【Spark计算引擎----第三篇(RDD)---《深入理解 RDD:依赖、Spark 流程、Shuffle 与缓存、Spark并行度》】
《深入理解 RDD:依赖、Spark 流程、Shuffle 与缓存》在 Apache Spark 中,Shuffle 是一个关键的概念,它涉及到数据的重新分布,通常发生在宽依赖操作中,例如groupByKeyjoin等。mapreduce的shuffle作用: 将map计算后的数据传递给reduce使用mapreduce的shuffle过程: 分区,排序,合并(规约)Shuffle 的定义Shuf
前言:
💞💞大家好,我是书生♡,本阶段和大家一起分享和探索大数据技术Spark—RDD,本篇文章主要讲述了:RDD的依赖、Spark 流程、Shuffle 与缓存等等。欢迎大家一起探索讨论!!!
💞💞代码是你的画笔,创新是你的画布,用它们绘出属于你的精彩世界,不断挑战,无限可能!
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
目录
1. RDD缓存和checkpoint
在 Apache Spark 中,缓存(也称为持久化)和 checkpoint 是两种用于优化性能和容错的重要机制。这两种机制可以帮助减少重复计算,提高应用程序的效率。
RDD的缓存和checkpoint机制也是spark计算速度快的原因之一
1.1 缓存机制
定义:
缓存是一种将 RDD 的计算结果存储在内存或磁盘上的机制。通过缓存,Spark 可以避免重新计算已经处理过的数据,从而显著提高应用程序的性能。
- 缓存是将RDD存储到内存上或者是本地磁盘上(Linux)
- 缓存是临时持久化操作

用途:
- 提高性能:对于需要多次访问的数据集,缓存可以避免重复计算,显著加快执行速度。
- 内存管理:可以根据可用内存和数据的重要性选择合适的存储级别。
- 保证RDD容错性:应用程序运行过程中, 可能因为一些原因导致rdd计算失败需要重新计算
应用场景:
- 计算时间长的rdd
- 计算成本昂贵的RDD
- 重复多次使用的RDD
注意点
- 应用程序结束后会自动清空缓存RDD
- 缓存不会切断RDD之间的依赖关系(缓存的rdd有可能丢失, 丢失后还可以通过依赖关系计算得到)
- 缓存的RDD需要通过aciton算子触发缓存任务, 触发缓存任务后的RDD才是从缓存中获取的,触发缓存任务之前, 调用的rdd还是通过依赖关系计算得到的
- 缓存级别:缓存的RDD存储在哪里 默认存储在内存中, 也可以设置存储在内存和本地磁盘
persist只是定义了一个缓存任务,并不是执行- 使用
unpersist:释放缓存
API
- cache():默认将 RDD 存储在内存中,如果内存不足则溢出到磁盘。
- persist(storageLevel):允许指定不同的存储级别,如 MEMORY_ONLY, MEMORY_AND_DISK, DISK_ONLY 等。
- is_cached :查看缓存状态,进行了缓存返回TRUE,反之返回False
- unpersist:释放缓存
缓存的级别:
缓存RDD默认存储在内存中
from pyspark.storagelevel import StorageLevel
- StorageLevel.DISK_ONLY # 将数据缓存到磁盘上
- StorageLevel.DISK_ONLY_2 #将数据缓存到磁盘上 保存两份
- StorageLevel.DISK_ONLY_3 # 将数据缓存到磁盘上 保存三份
- StorageLevel.MEMORY_ONLY # 将数据缓存到内存 默认
- StorageLevel.MEMORY_ONLY_2 #将数据缓存到内存 保存两份
- StorageLevel.MEMORY_AND_DISK # 将数据缓存到内存和磁盘 优先将数据缓存到内存上,内存不足可以缓存到磁盘
- StorageLevel.MEMORY_AND_DISK_2 # 将数据缓存到内存和磁盘
- StorageLevel.OFF_HEAP # 基本不使用 缓存在系统管理的内存上 jvm(内存)在系统上运行,系统内存
- StorageLevel.MEMORY_AND_DISK_ESER # 将数据缓存到内存和磁盘 序列化操作,按照二进制存储,节省空间
案例:
这个案例中我们对 rdd_cnt 这个RDD对象进行了缓存操作
rdd_cnt.persist(storageLevel=StorageLevel.MEMORY_ONLY)
# 创建SparkContext对象
sc = SparkContext()
# 从HDFS读取文本文件
rdd_file = sc.textFile("/data/stu.csv")
# 读取文件后,对文件进行分割,得到每个学生的信息
rdd_stu = rdd_file.map(lambda x: x.split(","))
rdd_map = rdd_stu.map(lambda x: (x[0], int(x[1])))
# 查看是否对rdd进行缓存操作, 返回True或False
print(rdd_map.is_cached)
# 统计不同年龄段的人数 0-30 为青年,30-60为中年,大于60为老年
rdd_age= rdd_map.map(lambda x: ('青年',1) if x[1]<30 else ('中年',1) if x[1]<=60 and x[1]>=30 else ('老年',1) )
rdd_cnt= rdd_age.reduceByKey(lambda x,y: x+y)
# 对rdd_reducebykey进行缓存操作, 只是定义了一个缓存任务
# 如果实现对rdd进行缓存, 需要调用action算子触发缓存任务
# 触发缓存任务之前, 调用的当前rdd还是通过依赖关系计算得到的
rdd_cnt.persist(storageLevel=StorageLevel.MEMORY_ONLY)
# 查看是否对rdd进行缓存操作, 返回True或False
print(rdd_cnt.is_cached)
# 手动释放
rdd_cnt.unpersist()
print(rdd_cnt.is_cached)
print(rdd_cnt.collect())

