教你用python爬取『京东』商品数据,原来这么简单!
从入手,一步一步教大家如何爬取『』商品数据,文中以【】电脑为例!通过api的接口可以快速的获取商品的数据,例如商品颜色,价格,评论等第二步:确定好需要的接口第三步:充值就可以使用京东以下接口的选择。
·
从小白的角度入手,一步一步教大家如何爬取『京东』商品数据,文中以【笔记本】电脑为例!
干货内容包括:
如何爬取商品信息?
如何爬取下一页?
通过api的接口可以快速的获取商品的数据,例如商品颜色,价格,评论等
第二步:确定好需要的接口
第三步:充值就可以使用
京东以下接口的选择
- item_get获得JD商品详情
- item_sku获得JD商品sku信息
- item_cat_get获得JD商品类目信息
- item_get_desc获得京东商品描述
- item_search按关键字搜索商品
- item_search_img按图搜索京东商品(拍立淘)
- item_search_shop获得店铺的所有商品
- item_history_price获取商品历史价格信息
- item_recommend获取推荐商品列表
- upload_img上传图片到JD
- item_review获得JD商品评论
- item_get_app获得JD商品详情原数据
- cat_get获得jd商品分类
1.查看网页
在『京东商城』搜索框输入:笔记本
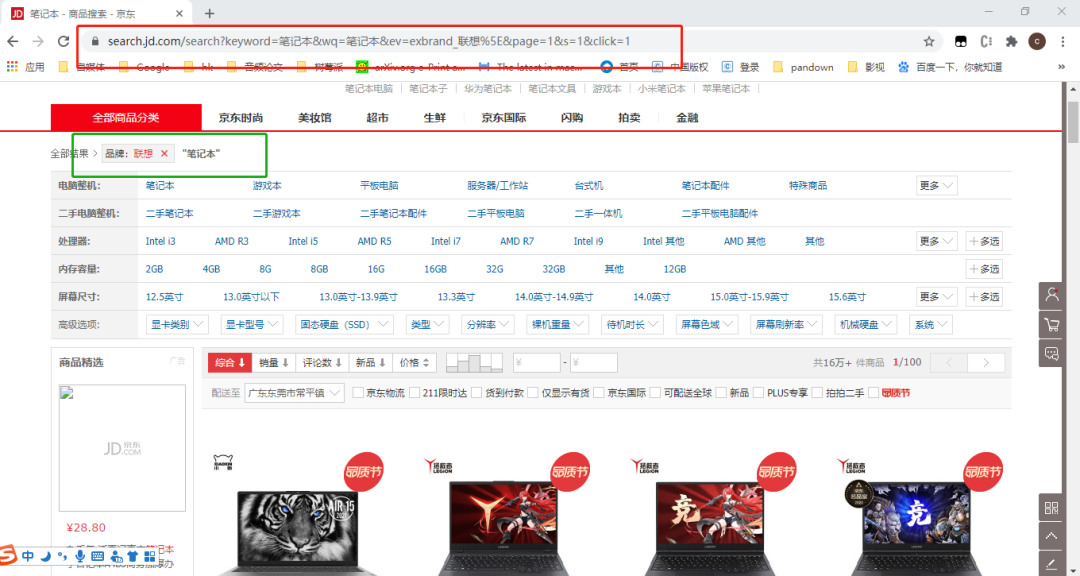
链接如下:
https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_联想%5E&page=9&s=241&click=1在浏览器里面按F12,分析网页标签(这里我们需要爬取1.商品名称、2.商品价格、3.商品评论数)
2.分析网页标签
获取当前网页所有商品
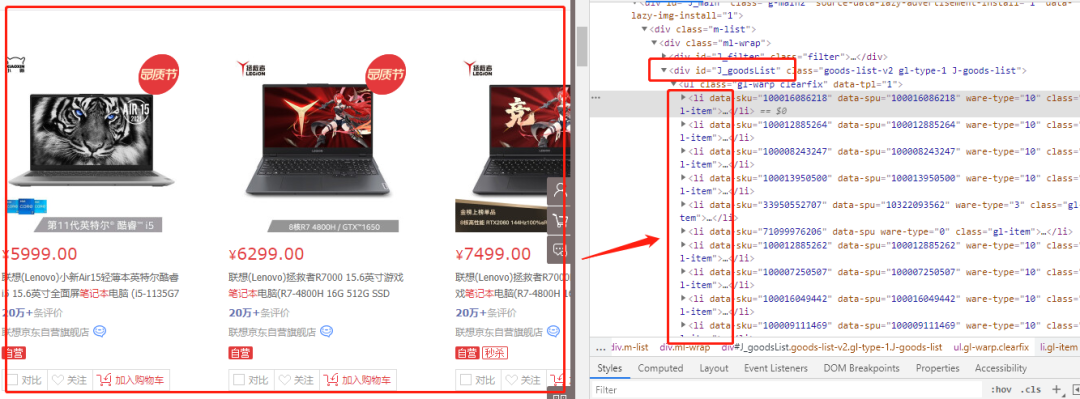
可以看到在class标签id=J_goodsList里ul->li,对应着所有商品列表
