具身 AI 技术
1. 什么是具身 AI?
具身 AI(Embodied AI / Embodied Intelligence) 是指具有“身体”或行动载体的人工智能系统。这个身体可以是真实机器人,也可以是虚拟环境中的智能体。它不仅能处理文本、图像或数据,还能通过感知环境、理解任务、规划动作并执行行为来影响环境。
具身 AI 的典型载体包括:
| 类型 | 示例 |
|---|---|
| 物理机器人 | 人形机器人、机械臂、移动机器人、无人车、无人机 |
| 虚拟智能体 | 游戏智能体、仿真机器人、虚拟助手 |
| 多模态 Agent | 能看、能听、能说、能操作工具或设备的智能体 |
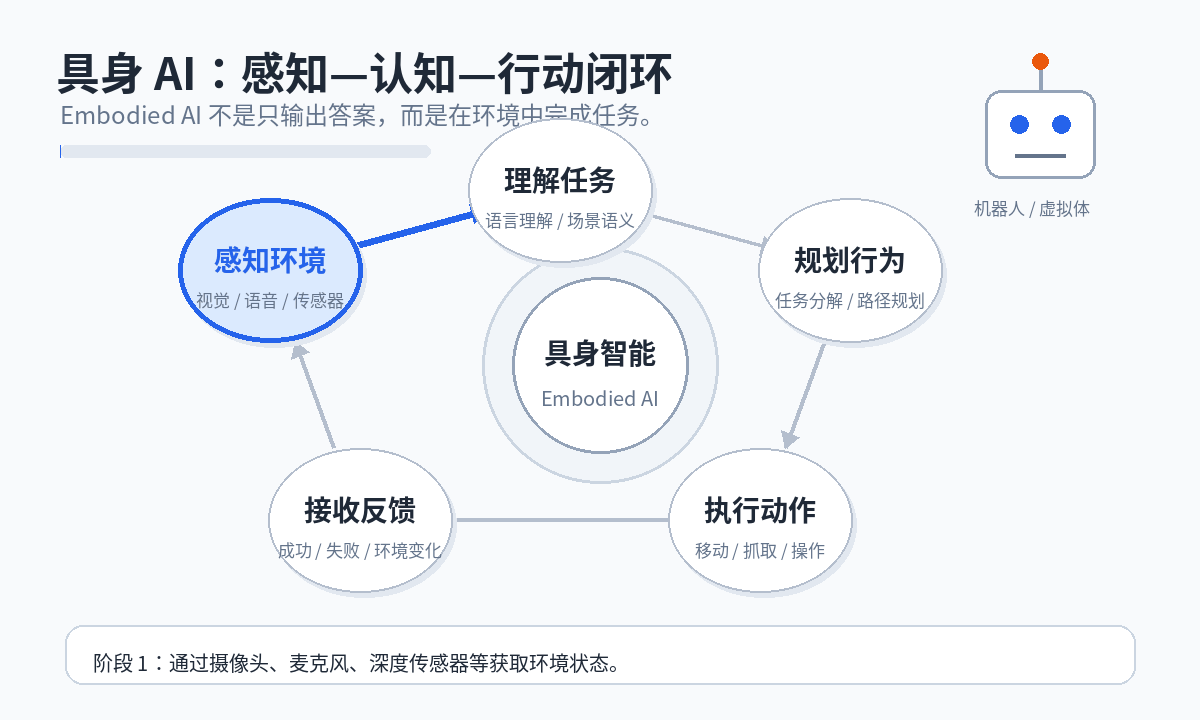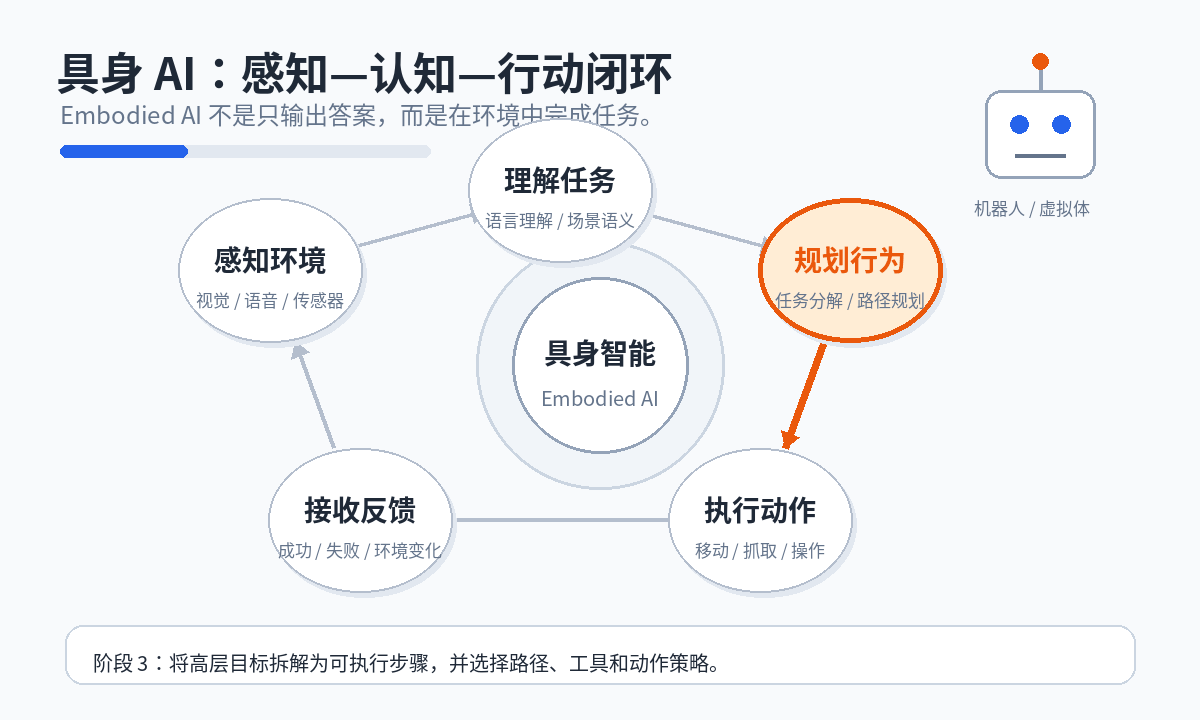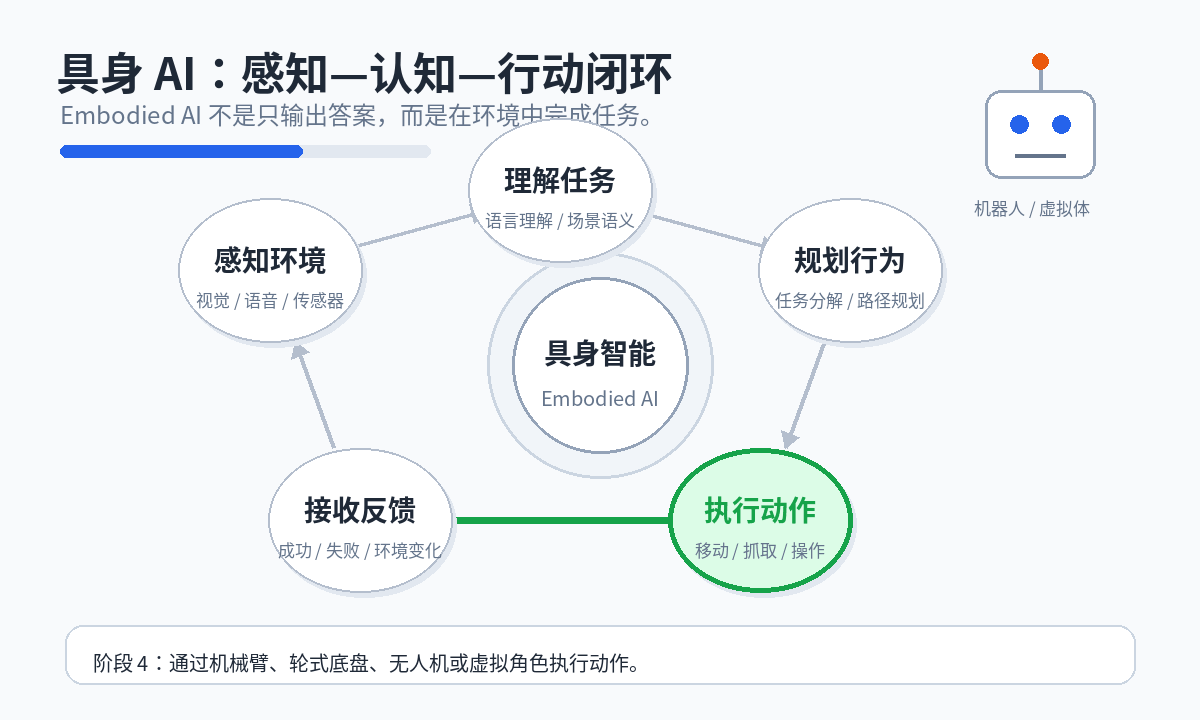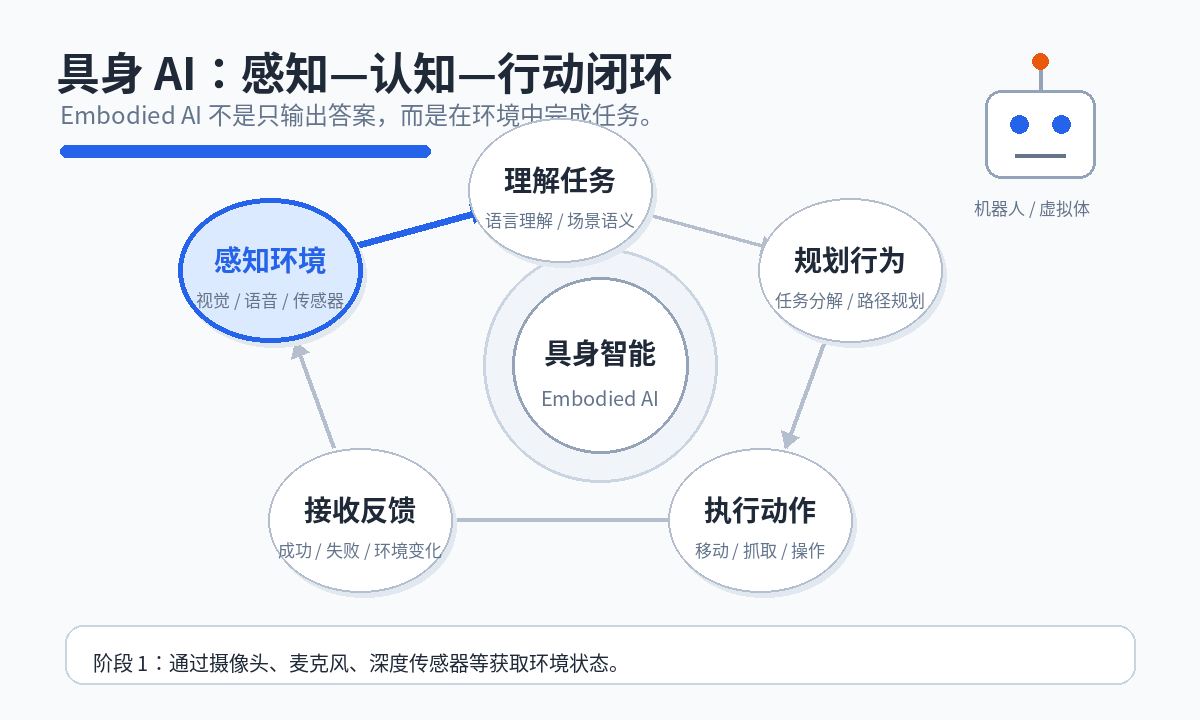
具身 AI 的关键特征是形成完整的环境交互闭环:
感知环境 → 理解任务 → 规划行为 → 执行动作 → 接收反馈 → 调整策略
例如,当用户说“帮我把桌上的红色杯子拿过来”时,具身 AI 需要完成的不只是语言理解,还包括识别杯子、定位空间位置、规划移动路径、控制机械臂抓取、避障并将杯子递给用户。
2. 具身 AI 的核心目标
具身 AI 的核心目标是:
让 AI 能够在真实或模拟环境中,通过感知、认知、决策和行动,与世界进行持续交互,并自主完成复杂任务。
该目标可以拆解为五个方面:
2.1 理解环境
系统需要识别物体、空间位置、物体之间的关系、环境状态和动态变化。
2.2 理解任务
系统需要把人类自然语言目标转化为可执行的任务结构。
2.3 自主规划
系统需要决定任务执行步骤,处理先后依赖,并在失败时重新规划。
2.4 物理执行
系统需要通过机械臂、轮式底盘、无人机、虚拟角色或其他执行器完成动作。
2.5 从反馈中学习
系统需要根据执行结果、错误、碰撞、环境变化和人类反馈不断调整策略。
因此,具身 AI 追求的不是单纯“回答正确”,而是“在环境中把事情做成”。
3. 大模型如何赋能具身 AI?
大模型主要增强具身 AI 的高层认知能力,使其能够理解语言、理解场景、分解任务、进行常识推理、选择工具并进行失败恢复。
传统机器人通常擅长执行预设动作,但不擅长理解开放式任务。例如,“把房间整理一下”对传统机器人来说过于抽象,而大模型可以将其拆解为多个可执行子任务:
1. 识别地面和桌面上的杂物
2. 将衣服放入篮子
3. 将书放回书架
4. 将垃圾放进垃圾桶
5. 避免移动易碎或高风险物品
4. 大模型增强具身 AI 的主要方面
4.1 自然语言理解
大模型让具身 AI 能够理解人类自然语言指令,而不是依赖固定命令。
例如:
用户:把沙发旁边那个蓝色盒子拿到厨房。
系统需要理解:
对象:蓝色盒子
当前位置:沙发旁边
目标位置:厨房
动作:拿取并移动
4.2 多模态感知
具身 AI 需要处理图像、视频、语音、深度信息、触觉、力反馈和位置传感器数据。多模态大模型可以把视觉、语言和动作信息连接起来,使系统理解复杂场景。
例如,机器人可以判断:
桌上有哪些物体?
用户说的“黑色遥控器”是哪一个?
杯子是否挡住了抓取路径?
4.3 任务分解与规划
