder() {
this.preOrder(0);
}
//编写一个方法,完成顺序存储二叉树的前序遍历
/**
*
* @param index 数组的下标
*/
public void preOrder(int index) {
//如果数组为空,或者 arr.length = 0
if(arr == null || arr.length == 0) {
System.out.println("数组为空,不能按照二叉树的前序遍历");
}
//输出当前这个元素
System.out.println(arr[index]);
//向左递归遍历
if((index * 2 + 1) < arr.length) {
preOrder(2 * index + 1 );
}
//向右递归遍历
if((index * 2 + 2) < arr.length) {
preOrder(2 * index + 2);
}
}
}
10.2.3 顺序存储二叉树应用实例

10.3 线索化二叉树
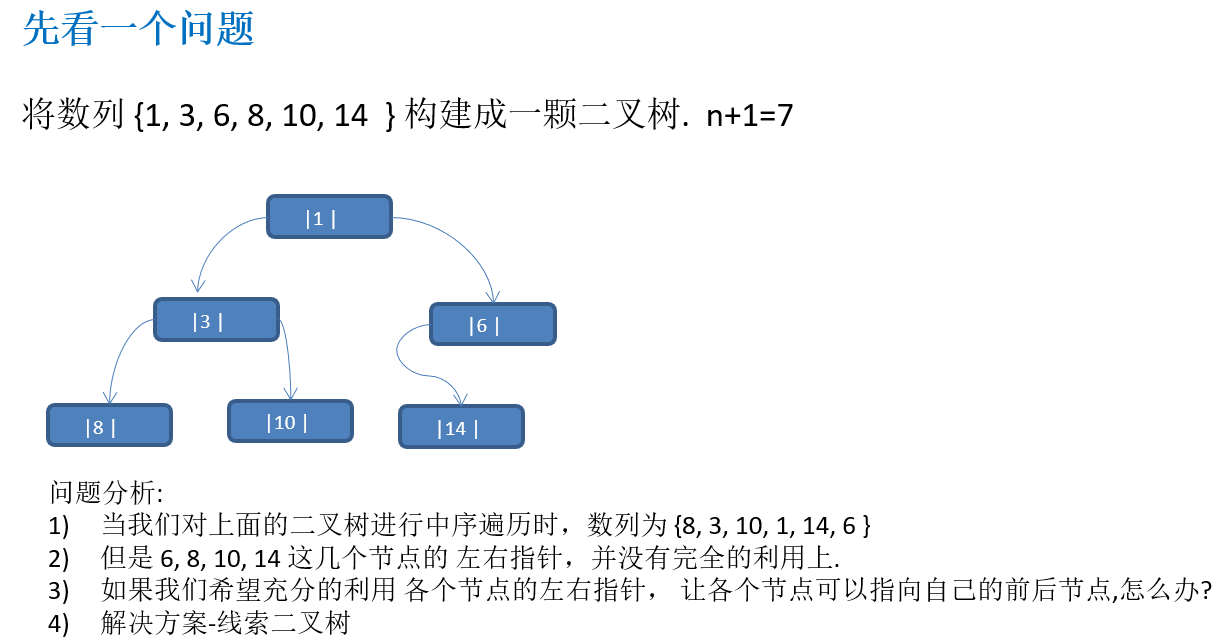
10.3.1 先看一个问题
10.3.2 线索二叉树基本介绍

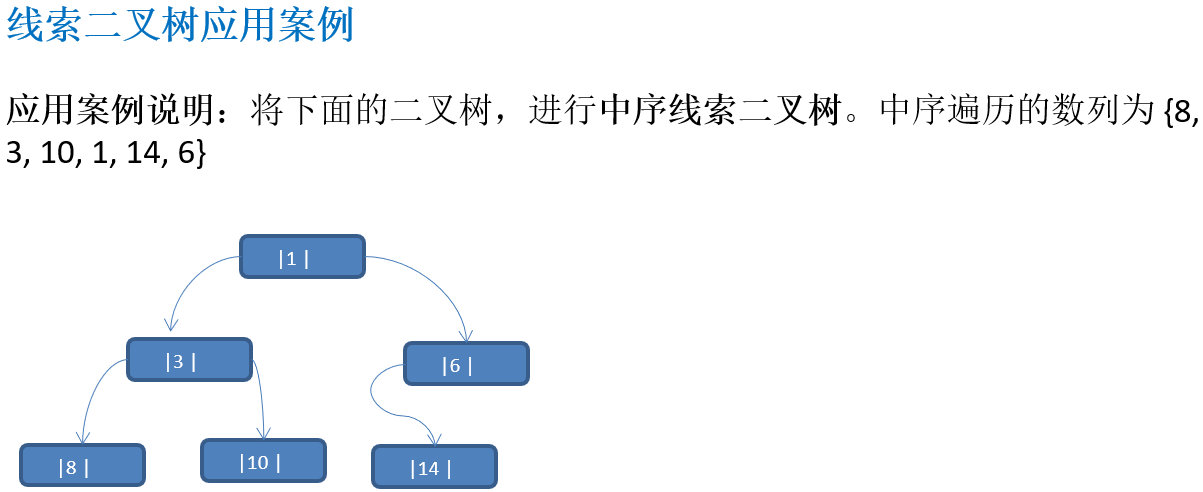
10.3.3 线索二叉树应用案例
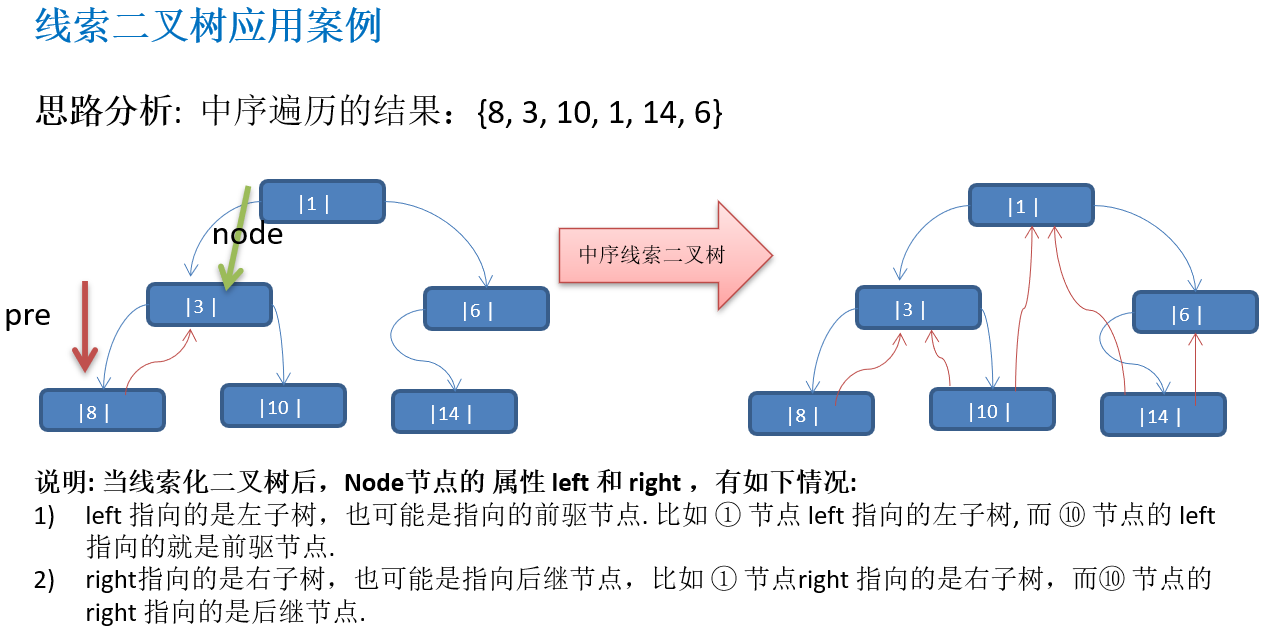

10.3.4 遍历线索化二叉树

package com.atguigu.tree.threadedbinarytree;
import java.util.concurrent.SynchronousQueue;
public class ThreadedBinaryTreeDemo {
public static void main(String[] args) {
//测试一把中序线索二叉树的功能
HeroNode root = new HeroNode(1, "tom");
HeroNode node2 = new HeroNode(3, "jack");
HeroNode node3 = new HeroNode(6, "smith");
HeroNode node4 = new HeroNode(8, "mary");
HeroNode node5 = new HeroNode(10, "king");
HeroNode node6 = new HeroNode(14, "dim");
//二叉树,后面我们要递归创建, 现在简单处理使用手动创建
root.setLeft(node2);
root.setRight(node3);
node2.setLeft(node4);
node2.setRight(node5);
node3.setLeft(node6);
//测试中序线索化
ThreadedBinaryTree threadedBinaryTree = new ThreadedBinaryTree();
threadedBinaryTree.setRoot(root);
threadedBinaryTree.threadedNodes();
//测试: 以10号节点测试
HeroNode leftNode = node5.getLeft();
HeroNode rightNode = node5.getRight();
System.out.println("10号结点的前驱结点是 =" + leftNode); //3
System.out.println("10号结点的后继结点是=" + rightNode); //1
//当线索化二叉树后,不能再使用原来的遍历方法
//threadedBinaryTree.infixOrder();
System.out.println("使用线索化的方式遍历 线索化二叉树");
threadedBinaryTree.threadedList(); // 8, 3, 10, 1, 14, 6
}
}
//定义ThreadedBinaryTree 实现了线索化功能的二叉树
class ThreadedBinaryTree {
private HeroNode root;
//为了实现线索化,需要创建一个指向当前结点的前驱结点的指针
//在递归进行线索化时,pre 总是保留前一个结点
private HeroNode pre = null;
public void setRoot(HeroNode root) {
this.root = root;
}
//重载一把threadedNodes方法
public void threadedNodes() {
this.threadedNodes(root);
}
//遍历线索化二叉树的方法
public void threadedList() {
//定义一个变量,存储当前遍历的结点,从root开始
HeroNode node = root;
while(node != null) {
//循环的找到leftType == 1的结点,第一个找到就是8结点
//后面随着遍历而变化,因为当leftType==1时,说明该结点是按照线索化
//处理后的有效结点
while(node.getLeftType() == 0) {
node = node.getLeft();
}
//打印当前这个结点
System.out.println(node);
//如果当前结点的右指针指向的是后继结点,就一直输出
while(node.getRightType() == 1) {
//获取到当前结点的后继结点
node = node.getRight();
System.out.println(node);
}
//替换这个遍历的结点
node = node.getRight();
}
}
//编写对二叉树进行中序线索化的方法
/**
*
* @param node 就是当前需要线索化的结点
*/
public void threadedNodes(HeroNode node) {
//如果node==null, 不能线索化
if(node == null) {
return;
}
//(一)先线索化左子树
threadedNodes(node.getLeft());
//(二)线索化当前结点[有难度]
//处理当前结点的前驱结点
//以8结点来理解
//8结点的.left = null , 8结点的.leftType = 1
if(node.getLeft() == null) {
//让当前结点的左指针指向前驱结点
node.setLeft(pre);
//修改当前结点的左指针的类型,指向前驱结点
node.setLeftType(1);
}
//处理后继结点
if (pre != null && pre.getRight() == null) {
//让前驱结点的右指针指向当前结点
pre.setRight(node);
//修改前驱结点的右指针类型
pre.setRightType(1);
}
//!!! 每处理一个结点后,让当前结点是下一个结点的前驱结点
pre = node;
//(三)在线索化右子树
threadedNodes(node.getRight());
}
//删除结点
public void delNode(int no) {
if(root != null) {
//如果只有一个root结点, 这里立即判断root是不是就是要删除结点
if(root.getNo() == no) {
root = null;
} else {
//递归删除
root.delNode(no);
}
}else{
System.out.println("空树,不能删除~");
}
}
//前序遍历
public void preOrder() {
if(this.root != null) {
this.root.preOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
//中序遍历
public void infixOrder() {
if(this.root != null) {
this.root.infixOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
//后序遍历
public void postOrder() {
if(this.root != null) {
this.root.postOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
//前序遍历
public HeroNode preOrderSearch(int no) {
if(root != null) {
return root.preOrderSearch(no);
} else {
return null;
}
}
//中序遍历
public HeroNode infixOrderSearch(int no) {
if(root != null) {
return root.infixOrderSearch(no);
}else {
return null;
}
}
//后序遍历
public HeroNode postOrderSearch(int no) {
if(root != null) {
return this.root.postOrderSearch(no);
}else {
return null;
}
}
}
//先创建HeroNode 结点
class HeroNode {
private int no;
private String name;
private HeroNode left; //默认null
private HeroNode right; //默认null
//说明
//1. 如果leftType == 0 表示指向的是左子树, 如果 1 则表示指向前驱结点
//2. 如果rightType == 0 表示指向是右子树, 如果 1表示指向后继结点
private int leftType;
private int rightType;
public int getLeftType() {
return leftType;
}
public void setLeftType(int leftType) {
this.leftType = leftType;
}
public int getRightType() {
return rightType;
}
public void setRightType(int rightType) {
this.rightType = rightType;
}
public HeroNode(int no, String name) {
this.no = no;
this.name = name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode getLeft() {
return left;
}
public void setLeft(HeroNode left) {
this.left = left;
}
public HeroNode getRight() {
return right;
}
public void setRight(HeroNode right) {
this.right = right;
}
@Override
public String toString() {
return "HeroNode [no=" + no + ", name=" + name + "]";
}
//递归删除结点
//1.如果删除的节点是叶子节点,则删除该节点
//2.如果删除的节点是非叶子节点,则删除该子树
public void delNode(int no) {
//思路
/*
* 1. 因为我们的二叉树是单向的,所以我们是判断当前结点的子结点是否需要删除结点,而不能去判断当前这个结点是不是需要删除结点.
2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将this.left = null; 并且就返回(结束递归删除)
3. 如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将this.right= null ;并且就返回(结束递归删除)
4. 如果第2和第3步没有删除结点,那么我们就需要向左子树进行递归删除
5. 如果第4步也没有删除结点,则应当向右子树进行递归删除.
*/
//2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将this.left = null; 并且就返回(结束递归删除)
if(this.left != null && this.left.no == no) {
this.left = null;
return;
}
//3.如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将this.right= null ;并且就返回(结束递归删除)
if(this.right != null && this.right.no == no) {
this.right = null;
return;
}
//4.我们就需要向左子树进行递归删除
if(this.left != null) {
this.left.delNode(no);
}
//5.则应当向右子树进行递归删除
if(this.right != null) {
this.right.delNode(no);
}
}
//编写前序遍历的方法
public void preOrder() {
System.out.println(this); //先输出父结点
//递归向左子树前序遍历
if(this.left != null) {
this.left.preOrder();
}
//递归向右子树前序遍历
if(this.right != null) {
this.right.preOrder();
}
}
//中序遍历
public void infixOrder() {
//递归向左子树中序遍历
if(this.left != null) {
this.left.infixOrder();
}
//输出父结点
System.out.println(this);
//递归向右子树中序遍历
if(this.right != null) {
this.right.infixOrder();
}
}
//后序遍历
public void postOrder() {
if(this.left != null) {
this.left.postOrder();
}
if(this.right != null) {
this.right.postOrder();
}
System.out.println(this);
}
//前序遍历查找
/**
*
* @param no 查找no
* @return 如果找到就返回该Node ,如果没有找到返回 null
*/
public HeroNode preOrderSearch(int no) {
System.out.println("进入前序遍历");
//比较当前结点是不是
if(this.no == no) {
return this;
}
//1.则判断当前结点的左子节点是否为空,如果不为空,则递归前序查找
//2.如果左递归前序查找,找到结点,则返回
HeroNode resNode = null;
if(this.left != null) {
resNode = this.left.preOrderSearch(no);
}
if(resNode != null) {//说明我们左子树找到
return resNode;
}
//1.左递归前序查找,找到结点,则返回,否继续判断,
//2.当前的结点的右子节点是否为空,如果不空,则继续向右递归前序查找
if(this.right != null) {
resNode = this.right.preOrderSearch(no);
}
return resNode;
}
//中序遍历查找
public HeroNode infixOrderSearch(int no) {
//判断当前结点的左子节点是否为空,如果不为空,则递归中序查找
HeroNode resNode = null;
if(this.left != null) {
resNode = this.left.infixOrderSearch(no);
}
if(resNode != null) {
return resNode;
}
System.out.println("进入中序查找");
//如果找到,则返回,如果没有找到,就和当前结点比较,如果是则返回当前结点
if(this.no == no) {
return this;
}
//否则继续进行右递归的中序查找
if(this.right != null) {
resNode = this.right.infixOrderSearch(no);
}
return resNode;
}
//后序遍历查找
public HeroNode postOrderSearch(int no) {
//判断当前结点的左子节点是否为空,如果不为空,则递归后序查找
HeroNode resNode = null;
if(this.left != null) {
resNode = this.left.postOrderSearch(no);
}
if(resNode != null) {//说明在左子树找到
return resNode;
}
//如果左子树没有找到,则向右子树递归进行后序遍历查找
if(this.right != null) {
resNode = this.right.postOrderSearch(no);
}
if(resNode != null) {
return resNode;
}
System.out.println("进入后序查找");
//如果左右子树都没有找到,就比较当前结点是不是
if(this.no == no) {
return this;
}
return resNode;
}
}
10.3.5 线索化二叉树的课后作业
这里讲解了中序线索化二叉树,前序线索化二叉树和后序线索化二叉树的分析思路类似,大家作为课后作业完成
第11章 树结构实际应用
11.1 堆排序★
11.1.1 堆排序基本介绍
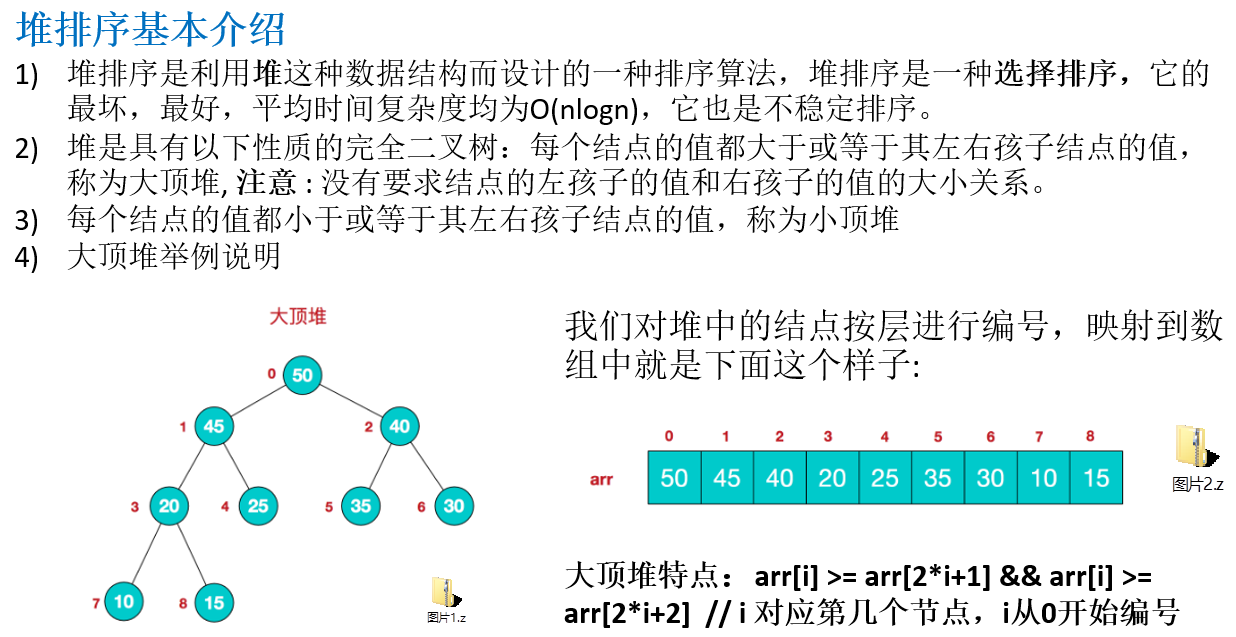
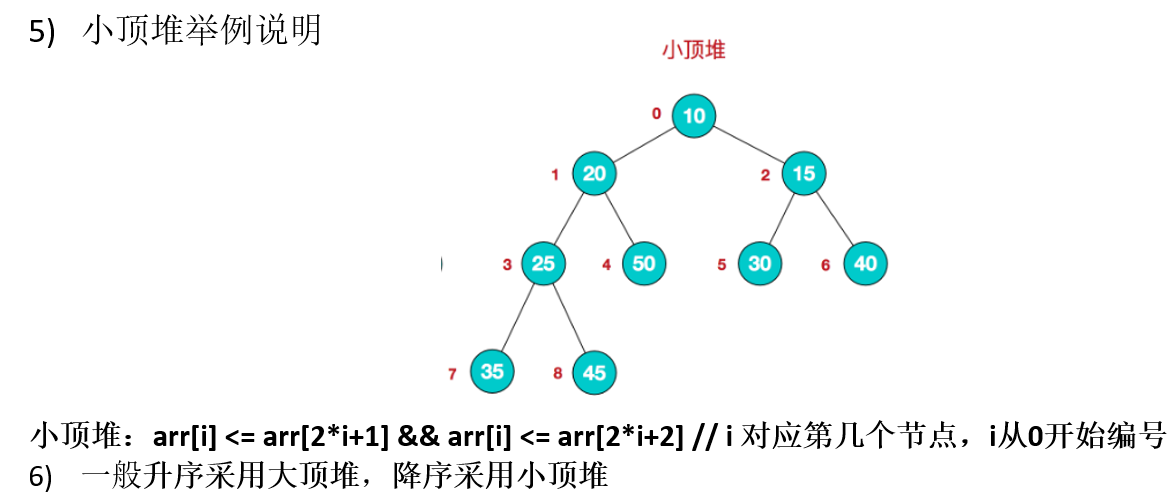
11.1.2 堆排序基本思想

11.1.3 堆排序步骤图解说明

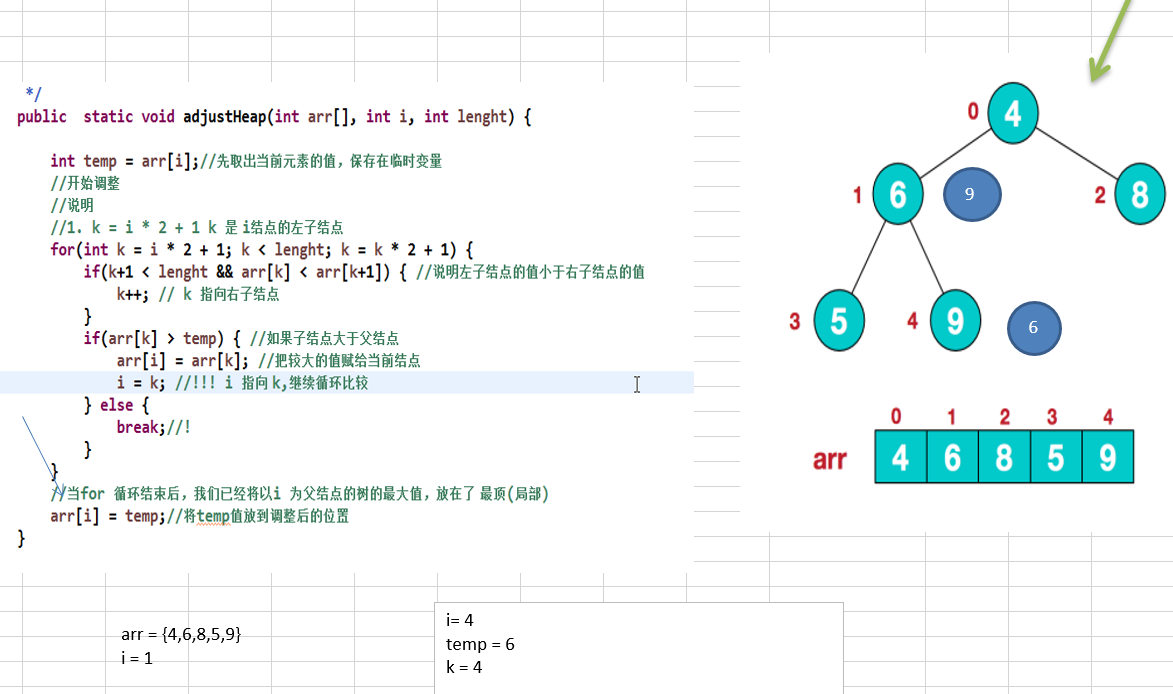
11.1.4 堆排序代码实现

package com.atguigu.tree;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
public class HeapSort {
public static void main(String[] args) {
//要求将数组进行升序排序
//int arr[] = {4, 6, 8, 5, 9};
// 创建要给80000个的随机的数组
int[] arr = new int[8000000];
for (int i = 0; i < 8000000; i++) {
arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数
}
System.out.println("排序前");
Date data1 = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date1Str = simpleDateFormat.format(data1);
System.out.println("排序前的时间是=" + date1Str);
heapSort(arr);
Date data2 = new Date();
String date2Str = simpleDateFormat.format(data2);
System.out.println("排序前的时间是=" + date2Str);
//System.out.println("排序后=" + Arrays.toString(arr));
}
//编写一个堆排序的方法
public static void heapSort(int arr[]) {
int temp = 0;
System.out.println("堆排序!!");
// //分步完成
// adjustHeap(arr, 1, arr.length);
// System.out.println("第一次" + Arrays.toString(arr)); // 4, 9, 8, 5, 6
//
// adjustHeap(arr, 0, arr.length);
// System.out.println("第2次" + Arrays.toString(arr)); // 9,6,8,5,4
//完成我们最终代码
//将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆
for(int i = arr.length / 2 -1; i >=0; i--) {
adjustHeap(arr, i, arr.length);
}
/*
* 2).将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
3).重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
*/
for(int j = arr.length-1;j >0; j--) {
//交换
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
adjustHeap(arr, 0, j);
}
//System.out.println("数组=" + Arrays.toString(arr));
}
//将一个数组(二叉树), 调整成一个大顶堆
/**
* 功能: 完成 将 以 i 对应的非叶子结点的树调整成大顶堆
* 举例 int arr[] = {4, 6, 8, 5, 9}; => i = 1 => adjustHeap => 得到 {4, 9, 8, 5, 6}
* 如果我们再次调用 adjustHeap 传入的是 i = 0 => 得到 {4, 9, 8, 5, 6} => {9,6,8,5, 4}
* @param arr 待调整的数组
* @param i 表示非叶子结点在数组中索引
* @param length 表示对多少个元素继续调整, length 是在逐渐的减少
*/
public static void adjustHeap(int arr[], int i, int length) {
int temp = arr[i];//先取出当前元素的值,保存在临时变量
//开始调整
//说明
//1. k = i * 2 + 1 k 是 i结点的左子结点
for(int k = i * 2 + 1; k < length; k = k * 2 + 1) {
if(k+1 < length && arr[k] < arr[k+1]) { //说明左子结点的值小于右子结点的值
k++; // k 指向右子结点
}
if(arr[k] > temp) { //如果子结点大于父结点
arr[i] = arr[k]; //把较大的值赋给当前结点
i = k; //!!! i 指向 k,继续循环比较
} else {
break;//!
}
}
//当for 循环结束后,我们已经将以i 为父结点的树的最大值,放在了 最顶(局部)
arr[i] = temp;//将temp值放到调整后的位置
}
}11.2 赫夫曼树
11.2.1 基本介绍

