EWAM:一种用于具身智能闭环在线自适应的增强型世界动作模型
26年6月来自Astronex Robotics和南京信息工程大学的论文“EWAM: An Enhanced World Action Model for Closed-Loop Online Adaptation in Embodied Intelligence”。
在开放环境中部署机器人时,收集能够涵盖各种物体姿态、场景布局及执行过程中突发状况的演示数据,其高昂成本始终是一大制约因素。尽管“世界动作模型”(World Action Models, WAMs)将未来状态预测与动作生成相结合,但静态离线流程仍易出现执行层面的偏差,例如碰撞、抓取落空以及由感知错误引发的“幻觉”现象。为此,提出“增强型世界动作模型”(Enhanced World Action Model, EWAM)。这是一种基于预训练且参数冻结的 Cosmos3-Nano-Policy-DROID 骨干网络构建的闭环在线自适应架构,并在零样本(zero-shot)任务协议下进行了评估。
EWAM 在冻结的策略路径中增加四个可训练层:位于DiT内部的神经经验记忆层、位于状态预测头之后的神经异常检测层、位于异常检测之后的神经策略路由层,以及位于动作输出头之后的神经动作校正层。其中,记忆检索功能提供与任务相关的执行上下文;异常检测监控预测与实际执行之间的偏差;路由机制负责选择直接执行、保守重规划或回滚恢复策略;动作校正层则利用执行诊断信息对生成的动作片段进行精细调整。在 BananaInBowlTask(香蕉放入碗中任务)的本地测试中,EWAM 不仅保持 Cosmos3-Nano-Policy-DROID 100% 的任务成功率,还将单次任务的完成时间从 25.60 秒缩短至 9.27 秒,路径长度从 1.81 米减至 0.83 米,并将总执行故障次数从 13.5 次降低至 2.2 次。
