让前瞻具有可操作性:在世界行动模型中重构表征对齐
26年6月来自港大和小鹏机器人的论文“Making Foresight Actionable: Repurposing Representation Alignment in World Action Models”。
世界动作模型(World Action Models, WAMs)为机器人操作任务提供了一种极具前景的方案:即在生成控制动作之前,利用视频生成模型来预测场景的未来演变。然而,实证观察揭示一个问题:生成看似合理的未来视觉画面,并不总是能确保提取出准确的动作。为了探究这一失效原因,对动作预测头(action-head)进行注意分析和因果干预实验。结果发现,动作解码器未能聚焦于与任务相关的交互区域,反而容易受到任务无关区域扰动的影响。这揭示表征层面的不匹配:针对视觉重建优化的隐状态(hidden states),其组织形式并不直接适用于底层的动作控制。为此,本文提出 AGRA(Action-Grounded Representation Alignment,即“动作导向的表征对齐”)目标函数。该方法通过将视频扩散模型的中间特征与基础视觉编码器(foundation visual encoder)提供的空间一致性语义表征进行对齐,从而规范了“世界-动作”接口。
如图 1 所示,在世界动作模型(World Action Models)中,即便能准确预测未来,也未必能实现可靠的控制;这是因为视觉特征在用于动作解码时可能缺乏良好的组织结构,从而导致注意偏移至与任务无关的区域。为此,提出 AGRA(Action-Grounded Representation Alignment,即“基于动作的表征对齐”)目标,旨在将视频特征与来自冻结的基础视觉编码器(frozen foundation visual encoder)且具有空间一致性的表征进行对齐。这种对齐方式增强了世界模型特征与动作的关联性,并将动作相关的注意聚焦于任务关键区域,进而提高了任务成功率。
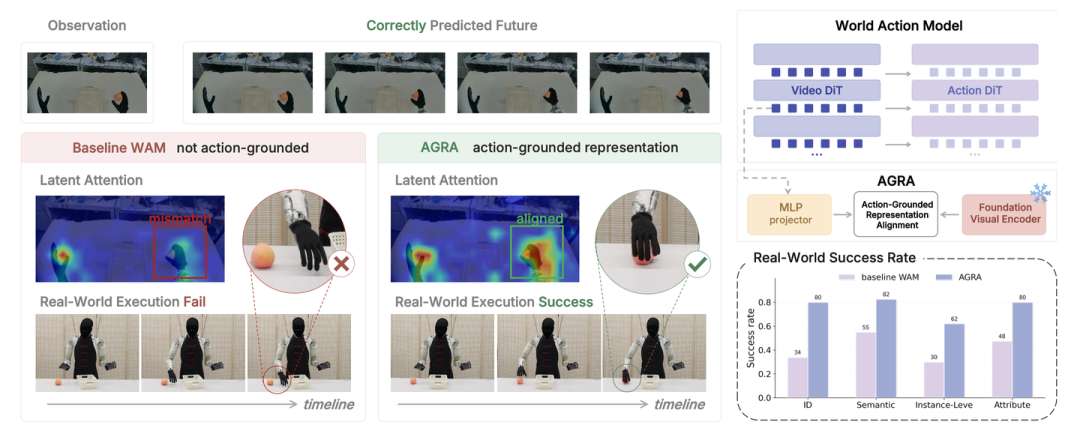
WAM 的一个核心假设是:预测性的世界表征应能为动作解码提供有益的指导。然而,在实际部署中,生成看似合理的视觉未来并不总是能确保提取出准确的控制动作。
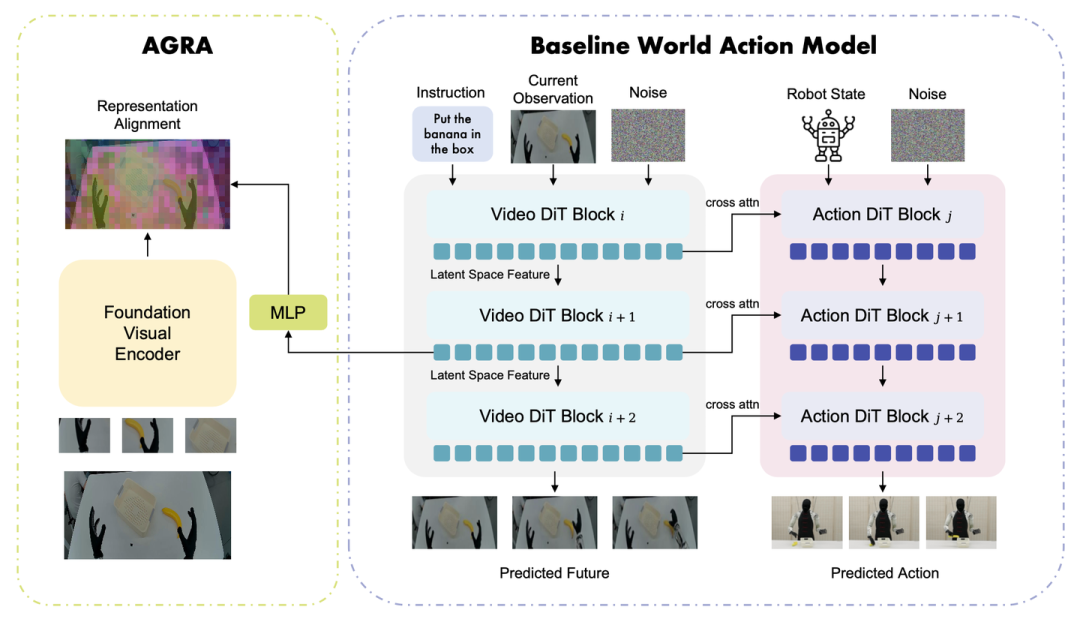
基准 WAM 采用双分支 DiT 架构:世界模型(Video DiT)负责生成未来的视觉内容,而动作头(Action DiT)则将中间的未来表征转化为连续动作。
这两个分支均采用流匹配(flow matching)[59] 方法进行训练。在动作生成阶段,Video DiT 仅在固定的高噪声水平(τ^cond_v = 1)下运行一次以提取预测特征,而 Action DiT 则在动作空间内执行迭代去噪,从而保持推理的高效性。本文采用 Cosmos-Predict-2.5 作为 Video DiT。
如图 7 所示基准世界动作模型与所提出的基于动作表征对齐的架构(AGRA):视频 DiT分支是一个基于流匹配(flow-matching)的视频 DiT,由 Cosmos-Predict2.5-2B 初始化而来。它根据当前的观测 o_0 和语言指令 c 来预测未来的视觉潜表示(visual latents)。在动作 DiT,采用了源自 Gr00T-N1 的流匹配(flow-matching)动作 DiT。该动作分支基于预测性视觉表征和机器人本体感知状态 s_0,从纯噪声中生成未来的动作片段。