11.2.2 赫夫曼树几个重要概念和举例说明
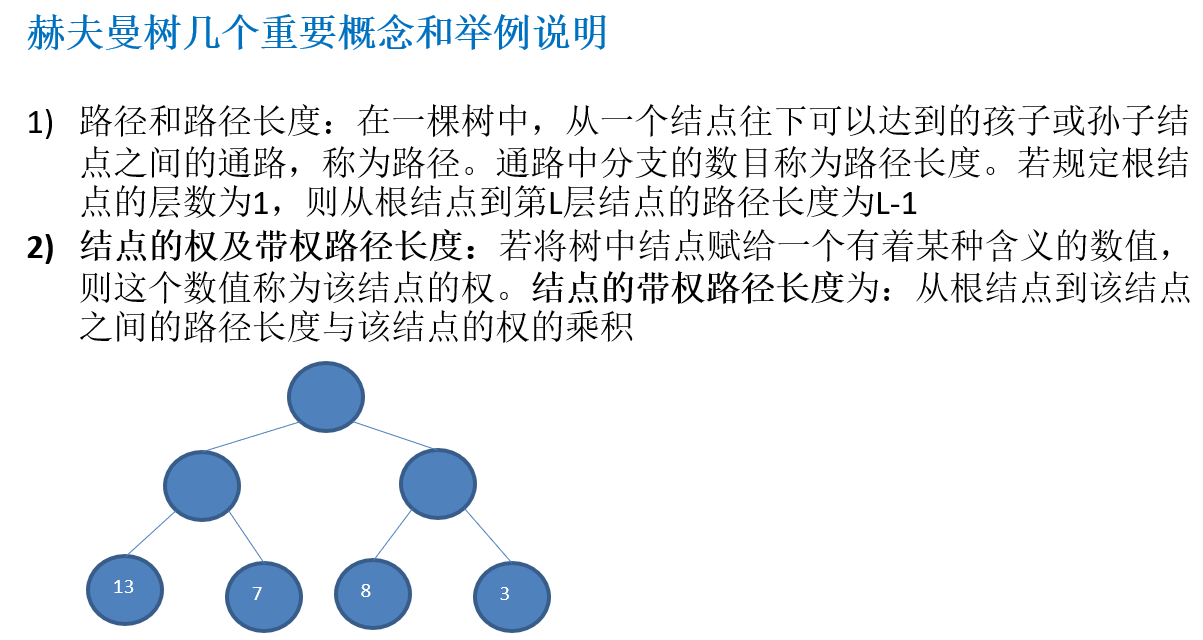
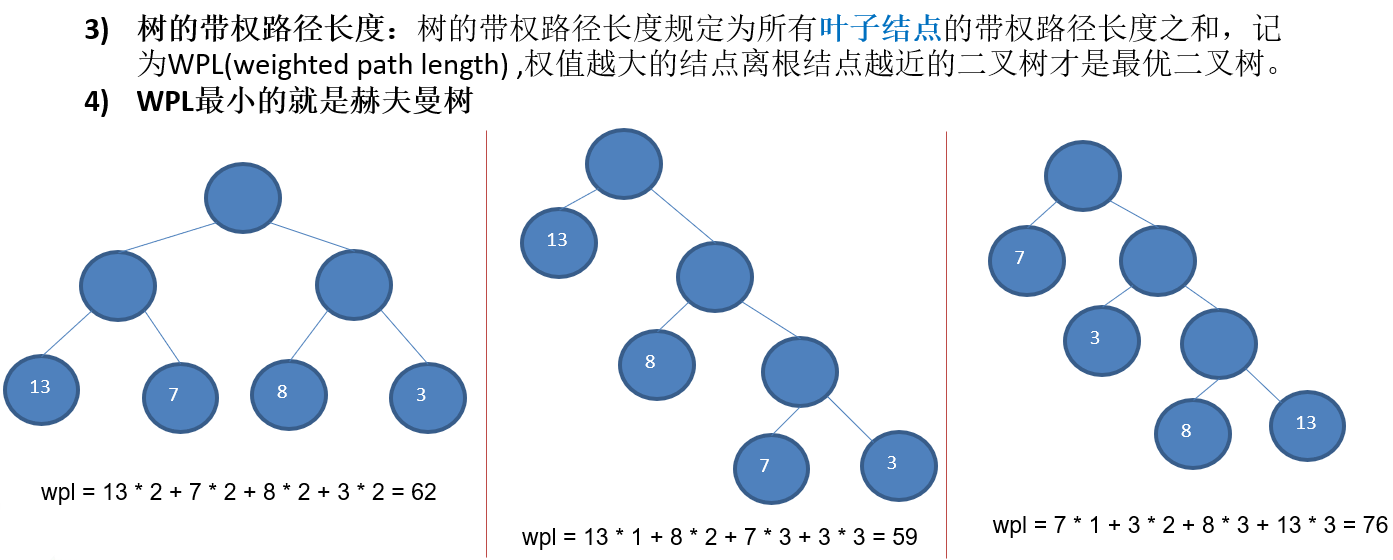
11.2.3 赫夫曼树创建思路图解

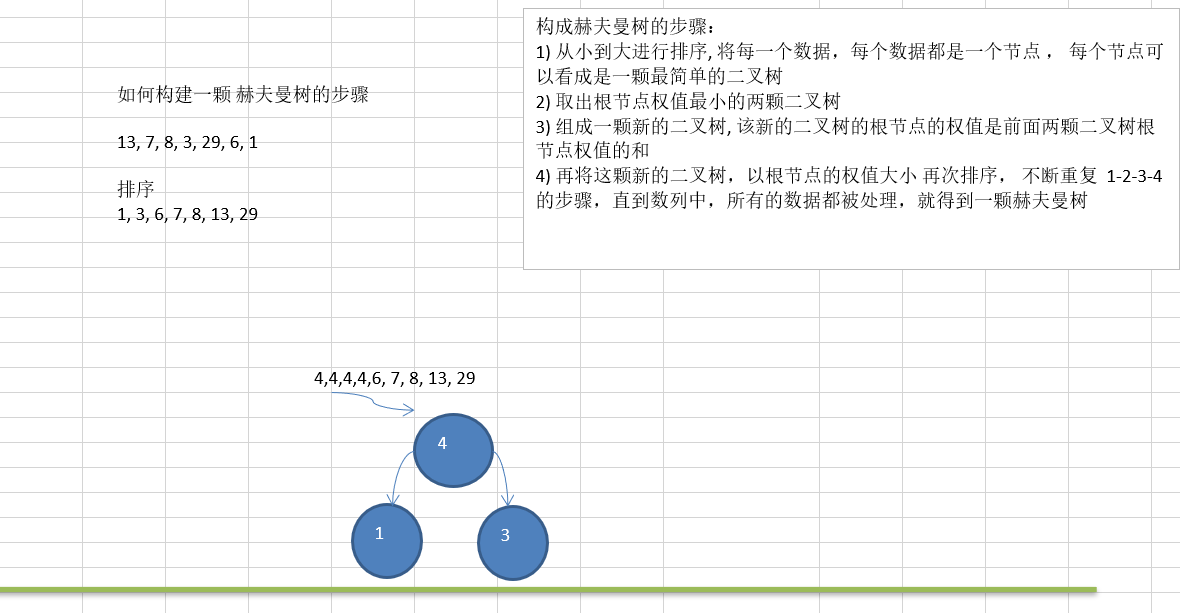
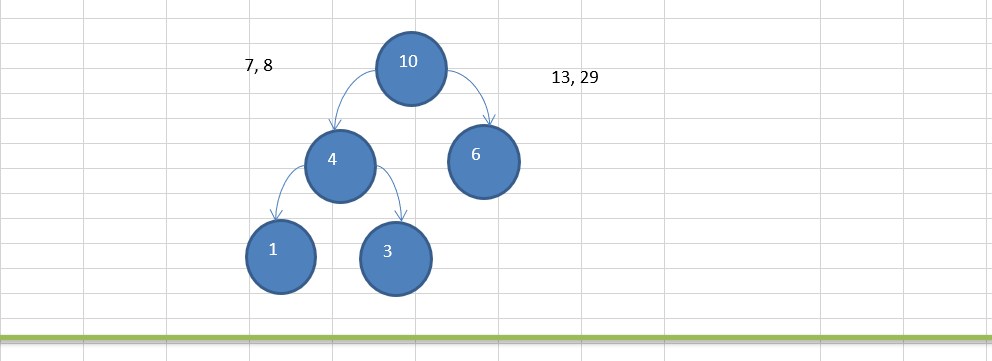

11.2.4 赫夫曼树的代码实现
package com.atguigu.huffmantree;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class HuffmanTree {
public static void main(String[] args) {
int arr[] = { 13, 7, 8, 3, 29, 6, 1 };
Node root = createHuffmanTree(arr);
//测试一把
preOrder(root); //
}
//编写一个前序遍历的方法
public static void preOrder(Node root) {
if(root != null) {
root.preOrder();
}else{
System.out.println("是空树,不能遍历~~");
}
}
// 创建赫夫曼树的方法
/**
*
* @param arr 需要创建成哈夫曼树的数组
* @return 创建好后的赫夫曼树的root结点
*/
public static Node createHuffmanTree(int[] arr) {
// 第一步为了操作方便
// 1. 遍历 arr 数组
// 2. 将arr的每个元素构成成一个Node
// 3. 将Node 放入到ArrayList中
List<Node> nodes = new ArrayList<Node>();
for (int value : arr) {
nodes.add(new Node(value));
}
//我们处理的过程是一个循环的过程
while(nodes.size() > 1) {
//排序 从小到大
Collections.sort(nodes);
System.out.println("nodes =" + nodes);
//取出根节点权值最小的两颗二叉树
//(1) 取出权值最小的结点(二叉树)
Node leftNode = nodes.get(0);
//(2) 取出权值第二小的结点(二叉树)
Node rightNode = nodes.get(1);
//(3)构建一颗新的二叉树
Node parent = new Node(leftNode.value + rightNode.value);
parent.left = leftNode;
parent.right = rightNode;
//(4)从ArrayList删除处理过的二叉树
nodes.remove(leftNode);
nodes.remove(rightNode);
//(5)将parent加入到nodes
nodes.add(parent);
}
//返回哈夫曼树的root结点
return nodes.get(0);
}
}
// 创建结点类
// 为了让Node 对象持续排序Collections集合排序
// 让Node 实现Comparable接口
class Node implements Comparable<Node> {
int value; // 结点权值
char c; //字符
Node left; // 指向左子结点
Node right; // 指向右子结点
//写一个前序遍历
public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
}
public Node(int value) {
this.value = value;
}
@Override
public String toString() {
return "Node [value=" + value + "]";
}
@Override
public int compareTo(Node o) {
// 表示从小到大排序
return this.value - o.value;
}
}
11.3 赫夫曼编码
11.3.1 基本介绍

11.3.2 原理剖析



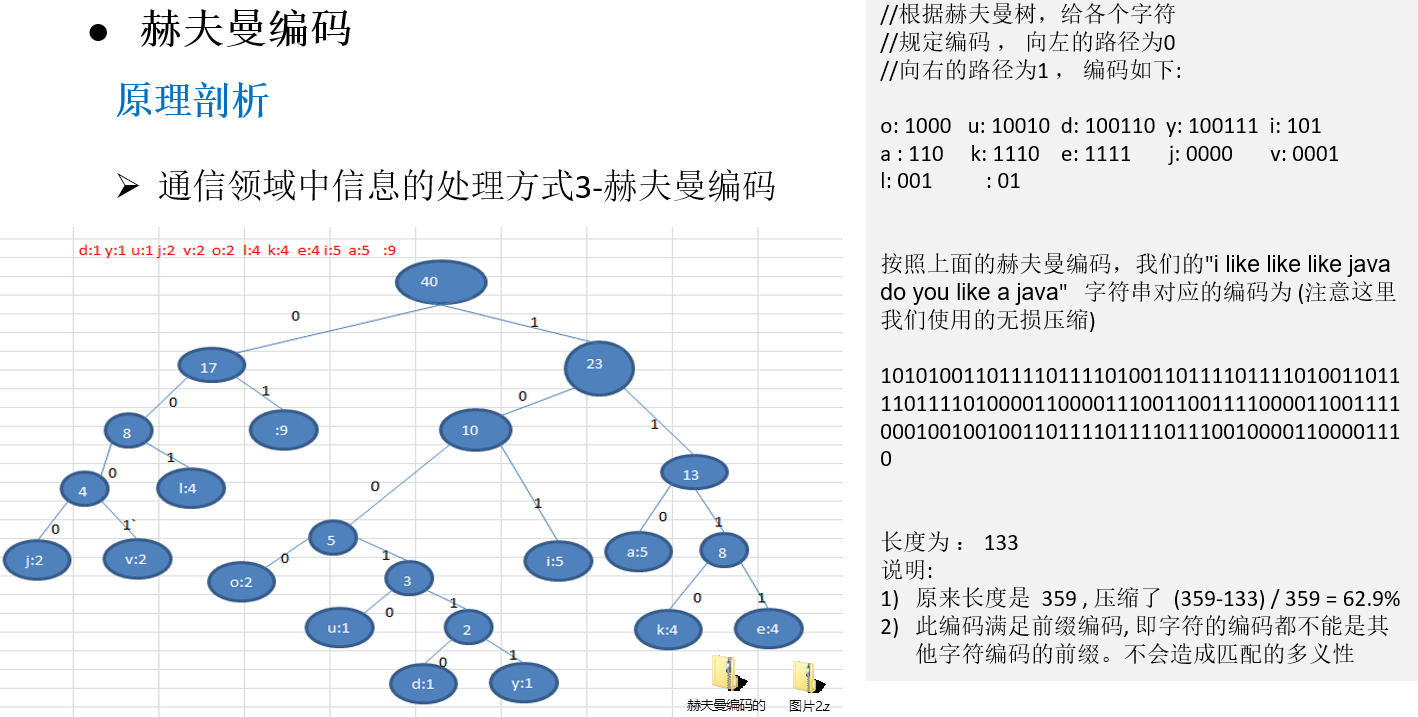
赫夫曼编码的原理剖析

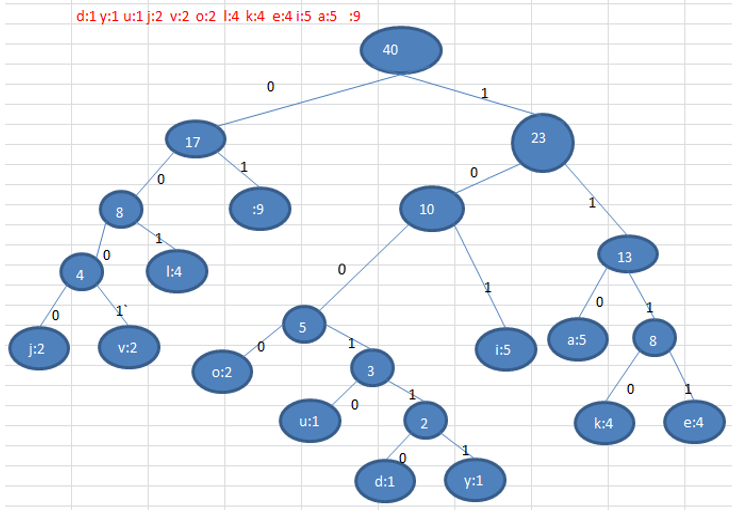

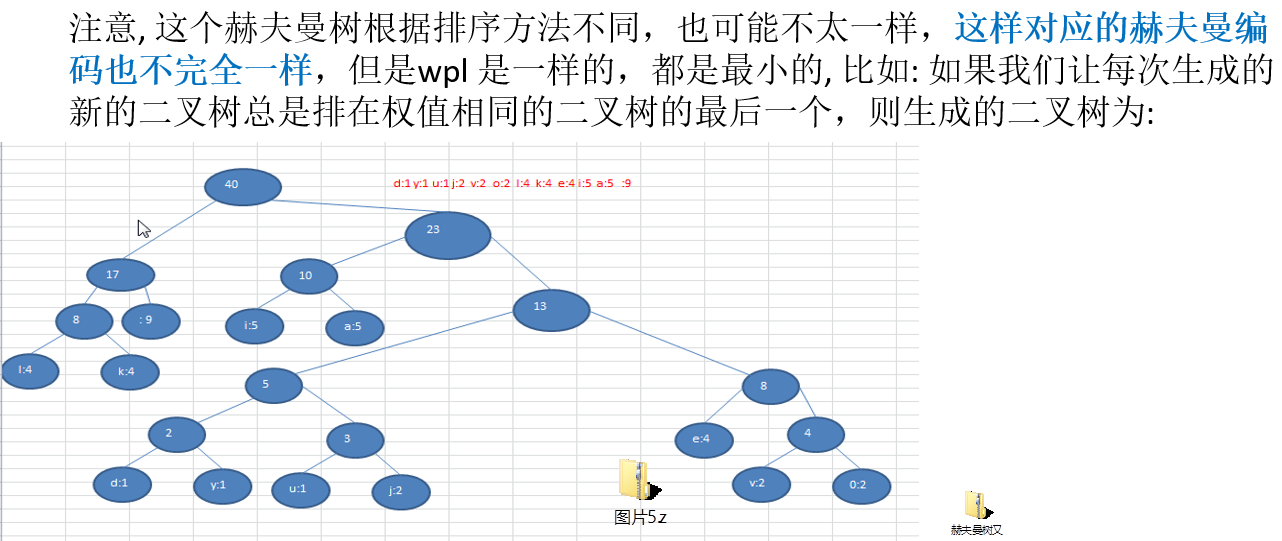
11.3.3 最佳实践-数据压缩(创建赫夫曼树)


11.3.4 最佳实践-数据压缩(生成赫夫曼编码和赫夫曼编码后的数据)

11.3.5 最佳实践-数据解压(使用赫夫曼编码解码)

11.3.6 最佳实践-文件压缩

11.3.7 最佳实践-文件解压(文件恢复)

