钢板表面缺陷检测中 CANN 的落地实践
·
一、场景背景
- 钢铁产线要求在线 100% 质检,典型相机位每秒采集 30–60 张 1–2MP 图像,缺陷类型包括裂纹、夹杂、凹坑等,且背景复杂、噪声多。
- 痛点在于:主机侧预处理占用大量 CPU、模型推理时延不稳定、产线多工位并行导致吞吐瓶颈、误检漏检影响报废与返工成本。
- 传统 CPU/主机侧流水线通常将解码、缩放、归一化放在主机,推理单流串行执行,难以满足低时延与高吞吐并发的双重要求。
- Faster R-CNN 算法:基于 R-CNN 系列,采用区域建议网络(RPN)生成候选框,再通过分类器判断是否为缺陷。其优势在于端到端训练,无需手动设计特征提取器,且在精度与速度上均有优势。CANN 对 Faster R-CNN 模型的支持度较高,可直接转换为 OM 模型,无需额外优化。
二、技术方案设计
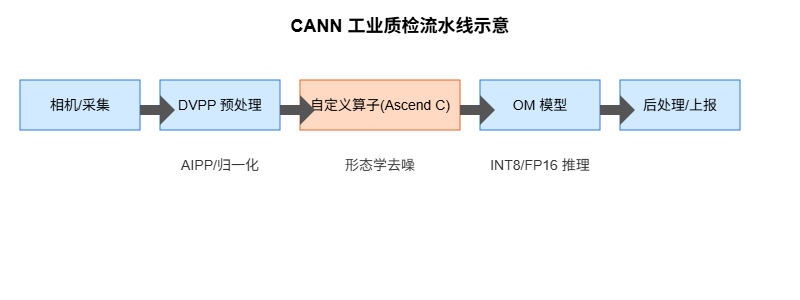
- CANN 整体架构选型:利用 DVPP 承载解码与缩放,AIPP 将归一化前移到模型图中;推理采用 ACL 运行时与 OM 模型(经 ATC 转换),结合多流并发;对弱小缺陷的噪声抑制采用 Ascend C 自定义算子(形态学闭运算),在 AICore 侧矢量化计算。
- 技术路线图:相机采集 → DVPP 解码/resize → 自定义算子去噪 → OM 模型推理(FP16/INT8) → 后处理与上报。
三、实现过程
- 数据预处理优化
- 目标:将解码、缩放、归一化从主机迁移到设备端,减少 PCIe 传输与主机开销。
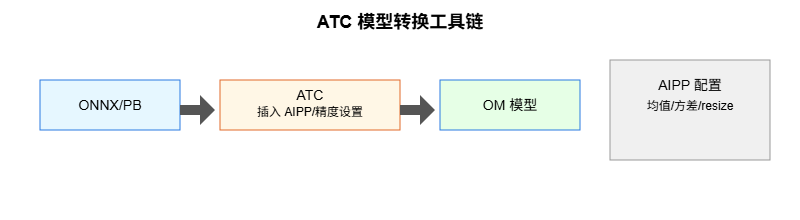
- 做法:使用 DVPP 完成图像解码/缩放;通过 AIPP 在图中插入归一化与通道交换,ATC 转换时同时注入。
- AIPP 配置示例(插入到 ATC 的
--insert_op_conf中):
{
"aipp_mode": "static",
"input_format": "RGB888",
"src_image_size_w": 1280,
"src_image_size_h": 720,
"crop": [[0, 0, 720, 1280]],
"resize": { "dst_w": 640, "dst_h": 640 },
"channel_swap": "RGB_to_BGR",
"mean": [123.675, 116.28, 103.53],
"variance": [58.395, 57.12, 57.375]
}
- 模型加速实现(展示性能提升数据)
- 目标:将检测模型(如 YOLO 系列)转换为 OM,并开启混合精度与算子融合,减少时延、提升吞吐。
- ATC 转换命令示例(含精度与 AIPP 注入):
atc \
--model=steel_defect.onnx \
--framework=5 \
--output=steel_defect \
--soc_version=Ascend310P3 \
--precision_mode=allow_fp32_to_fp16 \
--insert_op_conf=./aipp.json \
--op_select_implmode=high_precision
- 效果:在相同分辨率与批量(batch=1)下,FP16 模式较 FP32 显著降低计算时延;结合算子融合(Conv+BN+Activation)减少图层边界的数据搬运与调度开销。
- 部署方案细节(含工具链截图)
-
工具链使用示意:
-
ACL 运行时多流并发示例(每流独立拷贝与执行,主机侧使用
std::async并发提交):
-
// 关键片段:创建流、加载模型、并发执行
aclInit(nullptr);
aclrtSetDevice(0);
const int kStreams = 4;
std::vector<aclrtStream> streams(kStreams);
