RGB to 3D Action Tracking: Hyrbik+mjlab(4)
之前的工作摄像头输入的是我的一小段视频,具有鲁棒性
https://blog.csdn.net/2302_77159195/article/details/161853676?spm=1001.2014.3001.5502
上一篇论文我们测试了hybrik处理是否能做到实时
https://blog.csdn.net/2302_77159195/article/details/162495406?spm=1001.2014.3001.5502
接下来的工作是:用手机录制不同人的动作,录制成多个视频,随机选择一个视频作为摄像头的输入,当前视频的最后一帧输入完成后,给摄像头输入下一个视频的第一帧,目的是在训练的时候增加鲁棒性(因为之前一小段摄像头输入之后,训练发现很容易过拟合)
之前的工作流程:
[步骤 1: 在 hybrik 环境下]
视频文件 ──> 运行 HybrIK 模型 ──> 提取 pred_xyz 数据 ──> 导出为 pk 文件
│
(跨环境文件传递)
│
▼
[步骤 2: 在 unitree-rl 环境下]
npz 动作参考包 <── 保存结果 <── 运行重定向脚本 <── 读取并计算模型几何
批量处理的工作流程:
[预处理阶段] 多个视频 -> HybrIK 批量处理 -> 多个独立的 .pk 文件 -> 批量重定向 -> 多个独立的 .npz 文件
│
(统一放入 motions_dir)
│
▼
[RL初始化阶段] 启动环境 -> MotionManager 扫描该目录 -> 随机加载其中一个 .npz 文件作为当前追踪目标
│
▼
[训练循环阶段] 每个 step 推进一帧 -> 触发“末帧判定” -> 随机挑选下一个 .npz 并重置/平滑过渡 -> 循环往复
1.准备录制好的视频 play_all.py查看所有视频
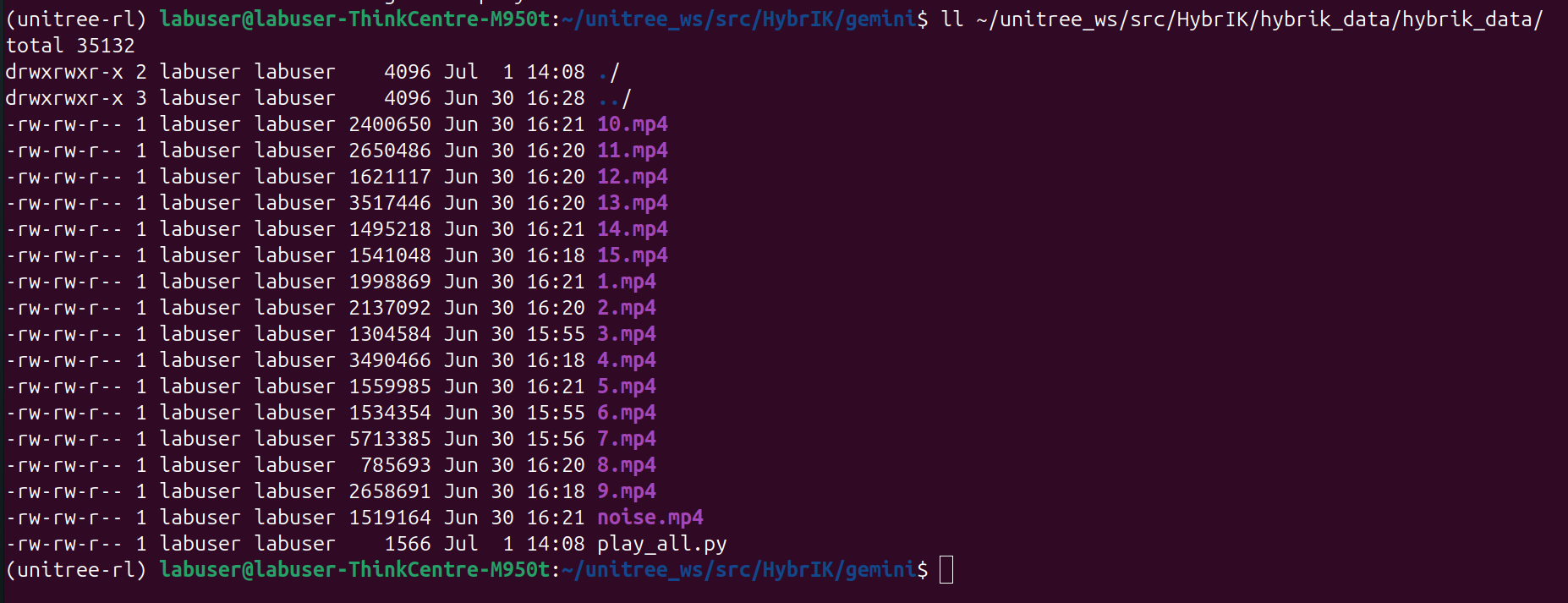
2.hybrik的批处理脚本 demo_video_bath,py
#!/usr/bin/env python3
"""Batch Video Processor for HybrIK (YOLOv8 + ResNet-34 Fast Injection Mode)."""