复杂任务通常需要多步骤执行。大模型可以把抽象目标拆解为具体行动序列。
例如:
用户:给我泡一杯茶。
可被拆解为:
找杯子 → 找茶包 → 加热水 → 放入茶包 → 倒入热水 → 等待浸泡 → 递给用户
4.4 常识推理
具身 AI 需要具备物理世界和生活常识,例如:
玻璃杯易碎
热水有危险
刀具不能随意递给儿童
湿地面可能打滑
鸡蛋不能用太大力抓
大模型可以为具身系统提供一定程度的常识推理能力。
4.5 动作选择与工具调度
大模型可以帮助具身 AI 在多个动作、工具或策略之间做选择。
例如,机器人要拿高处物品时,可以选择:
直接伸手
移动到更近位置
使用夹爪
请求人类帮助
4.6 失败恢复与反思
真实环境中的动作经常失败,例如抓取失败、目标被遮挡、路径被挡住或识别不确定。大模型可以帮助系统分析失败原因并提出修正策略。
示例:
失败原因:抓取角度不对。
修正策略:调整夹爪方向后重新尝试。
4.7 人机协作
大模型增强了具身 AI 的对话、解释、确认和协作能力。
当指令不清楚时,机器人可以追问:
你说的“那个杯子”是红色杯子还是白色杯子?
