《从AI通识到LangChain实战:构建你的第一个智能体应用》
前言
LangChain,作为智能体开发领域最具影响力的框架之一,提供了一套完整、灵活的工具链,帮助我们快速构建能够感知环境、自主决策并执行任务的智能系统。无论你是AI初学者,还是希望将LLM集成到实际项目中的开发者,LangChain都值得投入时间学习。
AI通识与基础
认识人工智能
AI 人工智能(Artificial Intelligence),是一门致力于使机器能够模拟人类思维、学习与解决问题的技术。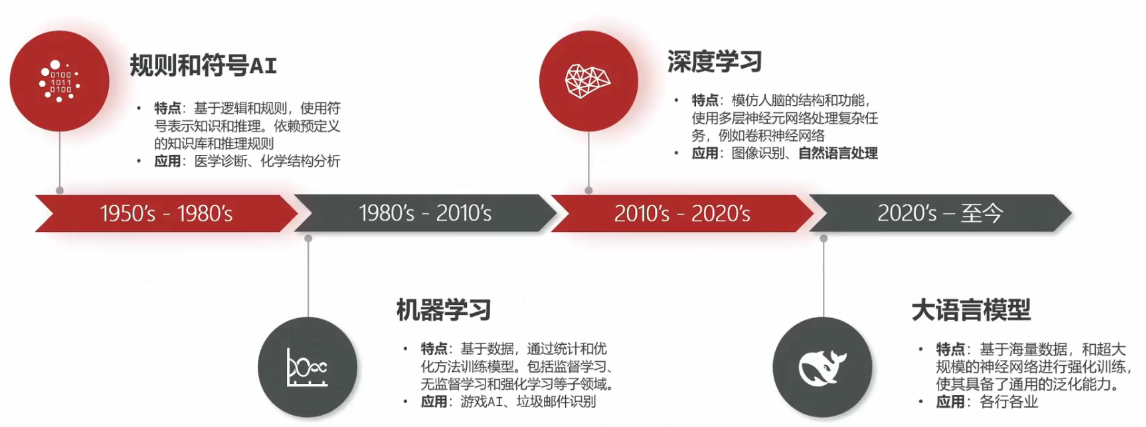
AI产生智能的核心有三点:模型、数据、算力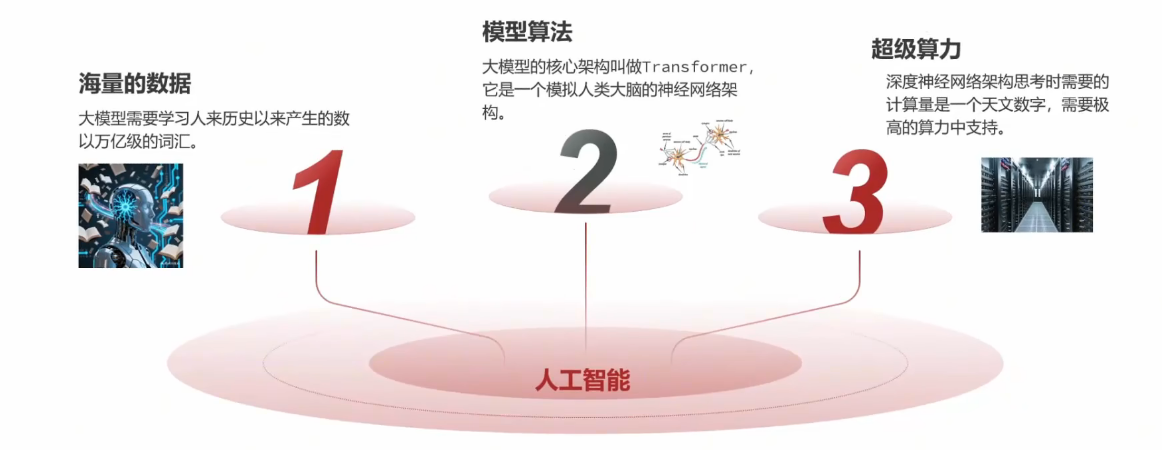
神经网络原理
AI的核心是Transformer,这是一种神经网络架构,本质就是在模拟人类大脑神经元。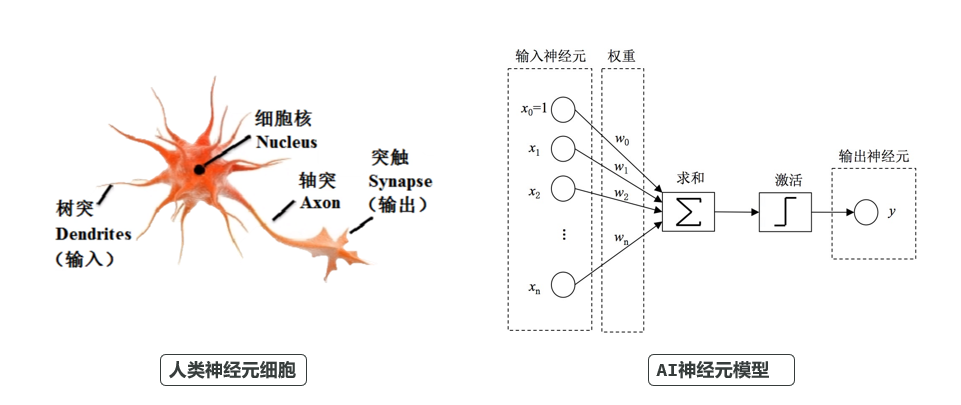
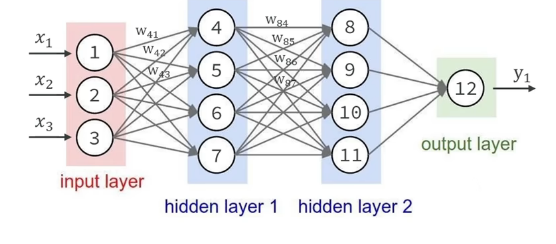
深度神经网络分为很多层(Layer),是神经网络基本的计算单元,分为:
- 输入层(Input Layer):入口,接收数据
- 隐藏层(Hidden Layers):信息处理和学习。可以有很多层。
- 输出层(Output Layer):出口,产生结果
1986年,David Rumelhart(戴维·莱姆哈特)找到了一个教这个复杂神经网络学习的高效方法,叫做反向传播(Backpropagation)
基本流程如下:
- 前向传播:数据逐层加工,直到输出层产出结果
- 计算误差:计算产出结果与正确结果的误差(Loss)
- 反向追责:倒推计算每一层的每个连接对误差的贡献
- 调整权重:根据每个连接的误差贡献比例,调整其权
重参数,使误差变小
大语言模型
在2003年,图灵奖得主约书亚·本吉奥(Yoshua Bengio) 的一篇名为《A neural probabilisticlanguage model》的论文首次提出了词向量(Word Embedding)的概念,为训练神经网络学习自然语言打下了基础。
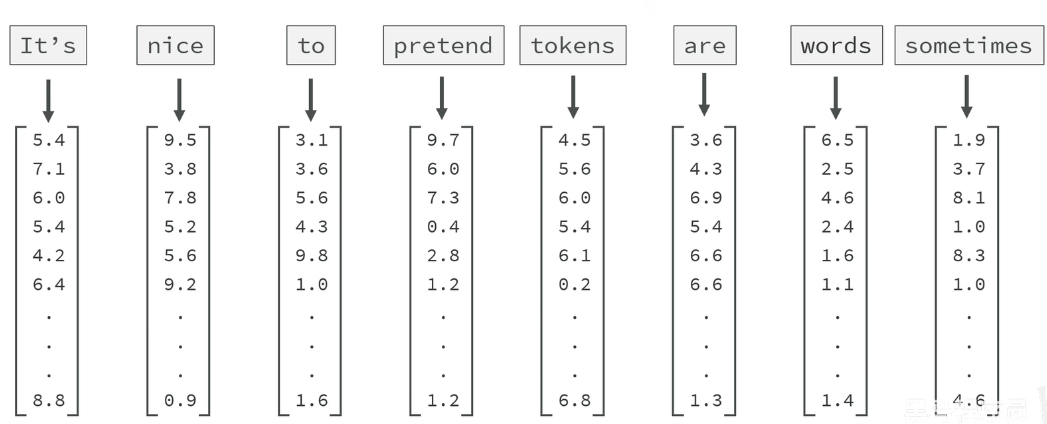
词向量(WordEmbedding)就是把词转为多维空间向量的一种技术。
- 首先,将人类自然语言文字拆分为一个个片段,称为Token(词)
- 每个Token都经过模型计算转为一个浮点数数组,作为向量坐标
- 目标:使词向量在多维空间中的不同方向表达不同的语义
SoftMax会根据模型计算出的向量结果得出下一个token的概率分布,然后基于概率的随机采样方式挑选一个作为结果。
这个概率受模型的Temperature参数影响,值越大,概率分布越均匀,模型生成结果的随机性越强;反之,结果越确定。
Transformer本来是作为翻译用的,但当模型规模和训练数据量增突破某个临界点时,模型像是突然拥有了智能,不仅可以理解人类语言,还能推理、分析。这种现象被称为"诵现”(Emergent Abllities)。这种超大规模的语言模型则被称为大语言模型(Large Language Model)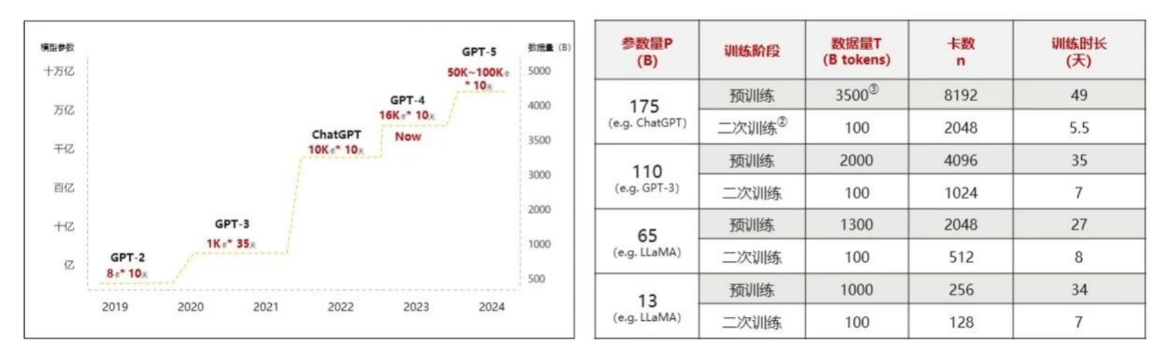
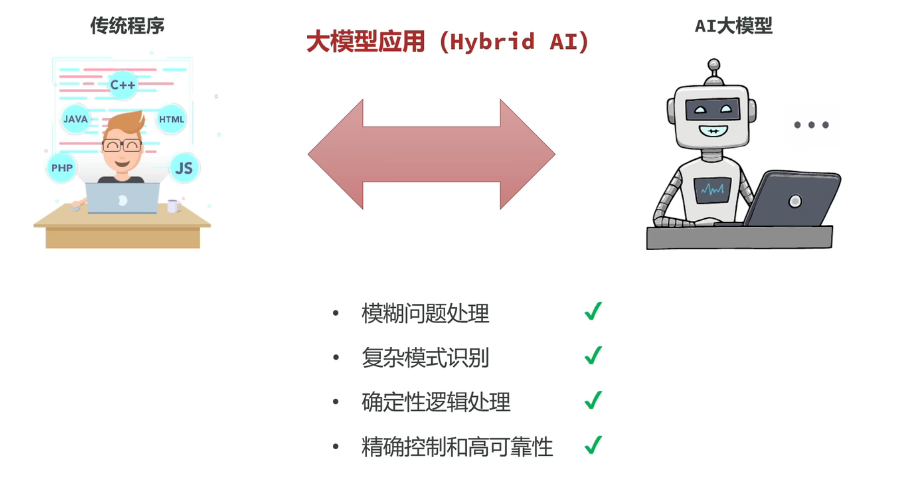
大模型应用

GPT是OpenAI公司研发的一个基于Transformer架构的大语言模型。
大语言模型(LargeLanguage Model,LLM)是指模型的参数规模、训练数据量、训练成本、智能程度都远超普通模
型的一种神经网络模型。
对话机器人(chatBot)是指可以与用户聊天、答疑,而且具有记忆的大模型应用。例如:ChatGpt、通义干问。
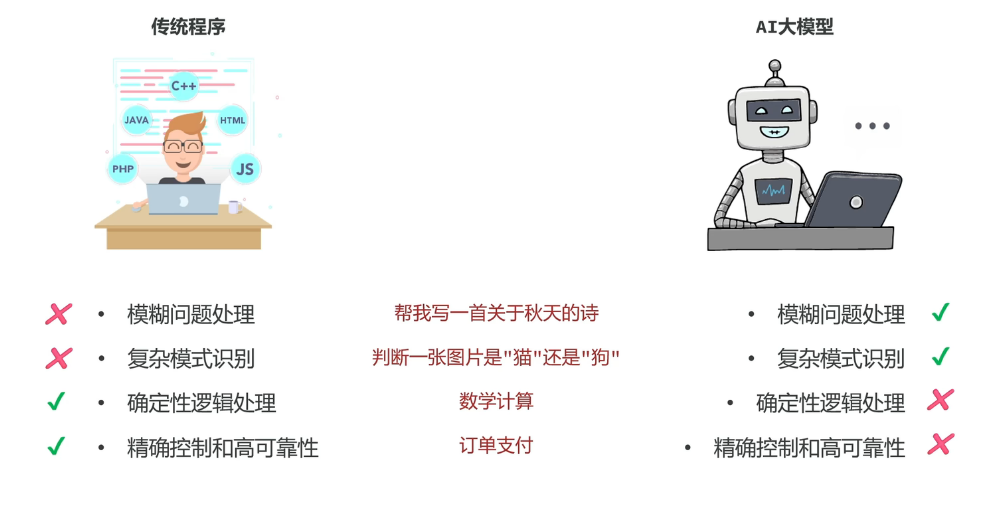
大模型应用是基于大模型的推理、分析、生成能力,结合传统编程精确计算控制能力,开发出的各种应用。
大模型应用通常是由传统web应用作为入口,再由传统应用调用大模型服务提供的基于HTTP协议的API接口,实现用户与大模型的交互。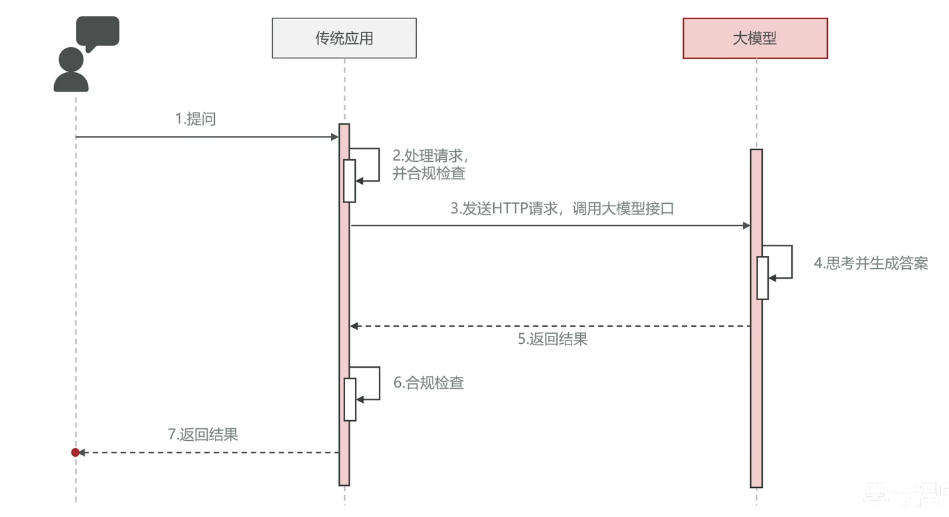
大模型服务
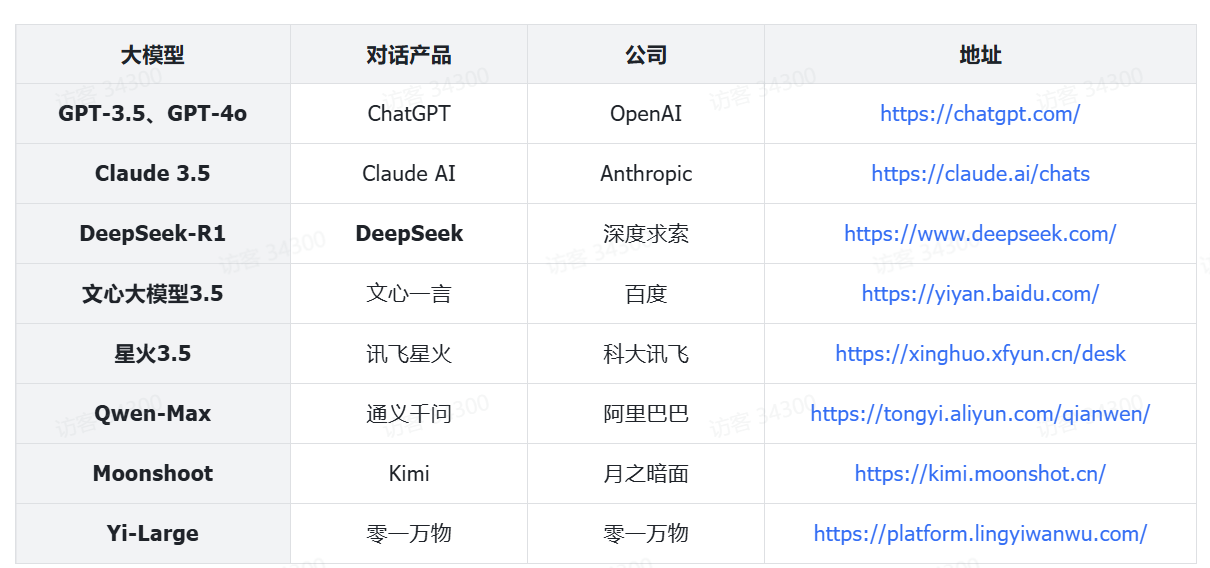