内存限制:确保有足够的内存来缓存数据,否则可能会导致 OutOfMemoryError。
1. 2 CheckPoint 机制
定义
Checkpoint 是一种容错机制,用于将 RDD 的数据持久化到可靠的存储系统(如 HDFS、S3 等)。与缓存不同,Checkpoint 不仅用于提高性能,还可以在节点故障时恢复数据。
- checkpoint将RDD存储到HDFS(分块多副本)中
- checkpoint的RDD是不会随程序运行结果而被清空
- checkpoint会永久存储RDD, RDD之间的依赖关系会被删除
- checkpoint是永久持久化操作
用途
- 提高计算效率
- 容错:当 Spark 应用程序遇到故障时,可以从 Checkpoint 恢复数据,避免重新计算整个数据流。
- 减少依赖:通过 Checkpoint,可以减少计算依赖的深度,从而降低故障时需要重新计算的数据量。
注意
- 永久存储在HDFS上
- 程序运行结束不会被删除
- 会切断rdd之间的依赖关系
- 需要通过action算子触发checkpoint任务
API
- setCheckpointDir(path=):将 RDD 的数据持久化到指定的目录。
- rdd.checkpoint() :对RDD进行checkpoint操作
使用
checkpoint:将rdd存储在HDFS中使用:
- ①设置checkpoint目录路径 sc.setCheckpointDir()
- ②rdd.checkpoint()
案例:
"""
checkpoint:将rdd存储在HDFS中
使用:①设置checkpoint目录路径 sc.setCheckpointDir() ②rdd.checkpoint()
注意点:①永久存储在HDFS上 ②程序运行结束不会被删除 ③会切断rdd之间的依赖关系 ④需要通过action算子触发checkpoint任务
"""
# 统计不同词出现的次数 -> 分组聚合操作
from pyspark import SparkContext
# 导入缓存级别类
from pyspark import StorageLevel
# 创建sc对象
sc = SparkContext()
# 设置checkpoint目录
sc.setCheckpointDir('/checkpoint')
# 读取hdfs文件数据,转换成rdd对象
rdd_words = sc.textFile('/data/words.txt')
rdd_flatmap = rdd_words.flatMap(lambda x: x.split(','))
rdd_map = rdd_flatmap.map(lambda x: (x, 1))
print(rdd_map.is_checkpointed)
rdd_reducebykey = rdd_map.reduceByKey(lambda x, y: x + y)
# 对rdd_reducebykey进行checkpoint操作, 只是定义了一个checkpoint任务
# 如果实现对rdd进行checkpoint, 需要调用action算子触发checkpoint任务
# 触发checkpoint任务之前, 调用的rdd还是通过依赖关系计算得到的
rdd_reducebykey.checkpoint()
# 查看是否对rdd进行checkpoint操作, 返回True或False
print(rdd_reducebykey.is_checkpointed)
# 根据词出现的次数进行降序操作
# rdd_reducebykey是通过依赖关系计算得到的, 不是从checkpoint中获取的
rdd_sortby = rdd_reducebykey.sortBy(lambda x: x[1], ascending=False)
print(rdd_sortby.collect())
# rdd_reducebykey是从checkpoint中获取的
rdd_sortby2 = rdd_reducebykey.sortBy(lambda x: x[1], ascending=True)
print(rdd_sortby2.collect())

