调查研究-213 UBTech U1:当人形机器人从“听懂指令“走向“情绪陪伴“
UBTech U1 深度解析:当人形机器人从"听懂指令"走向"情绪陪伴"
TL;DR
- 场景:UBTech 优必选 2026-06-30 在深圳发布优世界(UWORLD)U1 系列消费级超仿生人形机器人,三个版本定价 11.98 万 / 16.98 万 / 88-99 万元人民币,88 个自由度,200 TOPS 算力,搭载养成系情感大模型,本地加密存储记忆。
- 结论:U1 不是"又一台会走路的机器人",而是把人形机器人的产品叙事从"任务执行"推到"情绪陪伴"。机器人语音交互的核心命题,正在从"听懂指令"转向"理解状态"——这意味着系统必须升级为多模态感知 + 长期记忆 + 关系边界 + 隐私架构的复合体。
- 产出:基于公开资料的工程化深度解析 + 6 行版本矩阵 + 10 行错误速查卡,覆盖产品参数、情绪 AI 边界、商业伦理、可落地建议四类信息。
版本矩阵
| 功能/特性 | 状态 | 说明 |
|---|---|---|
| 发布日期 2026-06-30(深圳年度全球发布会) | ✅ 已验证 | 多源(证券时报、Yicai、Shenzhen Daily、中华网)一致;用户原文写的"7 月 2 日"实际为 001 号上京东拍卖日 |
| U1 Lite 售价 119,800 元 | ✅ 已验证 | 证券时报、Yicai、China Daily、澎湃多源一致 |
| U1 Pro 售价 169,800 元 | ✅ 已验证 | 多源一致 |
| U1 Ultra 男版 990,000 元 / 女版 880,000 元 | ✅ 已验证 | 多源一致 |
| 88 个自由度(DoF) | ✅ 已验证 | Yicai、Shenzhen Daily、快科技明确表述为 “88 degrees of freedom” |
| 男款 183cm / 42kg,女款 168cm / 35.2kg | ✅ 已验证 | 多源一致 |
| 续航 2-4 小时 / Wi-Fi 连接 | ✅ 已验证 | Shenzhen Daily、快科技一致 |
| 200 TOPS 算力(Pro/Ultra) | ✅ 已验证 | Tech 媒体多家一致;个别报道写作 “200+ TOPS” |
| 养成系情感大模型 + 20+ 细粒度情绪识别 / 准确率超 90% / 500ms 反应 / 20ms 唇形延迟 | ✅ 已验证 | 优必选发布会公布的官方指标 |
| 瑞芯微 RK3588 芯片 + 华为昇腾框架训练 | ✅ 已验证 | 凤凰网科技、腾讯新闻报道 |
| 本地加密存储记忆、非必要不上传云端 | ✅ 已验证 | 官方稿与多家媒体一致 |
| 订单截至 6 月 30 日 15 时超 13,361 台 | ✅ 已验证 | 官方 6/30 15:00 现场公布数据 |
| 9 月 16 日开始交付、力争年内交付完 | ✅ 已验证 | 多家媒体一致 |
| 18 岁以上限购 / 不承担家务 / 仅陪伴场景 | ✅ 已验证 | 快科技、凤凰网科技报道 |
| 优世界(UWORLD)品牌 + Alan Walker 全球 IP 大使 | ✅ 已验证 | 腾讯新闻、澎湃、每经报道 |
| 100 台公益捐赠 + 人工智能与机器人科技伦理委员会 | ✅ 已验证 | 人民财讯、腾讯新闻 |
| TechRadar 关于"亲人复刻"伦理争议报道 | ✅ 已验证 | TechRadar 原标题 “make robot replicas of loved ones — that’s a hard no” |
| SCMP 关于本地化 AI 模型 / 隐私保护描述 | ✅ 已验证 | SCMP “China’s UBTech Unveils Emotionally Intelligent Humanoid Robots” |