国内知名的云服务平台都提供了国内知名的大模型的API开放服务,只要花钱,无需部署就能访问。
本地部署最简单的一种方案就是使用ollama,官网地址:https://ollama.com
DeepSeek模型服务
官方平台地址:https://api.deepseek.com
点击API Keys选项卡,进入对应页面。第一次进入应该没有API key,可以点击创建API key: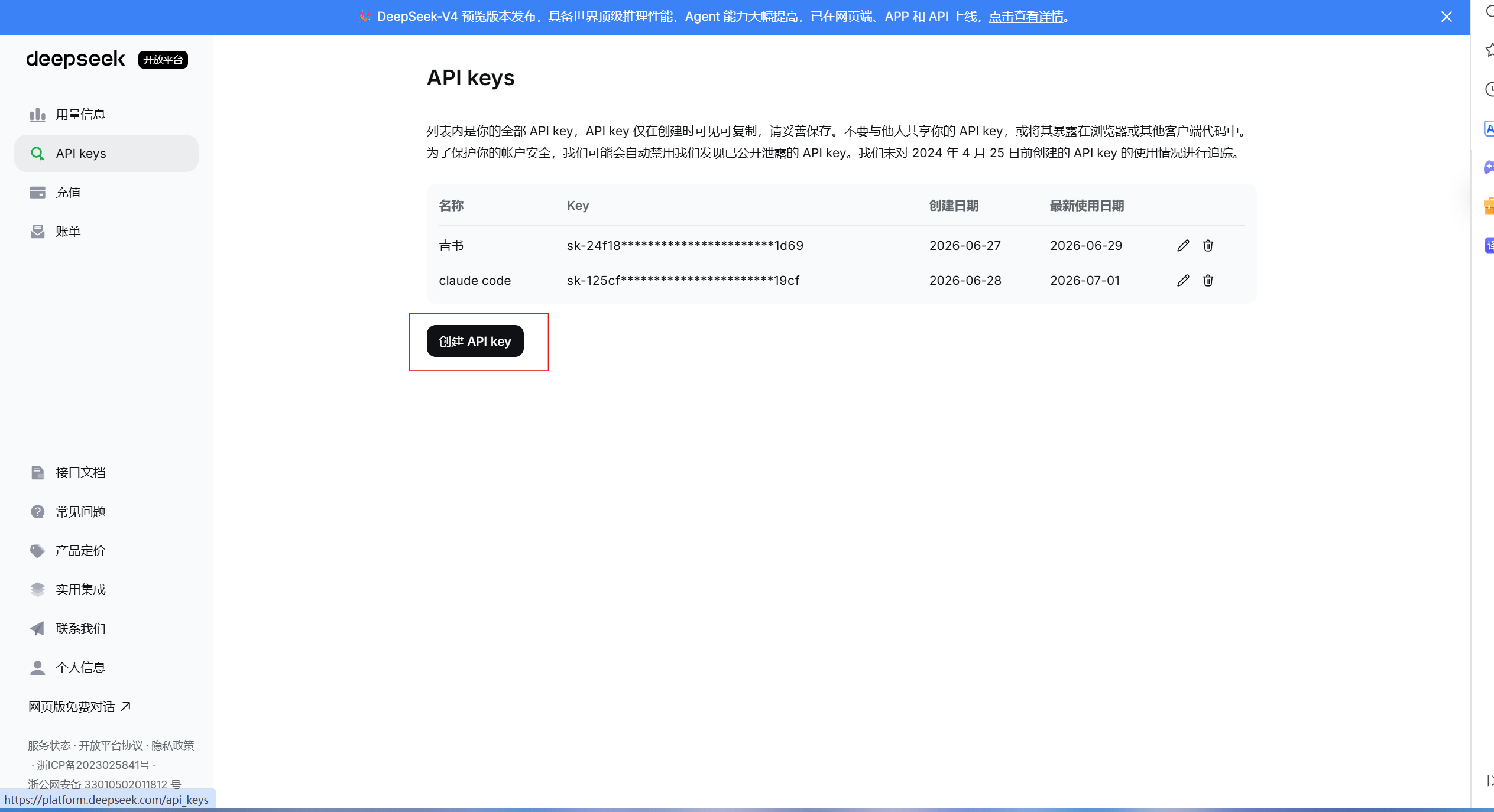
可以通过接口文档来了解如何调用deepseek
注册阿里云百炼
访问百炼平台:https://account.aliyun.com/
申请API key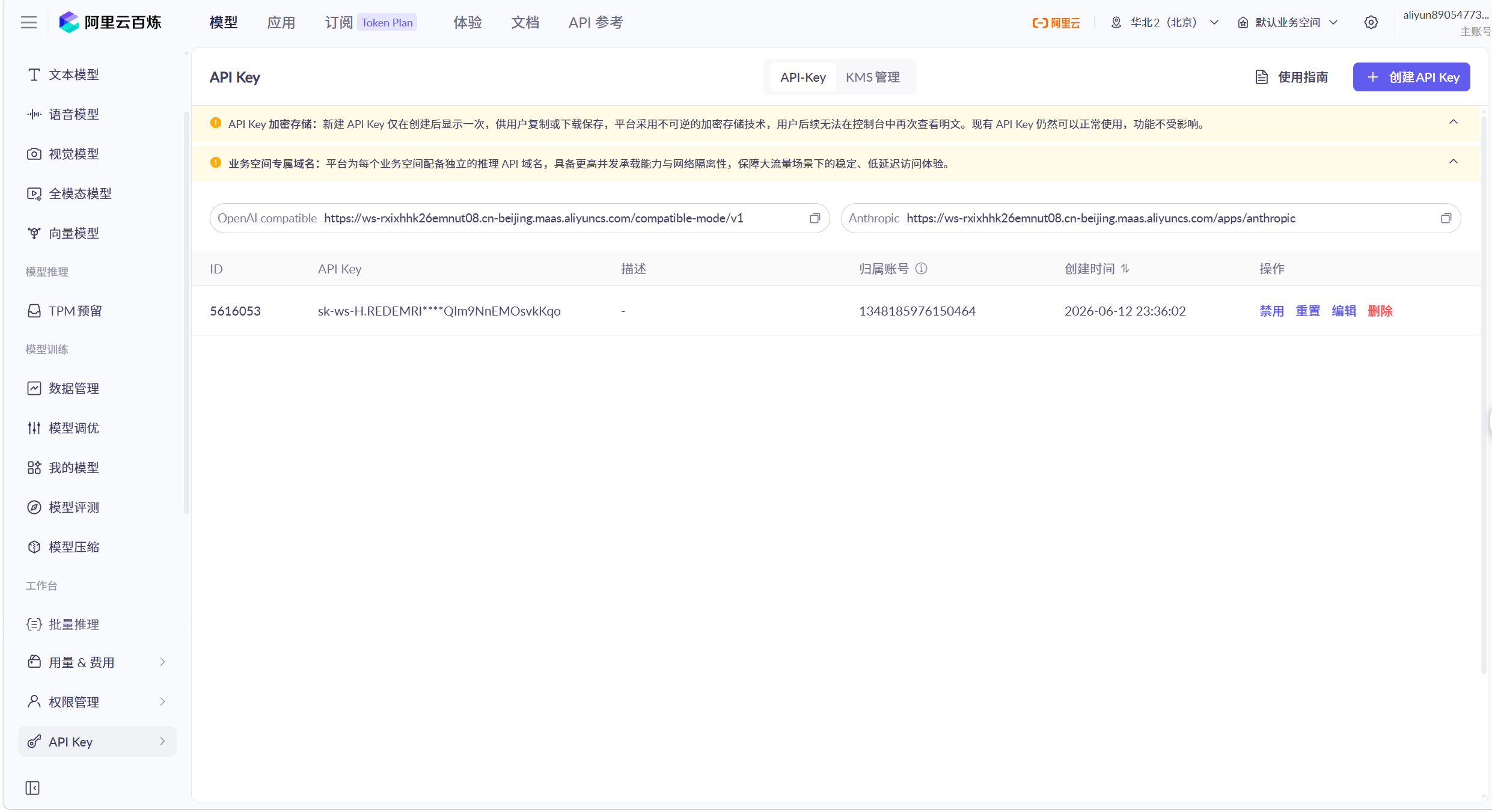
大模型API
DeepSeek官方给出的文档为例
curl -X POST https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <DeepSeek API Key>" \
-d '{
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
],
"stream": false
}'
- 请求方式:通常是POST,因为要传递JSON风格的参数
- 请求URL:与平台有关
- DeepSeek官方平台:https://api.deepseek.com/chat/completions
- 阿里云百炼平台:https://dashscope.aliyuncs.com/compatible-mode/v1
- 本地ollama部署的模型:http://localhost:11434
- 请求头:开放平台都需要提供API_KEY来校验权限,本地ollama则不需要
- Content-Type: application/json,请求参数的格式,必须是application/json,稍后解释
- Authorization: Bearer ,API_KEY
- 请求参数:JSON格式:
{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}
- model:模型名称,DeepSeek支持deepseek-reasoner和deepseek-chat两者模型
- messages:发送给大模型的消息,[]是数组的意思,里面可以有多条消息。消息结构:
- content:是消息的内容
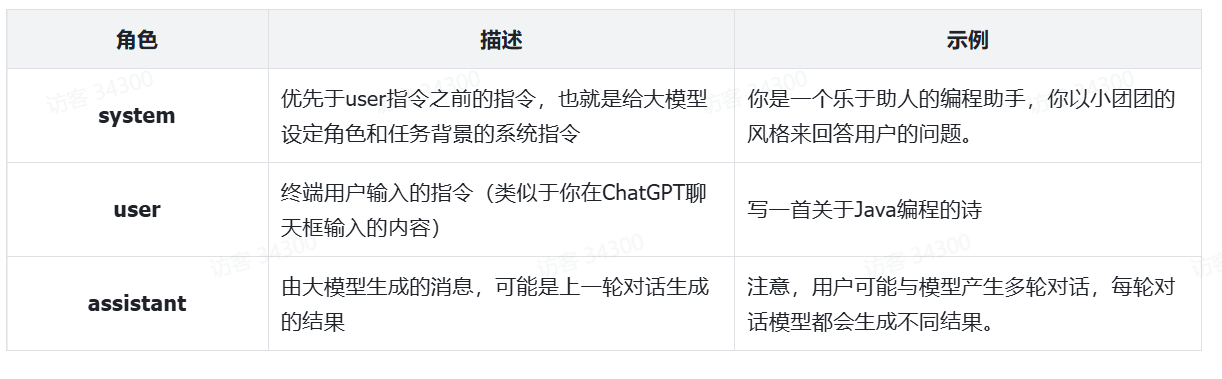
- role:消息的角色,有system、user、assisant三种角色
- system:是给大模型设定一个角色,比如你让她扮演你的奶奶,让她哄你睡觉
- user:就是用户提问的问题
- assisant:是大模型的回答
- stream:true,代表响应结果流式返回;false,代表响应结果一次性返回,但需要等待
注意,这里请求参数中的messages是一个消息数组,而且其中的消息要包含两个属性:
- role:消息对应的角色
- content:消息内容
其中System和User消息的内容,也被称为提示词(Prompt),也就是用户发送给大模型的指令。
- System提示词,是系统指令,给大模型设定一个角色,比如你让她扮演你的奶奶,让她哄你睡觉
- User提示词,是用户指令,也就是用户向大模型的提问或命令
会话记忆问题
要想让AI具备记忆,就必须把对话历史都添加到请求体中的messages数组中:
{
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "你是一位精通中国汉字文化的字谜大师,擅长出谜题、判对错、给提示。保持古风雅韵,用语简练。"
},
{
"role": "user",
"content": "出个字谜让我猜猜"
},
{
"role": "assistant",
"content": "谜面:\"一口咬掉牛尾巴\"(打一字)\n\n请说出你的答案。"
},
{
"role": "user",
"content": "告"
},
{
"role": "assistant",
"content": "妙哉!正是\"告\"字!牛字下面不出头,一口咬去尾巴留。再来一题可好?"