注意事项
存储空间:确保 Checkpoint 目录有足够的存储空间。
性能开销:频繁地执行 Checkpoint 会增加额外的 I/O 开销。
2. RDD依赖
在 Apache Spark 中,弹性分布式数据集(Resilient Distributed Dataset, RDD)之间的依赖关系是 Spark 计算模型的核心部分。依赖关系决定了数据的处理顺序和粒度,同时也影响着 Spark 作业的执行效率和容错性。
-
定义:
- RDD 之间的依赖关系指的是一个 RDD 如何依赖于另一个 RDD 的数据。(相邻RDD之间存在的因果关系, 可以称为依赖关系)----》新RDD一定是由旧RDD计算得到, RDD1->RDD2->RDD3
- 这种依赖关系决定了数据流的方向和数据处理的顺序。
- RDD特性之一
- 依赖关系可以保证RDD计算的容错性, 如果rdd因为某些原因计算失败, 可以根据依赖关系重新计算
-
类型:
- 窄依赖(Narrow Dependency):每个父 RDD 分区最多被一个子 RDD 分区使用。
- 宽依赖(Wide Dependency):一个子 RDD 分区可能依赖于多个父 RDD 分区。
-
影响:
- 窄依赖:允许 Spark 在流水线中并行执行任务。
- 宽依赖:导致数据重分布,增加了计算成本。

2.1 窄依赖(Narrow Dependency)
-
定义:
- 窄依赖指的是父 RDD 的每个分区最多被一个子 RDD 分区使用。(一对一或者多对一关系)
- 窄依赖通常出现在
map、filter、union等操作中。
-
触发窄依赖关系的算子
- map()
- flatMap()
- filter()
- mapValues()
- mapPartitions()
-
特点:
- 窄依赖操作可以并行执行,因为它们不需要重新分布数据。
- 通常不会触发 shuffle 操作。


- 示例:
- 使用
map操作将每个元素乘以 2:rdd = sc.parallelize([1, 2, 3, 4, 5]) doubled_rdd = rdd.map(lambda x: x * 2)
- 使用
2.2 宽依赖(Wide Dependency)
-
定义:
- 宽依赖指的是一个子 RDD 分区可能依赖于多个父 RDD 分区。
- 宽依赖通常出现在
groupByKey、reduceByKey、join等操作中。
-
触发宽依赖关系的算子
- groupBy()
- groupByKey()
- reduceByKey()
- sortBy()
- sortByKey()
- distinct()
-
特点:
- 宽依赖操作需要触发 shuffle 操作,即数据需要在节点间进行重分布。
- 通常会导致较高的计算成本。
-
示例:
- 使用
reduceByKey对数据进行聚合:rdd = sc.parallelize([(1, 2), (1, 3), (2, 4)]) result = rdd.reduceByKey(lambda x, y: x + y)
- 使用
影响
-
计算效率:
- 窄依赖通常比宽依赖更高效,因为它们不需要 shuffle 数据。
- 宽依赖可能会导致更多的磁盘 I/O 和网络传输,从而降低性能。
-
容错性:
- RDD 的容错性是通过 lineage 信息来实现的。
- 当数据丢失时,Spark 可以根据依赖关系重新计算丢失的数据。
-
执行计划:
- Spark 的 DAGScheduler 会根据依赖关系构建执行计划。
- 宽依赖会导致新的 stage 的形成,而窄依赖则可以在同一个 stage 内执行。


