人工智能导论:八数码问题(Python实现)
一篇文章帮你解决:A算法和A*算法傻傻分不清?不理解A*算法原理?为什么八数码问题会出现无解的情况?
目录
〇、写在前面
本文从数据结构开始梳理A*算法及相关知识点,只需要阅读广度优先搜索(BNF)和A*算法的即可速通本文章,其他内容仅作拓展。
一、八数码问题
1.引入问题
一个九宫格里有数字1~8和一个空格,只能将数字移动到相邻的空格里,要求把九宫格由初始状态转化为目标状态,如图
1 |
2 |
3 |
4 |
5 |
|
6 |
7 |
8 |
1 |
2 |
3 |
4 |
5 |
|
6 |
7 |
8 |
对于这种初始状态和目标状态,只需要把“5”向右移动一格就行了,这等效于把“空格”向左移动一格。在接下来的代码实践中,我们用二维列表模拟九宫格,用“0”代替空格进行移动。
2.分析问题
现在有以下状态:
2 |
7 |
8 |
1 |
0 |
3 |
2 |
4 |
5 |
0 |
1 |
2 |
5 |
4 |
3 |
6 |
7 |
8 |
在Python中用列表表示:
initial = [
[2,7,8],
[1,0,3],
[6,4,5]
]
goal = [
[0,1,2],
[5,4,3],
[6,7,8]
]注意目标数组第二行的顺序是[5, 4, 3]。
思考得出如下几条基本规则:
①“0”一开始可以向四个方向移动
②如果向左移动,此时“0”在左边,下次移动不能再向左移动(即每次移动都需要判断是否越界)
③如果本次向左移动,下次移动不能再向右移动,否则就会重复;如果按照“上”、“下”、“左”、“右”顺序进行移动,会回到原点,也会重复(即每次移动判断是否重复,这样可以提高代码运行效率)
我们发现,每做一次选择后,为了实现这些规则,我们很容易想到可以利用树的结构解决这个问题(有关“树”的解释见文章末尾),那么自然地引出以下三种方法:
①广度优先搜索BFS
②深度优先搜索DFS
③A*算法
其中,本文的重点是A*算法,BFS是铺垫,DFS是扩展内容。
下文将依次分步实现这些算法。
二、广度优先搜索(BFS)和深度优先搜索(DFS)
1.基本功能的实现
整体思路是边搜索边搭建这个搜索树。
首先导入copy包,用于深拷贝代表九宫格的二维列表;创建一个字典储存移动方式;创建一个队列用来储存搜索顺序;建立一个树的数据结构,用来储存每一步移动的结果。
value:本次移动后的九宫格。
parent:上次移动后的九宫格
children:下次移动后的九宫格列表
path:记录如何以移动“0”,从初始状态变为当前状态,如“上左下下右上”
import copy
# 基础数据
moves = [(1,0),(0,1),(-1,0),(0,-1)]
direction = ['上','右','下','左']
# 由两个列表创建字典
dic = dict(zip(moves, direction))
# 操作队列
queue:list = []
#数组的边界大小
MAX = 3
MIN = 0
# 节点类
class Node:
value: list[list[int]]
parent: 'Node'
children: list['Node']
path: str
# 创建子节点时需要定义子节点的数据、父节点、节点路径
def __init__(self, value, parent=None, path = ""):
self.value = copy.deepcopy(value)
self.parent = parent
self.children = []
self.path = copy.deepcopy(path)
# 树类
class Tree:
root: Node
def __init__(self, root):
self.root = root接下来是核心方法:
# 寻找0的坐标
def find_zero(matrix: list[list[int]]):
for i in range(len(matrix)):
for j in range(len(matrix[i])):
if matrix[i][j] == 0:
return i,j
# 判断两个矩阵是否相等
def is_equal(matrix1: list[list[int]] ,matrix2: list[list[int]]):
for i in range(len(matrix1)):
for j in range(len(matrix2)):
if matrix1[i][j] != matrix2[i][j]:
return False
return True
def generate(node: Node):
# 首先确定零在当前状态的位置
location = find_zero(node.value)
# 尝试从四个方向移动
for move in moves:
# x,y为移动后0的坐标
x, y = location[0]+move[0], location[1]+move[1]
if MIN <= x < MAX and MIN <= y < MAX:
# 如果移动成功,就创建一个子节点
node.children.append(Node(node.value,node,node.path))
# 移动0的位置
node.children[-1].value[location[0]][location[1]] = node.children[-1].value[x][y]
node.children[-1].value[x][y] = 0
# 添加该子节点的路径
node.children[-1].path += dic[move]
# 输出当前路径
print(node.children[-1].path, end = '\n')
# 如果寻找到了正确路径,就返回该路径
if is_equal(node.children[-1].value, goal):
return node.children[-1].path
# 把该子节点添加到队列
queue.insert(0, node.children[-1])
return ''然后定义初末状态,依次把队列中的节点作为参数传入generate()中创建子节点并判断是否符合条件,这样就实现了广度优先搜索。
initial = [
[2,7,8],
[1,0,3],
[6,4,5]
]
goal = [
[0,1,2],
[5,4,3],
[6,7,8]
]
tree = Tree(Node(initial))
queue.insert(0, tree.root)