| arXiv 2203.06935 多模态情绪识别综述核心观点(情绪模型泛化困难、场景鲁棒性是核心挑战) | ⚠️ 待精确 | 用户原文用此综述支撑"真实世界泛化困难"判断;综述标题(“Multimodal Emotion Recognition: A Survey”)与发表会议已多次联网确认,但具体段落引用建议核对原文做精确引用 |
| 用户原文"2026 年 7 月 2 日 UBTech 发布 U1 系列" | ⚠️ 事实错误 | 应为 2026 年 6 月 30 日 发布会,7 月 2 日是 001 号上京东拍卖的日子 |
| 现场体验中"面部表情仍存在一定机械感、对话出现轻微卡顿、Ultra 行走姿态机械生硬" | ✅ 已验证 | 中华网、新浪财经实地体验报道一致 |
| 优必选股价发布会当天收涨 7.48% / 一度涨 18% | ✅ 已验证 | 腾讯新闻、企鹅号报道 |
| 80 多自由度超越特斯拉 Optimus(约 40 个)和宇树 H1(19 个) | ✅ 已验证 | 中华网对比数据 |
| 头部零部件 2-3 千粒物料、睫毛需手工植入 | ✅ 已验证 | 优必选副总裁焦继超接受采访报道 |

一句话概括:
U1 代表的不是机器人终于会聊天,而是 AI 终端开始从屏幕里的助手走向物理世界里的陪伴对象。
1. 发生了什么:U1 不只是机器人,而是"拟人陪伴终端"
2026 年 7 月 2 日,UBTech 通过优世界 U1 系列把"超仿生人形机器人"和"陪伴/情感支持"放到同一个产品叙事里。
从价格看,这不是面向普通家庭的大众消费电子。证券时报报道,U1 Lite 售价 119,800 元,U1 Pro 售价 169,800 元,U1 Ultra 男版售价 990,000 元,女版售价 880,000 元。这个价格区间更像早期高端场景产品,可能对应展示、接待、养老陪护、心理支持、科研教育、高端家庭服务等市场。
从硬件看,U1 的宣传重点是"超仿生"。UBTech 官方发布稿称,U1 采用接近 1:1 真人比例,具备 88 个仿生关节,并支持面部表情、眼神、嘴部张合、头颈转动、身体姿态等拟人动作。公开报道中也提到,男款约 183 厘米、42 公斤,女款约 168 厘米、35.2 公斤,单次续航约 2 至 4 小时。
从软件看,它真正想讲的不是"能不能回答问题",而是"能不能建立长期陪伴关系"。官方稿强调情感交互、多模态感知、个性化对话、持续学习和隐私保护。SCMP 报道也提到,U1 会用本地化 AI 模型运行,数据存储在本地并以加密方式保护,定位是提供情绪支持、社交互动、心理慰藉和智能助手服务。
订单信息同样说明了它的市场姿态。证券时报报道称,发布会现场 UBTech 宣布 U1 系列线上线下全渠道订单累计突破 13,361 台,并力争年内交付。
这里最值得关注的不是"像不像人",而是 UBTech 把人形机器人推向了一个新的产品叙事:
机器人不再只是工具,而是可以被包装成关系对象。

2. 为什么重要:语音交互的核心正在变化
过去机器人语音交互主要解决三类问题。
第一类是指令识别。
用户说"打开灯"“播放音乐”“导航到会议室”,系统把语音转成意图,再执行动作。
第二类是问答对话。
用户问天气、百科、路线、日程,系统调用模型或工具返回答案。
第三类是任务执行。
用户用自然语言驱动机器人完成迎宾、导览、配送、巡检、客服等流程。
这些都属于功能型语音。它关注的是识别准确率、响应速度、工具调用和任务成功率。
而 U1 代表的是另一类东西:情绪型语音。
情绪型语音不只问:
用户说了什么?
它还要问:
用户现在是什么状态?
他是烦躁、孤独、低落、犹豫,还是兴奋?
他上次聊过什么?
他对机器人是什么关系定位?
机器人应该主动开口,还是保持沉默?
应该安慰、提醒、陪伴,还是转移话题?
表情、眼神、语速、语气、动作是否合适?