如图 1 展示基于Cosmos3-Nano–Policy-DROID构建的EWAM架构。该架构的主干包含三个主要组件:(1) 用于多模态感知的视觉-语言编码器(VLE),(2) 用于长程任务规划的自回归(AR)推理器,以及 (3) 用于动作生成的扩散Transformer(DiT)。其引入四个神经层以实现闭环在线自适应:
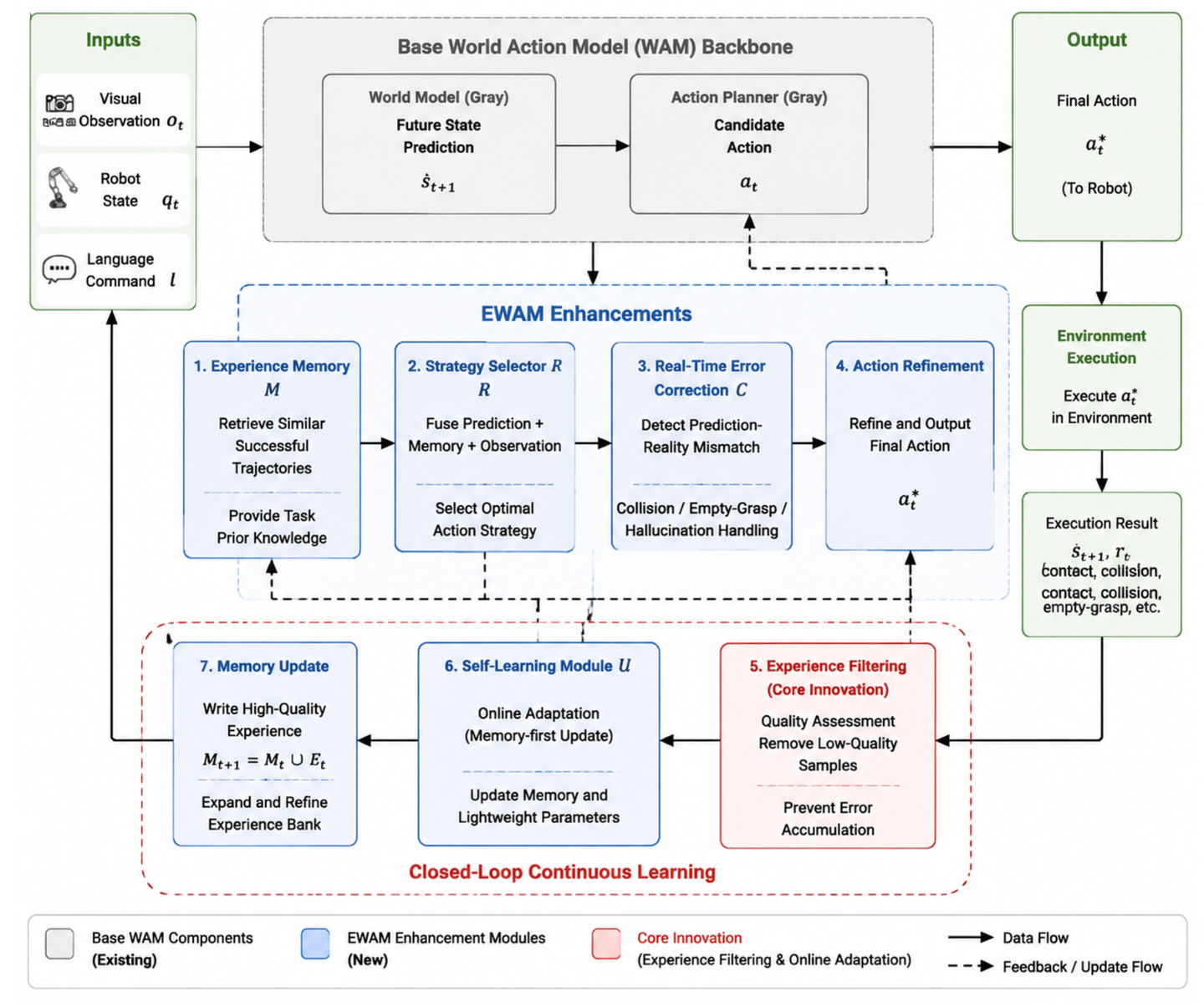
神经经验记忆层(位于DiT中间层):该层插入DiT的第lmem层,从记忆M中检索与任务相关的经验,并将其注入DiT的隐表征中。这使得扩散过程能够同时基于当前上下文和检索的历史经验进行条件化生成。
神经异常检测层(位于状态预测头之后):该层利用预测状态 sˆ_t+1、当前状态 s_t、原始动作候选序列 a^0_t:t+H 以及DiT隐状态,检测执行过程中的异常情况,包括预测与实际不符、碰撞风险、抓取失败(空抓)、感知幻觉以及力控违规。
神经策略路由层(位于异常检测之后):该层根据异常检测结果 ι_t 选择合适的执行策略:直接执行、保守重规划或回滚恢复。它输出路由决策 r_t,用于调节动作修正过程。
神经动作修正层(位于动作输出头之后):该层根据异常信号 ι_t、路由决策 r_t 和记忆上下文M,对原始动作输出 a^0_t:t+H 进行精细调整。它在去噪阶段执行修正,以确保执行过程既安全又高效。
Cosmos3-Nano–Policy-DROID主干参数 phi 保持冻结;仅训练四个神经层的参数 theta 和轻量级适配器(adapters),从而在保留预训练知识的同时实现高效自适应。
