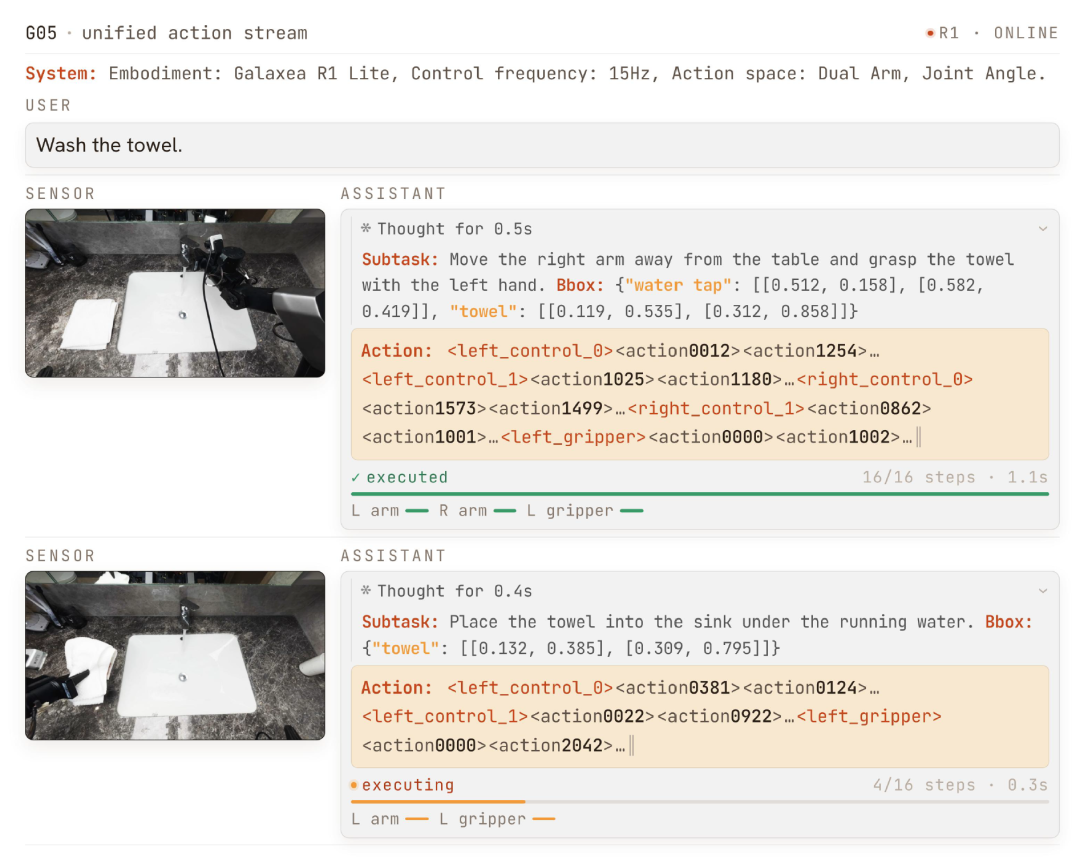
Galaxea G0.5横扫了7大具身评测:统一自回归架构重塑视觉语言动作模型
**摘要:**Galaxea G0.5模型突破了当前视觉语言动作(VLA)模型的架构局限,通过创新的跨具身动作分词器、原生思维链流和视觉记忆模块三大核心技术,实现了推理与动作生成的统一自回归框架。该模型在七大评测场景中表现卓越,包括真实世界双臂操作(76.7%成功率)、DROID零样本部署(82.5%成功率)等,全面超越现有最优方法。G0.5采用单一Transformer解码器处理多模态输入与动作
让预训练视觉语言模型真正成为机器人的决策中枢
Galaxea G0.5 Technical Report 技术报告解读 · 2026年6月
**摘要:**当前主流的视觉语言动作(VLA)模型普遍采用"视觉语言模型(VLM)作为编码器 + 独立动作专家"的架构设计,这种方案虽然提升了动作生成效率,却使得VLM退化为单纯的上下文编码器,丧失了其固有的推理与上下文学习能力。Galaxea团队最新发布的G0.5模型回归自回归本质,通过单一Transformer解码器统一生成推理与动作令牌,配合跨具身动作分词器、原生思维链流与视觉记忆模块,在七个独立评测场景中全面超越现有最优方法,为通用机器人控制提供了新的技术范式。
一、VLA架构的分野:编码器路线与行动者路线
视觉语言动作模型(Vision-Language-Action Models, VLA)作为连接大模型感知能力与物理世界交互的关键桥梁,近年来受到了学术界与产业界的广泛关注。这类模型的核心使命在于:将视觉感知、自然语言理解与机器人动作控制统一在一个框架内,使机器人能够像人类一样,通过观察环境和理解指令来完成复杂的物理操作任务。
从技术架构的维度审视,当前VLA领域呈现出两条截然不同的发展路线。第一条路线可称为"VLM-as-Encoder",即把预训练的视觉语言模型作为条件编码器,将其输出的隐藏状态或键值缓存(KV Cache)传递给一个独立训练的动作专家模块,由该模块通过流匹配(Flow Matching)或扩散(Diffusion)机制生成连续动作片段。π0、π0.5、GR00T-N1系列以及SmolVLA等代表性工作均采用了这一架构模板。