while True:
path = generate(queue.pop())
if path != '':
print("找到路径,该路径长度为", len(path),":")
print(path)
break2.简单优化
当然如果你用我给的initial和goal执行代码,那么一个月也不一定能算完(最短路径要移动22次,那么循环次数不少于2的22次幂,这是个天文数字)。代码已经实现了基本规则①和②(见问题分析部分),但是为了提高代码效率,还需要实现规则③,即判断重复,如果这个状态之前已经出现过,就会造成算力的浪费。
接下来我们创建一个集合,用来储存节点的状态:
# 集合(防止重复搜索,提高效率)
visited = set()接下来我们在节点类里面创建一个状态变量,把九宫格映射为一个九位数储存在这个状态变量中,这样每一个九宫格状态都有唯一的九位数与其一一对应,其实就是手写了一个哈希函数。
定义一个全局哈希函数:
# hash函数
def my_hash(matrix: list[list[int]]):
state = 0
for i in range(len(matrix)):
for j in range(len(matrix[i])):
state += matrix[i][j]
state *= 10
state /= 10
return state再在节点类中增加一个state成员变量,并在节点类中定义一个update_state()函数:
state: int
# 新增编码状态的方法
def update_state(self):
self.state = my_hash(self.value)思考:为什么不把代表九宫格的列表直接当作状态储存在集合中呢?
因为有哈希表了,通过哈希值进行比较效率更高,因此可以优化掉原来的is_equal()方法,把goal列表转化为hash值,最后,增加一个判重的方法,在generate()中添加判重这一步骤。
把goal转化为hash值:
hash_goal = my_hash(goal)添加一个判重方法:
# 判断该状态是否存在过
def is_visited(state: int):
if state in visited:
return True
else:
visited.add(state)
return False在generate()方法中添加判重的步骤,修改判断相同的方法:
# 更新节点状态并判重
node.children[-1].update_state()
if is_visited(node.children[-1].state):
node.children.pop()
continue
# 如果寻找到了正确路径,就返回该路径(比较哈希值)
if node.children[-1].state == hash_goal:
return node.children[-1].path3.广度优先搜索的完整代码
完整代码如下:
import copy
# 基础数据
moves = [(1,0),(0,1),(-1,0),(0,-1)]
direction = ['下','右','上','左']
# 由两个列表创建字典
dic = dict(zip(moves, direction))
# 集合(防止重复搜索,提高效率)
visited = set()
# 操作队列
queue:list = []
#数组的边界大小
MAX = 3
MIN = 0
# 节点类
class Node:
value: list[list[int]]
parent: 'Node'
children: list['Node']
path: str
state: int
# 创建子节点时需要定义子节点的数据、父节点、节点路径
def __init__(self, value, parent=None, path = ""):
self.value = copy.deepcopy(value)
self.parent = parent
self.children = []
self.path = copy.deepcopy(path)
def update_state(self):
self.state = my_hash(self.value)
# 树类
class Tree:
root: Node
def __init__(self, root):
self.root = root
# 哈希函数
def my_hash(matrix: list[list[int]]):
state = 0
for i in range(len(matrix)):
for j in range(len(matrix[i])):
state += matrix[i][j]
state *= 10
state /= 10
return state
# 寻找0的坐标
def find_zero(matrix: list[list[int]]):
for i in range(len(matrix)):
for j in range(len(matrix[i])):
if matrix[i][j] == 0:
return i,j
# 判断该状态是否存在过
def is_visited(state: int):
if state in visited:
return True
else:
visited.add(state)
return False
def generate(node: Node):
# 首先确定零在当前状态的位置
location = find_zero(node.value)
# 尝试从四个方向移动
for move in moves:
# x,y为移动后0的坐标
x, y = location[0]+move[0], location[1]+move[1]
if MIN <= x < MAX and MIN <= y < MAX:
# 如果移动成功,就创建一个子节点
node.children.append(Node(node.value,node,node.path))
# 移动0的位置
node.children[-1].value[location[0]][location[1]] = node.children[-1].value[x][y]
node.children[-1].value[x][y] = 0
# 添加该子节点的路径
node.children[-1].path += dic[move]
# 输出当前路径
print(node.children[-1].path, end = '\n')
