调查研究-209 Apptronik Robot Park 深度解析:人形机器人竞争,开始拼“真实世界数据工厂“
Apptronik Robot Park 深度解析:人形机器人下半场,开始拼「真实世界数据工厂」(Apollo 2 双形态, 2026)
TL;DR
- 场景:2026 年 6 月 30 日,Apptronik 在美国德州奥斯汀开放接近 9 万平方英尺的 Robot Park,并展示同时具备双足与轮式两种形态的 Apollo 2 人形机器人平台。
- 结论:人形机器人行业的竞争焦点,正在从「谁的 Demo 更炫」转向「谁能稳定生产真实世界任务数据」;Robot Park 的本质是物理世界里的数据生产线,与 Google DeepMind 的 Gemini Robotics 1.5 形成「模型 × 数据 × 硬件」闭环。
- 产出:一篇能落地的工程解读,覆盖 Apollo 2 双形态数据策略、机器人语音模块从 ASR+TTS 升级为任务入口的 7 类必记数据、可执行的事件结构样例,以及面向真实部署的语音-任务闭环设计。
版本矩阵
| 功能 / 事实 | 状态 | 说明 |
|---|---|---|
| Apptronik Robot Park 开放 | ✅ 已验证 | 2026-06-30 官宣,奥斯汀,~9 万平方英尺 |
| Apollo 2 双足形态 | ✅ 已验证 | 2026-06-26 在 Apptronik 官网首次亮相 |
| Apollo 2 轮式形态 | ✅ 已验证 | 与双足版同发,模块化共用上身/感知/任务系统 |
| Apptronik × Google DeepMind 合作 | ✅ 已验证 | 2024 年起持续推进;用于 Gemini Robotics 模型训练 |
| Gemini Robotics 1.5(VLA 模型) | ✅ 已验证 | 2025-09-25 DeepMind 发布 |
