PPO- BipedalWalkerHardcore-v3
前言
作为 Gym 中最硬核的机器人控制任务之一,BipedalWalkerHardcore-v3 对强化学习算法的鲁棒性提出了严峻考验。其训练曲线在后期呈现明显的高方差特性,这也使其成为剖析 PPO 参数细节与调试策略的理想案例。我们将以此为切入点,记录一次完整的调参与优化实战。
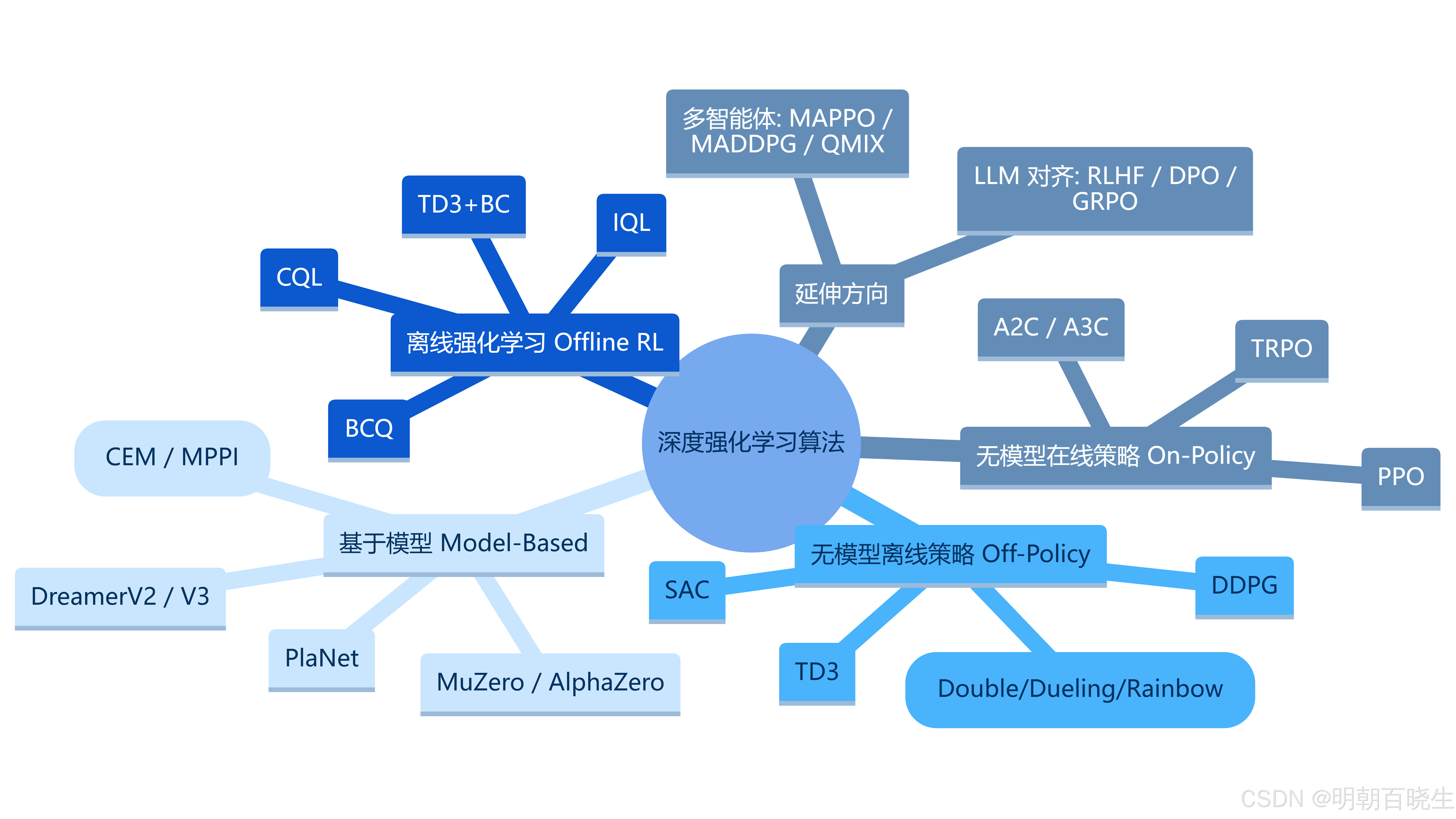
目录:
- on-policy vs off-policy
- importance sampling
- add constraint (TRPO 方案)
- add constraint (PPO 方案)
- 伪代码
- PPO-BipedalWalkerHardcore 例子
一 on-policy vs off-policy
On-policy:行为策略与目标策略一致。
Off-policy:行为策略与目标策略分离,目标策略多为贪心选最大Q值动作,行为策略可采用ε-贪婪、专家策略或历史旧策略,复用经验池数据。
标准策略梯度算法(如 REINFORCE 或 A2C)正是 On-policy 的典型代表。其目标函数的梯度为:
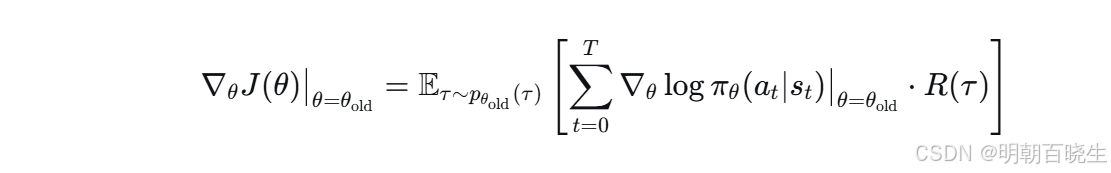
期望的下标 依赖于当前的优化变量
。一旦参数从
更新为
,采样分布立即从
变为
,这意味着此前采集的所有轨迹数据在数学上立刻过时,不再能用于表示新策略下的期望,因此每次更新后数据必须被丢弃并重新采样.
