【OHD】AHA - Predicting What Matters Next: Online Highlight Detection Without Looking Ahead 流视频场景HD
note
- AHA首次实现了严格因果约束下的在线视频高亮检测,通过轻量解耦头、任务聚焦的动态记忆和抗干扰训练,在零样本和全监督设置下均超越离线方法,为机器人、无人机等实时智能体提供了“边看边懂”(流式场景)的新范式。
- 问题:
- 问题一:关于"零样本超越离线模型"这件事
- 问题二:关于不确定性头的实际价值
- 问题三:关于 Dynamic SinkCache 的局限性
文章目录
一、研究动机
论文:AHA - Predicting What Matters Next: Online Highlight Detection Without Looking Ahead
单位:University of Southern California
现实需求
自动驾驶、救灾机器人、监控无人机等智能体,面对的是连续不断的视频流,必须在毫秒级内做出决策。例如:
- 机器人进入陌生房间,需要立刻识别“这里有鞋子”或“门开着”
- 无人机追踪目标时,需要实时标记异常事件
现有方法的致命缺陷
- 离线方法主导:绝大多数视频理解模型(如TR-DETR、UniVTG)假设能看完整段视频后再分析,双向注意力机制需要全局上下文。
- 流式Video-LM的局限:虽然有些大模型支持流式处理,但它们往往修改评测标准、使用后处理平滑(变相偷看未来),且高亮检测只是辅助功能,性能不佳。
- 因果约束下的空白:严格“只看过去和现在、不展望未来”的在线高亮检测(OHD),几乎是一个未被充分探索的领域。
二、AHA框架:核心设计思想
AHA的本质是一个轻量级自回归评分系统,建立在冻结的视觉语言模型(Qwen2-7B + SigLIP)之上,但只训练几个小小的预测头,实现高效实时推理。
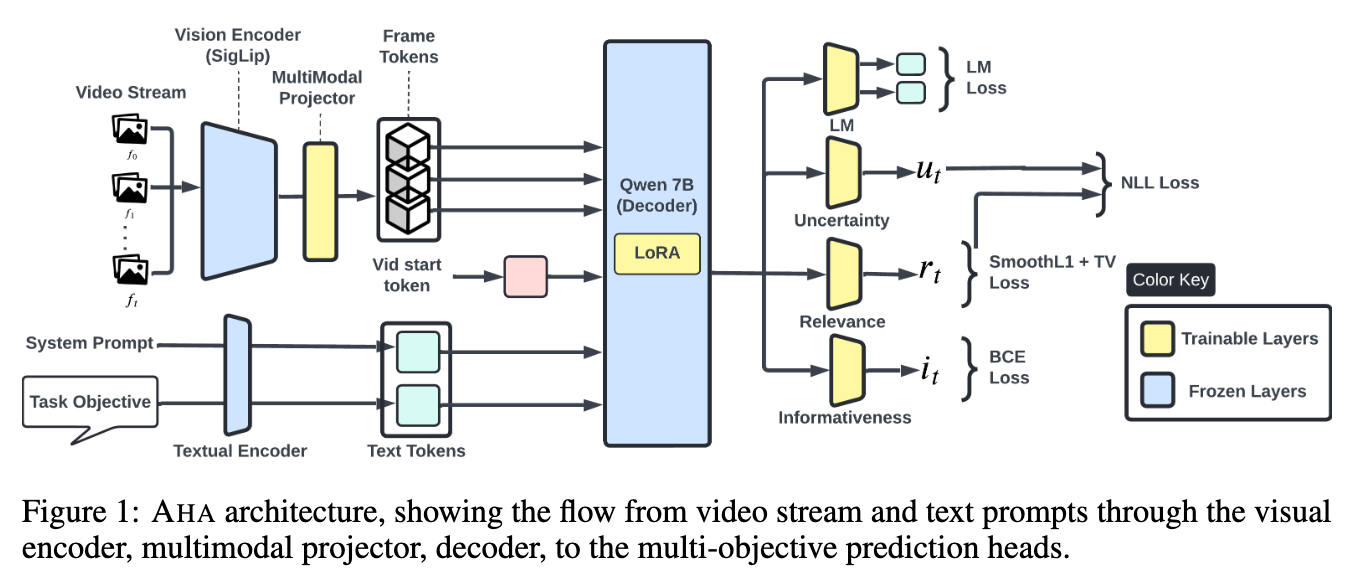
1. 三大预测头 —— 各司其职
| 预测头 | 输出 | 作用 | 监督信号 |
|---|---|---|---|
| 相关性头 | 标量 r ^ t \hat{r}_t r^t | 当前帧与任务目标的相关程度 | YouTube重播次数(用户参与度) |
| 信息量头 | 概率 i ^ t \hat{i}_t i^t | 当前帧是否带来新信息(vs冗余) | 基于Shot2Story/COIN数据集的启发式标签 |
| 不确定性头 | 对数方差 u ^ t \hat{u}_t u^t | 模型对自身预测的置信度 | 高斯负对数似然 + 多样性正则 |