第二条路线则是"VLM-as-Actor",即保持自回归(Autoregressive)接口,将连续动作离散化后纳入语言词汇表,由VLM本身在下一令牌预测(Next-Token Prediction)的框架下直接输出动作令牌。RT-2、OpenVLA以及π0-FAST等工作属于这一脉络。
这两条路线长期以来被视为一种效率与能力之间的权衡:连续动作头擅长生成平滑的高频控制信号,而自回归方法则以推理能力和架构简洁性见长。然而,一个更为本质的差异在于VLM在系统中的角色定位——在第一条路线中,VLM不再是动作生成器,而仅仅是一个视觉语言条件编码器;最终的动作分布由一个拥有独立参数、独立优化目标的专家模块产生。这意味着VLM核心的生成式能力——包括思维链推理、上下文学习以及基于提示的运动引导——只能经过一个压缩后的条件瓶颈间接影响行为输出,无法作为动作生成的原生组成部分。
二、G0.5的核心设计理念:回归自回归本质
针对上述架构性的能力损耗,Galaxea团队提出的G0.5模型选择回归自回归 formulation,但其关键创新在于消除了原始方案效率低下的根源——过度细粒度的动作令牌化。具体而言,G0.5通过三项核心设计,使得在基础模型尺度上实现统一的自回归VLA成为可能:
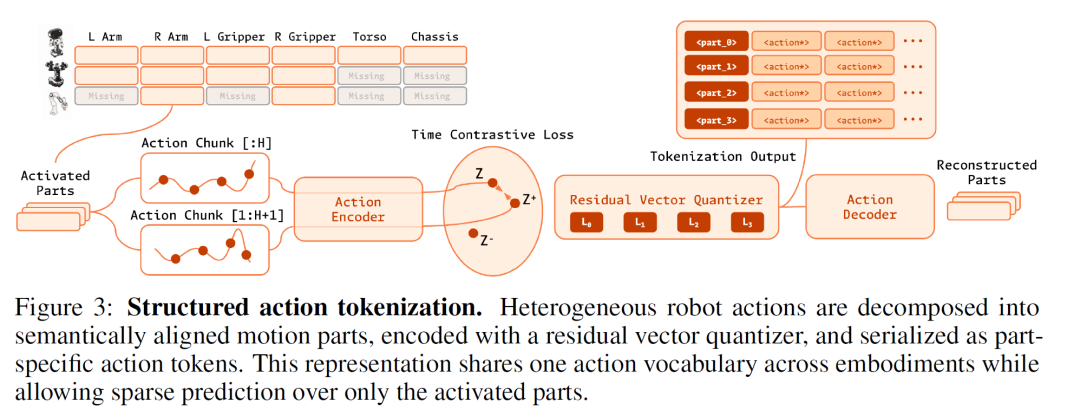
设计一:可学习的跨具身动作分词器(Learnable Cross-Embodiment Action Tokenizer)
异构机器人平台在动作空间上存在显著差异——从单臂夹爪到双臂人形机器人,从固定底座到移动底盘,自由度数量、关节构型与控制频率各不相同。G0.5引入了一个基于向量量化(Vector Quantization)的可学习动作编解码器,将不同具身平台的连续动作块压缩为紧凑的离散代码,同时通过"活跃自由度预测"机制避免为静止关节浪费令牌。当某只手臂处于闲置状态时,模型会直接将该臂的令牌组从序列中移除,而非填充占位符,从而显著降低了解码负担。
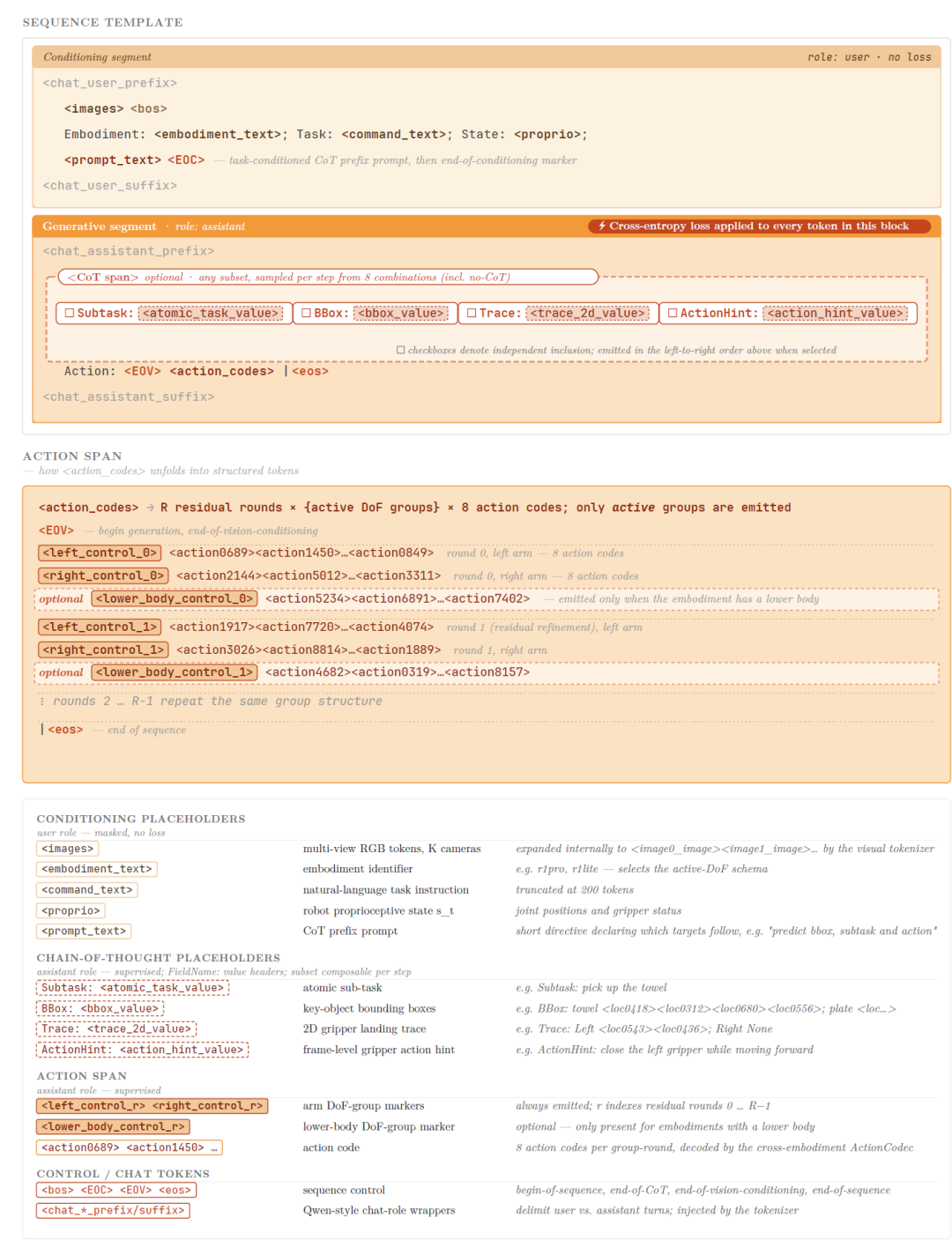
图1 G0.5的令牌序列模板。所有输入与输出被序列化为单一自回归序列:条件段(多视角RGB、具身标识、任务指令、本体感知状态)与生成段(可选思维链子集 + 动作代码)。动作代码进一步展开为R轮残差回合,每回合包含活跃自由度组标记与8个动作代码。(来源:Galaxea G0.5 Technical Report, Figure 2)
设计二:原生思维链流(Native Chain-of-Thought Stream)