强化学习[chapter8] [page20 ]Policy Gradient-CSDN博客 例: 强化学习[chapter8] [page20 ]Policy Gradient-CSDN博客
错误作法:
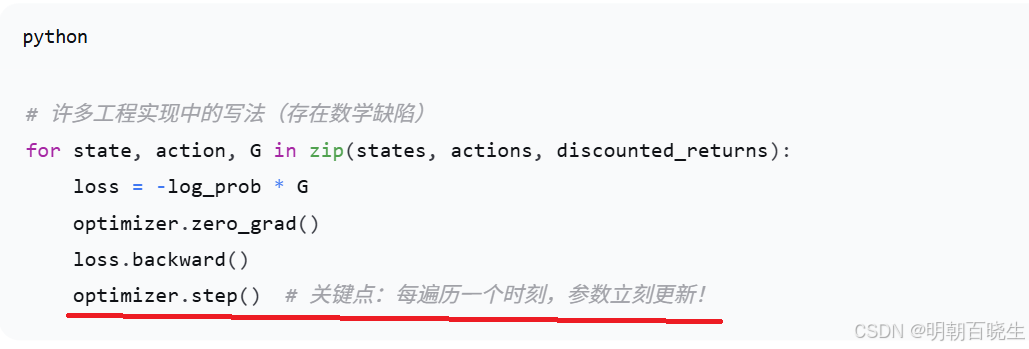
在 for循环内每遍历一个时刻就执行一次 optimizer.step()(即增量式更新):
那么处理 t=0 后参数已变为
紧接着处理 t=1 时,梯度
虽基于新参数,但权重
仍源于旧分布
,导致数学期望下标严重不匹配,梯度估计产生偏差。标准的正确做法必须在循环外部累计所有时刻的总损失,仅针对同一个固定的
执行一次梯度下降,以此来保证无偏性

正是由于 On-policy 这一“采样一次、更新一次、丢弃一次”的刚性约束,导致其样本利用率极为低下。若要打破这一瓶颈并复用历史数据,就必须转向 Off-policy 框架,并引入重要性采样 (Importance Sampling)技术,乘以似然比 来强行修正分布差异(这也是 PPO 等算法在两者间折中的核心动机).
二 Importance sampling
当我们无法从目标分布 p(x)中采样时,我们可以从另一个容易采样的分布 q(x) 中采样,并通过加权来修正期望偏差。
对于期望 ,我们有测度变换公式:
其中,权重 被称为重要性权重(Likelihood Ratio),定义为:
1 PPO应用: importance sampling
通过importance sampling 技术实现了off-policy 的强化学习

Off-policy 梯度更新以及目标函数
这里面有个假设各种状态的概率分布是差不多,符合均匀分布。

2 问题: 方差不一致,当两个分布差异过大的时候,会导致高方差
从新的分布q(x)采样会导致方差不一致,原理如下
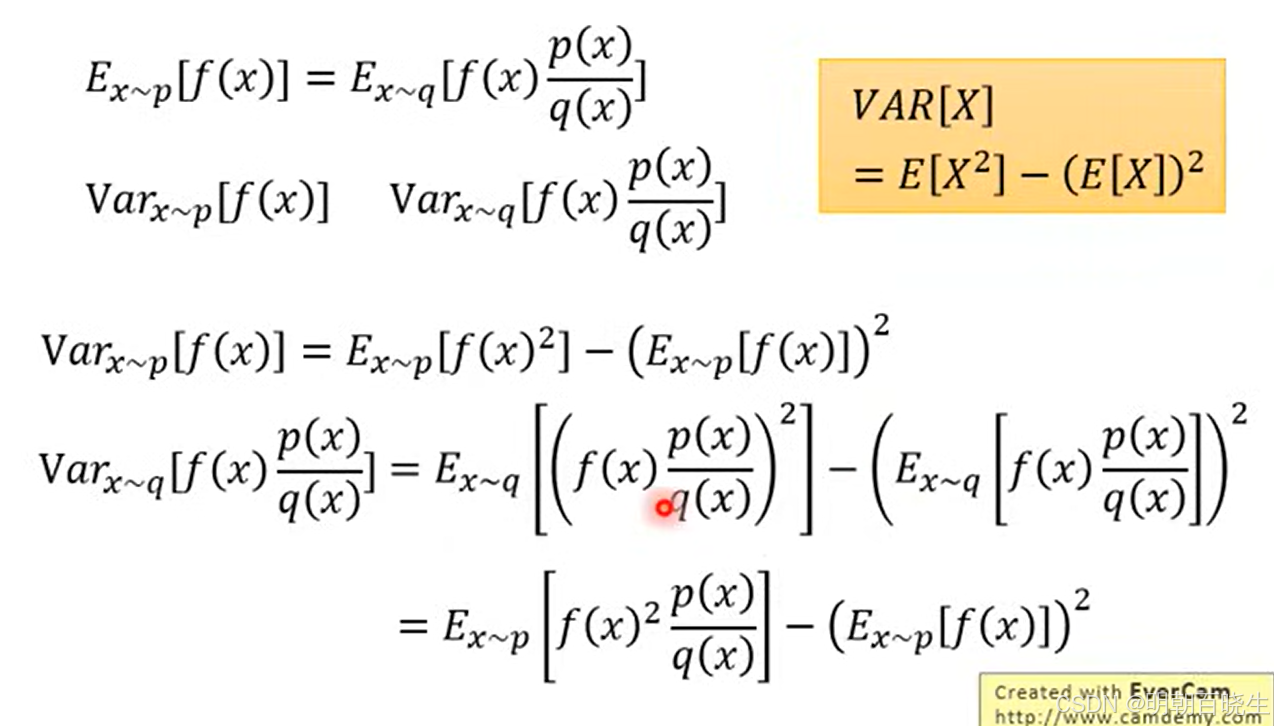
三 add constraint (TRPO 方案)
为了避免 和
相差太多,导致方差过大,需要增加约束

Trust Region Policy Optimization
TRPO(信任域策略优化)是2015年由Schulman提出的策略梯度算法,核心就四点:
-
解决的问题:传统算法步长难调,步长大易崩溃,步长小训练慢。
-
核心机制:强制要求新旧策略的KL散度不超过设定阈值,将更新限制在“信任域”内,确保策略单调提升。
-
实现手段:利用共轭梯度法近似求解带约束的优化问题,避免大量矩阵求逆运算。
-
地位:理论稳定性标杆,但因实现复杂、计算开销大,实战中已被更简洁的PPO(通过裁剪函数近似替代)广泛取代。
-

四 add constraint (PPO 方案)
PPO2 algorithm
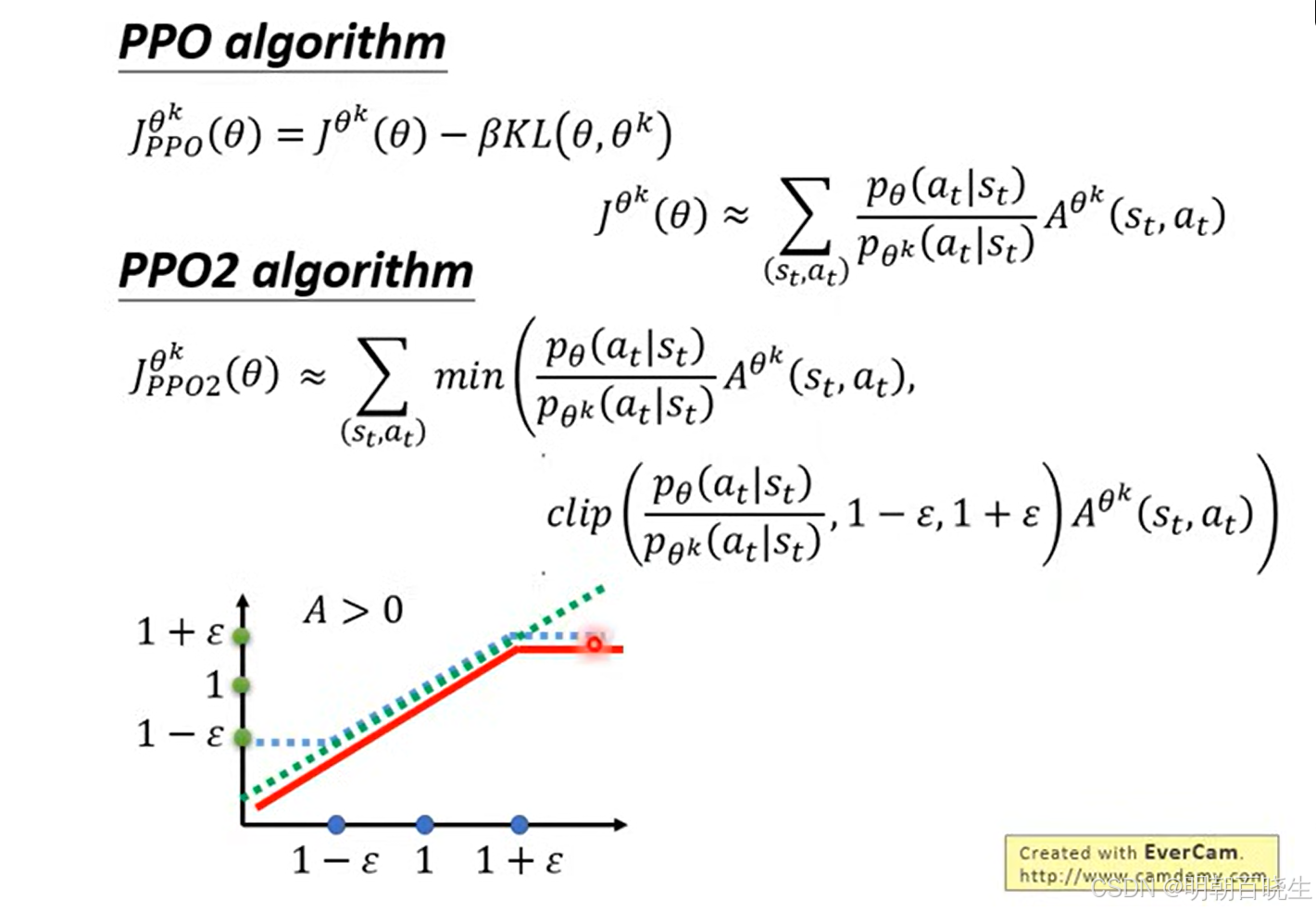
伪代码
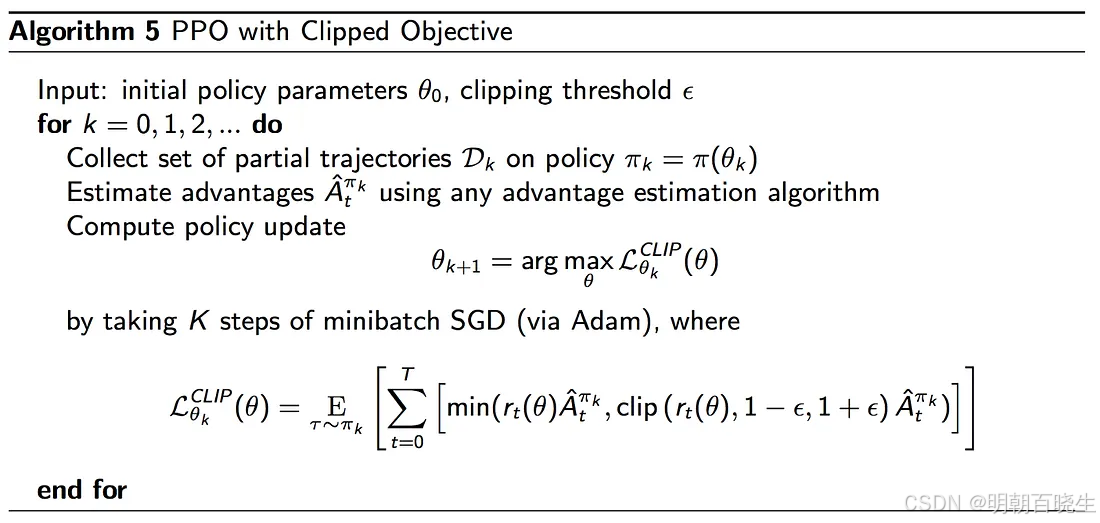
算法: PPO-Clip (Actor-Critic 架构)
For k = 0, 1, 2, ... do:
1. 收集经验 (采样阶段)
运行当前策略与环境交互 T 个时间步
收集轨迹集合
2. 估计优势与回报 (计算阶段)
计算每一步的折扣回报
基于当前的价值函数,计算优势估计
(通常使用广义优势估计 GAE 方法 )
3. 策略与价值网络更新 (优化阶段)
对收集到的一批数据,进行 K 次迭代更新
For epoch = 1, 2, ..., Kdo:
从中随机采样一个 mini-batch 数据
3a. 更新策略网络
基于存储的,计算重要性采样比率:

计算 PPO-Clip 目标函数 [reference:13]:
加入熵奖励以鼓励探索,通过随机梯度上升(如 Adam)最大化以下目标来更新
3b. 更新价值网络
计算价值函数的均方误差:
通过随机梯度下降最小化 $来更新
End For
End For
五 python 例子
背景知识
随机变量变换的概率密度函数公式: 这里面的action 用到了这个原理

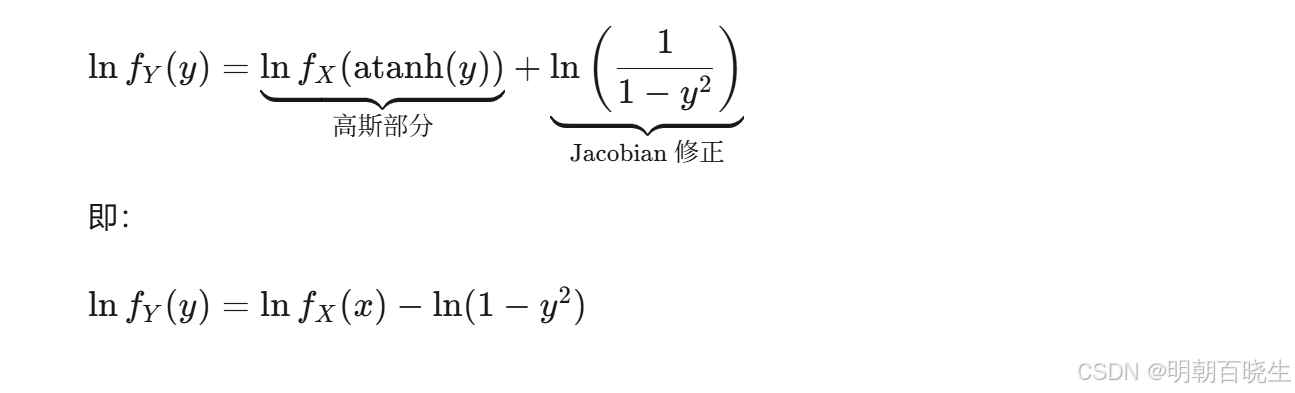
"""
代码版本:version5 (Expert Revised)
作者: chengxf
日期: 2026/6
colab 运行要线运行下面两个命令
!pip install swig
!pip install gymnasium[box2d]
"""
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Normal
from torch.utils.data.sampler import BatchSampler, SubsetRandomSampler
import gymnasium as gym
import matplotlib.pyplot as plt
import time
# ---------------------------- 超参数配置 ----------------------------
class Config:
"""集中管理所有超参数"""
GAMMA = 0.99 # [修改] 原来是0.95,偏小,PPO一般取0.99
LAMBDA_GAE = 0.95 # [修改] 原来是0.90,一般和GAMMA配合用0.95
CLIP_EPSILON = 0.2
ACTOR_LR = 3e-4 # [修改] PPO常用学习率