},
{
"role": "user",
"content": "好,再出一题"
}
],
"temperature": 1.2,
"max_tokens": 500,
"stream": false
}
安装UV
Python的虚拟环境管理、依赖管理、工具安装、打包发布一直是让人头疼的事情。
官方文档:https://docs.astral.sh/uv/
中文文档:https://uv.doczh.com/
安装命令:
pip install uv
添加镜像源
默认情况下,uv下载依赖是到国外站点:https://test.pypi.org/simple,速度很慢。推荐大家将下载的镜像源改为国内站点。
uv支持项目级配置和系统级配置两种方案,项目级优先级高,但是需要每个项目都配置,比较麻烦。推荐采用系统级配置。
系统配置方式如下:
- Windows系统,在CMD运行如下命令:
setx UV_DEFAULT_INDEX "https://pypi.tuna.tsinghua.edu.cn/simple"
常见的国内镜像站点有:
阿里云
https://mirrors.aliyun.com/pypi/simple/
腾讯云
https://mirrors.cloud.tencent.com/pypi/simple/
火山引擎
https://mirrors.volces.com/pypi/simple/
华为云
https://mirrors.huaweicloud.com/repository/pypi/simple/
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学
https://pypi.mirrors.ustc.edu.cn/simple/
创建项目
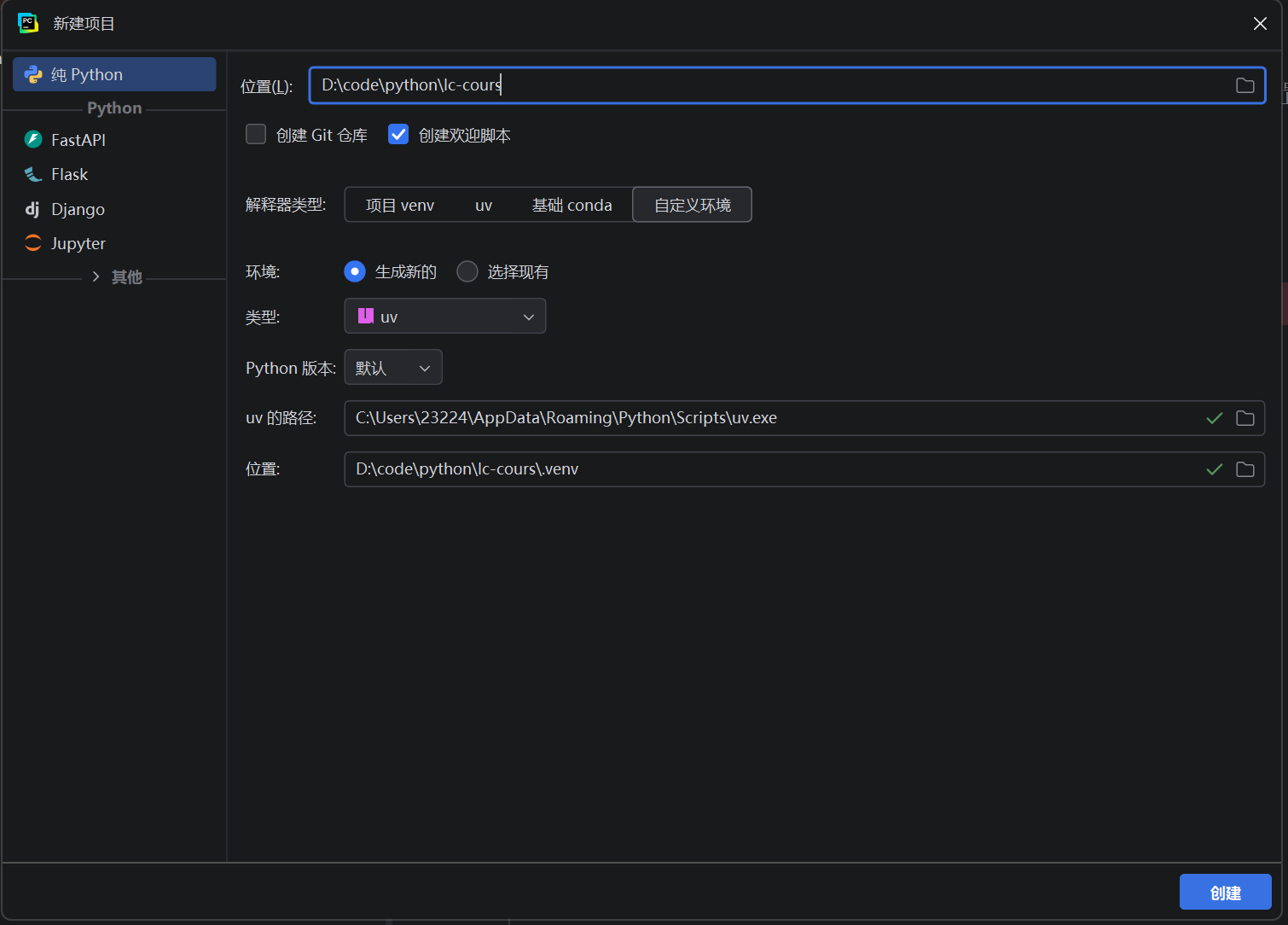
引入notebook依赖。
打开终端,运行命令
uv add notebook
认识LangChain
LangChain 由 Harrison Chase 创建于2022年10月,是用于开发智能体工程(Agent Engineering)的平台。
官网:https://www.langchain.com/
在人工智能领域,Agent(通常翻译为智能体或代理)是指一种能够感知环境、进行推理、自主决策并采取行动以实现特定目标的智能系统。
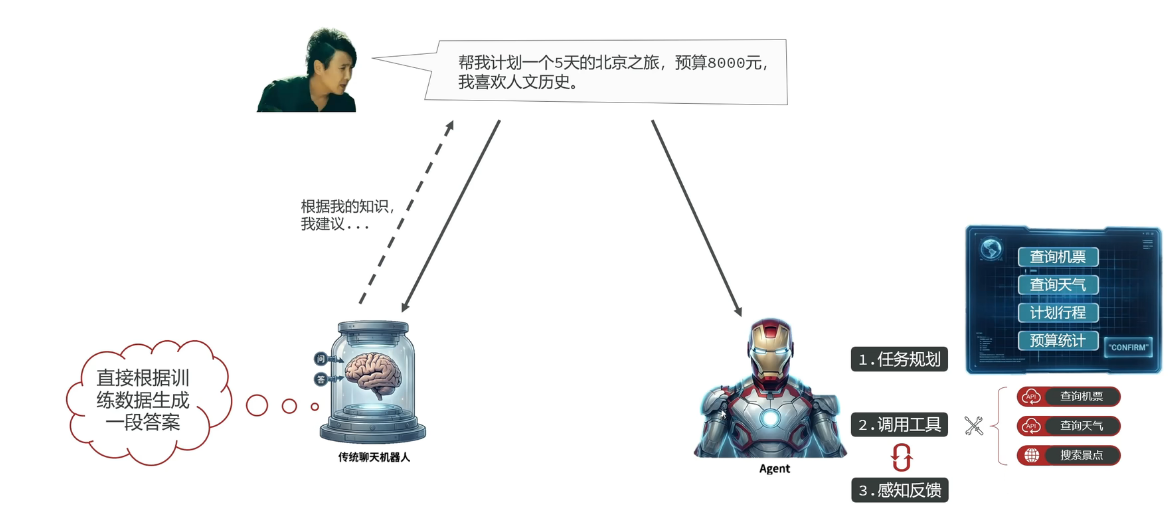
总结如下:
- LLM = 聪明的大脑
- Agent = 聪明的大脑 + 手脚
当然,Agent的模式也是在不断演进的:
- 阶段一:ReAct + Tool Calling
- 阶段二:Reflection + Long Memory
- 阶段三:Multi Agent System,MAS
快速入门
安装 LangChain 核心
pip install langchain
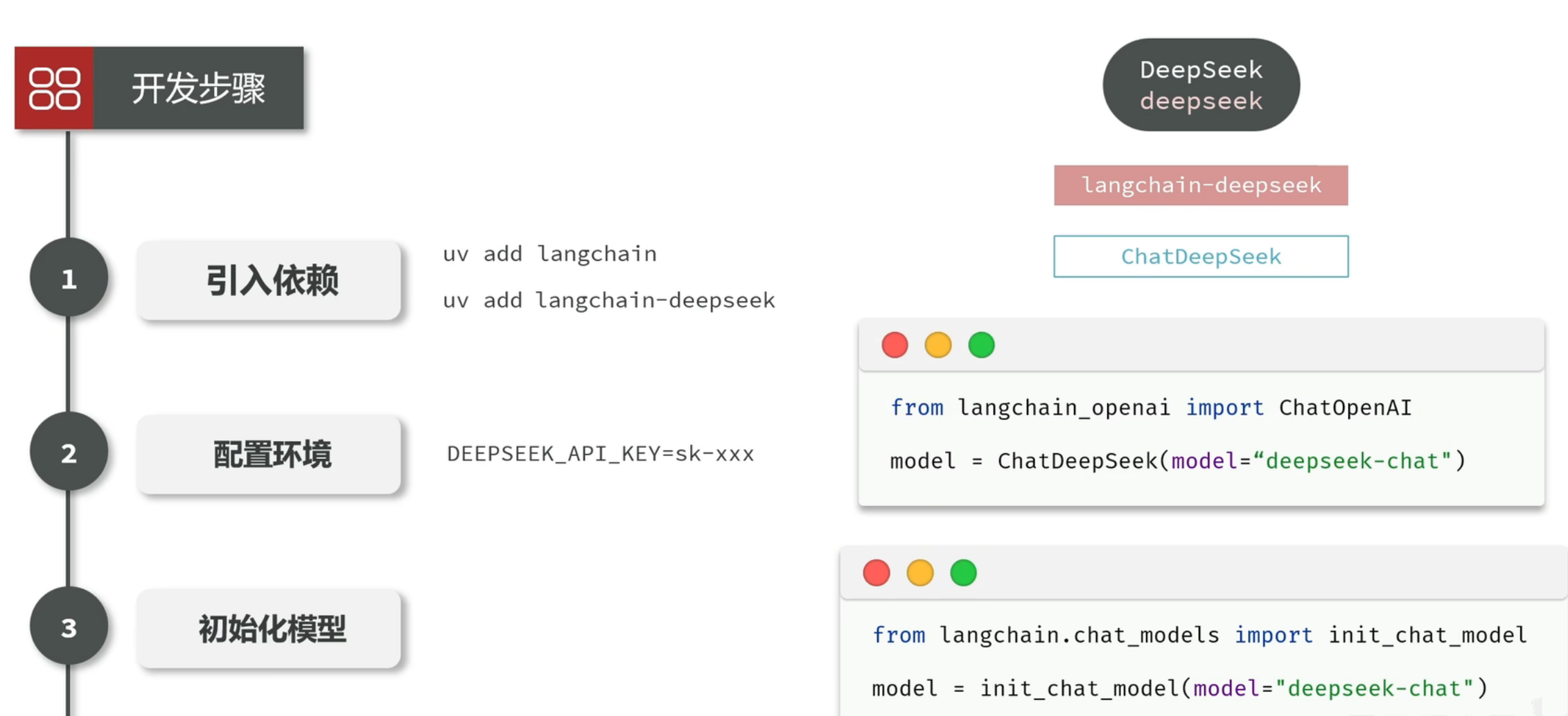
LangChain支持各种不同的模型,而且提供了对应的兼容SDK,不过也都需要安装对应依赖,你可以按需添加:
# DeepSeek 使用 OpenAI 兼容 API
pip install langchain-openai
pip install langchain-anthropic
# 3. 安装 DeepSeek 集成
pip install langchain-deepseek
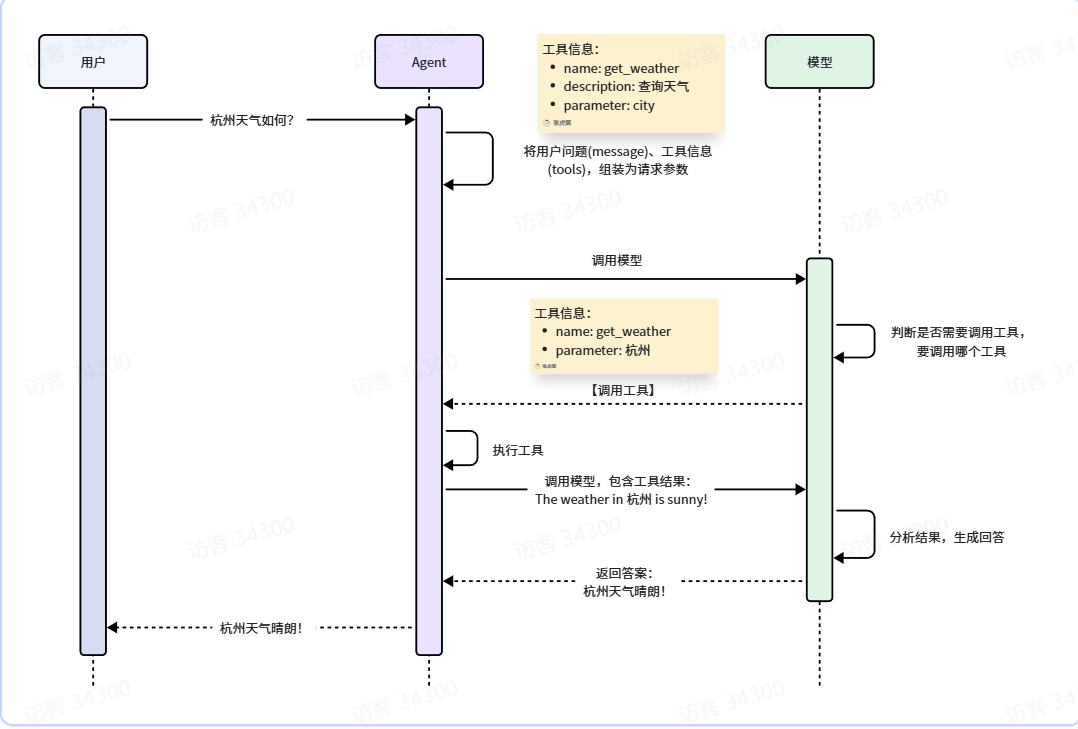
开发Agent了,基本步骤如下:
- 加载环境变量
- 定义工具
- 定义Agent
- 调用Agent
加载环境变量
# 1.加载环境变量
from dotenv import load_dotenv
load_dotenv()
定义工具
from langchain.tools import tool
# 2.定义工具,基础版,通过注释描述工具
@tool
def getWeather(location: str) -> str:
"""
Get the weather in a given location.