动作头注意分析。为了诊断这种失效模式,检查 Action DiT 中的交叉注意图(cross-attention maps),以了解动作解码器如何读取世界模型的特征。将注意权重在动作 Token 和注意头维度上进行平均,并将其映射回视频的潜空间(latent shape)形状。在大多数情况下,注意图能够定位到机器人手部的大致区域,但往往无法聚焦于对动作至关重要的交互部位。如图 2 左侧面板所示,模型的注意被静止的左手和桌面背景分散,未能聚焦于右手与香蕉之间关键的交互区域。
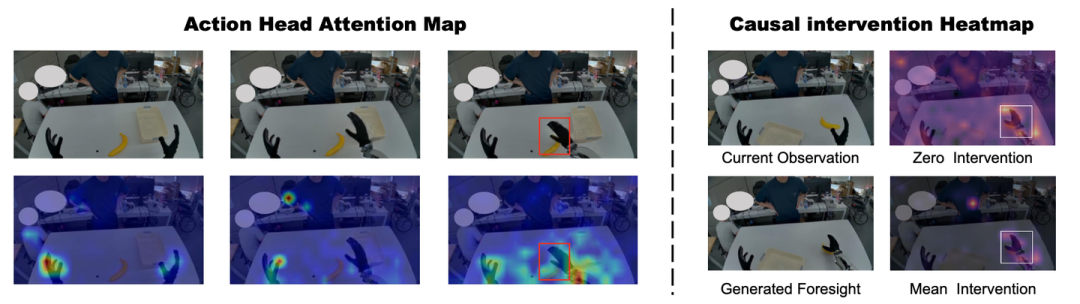
针对隐状态可操作性的因果干预。注意图揭示了动作解码器的读取位置,但无法确定哪些区域对预测动作产生因果影响。因此,对世界模型的隐状态执行 Token 级的因果干预,以评估每个空间位置的可操作性。其对每个空间 Token 施加干预措施(如替换为零值或均值),随后利用欧几里得距离衡量各位置对动作的影响程度,并通过最小-最大归一化(min-max normalization)生成热力图。热力图上的高值表示该位置对动作的影响较大。为了进行可视化展示,呈现最后一个潜帧(latent frame)上的热力图,因为该帧包含了最显著的运动和交互线索。理想情况下,高影响区域应与任务关键的手部-物体交互部位相吻合。然而,如图2右侧面板中的示例所示,当应用“均值干预”(Mean Intervention)时,对动作影响最大的区域位于背景中的一个人身上;而在“零干预”(Zero Intervention)下,整个无关背景都会对动作产生显著影响。这意味着无关区域的扰动会显著影响预测的动作,使得模型难以在分布外(OOD)场景(如背景改变或添加了干扰物)中保持稳健的性能。
经重构优化的特征并不一定能呈现出利于动作识别的场景结构。本文采用 Cosmos-Predict-2.5 作为世界模型。利用主成分分析(PCA)[60] 对 Cosmos 和当前最先进的自监督视觉模型 DINOv2 [51] 的特征空间结构进行了可视化。对于每个模型,从多个样本中收集图像块(patch)特征,联合拟合 PCA,并将前三个主成分映射为 RGB 颜色。如图3所示,DINOv2 特征展现出更具连贯性的空间组织结构:语义和功能相似的区域(如桌子和背景)在视觉迥异的场景中往往被映射为一致的颜色。即使是杂乱的背景也能得到平滑且可区分的表征,且桌子区域对外观变化的敏感度较低。相比之下,Cosmos 特征对视觉细节较为敏感。背景杂乱、有纹理的桌布以及功能相似表面的外观变化,往往会产生不同的特征。这表明其隐藏状态所呈现的语义信息在空间稳定性及下游动作解码的可利用性方面均较弱。这一观察结果与 REPA [18] 的研究动机相一致:尽管扩散模型能够形成有意义的内部表征,但其表征质量仍可能落后于强大的自监督视觉编码器。
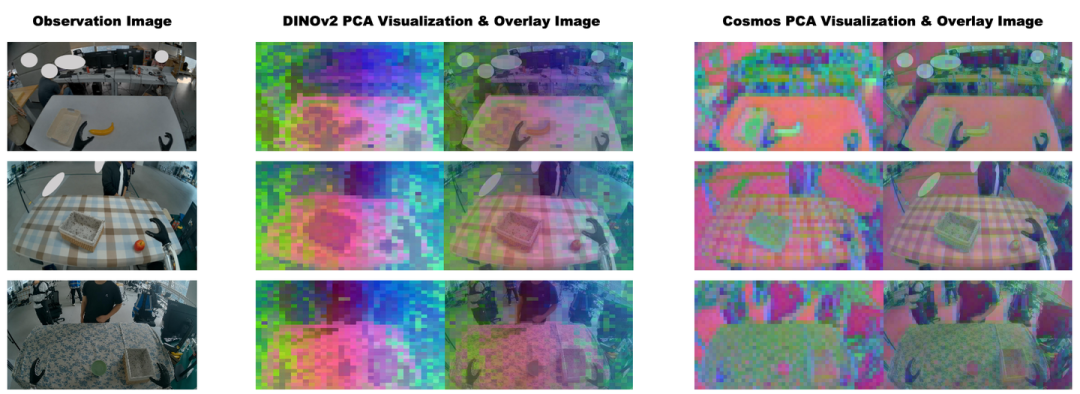