CRITIC_LR = 1e-3 # [修改] Critic学习率可以稍大一点
BATCH_SIZE = 2048 # [修改] 对于连续控制,Batch_Size稍大有助于稳定
MINI_BATCH_SIZE = 64
K_EPOCHS = 10 # [修改] 一般取 4~10
ENTROPY_COEF = 0.0 # [修改] BipedalWalker 中熵奖励加太大容易不收敛,先设为0或极小值
VALUE_COEF = 0.5
MAX_EPISODES = 300
MAX_STEPS_PER_EP = 1600 # BipedalWalker默认最大步数通常是1600
HIDDEN_DIM = 256
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
EPS = 1e-8
ACTION_CLIP_RANGE = 0.999
LOG_STD_MIN = -20.0
LOG_STD_MAX = 2.0
USE_HUBER_LOSS = False
MODEL_SAVE_PATH = "best_model.pt"
cfg = Config()
def orthogonal_init(layer, gain=1.0):
"""正交初始化(PPO 论文推荐)"""
if isinstance(layer, nn.Linear):
nn.init.orthogonal_(layer.weight, gain=gain)
if layer.bias is not None:
nn.init.constant_(layer.bias, 0.0)
# ---------------------------- Actor 网络 ----------------------------
class ActorNet(nn.Module):
"""策略网络,3个隐藏层 + LayerNorm"""
def __init__(self, state_dim, action_dim, hidden_dim=cfg.HIDDEN_DIM):
super().__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.ln1 = nn.LayerNorm(hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.ln2 = nn.LayerNorm(hidden_dim)
self.fc3 = nn.Linear(hidden_dim, hidden_dim)
self.ln3 = nn.LayerNorm(hidden_dim)
self.mu_head = nn.Linear(hidden_dim, action_dim)
# 可学习的 log_std(状态无关)
self.log_std = nn.Parameter(torch.zeros(1, action_dim))
# 初始化
orthogonal_init(self.fc1, gain=np.sqrt(2))
orthogonal_init(self.fc2, gain=np.sqrt(2))
orthogonal_init(self.fc3, gain=np.sqrt(2))
orthogonal_init(self.mu_head, gain=0.01)
def forward(self, state):
x = torch.relu(self.ln1(self.fc1(state)))
x = torch.relu(self.ln2(self.fc2(x)))
x = torch.relu(self.ln3(self.fc3(x)))
mu = self.mu_head(x)
batch_size = mu.size(0)
log_std = self.log_std.expand(batch_size, -1)
log_std = torch.clamp(log_std, cfg.LOG_STD_MIN, cfg.LOG_STD_MAX)
return mu, log_std
def get_action(self, state, deterministic=False):
mu, log_std = self.forward(state)
if deterministic:
action = torch.tanh(mu)
else:
std = log_std.exp()
dist = Normal(mu, std)
raw_action = dist.sample()
action = torch.tanh(raw_action)
action_clamped = torch.clamp(action, -cfg.ACTION_CLIP_RANGE, cfg.ACTION_CLIP_RANGE)
if not deterministic:
# [修正] 雅可比项应使用未经过 clamp 的 action (即 raw_action 的 tanh) 计算
log_prob = dist.log_prob(raw_action).sum(dim=-1) \
- torch.sum(torch.log(1 - action.pow(2) + cfg.EPS), dim=-1)
entropy = dist.entropy().sum(dim=-1).mean()
return action_clamped, log_prob, entropy
else:
return action_clamped, None, None
def evaluate(self, state, action):
"""评估给定动作的对数概率和熵"""
mu, log_std = self.forward(state)
std = log_std.exp()
dist = Normal(mu, std)
# 为防止 atanh 产生 inf,先将动作限制在安全范围内
action_clamped = torch.clamp(action, -cfg.ACTION_CLIP_RANGE, cfg.ACTION_CLIP_RANGE)
raw_action = torch.atanh(action_clamped)
# 此处传入的 action 实际上就是环境执行过的 action_clamped
log_prob = dist.log_prob(raw_action).sum(dim=-1) \
- torch.sum(torch.log(1 - action_clamped.pow(2) + cfg.EPS), dim=-1)
entropy = dist.entropy().sum(dim=-1).mean()
return log_prob, entropy
# ---------------------------- Critic 网络 ----------------------------
class CriticNet(nn.Module):
"""价值网络,3个隐藏层 + LayerNorm"""
def __init__(self, state_dim, hidden_dim=cfg.HIDDEN_DIM):
super().__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.ln1 = nn.LayerNorm(hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.ln2 = nn.LayerNorm(hidden_dim)
self.fc3 = nn.Linear(hidden_dim, hidden_dim)
self.ln3 = nn.LayerNorm(hidden_dim)
self.value_head = nn.Linear(hidden_dim, 1)
orthogonal_init(self.fc1, gain=np.sqrt(2))
orthogonal_init(self.fc2, gain=np.sqrt(2))
orthogonal_init(self.fc3, gain=np.sqrt(2))
orthogonal_init(self.value_head, gain=1.0)
def forward(self, state):
x = torch.relu(self.ln1(self.fc1(state)))
x = torch.relu(self.ln2(self.fc2(x)))
x = torch.relu(self.ln3(self.fc3(x)))
return self.value_head(x)
# ---------------------------- PPO 算法主体 ----------------------------
class PPO:
def __init__(self, state_dim, action_dim):
self.state_dim = state_dim
self.action_dim = action_dim
self.actor_net = ActorNet(state_dim, action_dim).to(cfg.DEVICE)
self.critic_net = CriticNet(state_dim).to(cfg.DEVICE)
self.actor_optimizer = optim.Adam(self.actor_net.parameters(),
lr=cfg.ACTOR_LR, eps=1e-5)
self.critic_optimizer = optim.Adam(self.critic_net.parameters(),
lr=cfg.CRITIC_LR, eps=1e-5)
self.best_reward = -float('inf')
self.best_actor_state = None
self.best_critic_state = None
# 轨迹缓存
self.states = []
self.actions = []
self.rewards = []
self.terminateds = []
self.truncateds = []
self.log_probs = []
self.values = []
def choose_action(self, state, deterministic=False):
state_t = torch.FloatTensor(state).unsqueeze(0).to(cfg.DEVICE)
with torch.no_grad():
action, log_prob, _ = self.actor_net.get_action(state_t, deterministic)
action_np = action.squeeze(0).cpu().numpy()
if deterministic:
return action_np, None