研究团队构建了一套思维链模板家族,涵盖任务分解、场景 grounding 与子目标排序等维度。与现有CoT-VLA、DualCoT-VLA等将推理模块附加在VLM-as-Encoder骨干上的方案不同,G0.5的思维链令牌与动作令牌共享同一个解码器、同一个上下文和同一个优化目标。推理与动作不再是分离的两个阶段,而是同一生成过程中的耦合相位。如图1所示,在生成段中,思维链跨度(Subtask、BBox、Trace、ActionHint)与动作代码交替出现,形成自然的推理-执行交错模式。
设计三:多秒视觉记忆模块(Visual Memory Module)
机器人操作往往需要跨越数秒乃至数分钟的时间跨度来维护对场景演变的理解。G0.5在视觉编码器中注入了多帧历史信息,通过因子化时空注意力(Factorized Spatial-Temporal Attention)处理多视角视觉上下文。训练过程中以30%的概率随机丢弃历史帧,防止模型对历史上下文过拟合。这一设计使得模型在仅使用单帧输入进行后训练(Post-Training)推理时,依然能够受益于预训练阶段习得的时间动态先验。
由于推理与动作共享同一组权重,预训练VLM的能力得以直接迁移到物理行为层面:模型能够紧密遵循自然语言指令,且提示词(Prompt)可以直接调控动作粒度、任务时间跨度以及对分布外场景的处理方式,无需额外的微调训练。这种"提示即控制"(Prompt-as-Control)的特性,在很大程度上保留了大规模语言模型预训练所赋予的上下文适应能力。
三、预训练数据构成与监督策略
G0.5的预训练语料由大规模机器人数据集与视觉问答(VQA)样本共同组成。在语言标注层面,研究团队首先应用基于规则的时间分割算法识别候选动作片段与关键帧,随后调用多模态大模型API(如Gemini 3与Doubao Seed 2.0 Pro)生成动作提示、原子任务描述与片段级指令。这些多粒度语言标注使得策略能够在不同指令粒度下进行训练与查询,并为中间推理阶段的思维链配对构建提供基础。
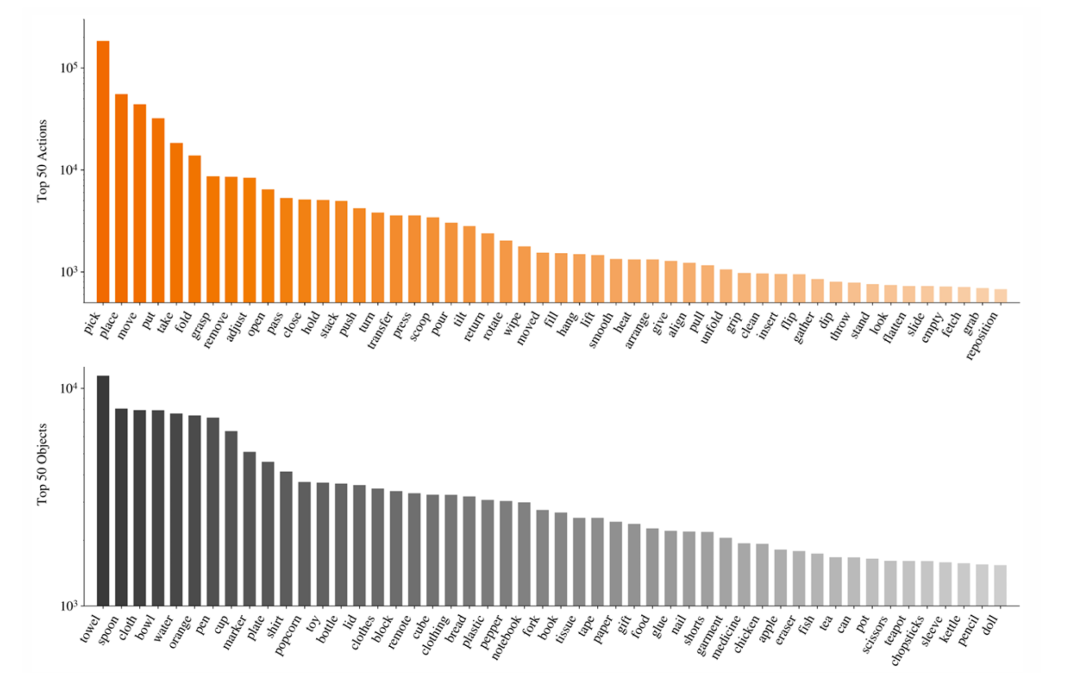
图2 预训练语料中的动作与物体概念分布。上图展示前50个动作动词,下图展示前50个物体名词,频率以对数尺度绘制。(来源:Galaxea G0.5 Technical Report, Figure 5)