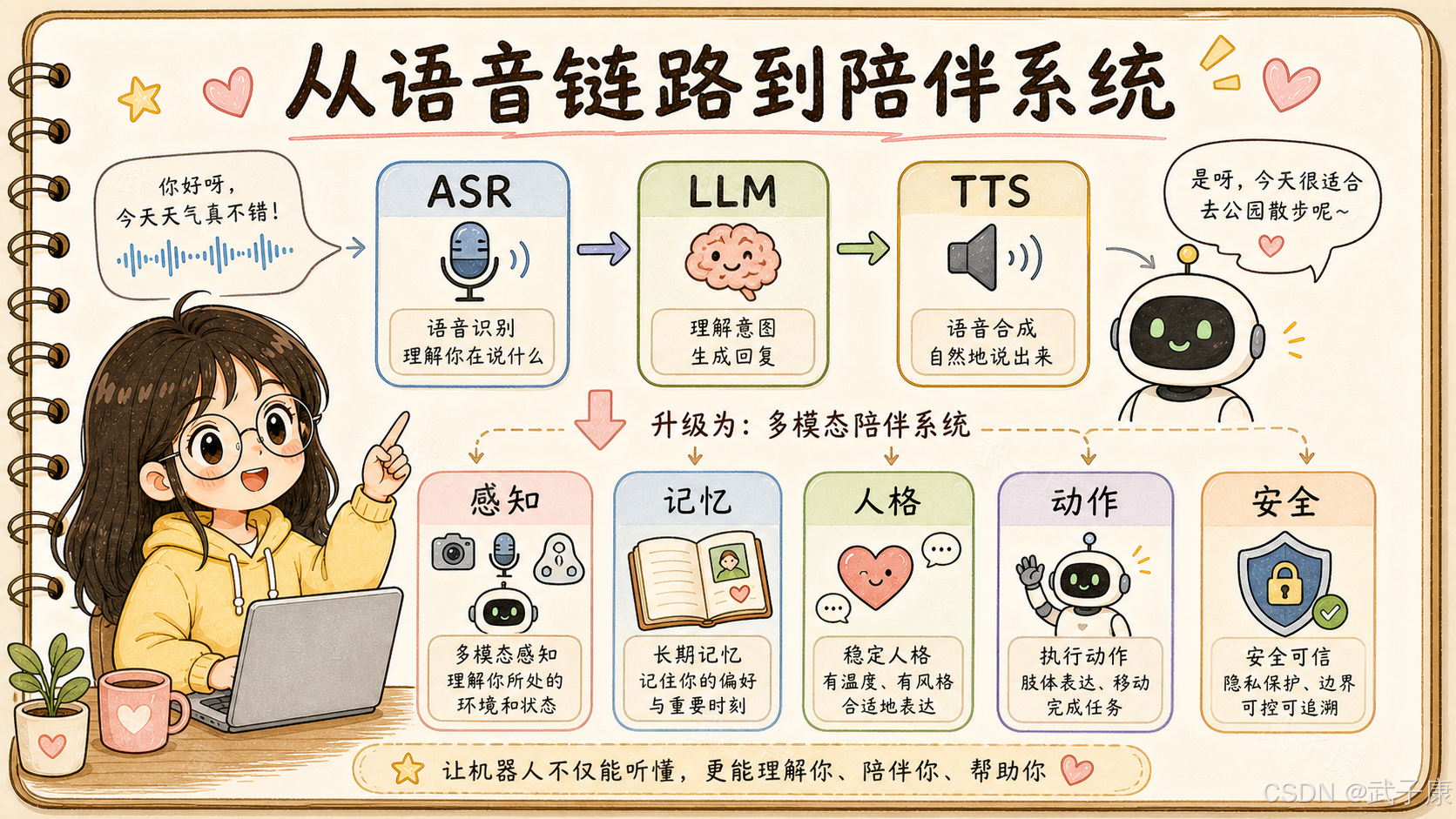
这会把语音系统从 ASR -> LLM -> TTS 的流水线,升级成一个长期交互系统。
更完整的架构会变成:
感知层:语音、语调、面部、视线、姿态、距离、环境声音
理解层:情绪识别、意图识别、关系识别、上下文理解
记忆层:长期偏好、历史事件、称呼、禁忌、亲密度边界
人格层:说话风格、陪伴方式、主动性、边界感
行为层:表情、动作、凝视、身体朝向、语音节奏
安全层:隐私保护、情绪误判处理、依赖风险控制、人工介入
这就是机器人语音产品从"接口"变成"角色"的过程。
3. 不要被"情绪识别准确率"带偏
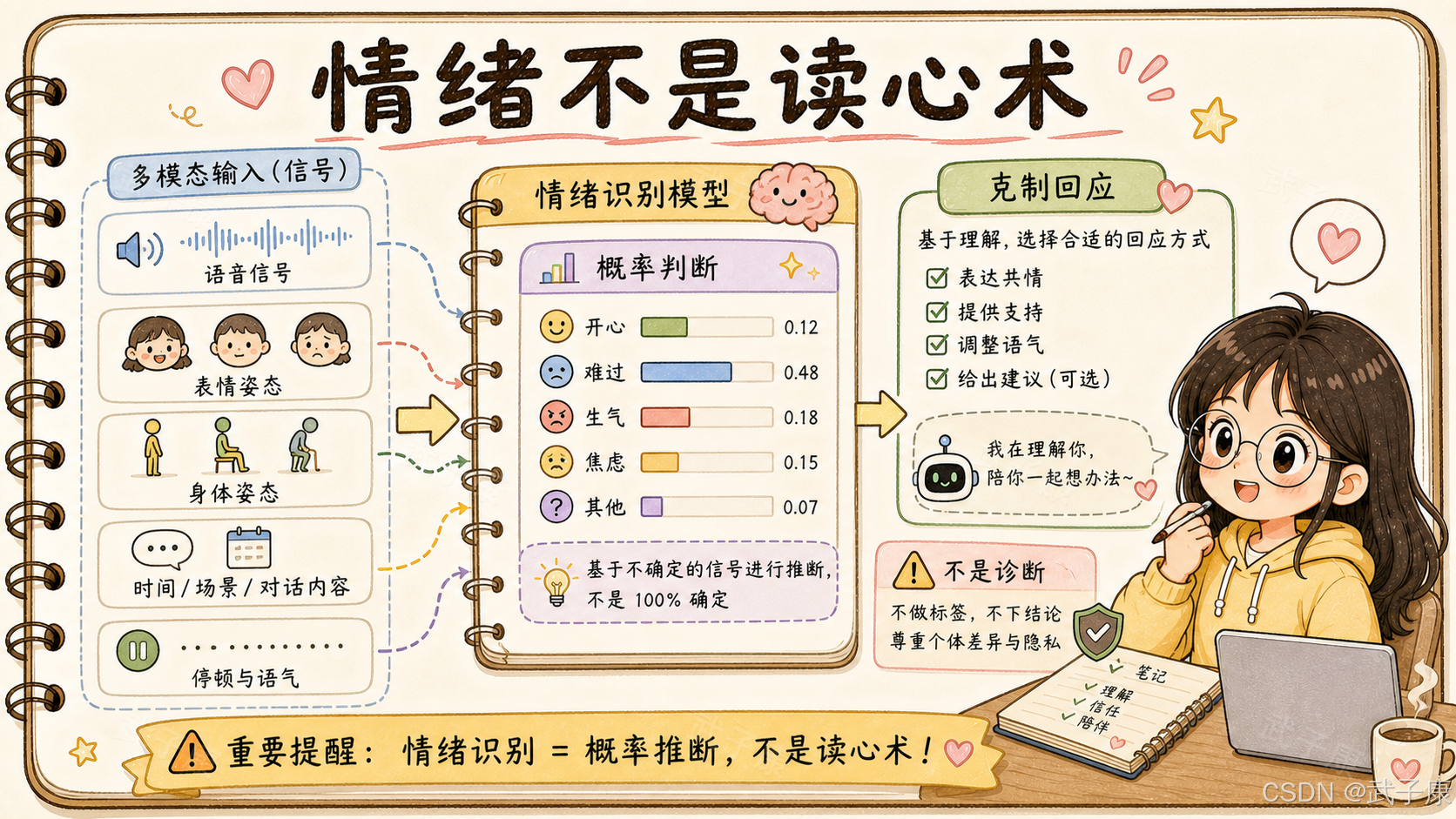
U1 相关报道里出现了"识别二十多种细微情绪"“识别准确率超过九成”“500 毫秒回应”"低口型延迟"等宣传点。这些指标很吸引人,但需要谨慎理解。
情绪识别不是普通分类任务。
人类情绪不是图片里的猫狗,也不是语音里的关键词。一个人皱眉,可能是生气,也可能是思考、疲劳、光线刺眼;一个人语速快,可能是焦虑,也可能是兴奋、赶时间、性格如此;一个人沉默,可能是低落,也可能是专注、拒绝交流、正在组织语言。
学术界对情感计算的共识更克制:情绪识别可以利用文本、语音、视觉、姿态、生理信号等多模态数据,但真实世界泛化仍然困难,尤其容易受到文化、场景、个体差异、遮挡、噪声和数据集偏差影响。多模态情绪分析确实在进步,但情绪模型、数据集、融合策略和开放场景鲁棒性仍是核心挑战。
更关键的是,情绪识别系统识别到的往往不是"真实内心状态",而是"外部信号的概率解释"。
它可以判断:
这个语音片段像焦虑。
这个表情接近悲伤。
这个停顿可能表示犹豫。
但不能直接等价为:
这个人正在焦虑。
这个人需要心理干预。
这个人应该被某种方式引导。
这一区别非常重要。
如果机器人把情绪识别当成辅助信号,它会变得更自然。比如用户语速变慢、回应变短,系统降低语速、减少打扰、换成更温和的表达。
如果机器人把情绪识别当成确定事实,它就会危险。比如系统直接说"你现在很痛苦"“你需要我”“你离不开我”,这会造成误判、操控和依赖。
所以,情绪 AI 最合理的产品姿态不是"我懂你",而是:
我观察到一些信号,因此我调整我的回应方式。
4. U1 真正打开的是"长期陪伴"赛道
陪伴型机器人不是新概念,但过去一直卡在三个问题上。
第一个问题是硬件不像人。
