VLA-Adapter论文解读(五):实验分析
论文链接:[2509.09372] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
项目主页:VLA-Adapter
前言:本文拆解了VLA-Adapter实验的研究方法论和架构设计,覆盖了模拟基准测试、消融实验、真实机器人部署三大维度,对比了20+个基线模型。
一、实验总览
论文的研究实验均在4块NVIDIA H100 GPU上运行。首先使用了长时域的LIBERO-Long,该任务通常成功率较低,用于探究VLA-Adapter的研究必要性。其次,采用了VLA领域广泛使用的LIBERO和CALVIN以及真实世界机器人数据,全面比较性能。最后利用LIBERO-Long探索VLA-Adapter的关键组成部分。
VLA-Adapter的实验体系概括为“三层金字塔”:
- 第一层:模拟基准测试——与20+baseline横向对比,验证性能;
- 第二层:消融实验——验证每个设计决策的必要性;
- 第三层:真实机器人部署——验证从仿真到现实的迁移能力。
二、VLA-Adapter的必要性
为了验证VLA-Adapter桥接范式的必要性,论文比较了三种骨干网络:基于Qwen2.5-0.5B训练的Prismatic VLM(B1)、基于LLaMA2-7B训练的Prismatic VLM(B2)以及机器人数据上预训练的OpenVLA-7B(B3)。本文采用了OpenVLA-OFT桥接范式进行了比较,该方法是目前VLA测试的SOTA模型。结果显示,B1条件下OFT与Adapter模型的success Rate分别是85.8%,95.0%;B2条件下success Rate87.5%,95.2%;B3条件下94.5%,95.4%。
并且在主干网络被冻结的情况下,VLA-Adapter依然有效,只有AQ和Policy是从头训练;SmolVLA专门用于研究冻结视觉语言模型(VLM)的VLA,论文将其与OpenVLA-OFT和SmolVLA进行比较得到:OpenVLA-OFT——0.0%,SmolVLA——77.0%,VLA-Adapter——86.4%。
因此,即使在没有机器人预训练的VLMs上,VLA-Adapter性能的改进效果也十分明显,即使是骨干网络冻结的情况下,VLA-Adapter仍然能保持强劲性能。其主要原因在于常规的VLA在机器人数据上预训练之后,最后一层的特征已经适应了动作域,从而能够通过简单的MLP实现高效微调。当没有经过预训练的VLM仅依赖最后一层的潜在特征时,不足以实现有效的动作映射。因此验证了VLA-Adapter可以在没有机器人预训练的情况下高效微调VLM,使用极小的骨干网络即可达到超越SOTA的性能。
三、基准测试
| 基准 | 全称 | 任务数量 | 特点 | 意义 |
| LIBERO-Spatial | 空间布局变化 | 10 | 物体位置变化 | 测试空间泛化能力 |
| LIBERO-Object | 物体类型变化 | 10 | 不同物体实例 | 测试物体泛化能力 |
| LIBERO-Goal | 目标变化 | 10 | 不同目标位置 | 测试目标泛化能力 |
| LIBERO-Long | 长时程任务 | 10 | 多步骤组合 | 测试长期规划能力 |
| CALVIN ABC → D | 跨环境泛化 | 1000条指令链 | 训练在A/B/C,测试在D | 测试零样本泛化能力 |