return action_np, log_prob.item()
def get_value(self, state):
state_t = torch.FloatTensor(state).unsqueeze(0).to(cfg.DEVICE)
with torch.no_grad():
return self.critic_net(state_t).squeeze(0).cpu().numpy().item()
def store_transition(self, state, action, reward, terminated, truncated,
log_prob, value):
self.states.append(state)
self.actions.append(action)
self.rewards.append(reward)
self.terminateds.append(terminated)
self.truncateds.append(truncated)
self.log_probs.append(log_prob)
self.values.append(value)
def compute_gae(self, next_state):
T = len(self.rewards)
advantages = np.zeros(T, dtype=np.float32)
returns = np.zeros(T, dtype=np.float32)
gae = 0.0
last_next_value = self.get_value(next_state)
extended_values = self.values + [last_next_value]
for i in reversed(range(T)):
terminated = self.terminateds[i]
# 只有真正终止才不考虑下一状态价值,截断需要 bootstrap
if terminated:
next_val = 0.0
else:
next_val = extended_values[i + 1]
target = self.rewards[i] + cfg.GAMMA * next_val
delta = target - self.values[i]
if terminated:
gae = delta
else:
gae = delta + cfg.GAMMA * cfg.LAMBDA_GAE * gae
advantages[i] = gae
returns[i] = gae + self.values[i]
return advantages, returns
def normalize_advantages(self, advantages):
adv_t = torch.tensor(advantages, dtype=torch.float32)
if adv_t.numel() > 1:
mean = adv_t.mean()
std = adv_t.std() + cfg.EPS
return ((adv_t - mean) / std).numpy()
return advantages
def update(self, next_state):
data_len = len(self.states)
if data_len == 0:
return 0.0, 0.0
advantages, returns_np = self.compute_gae(next_state)
advantages = self.normalize_advantages(advantages)
states = torch.FloatTensor(np.array(self.states)).to(cfg.DEVICE)
actions = torch.FloatTensor(np.array(self.actions)).to(cfg.DEVICE)
old_log_probs = torch.FloatTensor(np.array(self.log_probs)).to(cfg.DEVICE)
advantages_t = torch.FloatTensor(advantages).to(cfg.DEVICE)
returns_t = torch.FloatTensor(returns_np).to(cfg.DEVICE)
total_actor_loss = 0.0
total_critic_loss = 0.0
update_count = 0
for _ in range(cfg.K_EPOCHS):
sampler = BatchSampler(SubsetRandomSampler(range(data_len)),
cfg.MINI_BATCH_SIZE, drop_last=False)
for indices in sampler:
batch_states = states[indices]
batch_actions = actions[indices]
behavior_log_probs = old_log_probs[indices]
batch_adv = advantages_t[indices]
batch_returns = returns_t[indices]
# ----- Actor 更新 -----
target_log_probs, entropy = self.actor_net.evaluate(batch_states, batch_actions)