11.3.8 代码汇总,把前面所有的方法放在一起
package com.atguigu.huffmancode;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class HuffmanCode {
public static void main(String[] args) {
//测试压缩文件
// String srcFile = "d://Uninstall.xml";
// String dstFile = "d://Uninstall.zip";
//
// zipFile(srcFile, dstFile);
// System.out.println("压缩文件ok~~");
//测试解压文件
String zipFile = "d://Uninstall.zip";
String dstFile = "d://Uninstall2.xml";
unZipFile(zipFile, dstFile);
System.out.println("解压成功!");
/*
String content = "i like like like java do you like a java";
byte[] contentBytes = content.getBytes();
System.out.println(contentBytes.length); //40
byte[] huffmanCodesBytes= huffmanZip(contentBytes);
System.out.println("压缩后的结果是:" + Arrays.toString(huffmanCodesBytes) + " 长度= " + huffmanCodesBytes.length);
//测试一把byteToBitString方法
//System.out.println(byteToBitString((byte)1));
byte[] sourceBytes = decode(huffmanCodes, huffmanCodesBytes);
System.out.println("原来的字符串=" + new String(sourceBytes)); // "i like like like java do you like a java"
*/
//如何将 数据进行解压(解码)
//分步过程
/*
List<Node> nodes = getNodes(contentBytes);
System.out.println("nodes=" + nodes);
//测试一把,创建的赫夫曼树
System.out.println("赫夫曼树");
Node huffmanTreeRoot = createHuffmanTree(nodes);
System.out.println("前序遍历");
huffmanTreeRoot.preOrder();
//测试一把是否生成了对应的赫夫曼编码
Map<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot);
System.out.println("~生成的赫夫曼编码表= " + huffmanCodes);
//测试
byte[] huffmanCodeBytes = zip(contentBytes, huffmanCodes);
System.out.println("huffmanCodeBytes=" + Arrays.toString(huffmanCodeBytes));//17
//发送huffmanCodeBytes 数组 */
}
//编写一个方法,完成对压缩文件的解压
/**
*
* @param zipFile 准备解压的文件
* @param dstFile 将文件解压到哪个路径
*/
public static void unZipFile(String zipFile, String dstFile) {
//定义文件输入流
InputStream is = null;
//定义一个对象输入流
ObjectInputStream ois = null;
//定义文件的输出流
OutputStream os = null;
try {
//创建文件输入流
is = new FileInputStream(zipFile);
//创建一个和 is关联的对象输入流
ois = new ObjectInputStream(is);
//读取byte数组 huffmanBytes
byte[] huffmanBytes = (byte[])ois.readObject();
//读取赫夫曼编码表
Map<Byte,String> huffmanCodes = (Map<Byte,String>)ois.readObject();
//解码
byte[] bytes = decode(huffmanCodes, huffmanBytes);
//将bytes 数组写入到目标文件
os = new FileOutputStream(dstFile);
//写数据到 dstFile 文件
os.write(bytes);
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
try {
os.close();
ois.close();
is.close();
} catch (Exception e2) {
System.out.println(e2.getMessage());
}
}
}
//编写方法,将一个文件进行压缩
/**
*
* @param srcFile 你传入的希望压缩的文件的全路径
* @param dstFile 我们压缩后将压缩文件放到哪个目录
*/
public static void zipFile(String srcFile, String dstFile) {
//创建输出流
OutputStream os = null;
ObjectOutputStream oos = null;
//创建文件的输入流
FileInputStream is = null;
try {
//创建文件的输入流
is = new FileInputStream(srcFile);
//创建一个和源文件大小一样的byte[]
byte[] b = new byte[is.available()];
//读取文件
is.read(b);
//直接对源文件压缩
byte[] huffmanBytes = huffmanZip(b);
//创建文件的输出流, 存放压缩文件
os = new FileOutputStream(dstFile);
//创建一个和文件输出流关联的ObjectOutputStream
oos = new ObjectOutputStream(os);
//把 赫夫曼编码后的字节数组写入压缩文件
oos.writeObject(huffmanBytes); //我们是把
//这里我们以对象流的方式写入 赫夫曼编码,是为了以后我们恢复源文件时使用
//注意一定要把赫夫曼编码 写入压缩文件
oos.writeObject(huffmanCodes);
}catch (Exception e) {
System.out.println(e.getMessage());
}finally {
try {
is.close();
oos.close();
os.close();
}catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
//完成数据的解压
//思路
//1. 将huffmanCodeBytes [-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28]
// 重写先转成 赫夫曼编码对应的二进制的字符串 "1010100010111..."
//2. 赫夫曼编码对应的二进制的字符串 "1010100010111..." =》 对照 赫夫曼编码 =》 "i like like like java do you like a java"
//编写一个方法,完成对压缩数据的解码
/**
*
* @param huffmanCodes 赫夫曼编码表 map
* @param huffmanBytes 赫夫曼编码得到的字节数组
* @return 就是原来的字符串对应的数组
*/
private static byte[] decode(Map<Byte,String> huffmanCodes, byte[] huffmanBytes) {
//1. 先得到 huffmanBytes 对应的 二进制的字符串 , 形式 1010100010111...
StringBuilder stringBuilder = new StringBuilder();
//将byte数组转成二进制的字符串
for(int i = 0; i < huffmanBytes.length; i++) {
byte b = huffmanBytes[i];
//判断是不是最后一个字节
boolean flag = (i == huffmanBytes.length - 1);
stringBuilder.append(byteToBitString(!flag, b));
}
//把字符串安装指定的赫夫曼编码进行解码
//把赫夫曼编码表进行调换,因为反向查询 a->100 100->a
Map<String, Byte> map = new HashMap<String,Byte>();
for(Map.Entry<Byte, String> entry: huffmanCodes.entrySet()) {
map.put(entry.getValue(), entry.getKey());
}
//创建要给集合,存放byte
List<Byte> list = new ArrayList<>();
//i 可以理解成就是索引,扫描 stringBuilder
for(int i = 0; i < stringBuilder.length(); ) {
int count = 1; // 小的计数器
boolean flag = true;
Byte b = null;
while(flag) {
//1010100010111...
//递增的取出 key 1
String key = stringBuilder.substring(i, i+count);//i 不动,让count移动,直到匹配到一个字符
b = map.get(key);
if(b == null) {//说明没有匹配到
count++;
}else {
//匹配到
flag = false;
}
}
list.add(b);
i += count;//i 直接移动到 count
}
//当for循环结束后,我们list中就存放了所有的字符 "i like like like java do you like a java"
//把list 中的数据放入到byte[] 并返回
byte b[] = new byte[list.size()];
for(int i = 0;i < b.length; i++) {
b[i] = list.get(i);
}
return b;
}
/**
* 将一个byte 转成一个二进制的字符串, 如果看不懂,可以参考我讲的Java基础 二进制的原码,反码,补码
* @param b 传入的 byte
* @param flag 标志是否需要补高位如果是true ,表示需要补高位,如果是false表示不补, 如果是最后一个字节,无需补高位
* @return 是该b 对应的二进制的字符串,(注意是按补码返回)
*/
private static String byteToBitString(boolean flag, byte b) {
//使用变量保存 b
int temp = b; //将 b 转成 int
//如果是正数我们还存在补高位
if(flag) {
temp |= 256; //按位或 256 1 0000 0000 | 0000 0001 => 1 0000 0001
}
String str = Integer.toBinaryString(temp); //返回的是temp对应的二进制的补码
if(flag) {
return str.substring(str.length() - 8);
} else {
return str;
}
}
//使用一个方法,将前面的方法封装起来,便于我们的调用.
/**
*
* @param bytes 原始的字符串对应的字节数组
* @return 是经过 赫夫曼编码处理后的字节数组(压缩后的数组)
*/
private static byte[] huffmanZip(byte[] bytes) {
List<Node> nodes = getNodes(bytes);
//根据 nodes 创建的赫夫曼树
Node huffmanTreeRoot = createHuffmanTree(nodes);
//对应的赫夫曼编码(根据 赫夫曼树)
Map<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot);
//根据生成的赫夫曼编码,压缩得到压缩后的赫夫曼编码字节数组
byte[] huffmanCodeBytes = zip(bytes, huffmanCodes);
return huffmanCodeBytes;
}
//编写一个方法,将字符串对应的byte[] 数组,通过生成的赫夫曼编码表,返回一个赫夫曼编码 压缩后的byte[]
/**
*
* @param bytes 这时原始的字符串对应的 byte[]
* @param huffmanCodes 生成的赫夫曼编码map
* @return 返回赫夫曼编码处理后的 byte[]
* 举例: String content = "i like like like java do you like a java"; =》 byte[] contentBytes = content.getBytes();
* 返回的是 字符串 "1010100010111111110010001011111111001000101111111100100101001101110001110000011011101000111100101000101111111100110001001010011011100"
* => 对应的 byte[] huffmanCodeBytes ,即 8位对应一个 byte,放入到 huffmanCodeBytes
* huffmanCodeBytes[0] = 10101000(补码) => byte [推导 10101000=> 10101000 - 1 => 10100111(反码)=> 11011000(原码)= -88 ]
* huffmanCodeBytes[1] = -88
*/
private static byte[] zip(byte[] bytes, Map<Byte, String> huffmanCodes) {
//1.利用 huffmanCodes 将 bytes 转成 赫夫曼编码对应的字符串
StringBuilder stringBuilder = new StringBuilder();
//遍历bytes 数组
for(byte b: bytes) {
stringBuilder.append(huffmanCodes.get(b));
}
//System.out.println("测试 stringBuilder~~~=" + stringBuilder.toString());
//将 "1010100010111111110..." 转成 byte[]
//统计返回 byte[] huffmanCodeBytes 长度
//一句话 int len = (stringBuilder.length() + 7) / 8;
int len;
if(stringBuilder.length() % 8 == 0) {
len = stringBuilder.length() / 8;
} else {
len = stringBuilder.length() / 8 + 1;
}
//创建 存储压缩后的 byte数组
byte[] huffmanCodeBytes = new byte[len];
int index = 0;//记录是第几个byte
for (int i = 0; i < stringBuilder.length(); i += 8) { //因为是每8位对应一个byte,所以步长 +8
String strByte;
if(i+8 > stringBuilder.length()) {//不够8位
strByte = stringBuilder.substring(i);
}else{
strByte = stringBuilder.substring(i, i + 8);
}
//将strByte 转成一个byte,放入到 huffmanCodeBytes
huffmanCodeBytes[index] = (byte)Integer.parseInt(strByte, 2);
index++;
}
return huffmanCodeBytes;
}
//生成赫夫曼树对应的赫夫曼编码
//思路:
//1. 将赫夫曼编码表存放在 Map<Byte,String> 形式
// 生成的赫夫曼编码表{32=01, 97=100, 100=11000, 117=11001, 101=1110, 118=11011, 105=101, 121=11010, 106=0010, 107=1111, 108=000, 111=0011}
static Map<Byte, String> huffmanCodes = new HashMap<Byte,String>();
//2. 在生成赫夫曼编码表示,需要去拼接路径, 定义一个StringBuilder 存储某个叶子结点的路径
static StringBuilder stringBuilder = new StringBuilder();
//为了调用方便,我们重载 getCodes
private static Map<Byte, String> getCodes(Node root) {
if(root == null) {
return null;
}
//处理root的左子树
getCodes(root.left, "0", stringBuilder);
//处理root的右子树
getCodes(root.right, "1", stringBuilder);
return huffmanCodes;
}
/**
* 功能:将传入的node结点的所有叶子结点的赫夫曼编码得到,并放入到huffmanCodes集合
* @param node 传入结点
* @param code 路径: 左子结点是 0, 右子结点 1
* @param stringBuilder 用于拼接路径
*/
private static void getCodes(Node node, String code, StringBuilder stringBuilder) {
StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);
//将code 加入到 stringBuilder2
stringBuilder2.append(code);
if(node != null) { //如果node == null不处理
//判断当前node 是叶子结点还是非叶子结点
if(node.data == null) { //非叶子结点
//递归处理
//向左递归
getCodes(node.left, "0", stringBuilder2);
//向右递归
getCodes(node.right, "1", stringBuilder2);
} else { //说明是一个叶子结点
//就表示找到某个叶子结点的最后
huffmanCodes.put(node.data, stringBuilder2.toString());
}
}
}
//前序遍历的方法
private static void preOrder(Node root) {
if(root != null) {
root.preOrder();
}else {
System.out.println("赫夫曼树为空");
}
}
/**
*
* @param bytes 接收字节数组
* @return 返回的就是 List 形式 [Node[date=97 ,weight = 5], Node[]date=32,weight = 9]......],
*/
private static List<Node> getNodes(byte[] bytes) {
//1创建一个ArrayList
ArrayList<Node> nodes = new ArrayList<Node>();
//遍历 bytes , 统计 每一个byte出现的次数->map[key,value]
Map<Byte, Integer> counts = new HashMap<>();
for (byte b : bytes) {
Integer count = counts.get(b);
if (count == null) { // Map还没有这个字符数据,第一次
counts.put(b, 1);
} else {
counts.put(b, count + 1);
}
}
//把每一个键值对转成一个Node 对象,并加入到nodes集合
//遍历map
for(Map.Entry<Byte, Integer> entry: counts.entrySet()) {
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
//可以通过List 创建对应的赫夫曼树
private static Node createHuffmanTree(List<Node> nodes) {
while(nodes.size() > 1) {
//排序, 从小到大
Collections.sort(nodes);
//取出第一颗最小的二叉树
Node leftNode = nodes.get(0);
//取出第二颗最小的二叉树
Node rightNode = nodes.get(1);
//创建一颗新的二叉树,它的根节点 没有data, 只有权值
Node parent = new Node(null, leftNode.weight + rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
//将已经处理的两颗二叉树从nodes删除
nodes.remove(leftNode);
nodes.remove(rightNode);
//将新的二叉树,加入到nodes
nodes.add(parent);
}
//nodes 最后的结点,就是赫夫曼树的根结点
return nodes.get(0);
}
}
//创建Node ,待数据和权值
class Node implements Comparable<Node> {
Byte data; // 存放数据(字符)本身,比如'a' => 97 ' ' => 32
int weight; //权值, 表示字符出现的次数
Node left;//
Node right;
public Node(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
@Override
public int compareTo(Node o) {
// 从小到大排序
return this.weight - o.weight;
}
public String toString() {
return "Node [data = " + data + " weight=" + weight + "]";
}
//前序遍历
public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
}
}
11.3.9 赫夫曼编码压缩文件注意事项

11.4 二叉排序树(Binary Sort(Search) Tree,BST)
11.4.1 先看一个需求

11.4.2 解决方案分析

11.4.3 二叉排序树介绍
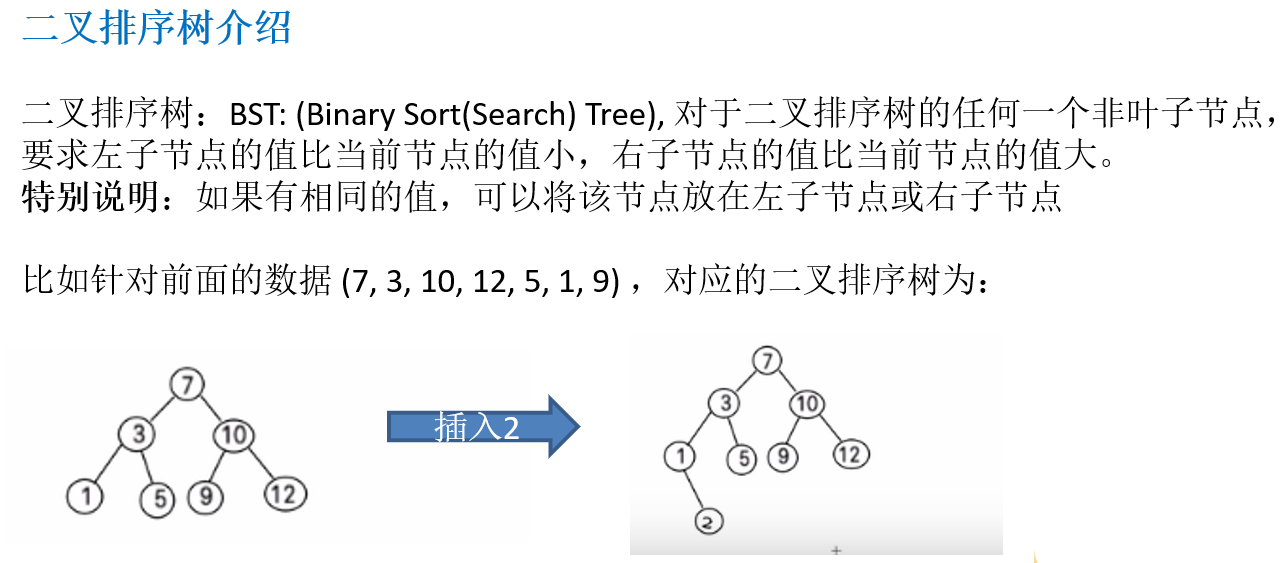
11.4.4 二叉排序树创建和遍历

11.4.5 二叉排序树的删除
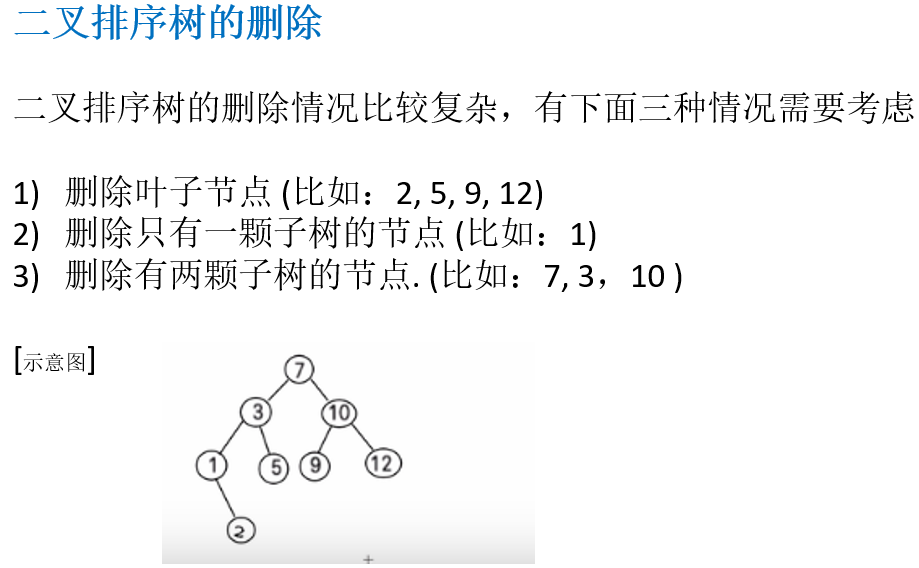


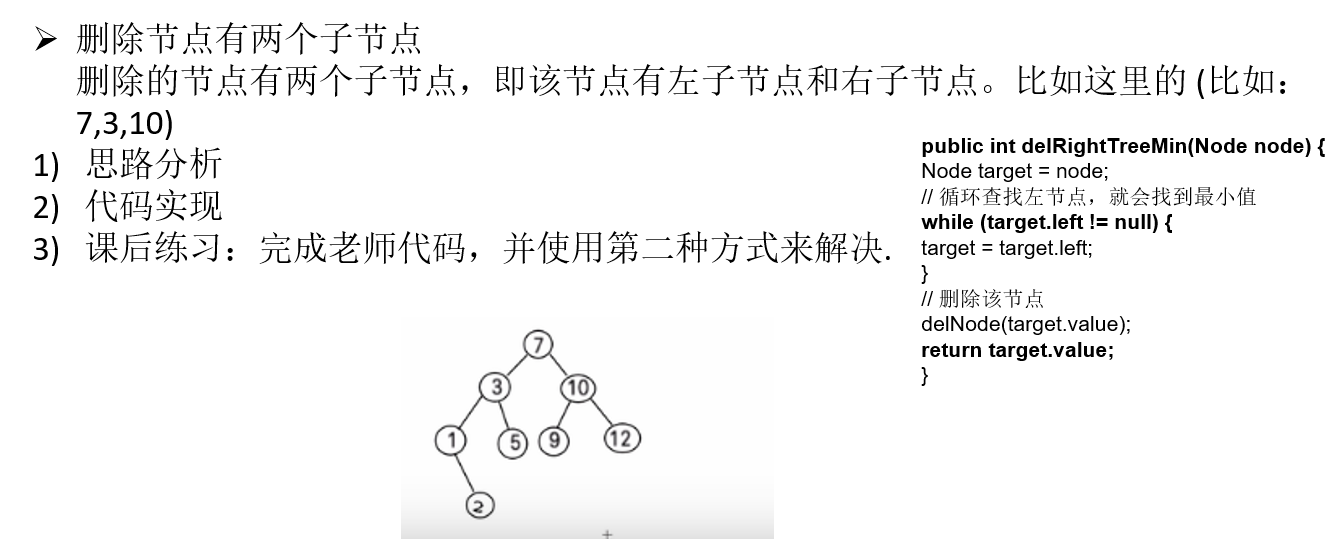

11.4.6 二叉排序树删除节点的代码实现
package com.atguigu.binarysorttree;
public class BinarySortTreeDemo {
public static void main(String[] args) {
int[] arr = {7, 3, 10, 12, 5, 1, 9, 2};
BinarySortTree binarySortTree = new BinarySortTree();
//循环的添加结点到二叉排序树
for(int i = 0; i< arr.length; i++) {
binarySortTree.add(new Node(arr[i]));
}
//中序遍历二叉排序树
System.out.println("中序遍历二叉排序树~");
binarySortTree.infixOrder(); // 1, 3, 5, 7, 9, 10, 12
//测试一下删除叶子结点
binarySortTree.delNode(12);
binarySortTree.delNode(5);
binarySortTree.delNode(10);
binarySortTree.delNode(2);
binarySortTree.delNode(3);
binarySortTree.delNode(9);
binarySortTree.delNode(1);
binarySortTree.delNode(7);
System.out.println("root=" + binarySortTree.getRoot());
System.out.println("删除结点后");
binarySortTree.infixOrder();
}
}
//创建二叉排序树
class BinarySortTree {
private Node root;
public Node getRoot() {
return root;
}
//查找要删除的结点
public Node search(int value) {
if(root == null) {
return null;
} else {
return root.search(value);
}
}
//查找父结点
public Node searchParent(int value) {
if(root == null) {
return null;
} else {
return root.searchParent(value);
}
}
//编写方法:
//1. 返回的 以node 为根结点的二叉排序树的最小结点的值
//2. 删除node 为根结点的二叉排序树的最小结点
/**
*
* @param node 传入的结点(当做二叉排序树的根结点)
* @return 返回的 以node 为根结点的二叉排序树的最小结点的值
*/
public int delRightTreeMin(Node node) {
Node target = node;
//循环的查找左子节点,就会找到最小值
while(target.left != null) {
target = target.left;
}
//这时 target就指向了最小结点
//删除最小结点
delNode(target.value);
return target.value;
}
//删除结点
public void delNode(int value) {
if(root == null) {
return;
}else {
//1.需求先去找到要删除的结点 targetNode
Node targetNode = search(value);
//如果没有找到要删除的结点
if(targetNode == null) {
return;
}
//如果我们发现当前这颗二叉排序树只有一个结点
if(root.left == null && root.right == null) {
root = null;
return;
}
//去找到targetNode的父结点
Node parent = searchParent(value);
//如果要删除的结点是叶子结点
if(targetNode.left == null && targetNode.right == null) {
//判断targetNode 是父结点的左子结点,还是右子结点
if(parent.left != null && parent.left.value == value) { //是左子结点
parent.left = null;
} else if (parent.right != null && parent.right.value == value) {//是右子结点
parent.right = null;
}
} else if (targetNode.left != null && targetNode.right != null) { //删除有两颗子树的节点
int minVal = delRightTreeMin(targetNode.right);
targetNode.value = minVal;
} else { // 删除只有一颗子树的结点
//如果要删除的结点有左子结点
if(targetNode.left != null) {
if(parent != null) {
//如果 targetNode 是 parent 的左子结点
if(parent.left.value == value) {
parent.left = targetNode.left;
} else { // targetNode 是 parent 的右子结点
parent.right = targetNode.left;
}
} else {
root = targetNode.left;
}
} else { //如果要删除的结点有右子结点
if(parent != null) {
//如果 targetNode 是 parent 的左子结点
if(parent.left.value == value) {
parent.left = targetNode.right;
} else { //如果 targetNode 是 parent 的右子结点
parent.right = targetNode.right;
}
} else {
root = targetNode.right;
}
}
}
}
}
//添加结点的方法
public void add(Node node) {
if(root == null) {
root = node;//如果root为空则直接让root指向node
} else {
root.add(node);
}
}
//中序遍历
public void infixOrder() {
if(root != null) {
root.infixOrder();
} else {
System.out.println("二叉排序树为空,不能遍历");
}
}
}
//创建Node结点
class Node {
int value;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
//查找要删除的结点
/**
*
* @param value 希望删除的结点的值
* @return 如果找到返回该结点,否则返回null
*/
public Node search(int value) {
if(value == this.value) { //找到就是该结点
return this;
} else if(value < this.value) {//如果查找的值小于当前结点,向左子树递归查找
//如果左子结点为空
if(this.left == null) {
return null;
}
return this.left.search(value);
} else { //如果查找的值不小于当前结点,向右子树递归查找
if(this.right == null) {
return null;
}
return this.right.search(value);
}
}
//查找要删除结点的父结点
/**
*
* @param value 要找到的结点的值
* @return 返回的是要删除的结点的父结点,如果没有就返回null
*/
public Node searchParent(int value) {
//如果当前结点就是要删除的结点的父结点,就返回
if((this.left != null && this.left.value == value) ||
(this.right != null && this.right.value == value)) {
return this;
} else {
//如果查找的值小于当前结点的值, 并且当前结点的左子结点不为空
if(value < this.value && this.left != null) {
return this.left.searchParent(value); //向左子树递归查找
} else if (value >= this.value && this.right != null) {
return this.right.searchParent(value); //向右子树递归查找
} else {
return null; // 没有找到父结点
}
}
}
@Override
public String toString() {
return "Node [value=" + value + "]";
}
//添加结点的方法
//递归的形式添加结点,注意需要满足二叉排序树的要求
public void add(Node node) {
if(node == null) {
return;
}
//判断传入的结点的值,和当前子树的根结点的值关系
if(node.value < this.value) {
//如果当前结点左子结点为null
if(this.left == null) {
this.left = node;
} else {
//递归的向左子树添加
this.left.add(node);
}
} else { //添加的结点的值大于 当前结点的值
if(this.right == null) {
this.right = node;
} else {
//递归的向右子树添加
this.right.add(node);
}
}
}
//中序遍历
public void infixOrder() {
if(this.left != null) {
this.left.infixOrder();
}
System.out.println(this);
if(this.right != null) {
this.right.infixOrder();
}
}
}
11.4.7 课后练习:完成代码,使用第二种方式解决

11.5 平衡二叉树(AVL树,Adelson-Velsky-Landis)
在计算机科学中,AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。AVL树得名于它的发明者G. M. Adelson-Velsky和E. M. Landis,他们在1962年的论文《An algorithm for the organization of information》中发表了它。
11.5.1 看一个案例(说明二叉排序树可能的问题)

11.5.2 基本介绍
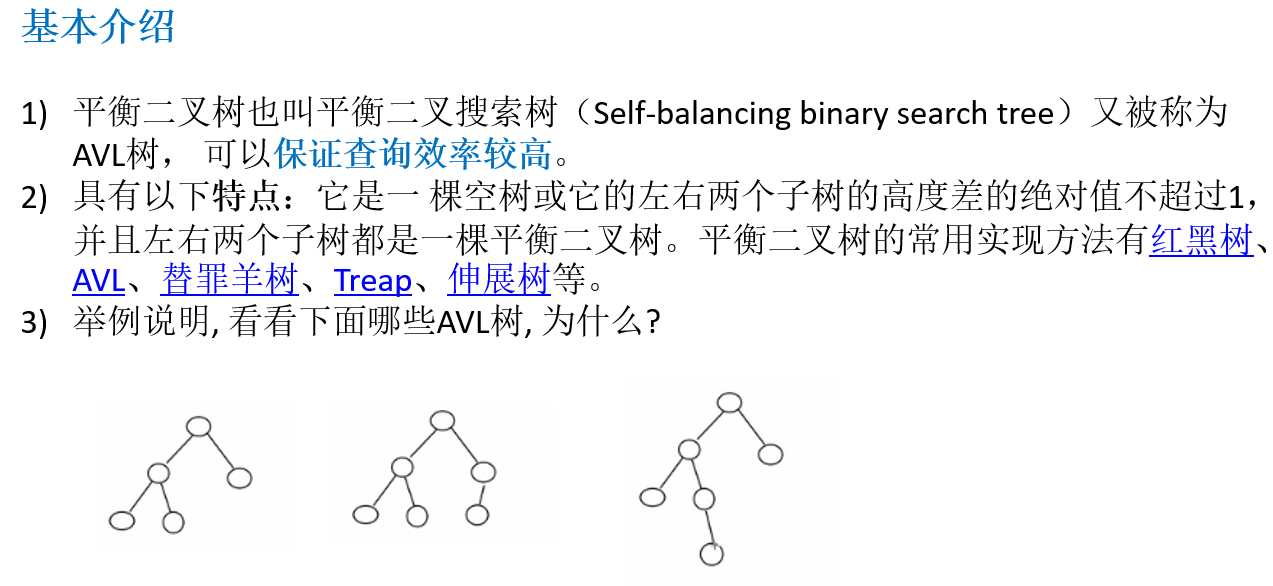
11.5.3 应用案例-单旋转(左旋转)



11.5.4 应用案例-单旋转(右旋转)