获取商品具体属性
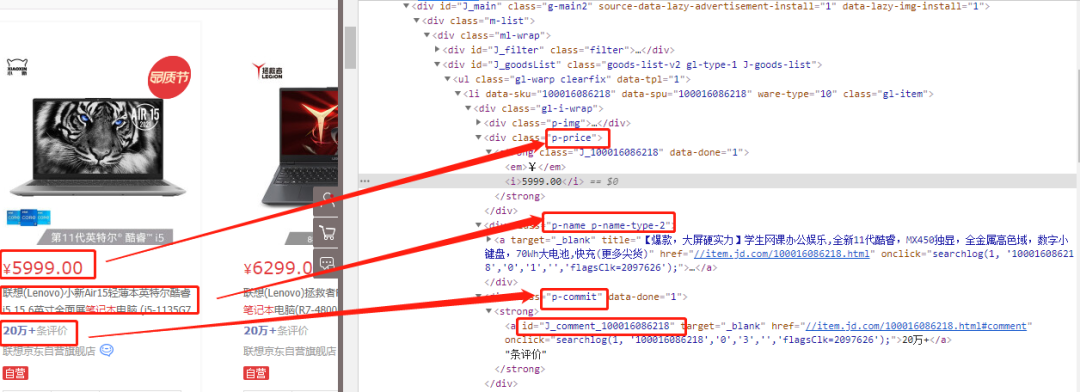
每一个li(商品)标签中,class=p-name p-name-type-2对应商品标题,class=p-price对应商品价格,class=p-commit对应商品ID(方便后面获取评论数)
避坑:
这里商品评论数不能直接在网页上获取!!!,需要根据商品ID去获取。
爬取数据
1.编程实现
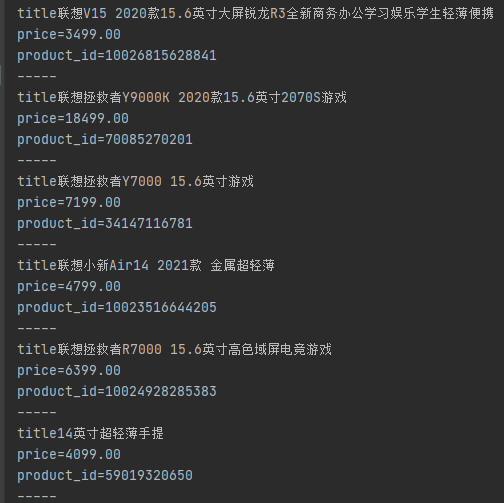
url="https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_联想%5E&page=9&s=241&click=1"res = requests.get(url,headers=headers)res.encoding = 'utf-8'text = res.textselector = etree.HTML(text)list = selector.xpath('//*[@id="J_goodsList"]/ul/li')for i in list:title=i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0]price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0]product_id = i.xpath('.//div[@class="p-commit"]/strong/a/@id')[0].replace("J_comment_","")print("title"+str(title))print("price="+str(price))print("product_id="+str(product_id))print("-----")

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)