示例
假设我们有一个简单的 RDD rdd1,并执行了一系列的操作来创建新的 RDD。
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
# 窄依赖
rdd2 = rdd1.map(lambda x: x * 2)
# 宽依赖
rdd3 = rdd2.groupByKey()
# 窄依赖
rdd4 = rdd3.flatMap(lambda x: x)
# 宽依赖
rdd5 = rdd4.reduceByKey(lambda x, y: x + y)
在这个例子中,rdd2 和 rdd4 之间的依赖关系是窄依赖,而 rdd3 和 rdd5 之间的依赖关系是宽依赖。宽依赖操作(如 groupByKey 和 reduceByKey)会导致数据重分布,而窄依赖操作(如 map 和 flatMap)则不需要重分布数据。
2.3 管理依赖
通过DAG有向无环图图计算算法管理RDD之间的依赖关系

- DAG称为有向无环图(有方向没有闭环), 是图计算中的一种算法
- DAG有向无环图作用
- 管理RDD之间的依赖关系, 保证RDD按照依赖关系进行有序地计算
- 根据RDD之间的依赖关系对计算任务划分成多个计算步骤, 每个步骤称为stage阶段
- 触发宽依赖关系的算子会产生新的stage阶段
- 窄依赖关系的算子计算步骤是在同一个stage阶段进行

2.4 日志查看依赖关系和计算流程
- app spark应用程序
- appID 就是这个程序的ID
- APP Name 就是这个spark程序的名字(别名)

- job -> 计算任务(一个app中是可能有多个job), 执行action算子时才会产生job

- stage -> 计算步骤/阶段, DAG根据宽依赖关系划分成多个stage

- task -> task线程任务, 真正执行的计算任务,有多少个分区就有多个task线程任务
- stage -> 计算步骤/阶段, DAG根据宽依赖关系划分成多个stage

2.5 划分stage
怎么划分stage:DAG根据宽依赖关系划分成多个stage
为甚要划分成多个stage呢?
- spark的task任务是以线程方式实现多任务计算, 线程多任务会有一个资源抢夺问题, 导致计算不准确
- spark中同一个stage中的多个task任务是并行计算的, 下一个stage中的多个task任务要想并行计算, 需要等上一个stage计算步骤完成后才能并行计算
- 为什么要等待上一个stage计算完成?
- 宽依赖是会进行shuffle过程, 数据需要重新洗牌, 等待过程就是洗牌过程
- 如何划分stage?
- 查看rdd之间是否存在宽依赖关系
- 触发宽依赖关系的算子
- 通过日志查看DAG有向无环图‘
注意:在一个stage中,会有多个线程也就是多个task任务是并行计算,那么就会有资源竞争,有的任务执行快,有的任务执行慢,当执行快的任务执行完的时候,慢的任务刚刚执行了,一旦这个时候通过宽依赖进行计算就会出现数据缺失的的问题,因此划分成多个stage,让执行快的任务等慢的任务执行完之后一起一起执行宽依赖的算子计算,这样子数据就不会缺失了。

3.Spark的运行流程(内核调度)
Spark框架中封装了三个Scheduler类完成整个spark的计算过程
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
- DAGScheduler
- 根据rdd间的依赖关系,将提交的job划分成多个stage。
- 对每个stage中的task进行描述(task编号,task执行的rdd算子)
- TaskScheduler
- 获取DAGScheduler提交的task
- 调用SchedulerBackend获取executor的资源信息
- 给task分配资源,维护task和executor对应关系
- 管理task任务队列
- 将task给到SchedulerBackend,然后由SchedulerBackend分发对应的executor执行
- SchedulerBackend
- 向RM申请资源
- 获取executor信息
- 分发task任务