AGRA 的作用。上述分析表明,与原生世界模型相比,DINOv2 特征提供一个空间组织性更强且语义基础更扎实的特征空间。因此,促使动作 DiT 所使用的引导视觉表征与 DINOv2 特征空间对齐。受状态与预训练视觉表征对齐可提升其语义质量——其引入 AGRA:一种基于动作的表征对齐目标,用于规范世界模型与动作模型之间的接口。与旨在改进扩散模型生成效果的原始 REPA 目标不同,AGRA 对用于机器人控制的世界-动作接口进行了正则化处理。
一种常见的策略 [43] 是选择单个视频层 l^* 并将其隐状态复用于所有动作交叉注意层,但这会舍弃视频 DiT 的层级结构——该结构在不同层级上编码了互补信息。因此,采用了一种多层桥接(multi-layer bridge)方案。假设视频 DiT 包含 M 层,而动作 DiT 包含 N 个交叉注意层;对于第 j 个动作交叉注意层,根据视频 DiT 的深度均匀地选择一个视频层。
随后,选定的视频隐状态被投影至动作特征维度,由此生成的引导特征通过上述交叉注意(cross-attention)操作注入到动作 DiT 中。这种桥接设计使得动作头(action head)能够获取来自视频世界模型的多层预测表征,同时保持动作解码器(action decoder)的轻量化。
动作采样。既往的视频-动作策略研究 [17, 13] 表明,视频扩散模型在高噪声水平下的早期去噪表征,能为下游机器人控制提供有用的预测性视觉特征。初步实验显示,基于单步视频去噪特征的动作策略,其任务成功率高于基于四步去噪后特征的策略。这表明,高噪声视频表征可能保留了全局任务动态和未来运动线索,这些信息对于动作预测比低噪声表征更有价值——后者往往更侧重于视觉细节。
因此,在推理过程中,基于当前的观测 o 和语言指令 c,在固定的高噪声水平 tau^cond_v= 1 下,针对未来的潜(latent)token 运行一次视频 DiT。
随后,利用桥接结构计算第 j 个动作交叉注意层的引导特征。轻量级动作 DiT 在动作空间内执行多步去噪(以 G = {G_j} 为条件),从而生成连续的动作片段。这种“单步视频采样”与“多步动作采样”相结合的策略,既降低了推理延迟,又保留了由视频世界模型提供的预测性引导。
WAM 的训练涉及两个流匹配(flow-matching)目标:视频预测损失 L_vid,以及动作预测损失 L_act。
对于视频生成模块,遵循标准的扩散模型训练范式。在每个训练步骤中,噪声水平从 [0, 1] 区间内随机采样。这使得视频模型能够接触到各种噪声水平,从而迫使其学习合成未来帧所需的完整去噪轨迹。
对于动作预测目标,动作预测头首先需要来自世界模型的预测性视觉表征。为了确保输入到动作模块的视觉信息是确定性的且与推理阶段保持一致,在固定的高噪声水平 τ_cond = 1 下,通过独立的视频 DiT 前向传播过程来计算这些表征。
实验设置
用具有28层结构的Cosmos-Predict-2.5-2B作为世界模型,并将其与一个包含5亿参数、8层结构的动作头(action head)相结合。在IRON-R01-1.11人形机器人上评估AGRA,并考察两项操作任务:“抓取并放置”(Pick-and-Place)以及“打开蒸笼并转移包子”(Open-Steamer-Transfer-Bun)。评估场景涵盖了分布内(ID)设置以及三种分布外(OOD)设置(语义泛化、实例级泛化和属性泛化)。