| Gemini Robotics-ER 1.5(具身推理) | ✅ 已验证 | 与 VLA 1.5 同步,扩展具身推理与跨形态迁移 |
| Apptronik 累计融资 ≈ 10 亿美元 | ✅ 已验证 | 2025 A 轮 ~$4.15 亿 + 2026-02 A-X 轮 $5.2 亿 |
| Apptronik 投后估值 ≈ $53 亿(2026-02) | ✅ 已验证 | TechCrunch 独家披露 |
| 投资者阵容(B Capital、Google、Mercedes、PEAK6 等) | ✅ 已验证 | 含 AT&T Ventures、John Deere、Qatar Investment Authority 等 |
| Apollo 2 已在客户场景规模化商用 | ⚠️ 待验证 | 官方口径仍以数据采集/试点为主,Apollo 3 才定位为未来商业化产品 |
| Robot Park 单年数据生产规模 | ⚠️ 待验证 | 官方未披露具体任务小时/失败率/标注量 |

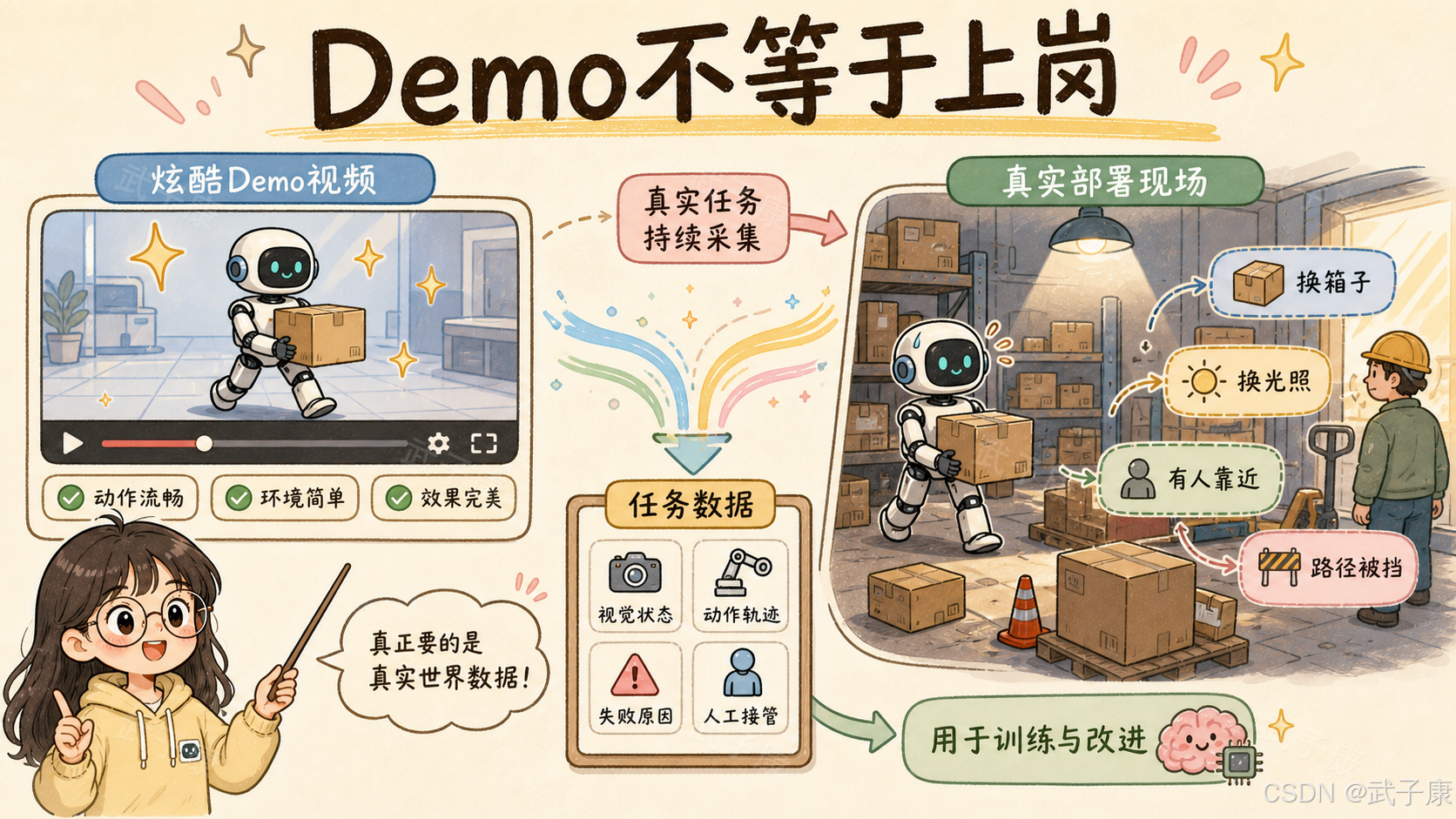
1. Robot Park 不是普通训练场,而是机器人数据工厂
过去几年,人形机器人行业最常见的传播方式是视频。
搬箱子、分拣、开门、叠衣服、走路、跳舞、和人对话。这些 Demo 有价值,因为它们证明了硬件、控制和感知系统已经能完成一些基本动作。
但 Demo 解决不了一个更现实的问题:
机器人能不能每天稳定完成重复任务?
真实部署关心的是另一组指标。
换一个箱子,它还能不能抓稳?换一个货架,它还能不能定位?光照变暗、地面摩擦变化、旁边有人经过、路径突然被挡住,它会不会做出危险动作?任务失败时,它知道失败发生在感知、规划、抓取、导航,还是用户指令理解阶段吗?