- 执行spark应用程序, 创建driver进程, driver进程调用三个scheduler类创建三个scheduler对象
- schedulerbackend向资源调度工具主服务申请计算资源, 创建executor进程
- 执行了action算子触发计算任务, DAGscheduler根据宽依赖关系划分stage, 同时分析stage中的task描述, 将taskSet提交给Taskscheduler
- Taskscheduler将计算资源分配给task, 同时维护task和executor之间关系, 管理task执行顺序, 将分配计算资源的task交给schedulerbackend
- schedulerbackend将task线程任务给到executor进程执行
4.spark的shuffle过程
4.1 shuffle介绍
在 Apache Spark 中,Shuffle 是一个关键的概念,它涉及到数据的重新分布,通常发生在宽依赖操作中,例如 groupByKey, reduceByKey, join 等。
mapreduce的shuffle作用: 将map计算后的数据传递给reduce使用
mapreduce的shuffle过程: 分区,排序,合并(规约)
-
Shuffle 的定义
Shuffle 是指在 Spark 中对数据进行重新分布的过程,通常涉及到将数据从一个节点移动到另一个节点。这个过程发生在宽依赖操作中,因为这些操作需要将具有相同 key 的数据聚集在一起,而这些数据可能最初分布在不同的节点上。 -
Shuffle 的原因
Shuffle 发生的主要原因是需要将数据重新分布到不同的分区中,以便进行聚合或连接等操作。例如,在groupByKey操作中,具有相同 key 的所有元素需要被聚集在一起以进行聚合计算。 -
作用:不同阶段的数据传递
-
无论是spark shuffle还是mapreduce shuffle,本质都是传递数据 -
spark的shuffle分成两个阶段
- map阶段: shuffle write, 将上一个stage的数据保存到磁盘文件中
- reduce阶段: shuffle read, 将磁盘文件中的数据保存到下一个stage中

spark的shuffle方法类:
是spark封装好的处理shuffle的方法
- hashshuffle
- spark1.2版本之前使用, 在spark2.0版本删除
- hash(key)%分区数=结果值…余数, 余数相同的数据放到一起
- 未优化的hashshuffle -> 有多少个buffer有多少个磁盘小文件
- 优化后的hashshuffle -> 有多少个分区有多少个磁盘小文件


- sortshuffle
- spark2.0/3.0版本使用的都是sortshuffle
- 普通模式 -> 使用排序方式将数据划分
- 将分区数据存储在5M大小的memory中, 从memory取1w条数据进行排序
- bypass模式
- 类似于优化后的hashshuffle
- hash(key)%分区数=结果值…余数, 余数相同的数据放到一起