如图2所示,预训练数据覆盖了丰富的动作动词(pick、place、move、put、take等)与物体名词(towel、spoon、chili、water、orange等),形成了对日常家庭环境与工业操作场景的广泛覆盖。在视觉 grounding 方面,研究团队结合多模态基础模型与SAM3追踪技术,为任务相关物体生成逐帧边界框与分割掩码;对于二维末端执行器轨迹,则通过正向运动学计算双臂末端位置,并投影到头戴相机图像平面。
为了保留VLM的通用语言能力并强化其空间感知,G0.5采用了网络与VQA协同训练策略。视觉语言混合数据约包含1亿样本,其中通用网络VQA样本、具身VQA样本与内部VQA标注各占一定比例。在预训练阶段,VQA样本与动作样本以1:4的比例混合,两者均采用相同的下一令牌交叉熵损失进行优化,因此语言答案、思维链轨迹与动作代码均在统一的自回归解码器内接受监督。
在思维链监督方面,每个机器人样本被赋予一种思维链格式,通过加权随机采样从八个候选格式中选取:无思维链基线、原子任务与高层任务文本、子任务文本、子任务加动作提示、二维轨迹追踪以及边界框变体。其中子任务文本格式被赋予更高的采样权重,以强化模型在子任务 grounding 方面的能力。
四、七大评测场景全面验证
为了全面评估G0.5作为通用VLA模型的能力边界,研究团队在七个独立的评测场景中进行了系统实验,涵盖真实世界微调、长程家庭任务、零样本部署以及多个标准化仿真基准。实验设计围绕七个核心研究问题展开:开箱即用性能、跨域迁移能力、域内任务表现、长程通用移动操作技能、语言遵循能力、上下文影响以及思维链与动作同流的实际收益。
LIBERO仿真基准98.9%平均成功率(State-of-the-Art)
RoboTwin 2.093.3%双臂操作平均成功率
SimplerEnv-Bridge87.3%跨域仿真平均成功率
DROID零样本82.5%无需微调直接部署
R1-Lite/R1-Pro76.7%真实世界双臂任务成功率
BEHAVIOR-1K31.4%50项长程家庭任务
4.1 真实世界双臂操作评估
在真实世界评估中,研究团队选用了R1-Lite与R1-Pro两种具身平台。R1-Lite为移动双臂操作平台,配备两只6自由度手臂、3自由度躯干与全向移动底座;R1-Pro则为类人上半身移动操作平台,配备两只7自由度手臂、4自由度躯干与全向底座。相比R1-Lite,R1-Pro额外的自由度提供了更强的灵巧性与全身协调能力。