这些问题不是靠一条展示视频解决的,而是靠大量真实任务数据解决的。
Apptronik 对 Robot Park 的描述很直接:Apollo 2 会在多个 Robot Park 和客户现场持续采集真实世界数据,覆盖物流、制造、零售等任务场景。官方还提到,Apollo 2 会通过遥操作和自主执行生成高质量训练数据,这些数据用于训练和改进 Gemini Robotics 模型。
这意味着 Robot Park 更像一个物理世界里的数据生产线。
过去大模型吃的是互联网文本、代码、图片、视频和偏好数据。机器人模型要吃的东西完全不同:视觉状态、动作轨迹、语音指令、力反馈、失败样本、人工接管、环境扰动、安全停机、任务恢复。
这些数据无法简单从互联网上爬取。它必须真实发生在物理世界里。
2. 人形机器人真正缺的不是硬件,而是泛化数据
机器人硬件当然重要。
电机、关节、传感器、手部结构、电池、安全外壳、散热、可靠性、维护成本,任何一项不过关,机器人都无法进入长期工作状态。
但当硬件达到"基本可用"之后,真正拉开差距的是泛化能力。
物理世界非常混乱。
同一个"把箱子放到货架上"的任务,在模型眼里并不是一个任务,而是无数个细分任务:箱子大小不同、重量不同、材质不同、摆放角度不同、遮挡不同、货架高度不同、地面摩擦不同、旁边是否有人不同、目标位置不同、任务优先级不同。
机器人不是在执行一个抽象命令,而是在连续变化的物理状态中做决策。
这也是 Gemini Robotics 这类模型要解决的问题。Google DeepMind 对 Gemini Robotics 的定位是让机器人感知、推理、使用工具并与人交互,处理复杂真实世界任务。Gemini Robotics 1.5 被描述为 VLA 模型,也就是 Vision-Language-Action:它要把视觉信息和用户指令转换成实际动作。页面还强调多步任务、动态交互和跨形态学习能力。
例如用户说:
把前面的箱子搬到左边架子上。
机器人需要理解的不只是这句话。
它要判断"前面的箱子"是哪一个物体,"左边架子"在当前空间中的位置,箱子是否可搬,路径是否安全,抓取点在哪里,是否需要先确认,当前动作执行到哪一步,失败后如何恢复,什么时候必须让人接管。
这不是传统语音助手问题,而是具身智能问题。
3. Apptronik 与 Google DeepMind 的组合逻辑
Apptronik 和 Google DeepMind 的合作不是突然出现的。