# 更新节点状态并判重
node.children[-1].update_state()
if is_visited(node.children[-1].state):
node.children.pop()
continue
# 如果寻找到了正确路径,就返回该路径
if node.children[-1].state == hash_goal:
return node.children[-1].path
# 把该子节点添加到队列
queue.insert(0, node.children[-1])
return ''
initial = [
[2,7,8],
[1,0,3],
[6,4,5]
]
goal = [
[0,1,2],
[5,4,3],
[6,7,8]
]
hash_goal = my_hash(goal)
tree = Tree(Node(initial))
queue.insert(0, tree.root)
while True:
path = generate(queue.pop())
if path != '':
print("找到路径,该路径长度为", len(path),":")
print(path)
break运行结果:

4.深度优先搜索
思路是:如果遇到状态重复的情况,就退回到上一个节点。核心代码相同,只要把队列改为栈即可。
如果你用的是Pycharm,按住快捷键Ctrl+R,把本文件所有的queue替换为stack(这一步完全可以省略,命名完美主义罢了),如果是其他编辑器则按住Ctrl+H进行替换。
然后改两处代码,①在generate()中,原来是把节点添加在队尾,更改为添加到栈顶。②注释掉generate()方法中输出当前节点路径的代码(否则程序运行会异常缓慢,思考:为什么?)。
以下是更改后的generate()方法:
def generate(node: Node):
# 首先确定零在当前状态的位置
location = find_zero(node.value)
# 尝试从四个方向移动
for move in moves:
# x,y为移动后0的坐标
x, y = location[0]+move[0], location[1]+move[1]
if MIN <= x < MAX and MIN <= y < MAX:
# 如果移动成功,就创建一个子节点
node.children.append(Node(node.value,node,node.path))
# 移动0的位置
node.children[-1].value[location[0]][location[1]] = node.children[-1].value[x][y]
node.children[-1].value[x][y] = 0
# 添加该子节点的路径
node.children[-1].path += dic[move]
# 输出当前路径
# print(node.children[-1].path, end = '\n') # 这里有更改
# 更新节点状态并判重, 并且规定节点路径长度不得超过50
node.children[-1].update_state()
if is_visited(node.children[-1].state):
node.children.pop()
continue
# 如果寻找到了正确路径,就返回该路径
if is_equal(node.children[-1].value, goal):
return node.children[-1].path
# 把该子节点添加到栈顶
stack.append(node.children[-1]) # 这里有更改
return ''运行该代码时需要耐心等待,最后会输出一个特别长的路径,如下:

如果你比较在乎运行效率,以上代码就是比较好的代码了,下面优化的环节会严重降低代码运行效率。
5.简单优化:
如果要缩短路径长度,我们可以事先规定搜索范围,也就是限定最大路径长度。
思考:第一步要删除用于判重的相关代码,想想看为什么?
总共需要删除的地方有三处:①visited集合②is_visited()方法③generate()中调用判重方法的地方。
没有了判重,为了提高代码效率,可以考虑让“0”不能往回移动,这需要对generate()整体进行修改。因为输出的路径不会过长了,可以取消输出路径的那一行代码的注释,防止等待过程太无聊。
以下是修改后的generate()函数:
def generate(node: Node):
# 首先确定零在当前状态的位置
location = find_zero(node.value)
# 尝试从四个方向移动
for i in range(len(moves)):
# x,y为移动后0的坐标
x, y = location[0]+moves[i][0], location[1]+moves[i][1]
if MIN <= x < MAX and MIN <= y < MAX and (node.path == "" or dic[moves[(i+2)%4]] != node.path[-1]):
# 如果移动成功,就创建一个子节点
node.children.append(Node(node.value,node,node.path))
# 移动0的位置
node.children[-1].value[location[0]][location[1]] = node.children[-1].value[x][y]
node.children[-1].value[x][y] = 0
# 添加该子节点的路径
node.children[-1].path += dic[moves[i]]
# 更新节点状态,并且规定节点路径长度不得超过25
node.children[-1].update_state()
if len(node.children[-1].path) > 25:
node.children.pop()
continue
# 输出当前路径
print(node.children[-1].path, end = '\n')
# 如果寻找到了正确路径,就返回该路径
if node.children[-1].state == hash_goal:
return node.children[-1].path
# 把该子节点添加到栈顶
stack.append(node.children[-1])
return ''思考:找不同,修改了genearte()方法的哪些地方?改变direction列表中“上”、“右”、“下”、“左”的顺序,程序还能正常运行吗?