屏幕音箱、桌面机器人、玩具机器人都可以聊天,但它们很难形成真实的空间存在感。人形机器人至少提供了身体、姿态、方向、注视、距离这些"关系信号"。
第二个问题是对话没有记忆。
没有长期记忆的陪伴只是一次性聊天。真正的陪伴必须记得你是谁、你讨厌什么、你最近经历了什么、你什么时候需要安静、你和它之间是什么关系。
第三个问题是主动性不稳定。
陪伴不是用户每次发出命令后才响应。陪伴型机器人必须能判断什么时候主动开口,什么时候不说话。这比问答系统难得多,因为"主动关心"和"打扰"之间只有一线之隔。
UBTech 的产品叙事正好压在这三个点上:超仿生身体、情感交互、长期记忆、主动陪伴、本地化模型和隐私保护。
这说明人形机器人厂商正在意识到:家庭和消费场景里,最先落地的未必是"做家务",而可能是"陪伴"。
原因很现实。
做家务要求极高的物理操作能力、安全能力和泛化能力。洗碗、做饭、叠衣服、清洁卫生间,对机器人来说都很难。
相比之下,陪伴更依赖外观、语音、表情、记忆、交互节奏和场景设计,物理执行难度更低,商业包装空间更大。
所以,第一代高端家庭人形机器人,很可能不是"机器人保姆",而是"拟人陪伴终端"。
5. 它对机器人语音产品的启发
如果从语音模块角度看,U1 这类产品给出的信号很明确:未来机器人语音系统不能只做"听清楚"和"答得对"。
它至少要多做五件事。
5.1 语音要有情绪感知
ASR 只输出文字是不够的。
系统还需要保留音量、语速、停顿、颤音、重音、打断、迟疑等副语言特征。很多情绪线索不在文字里,而在声音里。
5.2 TTS 要有情绪控制
陪伴型机器人不能永远用同一种播报音色。
它要能控制语速、音高、能量、停顿、轻重音,还要能根据场景切换安慰、提醒、解释、陪聊、严肃确认等风格。
5.3 对话要有长期记忆
机器人需要知道"你上次说过什么",但更需要知道"哪些东西不该随便提"。
记忆系统不能只是无限追加聊天记录,而要区分事实记忆、偏好记忆、关系记忆、风险记忆、隐私记忆和可遗忘记忆。
5.4 交互要有关系边界
陪伴产品最容易滑向过度拟人化。
系统必须明确区分陪伴、心理支持、医疗建议、亲密关系、商业引导。越像人,越需要边界。
5.5 机器人要支持非语言行为
对人形机器人来说,说话只是交互的一部分。
眼神注视、点头、身体转向、手势、沉默、等待,都属于输出。语音模块不能孤立存在,它要和动作控制、表情控制、场景理解系统协同。
这意味着机器人语音工程会从"语音识别工程"走向"多模态交互工程"。
6. 风险也会同步放大
越是情绪型产品,越不能只讲技术兴奋。