评估任务涵盖毛巾折叠、纸箱折叠、铅笔盒收纳以及箱体搬运与堆叠四项代表性长程操作。以纸箱折叠任务为例,该任务涉及边缘对齐、表面折叠与结构稳定化等多个协调双臂交互阶段。由于纸箱为非刚性物体且对操作误差敏感,中间阶段的微小不精确可能导致结构损坏或组装失败,因此对双臂协调精度、接触控制稳定性与序列执行可靠性提出了极高要求。
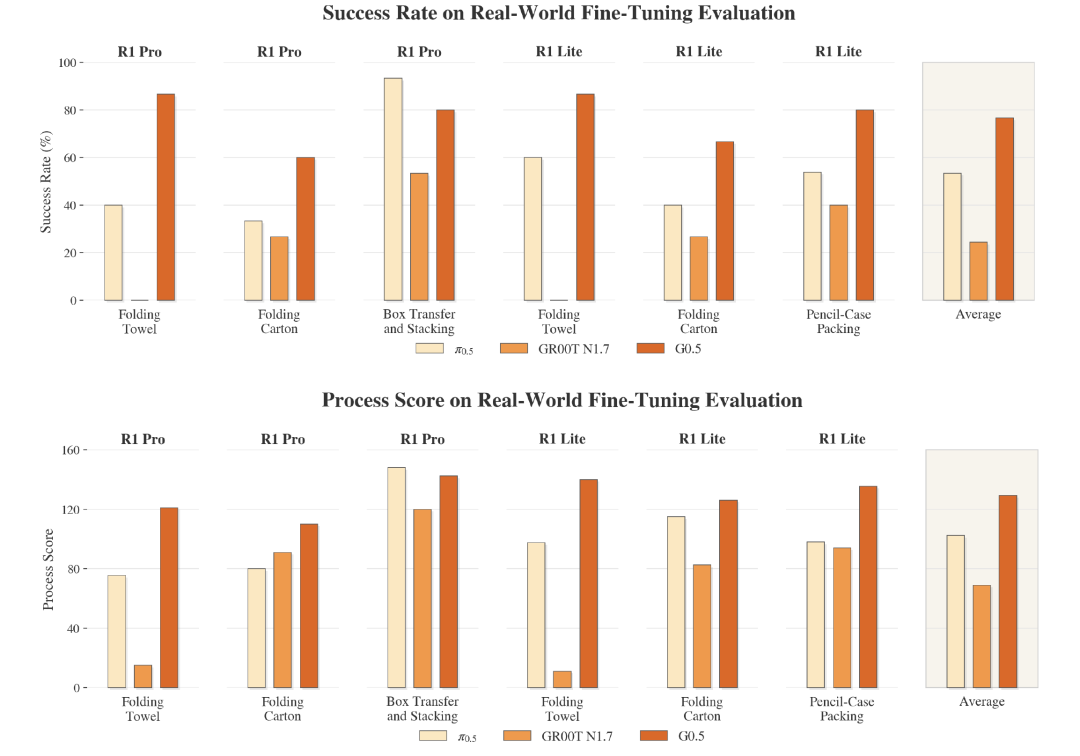
图3 真实世界微调评估结果。G0.5在六项真实世界操作设置中的任务成功率与过程得分均显著优于π0.5与GR00T-N1.7基线。(来源:Galaxea G0.5 Technical Report, Figure 9)
如图3所示,G0.5在六项真实世界评估设置中取得了最高的平均表现。整体平均成功率为76.7%,显著高于π0.5的53.3%与GR00T-N1.7的24.4%;平均过程得分达到129.2分,同样大幅领先于两个对比基线。在R1-Lite与R1-Pro两个平台共有的毛巾折叠与纸箱折叠任务上,G0.5的平均成功率为75.0%,而π0.5与GR00T-N1.7分别为43.3%与13.3%。这一结果表明,G0.5不仅能够适应特定具身平台的专属任务,还能够在相同任务目标下保持跨平台的一致性优势。
4.2 DROID零样本部署
零样本部署能力是衡量VLA模型泛化性的关键指标。研究团队在标准DROID硬件配置(Franka Research 7自由度机械臂配Robotiq 2F-85平行夹爪,双RGB相机分别提供第三人称全局视角与手腕近距离视角)上直接运行G0.5,未经过任何针对该平台的微调训练。
评估涵盖10项桌面操作任务,包括将胡萝卜/桃子移入碗中(需区分软体与刚体)、按颜色条件将积木放置到对应盘子、将积木放入高杯(需精确估计垂直间隙)、将毛巾/笔放入打开的抽屉(涉及可变形织物与细长刚性工具)、按空间方向移动碗、以及多步骤顺序任务(从碗中取出毛巾放到盘子上、将积木放入抽屉后关闭抽屉)。
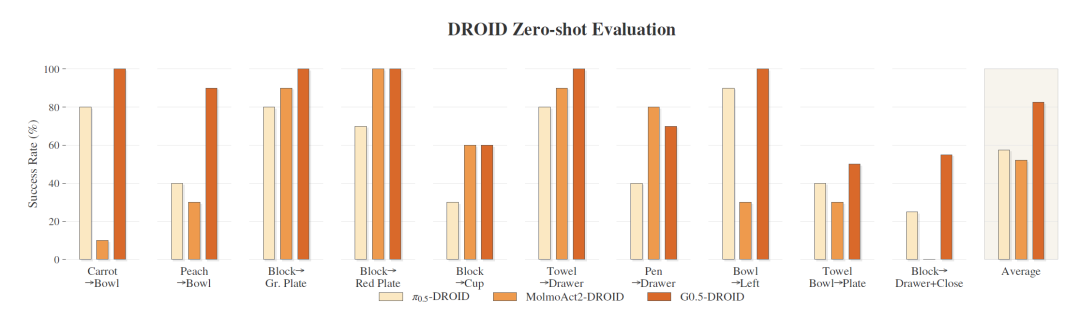
图4 DROID零样本评估结果。G0.5-DROID在全部10项任务上均优于π0.5-DROID与MolmoAct2-DROID基线,尤其在需要精确物体辨识与多步推理的任务上优势显著。(来源:Galaxea G0.5 Technical Report, Figure 7)