6.深度优先搜索的完整代码:
以下是优化后的深度优先搜索代码:
import copy
# 基础数据
moves = [(1,0),(0,1),(-1,0),(0,-1)]
direction = ['上','右','下','左']
# 由两个列表创建字典
dic = dict(zip(moves, direction))
# 操作栈
stack:list = []
#数组的边界大小
MAX = 3
MIN = 0
# 节点类
class Node:
value: list[list[int]]
parent: 'Node'
children: list['Node']
path: str
state: int
# 创建子节点时需要定义子节点的数据、父节点、节点路径
def __init__(self, value, parent=None, path = ""):
self.value = copy.deepcopy(value)
self.parent = parent
self.children = []
self.path = copy.deepcopy(path)
def update_state(self):
self.state = my_hash(self.value)
# 树类
class Tree:
root: Node
def __init__(self, root):
self.root = root
def my_hash(matrix: list[list[int]]):
state = 0
for i in range(len(matrix)):
for j in range(len(matrix[i])):
state += matrix[i][j]
state *= 10
state /= 10
return state
# 寻找0的坐标
def find_zero(matrix: list[list[int]]):
for i in range(len(matrix)):
for j in range(len(matrix[i])):
if matrix[i][j] == 0:
return i,j
def generate(node: Node):
# 首先确定零在当前状态的位置
location = find_zero(node.value)
# 尝试从四个方向移动
for i in range(len(moves)):
# x,y为移动后0的坐标
x, y = location[0]+moves[i][0], location[1]+moves[i][1]
if MIN <= x < MAX and MIN <= y < MAX and (node.path == "" or dic[moves[(i+2)%4]] != node.path[-1]):
# 如果移动成功,就创建一个子节点
node.children.append(Node(node.value,node,node.path))
# 移动0的位置
node.children[-1].value[location[0]][location[1]] = node.children[-1].value[x][y]
node.children[-1].value[x][y] = 0
# 添加该子节点的路径
node.children[-1].path += dic[moves[i]]
# 更新节点状态,并且规定节点路径长度不得超过25
node.children[-1].update_state()
if len(node.children[-1].path) > 25:
node.children.pop()
continue
# 输出当前路径
print(node.children[-1].path, end = '\n')
# 如果寻找到了正确路径,就返回该路径
if node.children[-1].state == hash_goal:
return node.children[-1].path
# 把该子节点添加到栈顶
stack.append(node.children[-1])
return ''
initial = [
[2,7,8],
[1,0,3],
[6,4,5]
]
goal = [
[0,1,2],
[5,4,3],
[6,7,8]
]