ratio = torch.exp(target_log_probs - behavior_log_probs)
surr1 = ratio * batch_adv
surr2 = torch.clamp(ratio, 1 - cfg.CLIP_EPSILON,
1 + cfg.CLIP_EPSILON) * batch_adv
clip_loss = torch.min(surr1, surr2).mean()
actor_loss = -clip_loss - cfg.ENTROPY_COEF * entropy
self.actor_optimizer.zero_grad()
actor_loss.backward()
# 梯度裁剪(PPO标准实践)
nn.utils.clip_grad_norm_(self.actor_net.parameters(), 0.5)
self.actor_optimizer.step()
# ----- Critic 更新 -----
current_values = self.critic_net(batch_states).squeeze(-1)
# [清理] 移除了错误的 Value Clipping 死代码
loss_fn = nn.SmoothL1Loss() if cfg.USE_HUBER_LOSS else nn.MSELoss()
critic_loss = cfg.VALUE_COEF * loss_fn(current_values, batch_returns)
self.critic_optimizer.zero_grad()
critic_loss.backward()
# 梯度裁剪(PPO标准实践)
nn.utils.clip_grad_norm_(self.critic_net.parameters(), 0.5)
self.critic_optimizer.step()
total_actor_loss += actor_loss.item()
total_critic_loss += critic_loss.item()
update_count += 1
# 清空缓存
self.states.clear()
self.actions.clear()
self.rewards.clear()
self.terminateds.clear()
self.truncateds.clear()
self.log_probs.clear()
self.values.clear()
avg_actor_loss = total_actor_loss / max(update_count, 1)
avg_critic_loss = total_critic_loss / max(update_count, 1)
return avg_actor_loss, avg_critic_loss
def save_best_model(self, ep):
self.best_actor_state = {k: v.cpu().clone() for k, v in self.actor_net.state_dict().items()}
self.best_critic_state = {k: v.cpu().clone() for k, v in self.critic_net.state_dict().items()}
torch.save({
'actor_state': self.best_actor_state,
'critic_state': self.best_critic_state,
'best_reward': self.best_reward,
}, cfg.MODEL_SAVE_PATH)
print(f" ✅ Episode {ep}: 保存最优模型 (Reward: {self.best_reward:.2f})")
def load_best_model(self):
if not os.path.exists(cfg.MODEL_SAVE_PATH):
return False
try:
checkpoint = torch.load(cfg.MODEL_SAVE_PATH, weights_only=False,map_location=cfg.DEVICE)
except Exception as e:
print(f"加载失败: {e}")
return False
self.actor_net.load_state_dict(checkpoint['actor_state'])
self.critic_net.load_state_dict(checkpoint['critic_state'])
self.best_reward = checkpoint['best_reward']
print(f"✓ 加载最优模型 (Reward: {self.best_reward:.2f})")
return True
def train(self, env, max_episodes=cfg.MAX_EPISODES, max_steps=cfg.MAX_STEPS_PER_EP):
self.best_reward = -float('inf')
ep_rewards = []
ep_actor_losses = []
ep_critic_losses = []