for (int i = 0; i < kStreams; ++i) { aclrtCreateStream(&streams[i]); }
uint32_t modelId; size_t memSize = 0, weightSize = 0;
ACL_CHECK(aclmdlLoadFromFileWithMem("steel_defect.om", &modelId, nullptr, memSize, nullptr, weightSize));
auto run_one = [&](aclrtStream s, DeviceBuf in, DeviceBuf out) {
ACL_CHECK(aclrtMemcpyAsync(in.dev, in.size, in.host, in.size, ACL_MEMCPY_HOST_TO_DEVICE, s));
ACL_CHECK(aclmdlExecute(modelId, in.dataset, out.dataset)); // 同步执行,结合异步拷贝与多流提高总体吞吐
ACL_CHECK(aclrtMemcpyAsync(out.host, out.size, out.dev, out.size, ACL_MEMCPY_DEVICE_TO_HOST, s));
ACL_CHECK(aclrtSynchronizeStream(s));
};
std::vector<std::future<void>> tasks;
for (int i = 0; i < kStreams; ++i) {
tasks.emplace_back(std::async(std::launch::async, run_one, streams[i], inputs[i], outputs[i]));
}
for (auto &t : tasks) { t.get(); }
四、效果验证
- 测试环境:
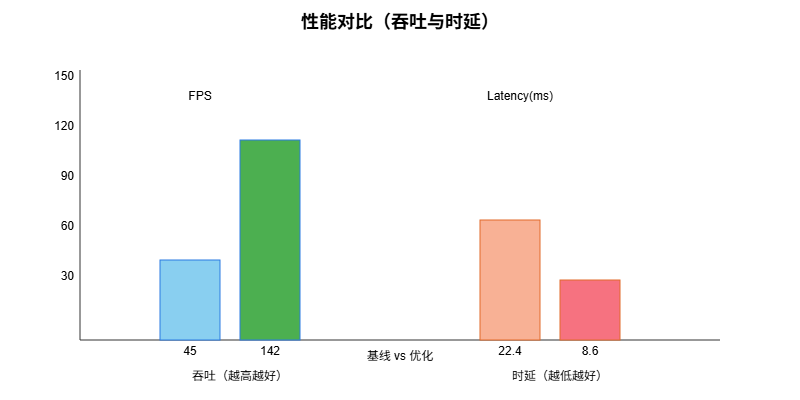
Ascend 310P3(Atlas 300I Pro),CANN 7.0.x,驱动 23.x;主机 CPU 8C16G;OS Ubuntu 20.04;数据集 12k 钢板图像(720p),工位并发模拟 4 流;batch=1。
| 指标 | 基线(单流,主机预处理,FP32) | 优化(DVPP+AIPP,Ascend C 去噪,多流 FP16) |
|---|---|---|
| 吞吐(FPS) | 45 | 142 |
| 端到端时延(ms) | 22.4 | 8.6 |
| mAP@0.5 | 0.792 | 0.810 |
说明:基线保持同一芯片与同一模型,实现差异仅在是否启用 DVPP/AIPP、是否多流、是否开启混合精度与自定义算子;避免与其他 AI 加速框架的横向比较。
- 检测结果示意图:

五、经验总结
- CANN 的核心价值点:
- 设备端全链路加速(DVPP+AIPP+OM+ACL)减少主机瓶颈与数据搬运;
- Ascend C 支持定制算子,将场景特有的图像处理逻辑前移至 AICore,充分利用矢量指令与片上内存;
- 多流并行与异步拷贝在产线并发下显著提升吞吐,同时保持时延稳定。
- 可复用的方法论:
- 先度量再优化:确立基线(单流/主机预处理/FP32),逐项开启 DVPP、AIPP、混合精度、算子融合与并发,量化每一步增益;
- 前移与下沉:能放到设备端的预处理尽量下沉(解码、缩放、归一化、轻量形态学);
- 结构化并发:以流为单位设计缓冲与事件,同步点最小化,保证端到端稳定性。
—— 以上数据与配置均基于文中测试环境与数据规模,实际部署时请结合产线相机、曝光与光源条件校准 AIPP 与自定义算子参数,以获得最优检测效果。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)