hash_goal = my_hash(goal)
tree = Tree(Node(initial))
stack.insert(0, tree.root)
while True:
path = generate(stack.pop())
if path != '':
print("找到路径,该路径长度为", len(path),":")
print(path)
break运行结果(需要耐心等待):

三、A*算法
1.A*算法简介:
A*算法的基本思路和广度优先搜索很相似,以下是几个不一样的地方:
①OpenList:相当于原来的queue队列,不过该队列是一个优先队列,会根据一定的规则对其储存的节点进行排序。
②CloseList:相当于原来的visited集合,已访问过的节点状态会被放入CloseList中,防止重复访问相同的状态造成运行效率下降。
③f(n)=g(n)+h(n):
•f(n)是从初始状态经由状态n到目标状态的代价估计,叫作估价函数
•g(n)是从初始状态到状态n的实际代价,
•h(n)是从状态n到目标状态的最佳路径的估计代价。
其中f(n)即为OpenList进行排序依据的数值。
g(n)也叫代价函数,是从初始状态到当前状态n的步数,可以直接用path的长度代替;h(n)也叫启发函数,是从当前状态n到目标状态的估计步数,估计方法有很多,需要我们进行设计。
启发函数h(n)是A*算法的核心,针对不同的需求,我们可以设计出不同的h(n)方法,不同的h(n)方法的效率也是不同的。我们以比较简单的不在位数为例。“不在位数”,即两个同构对象goal和initial在相同索引位置元素不一样的量化指标,文章最开头的两个二维数组的初始不在位数就是2,示例代码中二维数组的初始不在位数是8。
2.A*算法实现与简单优化:
首先在广度优先搜索代码的基础上对变量名进行修改(修改方法见“深度优先搜索”),把visited改为close_list,把queue改为open_list。
在node类中添加启发值属性与计算启发值的函数,并在构造函数中调用计算启发值的函数,以下是修改后的Node类:
class Node:
value: list[list[int]]
parent: 'Node'
children: list['Node']
path: str
state: int
# 启发值
heuristic_num: int
# 创建子节点时需要定义子节点的数据、父节点、节点路径
def __init__(self, value, parent=None, path = ""):
self.value = copy.deepcopy(value)
self.parent = parent
self.children = []
self.path = copy.deepcopy(path)
self.heuristic() # 调用启发值计算函数
def update_state(self):
self.state = my_hash(self.value)
# 启发值的计算
def heuristic(self):
self.heuristic_num = 0
for i in range(MAX):
for j in range(MAX):
if self.value[i][j] != goal[i][j]:
self.heuristic_num += 1在代码末尾处的while循环的最后添加代码,依据启发值和代价值(也就是path的长度)对队列进行排序:
# 对队列中每个元素代价值与启发值的和进行降序排序
open_list.sort(key=lambda node: node.heuristic_num + len(node.path), reverse=True)可以尝试输出了:

发现搜索速度并不没有比广度优先搜索快多少。此时我们可以通过改变启发函数的权重来加快搜索,缺点是不一定能找到最短路径。对排序算法进行以下修改:
# 对队列中每个元素代价值与启发值的和进行降序排序(改变启发值的权重)
open_list.sort(key=lambda node: 5 * node.heuristic_num + len(node.path), reverse=True)搜索速度明显加快,但是路径变长了:

思考:如果增大代价函数的权重,并使其趋近于无穷,会发生什么?如果启发函数的权重趋近无穷大,会发生什么?