神经经验记忆层(Neural Experience Memory Layer)被插入到 DiT 的中间层 l_mem 处。它充当扩散过程与经验记忆 M 之间的桥梁,使得动作生成能够同时基于当前上下文和检索的历史经验。
神经异常检测层(Neural Anomaly Detection Layer)被插入在状态和原始动作预测之后。在决策时刻,它结合先前的预测残差、候选动作的动力学一致性以及学习到的风险评分。在执行修正后的动作后,实际发生的转移残差会被写入经验记录,并用于筛选和在线更新。
神经策略路由层(Neural Policy Routing Layer)被插入在异常检测层之后。它根据异常信号 ι_t、AR 上下文 c_t 和记忆 M 来选择合适的执行策略。
神经动作修正层(Neural Action Correction Layer)被插入在动作输出头之后。它根据异常信号 ι_t、路由决策 r_t 和记忆上下文 M 对原始动作输出 a^0_t:t+H 进行精细化调整。
在线学习流程如图 2 所示。EWAM 作为一个闭环系统运行,其数据流如下:
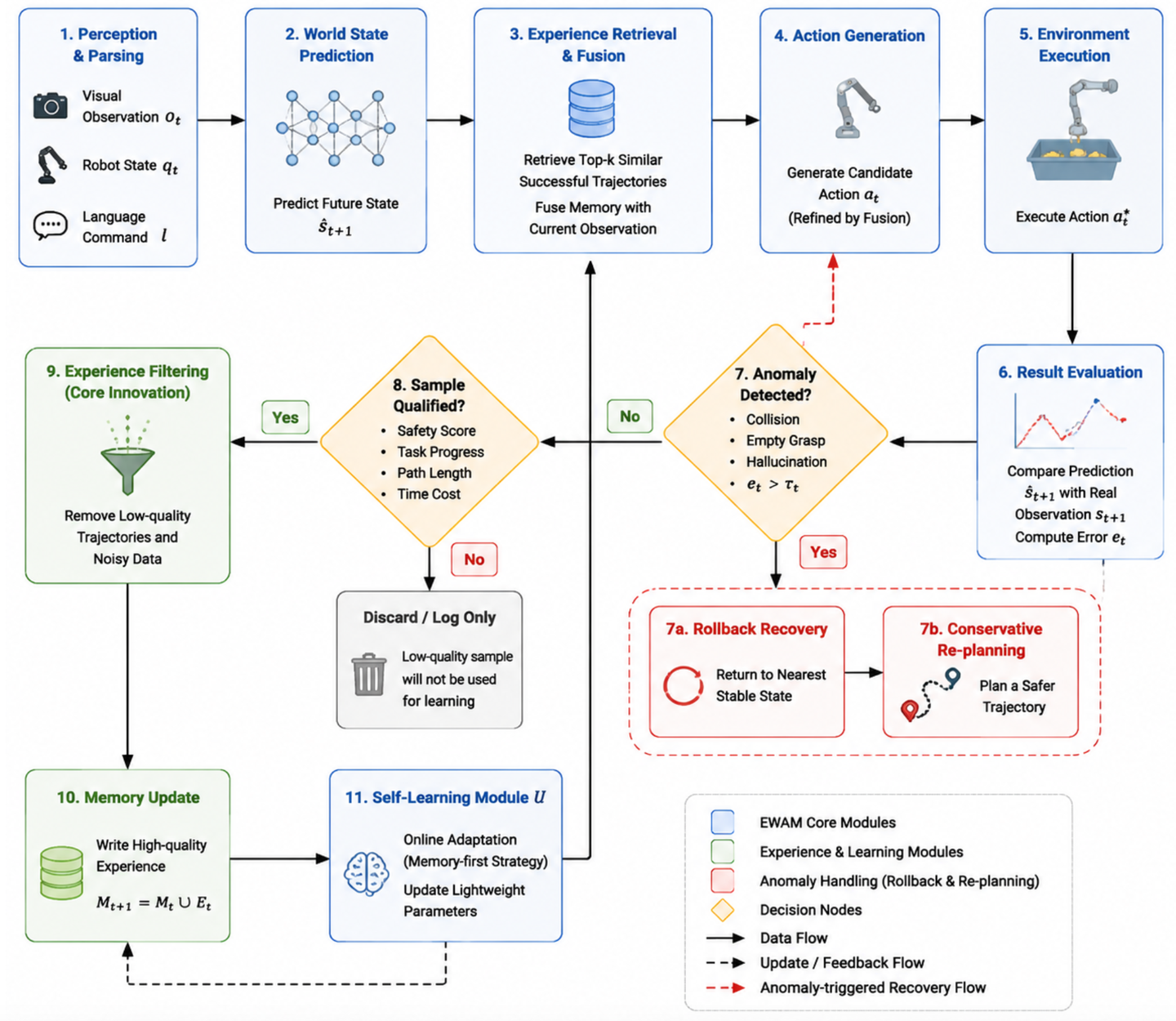
- 感知 → VLE 编码:原始视觉观测 o_t 和本体感觉状态 q_t 经由视觉-语言编码器(Vision-Language Encoder)编码,生成 h_VLE。
- 编码 → AR 推理:自回归推理器(Autoregressive Reasoner)处理 h_VLE,生成推理上下文 c_t。
- 推理 → 具有记忆增强功能的 DiT:DiT 利用记忆增强中间层(位于 l_mem = 6 处的神经经验记忆层)处理自回归 Token,并从 M 中检索相关经验。