Args:
location: city name or coordinates
"""
return f"Current weather in {location} is sunny"
创建agent
from langchain.agents import create_agent
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(
model="deepseek-chat",
api_key="xxxxxxx",
)
agent = create_agent(
model=llm,
tools=[getWeather],
)
发起调用
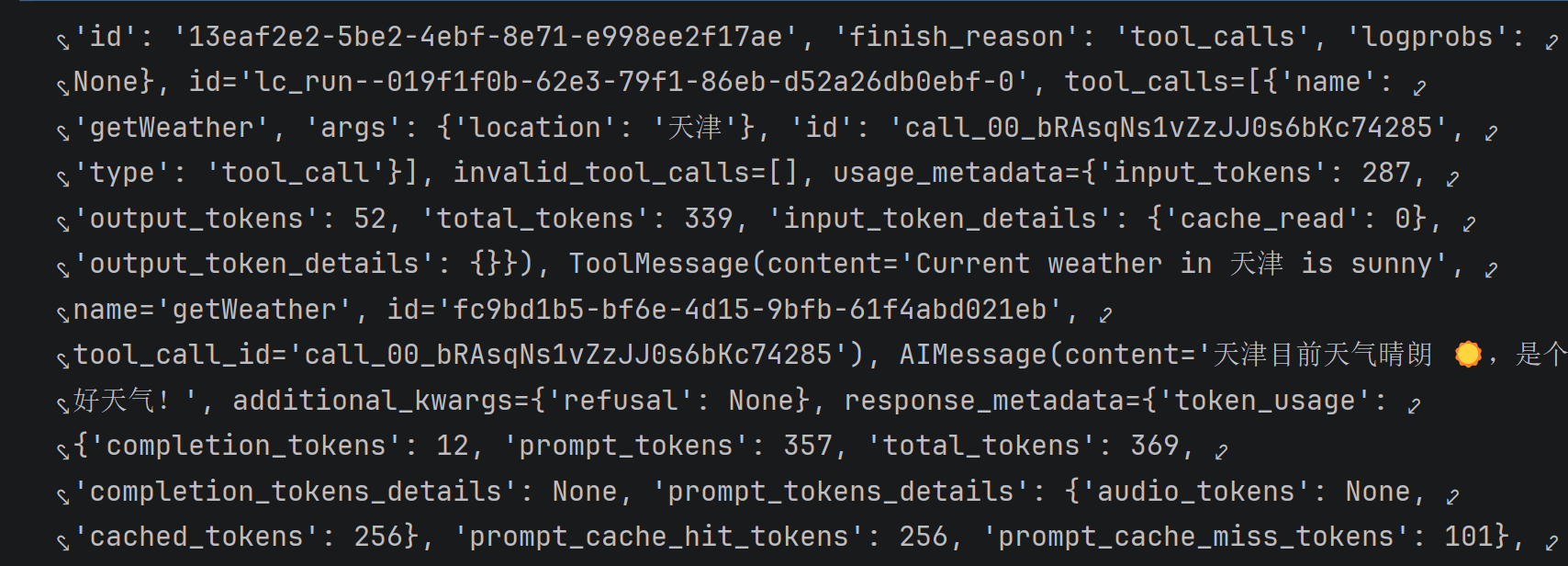
# 发起调用
response = agent.invoke({
"messages": [
{"role": "user", "content": "天津天气如何?"},
]
})
初始化模型
LangChain支持现在市面上大部分常见的大语言模型(LLM),并且提供了各个模型的对应依赖库。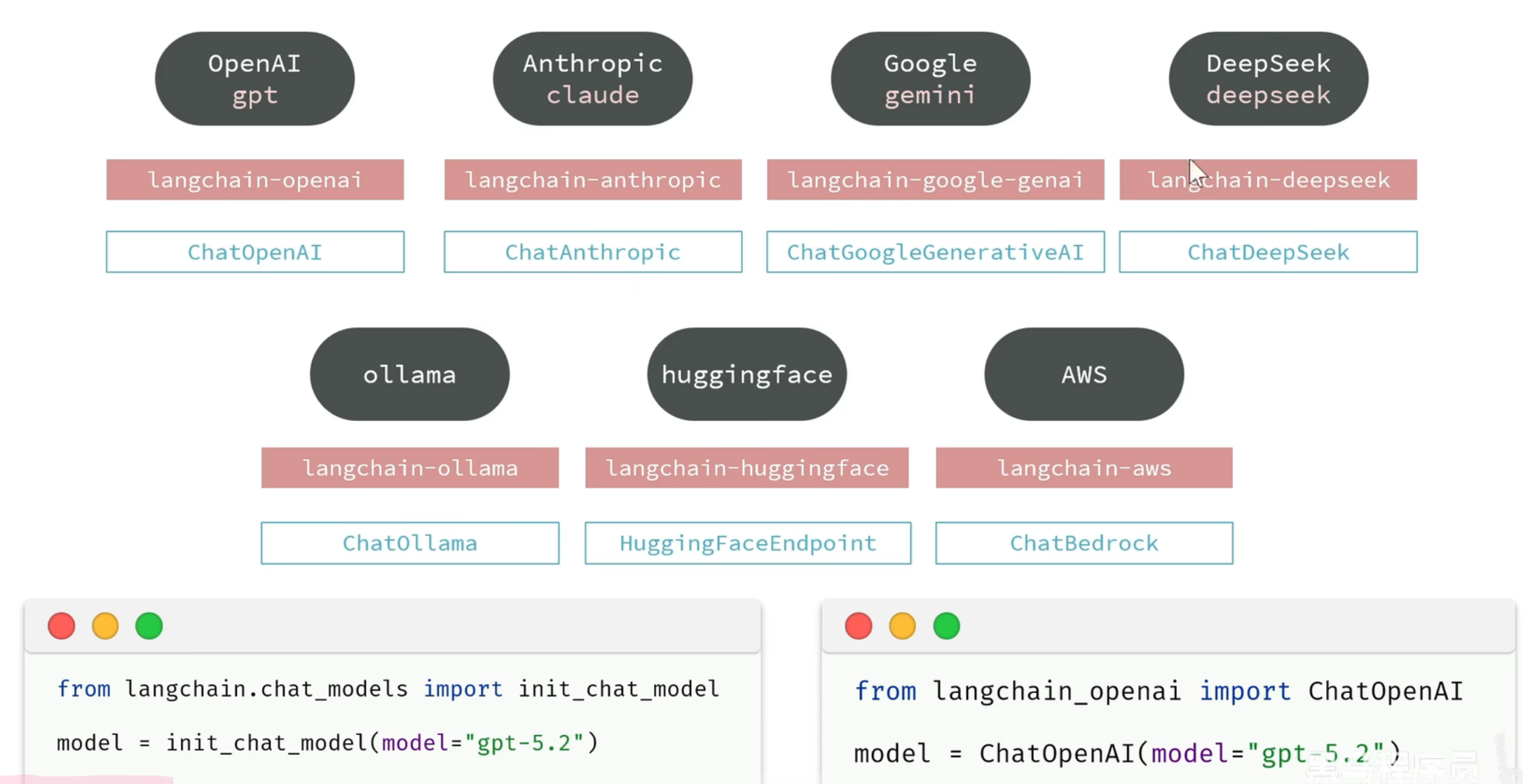
init_chat_model方法底层就是帮我们利用Model类创建对象。但只支持有限的模型。
具体支持的模型,可以查看官网地址:https://docs.langchain.com/oss/python/integrations/chat
from langchain.chat_models import init_chat_model
model = init_chat_model(model='deepseek-chat', api_key='xxxxxxxxx')
print(type(model))

访问模型
invoke方法是阻塞式调用,需要等待模型生成全部结果才会返回,等待时间较长。
from langchain.chat_models import init_chat_model
model = init_chat_model(model='deepseek-chat', api_key='xxxxxxxxxxxxxxxxxx')
# 调用invoke方法
response = model.invoke("你好")
print(response)

stream
阻塞式调用需要等待较长时间才能看到AI返回的结果,而流式调用则可以实时看到AI返回的一个个词。
from langchain.chat_models import init_chat_model
model = init_chat_model(model='deepseek-chat', api_key='xxxxxx')
# 调用invoke方法
stream = model.stream("你好")
print(type(stream))
for response in stream:
print(response.content, end="", flush=True)

在Agent中使用模型
Langchain提供了一个create_agent方法用来快速创建智能体。当我们创建Agent的时候,可以直接使用创建好的Model,也可以指定模型名,让Langchain自动初始化模型。
model = init_chat_model(model='deepseek-chat', api_key='xxxx')
agent = create_agent(model=model)
创建智能体,指定模型名,由Langchain初始化模型
from langchain.agents import create_agent
# 1.指定Model名称,由LangChain自动初始化模型
agent = create_agent(model="deepseek-chat")
阻塞式调用,使用invoke方法:
# 2.调用模型,需要传入一个消息列表
response = agent.invoke({
"messages": [{"role": "user", "content": "你是谁?"}]
})
print(response)
流式调用,只需要把调用方式改为stream:
for token, metadata in agent.stream(
{"messages": [{"role": "user", "content": "你是谁?"}]},
stream_mode="messages"
):
if token.content:
print(token.content, end="", flush=True) # Print token
消息
在调用模型时,发送给LLM的消息、LLM返回的消息都包含以下几部分内容:
- role:消息所属角色,可以是system、user、assistant
- content:消息的内容
- metadata(可选):消息的元数据,例如:消息的ID、消耗的token等
LangChain已经把常见消息根据角色(Role)创建了对应的BaseMessage的子类:
- SystemMessage:role是system,代表系统消息,用于设定模型角色和交互背景
- HumanMessage:role是user,代表用户输入的消息
- AIMessage:role是assistant,代表LLM生成的响应,包含:文本、工具调用、元数据
- ToolMessage:role是tool,代表工具调用时产生的结果
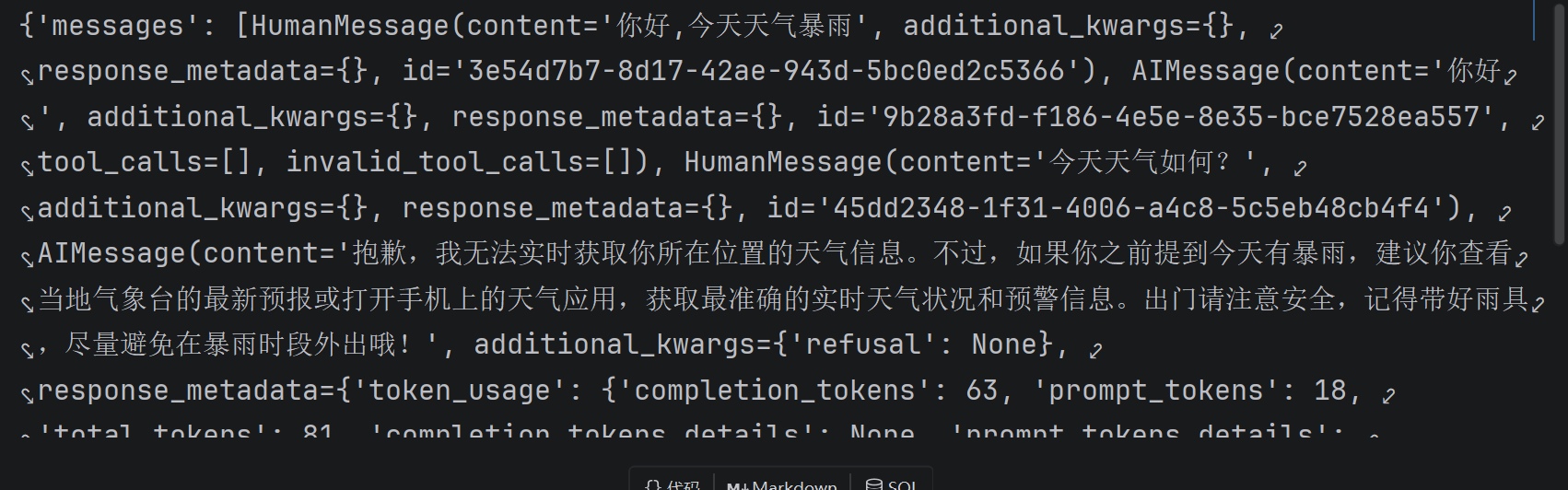
# 使用初始化的model
agent = create_agent(model=model)
# 2.调用模型,需要传入一个消息列表
response = agent.invoke({
"messages": [
HumanMessage(content="你好,今天天气暴雨"),
AIMessage(content="你好"),
HumanMessage(content="今天天气如何?")
]
})
print(response)
response = agent.invoke({
"messages": [
HumanMessage(content="你好,今天天气暴雨"),
AIMessage(content="你好"),
HumanMessage(content="今天天气如何?")
]
})
for message in response['messages']:
message.pretty_print()
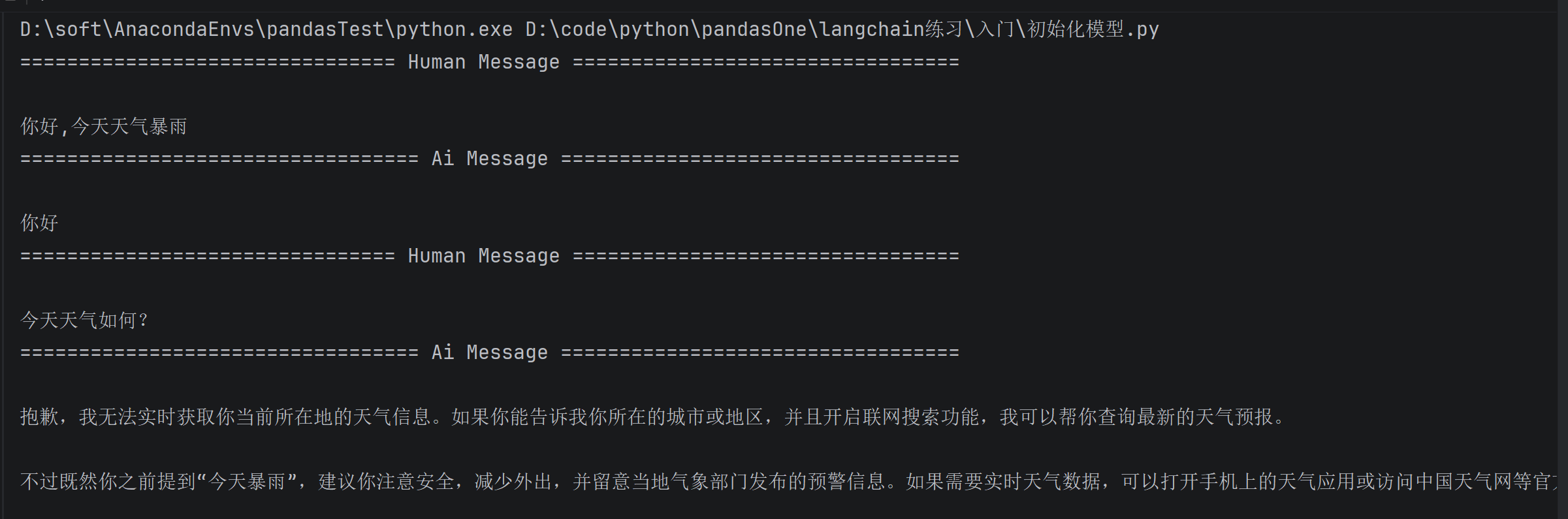
多模态消息
LangChain 也支持向模型发送多模态消息,比如图片、音频、视频、文本等。但前提是必须是多模态模型才支持。
在线图片
{
"role": "user",
"content": [
{"type": "image_url", "image_url": "https://xxx.com/a.jpeg"},
{"type": "text", "text": "这些图描绘了什么内容?"}
]
}
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
import os
from langchain_core.messages import HumanMessage
# 1.初始化模型
model = init_chat_model(
model="qwen3.5-plus", # 这里选择qwen3.5-plus,这是一个多模态模型,支持图片、文本、音频、视频
model_provider="openai",
base_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key='xxxxxxxxxxxxxxxxxxxxxx'
)
# 2.创建智能体
agent = create_agent(model=model)
# 3.组织多模态消息
multimodal_message = HumanMessage(
content=[
{"type": "image_url",
"image_url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"},
{"type": "text", "text": "这些图描绘了什么内容?"}
])
# 4.调用Agent,发送多模态消息
for token, metadata in agent.stream({
"messages": [multimodal_message]
}, stream_mode="messages"):
if token.content:
print(token.content, end="", flush=True)
agent.stream():以流式方式调用 agent,数据会逐步返回而不是一次性返回所有结果
{“messages”: [multimodal_message]}:输入数据,包含一个消息列表
multimodal_message:是一个多模态消息对象,可能包含文本和图片
stream_mode=“messages”:指定流式模式为 “messages”,表示逐条消息地流式输出
token:当前返回的消息片段(token),是一个消息对象
metadata:元数据信息,如消息ID、时间戳等
循环会持续直到所有消息流式传输完成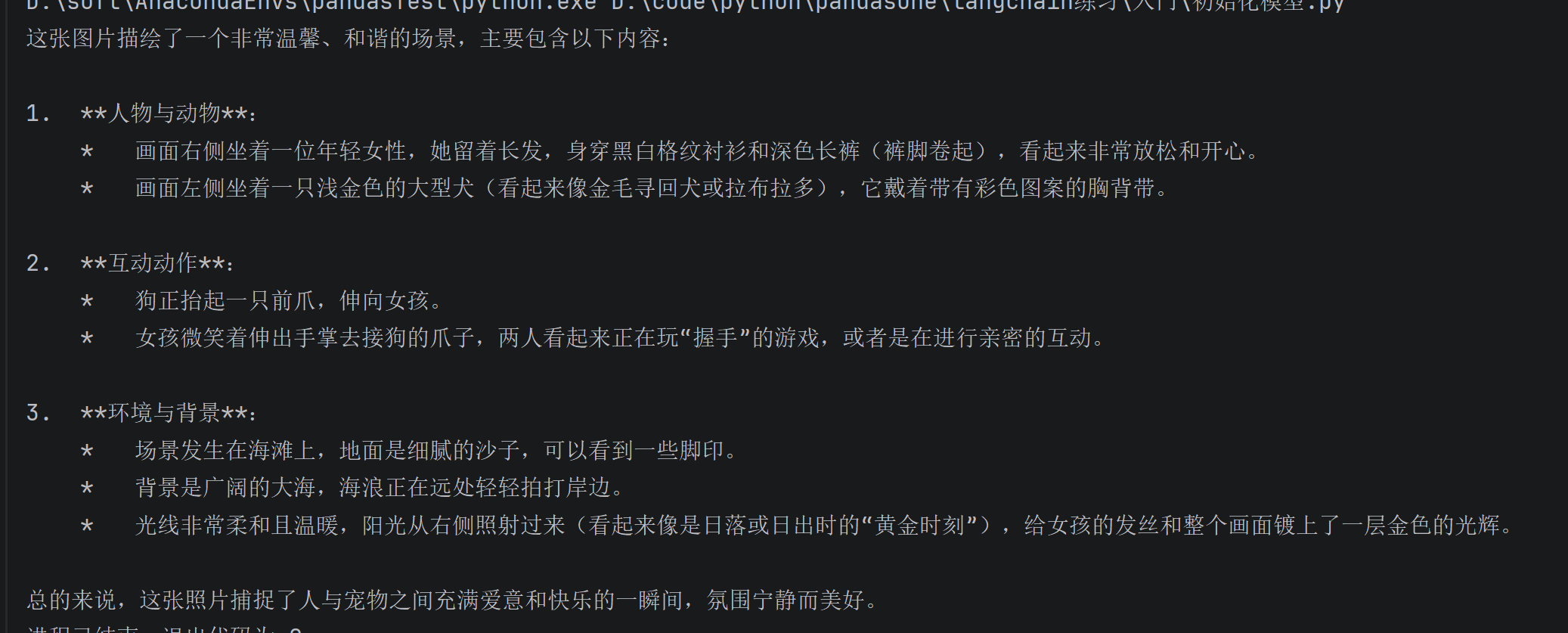
本地图片
{
"role": "user",
"content": [
{"type": "text", "text": "Describe the content of this image."},
{
"type": "image",
"base64": "AAAAIGZ0eXBtcDQyAAAAAGlzb21tcDQyAAACAGlzb2...",
"mime_type": "image/jpeg",
},
]
}
import base64
from langchain_core.messages import HumanMessage
# 从文件读取图片
with open("city.jpg", "rb") as f:
img_bytes = f.read()
img_b64 = base64.b64encode(img_bytes).decode("utf-8")
multimodal_question = HumanMessage(
content=[
{
"type": "text",
"text": "给我讲讲图片中的城市"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{img_b64}"
}
}
]
)
response = agent.invoke({"messages": [multimodal_question]})
print(response['messages'][-1].content)
response[‘messages’][-1].content 的意思是:
- response:从 Agent 获取的完整响应
- [‘messages’]:对话中的所有消息
- [-1]:最后一条消息(通常是最新的 AI 回复)
- .content:消息的文本内容
提示词(Prompts)
系统提示词
提示词(Prompt)就是发送给模型的消息,其中SystemMessage是系统提示词(system prompt),可以给模型设定角色、聊天的背景、任务说明,对模型生成的内容有很大的影响。
# 创建智能体
agent = create_agent(
model = "deepseek-chat",
system_prompt="像一个高冷女神."