Apptronik 早在 2024 年就宣布与 Google DeepMind Robotics 建立战略合作。Apptronik 的优势在机器人平台、硬件工程、真实客户场景和部署经验;Google DeepMind 的优势在基础模型、具身推理和跨形态学习。
这次 Robot Park 与 Apollo 2 的发布,可以理解成双方合作进一步进入"数据生产基础设施"阶段。
Apptronik 需要更强的机器人智能,DeepMind 需要真实机器人数据。
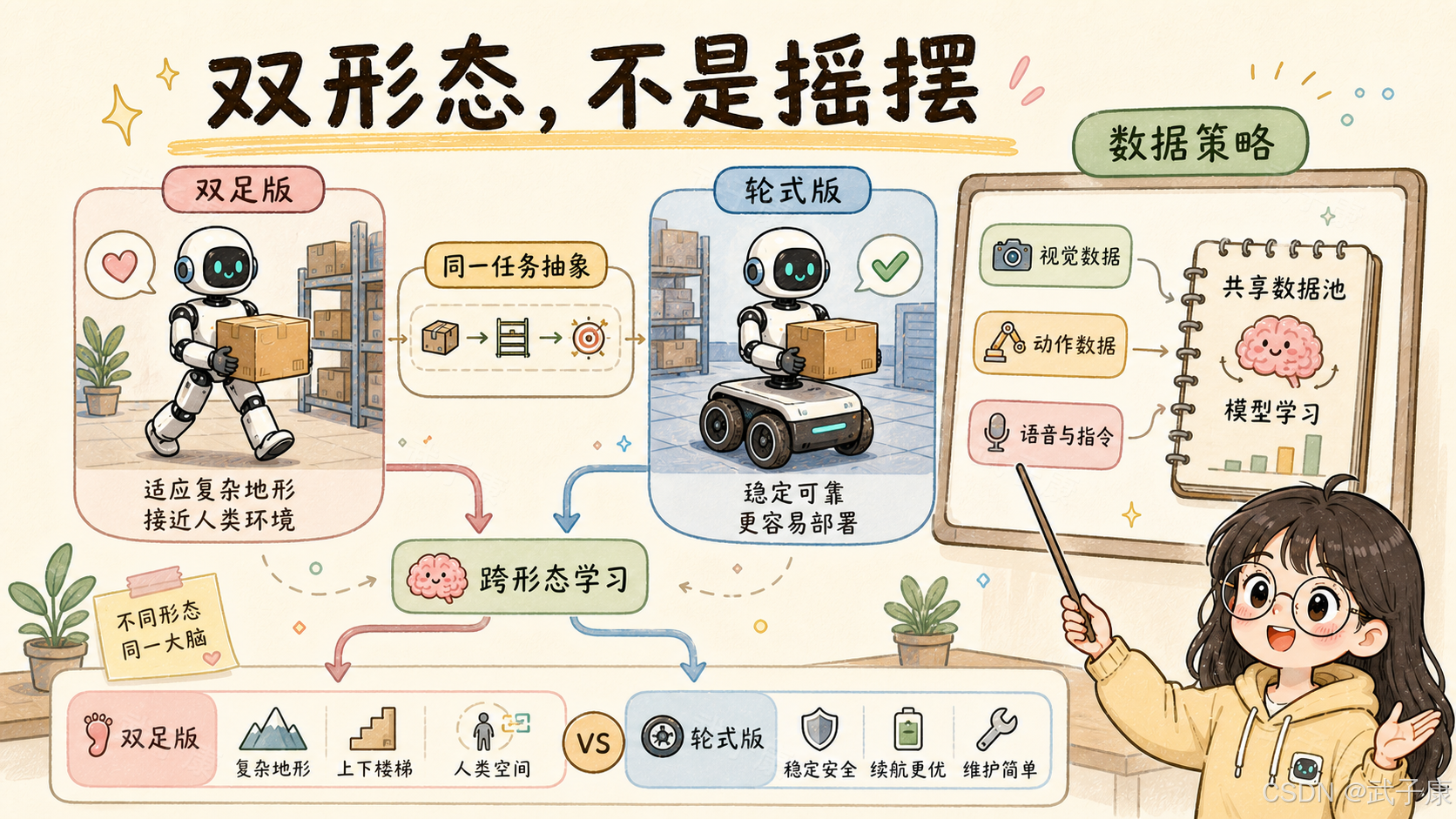
这也是 Apollo 2 同时提供双足和轮式配置的原因。
双足机器人更接近长期想象中的通用人形平台,可以适应楼梯、狭窄空间和人类环境。但双足也更难、更贵、更不稳定,安全和能耗挑战更大。
轮式机器人则更接近当前工业部署形态。它稳定、可控,更容易符合现有工业移动机器人安全标准,也更适合在仓储、制造和物流场景中先跑起来。
Apptronik 官方也提到,Apollo 2 的模块化设计可以让同一套核心人形技术在不同配置上部署:轮式形态更贴近当前客户运营和安全标准,双足形态则用于继续验证复杂环境下的适应性、安全和可靠性。
这不是路线摇摆,而是数据策略。
如果同一个上身、感知系统、任务系统和操作策略可以在不同底盘形态上采集任务数据,那么未来模型就有机会学习跨形态的任务抽象。
4. 新壁垒:真实世界数据生产能力
过去机器人公司的壁垒通常被理解成三件事:
硬件工程能力
运动控制能力
融资和供应链能力
现在正在增加第四个壁垒:
真实世界数据生产能力
这类数据有几个特点。
第一,它很贵。每一条高质量数据背后都有机器人、场地、操作员、维护、标注、失败复盘和安全测试成本。
第二,它很慢。文本和图片可以批量抓取,机器人动作必须真实执行,采集速度受物理时间限制。
第三,它很稀缺。成功样本有价值,但失败样本、安全边界、人类打断、人工接管记录更有价值,也更难系统性收集。
第四,它很难标准化。不同机器人形态、传感器、关节、控制频率、任务环境会产生不同数据格式。想让模型跨平台学习,就必须把数据结构、任务抽象和评测方法做出来。
这也是 Robot Park 的意义超过一次普通产品发布的地方。
它说明 Apptronik 和 Google DeepMind 不只是想做机器人演示,而是在建设机器人模型训练的底层生产线。
对比大语言模型,过去谁能拿到更多高质量文本、代码、偏好和反馈数据,谁就更可能训练出更强模型。到了机器人时代,谁能低成本、稳定、持续地产生真实世界任务数据,谁就更可能建立长期优势。