回答:对于f(n)=g(n)+h(n),其中f(n)是估价函数,g(n)是代价函数,h(n)是启发函数,则有:
①f(n)=g(n):广度优先搜索,搜索更全面但是速度慢
②f(n)=h(n):全局最优搜索,每次搜索都会去找最可能最先到终点的路径。
③f(n)=1/g(n):深度优先搜索
可以试着改变估价函数f(n)从而实现不同的算法。
3.A*算法的完整代码
import copy
# 基础数据
moves = [(1,0),(0,1),(-1,0),(0,-1)]
direction = ['下','右','上','左']
# 由两个列表创建字典
dic = dict(zip(moves, direction))
# 集合(防止重复搜索,提高效率)
close_list = set()
# 操作队列
open_list:list = []
#数组边界的大小
MAX = 3
MIN = 0
# 节点类
class Node:
value: list[list[int]]
parent: 'Node'
children: list['Node']
path: str
state: int
heuristic_num: int
# 创建子节点时需要定义子节点的数据、父节点、节点路径
def __init__(self, value, parent=None, path = ""):
self.value = copy.deepcopy(value)
self.parent = parent
self.children = []
self.path = copy.deepcopy(path)
self.heuristic()
def update_state(self):
self.state = my_hash(self.value)
# 启发值的计算
def heuristic(self):
self.heuristic_num = 0
for i in range(MAX):
for j in range(MAX):
if self.value[i][j] != goal[i][j]:
self.heuristic_num += 1
# 树类
class Tree:
root: Node
def __init__(self, root):
self.root = root
# 哈希函数
def my_hash(matrix: list[list[int]]):
state = 0
for i in range(len(matrix)):
for j in range(len(matrix[i])):
state += matrix[i][j]
state *= 10
state /= 10
return state
# 寻找0的坐标
def find_zero(matrix: list[list[int]]):
for i in range(len(matrix)):
for j in range(len(matrix[i])):
if matrix[i][j] == 0:
return i,j
# 判断该状态是否存在过
def is_close_list(state: int):
if state in close_list:
return True
else:
close_list.add(state)
return False
def generate(node: Node):
# 首先确定零在当前状态的位置
location = find_zero(node.value)
# 尝试从四个方向移动
for move in moves:
# x,y为移动后0的坐标
x, y = location[0]+move[0], location[1]+move[1]
if MIN <= x < MAX and MIN <= y < MAX:
# 如果移动成功,就创建一个子节点
node.children.append(Node(node.value,node,node.path))
# 移动0的位置
node.children[-1].value[location[0]][location[1]] = node.children[-1].value[x][y]
node.children[-1].value[x][y] = 0