无论是hash还是排序都是将相同key值放在一起处理
- [(‘a’,1),(‘b’,2),(‘a’,1)]
- hash(key)%分区数,相同的key数据余数是相同的,会放一起,交给同一个分区进行处理
- 按照key排序,相同key的数据也会放在一起 ,然后交给同一分区处理
4.2 Shuffle 的过程
Shuffle 的过程可以分为以下几个主要阶段:
-
Map 阶段:
- Map 阶段通常涉及对输入数据进行转换,例如应用
map或flatMap等操作。 - 在宽依赖操作中,数据会被标记为需要参与 shuffle。
- Map 阶段还会进行一些优化,例如将部分结果写入本地磁盘。
- Map 阶段通常涉及对输入数据进行转换,例如应用
-
Shuffle write:
- Map 阶段产生的数据会被写入本地磁盘上的 shuffle 文件。
- 每个 map 任务都会产生一个或多个 shuffle 文件,这些文件按 key 进行分区。
- Shuffle 文件通常会被压缩以节省存储空间和传输时间。
-
Shuffle read:
- 在 shuffle 读阶段,reduce 任务会从所有 map 任务产生的 shuffle 文件中读取数据。
- 读取数据时,reduce 任务会根据 key 去定位相应的 shuffle 文件,并从中读取数据。
- 数据可能需要在网络上传输,这取决于数据的存储位置。
-
Reduce 阶段:
- Reduce 阶段处理从 shuffle 文件中读取的数据。
- 对于每个 key,reduce 任务会执行相应的聚合或连接操作。
- 最终结果会被输出到内存或磁盘上。
Shuffle 的影响
Shuffle 过程可能会显著影响 Spark 应用程序的性能,因为它涉及到大量的磁盘 I/O 和网络传输。为了减少 shuffle 的影响,可以采取以下措施:
- 减少 shuffle 的数量:尽量使用窄依赖操作来减少 shuffle 的需求。
- 调整并行度:通过设置
spark.sql.shuffle.partitions来调整 shuffle 的并行度。 - 优化数据分布:确保数据在节点之间均匀分布,以减少数据倾斜。
- 启用压缩:通过启用 shuffle 文件的压缩来减少传输的数据量。
- 使用高效的序列化方式:例如使用 Kryo 序列化器来提高序列化和反序列化的效率。
示例
假设我们有一个简单的 RDD,我们想要使用 reduceByKey 来计算每个 key 的总和。
from pyspark import SparkContext
sc = SparkContext("local", "Shuffle Example")
# 创建一个 RDD
rdd = sc.parallelize([(1, 2), (1, 3), (2, 4)])
# 使用 reduceByKey 进行聚合
result = rdd.reduceByKey(lambda x, y: x + y)
print("Result:", result.collect())
在这个例子中,reduceByKey 操作会导致 shuffle,因为需要将具有相同 key 的元素聚集在一起。
4.3 SparkShuffle配置
spark.shuffle.file.buffer
参数说明:
该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小(默认是32K)。将数据写到磁盘文件之前会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。 2倍 3倍
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升
spark.reducer.maxSizeInFlight
参数说明:
该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。(默认48M)
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetriesandspark.shuffle.io.retryWai
spark.shuffle.io.maxRetries :
shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。(默认是3次)
spark.shuffle.io.retryWait:
该参数代表了每次重试拉取数据的等待间隔。(默认为5s)
调优建议:一般的调优都是将重试次数调高,不调整时间间隔。
spark.shuffle.memoryFraction=10
参数说明:
该参数代表了Executor 1G内存中,分配给shuffle read task进行聚合操作内存比例。
spark.shuffle.manager
参数说明:该参数用于设置shufflemanager的类型(默认为sort)
Hash:spark1.x版本的默认值,HashShuffleManager
Sort:spark2.x版本的默认值,普通机制。当shuffle read task 的数量小于等于200采用bypass机制
spark.shuffle.sort.bypassMergeThreshold=200- 根据task数量决定sortshuffle的模式