其对比以下变体:Freeze backbone(冻结主干)保持Cosmos模型冻结,仅优化动作头;WAM是未进行表征对齐的基线模型;AGRA-DinoL8(本文方法)将Cosmos的第8层与DINOv2特征进行对齐(除非另有说明,否则这是我们的默认模型);AGRA-DinoL15将Cosmos更深层与DINOv2对齐;AGRA-DinoL4/8/12同时对齐Cosmos的多个层;AGRA-SiglipL8将视觉对齐目标从DINOv2替换为SigLIP;AGRA-BridgeL8将对齐后的第8层特征重复输入到所有动作交叉注意力层中;最后,对比使用和不使用EgoDex [61]人类数据训练的变体,以评估方法是否能提升跨具身(cross-embodiment)迁移能力。
训练细节
在进行视频-动作联合优化之前,针对具身智能领域的 Cosmos 模型进行纯视频训练是一个关键的初始化步骤。初步实验表明,如果直接基于原始 Cosmos 检查点(checkpoint)同时训练视频分支和动作头,会导致下游任务的成功率急剧下降。因此,首先在相应数据集上仅利用视频去噪目标对 Cosmos 进行约 4,000 到 5,000 步的训练,并使用由此得到的检查点(而非原始 Cosmos 权重)来初始化视频分支,进而开展视频-动作联合训练。采用 256 的总批次大小(batch size),并使用包含 5% 预热(warm-up)阶段的余弦学习率调度策略来优化模型。所有训练均在 32 块 GPU 上进行,每块 GPU 配备 140GB 显存。总训练目标由 Cosmos 去噪损失 L_vid、动作去噪损失 L_act 和 AGRA 损失 L_AGRA 构成,对应的损失权重分别为 1.0、1.0 和 0.01。
在真实世界实验中,经过初始的纯视频适配阶段后,在联合预训练数据集上对完整的视频-动作模型进行 60,000 步训练。在此阶段,Cosmos 的学习率设为 1 X 10^-5,而动作头的学习率设为 1 X 10^-4。随后,在特定任务的微调数据集上对模型进行 2,000 步微调。微调期间,Cosmos 保持冻结状态,仅更新动作头。对于单个动作片段(action chunk),采用 K=48 的动作时域跨度(action horizon)。由于 Cosmos 预测 4 帧未来的潜(latent)帧(对应 16 帧 RGB 图像),在将视频目标与动作配对时,每隔 3 帧采样一次视频帧。这样可确保 16 帧视频目标的时间跨度与 48 步的动作片段保持一致。
在仿真实验中,模型在全数据(full-data)设定下训练 80,000 步,在少样本(few-shot)设定下训练 40,000 步。 Cosmos 和动作头(action head)的学习率均设定为 1 × 10−4。将动作片段的时间跨度(action chunk horizon)设定为 K = 16。相应的视频目标包含 16 帧 RGB 图像,因此无需进行时间间隔采样。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 1
1 0
0- 0



 已为社区贡献350条内容
已为社区贡献350条内容

所有评论(0)