)
提示词工程
通过优化System Prompt从而让模型输出更理想的结果的这一过程,我们称为提示词工程(Prompt Engineering)。
从内容来说,提示词通常包含以下几个部分,通常按此顺序排列:
- 身份(Identity):描述AI的职责、沟通风格和总体目标。
- 说明(Instructions):请指导模型如何生成所需的响应。它应该遵循哪些规则?模型应该做什么,以及模型绝对不能做什么?
- 示例(Examples):提供可能的输入示例,以及模型期望的输出。
- 背景信息(Context):向模型提供生成响应所需的任何额外信息,例如RAG的额外知识库数据,或您认为特别相关的任何其他数据。
从格式来说,在编写System Prompt时,您可以使用Markdown格式和XML 标签的组合来帮助模型理解提示和上下文数据的逻辑边界。
- Markdown 的标题和列表有助于标记提示的不同部分,并向模型传达层级结构。它们还可以提高开发过程中提示的可读性。
- XML 标签可以帮助明确区分一段内容(例如用作参考的辅助文档、对话示例等)的起始和结束位置。
在LangChain中,实现结构化输出会更加简单。我们无需自己在提示词中添加描述实现结构化输出,而仅仅是设定好一个数据类型即可。
定义一个类,用来封装模型要输出的数据:
from pydantic import BaseModel
class CapitalInfo(BaseModel):
name: str
location: str
vibe: str
economy: str
可以在创建Agent时设定好输出格式:
# 然后,我们就可以创建智能体并设置结构化输出的格式了。
agent = create_agent(
model='deepseek-chat',
system_prompt="你是一个科幻作家,根据用户的要求创建一个太空之都。",
response_format=CapitalInfo # 设置结构化输出的格式
)
response = agent.invoke(
{"messages": [HumanMessage(content="火星的首都是什么?")]}
)
工具(Tools)
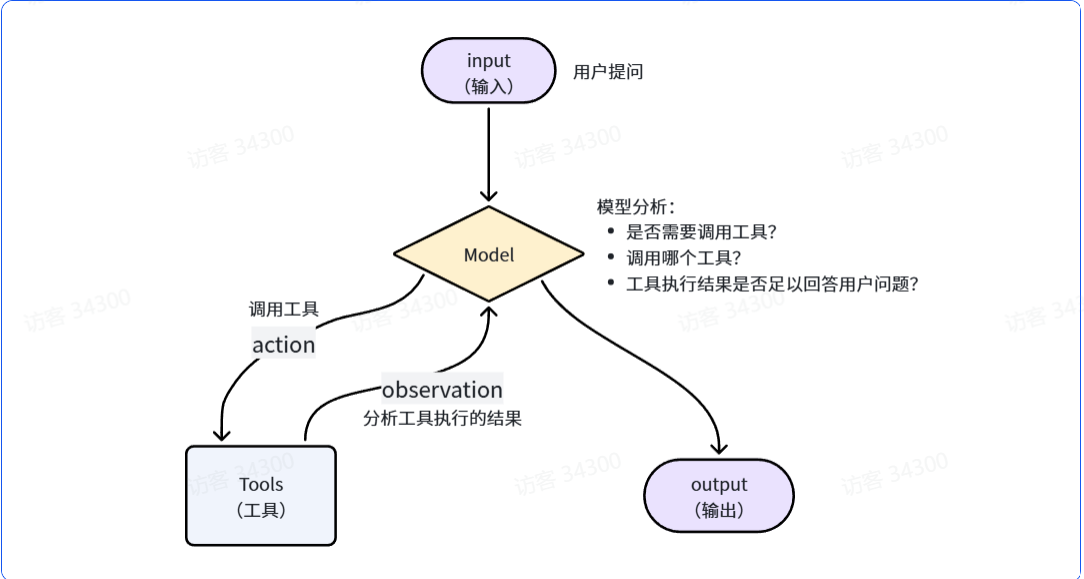
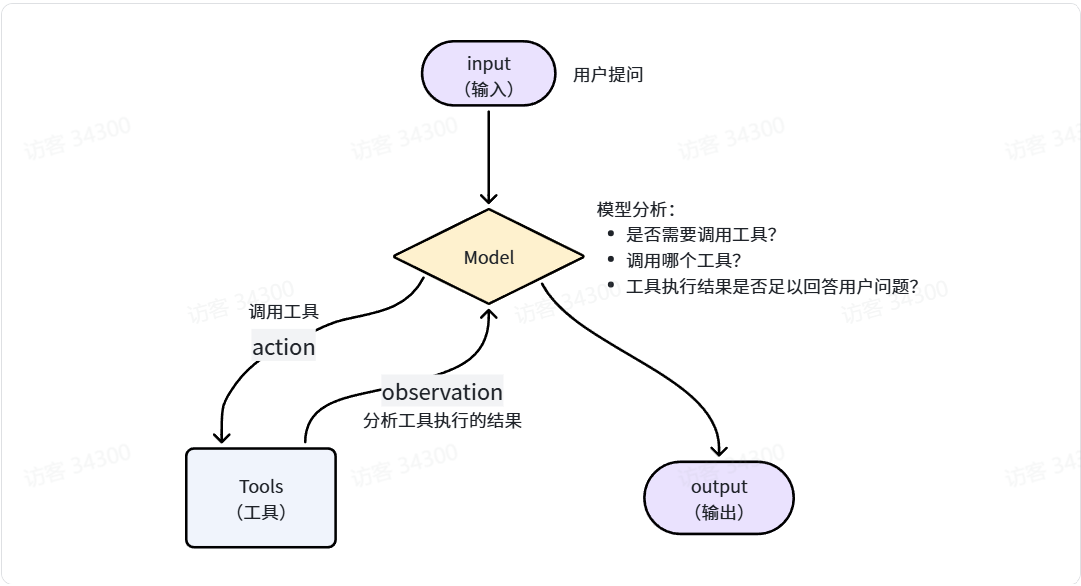
一个完整的Agent至少要包含两个关键的部分:
- 模型:是Agent的大脑,负责推理、分析,规划任务步骤
- 工具:是Agent的手脚,负责执行任务,与外界交互
自定义工具
在LangChain中,定义工具的过程被大大简化,与定义普通函数几乎没什么差别,只是在一些细节上需要注意。
定义工具需要在函数上添加@tool装饰器。
智能体在工作时,需要将函数的名称、输入、作用传递给大模型,默认情况下这些信息的来源是:
- 工具名称:函数名
- 工具输入:函数入参
- 工具作用:函数的注释
通过装饰器定义工具名称和工具作用描述
@tool("square_root",description="Calculate the square root of a number" )
def tool1(x: float) -> float:
return x ** 0.5
使用函数名和文档注释描述工具
如果不@tool装饰器没有定义工具名和作用描述,此时:
- 工具名:默认就是函数名
- 工具所需的参数:默认就是函数的参数列表
- 工具作用的描述:默认就是函数的文档注释
@tool
def tool1(x: float) -> float:
"""Calculate the square root of a number"""
return x ** 0.5
# 定义一个查询天气的tool
@tool(args_schema=WeatherInput)
def get_weather(location: str, units: str = "celsius", include_forecast: bool = False) -> str:
"""Get current weather and optional forecast."""
temp = 22 if units == "celsius" else 72
result = f"Current weather in {location}: {temp} degrees {units[0].upper()}"
if include_forecast:
result += "\nNext 5 days: Sunny"
return result
定义Pydartic Model描述参数
如果函数的参数比较多,而且比较复杂,此时建议通过pydantic model来描述参数列表。
class WeatherInput(BaseModel):
"""查询天气的输入参数"""
location: str = Field(description="City name or coordinates")
units: Literal["celsius", "fahrenheit"] = Field(
default="celsius",
description="Temperature unit preference"
)
include_forecast: bool = Field(
default=False,
description="Include 5-day forecast"
)
# 定义天气查询工具
@tool(args_schema=WeatherInput)
def get_weather(location: str, units: str = "celsius", include_forecast: bool = False) -> str:
"""Get current weather and optional forecast."""
temp = 22 if units == "celsius" else 72
result = f"Current weather in {location}: {temp} degrees {units[0].upper()}"
if include_forecast:
result += "\nNext 5 days: Sunny"
return result
预定义工具
LangChain中提供了很多预定义好的工具,方便我们使用,可使用的预定义工具列表可参考官网:https://docs.langchain.com/oss/python/integrations/tools
在LangChain中也提供了对Tavily的支持:
https://docs.langchain.com/oss/python/integrations/tools/tavily_search
要在Tavily官网注册一个账号,可以选择邮箱注册,或者直接用google、github登录
注册成功后,我们登录后台https://app.tavily.com/home,即可看到一个默认的API_KEY: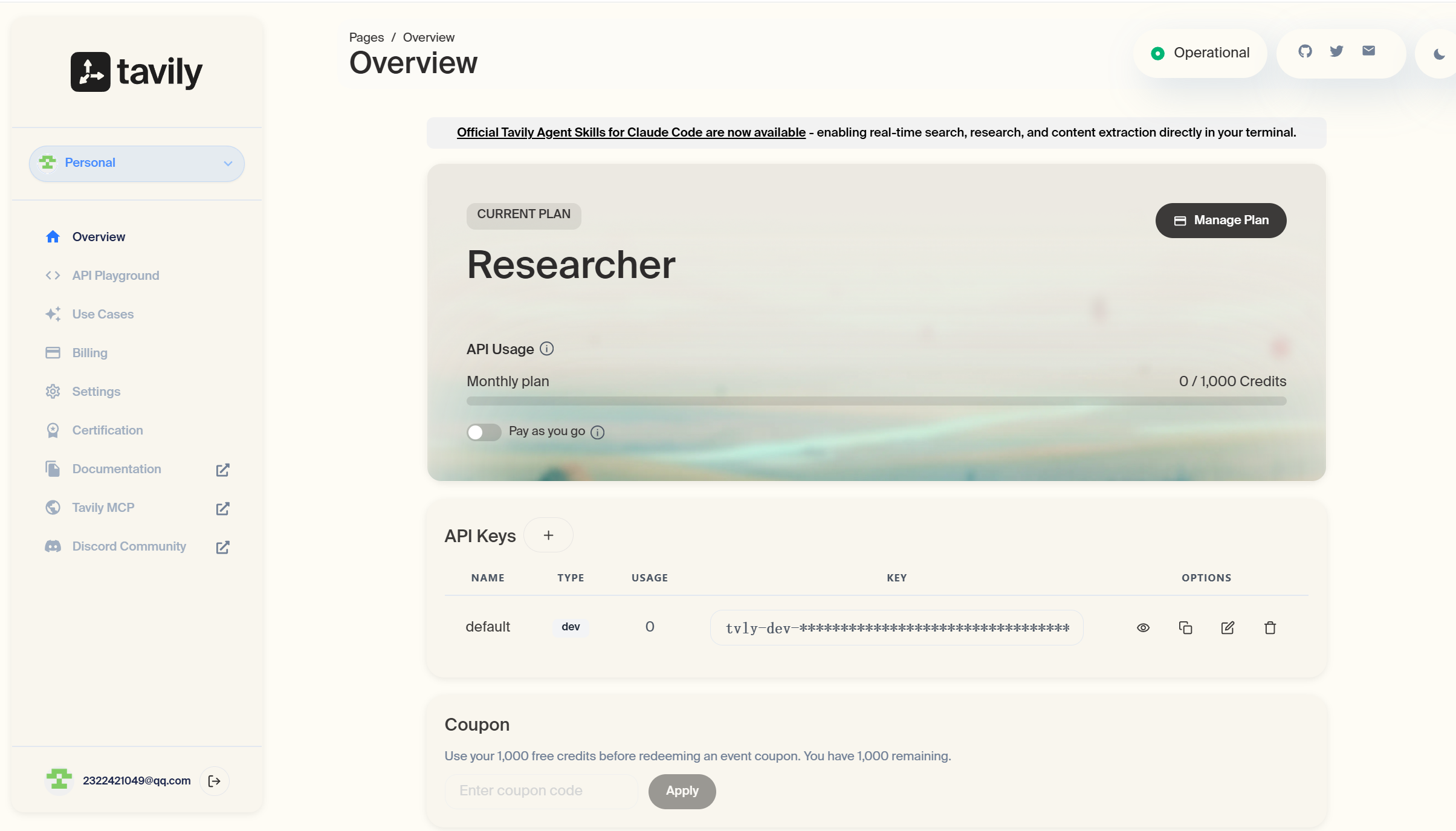
安装langchain-tavily的依赖:
pip install -U langchain-tavily
使用tavily来做web搜索
# 使用tavily作为web搜索工具
from langchain_tavily import TavilySearch
import json
tool = TavilySearch(
tavily_api_key="xxxxxxxxxxxxxxxx",
max_results=5,
topic="general"
)
response = tool.invoke("天津今天天气如何?")