实验结果显示,G0.5在所有10项任务上均一致性地优于两个基线模型,平均成功率达到82.5%。在涉及外观相似物体辨识与颜色条件目标选择的任务上,G0.5展现出明显更强的视觉 grounding 能力;在涉及空间语言指令与物体类别识别的任务上,G0.5的优势尤为突出。值得注意的是,在多步骤顺序任务"将积木放入打开的抽屉并关闭抽屉"中,对比基线MolmoAct2-DROID完全失败,而G0.5-DROID在超过半数试验中取得成功,体现出显著更强的多阶段任务执行能力。
4.3 长程家庭任务:BEHAVIOR-1K Challenge
2025年BEHAVIOR挑战赛基于BEHAVIOR-1K基准与NVIDIA Isaac Sim驱动的OmniGibson仿真器构建,是评估长程移动操作能力的权威测试平台。该挑战从1000项日常活动中选取50项完整家庭任务,涵盖重新整理、烹饪、清洁与安装等多样化活动。每项演示平均时长6.6分钟,最长可达14分钟。策略需要控制R1-Pro机器人同时处理头部与双腕相机的RGB观测,在房屋尺度环境中导航,并执行灵巧的双臂操作。
评估采用任务成功得分(Task Success Score)作为主要排名指标,该指标通过计算完成BDDL目标谓词的比例并选择最佳匹配的目标子句,为部分完成任务给予信用,从而提供了比传统二元成功指标更平滑可靠的评估方式。
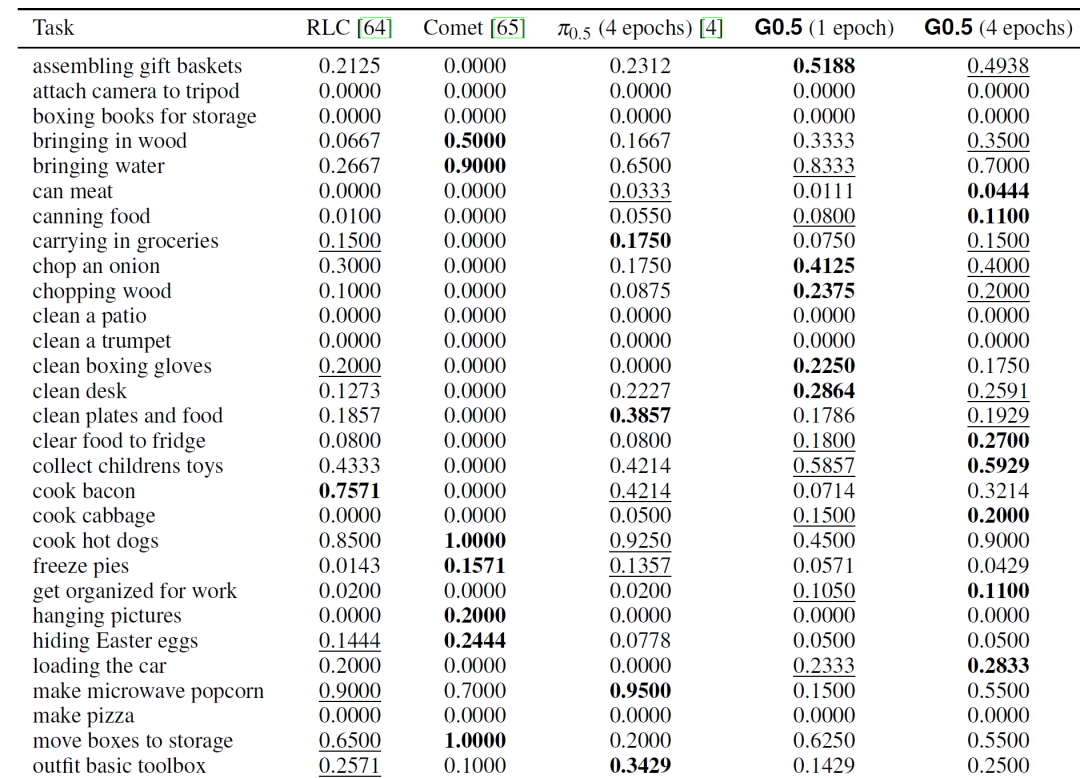
图5 BEHAVIOR-1K挑战赛50项任务详细结果。G0.5(1个checkpoint,1轮后训练周期)整体任务成功得分达到29.04%,超越π0.5(4轮后训练周期,26.26%)与挑战赛原冠军方案(26.05%)。(来源:Galaxea G0.5 Technical Report, Table 6)
如图5所示,G0.5仅使用单个checkpoint、经过一轮后训练,便在整体任务成功得分上达到29.04%,超越经过四轮后训练的π0.5(26.26%)以及使用四个checkpoint的冠军方案(26.05%)。在50项评估任务中,G0.5在29项任务上取得领先(占比58%),π0.5仅在15项任务上领先(占比30%)。这一广泛的覆盖度充分证明了预训练表示的通用性。
视觉记忆预训练对长程性能的增益在导航密集型任务上体现得尤为明显:搬运箱子到储藏室、装车、搬运木材以及整理卧室等任务需要机器人在远距离位置间反复穿梭,同时追踪已移动物体及其位置。尽管后训练阶段仅使用单帧输入,预训练阶段习得的时间动态先验使得视觉编码器能够编码场景演变的隐式理解,从而在单帧表示中蕴含更丰富的空间信息。
4.4 标准化仿真基准