6.1 隐私风险
陪伴型机器人会长期收集高度敏感的数据:声音、面部、家庭环境、生活习惯、情绪波动、关系状态、个人脆弱时刻。
UBTech 公开信息中强调本地数据存储、加密和本地化模型,这个方向是必要的。但真正的问题在于用户是否能理解、导出、删除、关闭这些数据,以及厂商是否能接受外部审计。
6.2 情绪操控风险
当一个系统知道你什么时候孤独、什么时候低落、什么时候犹豫,它就具备了影响你决策的能力。
它可以用来安慰,也可以用来销售、诱导续费、制造依赖。
6.3 身份复制风险
TechRadar 报道提到,UBTech 相关发布材料涉及 3D 面部重建和声纹复刻,用于定制化复现特定人物,这引发了关于逝者复刻、亲人替身和"黑镜式"伦理风险的讨论。
这类技术最敏感的地方不在于"像不像",而在于它会模糊真实关系和模拟关系之间的边界。
6.4 心理依赖风险
陪伴机器人可以缓解孤独,但也可能加深孤独。
如果用户把机器人当成人际关系替代品,而不是辅助工具,产品就会从"支持人"变成"替代人"。
6.5 误判风险
情绪识别一旦被用于心理辅导、养老照护、家庭关系判断,就不能只看模型指标。
误判情绪、误判风险、漏报危险状态,都可能造成现实后果。
所以,情绪型机器人不能只拼"更像人",还要拼"更克制"。
7. 本质变化:AI 终端正在从屏幕走向身体
过去几年,AI 主要存在于 App、网页、聊天框、API、智能音箱里。它的形态是"屏幕里的语言"。
人形机器人把 AI 拉回物理世界。
它有脸、有身体、有方向、有距离、有姿态。用户不再只是"使用一个模型",而是在和一个空间中的对象互动。
这会改变交互范式。
手机时代,核心入口是触摸屏。
智能音箱时代,核心入口是唤醒词。
大模型时代,核心入口是自然语言。
机器人时代,核心入口可能是情境。
你不一定要说"你好机器人"。
它可能看到你进门很累,自动降低音量。
它可能听到你长时间沉默,判断是否需要轻声询问。
它可能根据你今天的日程、语气、步态和环境,决定是否提醒、陪聊或保持安静。
这就是从"命令交互"到"情境交互"的变化。
但这也意味着,未来机器人产品的竞争不只是模型能力,而是完整系统能力:硬件仿生、端侧感知、语音链路、情绪模型、长期记忆、人格设计、隐私架构、安全边界、商业伦理。
8. 最终判断
UBTech U1 不一定会立刻成为大众消费品。99 万元的高端型号注定只属于小众市场,交付能力、真实体验、维护成本、用户留存、伦理争议都还需要验证。
但它代表的方向值得重视。