print(json.dumps(response, ensure_ascii=False, indent=2))
{
"query": "天津今天天气如何?",
"follow_up_questions": null,
"answer": null,
"images": [],
"results": [
{
"url": "https://weather.cma.cn/web/weather/54517.html",
"title": "天津市 - 天气预报",
"content": "| 气温 | 28.2℃ | 28.8℃ | 25.3℃ | 25.2℃ | 25.1℃ | 21.3℃ | 21.2℃ | 21.3℃ |. | 降水 | 7.1mm | 1.5mm | 1.8mm | 无降水 | 1.1mm | 10.6mm | 无降水 | 无降水 |. | 风向 | 东南风 | 东南风 | 东北风 | 西北风 | 西北风 | 东南风 | 东北风 | 东北风 |. | 云量 | 70% | 70% | 70% | 0% | 82.2% | 83% | 65.6% | 1.8% |. | 降水 | 无降水 | 无降水 | 无降水 | 无降水 | 无降水 | 无降水 | 无降水 | 无降水 |. | 降水 | 无降水 | 2.3mm | 2.3mm | 2.3mm | 2.3mm | 无降水 | 无降水 | 无降水 |. | 风向 | 东南风 | 西南风 | 西南风 | 西南风 | 西南风 | 西南风 | 西南风 | 西南风 |. | 风向 | 西南风 | 西南风 | 西南风 | 西北风 | 西北风 | 西北风 | 西南风 | 西北风 |.",
"score": 0.7237202,
"raw_content": null
},
{
"url": "https://www.weather.com.cn/weather40d/101030100.shtml",
"title": "【天津天气】天津40天天气预报,天津更长预报,天津天气日历,天津日历,15天天气预报,天气预报一周",
"content": "首页 预报 预警 雷达 云图 天气地图 专业产品 资讯 视频 节气. 台风路径 空间天气 图片 专题 环境 旅游 碳中和 气象科普 一带一路 产创平台. : 北京 上海 成都 杭州 南京 天津 深圳 重庆 西安 广州 青岛 武汉. : 故宫 阳朔漓江 龙门石窟 野三坡 颐和园 九寨沟 东方明珠 凤凰古城 秦始皇陵 桃花源. : 佘山 春城湖畔 华彬庄园 观澜湖 依必朗 旭宝 博鳌 玉龙雪山 番禺南沙 东方明珠. : 曼谷 东京 首尔 吉隆坡 新加坡 巴黎 罗马 伦敦 雅典 柏林 纽约 温哥华 墨西哥城 哈瓦那 圣何塞 巴西利亚 布宜诺斯艾利斯 圣地亚哥 利马 基多 悉尼 墨尔本 惠灵顿 奥克兰 苏瓦 开罗 内罗毕 开普敦 维多利亚 拉巴特. 16-40天预报数据来源于国家气候中心,是根据全球数值天气预报模式客观预报系统加工而成,未经预报员主观订正,反应未来一段时间内天气变化趋势,具有一定的不确定性,供公众参考,欲知更加准确的天气预报需随时关注短期天气预报和最新预报信息更新。. : 台风“海高斯”将向东北方向快速移动 对我国海域无影响 中国天气网 2026-06-26 18:11. : 山洪灾害气象预警:福建广西等5省区局地发生山洪灾害可能性较大 中国天气网 2026-06-26 18:05. : 未来10天夏种区多降水 墒情适宜利于夏播扫尾和幼苗生长 中国天气网 2026-06-26 17:45. : 地质灾害气象风险预警:福建广西等5省区部分地区风险较高 中国天气网 2026-06-26 17:35. : 北方多地6月以来雨量雨日均超标 今年北方的雨为何这么多? 中国天气网 2026-06-26 17:25. # 周边地区 *|* 周边景点 *2026-06-26 18:00更新*. # 高清图集. 今天(6月24日),南方主雨带的东段将继续减弱并南落,但西段的广西、贵州、云南交界一带仍将有暴雨或大暴雨。. 今明两天(6月23日至24日),长江中下游一带仍有强降雨,降水强度呈减弱趋势。24日后,南方的降雨将南压至贵州、广西北部到江南中南部一带,强度继续减弱。. 今起三天(6月22日至24日),我国主雨带仍将集中在长江沿线,公众需关注预警预报信息。同时,江南南部、华南等地炎热天气持续,将现成片高温。. 今明两天,长江中下游一带的降雨会再度增强;同时,东北地区的降雨也仍将持续。而在华南和江南南部一带,明天起会迎来成片的高温天气。. 端午假期后两天,南方大部和东北地区降雨仍然较多,其中长江中下游明天雨势较强。此外,今天起江南南部和华南一带的高温闷热天气将快速发展。. 端午节假期期间,长江中下游一带多地雨势强劲,同时东北、华北、黄淮的降雨或强对流天气也将较为频繁。此外,未来七天南北多地气温将有所下滑。. 今天(6月18日)开始,随着副热带高压北抬,南方强降雨的重心将从华南一带逐渐向江南、长江中下游转移。与此同时,在阴雨天气的压制下,上述地区气温将有所下滑,炎热褪去。. 今天(6月17日),华南一带仍有强降雨,明天起南方主雨带将北抬至长江中下游等地,华南多地高温闷热天气逐渐发展。. 未来三天(6月16日至18日),南方大范围降雨持续,伴随较大湿度,多地闷热感加剧。在北方,东北、华北等地受频繁降雨影响,今明天体感较凉爽。. 今后三天(6月15日至17日),广西、广东等地强降雨持续时间长、累计降雨量大。同时,西北地区东部、黄淮等地晴热持续,河南将为高温核心区。. 今起三天(6月14日至16日),江南南部、华南一带将维持多雨格局,部分地区暴雨持续。在北方,西北地区东部至黄淮一带则以晴热天气为主。. 南方强降雨集中期已开启,今天(6月13日)多地大到暴雨范围扩大,部分地区将有大暴雨。同时,华北、东北等地多阵雨或雷阵雨,并伴有强对流天气。. ## 南方将进入强降雨集中期 华北东北等地多雷雨. 今天(6月12日)夜间起,南方将进入强降雨集中期,明后天雨势明显增强。华北、黄淮东部、东北地区、内蒙古东南部等地多阵雨或雷阵雨。. * 九寨沟 多云转阵雨 16/27℃ 适宜. * 大理 小雨转阵雨 17/22℃ 适宜. * 张家界 多云 21/33℃ 适宜. * 青岛 晴 21/27℃ 适宜. 中国天气网版权所有,未经书面授权禁止使用 Copyright©中国气象局公共气象服务中心 All Rights Reserved (2008-2026).",
"score": 0.7120925,
"raw_content": null
},
{
"url": "https://www.ventusky.com/zh-tw/tianjin",
"title": "天氣- 天津市- 14天預報:氣溫、風和雷達 - Ventusky",
"content": "| 高雲 29 °C 0 mm 0 % 東南 10 km/h | 高雲 26 °C 0 mm 0 % 東南 10 km/h | 高雲 25 °C 0 mm 0 % 東南 8 km/h | 晴朗的天空 25 °C 0 mm 0 % 東南 8 km/h | 晴朗的天空,幾朵雲 24 °C 0 mm 0 % 東南 8 km/h | 晴朗的天空,幾朵雲 24 °C 0 mm 0 % 東南 6 km/h | 晴朗的天空 24 °C 0 mm 0 % 東南 6 km/h | 晴朗的天空 24 °C 0 mm 0 % 南 5 km/h | 晴朗的天空 24 °C 0 mm 0 % 南 5 km/h | 晴朗的天空,幾朵雲 24 °C 0 mm 0 % 南 5 km/h | 晴朗的天空,幾朵雲 24 °C 0 mm 0 % 南 5 km/h | 晴朗的天空,幾朵雲 24 °C 0 mm 0 % 南 5 km/h | 晴朗的天空,幾朵雲 26 °C 0 mm 0 % 南 5 km/h | 晴朗的天空 27 °C 0 mm 0 % 南 5 km/h | 晴朗的天空 29 °C 0 mm 0 % 西南 6 km/h | 多雲 31 °C 0 mm 0 % 西南 7 km/h | 多雲 33 °C 0 mm 10 % 西南 10 km/h | 多雲 34 °C 0 mm 0 % 西南 10 km/h | 多雲 35 °C 0 mm 0 % 西南 11 km/h | 晴朗的天空,幾朵雲 36 °C 0 mm 0 % 西南 10 km/h | 晴朗的天空,幾朵雲 36 °C 0 mm 0 % 西南 12 km/h | 多雲 36 °C 0 mm 0 % 南 11 km/h | 大部分多雲 36 °C 0 mm 10 % 南 11 km/h | 多雲 35 °C 0 mm 10 % 南 9 km/h | 多雲 33 °C 0 mm 10 % 東南 11 km/h |.",
"score": 0.7099254,
"raw_content": null
},
{
"url": "https://www.weather.com.cn/weather/101030100.shtml",
"title": "天津天气预报,天津7天天气预报,天津15天天气预报,天津天气查询",
"content": "首页 预报 预警 雷达 云图 天气地图 专业产品 资讯 视频 节气. 台风路径 空间天气 图片 专题 环境 旅游 碳中和 气象科普 一带一路 产创平台. : 北京 上海 成都 杭州 南京 天津 深圳 重庆 西安 广州 青岛 武汉. : 故宫 阳朔漓江 龙门石窟 野三坡 颐和园 九寨沟 东方明珠 凤凰古城 秦始皇陵 桃花源. : 佘山 春城湖畔 华彬庄园 观澜湖 依必朗 旭宝 博鳌 玉龙雪山 番禺南沙 东方明珠. : 曼谷 东京 首尔 吉隆坡 新加坡 巴黎 罗马 伦敦 雅典 柏林 纽约 温哥华 墨西哥城 哈瓦那 圣何塞 巴西利亚 布宜诺斯艾利斯 圣地亚哥 利马 基多 悉尼 墨尔本 惠灵顿 奥克兰 苏瓦 开罗 内罗毕 开普敦 维多利亚 拉巴特. : 山洪灾害气象预警:浙江江西局部地区发生山洪灾害可能性较大 中国天气网 2026-07-01 18:05. : 暴雨蓝色预警:11省区市部分地区有大到暴雨 江西浙江局地大暴雨 中国天气网 2026-07-01 18:05. : 台风蓝色预警:南海热带低压将于3日登陆海南至广东一带沿海 中国天气网 2026-07-01 18:05. : 地质灾害气象风险预警:浙江安徽等7省市部分地区风险较高 中国天气网 2026-07-01 17:30. : 破纪录!数据盘点6月南方下了多少雨 华南台风雨即将来袭 中国天气网 2026-07-01 17:01. # 周边地区 *|* 周边景点 *2026-07-01 18:00更新*. # 高清图集. 未来3天,云贵高原至江南中北部一带强降雨仍将持续,多地有暴雨、大暴雨,华北、东北的强对流天气也依然频繁。同时,未来三天我国多地热意增强。. 今天起,南方新一轮强降雨来袭,长江中下游一带以及贵州、广西、云南等地需警惕暴雨致灾,同时东北、华北一带仍将维持多雨格局。. 今天(6月27日),南方降降雨主要集中在华南和西南地区,雨势较前期有所减弱。明天起,南方主雨带东段将北抬至江南北部,需注意防范。. 今天(6月27日),南方降雨将减弱,华南等地部分地区有大到暴雨。明后天,南方主雨带将北抬。在北方,华北、东北等地未来三天多雷雨天气出没。. 今天(6月24日),南方主雨带的东段将继续减弱并南落,但西段的广西、贵州、云南交界一带仍将有暴雨或大暴雨。. 今明两天(6月23日至24日),长江中下游一带仍有强降雨,降水强度呈减弱趋势。24日后,南方的降雨将南压至贵州、广西北部到江南中南部一带,强度继续减弱。. 今起三天(6月22日至24日),我国主雨带仍将集中在长江沿线,公众需关注预警预报信息。同时,江南南部、华南等地炎热天气持续,将现成片高温。. 今明两天,长江中下游一带的降雨会再度增强;同时,东北地区的降雨也仍将持续。而在华南和江南南部一带,明天起会迎来成片的高温天气。. 端午假期后两天,南方大部和东北地区降雨仍然较多,其中长江中下游明天雨势较强。此外,今天起江南南部和华南一带的高温闷热天气将快速发展。. 端午节假期期间,长江中下游一带多地雨势强劲,同时东北、华北、黄淮的降雨或强对流天气也将较为频繁。此外,未来七天南北多地气温将有所下滑。. 今天(6月18日)开始,随着副热带高压北抬,南方强降雨的重心将从华南一带逐渐向江南、长江中下游转移。与此同时,在阴雨天气的压制下,上述地区气温将有所下滑,炎热褪去。. 今天(6月17日),华南一带仍有强降雨,明天起南方主雨带将北抬至长江中下游等地,华南多地高温闷热天气逐渐发展。. * 三亚 多云转雷阵雨 26/35℃ 适宜. * 九寨沟 阵雨 16/26℃ 适宜. * 大理 小雨转中雨 16/21℃ 适宜. * 张家界 小雨 20/26℃ 适宜. * 青岛 多云 22/25℃ 适宜. 中国天气网版权所有,未经书面授权禁止使用 Copyright©中国气象局公共气象服务中心 All Rights Reserved (2008-2026).",
"score": 0.6999322,
"raw_content": null
},
{
"url": "https://tianqi.so.com/weather/101030100",
"title": "【天津天气预报】天津天气预报7天,10天,15天_全国天气网",
"content": "# 全国天气网. 当前时间:2026-07-02周四18:33. ### 空气质量. ### 主要污染物. ### 明日天气信息. ### 最差空气质量排行榜. 天气炎热,建议着短衫、短裙、短裤、薄型T恤衫等清凉夏季服装。. 紫外线辐射极强,建议涂擦SPF20以上、PA++的防晒护肤品,尽量避免暴露... 天气较好,但气温很高,风力较大,请减少运动时间并降低运动强度,户外运动须注... 限行时间:7:00-19:00(工作日)。限行范围:外环线(不含)以内道路...",
"score": 0.6320719,
"raw_content": null
}
],
"response_time": 1.46,
"request_id": "beb09102-8c24-48d5-a7a4-8c7eafbbbfc8"
}
结合智能体
# 使用tavily作为web搜索工具
from langchain.agents import create_agent
from langchain_tavily import TavilySearch
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage
tool = TavilySearch(
tavily_api_key="xxxxxxxxxxxxxxxxxxxxxx",
max_results=5,
topic="general"
)
model = init_chat_model(model="deepseek-chat",
api_key="xxxxxxxxxxxxxxxxxxxxxxxx")
# 创建智能体
agent = create_agent(
model = model,
tools=[tool]
)
response = agent.invoke({
'messages': [HumanMessage("天津今天天气如何?")]
})
for message in response['messages']:
message.pretty_print()
================================ Human Message =================================
天津今天天气如何?