import argparse
import os
import pickle as pk
import time
import warnings
import cv2
import numpy as np
import torch
from easydict import EasyDict as edict
# 隐藏无关警告
warnings.filterwarnings("ignore")
os.environ["PYTORCH_MAGMA_WARNINGS"] = "0"
try:
from ultralytics import YOLO
except ImportError:
print("❌ Error: Please install ultralytics to use YOLOv8 (pip install ultralytics)")
exit(1)
from hybrik.models import builder
from hybrik.utils.config import update_config
from hybrik.utils.presets import SimpleTransform3DSMPLCam
def xyxy2xywh(bbox):
x1, y1, x2, y2 = bbox
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
return [cx, cy, w, h]
parser = argparse.ArgumentParser(description='HybrIK Batch Video Process Stream')
parser.add_argument('--gpu', help='gpu id', default=0, type=int)
parser.add_argument('--input-dir', help='Path to your video folder', default='hybrik_data/hybrik_data', type=str)
parser.add_argument('--out-dir', help='output root folder', default='camera_output_fast', type=str)
parser.add_argument('--save-img', default=False, dest='save_img', help='save 2d annotated images', action='store_true')
parser.add_argument('--yolo-model', default='yolov8n.pt', type=str)
opt = parser.parse_args()
if not os.path.exists(opt.input_dir):
print(f"❌ Error: Cannot find input folder: {opt.input_dir}")
exit(1)
# 自动扫描目录下所有的 MP4 视频
video_files = [f for f in os.listdir(opt.input_dir) if f.endswith('.mp4')]
if not video_files:
print(f"⚠️ Warning: No .mp4 files found in {opt.input_dir}")
exit(0)
print(f"📚 找到 {len(video_files)} 个视频目标,开始构建批量极速预处理流水线...")
# ================= 核心配置加载:ResNet-34 极速版 =================
cfg_file = 'configs/256x192_adam_lr1e-3-res34_smpl_3d_cam_2x_mix_w_pw3d.yaml'
CKPT = './pretrained_models/hybrik_res34.pth'
cfg = update_config(cfg_file)
bbox_3d_shape = getattr(cfg.MODEL, 'BBOX_3D_SHAPE', (2000, 2000, 2000))
bbox_3d_shape = [item * 1e-3 for item in bbox_3d_shape]
dummpy_set = edict({
'joint_pairs_17': None,
'joint_pairs_24': None,
'joint_pairs_29': None,
'bbox_3d_shape': bbox_3d_shape
})
res_keys = [
'pred_uvd', 'pred_xyz_17', 'pred_xyz_29', 'pred_xyz_24_struct', 'pred_scores',
'pred_camera', 'pred_betas', 'pred_thetas', 'pred_phi', 'pred_cam_root',
'transl', 'transl_camsys', 'bbox', 'height', 'width', 'img_path', 'timestamp'
]
transformation = SimpleTransform3DSMPLCam(
dummpy_set,
scale_factor=cfg.DATASET.SCALE_FACTOR,
color_factor=cfg.DATASET.COLOR_FACTOR,
occlusion=cfg.DATASET.OCCLUSION,
input_size=cfg.MODEL.IMAGE_SIZE,
output_size=cfg.MODEL.HEATMAP_SIZE,
depth_dim=cfg.MODEL.EXTRA.DEPTH_DIM,
bbox_3d_shape=bbox_3d_shape,
rot=cfg.DATASET.ROT_FACTOR,
sigma=cfg.MODEL.EXTRA.SIGMA,
train=False,
add_dpg=False,
loss_type=cfg.LOSS['TYPE'])
device = torch.device(f'cuda:{opt.gpu}' if torch.cuda.is_available() and opt.gpu >= 0 else 'cpu')
print(f"Using device: {device}")
# 一次性初始化全局常驻模型,避免循环内重复创建
print(f"📦 Loading YOLOv8 Detector ({opt.yolo_model})...")