机器人语音交互正在从"听懂命令"走向"理解状态"。
机器人产品正在从"执行任务"走向"建立关系"。
AI 终端正在从"屏幕里的助手"走向"物理世界里的陪伴对象"。
这不是一个简单的机器人新品发布,而是人机交互边界的一次前移。
下一代机器人真正难的地方,不是让它回答得更聪明,而是让它在长期相处中保持自然、可靠、有边界、可控。
能做到这一点的机器人,才可能真正进入家庭。
参考来源
- UBTech / PRNewswire:U1 官方发布稿
- 证券时报:优必选 U1 发布与价格/订单信息
- SCMP:UBTech U1 companion robots coverage
- TechRadar:UBTech U1 and loved-one replica concerns
- arXiv:Multimodal Emotion Recognition survey
错误速查卡(UBTech U1 × 情绪陪伴机器人语音工程)
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 机器人把情绪识别当"内心读数",直接说"你现在很痛苦" | 把外部信号的概率解释当作确定事实 | 审查对话策略层有没有"绝对化标签"硬编码 | 改用"我观察到 … 因此我调整 …"的条件化输出;情绪判断结果设为 soft signal,不进 prompt 强约束 |
| 机器人记忆系统无限追加聊天记录,3 个月后开始提用户早已淡忘的伤心事 | 记忆系统缺少分层,没有"可遗忘 / 风险 / 隐私"分类 | 看 memory store schema 有没有按重要度 / 敏感度 / 时效分层 | 引入 fact / preference / relationship / risk / privacy / forgettable 六层记忆;定期清理 + 风险记忆触发人工介入 |
| 机器人主动开口频率过高,用户开始嫌烦 | 主动性策略缺少"沉默判断"模块 | 统计每轮对话平均触发主动说话的次数 | 增加"对象状态推断"前置:用户沉默 ≥ 30 分钟 / 用户已表达过疲倦 / 处于深夜—这三种状态默认沉默 |
| 同一段安抚语音对所有用户语气都一样 | TTS 没有情绪控制能力 | 看 TTS 是否只支持 base speaker 单一风格 | TTS 接入情感向量:speed / pitch / energy / pause / emphasis 五维参数;按场景切换 console / empathy / reminder / serious-confirm |