11.5.5 应用案例-双旋转

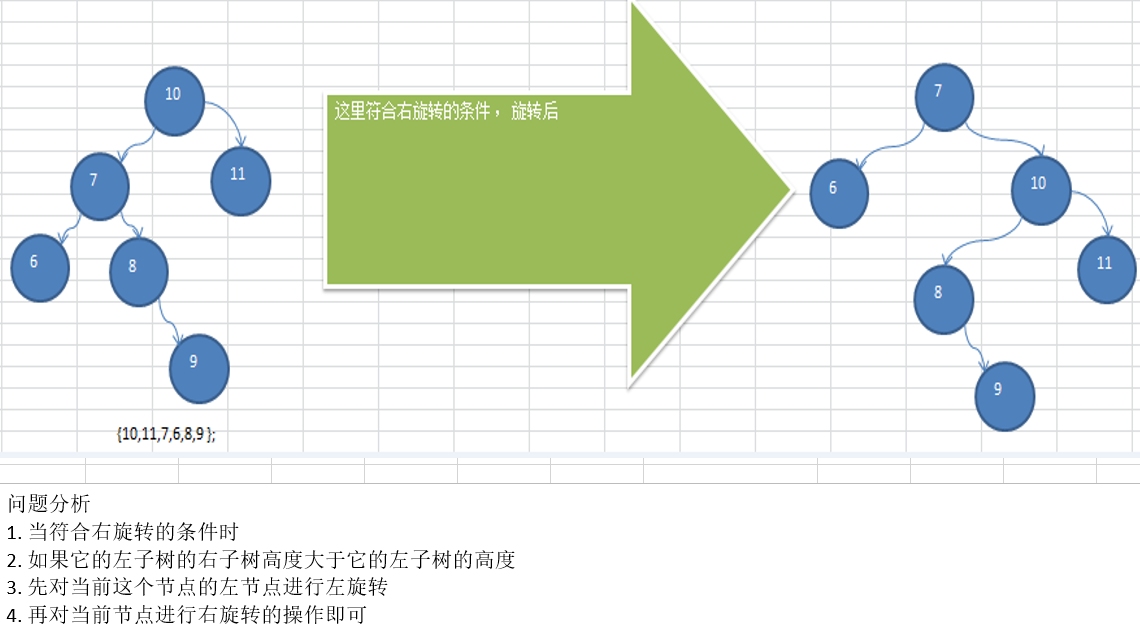
package com.atguigu.avl;
public class AVLTreeDemo {
public static void main(String[] args) {
//int[] arr = {4,3,6,5,7,8};
//int[] arr = { 10, 12, 8, 9, 7, 6 };
int[] arr = { 10, 11, 7, 6, 8, 9 };
//创建一个 AVLTree对象
AVLTree avlTree = new AVLTree();
//添加结点
for(int i=0; i < arr.length; i++) {
avlTree.add(new Node(arr[i]));
}
//遍历
System.out.println("中序遍历");
avlTree.infixOrder();
System.out.println("在平衡处理~~");
System.out.println("树的高度=" + avlTree.getRoot().height()); //3
System.out.println("树的左子树高度=" + avlTree.getRoot().leftHeight()); // 2
System.out.println("树的右子树高度=" + avlTree.getRoot().rightHeight()); // 2
System.out.println("当前的根结点=" + avlTree.getRoot());//8
}
}
// 创建AVLTree
class AVLTree {
private Node root;
public Node getRoot() {
return root;
}
// 查找要删除的结点
public Node search(int value) {
if (root == null) {
return null;
} else {
return root.search(value);
}
}
// 查找父结点
public Node searchParent(int value) {
if (root == null) {
return null;
} else {
return root.searchParent(value);
}
}
// 编写方法:
// 1. 返回的 以node 为根结点的二叉排序树的最小结点的值
// 2. 删除node 为根结点的二叉排序树的最小结点
/**
*
* @param node
* 传入的结点(当做二叉排序树的根结点)
* @return 返回的 以node 为根结点的二叉排序树的最小结点的值
*/
public int delRightTreeMin(Node node) {
Node target = node;
// 循环的查找左子节点,就会找到最小值
while (target.left != null) {
target = target.left;
}
// 这时 target就指向了最小结点
// 删除最小结点
delNode(target.value);
return target.value;
}
// 删除结点
public void delNode(int value) {
if (root == null) {
return;
} else {
// 1.需求先去找到要删除的结点 targetNode
Node targetNode = search(value);
// 如果没有找到要删除的结点
if (targetNode == null) {
return;
}
// 如果我们发现当前这颗二叉排序树只有一个结点
if (root.left == null && root.right == null) {
root = null;
return;
}
// 去找到targetNode的父结点
Node parent = searchParent(value);
// 如果要删除的结点是叶子结点
if (targetNode.left == null && targetNode.right == null) {
// 判断targetNode 是父结点的左子结点,还是右子结点
if (parent.left != null && parent.left.value == value) { // 是左子结点
parent.left = null;
} else if (parent.right != null && parent.right.value == value) {// 是由子结点
parent.right = null;
}
} else if (targetNode.left != null && targetNode.right != null) { // 删除有两颗子树的节点
int minVal = delRightTreeMin(targetNode.right);
targetNode.value = minVal;
} else { // 删除只有一颗子树的结点
// 如果要删除的结点有左子结点
if (targetNode.left != null) {
if (parent != null) {
// 如果 targetNode 是 parent 的左子结点
if (parent.left.value == value) {
parent.left = targetNode.left;
} else { // targetNode 是 parent 的右子结点
parent.right = targetNode.left;
}
} else {
root = targetNode.left;
}
} else { // 如果要删除的结点有右子结点
if (parent != null) {
// 如果 targetNode 是 parent 的左子结点
if (parent.left.value == value) {
parent.left = targetNode.right;
} else { // 如果 targetNode 是 parent 的右子结点
parent.right = targetNode.right;
}
} else {
root = targetNode.right;
}
}
}
}
}
// 添加结点的方法
public void add(Node node) {
if (root == null) {
root = node;// 如果root为空则直接让root指向node
} else {
root.add(node);
}
}
// 中序遍历
public void infixOrder() {
if (root != null) {
root.infixOrder();
} else {
System.out.println("二叉排序树为空,不能遍历");
}
}
}
// 创建Node结点
class Node {
int value;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
// 返回左子树的高度
public int leftHeight() {
if (left == null) {
return 0;
}
return left.height();
}
// 返回右子树的高度
public int rightHeight() {
if (right == null) {
return 0;
}
return right.height();
}
// 返回 以该结点为根结点的树的高度
public int height() {
return Math.max(left == null ? 0 : left.height(), right == null ? 0 : right.height()) + 1;
}
//左旋转方法
private void leftRotate() {
//创建新的节点,以当前根节点的值
Node newNode = new Node(value);
//把新的节点的左子树设置成当前节点的左子树
newNode.left = left;
//把新的节点的右子树设置成当前节点的右子树的左子树
newNode.right = right.left;
//把当前节点的值替换成右子节点的值
value = right.value;
//把当前节点的右子树设置成当前节点右子树的右子树
right = right.right;
//把当前节点的左子树(左子结点)设置成新的节点
left = newNode;
}
//右旋转
private void rightRotate() {
Node newNode = new Node(value);
newNode.right = right;
newNode.left = left.right;
value = left.value;
left = left.left;
right = newNode;
}
// 查找要删除的结点
/**
*
* @param value
* 希望删除的结点的值
* @return 如果找到返回该结点,否则返回null
*/
public Node search(int value) {
if (value == this.value) { // 找到就是该结点
return this;
} else if (value < this.value) {// 如果查找的值小于当前结点,向左子树递归查找
// 如果左子结点为空
if (this.left == null) {
return null;
}
return this.left.search(value);
} else { // 如果查找的值不小于当前结点,向右子树递归查找
if (this.right == null) {
return null;
}
return this.right.search(value);
}
}
// 查找要删除结点的父结点
/**
*
* @param value
* 要找到的结点的值
* @return 返回的是要删除的结点的父结点,如果没有就返回null
*/
public Node searchParent(int value) {
// 如果当前结点就是要删除的结点的父结点,就返回
if ((this.left != null && this.left.value == value) || (this.right != null && this.right.value == value)) {
return this;
} else {
// 如果查找的值小于当前结点的值, 并且当前结点的左子结点不为空
if (value < this.value && this.left != null) {
return this.left.searchParent(value); // 向左子树递归查找
} else if (value >= this.value && this.right != null) {
return this.right.searchParent(value); // 向右子树递归查找
} else {
return null; // 没有找到父结点
}
}
}
@Override
public String toString() {
return "Node [value=" + value + "]";
}
// 添加结点的方法
// 递归的形式添加结点,注意需要满足二叉排序树的要求
public void add(Node node) {
if (node == null) {
return;
}
// 判断传入的结点的值,和当前子树的根结点的值关系
if (node.value < this.value) {
// 如果当前结点左子结点为null
if (this.left == null) {
this.left = node;
} else {
// 递归的向左子树添加
this.left.add(node);
}
} else { // 添加的结点的值大于 当前结点的值
if (this.right == null) {
this.right = node;
} else {
// 递归的向右子树添加
this.right.add(node);
}
}
//当添加完一个结点后,如果: (右子树的高度-左子树的高度) > 1 , 左旋转
if(rightHeight() - leftHeight() > 1) {
//如果它的右子树的左子树的高度大于它的右子树的右子树的高度
if(right != null && right.leftHeight() > right.rightHeight()) {
//先对右子结点进行右旋转
right.rightRotate();
//然后在对当前结点进行左旋转
leftRotate(); //左旋转..
} else {
//直接进行左旋转即可
leftRotate();
}
return ; //必须要!!!
}
//当添加完一个结点后,如果 (左子树的高度 - 右子树的高度) > 1, 右旋转
if(leftHeight() - rightHeight() > 1) {
//如果它的左子树的右子树高度大于它的左子树的高度
if(left != null && left.rightHeight() > left.leftHeight()) {
//先对当前结点的左结点(左子树)->左旋转
left.leftRotate();
//再对当前结点进行右旋转
rightRotate();
} else {
//直接进行右旋转即可
rightRotate();
}
}
}
// 中序遍历
public void infixOrder() {
if (this.left != null) {
this.left.infixOrder();
}
System.out.println(this);
if (this.right != null) {
this.right.infixOrder();
}
}
}
第12章 多路查找树
12.1 二叉树与B树
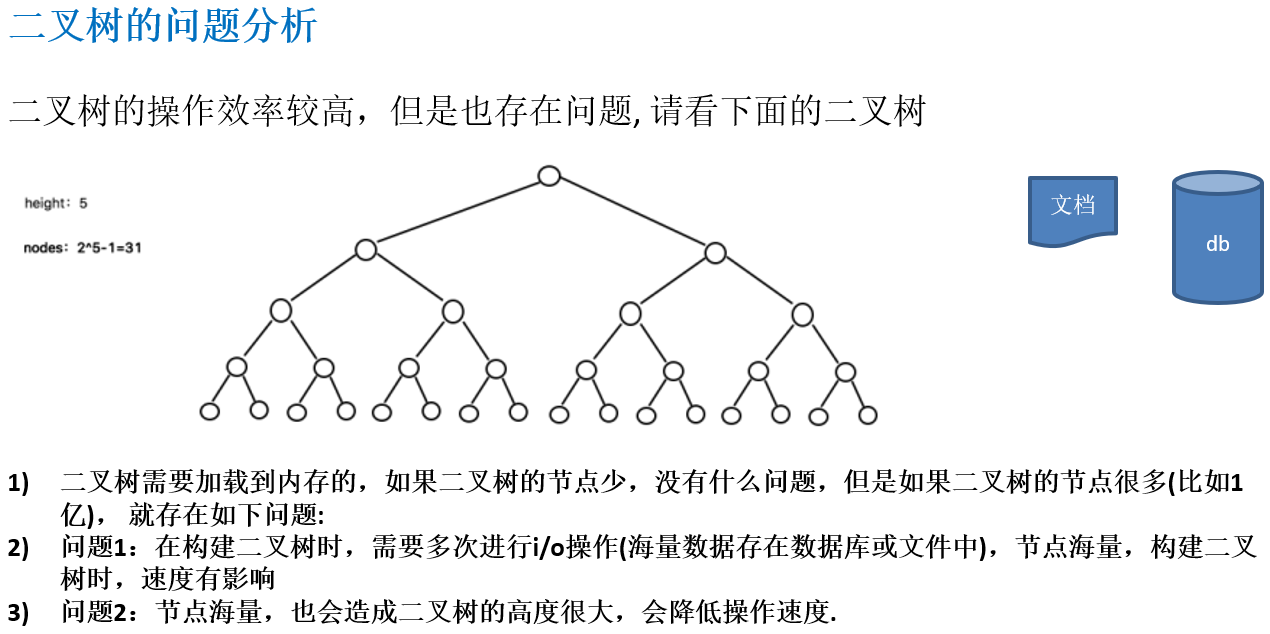
12.1.1 二叉树的问题分析
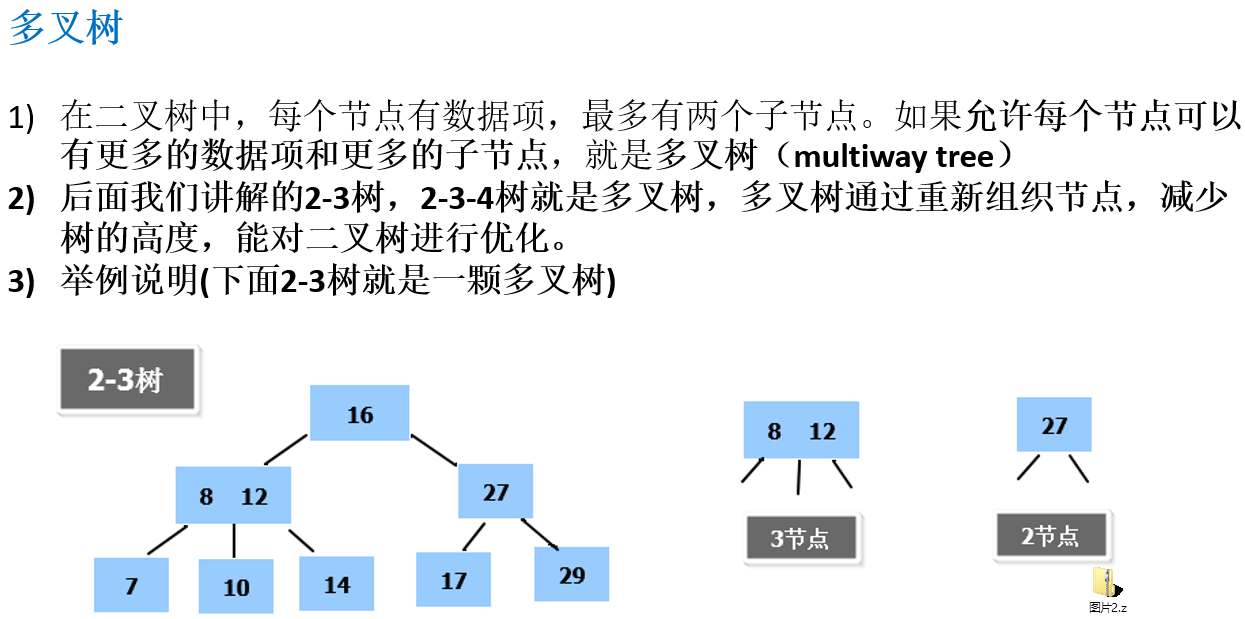
12.1.2 多叉树
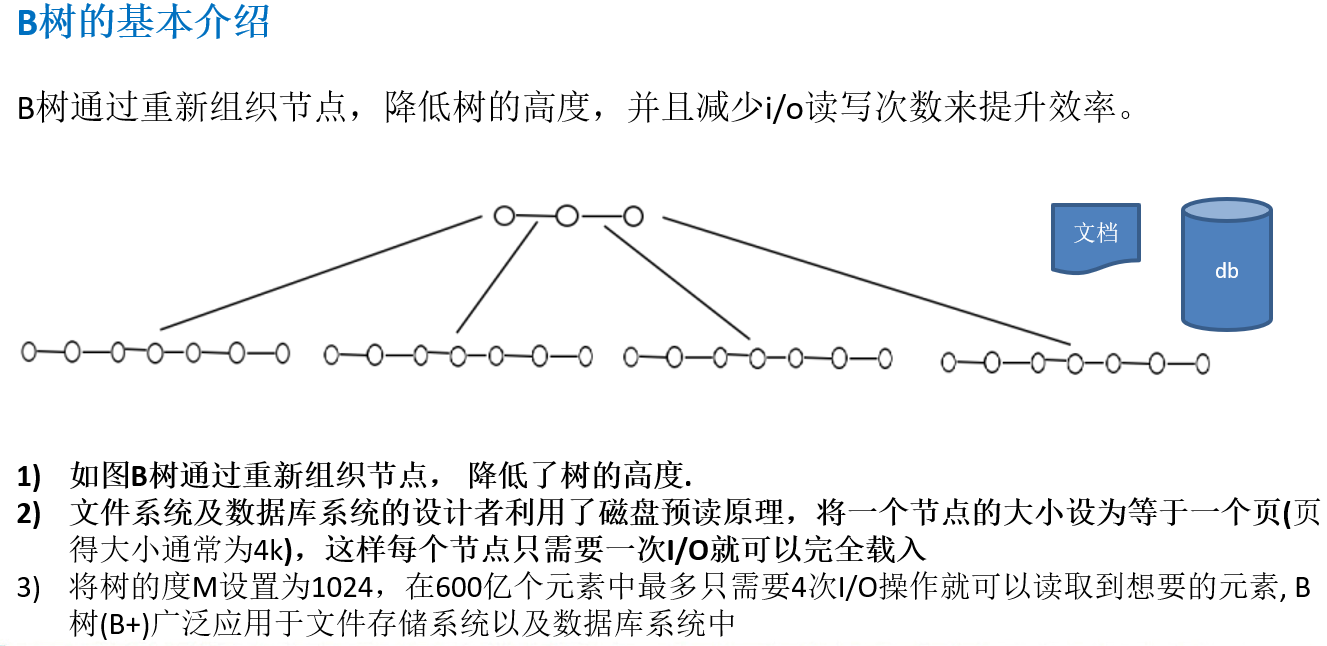
12.1.3 B树的基本介绍
12.2 2-3树
12.2.1 2-3树基本介绍

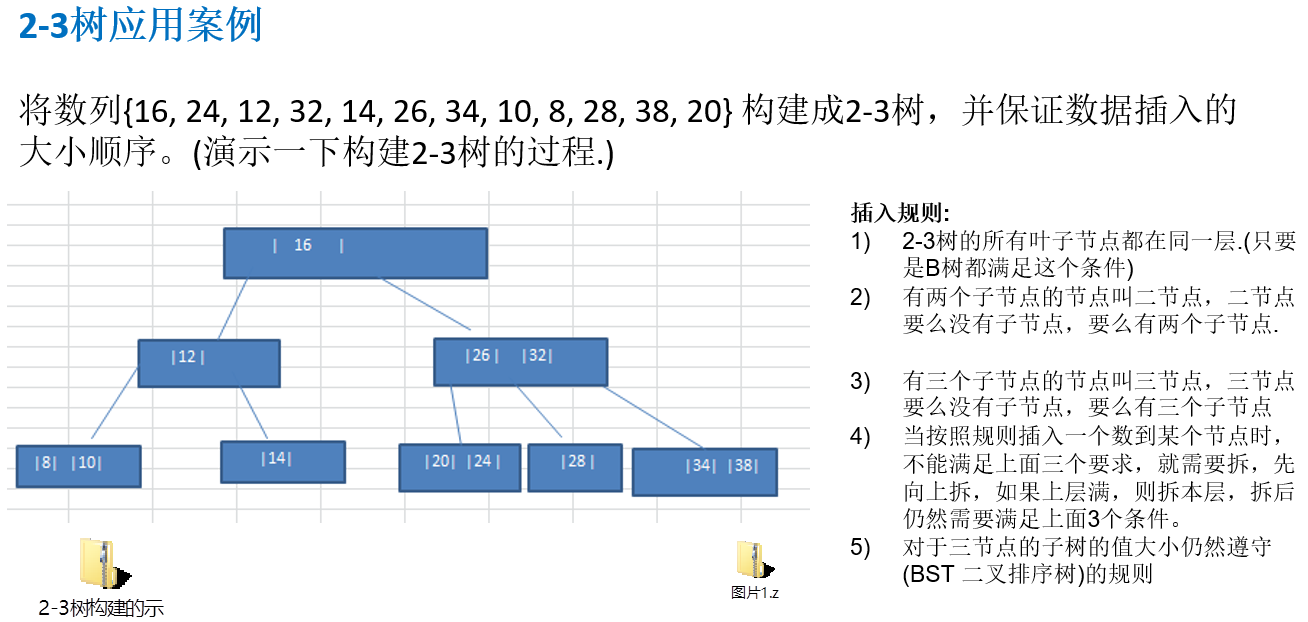
12.2.2 2-3树应用案例
12.2.3 其它说明
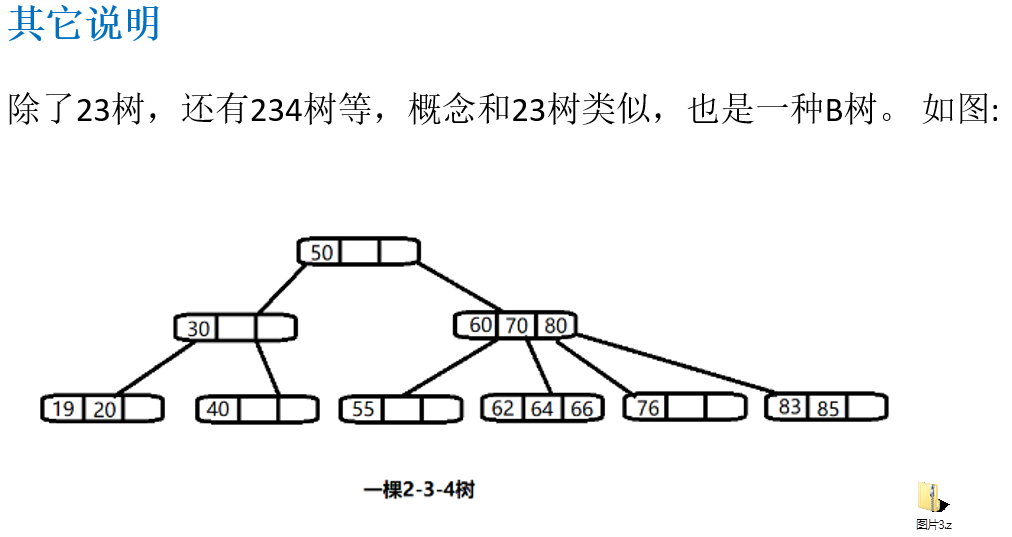
12.3 B树、B+树和B*树(Balanced)★
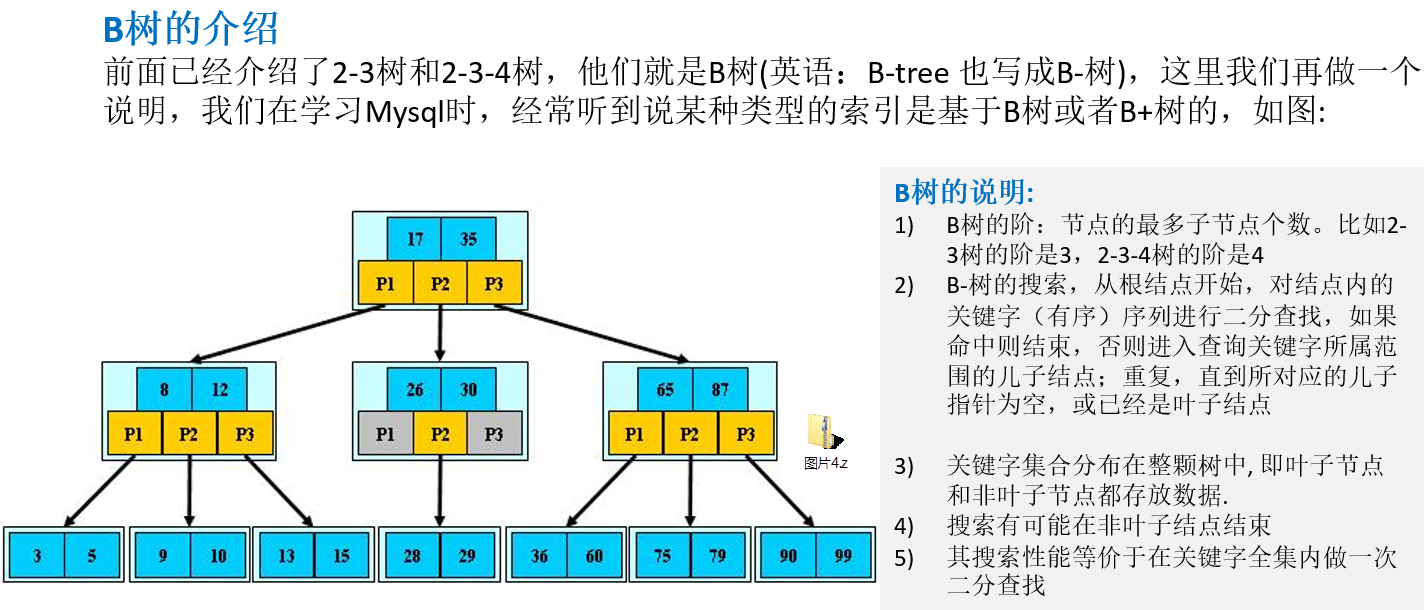
12.3.1 B树的介绍