当任务有风险时,机器人可以确认:
这个杯子里有热水,我需要先确认是否移动它。
4.8 跨任务泛化
大模型可以让具身 AI 更容易处理开放式任务,而不是为每个任务单独写规则。
示例任务包括:
收拾桌子
找钥匙
递水
整理货架
检查设备
引导用户到会议室
5. 大模型在具身 AI 中的定位
大模型并不是直接替代底层机器人控制系统。具身 AI 仍然需要传感器、运动规划、SLAM、控制算法、抓取算法、强化学习、模仿学习、安全控制和实时系统。
更准确地说,大模型通常承担以下角色:
任务理解器
高层规划器
常识推理器
多模态理解器
工具调度器
人机交互接口
反思与恢复模块
底层执行仍依赖机器人控制系统和环境反馈闭环。
6. 具身智能与传统 AI 的主要区别
具身智能与传统 AI 的根本区别在于:
传统 AI 主要处理信息;具身 AI 需要在环境中行动。
可以简化为:
传统 AI:看懂、听懂、算对、答对。
具身 AI:看懂、想清楚、动起来、做成功。
| 维度 | 传统 AI | 具身 AI |
|---|---|---|
| 核心对象 | 数据、文本、图像、语音 | 环境、物体、空间、身体、动作 |
| 主要目标 | 分类、预测、生成、问答 | 感知、规划、执行、交互、完成任务 |
| 是否需要身体 | 通常不需要 | 需要物理或虚拟行动载体 |
| 输入形式 | 静态数据较多 | 连续、多模态、动态环境输入 |
| 输出形式 | 标签、文本、图片、代码 | 动作、路径、抓取、移动、操作 |
| 环境反馈 | 通常弱反馈或离线反馈 | 实时反馈、物理反馈、任务反馈 |
| 错误后果 | 多数是答案错误 | 可能造成碰撞、损坏、危险 |
| 评估标准 | 准确率、loss、pass@k 等 | 任务完成率、安全性、效率、鲁棒性 |
| 学习方式 | 数据驱动为主 | 数据驱动 + 环境交互 + 反馈学习 |
| 典型代表 | 图像分类、文本生成、推荐系统 | 机器人、无人车、机械臂、家庭助手 |
7. 具身 AI 的典型架构
一个典型具身 AI 系统可分为以下层次:
用户指令
↓
语言理解层
↓
多模态感知层
↓
任务规划层
↓
动作决策层
↓
机器人控制层
↓
环境反馈层
↓
反思与记忆更新
其中,大模型主要增强语言理解、多模态理解、任务规划、常识推理、工具调度和失败恢复;机器人控制系统主要负责底层运动控制、路径规划、抓取和实时安全约束。
8. 动态闭环示意
感知环境 → 理解任务 → 规划行为 → 执行动作 → 接收反馈 → 调整策略
对应动态展示文件:

9. 总结
具身 AI 是让 AI 从“理解世界”走向“参与世界”的技术方向。它的核心目标是构建能够在真实或虚拟环境中感知、理解、规划、行动并持续学习的智能体。
大模型对具身 AI 的主要价值在于增强其高层认知能力,包括自然语言理解、多模态感知、任务分解、常识推理、工具调度、人机协作、失败恢复和跨任务泛化。
具身 AI 与传统 AI 的核心区别在于:传统 AI 主要处理信息,而具身 AI 必须通过身体与环境交互,并通过行动完成任务。
因此,具身 AI 不是“大模型 + 机器人外壳”,而是一个融合大模型、多模态感知、机器人控制、环境交互、规划决策、安全机制和持续学习能力的完整智能系统。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 17
17 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)