不过这里也要保持克制。
Robot Park 证明的是数据生产能力正在被系统化建设,不等于人形机器人已经进入大规模成熟商用。Apollo 2 在官方口径里仍然更像数据采集和训练平台,Apollo 3 才被描述为未来商业化产品方向。也就是说,行业正在从"演示可行"走向"试点可用",但距离大规模 ROI 闭环还有很多工程问题。
5. 为什么机器人语音模块不能只做 ASR + TTS
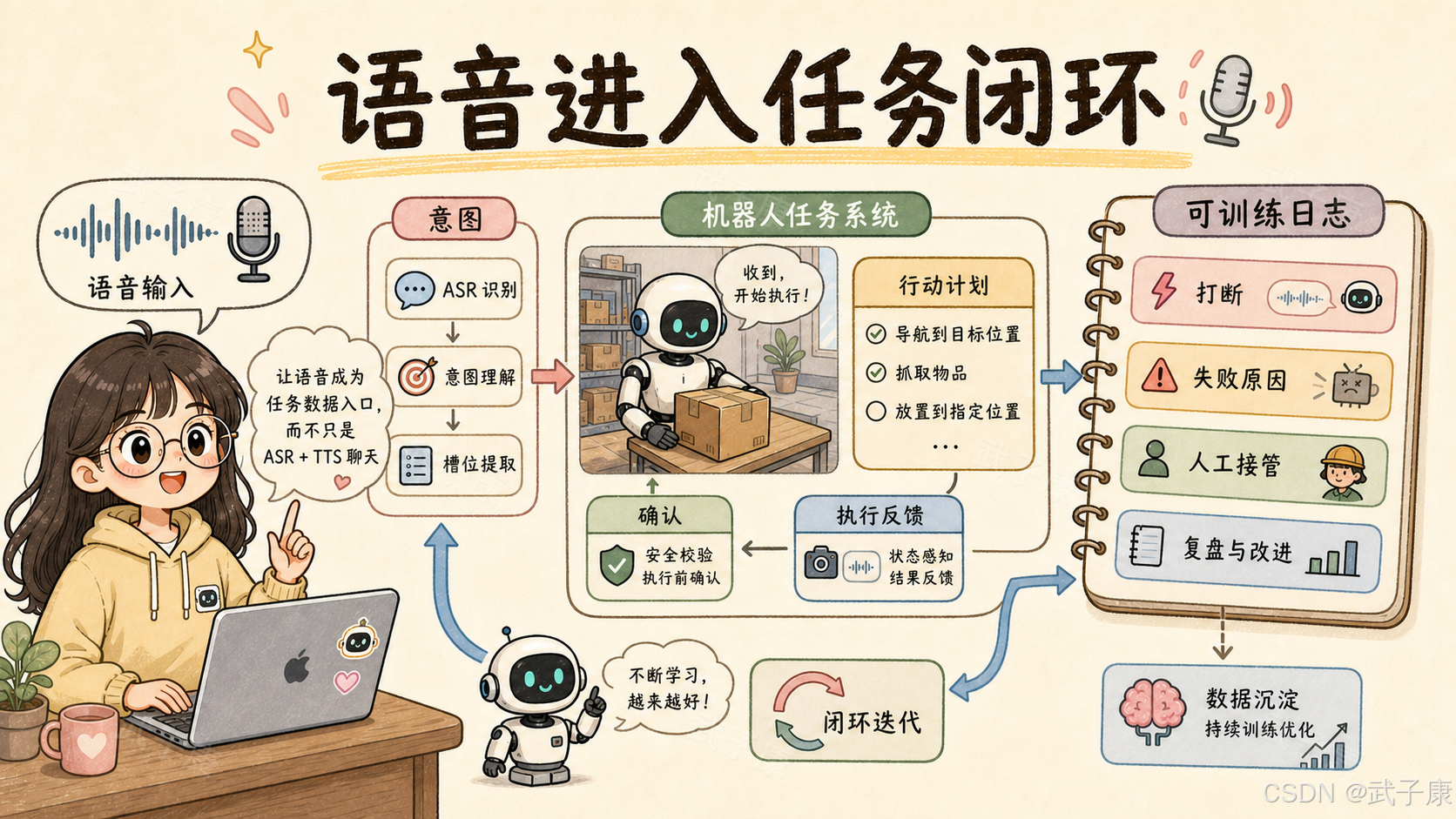
这件事对机器人语音系统有一个很直接的启发:语音模块不能只被看成"让机器人能聊天"的模块。
在真实机器人系统里,语音应该成为任务数据入口。
因为人和机器人交互时,很多关键信息首先通过语音出现:
用户想让机器人做什么
用户是否表达了紧急性
用户是否在纠正机器人
用户是否打断了任务
用户是否对结果满意
用户是否授权机器人继续动作
用户是否指出了环境变化
用户是否因为不信任而接管
这些信息如果只被 ASR 转成文本,再丢给 LLM 生成一句回复,就浪费了。
真正有价值的做法是:每一次语音交互都进入任务日志,并和机器人状态、视觉状态、动作执行结果、失败原因绑定起来。
例如用户说:
停一下,别往前了。
普通语音助手会识别成 stop 指令,然后结束。
机器人数据系统应该记录:
原始音频
ASR 文本
唤醒词与声源方向
当前 task_id
当前机器人位置
当前动作类型
打断发生时间点
打断前 3 秒视觉帧
打断前动作轨迹
是否触发安全停机
用户打断原因分类
后续是否人工接管
任务是否恢复
最终是否成功
这才是机器人语音模块的长期价值。
6. 面向机器人任务闭环的事件结构
如果把语音模块升级为任务系统入口,每一次交互都应该沉淀成结构化事件。
示例:
{
"session_id": "s_20260701_001",
"task_id": "t_move_box_001",
"timestamp": "2026-07-01T10:20:30Z",
"user_utterance": "帮我把前面的箱子搬到左边",
"asr_text": "帮我把前面的箱子搬到左边",
"intent": "move_object",
"target_object": "box",
"target_location": "left_shelf",
"confidence": 0.82,