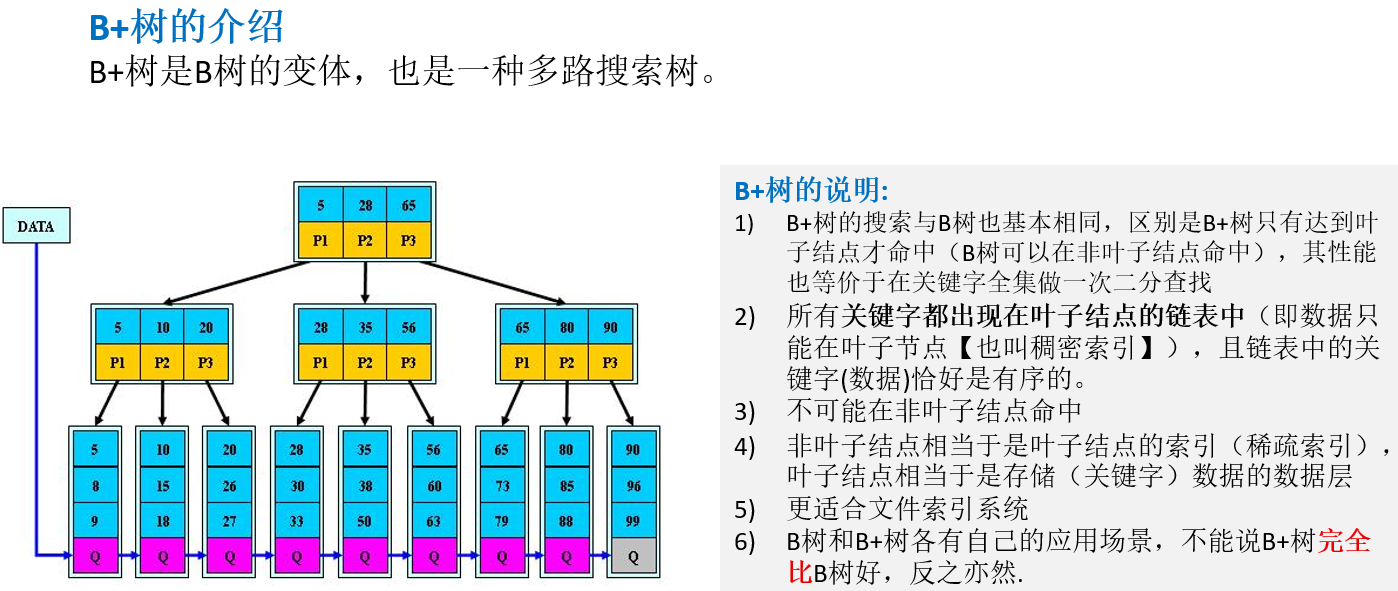
12.3.2 B+树的介绍
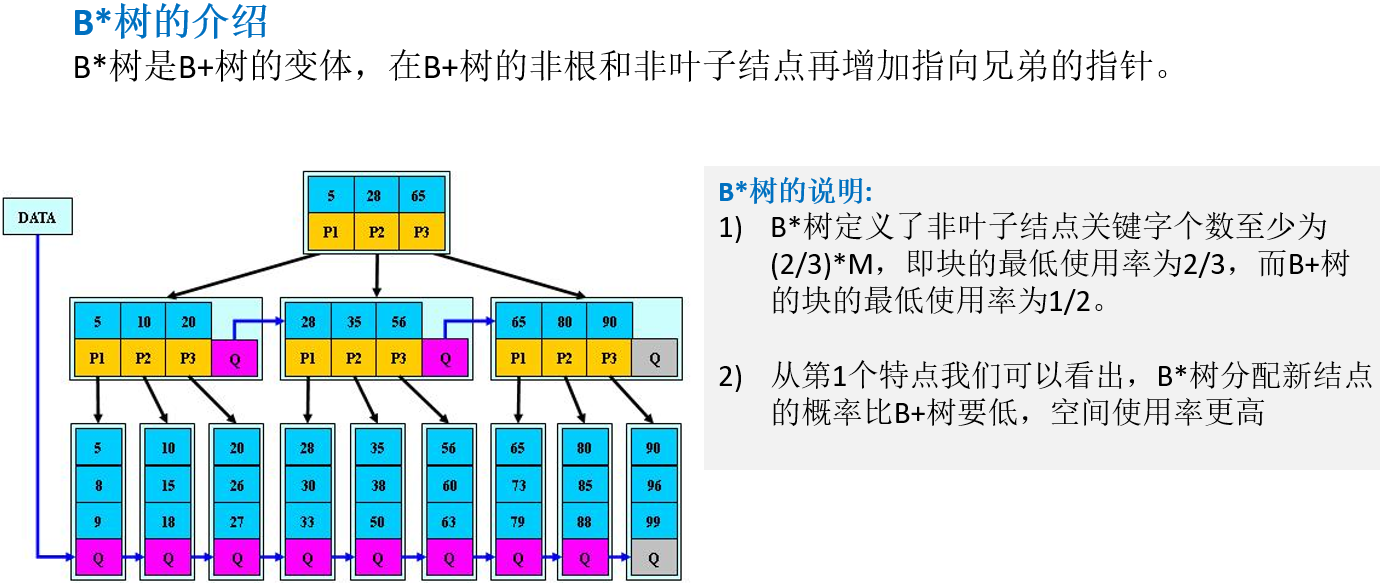
12.3.3 B*树的介绍
第13章 图
13.1 图基本介绍
13.1.1 为什么要有图

13.1.2 图的举例说明

13.1.3 图的常用概念
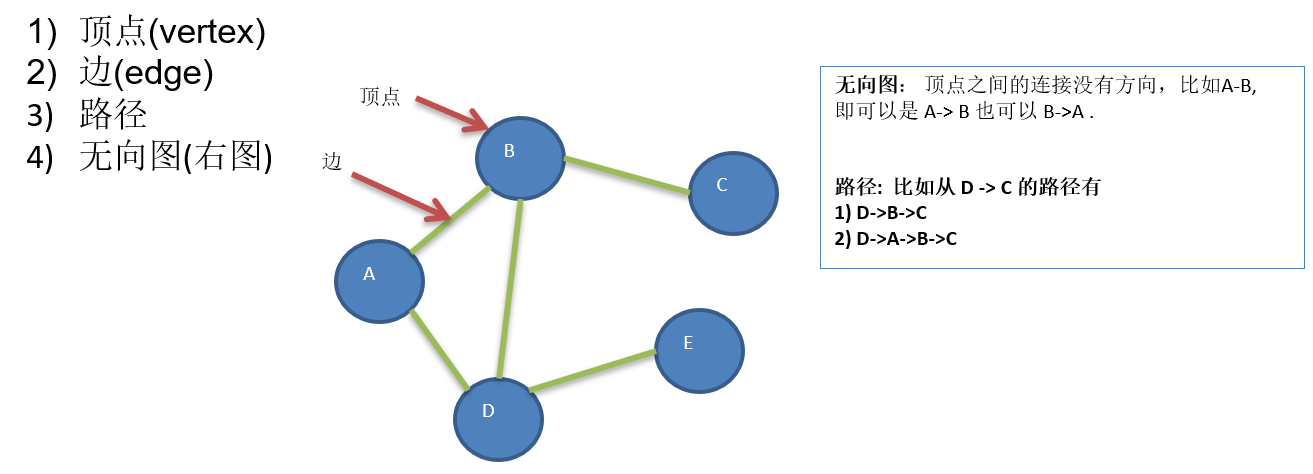
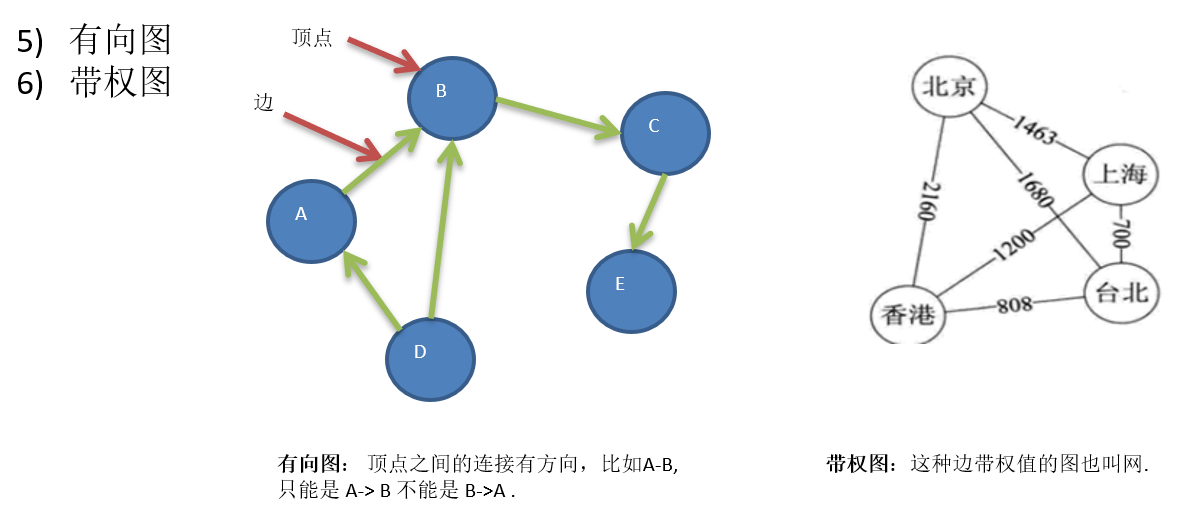
13.2 图的表示方式
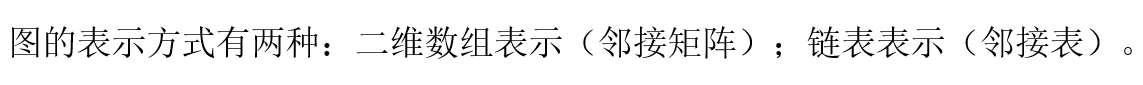
13.2.1 邻接矩阵
13.2.2 邻接表
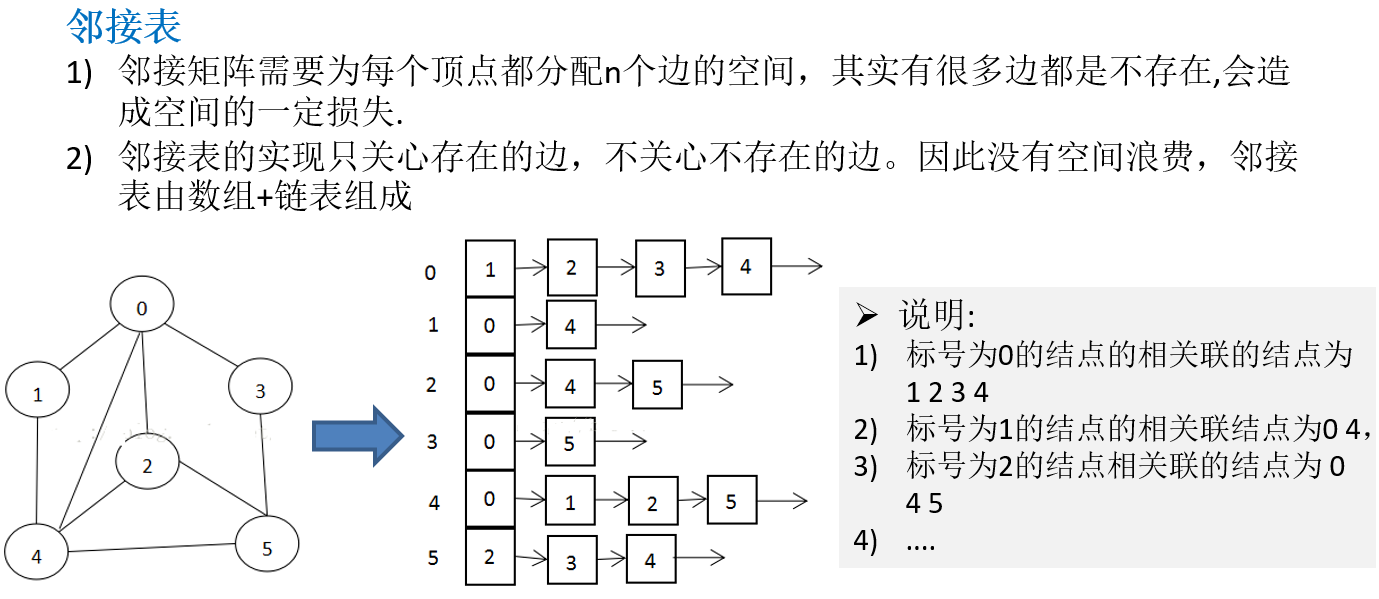
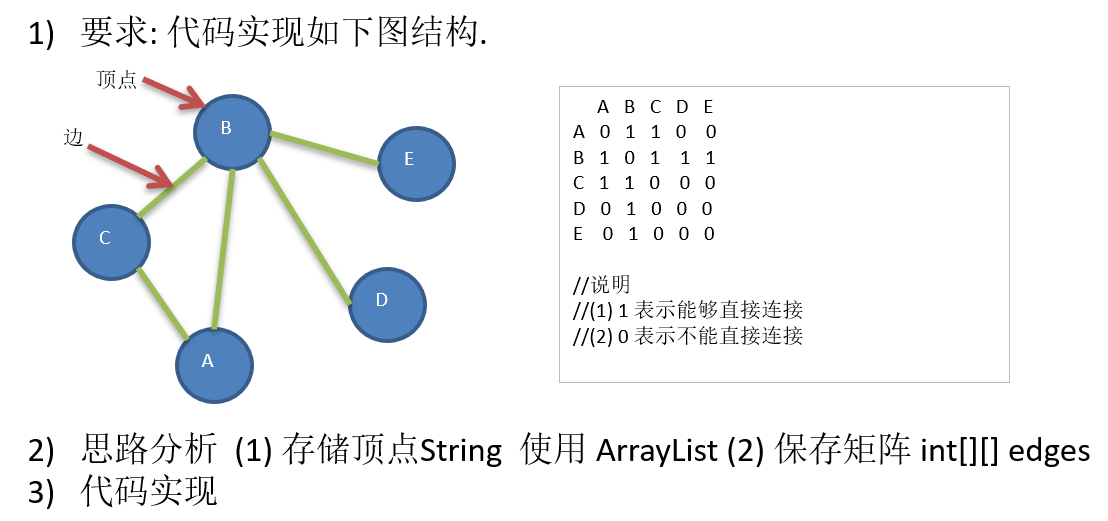
13.3 图的快速入门案例
13.4 图的深度优先遍历介绍(Depth First Search,DFS)
13.4.1 图遍历介绍

13.4.2 深度优先遍历基本思想

13.4.3 深度优先遍历算法步骤
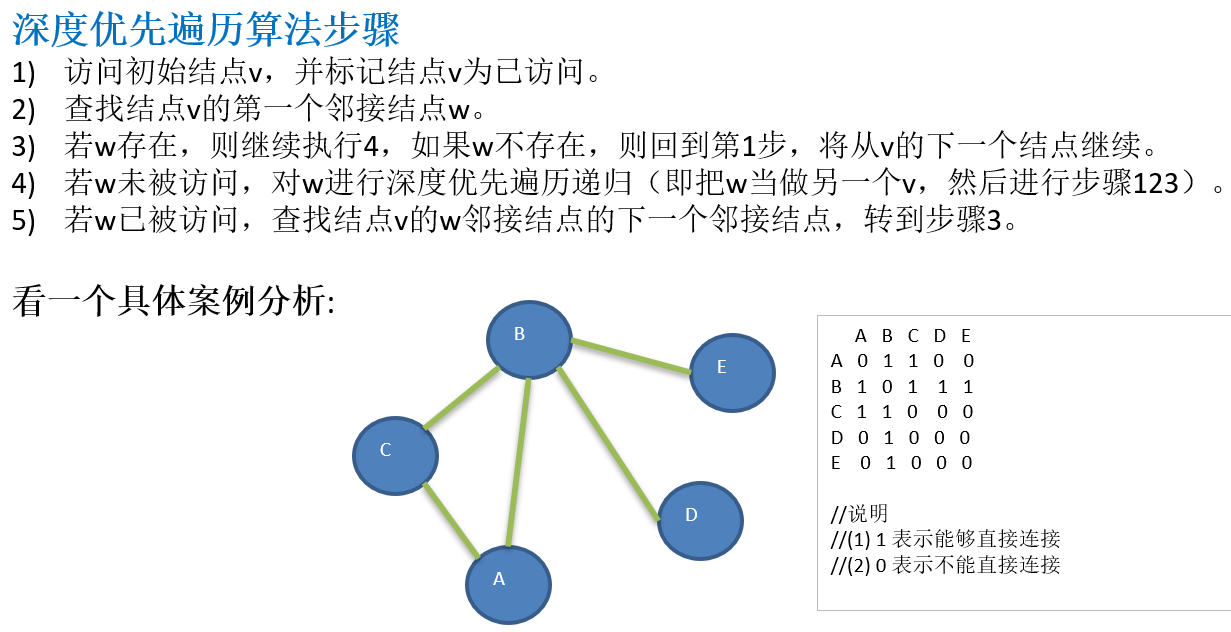
13.4.4 深度优先算法的代码实现
//深度优先遍历算法
//i 第一次就是 0
private void dfs(boolean[] isVisited, int i) {
//首先我们访问该结点,输出
System.out.print(getValueByIndex(i) + "->");
//将结点设置为已经访问
isVisited[i] = true;
//查找结点i的第一个邻接结点w
int w = getFirstNeighbor(i);
while(w != -1) {//说明有
if(!isVisited[w]) {
dfs(isVisited, w);
}
//如果w结点已经被访问过
w = getNextNeighbor(i, w);
}
}
//对dfs 进行一个重载, 遍历我们所有的结点,并进行 dfs
public void dfs() {
isVisited = new boolean[vertexList.size()];
//遍历所有的结点,进行dfs[回溯]
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
dfs(isVisited, i);
}
}
}13.5 图的广度优先遍历(Broad First Search,BFS)
13.5.1 广度优先遍历基本思想

13.5.2 广度优先遍历算法步骤

13.5.3 广度优先算法的图示
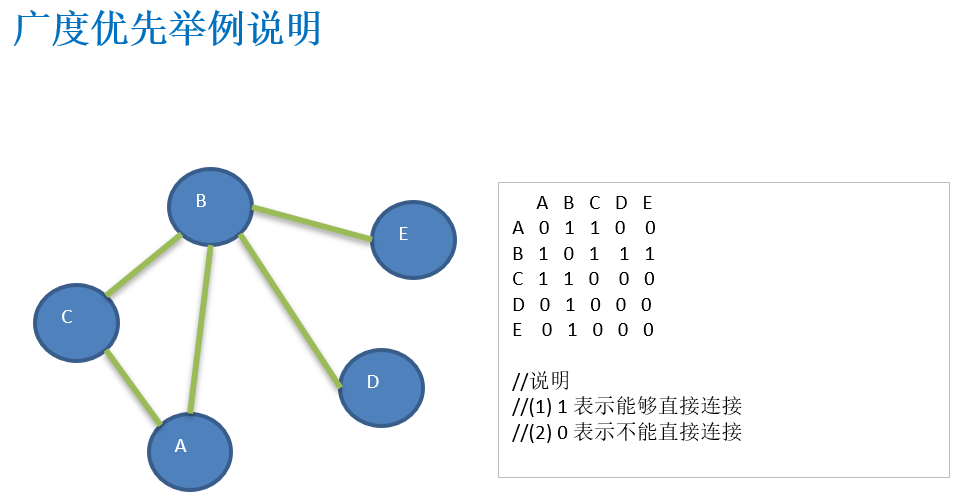
13.5.4 广度优先算法的代码实现
//对一个结点进行广度优先遍历的方法
private void bfs(boolean[] isVisited, int i) {
int u ; // 表示队列的头结点对应下标
int w ; // 邻接结点w
//队列,记录结点访问的顺序
LinkedList queue = new LinkedList();
//访问结点,输出结点信息
System.out.print(getValueByIndex(i) + "=>");
//标记为已访问
isVisited[i] = true;
//将结点加入队列
queue.addLast(i);
while( !queue.isEmpty()) {
//取出队列的头结点下标
u = (Integer)queue.removeFirst();
//得到第一个邻接结点的下标 w
w = getFirstNeighbor(u);
while(w != -1) {//找到
//是否访问过
if(!isVisited[w]) {
System.out.print(getValueByIndex(w) + "=>");
//标记已经访问
isVisited[w] = true;
//入队
queue.addLast(w);
}
//以u为前驱点,找w后面的下一个邻结点
w = getNextNeighbor(u, w); //体现出我们的广度优先
}
}
}
//遍历所有的结点,都进行广度优先搜索
public void bfs() {
isVisited = new boolean[vertexList.size()];
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
bfs(isVisited, i);
}
}
}13.6 图的代码汇总
package com.atguigu.graph;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
public class Graph {
private ArrayList<String> vertexList; //存储顶点集合
private int[][] edges; //存储图对应的邻结矩阵
private int numOfEdges; //表示边的数目
//定义一个数组boolean[], 记录某个结点是否被访问
private boolean[] isVisited;
public static void main(String[] args) {
//测试一把图是否创建ok
int n = 8; //结点的个数
//String Vertexs[] = {"A", "B", "C", "D", "E"};
String Vertexs[] = {"1", "2", "3", "4", "5", "6", "7", "8"};
//创建图对象
Graph graph = new Graph(n);
//循环的添加顶点
for(String vertex: Vertexs) {
graph.insertVertex(vertex);
}
//添加边
//A-B A-C B-C B-D B-E
// graph.insertEdge(0, 1, 1); // A-B
// graph.insertEdge(0, 2, 1); //
// graph.insertEdge(1, 2, 1); //
// graph.insertEdge(1, 3, 1); //
// graph.insertEdge(1, 4, 1); //
//更新边的关系
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.insertEdge(3, 7, 1);
graph.insertEdge(4, 7, 1);
graph.insertEdge(2, 5, 1);
graph.insertEdge(2, 6, 1);
graph.insertEdge(5, 6, 1);
//显示一把邻结矩阵
graph.showGraph();
//测试一把,我们的dfs遍历是否ok
System.out.println("深度遍历");
graph.dfs(); // A->B->C->D->E [1->2->4->8->5->3->6->7]
// System.out.println();
System.out.println("广度优先!");
graph.bfs(); // A->B->C->D-E [1->2->3->4->5->6->7->8]
}
//构造器
public Graph(int n) {
//初始化矩阵和vertexList
edges = new int[n][n];
vertexList = new ArrayList<String>(n);
numOfEdges = 0;
}
//得到第一个邻接结点的下标 w
/**
*
* @param index
* @return 如果存在就返回对应的下标,否则返回-1
*/
public int getFirstNeighbor(int index) {
for(int j = 0; j < vertexList.size(); j++) {
if(edges[index][j] > 0) {
return j;
}
}
return -1;
}
//根据前一个邻接结点的下标来获取下一个邻接结点
public int getNextNeighbor(int v1, int v2) {
for(int j = v2 + 1; j < vertexList.size(); j++) {
if(edges[v1][j] > 0) {
return j;
}
}
return -1;
}
//深度优先遍历算法
//i 第一次就是 0
private void dfs(boolean[] isVisited, int i) {
//首先我们访问该结点,输出
System.out.print(getValueByIndex(i) + "->");
//将结点设置为已经访问
isVisited[i] = true;
//查找结点i的第一个邻接结点w
int w = getFirstNeighbor(i);
while(w != -1) {//说明有
if(!isVisited[w]) {
dfs(isVisited, w);
}
//如果w结点已经被访问过
w = getNextNeighbor(i, w);
}
}
//对dfs 进行一个重载, 遍历我们所有的结点,并进行 dfs
public void dfs() {
isVisited = new boolean[vertexList.size()];
//遍历所有的结点,进行dfs[回溯]
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
dfs(isVisited, i);
}
}
}
//对一个结点进行广度优先遍历的方法
private void bfs(boolean[] isVisited, int i) {
int u ; // 表示队列的头结点对应下标
int w ; // 邻接结点w
//队列,记录结点访问的顺序
LinkedList queue = new LinkedList();
//访问结点,输出结点信息
System.out.print(getValueByIndex(i) + "=>");
//标记为已访问
isVisited[i] = true;
//将结点加入队列
queue.addLast(i);
while( !queue.isEmpty()) {
//取出队列的头结点下标
u = (Integer)queue.removeFirst();
//得到第一个邻接结点的下标 w
w = getFirstNeighbor(u);
while(w != -1) {//找到
//是否访问过
if(!isVisited[w]) {
System.out.print(getValueByIndex(w) + "=>");
//标记已经访问
isVisited[w] = true;
//入队
queue.addLast(w);
}
//以u为前驱点,找w后面的下一个邻结点
w = getNextNeighbor(u, w); //体现出我们的广度优先
}
}
}
//遍历所有的结点,都进行广度优先搜索
public void bfs() {
isVisited = new boolean[vertexList.size()];
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
bfs(isVisited, i);
}
}
}
//图中常用的方法
//返回结点的个数
public int getNumOfVertex() {
return vertexList.size();
}
//显示图对应的矩阵
public void showGraph() {
for(int[] link : edges) {
System.err.println(Arrays.toString(link));
}
}
//得到边的数目
public int getNumOfEdges() {
return numOfEdges;
}
//返回结点i(下标)对应的数据 0->"A" 1->"B" 2->"C"
public String getValueByIndex(int i) {
return vertexList.get(i);
}
//返回v1和v2的权值
public int getWeight(int v1, int v2) {
return edges[v1][v2];
}
//插入结点
public void insertVertex(String vertex) {
vertexList.add(vertex);
}
//添加边
/**
*
* @param v1 表示点的下标即使第几个顶点 "A"-"B" "A"->0 "B"->1
* @param v2 第二个顶点对应的下标
* @param weight 表示
*/
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges++;
}
}
13.7 图的深度优先VS广度优先
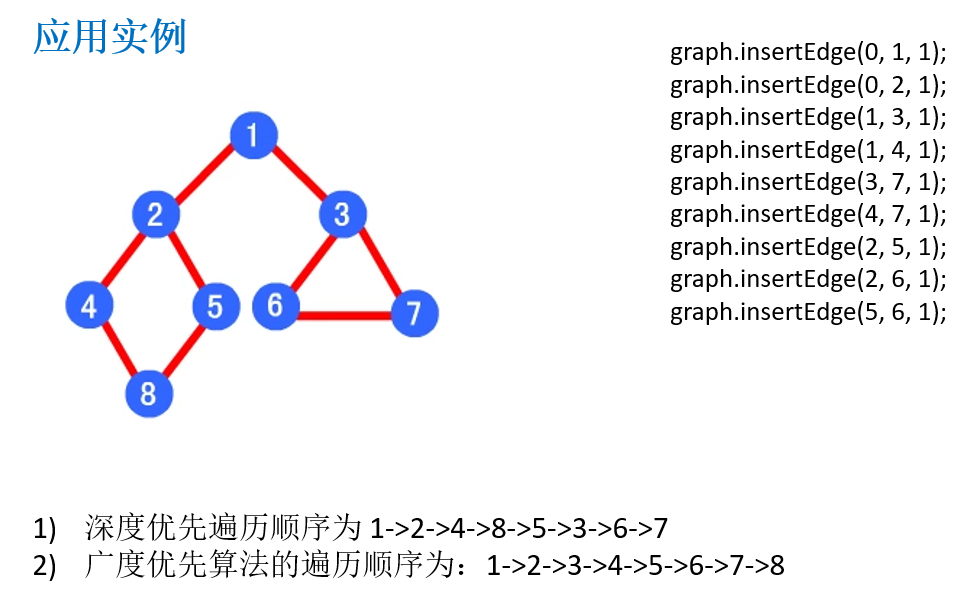
第14章 程序员常用10种算法
14.1 二分查找算法(非递归)
14.1.1 二分查找算法(非递归)介绍

