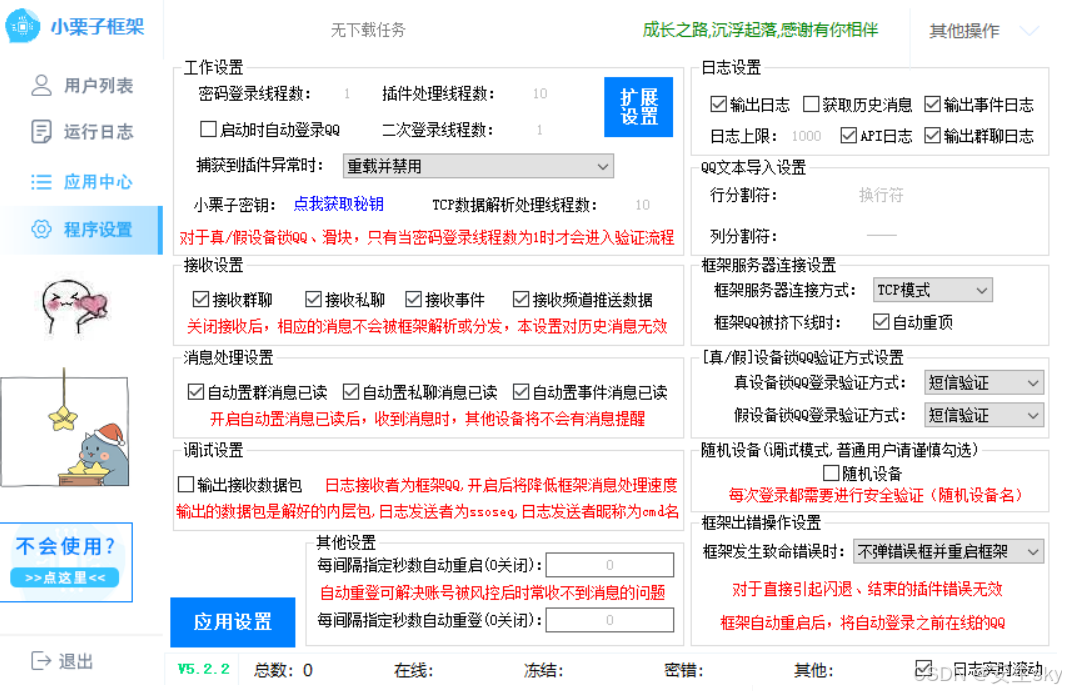
QQ机器人框架小栗子520源码
下载:小栗子520源码.zip - 蓝奏云
·

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容
下载:小栗子520源码.zip - 蓝奏云
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
0 0
已为社区贡献2条内容

所有评论(0)