"requires_confirmation": true,
"confirmation_result": "confirmed",
"robot_state": {
"pose": "...",
"battery": 72,
"current_mode": "idle"
},
"environment_state": {
"human_nearby": true,
"obstacle_detected": false
},
"action_plan": [
"locate_box",
"approach_box",
"grasp_box",
"move_to_left_shelf",
"place_box"
],
"execution_result": "failed",
"failure_reason": "grasp_slip",
"interrupted": false,
"handover_required": true
}
这类数据现在看起来像日志,未来就是训练数据。
它能反哺三类系统。
第一,反哺 Agent。哪些用户指令最常见,哪些表达最容易歧义,哪些任务最容易失败,哪些场景需要二次确认,都可以用于优化任务规划。
第二,反哺运控和工具链。失败发生在抓取、移动、避障、放置、路径规划还是视觉识别阶段,可以逐步定位机器人能力短板。
第三,反哺产品闭环。用户真正高频想让机器人做的任务,不一定是产品经理想象的任务。语音交互会暴露真实需求。
7. 机器人数据闭环至少要记录什么
如果以 Robot Park 的逻辑反推,一个面向真实部署的机器人语音系统,至少要记录七类数据。
第一,意图数据。用户说了什么,系统识别成什么任务,是否存在歧义,是否需要追问。
第二,确认数据。哪些动作需要用户确认,用户是否确认,确认前机器人给出的解释是什么。
第三,动作结果。任务是否成功,成功耗时多少,失败发生在哪个阶段。
第四,失败原因。是 ASR 错误、LLM 规划错误、工具调用错误、导航失败、抓取失败、视觉识别错误,还是用户临时改变目标。
第五,打断数据。用户什么时候打断,打断前机器人在做什么,打断是否因为安全风险。
第六,环境状态。是否有人靠近,是否有障碍物,是否处于噪声环境,是否光照不足,是否目标物被遮挡。
第七,人工接管。什么时候接管,谁接管,接管前系统已经做了什么,接管后任务如何完成。
这里的重点不是"日志越多越好"。
真正有价值的数据必须围绕任务闭环设计,并且能回答一个问题:
机器人为什么成功?