for ep in range(max_episodes):
state, _ = env.reset()
episode_reward = 0
episode_length = 0
actor_losses_this_ep = []
critic_losses_this_ep = []
# 1. 收集经验 (采样阶段)
for t in range(max_steps):
action, log_prob = self.choose_action(state)
value = self.get_value(state)
next_state, reward, terminated, truncated, _ = env.step(action)
self.store_transition(state, action, reward, terminated, truncated, log_prob, value)
state = next_state
episode_reward += reward
episode_length += 1
if terminated or truncated:
break
# 收集到足够数据才更新,3 策略与价值网络更新 (优化阶段)
if len(self.states) >= cfg.BATCH_SIZE :
a_loss, c_loss = self.update(next_state)
actor_losses_this_ep.append(a_loss)
critic_losses_this_ep.append(c_loss)
ep_rewards.append(episode_reward)
avg_actor = np.mean(actor_losses_this_ep) if actor_losses_this_ep else None
avg_critic = np.mean(critic_losses_this_ep) if critic_losses_this_ep else None
ep_actor_losses.append(avg_actor)
ep_critic_losses.append(avg_critic)
if episode_reward > self.best_reward:
self.best_reward = episode_reward
self.save_best_model(ep)
if (ep + 1) % 10 == 0:
avg_reward = np.mean(ep_rewards[-10:])
std_reward = np.std(ep_rewards[-10:])
print(f"\t\t Episode {ep+1:4d} | Avg Reward: {avg_reward:8.1f} ± {std_reward:5.1f} | Best: {self.best_reward:8.1f} | Steps: {episode_length}")
if avg_actor is not None:
print(f"\t\t 📈Avg Actor Loss: {avg_actor:8.4f} | Avg Critic Loss: {avg_critic:8.4f}")
if avg_reward >= 300.0: # BipedalWalker解决标准一般是300
print(f"--> 环境在第 {ep+1} 回合已被解决 (Solved)! 退出训练。")
break
return ep_rewards, ep_actor_losses, ep_critic_losses
# ---------------------------- 测试与绘图 ----------------------------
def test_agent(env_name, agent, num_episodes=10, render=False):
render_mode = 'human' if render else None
test_env = gym.make(env_name, render_mode=render_mode)
all_rewards = []
for ep in range(num_episodes):
state, _ = test_env.reset()
episode_reward = 0
done = False
t = 0
while not done and t < cfg.MAX_STEPS_PER_EP:
action, _ = agent.choose_action(state, deterministic=True)
next_state, reward, terminated, truncated, _ = test_env.step(action)
state = next_state
episode_reward += reward
done = terminated or truncated
t += 1
all_rewards.append(episode_reward)
print(f"Test Episode {ep+1:2d} | Reward: {episode_reward:.2f}")
test_env.close()
avg_reward = np.mean(all_rewards)
print(f"\n-> 测试完成 | 平均奖励: {avg_reward:.2f}")
return avg_reward