14.1.2 二分查找算法(非递归)代码实现

package com.atguigu.binarysearchnorecursion;
public class BinarySearchNoRecur {
public static void main(String[] args) {
//测试
int[] arr = {1,3, 8, 10, 11, 67, 100};
int index = binarySearch(arr, 100);
System.out.println("index=" + index);//
}
//二分查找的非递归实现
/**
*
* @param arr 待查找的数组, arr是升序排序
* @param target 需要查找的数
* @return 返回对应下标,-1表示没有找到
*/
public static int binarySearch(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while(left <= right) { //说明继续查找
int mid = (left + right) / 2;
if(arr[mid] == target) {
return mid;
} else if ( arr[mid] > target) {
right = mid - 1;//需要向左边查找
} else {
left = mid + 1; //需要向右边查找
}
}
return -1;
}
}
14.2 分治算法
14.2.1 分治算法介绍

14.2.2 分治算法的基本步骤

14.2.3 分治(Divide-and-Conquer(P))算法设计模式如下

14.2.4 分治算法最佳实践-汉诺塔


package com.atguigu.dac;
public class Hanoitower {
public static void main(String[] args) {
hanoiTower(64, 'A', 'B', 'C');
}
//汉诺塔的移动的方法
//使用分治算法
public static void hanoiTower(int num, char a, char b, char c) {
//如果只有一个盘
if(num == 1) {
System.out.println("第1个盘从 " + a + "->" + c);
} else {
//如果我们有 n >= 2 情况,我们总是可以看做是两个盘 1.最下边的一个盘 2. 上面的所有盘
//1. 先把 最上面的所有盘 A->B, 移动过程会使用到 c
hanoiTower(num - 1, a, c, b);
//2. 把最下边的盘 A->C
System.out.println("第" + num + "个盘从 " + a + "->" + c);
//3. 把B塔的所有盘 从 B->C , 移动过程使用到 a塔
hanoiTower(num - 1, b, a, c);
}
}
}
14.3 动态规划算法(Dynamic Programming)
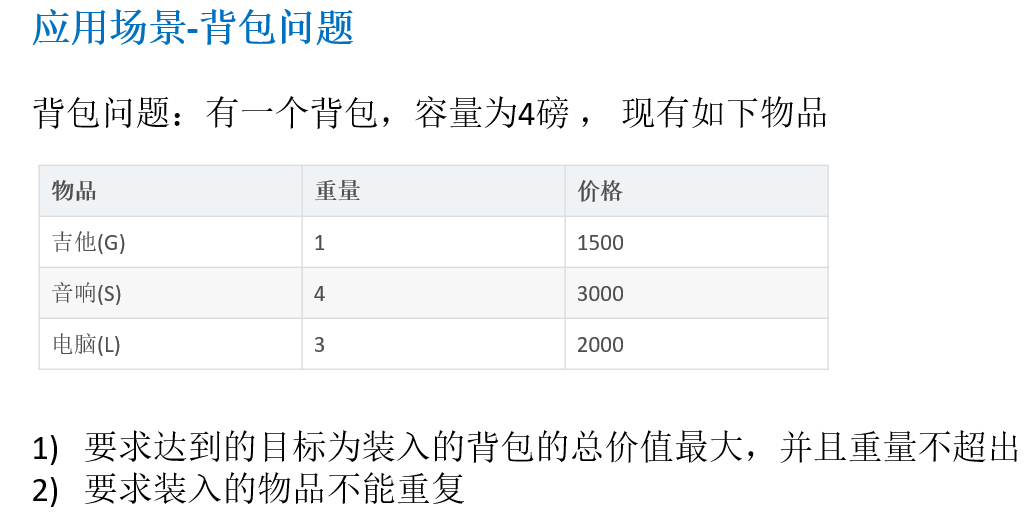
14.3.1 应用场景-背包问题(Knapsack Problem)
14.3.2 动态规划算法介绍

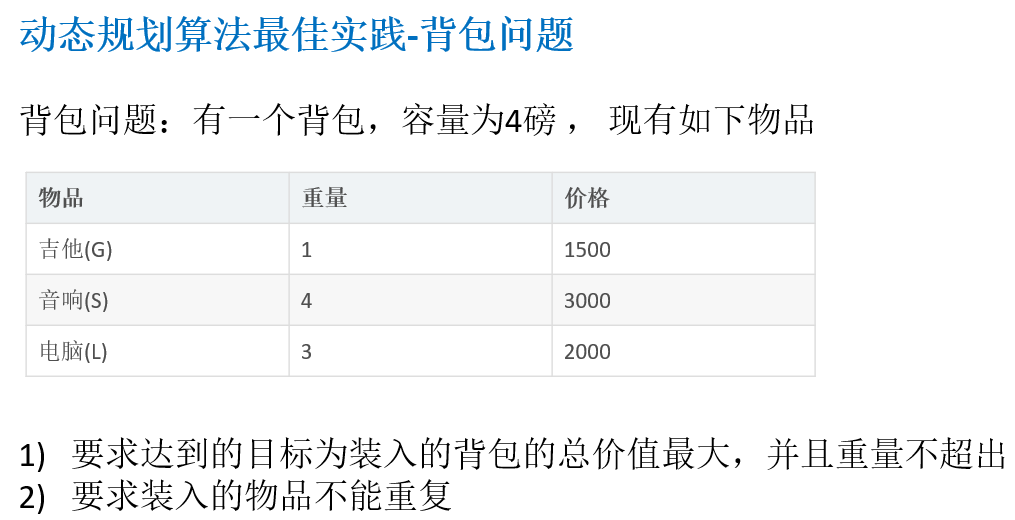
14.3.3 动态规划算法最佳实践-背包问题
思路分析和图解


图解的分析
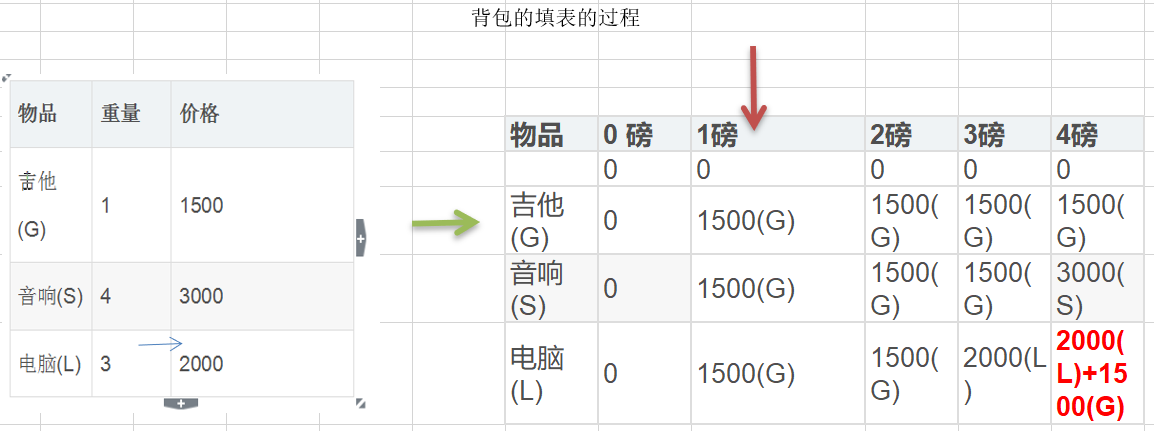

14.3.4 动态规划-背包问题的代码实现
package com.atguigu.dynamic;
public class KnapsackProblem {
public static void main(String[] args) {
int[] w = {1, 4, 3};//物品的重量
int[] val = {1500, 3000, 2000}; //物品的价值 这里val[i] 就是前面讲的v[i]
int m = 4; //背包的容量
int n = val.length; //物品的个数
//创建二维数组,
//v[i][j] 表示在前i个物品中能够装入容量为j的背包中的最大价值
int[][] v = new int[n + 1][m + 1];
//为了记录放入商品的情况,我们定一个二维数组
int[][] path = new int[n + 1][m + 1];
//初始化第一行和第一列, 这里在本程序中,可以不去处理,因为默认就是0
for (int i = 0; i < v.length; i++) {
v[i][0] = 0; //将第一列设置为0
}
for (int i = 0; i < v[0].length; i++) {
v[0][i] = 0; //将第一行设置0
}
//根据前面得到公式来动态规划处理
for (int i = 1; i < v.length; i++) { //不处理第一行 i是从1开始的
for (int j = 1; j < v[0].length; j++) {//不处理第一列, j是从1开始的
//公式
if (w[i - 1] > j) { // 因为我们程序i 是从1开始的,因此原来公式中的 w[i] 修改成 w[i-1]
v[i][j] = v[i - 1][j];
} else {
//说明:
//因为我们的i 从1开始的, 因此公式需要调整成
//v[i][j]=Math.max(v[i-1][j], val[i-1]+v[i-1][j-w[i-1]]);
//v[i][j] = Math.max(v[i - 1][j], val[i - 1] + v[i - 1][j - w[i - 1]]);
//为了记录商品存放到背包的情况,我们不能直接的使用上面的公式,需要使用if-else来体现公式
if (v[i - 1][j] < val[i - 1] + v[i - 1][j - w[i - 1]]) {
v[i][j] = val[i - 1] + v[i - 1][j - w[i - 1]];
//把当前的情况记录到path
path[i][j] = 1;
} else {
v[i][j] = v[i - 1][j];
}
}
}
}
//输出一下v 看看目前的情况
for (int i = 0; i < v.length; i++) {
for (int j = 0; j < v[i].length; j++) {
System.out.print(v[i][j] + " ");
}
System.out.println();
}
System.out.println("============================");
//输出最后我们是放入的哪些商品
//遍历path, 这样输出会把所有的放入情况都得到, 其实我们只需要最后的放入
// for(int i = 0; i < path.length; i++) {
// for(int j=0; j < path[i].length; j++) {
// if(path[i][j] == 1) {
// System.out.printf("第%d个商品放入到背包\n", i);
// }
// }
// }
//动脑筋
int i = path.length - 1; //行的最大下标
int j = path[0].length - 1; //列的最大下标
while (i > 0 && j > 0) { //从path的最后开始找
if (path[i][j] == 1) {
System.out.printf("第%d个商品放入到背包\n", i);
j -= w[i - 1]; //w[i-1]
}
i--;
}
}
}
14.4 KMP算法
14.4.1 应用场景-字符串匹配问题

14.4.2 暴力匹配算法

package com.atguigu.kmp;
public class ViolenceMatch {
public static void main(String[] args) {
//测试暴力匹配算法
String str1 = "硅硅谷 尚硅谷你尚硅 尚硅谷你尚硅谷你尚硅你好";
String str2 = "尚硅谷你尚硅你~";
int index = violenceMatch(str1, str2);
System.out.println("index=" + index);
}
// 暴力匹配算法实现
public static int violenceMatch(String str1, String str2) {
char[] s1 = str1.toCharArray();
char[] s2 = str2.toCharArray();
int s1Len = s1.length;
int s2Len = s2.length;
int i = 0; // i索引指向s1
int j = 0; // j索引指向s2
while (i < s1Len && j < s2Len) {// 保证匹配时,不越界
if(s1[i] == s2[j]) {//匹配ok
i++;
j++;
} else { //没有匹配成功
//如果失配(即str1[i]! = str2[j]),令i = i - (j - 1),j = 0。
i = i - (j - 1);
j = 0;
}
}
//判断是否匹配成功
if(j == s2Len) {
return i - j;
} else {
return -1;
}
}
}
14.4.3 KMP算法介绍

14.4.4 KMP算法最佳应用-字符串匹配问题



package com.atguigu.kmp;
import java.util.Arrays;
public class KMPAlgorithm {
public static void main(String[] args) {
String str1 = "BBC ABCDAB ABCDABCDABDE";
String str2 = "ABCDABD";
//String str2 = "BBC";
int[] next = kmpNext("ABCDABD"); //[0, 1, 2, 0]
System.out.println("next=" + Arrays.toString(next));
int index = kmpSearch(str1, str2, next);
System.out.println("index=" + index); // 15了
}
//写出我们的kmp搜索算法
/**
*
* @param str1 源字符串
* @param str2 子串
* @param next 部分匹配表, 是子串对应的部分匹配表
* @return 如果是-1就是没有匹配到,否则返回第一个匹配的位置
*/
public static int kmpSearch(String str1, String str2, int[] next) {
//遍历
for(int i = 0, j = 0; i < str1.length(); i++) {
//需要处理 str1.charAt(i) != str2.charAt(j), 去调整j的大小
//KMP算法核心点, 可以验证...
while( j > 0 && str1.charAt(i) != str2.charAt(j)) {
j = next[j-1];
}
if(str1.charAt(i) == str2.charAt(j)) {
j++;
}
if(j == str2.length()) {//找到了 // j = 3 i
return i - j + 1;
}
}
return -1;
}
//获取到一个字符串(子串) 的部分匹配值表
public static int[] kmpNext(String dest) {
//创建一个next 数组保存部分匹配值
int[] next = new int[dest.length()];
next[0] = 0; //如果字符串是长度为1 部分匹配值就是0
for(int i = 1, j = 0; i < dest.length(); i++) {
//当dest.charAt(i) != dest.charAt(j) ,我们需要从next[j-1]获取新的j
//直到我们发现 有 dest.charAt(i) == dest.charAt(j)成立才退出
//这是 kmp算法的核心点
while(j > 0 && dest.charAt(i) != dest.charAt(j)) {
j = next[j-1];
}
//当dest.charAt(i) == dest.charAt(j) 满足时,部分匹配值就是+1
if(dest.charAt(i) == dest.charAt(j)) {
j++;
}
next[i] = j;
}
return next;
}
}
14.5 贪心算法(greedy)
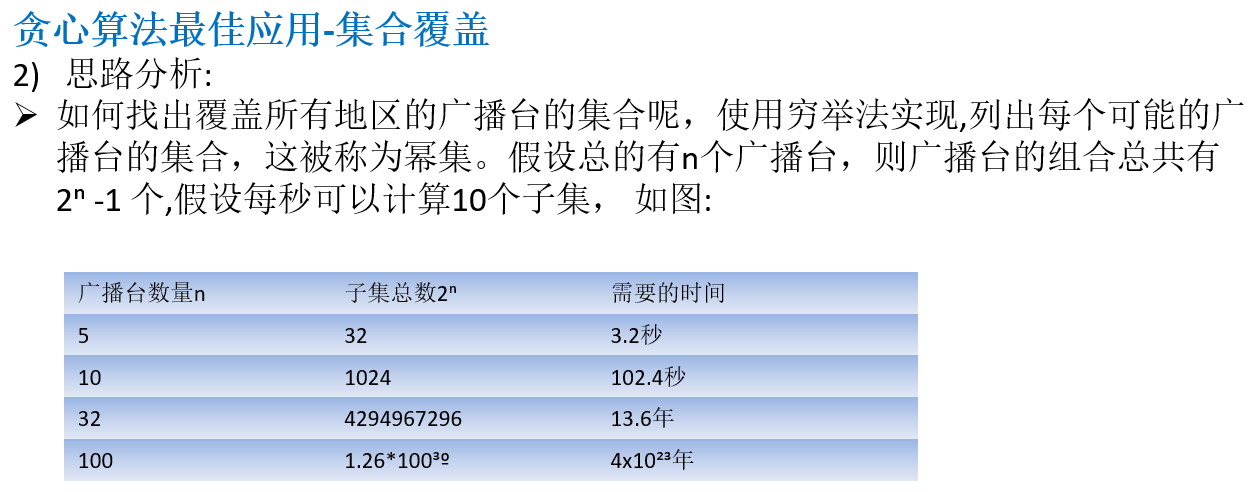
14.5.1 应用场景-集合覆盖问题

14.5.2 贪心算法介绍

14.5.3 贪心算法最佳应用-集合覆盖


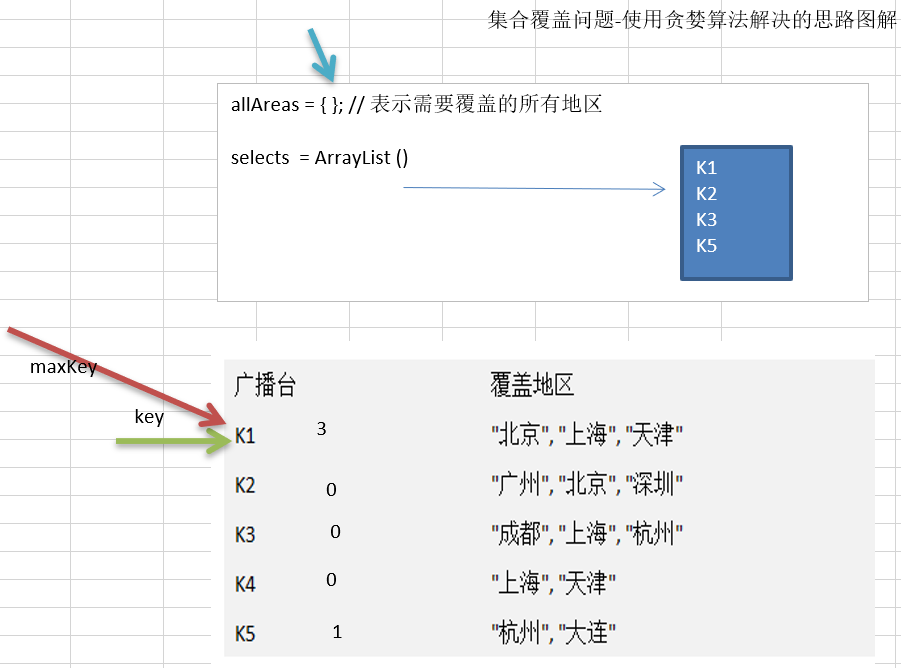
package com.atguigu.greedy;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
public class GreedyAlgorithm {
public static void main(String[] args) {
//创建广播电台,放入到Map
HashMap<String,HashSet<String>> broadcasts = new HashMap<String, HashSet<String>>();
//将各个电台放入到broadcasts
HashSet<String> hashSet1 = new HashSet<String>();
hashSet1.add("北京");
hashSet1.add("上海");
hashSet1.add("天津");
HashSet<String> hashSet2 = new HashSet<String>();
hashSet2.add("广州");
hashSet2.add("北京");
hashSet2.add("深圳");
HashSet<String> hashSet3 = new HashSet<String>();
hashSet3.add("成都");
hashSet3.add("上海");
hashSet3.add("杭州");
HashSet<String> hashSet4 = new HashSet<String>();
hashSet4.add("上海");
hashSet4.add("天津");
HashSet<String> hashSet5 = new HashSet<String>();
hashSet5.add("杭州");
hashSet5.add("大连");
//加入到map
broadcasts.put("K1", hashSet1);
broadcasts.put("K2", hashSet2);
broadcasts.put("K3", hashSet3);
broadcasts.put("K4", hashSet4);
broadcasts.put("K5", hashSet5);
//allAreas 存放所有的地区
HashSet<String> allAreas = new HashSet<String>();
allAreas.add("北京");
allAreas.add("上海");
allAreas.add("天津");
allAreas.add("广州");
allAreas.add("深圳");
allAreas.add("成都");
allAreas.add("杭州");
allAreas.add("大连");
//创建ArrayList, 存放选择的电台集合
ArrayList<String> selects = new ArrayList<String>();
//定义一个临时的集合, 在遍历的过程中,存放遍历过程中的电台覆盖的地区和当前还没有覆盖的地区的交集
HashSet<String> tempSet = new HashSet<String>();
//定义一个maxKey , 保存在一次遍历过程中,能够覆盖最大未覆盖的地区对应的电台的key
//如果maxKey 不为null , 则会加入到 selects
String maxKey = null;
while(allAreas.size() != 0) { // 如果allAreas 不为0, 则表示还没有覆盖到所有的地区
//每进行一次while,需要
maxKey = null;
//遍历 broadcasts, 取出对应key
for(String key : broadcasts.keySet()) {
//每进行一次for
tempSet.clear();
//当前这个key能够覆盖的地区
HashSet<String> areas = broadcasts.get(key);
tempSet.addAll(areas);
//求出tempSet 和 allAreas 集合的交集, 交集会赋给 tempSet
tempSet.retainAll(allAreas);
//如果当前这个集合包含的未覆盖地区的数量,比maxKey指向的集合地区还多
//就需要重置maxKey
// tempSet.size() >broadcasts.get(maxKey).size()) 体现出贪心算法的特点,每次都选择最优的
if(tempSet.size() > 0 &&
(maxKey == null || tempSet.size() >broadcasts.get(maxKey).size())){
maxKey = key;
}
}
//maxKey != null, 就应该将maxKey 加入selects
if(maxKey != null) {
selects.add(maxKey);
//将maxKey指向的广播电台覆盖的地区,从 allAreas 去掉
allAreas.removeAll(broadcasts.get(maxKey));
}
}
System.out.println("得到的选择结果是" + selects);//[K1,K2,K3,K5]
}
}
14.5.4 贪心算法注意事项和细节