论文选择了几种大模型、小模型以及微型模型进行baseline的实验对比,LIBERO实验中子任务重复50×次进行评估,成功率的数值范围越高越好。结果如下表所示:
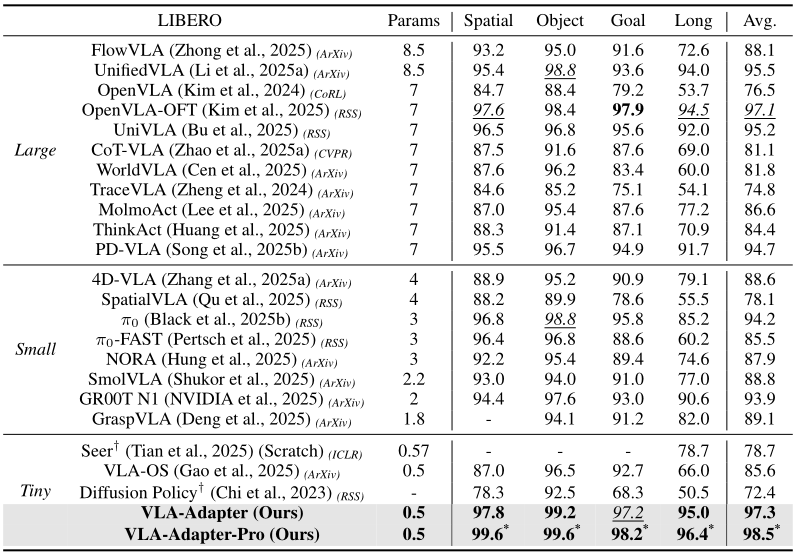
实验结果验证,VLA-Adapter仅使用极小规模的主干网络,即可达到与规模大14×倍的OpenVLA-OFT相当的性能。并且在LIBERO-Long任务上,VLA-Adapter相比同规模主干网络的VLA-OS具有29.0%的显著优势。
其次使用CALVIN ABC → D用于评估零样本泛化任务的性能。CALVIN包含了四种环境,ABC → D表示环境在A、B和C上训练,在环境D上评估。VLA需要按顺序执行预设的1000个任务序列,每个任务行由五个子任务组成(例如一条指令链“拿起红色方块→放到托盘上→拿起蓝色方块→放到红色方块上→推动托盘”),模型只有在完成当前子任务后才能进入下一个子任务。baseline实验结果如下表所示:
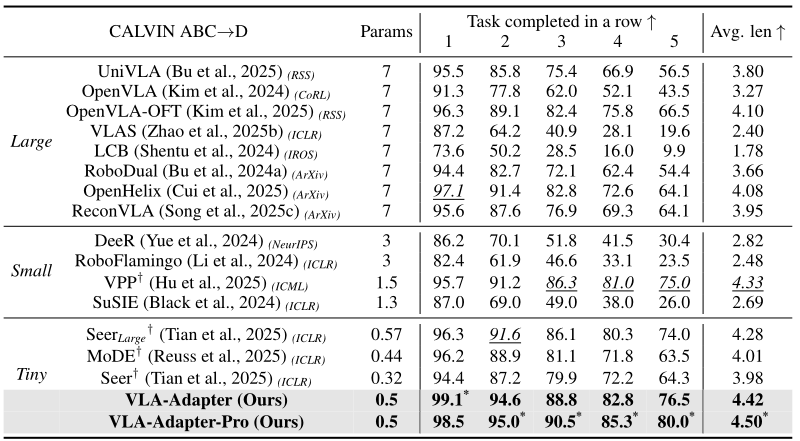
指标解读:
“Task completed in a row”:
| 列名 | 含义 | 实例 |
| 1 | 完成至少1个子任务的比例 | 98.5%的测试中完成了第1步 |
| 2 | 完成至少2个子任务的比例 | 95.5%的测试中完成了第2步 |
| 3 | 完成至少3个子任务的比例 | 90.5%的测试中完成了第3步 |
| 4 | 完成至少4个子任务的比例 | 85.3%的测试中完成了第4步 |
| 5 | 完成至少5个子任务的比例 | 80.0%的测试中完成了第5步 |
Avg.len(平均长度)
(完成至少k步)
该公式主要衡量的是模型平均能连续完成多少个子任务。该指标比单步成功率更加严格,因为模型的每一步都不能出错。例如:Avg.len=4.5,平均能完成4.5个子任务(约90%的指令链能走完)。
CALVIN属于快换精品测试,证明了模型不是过拟合特定场景,并且5步的连续任务要求模型具备一定的哦长期规划能力,而非走一步看一步,最后0.5B参数模型性能高于7B的SOTA,验证了“桥接设计优于单纯扩大规模”的结论。
四、消融实验
论文总共做了三组消融实验,分别对应架构中的三个核心设计:
| 消融实验 | 探索问题 | 对应内容 |
| 1 | 多少个Query token最优? | ActionQuery数量 |
| 2 | Raw+AQ是否优于只用一种? | 条件类型 |
| 3 | 不对称门控是否最优? | 门控策略 |
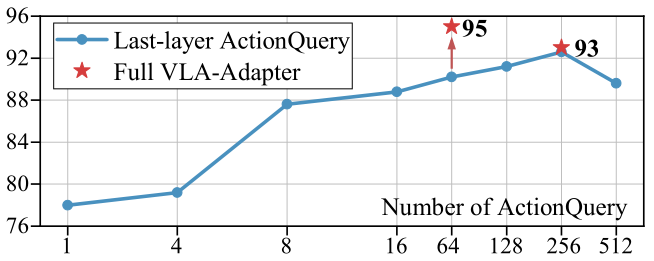
ActionQuery属于插入VLM输入序列末尾中的可学习token,数量是一个关键超参数。论文作者测试了1,4,8,16,64,128,256,512共8种配置,在LIBERO-Long基准上评估。实验结果如下所示,在8种配置当中,LIBERO-Long的成功率分别为:~68%,~74%,~78%,~84%,95.0%(最优),~93%,91%以及~88%。因此可以得出结论:当AQ token的数量<16时,因为Query太少,无法充分聚合多模态信息,表达能力不足(性能差);当AQ token数量=64时,信息容量与计算效率达到最佳平衡点(性能最优);当AQ token数量>128时,Query过多引入冗余信息,干扰注意力机制,同时增加计算开销。