# 添加该子节点的路径
node.children[-1].path += dic[move]
# 输出当前路径
print(node.children[-1].path, end = '\n')
# 更新节点状态并判重
node.children[-1].update_state()
if is_close_list(node.children[-1].state):
node.children.pop()
continue
# 如果寻找到了正确路径,就返回该路径
if node.children[-1].state == hash_goal:
return node.children[-1].path
# 把该子节点添加到队列
open_list.insert(0, node.children[-1])
return ''
initial = [
[2,7,8],
[1,0,3],
[6,4,5]
]
goal = [
[0,1,2],
[5,4,3],
[6,7,8]
]
hash_goal = my_hash(goal)
tree = Tree(Node(initial))
open_list.insert(0, tree.root)
while True:
path = generate(open_list.pop())
if path != '':
print("找到路径,该路径长度为", len(path),":")
print(path)
break
# 对队列中每个元素代价值与启发值的和进行降序排序
open_list.sort(key=lambda node: node.heuristic_num + len(node.path), reverse=True)四、细节补充
1.如何判断初始状态与目标状态不兼容
如果你玩过数字华容道,那么你应该知道数字数字华容道有“Z形”和“S形”两种解,同一局游戏中只会达成两种解的一个,这两种解在游戏规则的约束下不可相互转化,即不兼容。八数码问题中的初始状态和目标状态也可能不兼容,无论你如何移动,都不可能从初始状态转化为目标状态。
什么因素造成了这种情况呢?和逆序数有关。对于一个九位数列,我们规定以下规则:
①交换0与其索引相邻的数字
②交换0与其索引相差3的数字
逆序数指数列中次序相反的有序对的个数。容易证明:规则①和规则②都会改变逆序数的奇偶。可以发现,如果把这九个数从左到右从上到下排成九宫格,八数码问题的规则恰是以上两种规则的特殊情况(虽然在列表中3号位的数字和4号位的数字相邻,但是在八数码问题中两个位置不能相互移动),因此在八数码问题的九宫格中,每次移动0,都会改变逆序数的奇偶。
假设有两个不同的三阶矩阵A和B,0的位置相同,但是逆序数的奇偶不同。如果要把A转化为B,不论如何移动0,总是要把0移动回原来的位置,那么移动次数一定是偶数,这样就不会改变逆序数的奇偶,但是两个矩阵的逆序数奇偶是不同的,所以无论如何也不能把A变为B。
通过计算逆序数,我们判断初始状态到目标状态是否有解,下面是Python代码实现:
# 计算0的位置相同时的逆序数的奇偶,逆序数是奇数返回1,是偶数返回0
def calculate_inverse(matrix: list[list[int]]):
location = find_zero(matrix)
# 把0逐步移动到第一个位置,计算逆序数的改变次数
n = 3 * location[0] + location[1] + 1
for i in range(MAX*MAX):
for j in range(i+1, MAX*MAX):
if matrix[i//MAX][i%MAX] > matrix[j//MAX][j%MAX]:
n += 1
return n % 2
# 判断是否有解
if calculate_inverse(initial) != calculate_inverse(goal):
while True:
print("该问题无解,请按Ctrl+C退出")
2.A*算法与A算法的区别:
概括A*算法和A算法的联系与区别:
①A*算法是一类特殊的A算法
②A算法可以不唯一,A*算法也可以不唯一
③A算法不一定能找到最短路径,A*算法一定能找到最短路径
下面一段划重点:
记一个A算法的启发函数为h(n),重复一下h(n)的定义:从n状态到目标状态最佳路径的估计代价。现在定义h*(n):从n状态到目标状态最佳路径的实际代价(也就是通过暴力搜索求解出来的最短路径)。如果h(n)≤h*(n)恒成立(A*算法更严格的证明是具有单调性,然后推出可采纳性),那么这个A算法就是一个A*算法。
当h(n)=0时,0≤h*(n)恒成立,此时算法退化为广度优先搜索,所以可以认为广度优先搜索是特殊的A*算法,因此广度优先搜索继承了A*算法的所有特性,比如:广度优先搜索一定能找到最短路径。
A*算法有以下特性:
可采纳性(关键):
当一个搜索算法在最短路径存在时能在有限步内保证找到它,就称它是可采纳的。
单调性(本质):
如果某一启发函数满足:
① 对所有状态 ni 和 nj,其中nj是ni的后裔,满足h(ni)-h(nj)≤cost(ni,nj),其中 cost(ni,nj)是从ni到nj的实际代价。
②目的状态的启发函数值为0或h(goal)=0。
则称该启发函数h(n)是单调的。信息性:
如果两个启发函数满足h1(n)<h2(n),就说h2(n)比h1(n)具备更多的信息。
如果h1和h2都能构成A*算法,即都具备可采纳性,那么h2就能在保证搜索到最短路径的前提下拥有更高的搜索效率。
我们把“不在位数”这个启发函数作为例子解释上述特性。这里就不严格证明不在位数具有单调性了,只简单说明它的h(n)≤h*(n),举一个极端的例子。
现在有以下状态:
1 |
2 |
3 |
6 |
5 |
4 |
7 |
8 |
0 |
0 |
1 |
2 |
5 |
4 |
3 |
6 |
7 |
8 |
单调性:如果不统计0的不在位,那么状态n的不在位数和到达目标状态goal最短路径都是8,即h(n)=h*(n)。通过不完全归纳,任何过程状态n的h(n)都不大于h*(n),即该算法具有单调性(不严谨),该A算法是一个A*算法。
可采纳性:定义新的启发函数h'(n)=1.01h(n)(等效于更改h(n)的权重,见A*算法优化那一节),因为存在h(n)=h*(n),那么就有存在1.01h(n)>h*(n),此时就不能确保你找到最短路径。即使h(n)具有可采纳性,新的启发函数h'(n)=1.01h(n)也不具备可采纳性。
信息性:定义一个新的启发函数h''(n)=0.5h(n),显然h''(n)<h*(n),具备可采纳性,但是使用h''(n)作为启发函数进行查找的效率是极低的。
简而言之:如果一个启发函数具有单调性,那么它对应的A算法一定是A*算法,也就一定具有可采纳性。
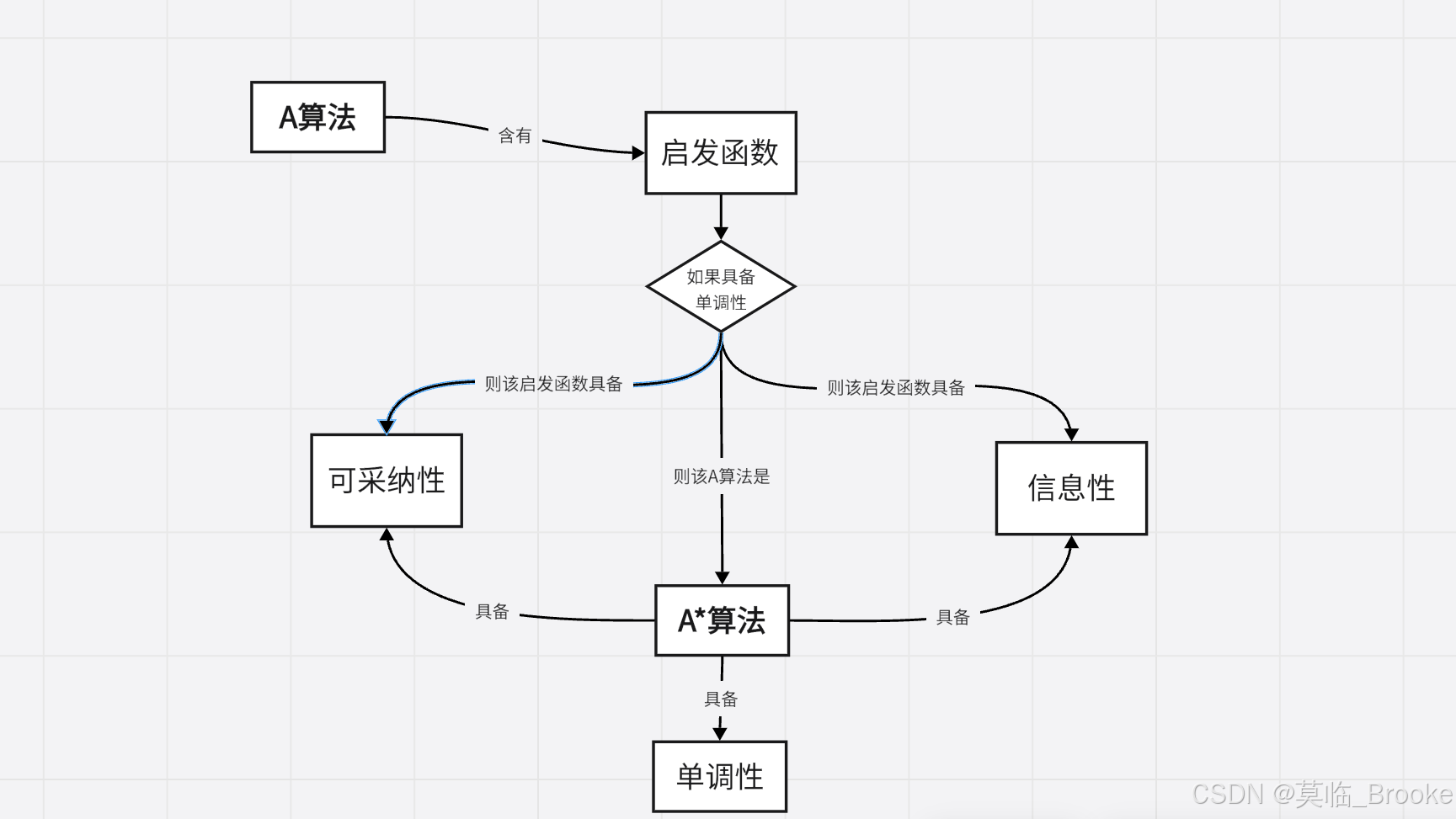
3.数据结构:树
对于以下初始状态进行搜索:
1 |
4 |
3 |
7 |
6 |
|
5 |
8 |
2 |
第一步:将空格向“上下左右”四个方向移动
第二步:若第一步向“上”移动,那么第二步可以向“左右”移动(不回头);若第一步向“下”移动,那么第二步可以向“左右”移动……
第三步:……
……
以上步骤可以用下面这个树状图表示:
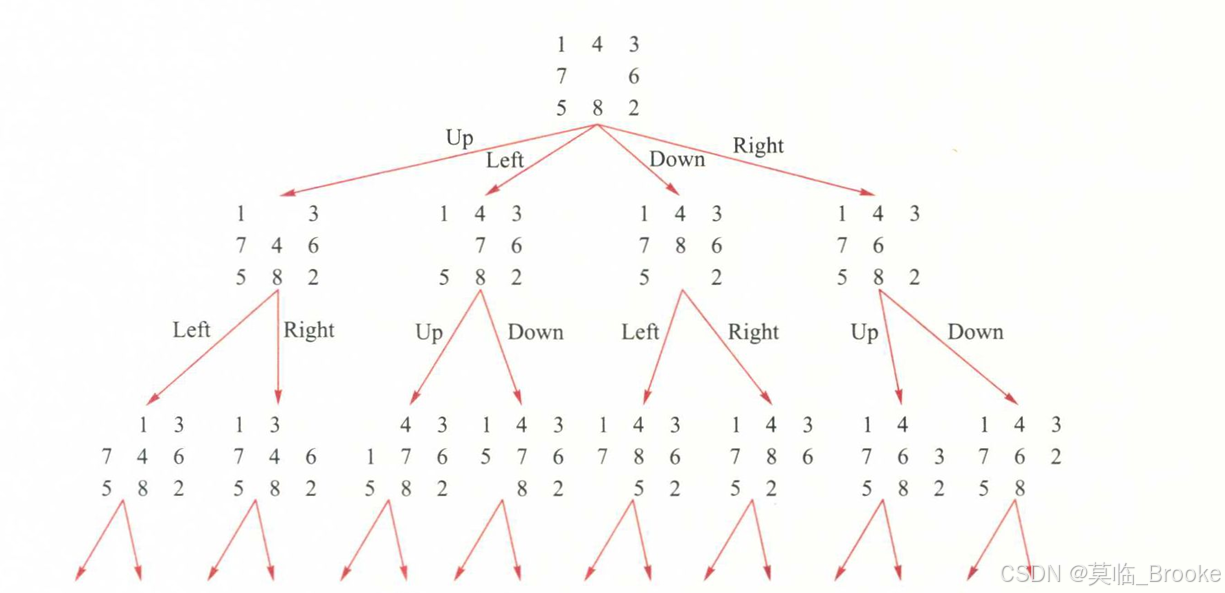
这就是搜索树。下面是一个最基本的树的实现:
# 节点类
class Node:
value: list[list[int]]
parent: 'Node'
children: list['Node']
# 创建子节点时需要定义子节点、父节点
def __init__(self, value, parent=None):
self.value = copy.deepcopy(value)
self.parent = parent
self.children = []
# 树类
class Tree:
root: Node
def __init__(self, root):
self.root = rootNode:
value:本节点数据
parent:父节点引用
children:子节点引用的列表
__init__():构造方法
Tree:
root:根节点的引用
__init__():构造方法
很明显,这个搜索树是无限大的,在无穷多个节点中,有无穷多个符合目标状态的节点。我们需要按照一定的次序遍历这个树,快速找到符合条件的路径较短的节点。
遍历这个树的方法就是上文提到的BNF、DNF和A*。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)