14.6 普里姆算法(Prim)
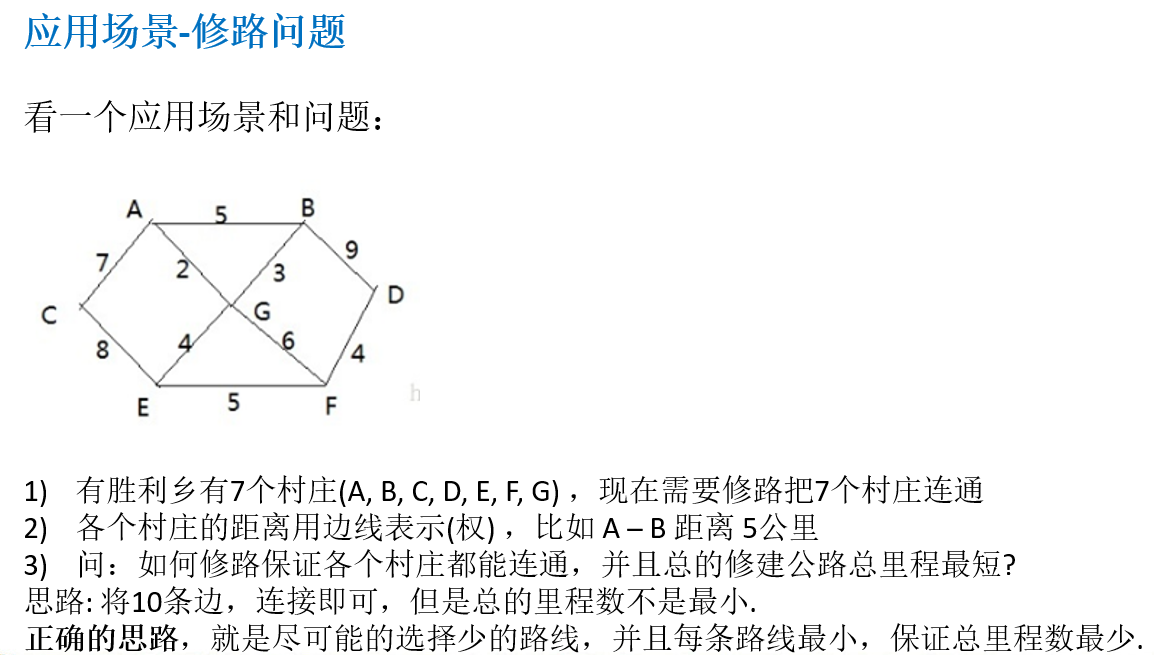
14.6.1 应用场景-修路问题
14.6.2 最小生成树(Minimum Cost Spanning Tree,MST)
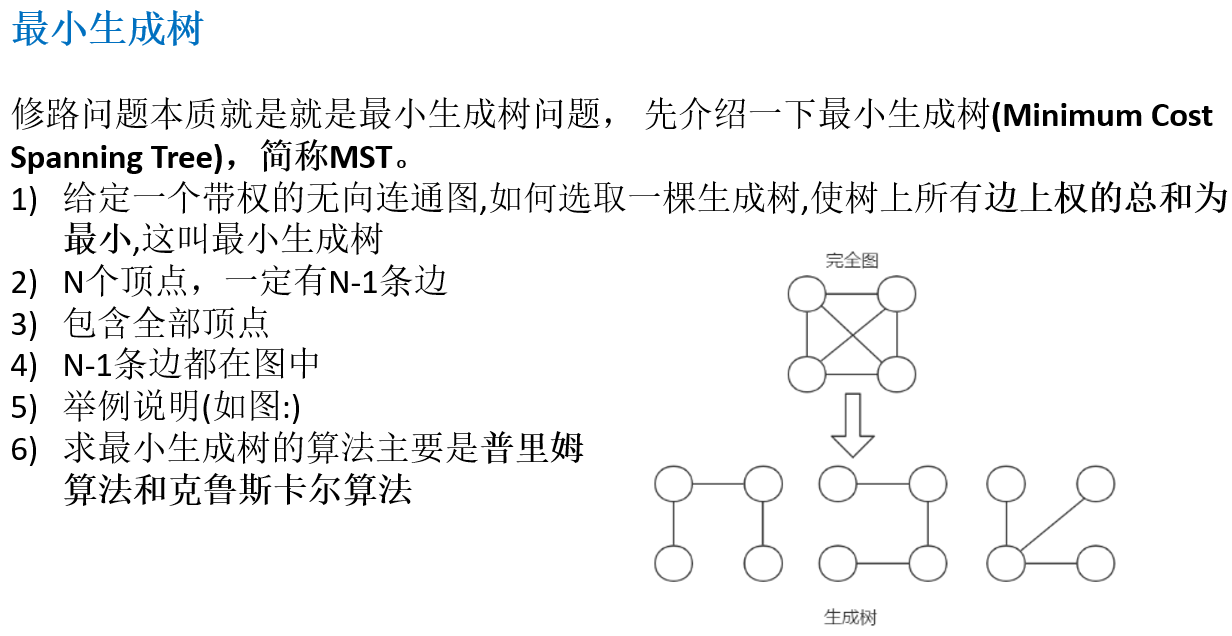
14.6.3 普里姆算法介绍

14.6.4 普里姆算法最佳实践(修路问题)
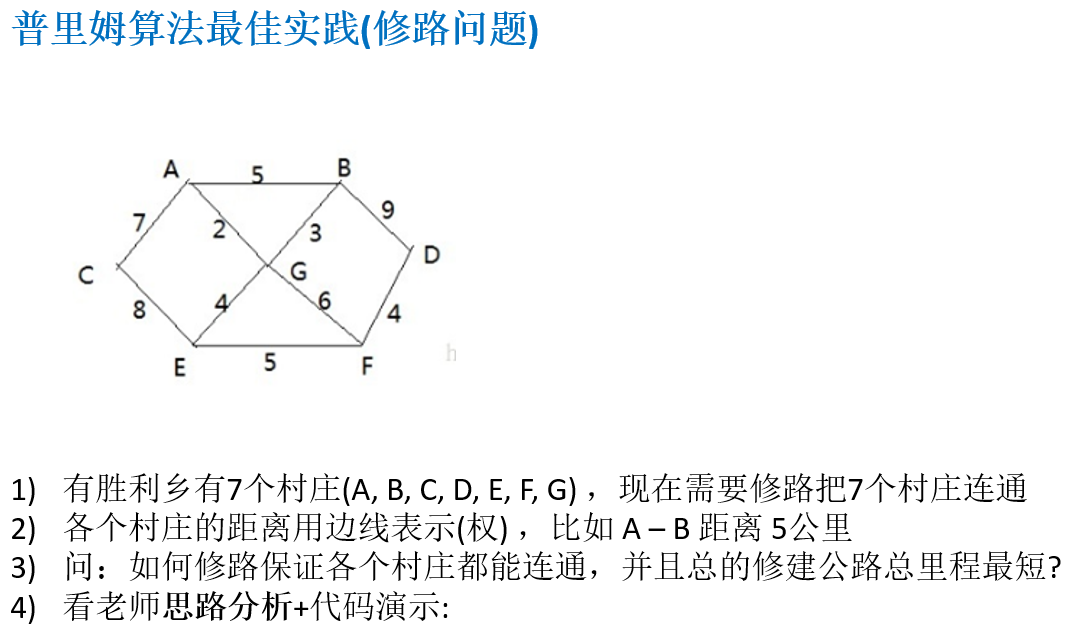

package com.atguigu.prim;
import java.util.Arrays;
public class PrimAlgorithm {
public static void main(String[] args) {
//测试看看图是否创建ok
char[] data = new char[]{'A','B','C','D','E','F','G'};
int verxs = data.length;
//邻接矩阵的关系使用二维数组表示,10000这个大数,表示两个点不联通
int [][]weight=new int[][]{
{10000,5,7,10000,10000,10000,2},
{5,10000,10000,9,10000,10000,3},
{7,10000,10000,10000,8,10000,10000},
{10000,9,10000,10000,10000,4,10000},
{10000,10000,8,10000,10000,5,4},
{10000,10000,10000,4,5,10000,6},
{2,3,10000,10000,4,6,10000},};
//创建MGraph对象
MGraph graph = new MGraph(verxs);
//创建一个MinTree对象
MinTree minTree = new MinTree();
minTree.createGraph(graph, verxs, data, weight);
//输出
minTree.showGraph(graph);
//测试普利姆算法
minTree.prim(graph, 1);//
}
}
//创建最小生成树->村庄的图
class MinTree {
//创建图的邻接矩阵
/**
*
* @param graph 图对象
* @param verxs 图对应的顶点个数
* @param data 图的各个顶点的值
* @param weight 图的邻接矩阵
*/
public void createGraph(MGraph graph, int verxs, char data[], int[][] weight) {
int i, j;
for(i = 0; i < verxs; i++) {//顶点
graph.data[i] = data[i];
for(j = 0; j < verxs; j++) {
graph.weight[i][j] = weight[i][j];
}
}
}
//显示图的邻接矩阵
public void showGraph(MGraph graph) {
for(int[] link: graph.weight) {
System.out.println(Arrays.toString(link));
}
}
//编写prim算法,得到最小生成树
/**
*
* @param graph 图
* @param v 表示从图的第几个顶点开始生成'A'->0 'B'->1...
*/
public void prim(MGraph graph, int v) {
//visited[] 标记结点(顶点)是否被访问过
int visited[] = new int[graph.verxs];
//visited[] 默认元素的值都是0, 表示没有访问过
// for(int i =0; i <graph.verxs; i++) {
// visited[i] = 0;
// }
//把当前这个结点标记为已访问
visited[v] = 1;
//h1 和 h2 记录两个顶点的下标
int h1 = -1;
int h2 = -1;
int minWeight = 10000; //将 minWeight 初始成一个大数,后面在遍历过程中,会被替换
for(int k = 1; k < graph.verxs; k++) {//因为有 graph.verxs顶点,普利姆算法结束后,有 graph.verxs-1边
//这个是确定每一次生成的子图 ,和哪个结点的距离最近
for(int i = 0; i < graph.verxs; i++) {// i结点表示被访问过的结点
for(int j = 0; j< graph.verxs;j++) {//j结点表示还没有访问过的结点
if(visited[i] == 1 && visited[j] == 0 && graph.weight[i][j] < minWeight) {
//替换minWeight(寻找已经访问过的结点和未访问过的结点间的权值最小的边)
minWeight = graph.weight[i][j];
h1 = i;
h2 = j;
}
}
}
//找到一条边是最小
System.out.println("边<" + graph.data[h1] + "," + graph.data[h2] + "> 权值:" + minWeight);
//将当前这个结点标记为已经访问
visited[h2] = 1;
//minWeight 重新设置为最大值 10000
minWeight = 10000;
}
}
}
class MGraph {
int verxs; //表示图的节点个数
char[] data;//存放结点数据
int[][] weight; //存放边,就是我们的邻接矩阵
public MGraph(int verxs) {
this.verxs = verxs;
data = new char[verxs];
weight = new int[verxs][verxs];
}
}
14.7 克鲁斯卡尔算法(Kruskal)
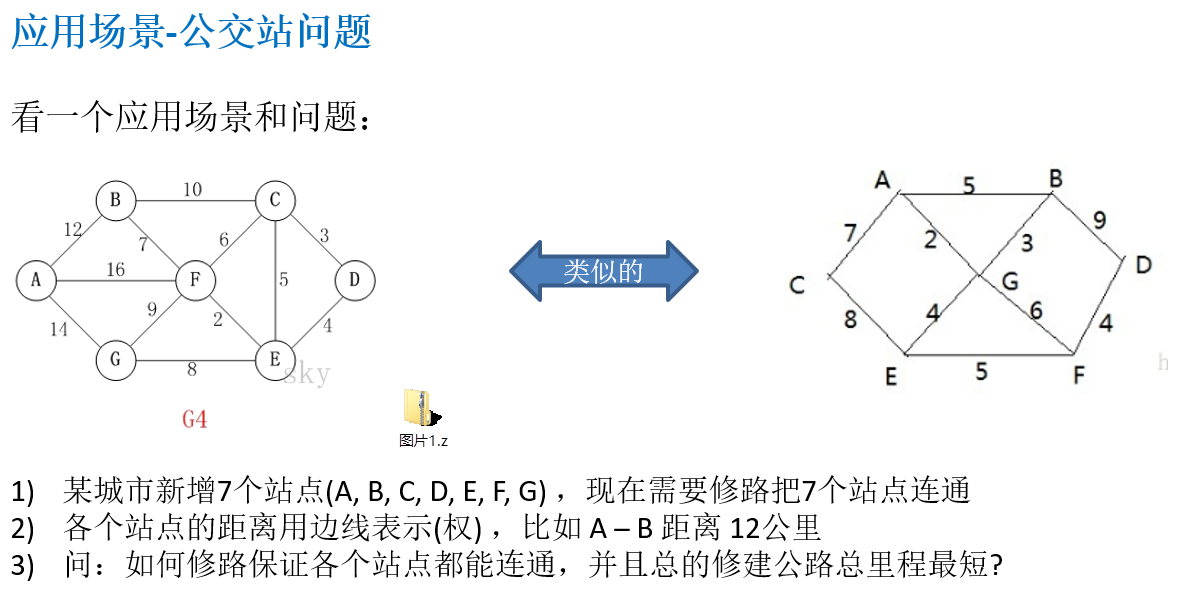
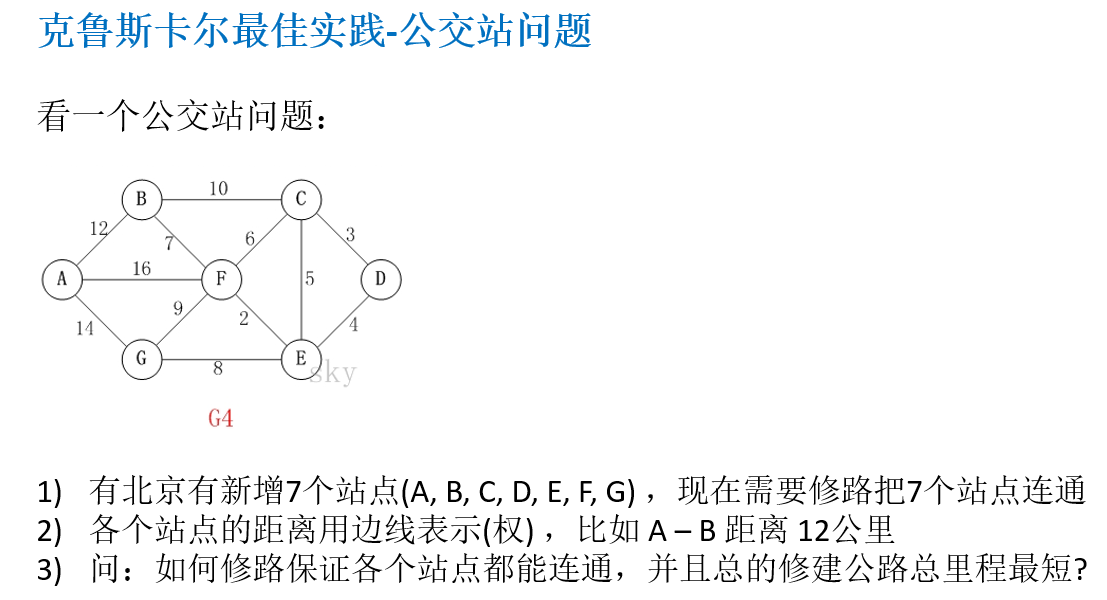
14.7.1 应用场景-公交站问题
14.7.2 克鲁斯卡尔算法介绍

14.7.3 克鲁斯卡尔算法图解说明
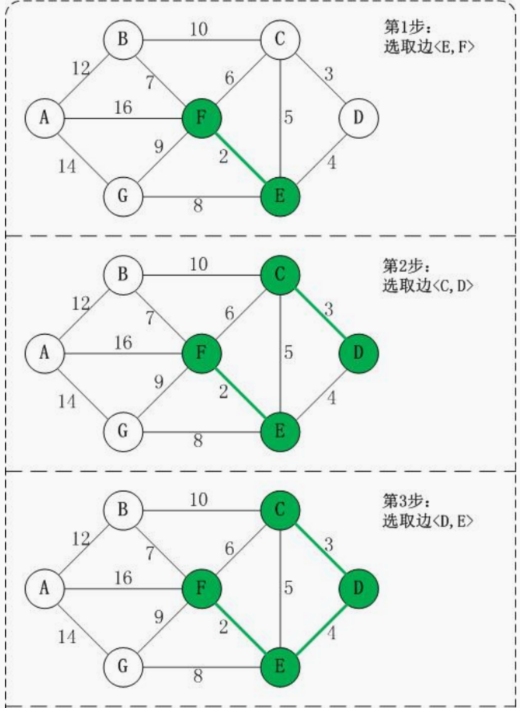
以城市公交站问题来图解说明 克鲁斯卡尔算法的原理和步骤:


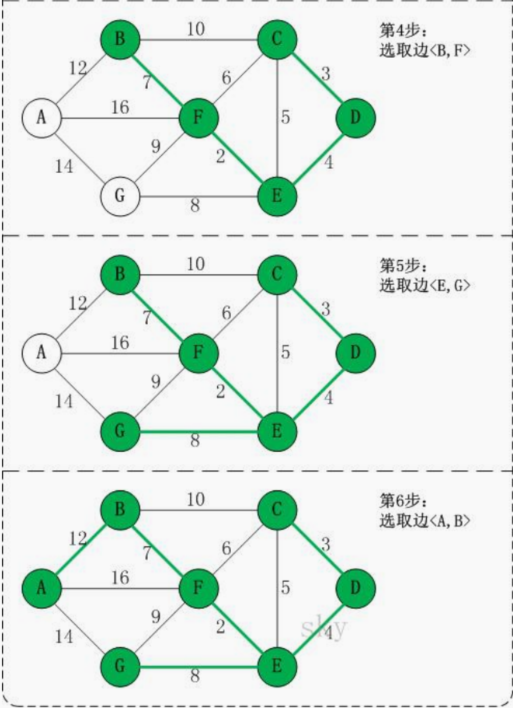



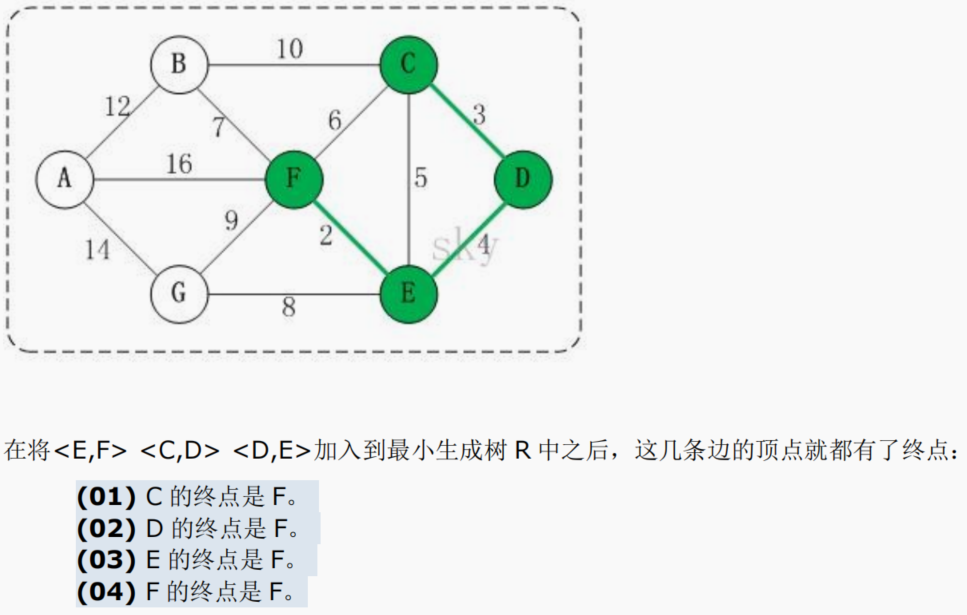

14.7.4 克鲁斯卡尔最佳实践-公交站问题
package com.atguigu.kruskal;
import java.util.Arrays;
public class KruskalCase {
private int edgeNum; //边的个数
private char[] vertexs; //顶点数组
private int[][] matrix; //邻接矩阵
//使用 INF 表示两个顶点不能连通
private static final int INF = Integer.MAX_VALUE;
public static void main(String[] args) {
char[] vertexs = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
//克鲁斯卡尔算法的邻接矩阵
int matrix[][] = {
/*A*//*B*//*C*//*D*//*E*//*F*//*G*/
/*A*/ { 0, 12, INF, INF, INF, 16, 14},
/*B*/ { 12, 0, 10, INF, INF, 7, INF},
/*C*/ { INF, 10, 0, 3, 5, 6, INF},
/*D*/ { INF, INF, 3, 0, 4, INF, INF},
/*E*/ { INF, INF, 5, 4, 0, 2, 8},
/*F*/ { 16, 7, 6, INF, 2, 0, 9},
/*G*/ { 14, INF, INF, INF, 8, 9, 0}};
//大家可以再去测试其它的邻接矩阵,结果都可以得到最小生成树.
//创建KruskalCase 对象实例
KruskalCase kruskalCase = new KruskalCase(vertexs, matrix);
//输出构建的
kruskalCase.print();
kruskalCase.kruskal();
}
//构造器
public KruskalCase(char[] vertexs, int[][] matrix) {
//初始化顶点数和边的个数
int vlen = vertexs.length;
//初始化顶点, 复制拷贝的方式
this.vertexs = new char[vlen];
for(int i = 0; i < vertexs.length; i++) {
this.vertexs[i] = vertexs[i];
}
//初始化边, 使用的是复制拷贝的方式
this.matrix = new int[vlen][vlen];
for(int i = 0; i < vlen; i++) {
for(int j= 0; j < vlen; j++) {
this.matrix[i][j] = matrix[i][j];
}
}
//统计边的条数
for(int i =0; i < vlen; i++) {
for(int j = i+1; j < vlen; j++) {
if(this.matrix[i][j] != INF) {
edgeNum++;
}
}
}
}
public void kruskal() {
int index = 0; //表示最后结果数组的索引
int[] ends = new int[edgeNum]; //用于保存"已有最小生成树" 中的每个顶点在最小生成树中的终点
//创建结果数组, 保存最后的最小生成树
EData[] rets = new EData[edgeNum];
//获取图中 所有的边的集合 , 一共有12条边
EData[] edges = getEdges();
System.out.println("图的边的集合=" + Arrays.toString(edges) + " 共"+ edges.length); //12
//按照边的权值大小进行排序(从小到大)
sortEdges(edges);
//遍历edges 数组,将边添加到最小生成树中时,判断是准备加入的边否形成了回路,如果没有,就加入 rets, 否则不能加入
for(int i=0; i < edgeNum; i++) {
//获取到第i条边的第一个顶点(起点)
int p1 = getPosition(edges[i].start); //p1=4
//获取到第i条边的第2个顶点
int p2 = getPosition(edges[i].end); //p2 = 5
//获取p1这个顶点在已有最小生成树中的终点
int m = getEnd(ends, p1); //m = 4
//获取p2这个顶点在已有最小生成树中的终点
int n = getEnd(ends, p2); // n = 5
//是否构成回路
if(m != n) { //没有构成回路
ends[m] = n; // 设置m 在"已有最小生成树"中的终点 <E,F> [0,0,0,0,5,0,0,0,0,0,0,0]
rets[index++] = edges[i]; //有一条边加入到rets数组
}
}
//<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>。
//统计并打印 "最小生成树", 输出 rets
System.out.println("最小生成树为");
for(int i = 0; i < index; i++) {
System.out.println(rets[i]);
}
}
//打印邻接矩阵
public void print() {
System.out.println("邻接矩阵为: \n");
for(int i = 0; i < vertexs.length; i++) {
for(int j=0; j < vertexs.length; j++) {
System.out.printf("%12d", matrix[i][j]);
}
System.out.println();//换行
}
}
/**
* 功能:对边进行排序处理, 冒泡排序
* @param edges 边的集合
*/
private void sortEdges(EData[] edges) {
for(int i = 0; i < edges.length - 1; i++) {
for(int j = 0; j < edges.length - 1 - i; j++) {
if(edges[j].weight > edges[j+1].weight) {//交换
EData tmp = edges[j];
edges[j] = edges[j+1];
edges[j+1] = tmp;
}
}
}
}
/**
*
* @param ch 顶点的值,比如'A','B'
* @return 返回ch顶点对应的下标,如果找不到,返回-1
*/
private int getPosition(char ch) {
for(int i = 0; i < vertexs.length; i++) {
if(vertexs[i] == ch) {//找到
return i;
}
}
//找不到,返回-1
return -1;
}
/**
* 功能: 获取图中边,放到EData[] 数组中,后面我们需要遍历该数组
* 是通过matrix 邻接矩阵来获取
* EData[] 形式 [['A','B', 12], ['B','F',7], .....]
* @return
*/
private EData[] getEdges() {
int index = 0;
EData[] edges = new EData[edgeNum];
for(int i = 0; i < vertexs.length; i++) {
for(int j=i+1; j <vertexs.length; j++) {
if(matrix[i][j] != INF) {
edges[index++] = new EData(vertexs[i], vertexs[j], matrix[i][j]);
}
}
}
return edges;
}
/**
* 功能: 获取下标为i的顶点的终点(), 用于后面判断两个顶点的终点是否相同
* @param ends : 数组就是记录了各个顶点对应的终点是哪个,ends 数组是在遍历过程中,逐步形成
* @param i : 表示传入的顶点对应的下标
* @return 返回的就是 下标为i的这个顶点对应的终点的下标, 一会回头还要来理解
*/
private int getEnd(int[] ends, int i) { // i = 4 [0,0,0,0,5,0,0,0,0,0,0,0]
while(ends[i] != 0) {
i = ends[i];
}
return i;
}
}
//创建一个类EData ,它的对象实例就表示一条边
class EData {
char start; //边的一个点
char end; //边的另外一个点
int weight; //边的权值
//构造器
public EData(char start, char end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
//重写toString, 便于输出边信息
@Override
public String toString() {
return "EData [<" + start + ", " + end + ">= " + weight + "]";
}
}
14.8 迪杰斯特拉算法(Dijkstra)
14.8.1 应用场景-最短路径问题
14.8.2 迪杰斯特拉算法介绍