论文对比了四种“VL→A桥接”范式,验证Raw特征+AQ特征联合使用的必要性。
| 方法 | 使用的特征 | 层级 | 对应范式 | 代表性工作 |
| 1 | 仅Raw | 最后一层 | 原始特征直传 | RoboVLM |
| 2 | 仅AQ | 最后一层 | Query接口 | OpenVLA-OFT |
| 3 | 仅Raw | 中间层 | 原始特征直传 | GROOT N1 |
| 4 | 仅Raw | 全层 | 原始特征直传 | π0 |
| 5 | 仅AQ | 全层 | Query接口 | N/A |
| 6 | Raw+AQ | 全层 | 联合使用 | VLA-Adapter |
实验结果的成功率分别是:85.8%,90.2%,88.4%,90.6%,92.6%以及95.0%。由此可见,全层Raw>最后一层Raw,全层AQ>全层Raw,AQ略优但差距不大,因此联合使用>单独使用,验证两类特征互补。
Bridege Attention中,Raw特征通过可学习门控tanh(g)注入,AQ特征完全注入(无门控),因此作者测试了四种门控组合:
| 配置 | Raw特征注入 | AQ特征注入 | 设计意图 |
| 1(Adapter) | tanh(g) | 1(无门控) | 不对称,Raw可信度低→门控,AQ完全可信→无门控 |
| 2 | 1(无门控) | 1(无门控) | 完全信任 |
| 3 | tanh(g) | tanh(g) | 同时限制Raw和AQ |
| 4 | 1(无门控) | tanh(g) | 不对称:信任Raw,限制AQ |
实验结果表明,四种门控组合的LIBERO-Long成功率分别为:91.4%,91.0%,92.6%以及95.0%。根据结果可知,在都无门控的情况下,Raw特征来自预训练VLM,分布与动作空间差异大,初期注入会严重干扰动作生成,训练不稳定。
五、真机部署
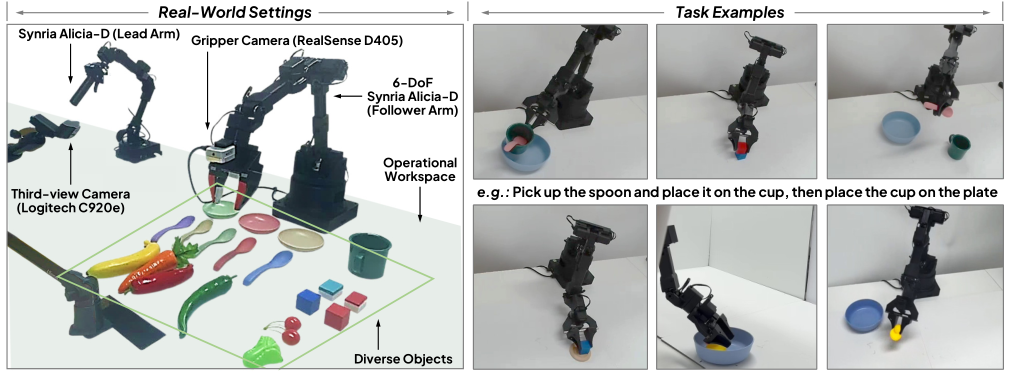
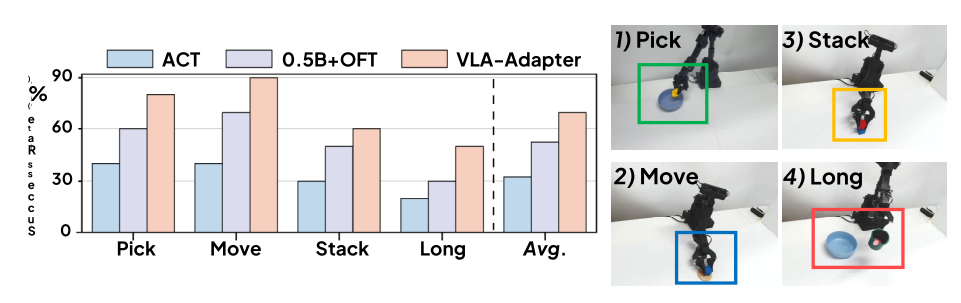
论文使用了机器人系统执行了真实世界任务。采用了配备1自由度夹爪的6自由度SynriaAlicia-D机器人,并使用Logitech C920e和RealSense D405摄像头采集第三视角图像和夹爪图像。真实机器人系统如图所示。在四个实验类别中评估VLA-Adapter方法:
1). 简单的拾取与放置任务,涉及各种材质和几何结构的物体;
2). 以卡尔文为灵感来源的具有挑战性的任务 II:横向块体位置调整;
3). 以卡尔文为灵感来源的具有挑战性的操纵任务I:“积木堆叠”;
4). LIBERO启发式复杂任务与长期目标:(例如:“拿起勺子并将其放置于...”)
为了加强评估严谨性并评估泛化性能,本文在测试时随机化物体位置,以引发分布偏移并增加任务难度。
对比结果如下图所示,每个结果均为10次执行结果的平均值,实验结果表明,VLA-Adapter在各种场景下具有更好的泛化能力。因此,VLA-Adapter大大降低了在实际应用中采用VLA的门槛。
六、结论与总结
VLA-Adapter的三大消融实验系统性地验证了:64个ActionQuery最优、Raw+AQ联合使用优于单独使用、不对称门控(Raw带门控+AQ无门控)最优。并且每个设计决策都有实验数据支撑,而非凭空猜测。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)