关键创新:这三个头是解耦的。相关性关注“任务匹配”,信息量关注“视觉新颖性”。论文在机器人视频上验证:当机器人进入暗室(无任务物体),信息量高但相关性低;当远处出现日历,两者都高但相关性随后超越——证明模型真正学到了不同概念。
2. 动态SinkCache —— 恒定内存的秘诀
这是工程上的亮点。传统KV缓存随视频变长无限增长,最终GPU显存爆炸。AHA借鉴StreamingLLM的SinkCache,但做了关键改造:
- 标准SinkCache:把序列最前面的几个token(可能是系统提示、任务描述、第一帧)作为“记忆池”。
- Dynamic SinkCache:动态构建记忆池,只包含自然语言任务目标 Q \mathcal{Q} Q 的token(约45个),再加上一个滑动窗口(2048个近期视觉token)。
- 效果:内存占用仅为标准缓存的17%,却能支持无限长视频的恒定成本推理,且在TVSum上mAP反而更高(93.0 vs 92.6)。
3. 不确定性感知评分函数
最终高亮分数 y ^ t \hat{y}_t y^t 不是简单加权平均,而是一个分段线性函数:
- 当不确定性 ≤ 阈值:正常加权( α i ^ t + β r ^ t \alpha \hat{i}_t + \beta \hat{r}_t αi^t+βr^t)
- 当不确定性 > 阈值:额外减去惩罚项 ϵ ( u ^ t − τ u ) \epsilon(\hat{u}_t - \tau_u) ϵ(u^t−τu)
这种设计让模型在“看不准”时自动降低分数,相当于一个风险厌恶策略,避免在模糊帧上误报。
4. 抗退化训练(Video Quality Dropout)
真实世界视频常有压缩伪影、卡顿、黑屏。AHA在训练时随机将5-20%的视频段施加四种扰动:
- 质量降级(下采样+模糊)
- 块噪声(模拟传输错误)
- 色带(颜色量化)
- 黑屏
这让模型在TVSum测试集上面对这些 corruption 时,mAP仅下降0.4~4.8个百分点,展现了极强的鲁棒性。
三、数据集贡献:HIHD
作者构建了Human Intuition Highlight Dataset (HIHD),包含约2.2万个视频,特点如下:
- 来源:从Mr.Hisum基准出发,爬取YouTube原始视频(过滤掉观看量<7万的)
- 相关性标签:使用YouTube“最多重播”数据归一化到[0,1],作为人类直觉的代理信号
- 任务条件:用模板将视频标题转化为自然语言查询(如“What segment addresses ‘Exploring Riemann Hypothesis’?”)