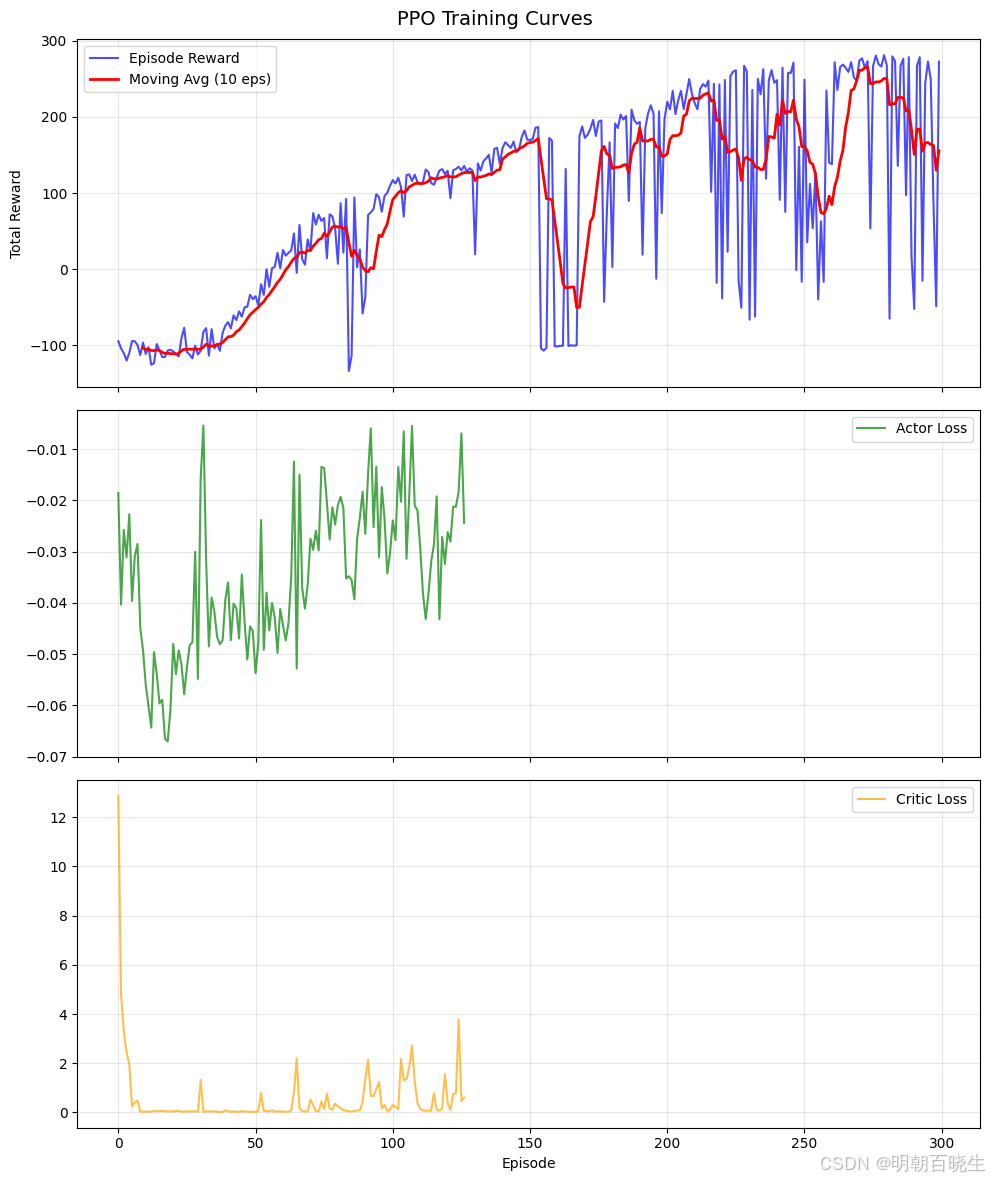
def plot_history(rewards, actor_losses, critic_losses, save_path="training_curves.png"):
fig, axes = plt.subplots(3, 1, figsize=(10, 12), sharex=True)
axes[0].plot(rewards, label='Episode Reward', color='blue', alpha=0.7)
window = 10
if len(rewards) >= window:
smooth = np.convolve(rewards, np.ones(window)/window, mode='valid')
axes[0].plot(range(window-1, len(rewards)), smooth, label=f'Moving Avg ({window} eps)', color='red', linewidth=2)
axes[0].set_ylabel('Total Reward')
axes[0].legend(); axes[0].grid(True, alpha=0.3)
valid_actor = [v for v in actor_losses if v is not None]
if valid_actor:
axes[1].plot(valid_actor, label='Actor Loss', color='green', alpha=0.7)
axes[1].legend(); axes[1].grid(True, alpha=0.3)
valid_critic = [v for v in critic_losses if v is not None]
if valid_critic:
axes[2].plot(valid_critic, label='Critic Loss', color='orange', alpha=0.7)
axes[2].legend(); axes[2].grid(True, alpha=0.3)
axes[2].set_xlabel('Episode')
plt.suptitle('PPO Training Curves', fontsize=14)
plt.tight_layout()
plt.savefig(save_path, dpi=150)
print(f"训练曲线已保存至: {save_path}")
plt.show()
# ---------------------------- 主程序 ----------------------------
if __name__ == "__main__":
env_name = 'BipedalWalker-v3'
# [重要添加] 包装环境进行状态归一化,PPO对输入尺度极度敏感
env = gym.make(env_name)
env = gym.wrappers.NormalizeObservation(env)
env = gym.wrappers.TransformObservation(env, lambda obs: np.clip(obs, -10, 10), env.observation_space)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
print(f"环境: {env_name} | 状态维度: {state_dim} | 动作维度: {action_dim}")
start = time.perf_counter()
agent = PPO(state_dim, action_dim)
print("\n【训练】启动 PPO 训练...")
rewards, actor_losses, critic_losses = agent.train(env, max_episodes=cfg.MAX_EPISODES)
print("\n【测试】加载最优模型测试...")
agent.load_best_model()
test_agent(env_name, agent, num_episodes=3, render=True)
end = time.perf_counter()
print(f"总耗时: {int((end-start)//60)} 分 {(end-start)%60:.1f} 秒")
plot_history(rewards, actor_losses, critic_losses)
env.close()
参考:
https://wbrucek.medium.com/trust-region-policy-optimization-overview-dd0061363771
https://huggingface.co/blog/deep-rl-ppo
https://www.youtube.com/watch?v=OAKAZhFmYoI&t=1550s
https://jonathan-hui.medium.com/rl-the-math-behind-trpo-ppo-d12f6c745f33

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 2
2 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)