- task数量小于等于200 就采用bypass task大于200就采用普通模式
参数说明:
当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作。
调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些
- 交互式开发中使用
pyspark --master yarn --name shuffle_demo --conf 'spark.shuffle.sort.bypassMergeThreshold=300'
通过--conf = ''来配置参数
- 脚本中配置参数
- 创建conf对象, 实现spark参数设置
- 对象名=类名()
- 调用set()返回对象本身
conf = (SparkConf().
set('spark.shuffle.sort.bypassMergeThreshold', '300').
set('spark.shuffle.io.maxRetries', '5'))
- 创建sc对象
- 传递conf对象
- sc = SparkContext(master=‘yarn’, appName=‘shuffle_demo’, conf=conf)
from pyspark import SparkContext
from pyspark import SparkConf
# 创建conf对象, 实现spark参数设置
# 对象名=类名()
# 调用set()返回对象本身
conf = (SparkConf().
set('spark.shuffle.sort.bypassMergeThreshold', '300').
set('spark.shuffle.io.maxRetries', '5'))
# 创建sc对象
# 传递conf对象
sc = SparkContext(master='yarn', appName='shuffle_demo', conf=conf)
# 读取hdfs文件数据,转换成rdd对象
rdd_words = sc.textFile('/data/words.txt')
print(rdd_words.take(num=3))
rdd_flatmap = rdd_words.flatMap(lambda x: x.split(','))
print(rdd_flatmap.collect())
rdd_map = rdd_flatmap.map(lambda x: (x, 1))
print(rdd_map.collect())
rdd_reducebykey = rdd_map.reduceByKey(lambda x, y: x + y)
print(rdd_reducebykey.collect())
# 根据词出现的次数进行降序操作
rdd_sortby = rdd_reducebykey.sortBy(lambda x: x[1], ascending=False)
print(rdd_sortby.collect())
查看历史服务,发现配置生效
5. spark并行度
作用:
- 提高程序的执行效率
- 合理分配资源
spark并行也是spark中的一种调优手段
- 资源并行度(物理并行度)
- 调整spark集群的executor数量和core数量
- executor进程->工作节点服务器的数量
- core核->cpu核数
- 从多任务角度去思考
- spark是以线程方式实现的多任务, 一个核处理一个task线程, 有多少个核可以同时执行多少个task线程
- 数据并行度(逻辑并行度)
- 调整RDD/DF分区数
- 一个分区数据对应一个task线程, 一个task线程由一个核执行
- 官方建议分区数是总核数的2-3倍
- 分区的数据量大小可能不一样, 存在有些task先执行完成, 就会造成资源浪费问题
5.1 资源并行度(物理并行)
spark中cpu核心数据设置
- –num-executors=2 设置executors数量
- –executor-cores=2 设置每个executors中的cpu核心数,不能超过服务器cpu核心数
这两个参数的配置只能在指令中配置,脚本中是不行的
spark-submit --master yarn --deploy-mode cluster --num-executors 3 --executor-cores 2 a.py
5.2 数据并行度
数据并行度又称为
逻辑并行,由task数量决定,task由分区数决定,
因此我们的数据并行就是配置分区数
-
创建RDD对象的时候指定分区数
sc.parallelize(c=, numSlices=)通过Python类型的对象创建sc.textFile(name=, minPartitons=)通过文件类型的对象创建sc.wholeTextFiles(name=, minPartitons=)通过合并文件类型的对象创建
from pyspark import SparkContext
# 创建sc对象
sc = SparkContext()
# 创建rdd对象
rdd1 = sc.parallelize([1, 2, 3, 1, 2, 5, 6, 4, 5, 6, 7, 8], numSlices=4)