在LIBERO基准(包含Goal、Spatial、Object、Long四个任务套件)上,G0.5经过10万步微调后达到98.9%的平均成功率,创下该基准上的最优表现。尤其在最具挑战性的Long套件(长程操作)上取得98.6%的成功率,显示出强大的长程任务执行能力。
在RoboTwin 2.0双臂操作仿真基准上,G0.5在清洁场景与随机化场景下的平均成功率达到93.3%,超越包括Fast-WAM(91.8%)、LingBot-VA(92.2%)在内的多个强基线。
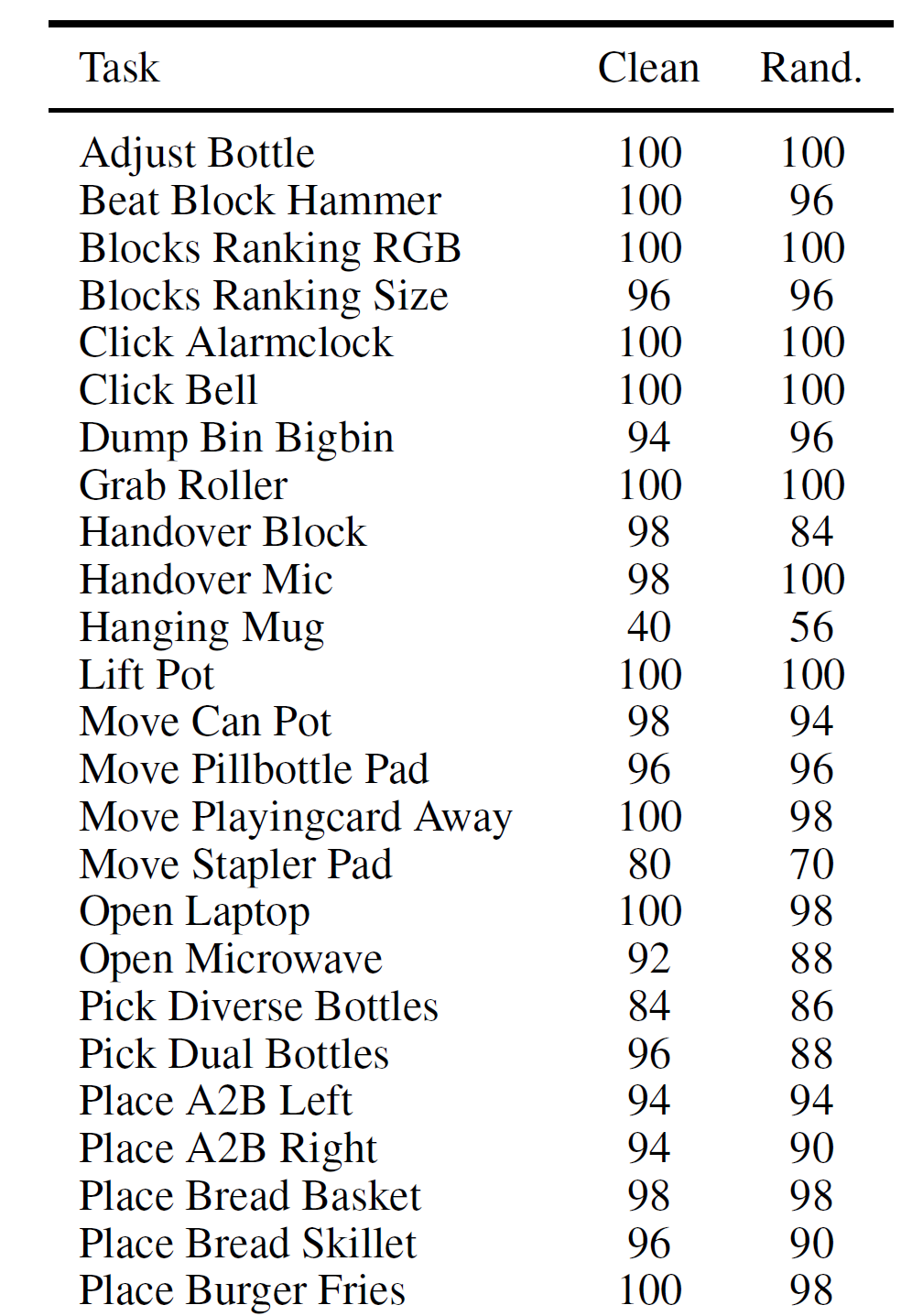
图6 G0.5在RoboTwin 2.0上的逐任务成功率。在超过50项双臂操作任务中,G0.5在清洁场景与随机化场景下均保持了高度稳定的性能。(来源:Galaxea G0.5 Technical Report, Table 7)
在SimplerEnv-Bridge跨域仿真基准上,G0.5以87.3%的平均成功率位居所有对比方法之首,较第二名Xiaomi-Robotics-0的79.2%提升超过8个百分点。这一结果验证了G0.5表示在跨域迁移场景下的有效性——当具身形态与数据分布均与预训练阶段存在差异时,预训练表示依然能够高效适配。
五、语言遵循与提示驱动的行为调控
除了低层动作生成质量,大规模预训练预期还应提升模型在视觉杂乱场景中的语言遵循能力。真实世界操作中,策略必须首先根据指令辨识目标物体与目标容器,然后执行抓取与放置等原语技能。失败可能源于两个不同层面:一是语言遵循错误(机器人与错误物体交互),二是正确目标选择后的低层执行误差。为了解耦这两个因素,研究团队专门构建了Pick-and-Place基准(PP Bench),分别报告语言遵循率与最终任务成功率。
该基准在R1-Lite平台上收集了50小时桌面操作数据,每个场景包含5至20个随机摆放的物体。测试集同时包含分布内与分布外物体类别,以检验模型的泛化性。实验结果表明,G0.5的语言遵循率在多个数据规模设置下均优于VLM-as-Encoder架构的基线,这一优势在分布外物体类别上表现得尤为明显。
