简单!直接copy代码就可运行!爬虫获取Bilibili评论数据!!!
从B站指定的视频下面的评论区中获取每条评论的:(1)评论的内容 content(2)评论者的性别 sex(3)评论的点赞数 like_count(4)评论的时间 created_time(5)评论者的 IP 地址(6)以及每条评论的子评论的(1)-(5)的信息
目录
一、简介
1.1 代码的功能
从B站指定的视频下面的评论区中获取每条评论的:
(1)评论的内容 content
(2)评论者的性别 sex
(3)评论的点赞数 like_count
(4)评论的时间 created_time
(5)评论者的 IP 地址
(6)以及每条评论的子评论的(1)-(5)的信息
1.2 适用对象
文章适用于急需使用代码爬取B站评论,没有时间搞懂原理的同学。所以代码只需要获取3处,就可以直接运行!
1.3 需要获取的3个参数
第一处:获取B站视频的Bvid账号,对应代码中的这一行
video_bv = input("请输入Bvid号:") # video_bv第二处:获取User-Agent,对应代码中的这一行
user_agent = input("请输入 User-Agent:")第三处:获取Cookie,对应代码中的这一行
cookie = input("请输入 Cookie:")接下来将介绍如何获取这三个参数!!!
二、获取Bvid账号
首先,让我们随便打开一个视频。
这个视频的链接为:【中英双语】特朗普2024年总统大选胜选后的演讲(完整版)_哔哩哔哩_bilibili
下图中红框中的一串字符(在video/后面的一串字符)就是视频的Bvid号。每个视频都只对应一个Bvid号,每个Bvid号都只对应一个视频。换言之,Bvid号是视频的一种唯一表示,通过输入这个Bvid号,将相当于告诉程序要爬取哪个视频对应的评论区了。
复制这串字符,当作运行程序后的第一个输入。

三、获取User-Agent和Cookie
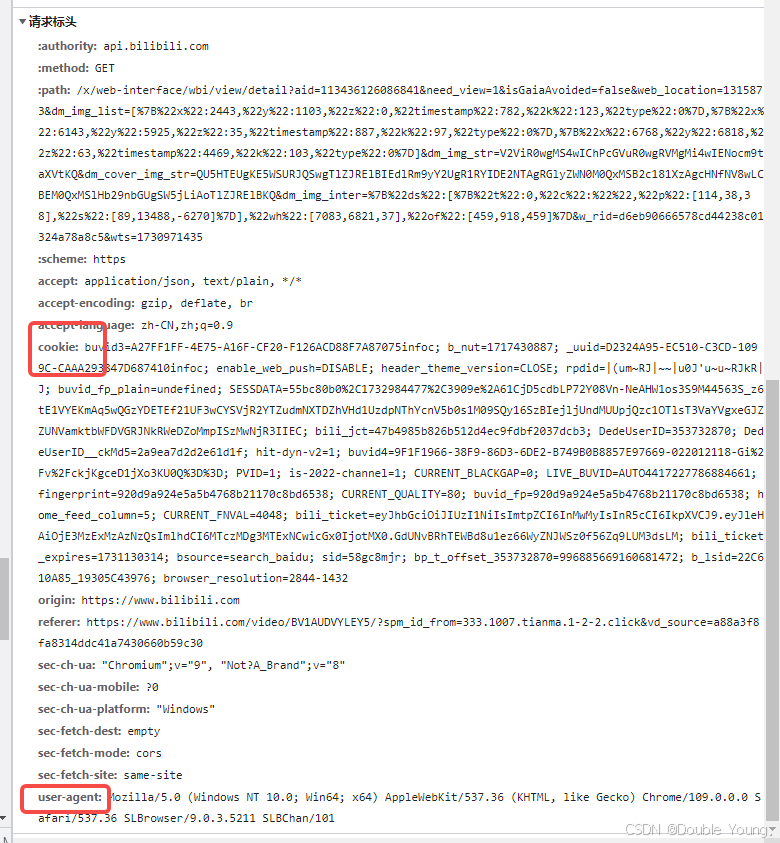
Step 1:点击F12,就可以看到抓包工具。(如何抓包工具没有显示抓到为文件,刷新一下就行)
Step 2:然后按照图片中序号的指示依次操作就行
(1)先点击搜索按钮
(2)然后在搜索框中随意搜索一个评论中的关键字
(3)接着打开搜索到的内容
(4)最后点击“标头”即可

Step 3:下拉,就可以看到User-Agent和Cookie了。分别复制然后当作程序的输入就可以了。
四、完整代码
import requests
import time
import csv
def trans_date(v_timestamp):
"""10位时间戳转换为时间字符串"""
v_timestamp = float(v_timestamp)
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
def fecth_everything(comment):
gender = comment["member"]["sex"]
# 评论的时间
time_un = comment["ctime"]
publish_time = trans_date(time_un)
# 评论的IP属地
if "location" in comment["reply_control"]:
IP = comment["reply_control"]["location"].replace("IP属地:", "")
else:
IP = "未知"
# 评论的内容
content = comment["content"]["message"]
# 评论的点赞数
num = comment["like"]
return gender, publish_time, IP, content, num
def fetch_comments(video_bv, headers, max_pages, csv_write): # 最大页面数量可调整
for page in range(1, max_pages + 1):
url = f'https://api.bilibili.com/x/v2/reply/main?next={page}&type=1&oid={video_bv}&mode=3'
print(url)
try:
# 添加超时设置
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
print(f"第{page}页已获取,over!")
if data['data']['replies'] == None:
break
if data and 'replies' in data['data']:
for comment in data['data']['replies']:
gender, publish_time, IP, content, num = fecth_everything(comment)
csv_write.writerow([gender, publish_time, IP, content, num])
if comment["replies"]:
for child in comment["replies"]:
gender, publish_time, IP, content, num = fecth_everything(child)
csv_write.writerow([gender, publish_time, IP, content, num])
else:
break
except requests.RequestException as e:
print(f"请求出错: {e}")
break
# 控制请求频率
time.sleep(1)
return comments
# 打开文件
f = open("comments.csv", mode="a", encoding="utf-8-sig")
csv_write = csv.writer(f)
video_bv = input("请输入Bvid号:") # video_bv
user_agent = input("请输入 User-Agent:")
cookie = input("请输入 Cookie:")
headers = {
'User-Agent': user_agent,
'Cookie': cookie
}
comments = fetch_comments(video_bv=video_bv, headers=headers, max_pages=40, csv_write=csv_write)
f.close()有任何问题欢迎评论区留言讨论哦!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)