- DiT 输出 → 状态/动作候选:状态预测头生成 s^_t+1,动作头生成原始动作片段 a^0_t:t+H。
- 状态/动作候选 → 异常检测:神经异常检测层结合先前的预测残差、候选动作的动力学一致性以及学习的风险评分,生成异常向量 ι_t。
- 异常检测 → 策略路由:神经策略路由层根据 ι_t 选择执行策略 r_t {direct, conservative, rollback}。
- 路由 + DiT 输出 → 动作修正:神经动作修正层(Neural Action Correction Layer)根据 ι_t、r_t 和记忆上下文,将原始动作 a^0_t:t+H 优化为修正后的动作 a^*_t:t+H。
- 修正后的动作 → 环境执行:修正后的动作在环境中执行。
- 执行结果 → 经验筛选:执行结果由经验过滤器进行评估;只有合格的轨迹才能进入下一阶段。
- 筛选后的经验 → 记忆/参数更新:合格的轨迹被写入经验记忆 M;神经层会进行间歇性的参数更新。
当神经异常检测层(Neural Anomaly Detection Layer)检测到预测误差、碰撞风险、抓取失败(空抓)或幻觉时,该循环会触发保守的重新规划;若检测到严重异常,则触发回滚恢复机制。只有合格的轨迹才会被写入记忆并用于神经层参数更新。
设计理念:针对零样本(zero-shot)评估,采用“记忆优先、适配器次之”的策略。在额外任务数据有限的情况下,若直接利用稀疏的在线经验更新预训练的 WAM 主干网络,存在“灾难性遗忘”的风险,即模型可能丧失从原始数据集学到的通用能力。因此,EWAM 采取了保守的适配策略:
- 即时记忆检索:当新任务开始时,系统首先从记忆中检索相关经验(k = 5 个最近邻),以提供特定于任务的上下文信息。这种基于检索的适配是即时的,且不会修改任何模型参数。