================================== Ai Message ==================================
好的,我来帮你查询天津今天的天气情况。
Tool Calls:
tavily_search (call_00_MdiHoODpLexcORHUBRKD9643)
Call ID: call_00_MdiHoODpLexcORHUBRKD9643
Args:
query: 天津今天天气 2025年7月
search_depth: basic
topic: general
================================= Tool Message =================================
Name: tavily_search
{'error': SSLError(MaxRetryError("HTTPSConnectionPool(host='api.tavily.com', port=443): Max retries exceeded with url: /search (Caused by SSLError(SSLEOFError(8, '[SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1032)')))"))}
================================== Ai Message ==================================
Tool Calls:
tavily_search (call_00_xrctAp5epiihKbzS9hK21022)
Call ID: call_00_xrctAp5epiihKbzS9hK21022
Args:
query: 天津天气预报 今天
search_depth: basic
topic: general
================================= Tool Message =================================
Name: tavily_search
{"query": "天津天气预报 今天", "follow_up_questions": null, "answer": null, "images": [], "results": [{"url": "https://m.weather.com.cn/mweather/101030100.shtml", "title": "天津天气预报7天、15天、40天天查询", "content": "今天. 6/26. 周六. 6/27. 周日. 6/28 ; 多云, 晴, 阴 ; 35° 35° 34° 27° 31° 32° 30° 27° 32° 33° 31° 33° 35° 26° 28° ; 24° 25° 22° 21° 23° 23° 22° 22° 23° 21° 25° 25°", "score": 0.82048416, "raw_content": null}, {"url": "https://www.weather.com.cn/weather/101030100.shtml", "title": "天津天气预报,天津7天天气预报,天津15天天气预报,天津天气查询", "content": "首页 预报 预警 雷达 云图 天气地图 专业产品 资讯 视频 节气. 台风路径 空间天气 图片 专题 环境 旅游 碳中和 气象科普 一带一路 产创平台. : 北京 上海 成都 杭州 南京 天津 深圳 重庆 西安 广州 青岛 武汉. : 故宫 阳朔漓江 龙门石窟 野三坡 颐和园 九寨沟 东方明珠 凤凰古城 秦始皇陵 桃花源. : 佘山 春城湖畔 华彬庄园 观澜湖 依必朗 旭宝 博鳌 玉龙雪山 番禺南沙 东方明珠. : 曼谷 东京 首尔 吉隆坡 新加坡 巴黎 罗马 伦敦 雅典 柏林 纽约 温哥华 墨西哥城 哈瓦那 圣何塞 巴西利亚 布宜诺斯艾利斯 圣地亚哥 利马 基多 悉尼 墨尔本 惠灵顿 奥克兰 苏瓦 开罗 内罗毕 开普敦 维多利亚 拉巴特. : 山洪灾害气象预警:浙江江西局部地区发生山洪灾害可能性较大 中国天气网 2026-07-01 18:05. : 暴雨蓝色预警:11省区市部分地区有大到暴雨 江西浙江局地大暴雨 中国天气网 2026-07-01 18:05. : 台风蓝色预警:南海热带低压将于3日登陆海南至广东一带沿海 中国天气网 2026-07-01 18:05. : 地质灾害气象风险预警:浙江安徽等7省市部分地区风险较高 中国天气网 2026-07-01 17:30. : 破纪录!数据盘点6月南方下了多少雨 华南台风雨即将来袭 中国天气网 2026-07-01 17:01. # 周边地区 *|* 周边景点 *2026-07-01 18:00更新*. # 高清图集. 未来3天,云贵高原至江南中北部一带强降雨仍将持续,多地有暴雨、大暴雨,华北、东北的强对流天气也依然频繁。同时,未来三天我国多地热意增强。. 今天起,南方新一轮强降雨来袭,长江中下游一带以及贵州、广西、云南等地需警惕暴雨致灾,同时东北、华北一带仍将维持多雨格局。. 今天(6月27日),南方降降雨主要集中在华南和西南地区,雨势较前期有所减弱。明天起,南方主雨带东段将北抬至江南北部,需注意防范。. 今天(6月27日),南方降雨将减弱,华南等地部分地区有大到暴雨。明后天,南方主雨带将北抬。在北方,华北、东北等地未来三天多雷雨天气出没。. 今天(6月24日),南方主雨带的东段将继续减弱并南落,但西段的广西、贵州、云南交界一带仍将有暴雨或大暴雨。. 今明两天(6月23日至24日),长江中下游一带仍有强降雨,降水强度呈减弱趋势。24日后,南方的降雨将南压至贵州、广西北部到江南中南部一带,强度继续减弱。. 今起三天(6月22日至24日),我国主雨带仍将集中在长江沿线,公众需关注预警预报信息。同时,江南南部、华南等地炎热天气持续,将现成片高温。. 今明两天,长江中下游一带的降雨会再度增强;同时,东北地区的降雨也仍将持续。而在华南和江南南部一带,明天起会迎来成片的高温天气。. 端午假期后两天,南方大部和东北地区降雨仍然较多,其中长江中下游明天雨势较强。此外,今天起江南南部和华南一带的高温闷热天气将快速发展。. 端午节假期期间,长江中下游一带多地雨势强劲,同时东北、华北、黄淮的降雨或强对流天气也将较为频繁。此外,未来七天南北多地气温将有所下滑。. 今天(6月18日)开始,随着副热带高压北抬,南方强降雨的重心将从华南一带逐渐向江南、长江中下游转移。与此同时,在阴雨天气的压制下,上述地区气温将有所下滑,炎热褪去。. 今天(6月17日),华南一带仍有强降雨,明天起南方主雨带将北抬至长江中下游等地,华南多地高温闷热天气逐渐发展。. * 三亚 多云转雷阵雨 26/35℃ 适宜. * 九寨沟 阵雨 16/26℃ 适宜. * 大理 小雨转中雨 16/21℃ 适宜. * 张家界 小雨 20/26℃ 适宜. * 青岛 多云 22/25℃ 适宜. 中国天气网版权所有,未经书面授权禁止使用 Copyright©中国气象局公共气象服务中心 All Rights Reserved (2008-2026).", "score": 0.77893573, "raw_content": null}, {"url": "https://weather.cma.cn/web/weather/54517.html", "title": "天津市 - 天气预报", "content": "| 气温 | 28.2℃ | 28.8℃ | 25.3℃ | 25.2℃ | 25.1℃ | 21.3℃ | 21.2℃ | 21.3℃ |. | 降水 | 7.1mm | 1.5mm | 1.8mm | 无降水 | 1.1mm | 10.6mm | 无降水 | 无降水 |. | 风向 | 东南风 | 东南风 | 东北风 | 西北风 | 西北风 | 东南风 | 东北风 | 东北风 |. | 云量 | 70% | 70% | 70% | 0% | 82.2% | 83% | 65.6% | 1.8% |. | 降水 | 无降水 | 无降水 | 无降水 | 无降水 | 无降水 | 无降水 | 无降水 | 无降水 |. | 降水 | 无降水 | 2.3mm | 2.3mm | 2.3mm | 2.3mm | 无降水 | 无降水 | 无降水 |. | 风向 | 东南风 | 西南风 | 西南风 | 西南风 | 西南风 | 西南风 | 西南风 | 西南风 |. | 风向 | 西南风 | 西南风 | 西南风 | 西北风 | 西北风 | 西北风 | 西南风 | 西北风 |.", "score": 0.7750779, "raw_content": null}, {"url": "https://www.ventusky.com/zh-tw/tianjin", "title": "天氣- 天津市- 14天預報:氣溫、風和雷達 - Ventusky", "content": "| 高雲 29 °C 0 mm 0 % 東南 10 km/h | 高雲 26 °C 0 mm 0 % 東南 10 km/h | 高雲 25 °C 0 mm 0 % 東南 8 km/h | 晴朗的天空 25 °C 0 mm 0 % 東南 8 km/h | 晴朗的天空,幾朵雲 24 °C 0 mm 0 % 東南 8 km/h | 晴朗的天空,幾朵雲 24 °C 0 mm 0 % 東南 6 km/h | 晴朗的天空 24 °C 0 mm 0 % 東南 6 km/h | 晴朗的天空 24 °C 0 mm 0 % 南 5 km/h | 晴朗的天空 24 °C 0 mm 0 % 南 5 km/h | 晴朗的天空,幾朵雲 24 °C 0 mm 0 % 南 5 km/h | 晴朗的天空,幾朵雲 24 °C 0 mm 0 % 南 5 km/h | 晴朗的天空,幾朵雲 24 °C 0 mm 0 % 南 5 km/h | 晴朗的天空,幾朵雲 26 °C 0 mm 0 % 南 5 km/h | 晴朗的天空 27 °C 0 mm 0 % 南 5 km/h | 晴朗的天空 29 °C 0 mm 0 % 西南 6 km/h | 多雲 31 °C 0 mm 0 % 西南 7 km/h | 多雲 33 °C 0 mm 10 % 西南 10 km/h | 多雲 34 °C 0 mm 0 % 西南 10 km/h | 多雲 35 °C 0 mm 0 % 西南 11 km/h | 晴朗的天空,幾朵雲 36 °C 0 mm 0 % 西南 10 km/h | 晴朗的天空,幾朵雲 36 °C 0 mm 0 % 西南 12 km/h | 多雲 36 °C 0 mm 0 % 南 11 km/h | 大部分多雲 36 °C 0 mm 10 % 南 11 km/h | 多雲 35 °C 0 mm 10 % 南 9 km/h | 多雲 33 °C 0 mm 10 % 東南 11 km/h |.", "score": 0.7636429, "raw_content": null}, {"url": "https://www.accuweather.com/zh/cn/tianjin/106780/weather-forecast/106780", "title": "天津, 天津市, 中國三日天氣預報", "content": "# 天津, 天津市. 今天 WinterCast 當地{stormName}追蹤 每小時 十天賽 雷達 MinuteCast® 月刊 空氣品質 健康與活動. ### 颶風 ### 惡劣天氣 ### 雷達與氣象圖 ### 視訊. ## 今天 每小時 十天賽 雷達 MinuteCast® 每月 空氣品質 健康與活動. ## 天津 氣象雷達圖. Thank you for your patience as we work to get everything up and running again. ## 每小時預測. rain drop 34% 下午9时 25°. ## 太陽和月亮. ## 空氣品質. ## 過敏展望. 世界 亞洲 中國 天津市 天津. ## 附近地方:. © 2026 AccuWeather, Inc. 版權所有。「AccuWeather」和太陽商標設計是 AccuWeather, Inc. 的註冊商標。保留所有權利。. 使用條款 | 隱私權政策 | Cookie 政策 | 資料來源.", "score": 0.75181264, "raw_content": null}], "response_time": 1.91, "request_id": "f7fc65fe-2459-459c-bc30-0e334e98f192"}
================================== Ai Message ==================================
根据搜索结果,我为你整理了天津今天的天气情况:
**天津今日天气概览(截至2026年7月1日):**
- **天气状况:** 多云 / 高云 🌤️
- **气温:** 目前气温约 **28°C**,今天最高气温约 **29°C**,最低气温约 **24°C**
- **风力:** 东南风,风力约 **10 km/h**,风力较小
- **降水:** **无降水**,降雨概率较低
- **湿度/云量:** 云量约70%
总体来看,今天天津天气以多云为主,气温舒适,没有降雨,适合外出活动。不过由于是夏季,建议出行时注意防暑和防晒哦!😊
优化
LangChain提供的TavilySearch工具描述非常复杂,参数也很多。会有额外的网络消耗。如果我们仅仅是需要query参数,建议自定义工具。
from pydantic import BaseModel, Field
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage
from langchain_tavily import TavilySearch
# =========================
# 初始化模型
# =========================
model = init_chat_model(
model="deepseek-chat",
model_provider="openai", # 如果是 DeepSeek 官方 API
base_url="https://api.deepseek.com/v1",
api_key="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
)
# =========================
# Tavily 搜索工具
# =========================
web_search = TavilySearch(
tavily_api_key="xxxxxxxxxxxxxxxxxxxxxxxxxx",
max_results=5,
topic="general",
)
# =========================
# 定义结构化输出
# =========================
class Reference(BaseModel):
title: str = Field(description="引用网页标题")
url: str = Field(description="引用网页URL")
class AnswerInfo(BaseModel):
answer: str = Field(description="最终回答")
reference: list[Reference] = Field(description="引用网页列表")
# =========================
# 创建 Agent
# =========================
agent = create_agent(
model=model,
tools=[web_search],
system_prompt="你是一个智能助手,可以使用 Tavily 搜索互联网。",
response_format=AnswerInfo,
)
# =========================
# 调用
# =========================
response = agent.invoke(
{
"messages": [
HumanMessage(content="介绍一下 LangChain,并给出参考资料")
]
}
)
# =========================
# 输出结构化结果
# =========================
result: AnswerInfo = response["structured_response"]
print(result.answer)
print("\n参考资料:")
for ref in result.reference:
print(ref.title)
print(ref.url)
预定义工具(如 TavilySearch)不需要,也不能再加 @tool
记忆
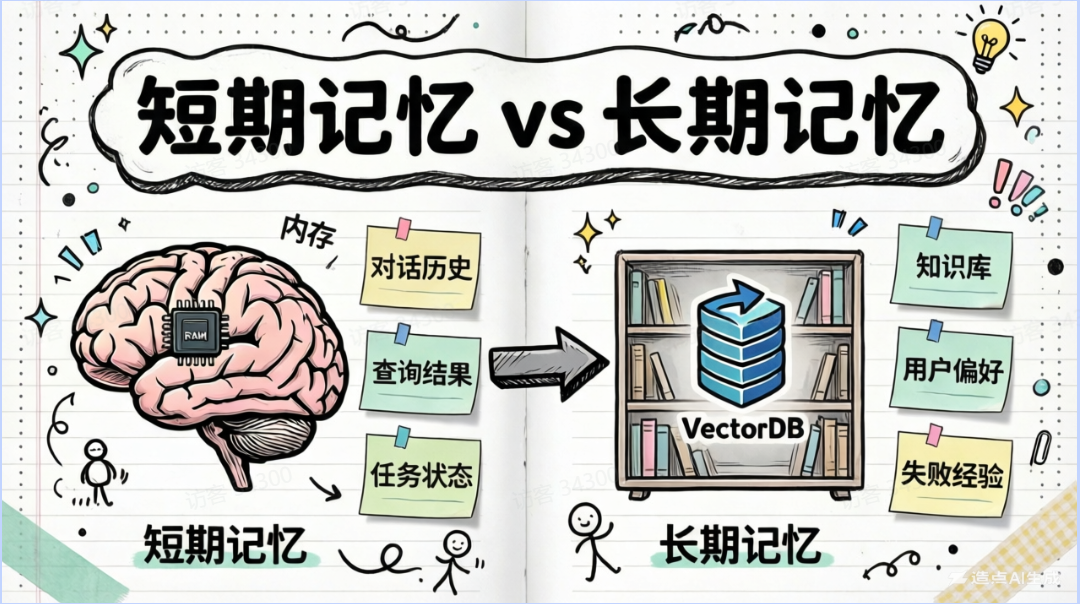
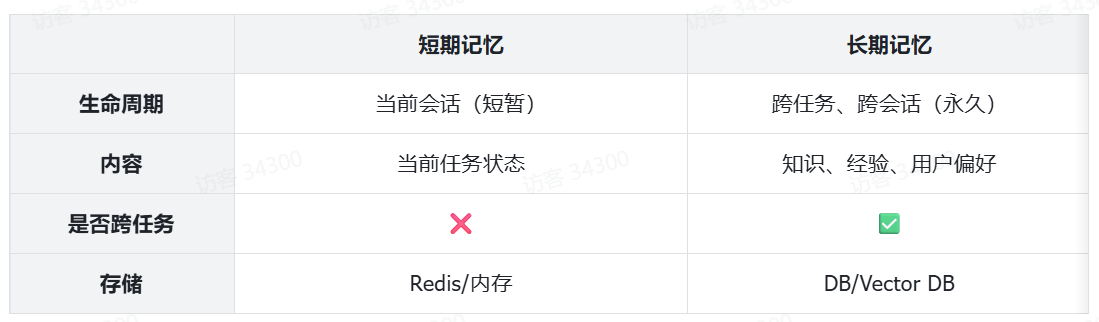
对于智能体而言,记忆分为了两类:
- 短期记忆(short-term memory)
- 长期记忆(long-term memory)
短期记忆:当前任务或会话的上下文(Working Memory 或 Session Memory)
长期记忆:跨任务或会话的经验与知识(Persistent Memory)
短期记忆
由于短期记忆通常生命周期是当前会话,所以我们也可以称为会话记忆。Agent的会话记忆通常包含三部分:
- 对话历史
- 查询结果
- 任务状态
LangChain提供了自动化的记忆管理方案:
- 首先,LangChain把会话记忆(也就是Messages列表)记录为AgentState的一部分
- AgentState通过Checkpointer对象来保存,每一次与AI的交互都会生成一个快照,记录为一个checkpoint,把同一会话的所有checkpoint组合在一起,就是完整的会话历史了。
- 为了区分不同的会话记忆,不同会话需要设定各自的thread_id,相同会话则使用相同thread_id
- 向Agent发起会话时必须指定自己的thread_id以唤起对应的会话记忆
InMemorySaver
导入CheckPointer的内存版实现:
# langchain提供的checkpointer的默认实现,基于内存存储
from langgraph.checkpoint.memory import InMemorySaver
创建智能体,设置checkpointer:
agent = create_agent(
model=model,
checkpointer=InMemorySaver(),
)
发起调用时,指定thread_id
第一次调用,告知AI一些信息
#设定thread_id,作为会话标识
config = {"configurable": {'thread_id': 'thread_1'}}
response = agent.invoke({
"messages": [HumanMessage(content="12个苹果两个人怎么分")]
},
config=config
)
print(response['messages'][-1].content)

第二次调用
response = agent.invoke({
"messages": [HumanMessage(content="3个人呢?")]