print(rdd1.glom().collect())
rdd2 = sc.textFile('/data/words.txt', minPartitions=4)
print(rdd2.glom().collect())
rdd3 = sc.wholeTextFiles('/data', minPartitions=2)
print(rdd3.glom().collect())
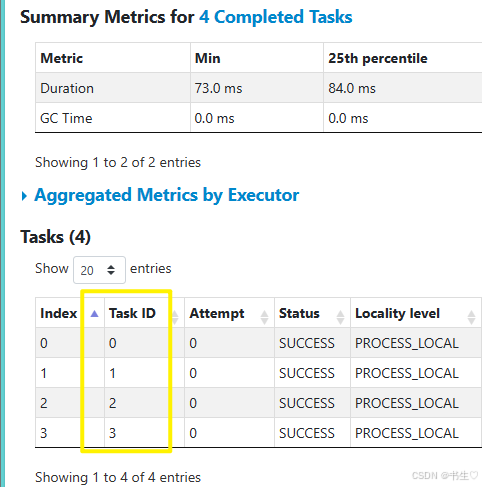
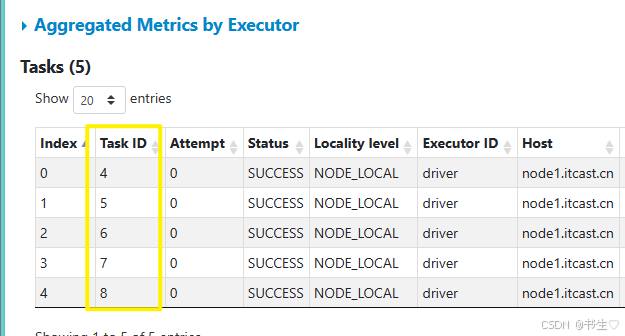
- 调用rdd对象transformation算子时修改分区数
'''
②调用转化算子时调整新rdd分区数
rdd1.distinct(numPartitions=)
rdd1.groupBy(numPartitions=)
rdd1.reduceByKey(numPartitions=)
rdd1.sortBy(numPartitions=)
rdd1.sortByKey(numPartitions=)
rdd1.groupByKey(numPartitions=)
'''
# 调用转化算子时调整新rdd分区数
# rdd4 = rdd1.distinct(numPartitions=3)
rdd4 = rdd1.distinct(numPartitions=6)
print(rdd4.glom().collect())
# rdd1.groupBy(numPartitions=)
# rdd1.reduceByKey(numPartitions=)
# rdd1.sortBy(numPartitions=)
# rdd1.sortByKey(numPartitions=)
# rdd1.groupByKey(numPartitions=)
我将去重的转换算子分区数设置为6 ,因此执行完成后就会有6 task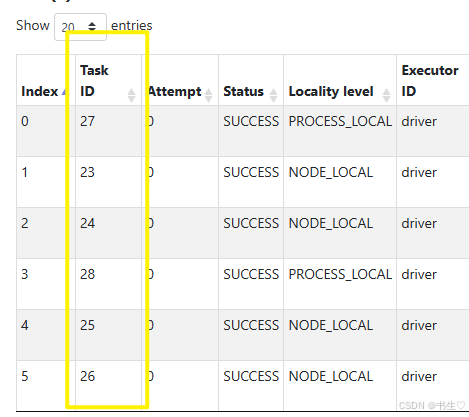
- 调用rdd对象修改分区数的transformation算子
rdd/df.repartition(numPartitions=) rdd/df.coalesce(numPartitions=,shuffle=False)
#coalesce()方法的参数shuffle, 默认设置为false
#repartition()方法就是coalesce()方法shuffle为true的情况。
repartition
- repartition(numPartitions=)等于coalesce(shuffle=True)操作
- repartition(numPartitions=)一定会发生shuffle过程
- repartition可以增加或减少rdd的分区数
coalesce
- coalesce(numPartitions=, shuffle=False)
- coalesce只能减少rdd的分区数, 不能增加分区数
应用场景:
- 增加分区数: 旧rdd分区数<新rdd分区数, 一定会发生shuffle 使用repartition()(shuffle=True)
- 减少分区数: 旧rdd分区数>新rdd分区数(相差不大), 将旧rdd多个分区数据合并到一个分区中(不发生shuffle), 使用coalesce(shuffle=False)
- 减少分区数: 旧rdd分区数>>新rdd分区数(相差很大), 使用repartition()或coalesce(shuffle=True), 将数据重新洗牌, 保证相同数据放到一起处理(提高性能)
# 增加分区数
rdd_repartition1 = rdd1.repartition(numPartitions=6)
print(rdd_repartition1.glom().collect())
# 减少分区数
rdd_repartition2 = rdd1.repartition(numPartitions=3)
print(rdd_repartition2.glom().collect())
print('=' * 50)
# 增加分区数, 没有效果
rdd_coalesce1 = rdd1.coalesce(numPartitions=6, shuffle=False)
print(rdd_coalesce1.glom().collect())
# 减少分区数
rdd_coalesce2 = rdd1.coalesce(numPartitions=3, shuffle=False)
print(rdd_coalesce2.glom().collect())
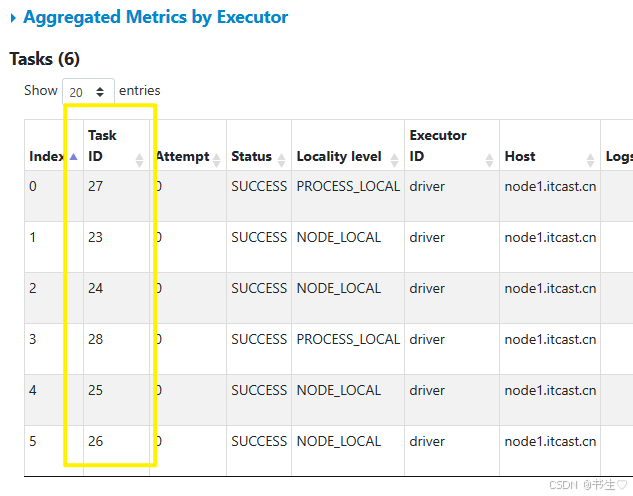
💕💕在这篇文章中,我们深入探讨了深入理解 RDD:依赖、Spark 流程、Shuffle 与缓存、Spark并行度,希望能为读者带来启发和收获。
💖💖感谢大家的阅读,如果您有任何疑问或建议,欢迎在评论区留言交流。同时,也请大家关注我的后续文章,一起探索更多知识领域。
愿我们共同进步,不断提升自我。💞💞💞

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)