14.8.3 迪杰斯特拉算法过程

14.8.4 迪杰斯特拉算法最佳应用-最短路径
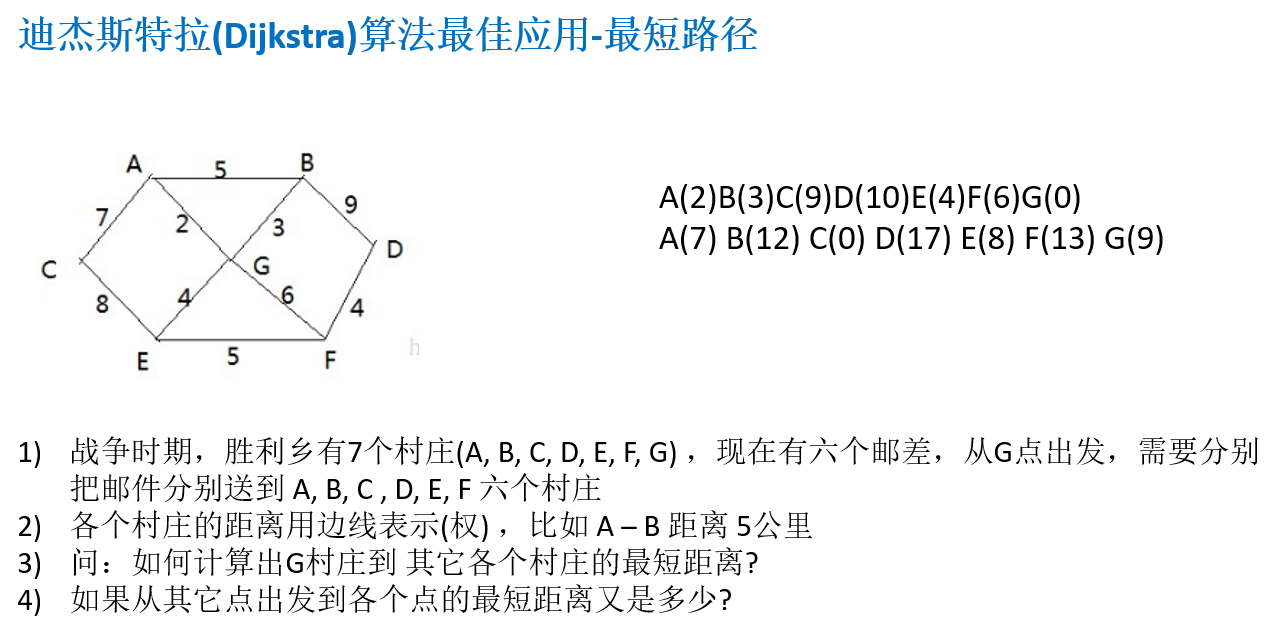
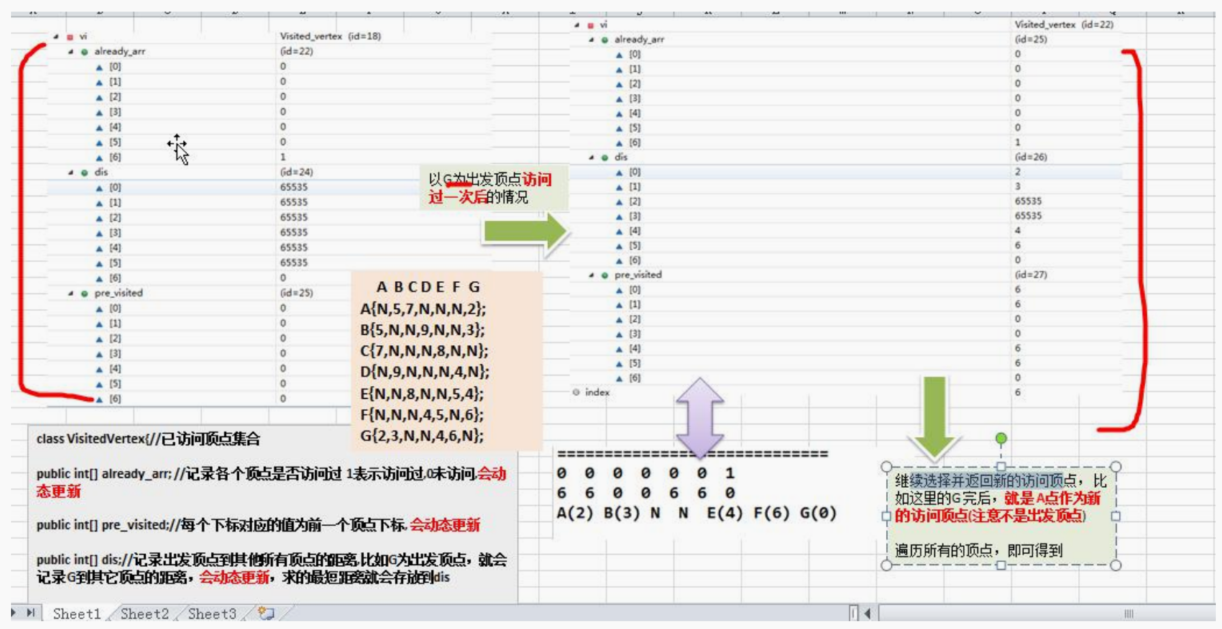
package com.atguigu.dijkstra;
import java.util.Arrays;
public class DijkstraAlgorithm {
public static void main(String[] args) {
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
//邻接矩阵
int[][] matrix = new int[vertex.length][vertex.length];
final int N = 65535;// 表示不可以连接
matrix[0]=new int[]{N,5,7,N,N,N,2};
matrix[1]=new int[]{5,N,N,9,N,N,3};
matrix[2]=new int[]{7,N,N,N,8,N,N};
matrix[3]=new int[]{N,9,N,N,N,4,N};
matrix[4]=new int[]{N,N,8,N,N,5,4};
matrix[5]=new int[]{N,N,N,4,5,N,6};
matrix[6]=new int[]{2,3,N,N,4,6,N};
//创建 Graph对象
Graph graph = new Graph(vertex, matrix);
//测试, 看看图的邻接矩阵是否ok
graph.showGraph();
//测试迪杰斯特拉算法
graph.dsj(2);//C
graph.showDijkstra();
}
}
class Graph {
private char[] vertex; // 顶点数组
private int[][] matrix; // 邻接矩阵
private VisitedVertex vv; //已经访问的顶点的集合
// 构造器
public Graph(char[] vertex, int[][] matrix) {
this.vertex = vertex;
this.matrix = matrix;
}
//显示结果
public void showDijkstra() {
vv.show();
}
// 显示图
public void showGraph() {
for (int[] link : matrix) {
System.out.println(Arrays.toString(link));
}
}
//迪杰斯特拉算法实现
/**
*
* @param index 表示出发顶点对应的下标
*/
public void dsj(int index) {
vv = new VisitedVertex(vertex.length, index);
update(index);//更新index顶点到周围顶点的距离和前驱顶点
for(int j = 1; j <vertex.length; j++) {
index = vv.updateArr();// 选择并返回新的访问顶点
update(index); // 更新index顶点到周围顶点的距离和前驱顶点
}
}
//更新index下标顶点到周围顶点的距离和周围顶点的前驱顶点,
private void update(int index) {
int len = 0;
//根据遍历我们的邻接矩阵的 matrix[index]行
for(int j = 0; j < matrix[index].length; j++) {
// len 含义是 : 出发顶点到index顶点的距离 + 从index顶点到j顶点的距离的和
len = vv.getDis(index) + matrix[index][j];
// 如果j顶点没有被访问过,并且 len 小于出发顶点到j顶点的距离,就需要更新
if(!vv.in(j) && len < vv.getDis(j)) {
vv.updatePre(j, index); //更新j顶点的前驱为index顶点
vv.updateDis(j, len); //更新出发顶点到j顶点的距离
}
}
}
}
// 已访问顶点集合
class VisitedVertex {
// 记录各个顶点是否访问过 1表示访问过,0未访问,会动态更新
public int[] already_arr;
// 每个下标对应的值为前一个顶点下标, 会动态更新
public int[] pre_visited;
// 记录出发顶点到其他所有顶点的距离,比如G为出发顶点,就会记录G到其它顶点的距离,会动态更新,求的最短距离就会存放到dis
public int[] dis;
//构造器
/**
*
* @param length :表示顶点的个数
* @param index: 出发顶点对应的下标, 比如G顶点,下标就是6
*/
public VisitedVertex(int length, int index) {
this.already_arr = new int[length];
this.pre_visited = new int[length];
this.dis = new int[length];
//初始化 dis数组
Arrays.fill(dis, 65535);
this.already_arr[index] = 1; //设置出发顶点被访问过
this.dis[index] = 0;//设置出发顶点的访问距离为0
}
/**
* 功能: 判断index顶点是否被访问过
* @param index
* @return 如果访问过,就返回true, 否则访问false
*/
public boolean in(int index) {
return already_arr[index] == 1;
}
/**
* 功能: 更新出发顶点到index顶点的距离
* @param index
* @param len
*/
public void updateDis(int index, int len) {
dis[index] = len;
}
/**
* 功能: 更新pre这个顶点的前驱顶点为index顶点
* @param pre
* @param index
*/
public void updatePre(int pre, int index) {
pre_visited[pre] = index;
}
/**
* 功能:返回出发顶点到index顶点的距离
* @param index
*/
public int getDis(int index) {
return dis[index];
}
/**
* 继续选择并返回新的访问顶点, 比如这里的G 完后,就是 A点作为新的访问顶点(注意不是出发顶点)
* @return
*/
public int updateArr() {
int min = 65535, index = 0;
for(int i = 0; i < already_arr.length; i++) {
if(already_arr[i] == 0 && dis[i] < min ) {
min = dis[i];
index = i;
}
}
//更新 index 顶点被访问过
already_arr[index] = 1;
return index;
}
//显示最后的结果
//即将三个数组的情况输出
public void show() {
System.out.println("==========================");
//输出already_arr
for(int i : already_arr) {
System.out.print(i + " ");
}
System.out.println();
//输出pre_visited
for(int i : pre_visited) {
System.out.print(i + " ");
}
System.out.println();
//输出dis
for(int i : dis) {
System.out.print(i + " ");
}
System.out.println();
//为了好看最后的最短距离,我们处理
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
int count = 0;
for (int i : dis) {
if (i != 65535) {
System.out.print(vertex[count] + "("+i+") ");
} else {
System.out.println("N ");
}
count++;
}
System.out.println();
}
}14.9 弗洛伊德算法(Floyd)
14.9.1 弗洛伊德算法介绍

14.9.2 弗洛伊德算法图解分析

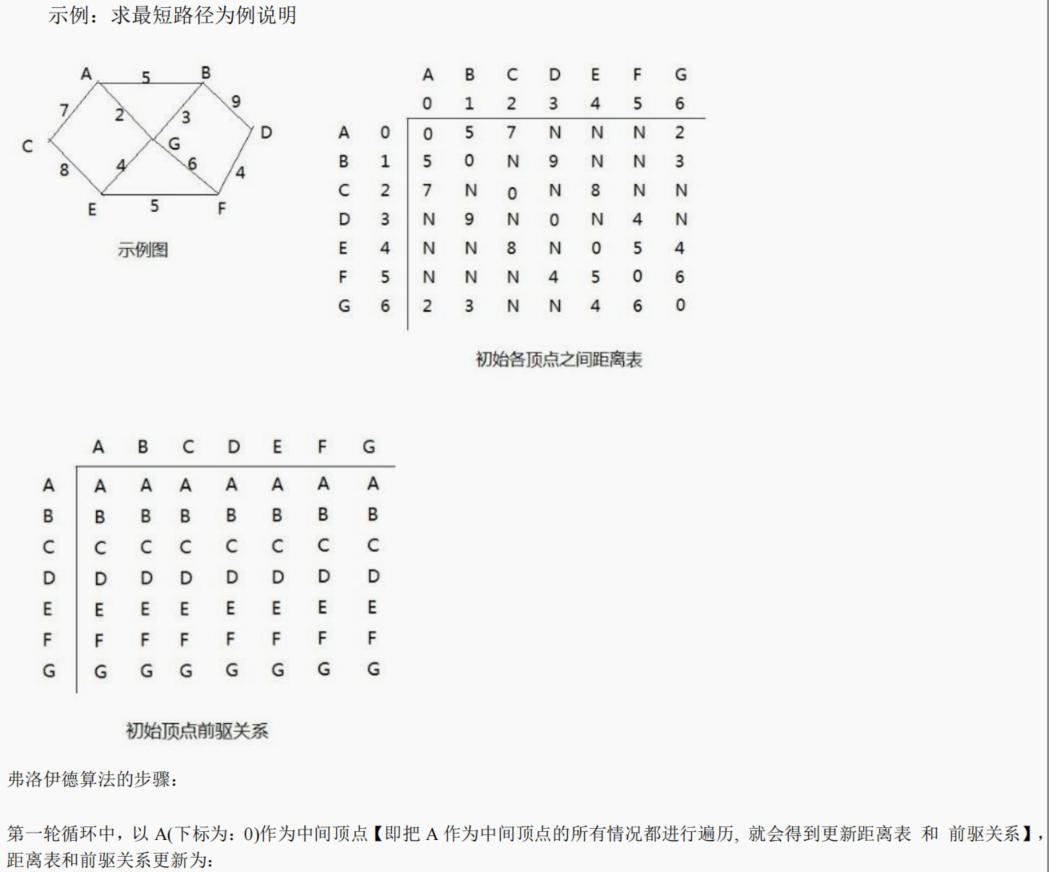

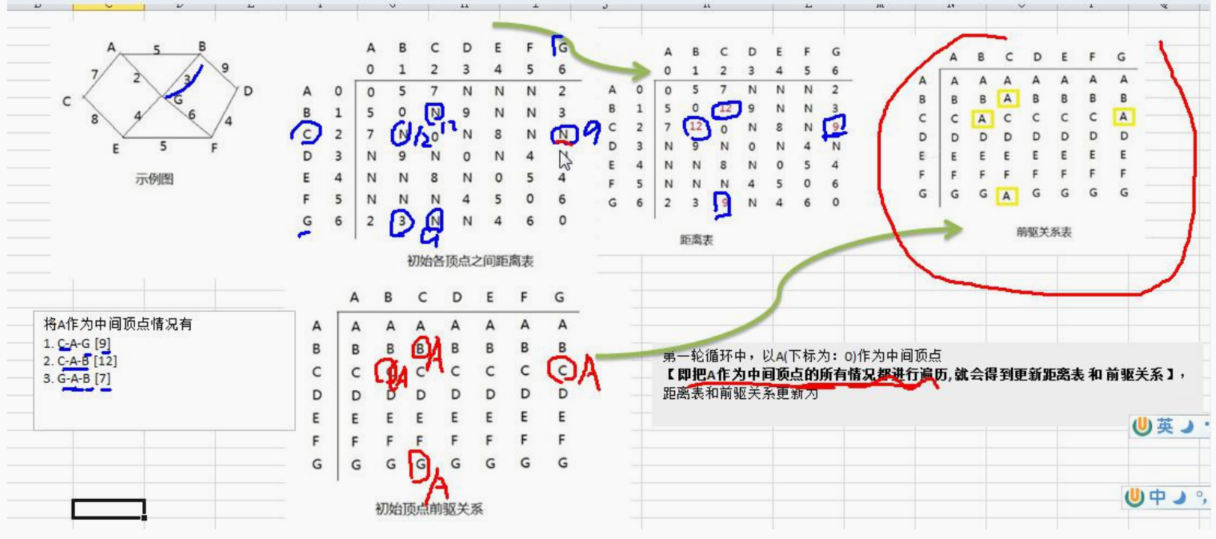
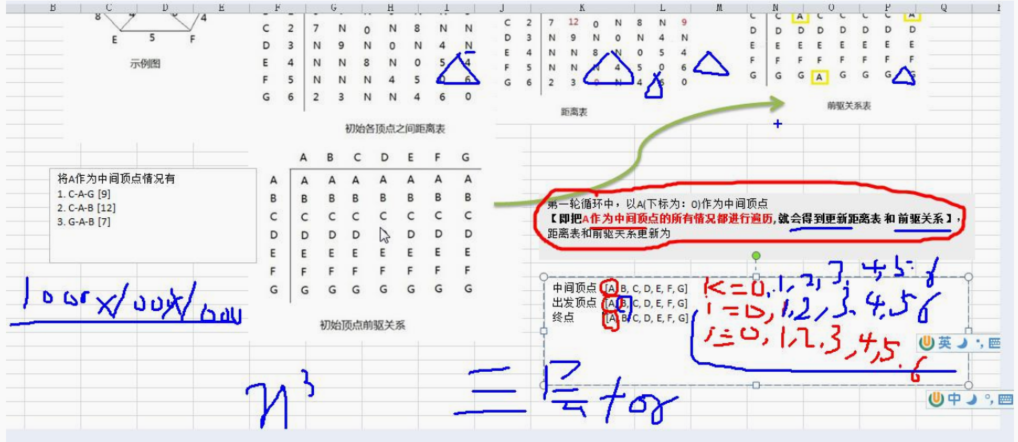
14.9.3 弗洛伊德算法最佳应用-最短路径
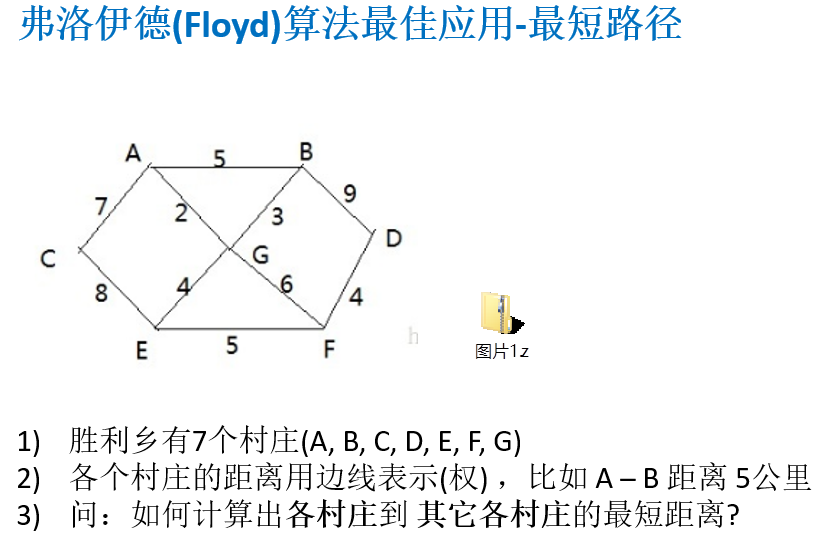
package com.atguigu.floyd;
import java.util.Arrays;
public class FloydAlgorithm {
public static void main(String[] args) {
// 测试看看图是否创建成功
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
//创建邻接矩阵
int[][] matrix = new int[vertex.length][vertex.length];
final int N = 65535;
matrix[0] = new int[] { 0, 5, 7, N, N, N, 2 };
matrix[1] = new int[] { 5, 0, N, 9, N, N, 3 };
matrix[2] = new int[] { 7, N, 0, N, 8, N, N };
matrix[3] = new int[] { N, 9, N, 0, N, 4, N };
matrix[4] = new int[] { N, N, 8, N, 0, 5, 4 };
matrix[5] = new int[] { N, N, N, 4, 5, 0, 6 };
matrix[6] = new int[] { 2, 3, N, N, 4, 6, 0 };
//创建 Graph 对象
Graph graph = new Graph(vertex.length, matrix, vertex);
//调用弗洛伊德算法
graph.floyd();
graph.show();
}
}
// 创建图
class Graph {
private char[] vertex; // 存放顶点的数组
private int[][] dis; // 保存,从各个顶点出发到其它顶点的距离,最后的结果,也是保留在该数组
private int[][] pre;// 保存到达目标顶点的前驱顶点
// 构造器
/**
*
* @param length
* 大小
* @param matrix
* 邻接矩阵
* @param vertex
* 顶点数组
*/
public Graph(int length, int[][] matrix, char[] vertex) {
this.vertex = vertex;
this.dis = matrix;
this.pre = new int[length][length];
// 对pre数组初始化, 注意存放的是前驱顶点的下标
for (int i = 0; i < length; i++) {
Arrays.fill(pre[i], i);
}
}
// 显示pre数组和dis数组
public void show() {
//为了显示便于阅读,我们优化一下输出
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
for (int k = 0; k < dis.length; k++) {
// 先将pre数组输出的一行
for (int i = 0; i < dis.length; i++) {
System.out.print(vertex[pre[k][i]] + " ");
}
System.out.println();
// 输出dis数组的一行数据
for (int i = 0; i < dis.length; i++) {
System.out.print("("+vertex[k]+"到"+vertex[i]+"的最短路径是" + dis[k][i] + ") ");
}
System.out.println();
System.out.println();
}
}
//弗洛伊德算法, 比较容易理解,而且容易实现
public void floyd() {
int len = 0; //变量保存距离
//对中间顶点遍历, k 就是中间顶点的下标 [A, B, C, D, E, F, G]
for(int k = 0; k < dis.length; k++) { //
//从i顶点开始出发 [A, B, C, D, E, F, G]
for(int i = 0; i < dis.length; i++) {
//到达j顶点 // [A, B, C, D, E, F, G]
for(int j = 0; j < dis.length; j++) {
len = dis[i][k] + dis[k][j];// => 求出从i 顶点出发,经过 k中间顶点,到达 j 顶点距离
if(len < dis[i][j]) {//如果len小于 dis[i][j]
dis[i][j] = len;//更新距离
pre[i][j] = pre[k][j];//更新前驱顶点
}
}
}
}
}
}
14.10 马踏棋盘算法(骑士周游回溯算法)
14.10.1 马踏棋盘算法介绍和游戏演示

14.10.2 马踏棋盘游戏代码实现


package com.atguigu.horse;
import java.awt.Point;
import java.util.ArrayList;
import java.util.Comparator;
public class HorseChessboard {
private static int X; // 棋盘的列数
private static int Y; // 棋盘的行数
//创建一个数组,标记棋盘的各个位置是否被访问过
private static boolean visited[];
//使用一个属性,标记是否棋盘的所有位置都被访问
private static boolean finished; // 如果为true,表示成功
public static void main(String[] args) {
System.out.println("骑士周游算法,开始运行~~");
//测试骑士周游算法是否正确
X = 8;
Y = 8;
int row = 1; //马儿初始位置的行,从1开始编号
int column = 1; //马儿初始位置的列,从1开始编号
//创建棋盘
int[][] chessboard = new int[X][Y];
visited = new boolean[X * Y];//初始值都是false
//测试一下耗时
long start = System.currentTimeMillis();
traversalChessboard(chessboard, row - 1, column - 1, 1);
long end = System.currentTimeMillis();
System.out.println("共耗时: " + (end - start) + " 毫秒");
//输出棋盘的最后情况
for(int[] rows : chessboard) {
for(int step: rows) {
System.out.print(step + "\t");
}
System.out.println();
}
}
/**
* 完成骑士周游问题的算法
* @param chessboard 棋盘
* @param row 马儿当前的位置的行 从0开始
* @param column 马儿当前的位置的列 从0开始
* @param step 是第几步 ,初始位置就是第1步
*/
public static void traversalChessboard(int[][] chessboard, int row, int column, int step) {
chessboard[row][column] = step;
//row = 4 X = 8 column = 4 = 4 * 8 + 4 = 36
visited[row * X + column] = true; //标记该位置已经访问
//获取当前位置可以走的下一个位置的集合
ArrayList<Point> ps = next(new Point(column, row));
//对ps进行排序,排序的规则就是对ps的所有的Point对象的下一步的位置的数目,进行非递减排序
sort(ps);
//遍历 ps
while(!ps.isEmpty()) {
Point p = ps.remove(0);//取出下一个可以走的位置
//判断该点是否已经访问过
if(!visited[p.y * X + p.x]) {//说明还没有访问过
traversalChessboard(chessboard, p.y, p.x, step + 1);
}
}
//判断马儿是否完成了任务,使用 step 和应该走的步数比较 ,
//如果没有达到数量,则表示没有完成任务,将整个棋盘置0
//说明: step < X * Y 成立的情况有两种
//1. 棋盘到目前位置,仍然没有走完
//2. 棋盘处于一个回溯过程
if(step < X * Y && !finished ) {
chessboard[row][column] = 0;
visited[row * X + column] = false;
} else {
finished = true;
}
}
/**
* 功能: 根据当前位置(Point对象),计算马儿还能走哪些位置(Point),并放入到一个集合中(ArrayList), 最多有8个位置
* @param curPoint
* @return
*/
public static ArrayList<Point> next(Point curPoint) {
//创建一个ArrayList
ArrayList<Point> ps = new ArrayList<Point>();
//创建一个Point
Point p1 = new Point();
//表示马儿可以走5这个位置
if((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y -1) >= 0) {
ps.add(new Point(p1));
}
//判断马儿可以走6这个位置
if((p1.x = curPoint.x - 1) >=0 && (p1.y=curPoint.y-2)>=0) {
ps.add(new Point(p1));
}
//判断马儿可以走7这个位置
if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y - 2) >= 0) {
ps.add(new Point(p1));
}
//判断马儿可以走0这个位置
if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y - 1) >= 0) {
ps.add(new Point(p1));
}
//判断马儿可以走1这个位置
if ((p1.x = curPoint.x + 2) < X && (p1.y = curPoint.y + 1) < Y) {
ps.add(new Point(p1));
}
//判断马儿可以走2这个位置
if ((p1.x = curPoint.x + 1) < X && (p1.y = curPoint.y + 2) < Y) {
ps.add(new Point(p1));
}
//判断马儿可以走3这个位置
if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y + 2) < Y) {
ps.add(new Point(p1));
}
//判断马儿可以走4这个位置
if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y + 1) < Y) {
ps.add(new Point(p1));
}
return ps;
}
//根据当前这个一步的所有的下一步的选择位置,进行非递减排序, 减少回溯的次数
public static void sort(ArrayList<Point> ps) {
ps.sort(new Comparator<Point>() {
@Override
public int compare(Point o1, Point o2) {
//获取到o1的下一步的所有位置个数
int count1 = next(o1).size();
//获取到o2的下一步的所有位置个数
int count2 = next(o2).size();
if(count1 < count2) {
return -1;
} else if (count1 == count2) {
return 0;
} else {
return 1;
}
}
});
}
}

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)