},
config=config
)
print(response['messages'][-1].content)

持久化Memory
LangChain也提供了很多持久化存储的checkpointer,例如:
- SqlLiteSaver :基于sqlite存储
- PostgresSaver :基于Postgres存储
- CosmosDBSaver :使用Azure Cosmos DB的实现
以SqlLiteSaver 来如何自定义Memory存储方案
安装对应依赖
pip install langgraph-checkpoint-postgres
导入依赖,并初始化sqlite-checkpointer
import sqlite3
from langgraph.checkpoint.sqlite import SqliteSaver
# 初始化checkpointer
checkpointer = SqliteSaver(sqlite3.connect("checkpoint.db", check_same_thread=False))
# 自动建表
checkpointer.setup()
最后,创建Agent,并设置checkpointer:
# 创建agent
agent = create_agent(
"deepseek-chat",
checkpointer=checkpointer,
)
记忆管理策略
由于会话记忆要保存会话的历史,并且在调用LLM时携带历史消息列表。而当会话越来越长时,历史消息就可能超过LLM的上下文限制。例如,DeepSeek的上下文不能超过128K.
一旦会话历史超过上下文窗口,就会出现上下文丢失的情况,从而导致丢失记忆。而且即便不丢失,太长的上下文容易让模型出现“注意力分散”问题,模型的响应速度、回答质量会大大降低。
解决这一问题,通常有以下几种手段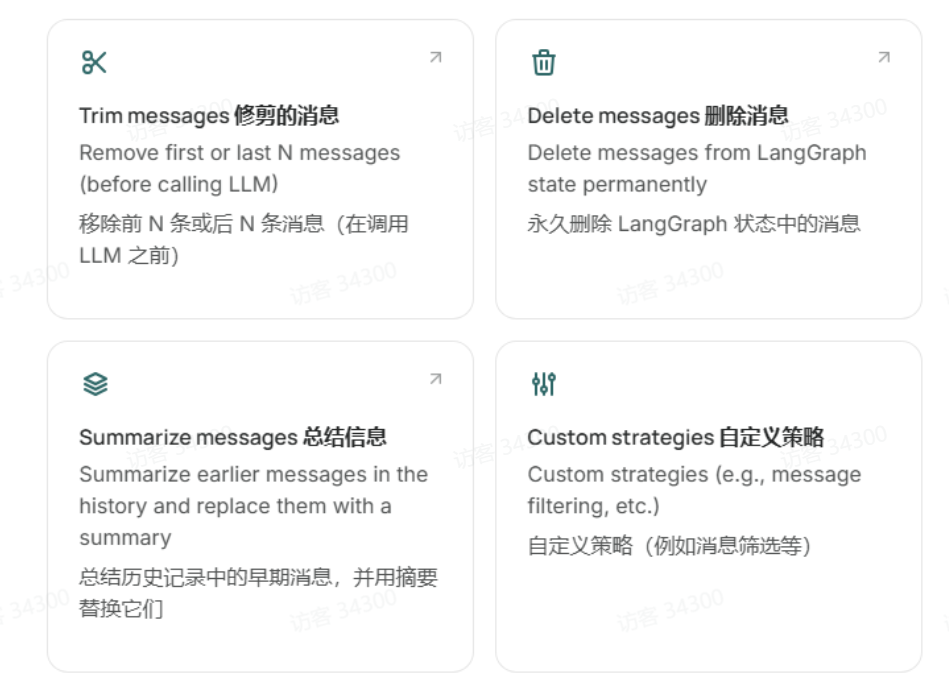
修剪消息
修剪消息并不是真正的删除消息,在AgentState中的消息列表依然是完整的,只不过发送给LLM之前会进行修剪,只保留一部分消息。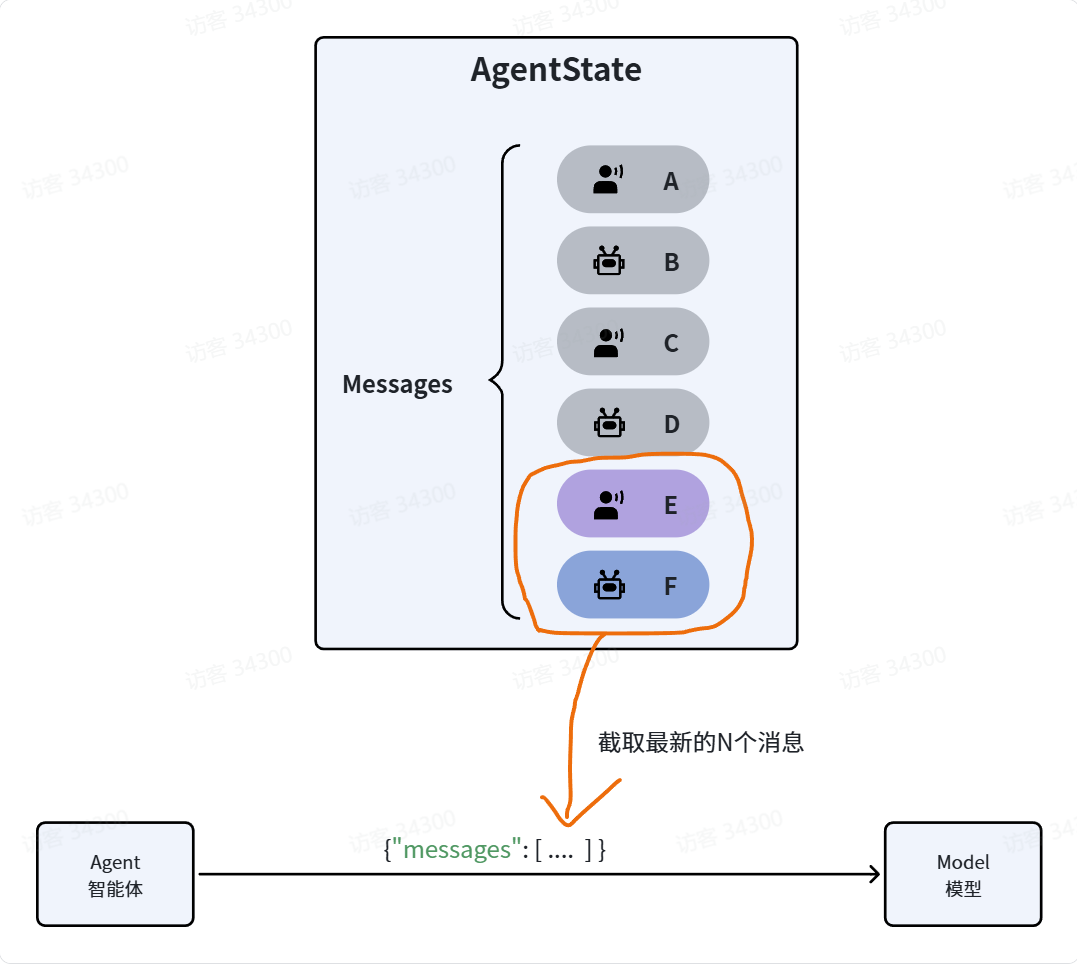
删除消息
删除消息与修剪不同:
- 修剪消息:只是从State中选取一部分消息发送给模型
- 删除消息:直接删除State中保存的消息,也就是说消息历史中不再存在!
总结消息
不管是修剪还是删除,都会导致一部分消息丢失,从而丢失记忆。所以就有了第三种策略:总结消息(Summarize Messages)
它的思路很简单,就是把历史的消息利用大模型总结出摘要,然后把最新的消息拼接在一起作为新的消息列表发送给大模型,这样既不会超出模型的上下文窗口限制,还能尽量保留所有的记忆。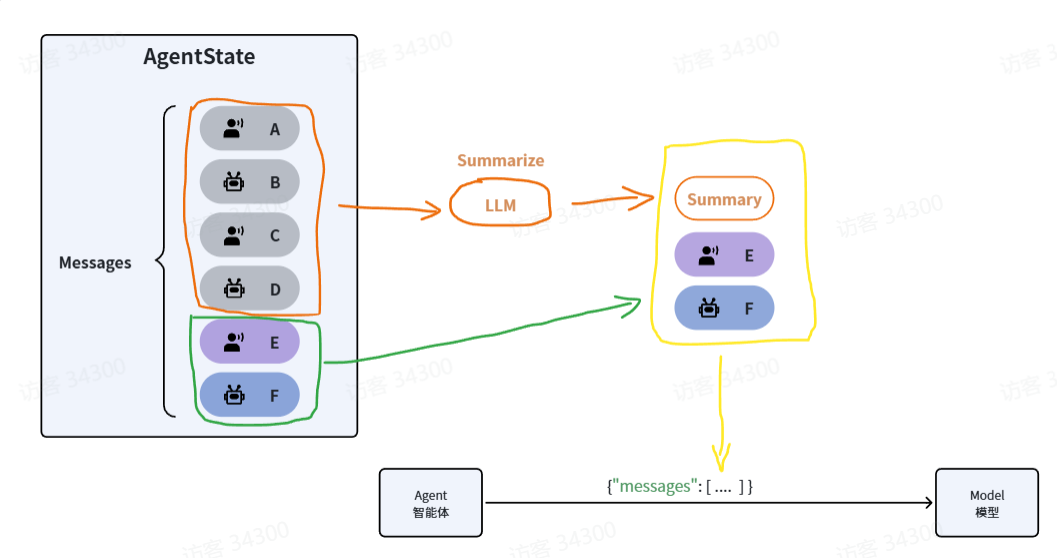
LangChain提供了总结消息的默认实现:SummarizationMiddleware
- 初始化SummarizationMiddleware和checkpointer
rom langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
# 初始化checkpointer
checkpointer = InMemorySaver()
# 初始化中间件
middleware = SummarizationMiddleware(
model="deepseek-chat",
trigger=("messages", 3), # 触发时机,当消息数超过3时,进行总结
keep=("messages", 1) # 保留的会话数,超过2条
)
SummarizationMiddleware的参数(详细内容参考官网链接:summarization):
- model:会话摘要时要使用的模型
- trigger:会话摘要的触发时机,有三种设置:
- fraction (float): 模型上下文大小的比例(0-1)
- tokens (int): 令牌数量
- messages (int): 消息数量
- keep:是指触发摘要后要保留的消息
- fraction (float): 要保留的消息占模型上下文大小的比例(0-1)
- tokens (int): 要保留的消息的令牌数量
- messages (int): 要保留的消息数量
- 创建Agent,设置middleware和checkpointer
# 创建agent
agent = create_agent(
model="deepseek-chat",
middleware=[middleware],
checkpointer=checkpointer,
)
- 调用Agent即可
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
# 自定义测试对话
agent.invoke({"messages": "你好,我是小明,我喜欢编程。"}, config)
agent.invoke({"messages": "我最近在学习Python爬虫。"}, config)
agent.invoke({"messages": "Python的requests库怎么用?"}, config)
final_response = agent.invoke({"messages": "我的名字是什么?我喜欢什么?"}, config)
for message in final_response["messages"]:
message.pretty_print()
================================ Human Message =================================
Here is a summary of the conversation to date:
## SESSION INTENT
用户小明正在学习Python爬虫,具体询问了requests库的使用方法。会话目标是为小明提供requests库的系统讲解,帮助他掌握发送HTTP请求的基础技能。
## SUMMARY
- 用户小明询问"Python的requests库怎么用?"
- 助手提供了requests库的完整讲解,涵盖以下内容:
1. 安装方法(pip install requests)
2. GET请求基础用法(requests.get获取网页内容)
3. 带参数的GET请求(使用params参数传递查询参数)
4. POST请求用法(用于登录、提交表单)
5. 设置请求头伪装浏览器(User-Agent、Referer、Cookie等)
6. Cookie处理(手动设置Cookie vs 使用Session自动管理)
7. 响应内容处理(.text、.json()、.status_code、.headers、.encoding、.content)
8. 超时与异常处理(timeout参数、try-except捕获Timeout/ConnectionError)
- 提供了实战小例子:用requests获取豆瓣电影Top250第一页并保存到本地HTML文件
- 建议了下一步学习方向:
- 尝试爬取其他网站
- 解决403/反爬问题
- 学习BeautifulSoup解析数据
- 学习Selenium处理动态页面
- 助手正在等待小明提供进一步反馈:是否动手尝试、遇到什么具体问题、或想学习其他功能
## ARTIFACTS
None(未创建或修改任何文件)
## NEXT STEPS
- 等待小明回应:是否尝试了requests代码、遇到了什么问题、需要哪些进一步指导
- 根据小明反馈,针对性地解决具体爬虫问题,或进入下一主题(BeautifulSoup解析、反爬处理、Selenium等)
================================ Human Message =================================
我的名字是什么?我喜欢什么?
================================== Ai Message ==================================
根据我们的对话记录,您最初提到自己的名字是**小明**,并且正在学习**Python爬虫**,特别是想了解`requests`库的使用方法。目前对话中没有提及您其他具体的喜好(如兴趣爱好、音乐、运动等),所以除了知道您对Python爬虫技术有学习兴趣外,没有更多关于个人爱好的信息。
如果您愿意分享更多关于自己的信息或者想讨论其他话题,我很乐意继续为您提供帮助! 😊
总结
通过最后的完整示例,我们将这些知识点有机串联,构建了一个具备联网搜索、结构化输出、会话记忆和自动总结能力的智能体,展示了LangChain在实际项目中的强大生产力。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)