- 质量dropout掩码:同步生成,用于鲁棒性训练
- 严格划分:排除常见高亮检测评估集的视频,确保公平泛化测试
四、实验结果
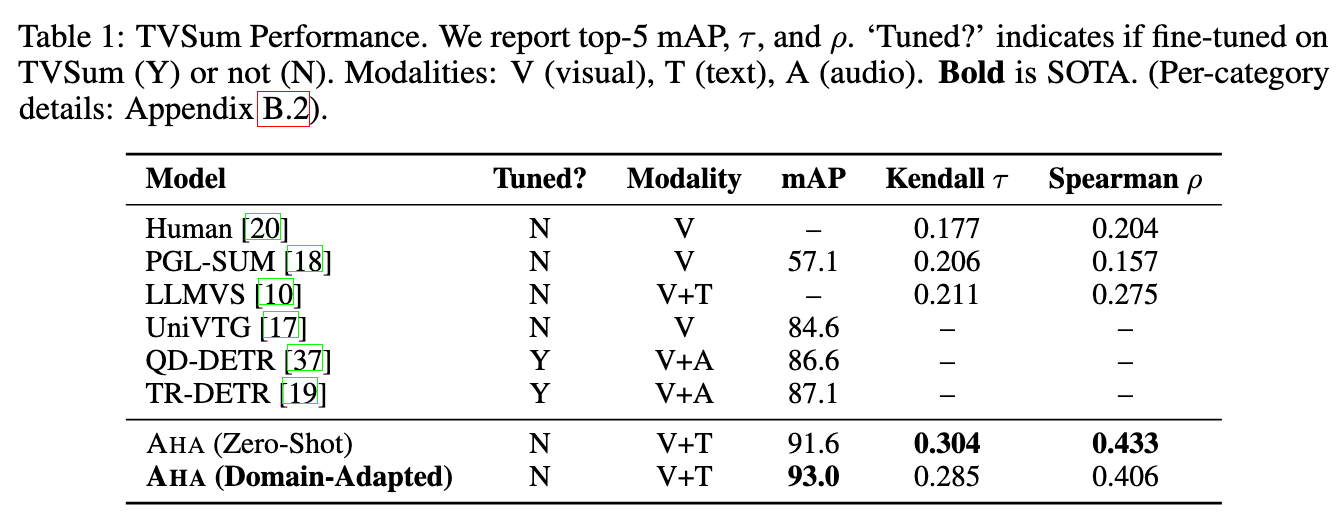
1. TVSum基准(50个视频,小规模但经典)
| 模型 | 是否微调 | mAP | Kendall τ | Spearman ρ |
|---|---|---|---|---|
| TR-DETR(之前最佳离线) | 是 | 87.1 | - | - |
| AHA(零样本) | 否 | 91.6 | 0.304 | 0.433 |
| AHA(域适应) | 否 | 93.0 | 0.285 | 0.406 |
发现:AHA零样本就超越了所有经过TVSum专门微调的离线模型,且排名相关性指标(τ和ρ)全面领先。这说明大规模预训练+在线因果建模的泛化能力极强。
2. Mr.Hisum基准(大规模,测试集独立)
仅用相关性头(β=1,其余为0)就在测试集上达到:
- mAP@50: 64.19(比之前最佳高8.3)
- mAP@15: 32.66(比之前最佳高5.2)
证明从HIHD学到的用户参与模式能有效迁移到未见过的视频。
3. 消融实验揭示的关键事实
- 去掉相关性头(β=0):mAP暴跌15.7 → 相关性是核心
- 去掉信息量头(α=0):mAP降9.8 → 新颖性信号很重要
- 去掉语言条件(空任务):mAP降11.8 → 任务描述是灵魂
- 动态权重融合 vs 静态网格搜索:动态方法(MLP门控、EMA适配器)不稳定且性能差(87.9/87.5),静态网格搜索达到最优93.0
4. 真实机器人视频(SCOUT数据集)
一段20分钟的第一人称救灾机器人视频,充满运动模糊、黑屏、畸变。AHA实时打分后经平滑处理,在8分钟分析中:
- 16/18个预测峰值 精确对应人类操作员的语音指令(如“机器人拍张鞋子的特写”)或关键动作
- 即使在没有指令时,模型也能因视觉显著性产生峰值(可能对应潜在兴趣点)
这证明了AHA在非互联网域、长时程、恶劣条件下的实用价值。
五、局限性与未来方向
论文坦诚讨论了几个开放问题:
- 不确定性头的监督缺失:当前用无监督NLL损失,未来可用MultiVENT-G等带人工置信度标注的数据集进行有监督校准。
- 训练效率与骨干网络:受算力限制,只在Qwen2-7B上验证,未来可测试更小或更大的VLM,或蒸馏轻量版。
- 静态权重融合:虽然静态方案稳定且SOTA,但自适应权重仍是值得探索的方向。
- 训练时的记忆限制:训练用固定窗口,未跨片段持久记忆,可能影响全局推理。
- 伦理风险:可能被用于大规模监控,作者建议配合隐私保护(人脸模糊)和伦理审查。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 2
2 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)