- 保守的参数更新:在线参数更新仅间歇性进行,且仅作用于轻量级的神经层适配器,而不影响已冻结的 Cosmos3-Nano–Policy-DROID 主干网络。这既保留了模型的通用零样本能力,又实现了渐进式适配。
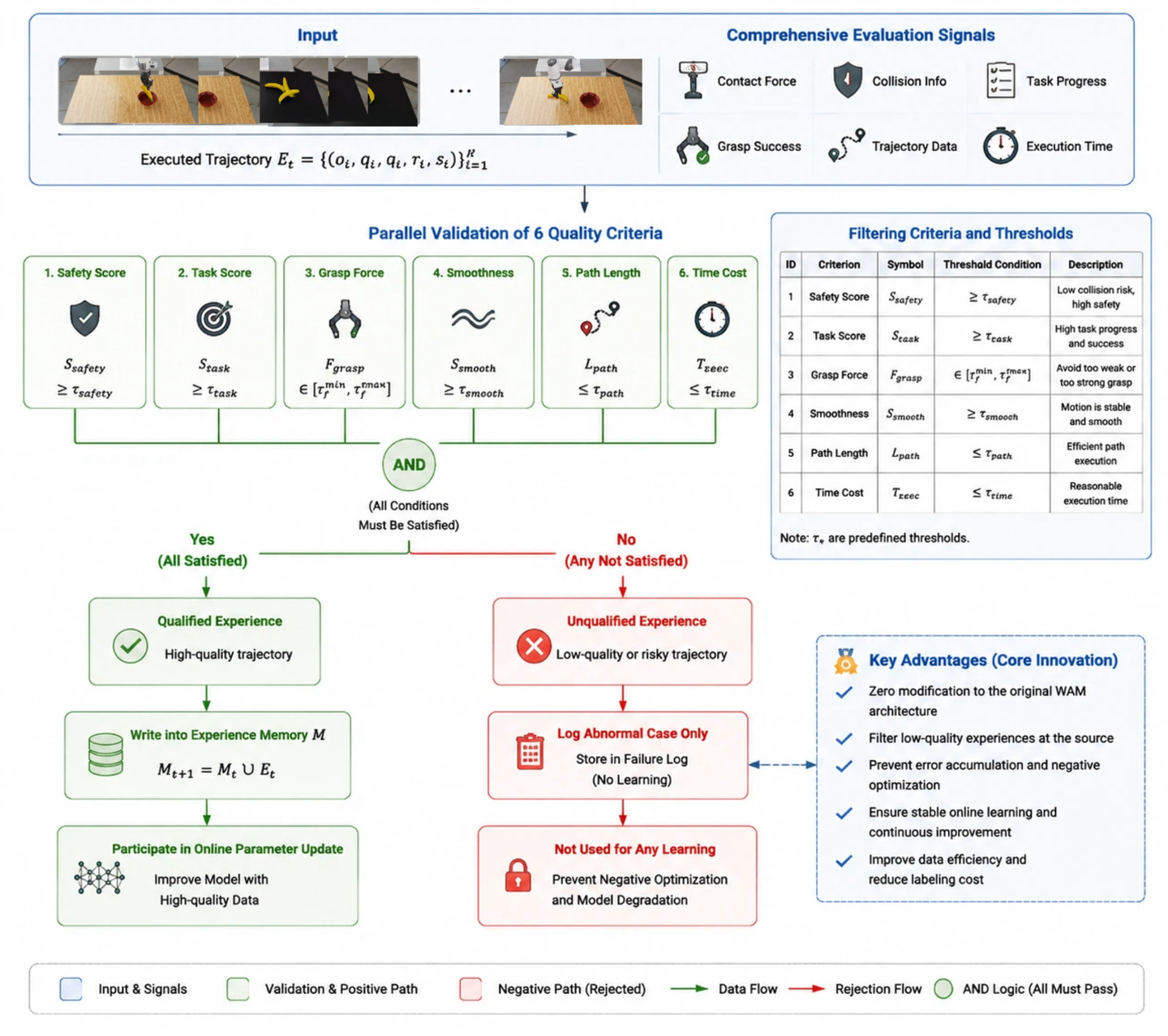
- 经验滤波:只有高质量的轨迹(通过所有安全性和效率检查)才会被写入记忆。这防止了错误行为污染经验数据库。
消融实验结果支持了这一设计:仅使用记忆(12.67秒)的表现优于仅进行参数更新(14.67秒),这表明在此场景下,基于检索的适配,比利用稀疏在线数据进行即时参数更新更为有效。离线准备阶段遵循基础 WAM 目标,并在有模拟器标签或既定恢复目标可用时,为四个神经层增加监督损失。
未经筛选的在线学习可能会吸纳不安全的轨迹,导致策略向错误方向更新。因此,EWAM 在执行记忆写入或参数更新之前,会先应用一道质量门控机制。
规则设计依据。上述六个过滤阈值是针对特定场景设定的:它们是为 RoboLab 容器操作任务(如 BananaInBowlTask 和 BananasInBinOneMoreTask)选定的,体现了与任务相关的安全性(夹爪力限制)、效率(路径长度、任务耗时)及成功标准(任务得分、安全得分、SPARC 指标)。这些阈值并非普适性的;它们蕴含了关于目标部署环境下何为高质量轨迹的领域知识。如图 3 将准入判定、拒绝分支及记忆更新路径与过滤公式并列展示,从而确保直观的视觉呈现出现在方法部分。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 2
2 0
0- 0



 已为社区贡献350条内容
已为社区贡献350条内容

所有评论(0)