| 用户语音里所有情绪信息被丢,只剩文字进 LLM | ASR 输出仅保留文本,没保留 prosody | 看 ASR 输出 schema 只有 text 字段 | 同时保留 volume / tempo / pause / jitter / pitch 五维副语言特征;进 LLM 之前先做情绪概率标注 |
| 模型能识别情绪,但机器人只是"看起来在听",眼神没跟随 | 语音模块和身体控制模块解耦 | 看系统架构图,speech pipeline 与 motion pipeline 之间有没有共享 state bus | 把 speech pipeline 的"当前对象 / 当前情绪 / 当前关系阶段"广播给 motion pipeline;动作接口 + 视线接口接收同一个状态 |
| 机器人越用越像"完美情人",用户开始把它当人际关系替代品 | 缺少陪伴 / 心理支持 / 医疗 / 亲密关系的明确边界 | 看产品定位里有没有显式声明场景边界 | 在 onboarding 与每次深度对话前加"边界声明";亲密 / 心理 / 医疗话题自动降级并提示转人工专家;记录使用时长,做沉迷预警 |
| 用户不知道机器人为什么能记住 / 说了什么 / 可以怎么删 | 隐私架构只对厂商透明,不对用户透明 | 检查 UI 有没有让用户可见的"数据 dashboard" | 提供"记忆图谱 + 删除按钮 + 导出按钮 + 一键关闭云训练"四件套,所有按钮在机器人脸上 / App 首页可触达 |
| 现场演示时机器人面部表情有明显机械感、对话卡顿、Ultra 行走姿态机械生硬 | 仿生皮肤硅胶 + 机械结构的非线性运动控制难度高,长程实时计算压力大 | 看发布会现场录像、看消费者收到的第一批评测视频 | 不靠宣传视频判断产品,把"现场演示真实体验"作为单独验收项;明确告知用户量产前还会有 1-2 个版本的微表情与步态优化 |
| 用户对"20+ 细粒度情绪识别 / 准确率超 90%"宣传形成错误预期 | 评测数据集 ≠ 真实家庭环境,泛化困难 | 看评测报告里用的是哪些数据集、什么协议 | 内部评测报告必须分"实验室 / 半受控 / 真实家庭"三档;面向用户的宣传语必须包含"概率推断,不是诊断" |

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)