更具启发性的是,G0.5展现出初步的提示级行为调控(Prompt-Level Behavior Steering)能力。在零样本长程家庭任务探针实验中,研究人员观察到,阶段级指令的措辞变化——如副词修饰语、空间提示词或近义动词替换——能够在无需重新训练的情况下改变策略的推出行为。例如,使用"小心地"(carefully)与"快速地"(quickly)修饰同一动作指令,模型在双臂协调速度与接触力控制上呈现出可辨识的差异;指定"左侧抽屉"与"右侧抽屉"时,模型能够正确映射空间关系并调整基座位姿。虽然这些观察目前仍属于定性层面的初步发现,但它们揭示了自回归接口在保留VLM上下文学习能力方面的结构性优势:当VLM仅作为外部专家的条件时,提示词可以塑造条件表示,却无法直接重塑下一动作的分布;而在统一自回归流中,提示词能够通过注意力机制直接参与动作令牌的生成过程。
六、技术意义与未来展望
G0.5的实验结果指向了若干具有结构性的技术结论,而非偶然的精度提升。首先,在Pick-and-Place基准上,G0.5的零样本语言遵循率超越了经过后训练的π0.5基线,这表明自回归动作监督保护而非削弱了VLM的指令遵循能力。其次,在BEHAVIOR-1K挑战赛上,单个G0.5 checkpoint经过一轮后训练即超越四轮后训练的π0.5与四checkpoint冠军方案,说明预训练表示携带了通用移动操作的先验知识。第三,在R1-Lite与R1-Pro平台上的匹配计算预算与相同协议微调实验中,G0.5持续领先于VLM-as-Encoder架构,表明这一优势在公平对比条件下依然成立。
这些发现共同支持了一个核心观点:VLA模型的前进路径并非在未被充分利用的VLM骨干上堆叠越来越复杂的动作专家,而是让VLM保持其预训练所赋予的本质——一个能够行动、记忆并在上下文中自适应的自回归推理器。
当然,G0.5也继承了若干有待未来工作解决的局限。抽屉插入与半透明橱柜任务在两种G0.5变体上均表现较弱,指向了感知层面的瓶颈,这一问题并非单纯通过架构变革即可闭合;视觉记忆目前仅覆盖数秒历史,更长程的记忆机制仍有待研究;下肢驱动虽然在统一动作空间中有表示,但尚未在本文中进行独立评估。更广泛地,提示级可控性所展现的潜力——在分布外家庭任务上通过阶段指令措辞调整推出行为——值得开展系统性的实证研究。
研究团队已公开发布预训练骨干模型,期待这一工作能够重新确立自回归建模作为VLA基础范式的地位,并为后续研究在长程记忆、多模态感知融合以及开放世界泛化等方向的探索提供有价值的起点。
具身智能&世界模型blog: https://jinxindeep.github.io/blog/blog2026.html

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)