机器人为什么失败?
下次如何更稳?
如果回答不了这个问题,日志再多也只是噪声。
8. 语音模块的产品定位要升级
很多机器人项目会把语音模块放在很靠外的位置:
ASR 识别
LLM 对话
TTS 播报
控制指令下发
这个定位太低。
在真实机器人产品里,语音模块应该是"人类意图到机器人任务系统"的入口层。它连接用户、Agent、工具、运控、安全系统和数据系统。
它至少要承担五个职责:
理解用户目标
判断是否需要确认
把自然语言转成可执行任务
在任务执行中处理打断和修正
把全过程沉淀为可训练、可复盘、可评测的数据
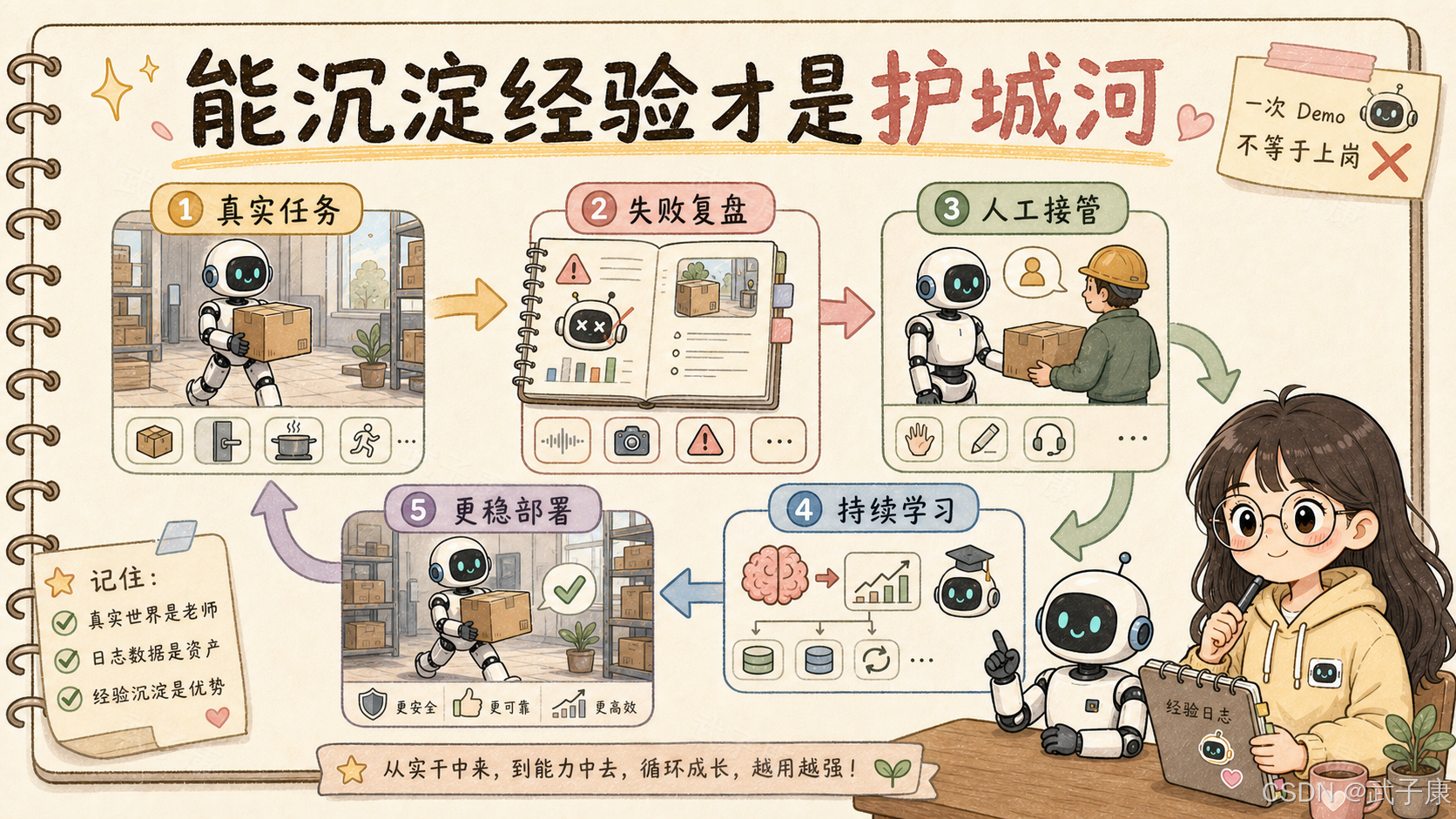
也就是说,语音模块不是机器人身上的"嘴"和"耳朵",而是任务闭环的入口。
这也是 Robot Park 对行业最重要的信号。
人形机器人接下来比的不只是"能不能动",而是能不能在真实或接近真实的场景中持续工作、持续产生数据、持续修正模型、持续降低失败率。
Apptronik 的 Robot Park、Google DeepMind 的 Gemini Robotics、Apollo 2 的双形态平台,本质上都指向同一个方向:
把机器人变成可训练、可部署、可评估、可迭代的系统。
对机器人语音系统来说,也同样如此。
能聊天不够。
能把人的意图、确认、打断、失败、接管和环境状态沉淀下来,才算真正进入机器人智能闭环。
参考资料
- Apptronik: Welcome to Robot Park: Where Apptronik’s Apollo Goes to Work
- Apptronik: Apollo 2
- Apptronik: Apptronik Partners with Google DeepMind Robotics
- Google DeepMind: Gemini Robotics
- arXiv: Gemini Robotics 1.5
- Business Insider: This $5.5 billion robotics startup built a school for humanoids
错误速查卡:机器人语音 × 任务闭环常见问题
| 症状 | 根因 | 定位方法 | 修复方案 |
|---|---|---|---|
| 用户说"停一下",机器人继续走完当前动作 | 打断事件没和 task_id、action_type 绑定 |
看任务日志里是否有 interrupted=true 和 interrupt_at_step 字段 |
