VLA-Adapter论文解读(四):L1-based Policy的轻量化设计
论文链接:[2509.09372] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
项目主页:VLA-Adapter
在VLA-Adapter论文中,L1策略网络(L1-based Policy)指的是采用L1损失函数进行训练,以直接回归方式生成连续动作的策略网络。它是VLA-Adapter最终采用的动作生成模块,与基于扩散模型的DiT策略网络形成对比。
一、L1策略网络基本概念
VLA-Adapter框架中的策略网络(Policy Network)负责将VLM提供的条件特征转化为可执行的动作指令。输入为Raw特征、ActionQuery特征、本体感受状态以及初始动作(全零);输出长度为8的动作块,即未来8个时间步的7维动作向量,参数量大约为97M。
传统的VLA模型通常采用离散化Token预测或者扩散去噪生成的方式输出动作。而L1策略网络选择了更直接的路径——把动作生成视为一个回归问题:模型直接预测连续动作值,并通过最小化预测值与真实值之间的L1误差来训练。这种设计的优势在于单次前向传播即可输出完整动作块,无需多步迭代,连续输出无需离散化,避免量化误差;97M的参数轻量高效,推理速度达到219.2Hz。
L1策略网络采用L1 Loss(平均绝对误差,MAE)作为训练目标。给定预测动作和真实动作
,损失函数为:
,
即预测动作与真实动作之间绝对差值的平均值。在机器人动作数据中,可能存在少量标注噪声或异常轨迹,L1 Loss对异常值不敏感的特性使得训练更加稳定。
L1的网络结构是一个24层的Transformer解码器,与VLM层数的(M=24)逐层对齐。每一层都由Bridge Attention(三路注意力融合)和FFN(前馈网络)组成。Bridge Attention让动作隐变量主动查询VLM对应层的Raw和AQ特征,FFN则对融合后的特征进行非线性变换。
L1策略网络是VLA-Adapter的动作生成模块,它用L1损失函数直接回归连续动作值,以97M参数和单次前向传播实现了219Hz的推理速度,在微调场景下优于更复杂的扩散策略。
二、L1-based Policy的详细架构
2.1 整体流程
L1-based Policy的输入为VLM提供的条件特征(Raw + AQ)和机器人状态信息,输出是H=8步的动作块,其详细架构如图1所示。
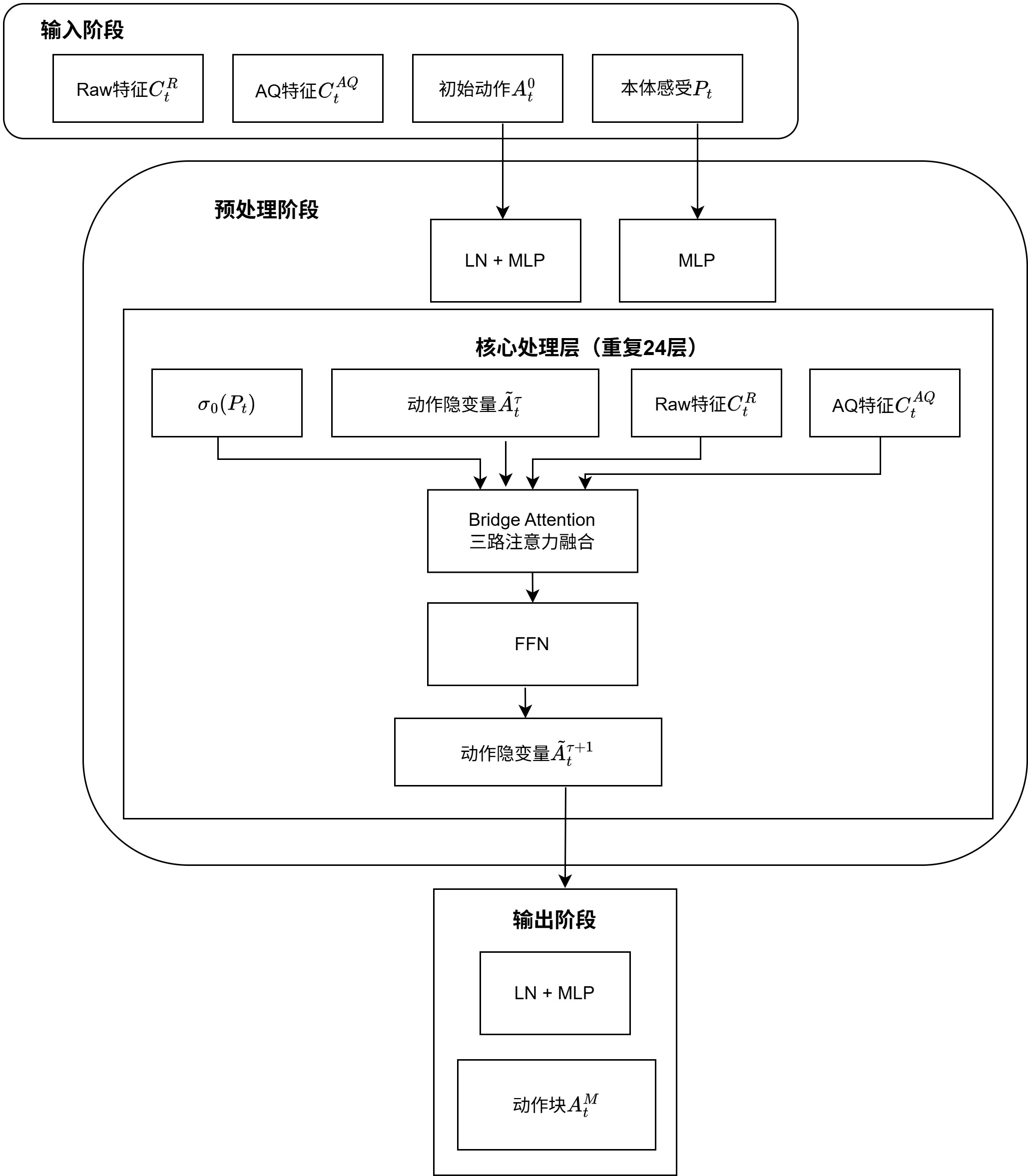
其中,每一层的Policy由两个核心组件构成:Bridge Attention + FFN。在机器人动作回归当中,数据中可能存在少量异常标注或者极端值。L1 Loss对异常值不敏感,因此训练会更加稳定。此外,L1 Loss的梯度恒定,有利于模型在训练后期进行精细化调整。
2.3 损失函数
给定一个批次的数据,模型的目标是最小化预测动作与真实动作之间的L1距离:
训练配置:
- 优化器:AdamW
- 学习率:1e-4
- 学习率调度:Cosine Annealing with Warmup (10%)
- Batch Size:16
- 训练步数:150,000
- 动作块长度(H):8
- Policy层数(M):24
L1-based Policy是VLA-Adapter的动作生成模块,作为一个24层Transformer解码器,从全零动作出发,每层通过Bridge Attention主动查询VLM对应层的Raw和AQ特征,并利用自注意力建模动作时序,最后用L1损失函数直接回归连续动作值,以97M参数和单次前向传播实现了219Hz的推理速度,在微调场景下更优于复杂的扩散策略。整个过程“从零开始,逐层迭代,一步到位”。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)