在语音客户端把打断事件实时写入任务日志,并立即触发安全停机/减速策略 |
| 机器人抓箱子反复失败,但不知道是哪里出问题 | 失败原因没有分类字段,只有字符串日志 | 在动作执行模块添加结构化失败码 | 引入 failure_reason enum:asr_error / plan_error / grasp_slip / object_lost / collision / vision_error / user_cancel 等 |
| ASR 文本被存进训练集,但缺原始音频,无法二次核对 | 训练 schema 只存了 text,没有音频引用 | 查数据集 schema 是否含 raw_audio_path / sample_rate |
同时保存原始音频(采样率/通道统一),并和 ASR 文本、意图、置信度、机器人状态做强关联 |
| 任务失败后没通知人工接管 | 缺 handover_required 标志 |
看 action_plan 末位状态字段 | 在判定失败时把 handover_required=true 置位,并推送告警 |
| 双足/轮式两种 Apollo 数据无法共享训练 | 不同底盘字段没抽象化 | 查数据集 schema 是否含 robot_form 抽象 |
用统一的 task_state + robot_form 抽象层,把底盘差异(双足/轮式/外骨骼)抽出 |
| 用户一句"搬一下"机器人根本不知道搬啥 | LLM 槽位提取太软,没有 target_object 必填校验 |
在意图层日志里看 slot_missing 字段 |
关键槽位缺失时强制触发追问(“您想搬哪个?是前面那个大箱子吗?”),不允许直接执行 |
| 模型在仿真里表现很好,到真实场地掉点严重 | 训练数据里没有失败样本和人工接管记录 | 统计训练集 failure_sample_ratio 和 handover_event_ratio |
系统化采集失败集、抓滑、人工接管记录,提高高难度样本在训练集里的占比 |
| 用户突然说"先别动,我来"之后系统继续走 | 接管流程没和语音流打通 | 查是否触发 takeover_mode=true |
语音层一旦识别接管意图,立即冻结任务、下发 hold 指令,并切换成手动控制优先 |
作者:武子康的个人博客

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)