det_model = YOLO(opt.yolo_model)
det_model.to(device)
print(f'Loading HybrIK ResNet-34 model from {CKPT}...')
hybrik_model = builder.build_sppe(cfg.MODEL)
if hasattr(hybrik_model, "smpl") and hasattr(hybrik_model.smpl, "shapedirs"):
if hybrik_model.smpl.shapedirs.shape[-1] == 300:
hybrik_model.smpl.shapedirs = hybrik_model.smpl.shapedirs[:, :, :10]
save_dict = torch.load(CKPT, map_location='cpu')
hybrik_model.load_state_dict(save_dict['model'] if type(save_dict) == dict else save_dict, strict=False)
hybrik_model.to(device)
hybrik_model.eval()
if not os.path.exists(opt.out_dir):
os.makedirs(opt.out_dir)
# ================= 批量主循环 =================
for idx, v_name in enumerate(sorted(video_files)):
video_path = os.path.join(opt.input_dir, v_name)
base_name = os.path.splitext(v_name)[0]
pk_filename = f"{base_name}.pk"
pk_output_path = os.path.join(opt.out_dir, pk_filename)
print(f"\n🚀 [{idx+1}/{len(video_files)}] 正在处理: {v_name} -> 目标保存点: {pk_output_path}")
cap_sim = cv2.VideoCapture(video_path)
frame_width = int(cap_sim.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap_sim.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap_sim.get(cv2.CAP_PROP_FPS)
if fps <= 0: fps = 30
# 局部重置每个视频的结果数据库
res_db = {k: [] for k in res_keys}
frame_count = 0
start_time = time.time()
# 如果开启了图像保存,为各个视频创建子目录
video_img_dir = os.path.join(opt.out_dir, f'res_2d_{base_name}')
if opt.save_img and not os.path.exists(video_img_dir):
os.makedirs(video_img_dir)
while True:
ret, frame = cap_sim.read()
if not ret:
break
frame_count += 1
current_timestamp = time.time()
# YOLOv8 跟踪
det_results = det_model.track(frame, classes=0, persist=True, verbose=False, device=device)
if len(det_results) == 0 or det_results[0].boxes is None or len(det_results[0].boxes.xyxy) == 0:
continue
tight_bbox = det_results[0].boxes.xyxy[0].cpu().numpy()
with torch.no_grad():
input_image_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
pose_input, bbox, img_center = transformation.test_transform(input_image_rgb, tight_bbox)
pose_input = pose_input.to(device)[None, :, :, :]
pose_output = hybrik_model(
pose_input,
flip_test=False,
bboxes=torch.from_numpy(np.array(bbox)).to(device).unsqueeze(0).float(),
img_center=torch.from_numpy(img_center).to(device).unsqueeze(0).float()
)
def safe_get(obj, *names):
for name in names:
if hasattr(obj, name):
val = getattr(obj, name)
if torch.is_tensor(val):
return val.cpu().detach().numpy().squeeze()
return val
return None
pred_uvd = safe_get(pose_output, 'pred_uvd_jts')
if pred_uvd is not None: pred_uvd = pred_uvd.reshape(-1, 3)
# 配合图像调试保存
if opt.save_img:
display_image = frame.copy()
if pred_uvd is not None:
bbox_xywh = xyxy2xywh(bbox)
pts = pred_uvd[:, :2] * bbox_xywh[2]
pts[:, 0] += bbox_xywh[0]
pts[:, 1] += bbox_xywh[1]
for i in range(min(pts.shape[0], 29)):
x, y = int(pts[i, 0]), int(pts[i, 1])
if 0 <= x < frame_width and 0 <= y < frame_height:
cv2.circle(display_image, (x, y), radius=3, color=(0, 255, 0), thickness=-1)
cv2.imwrite(os.path.join(video_img_dir, f'image-{frame_count:06d}.jpg'), display_image)
# 结构化填充
res_db['pred_uvd'].append(pred_uvd)
res_db['pred_xyz_17'].append(safe_get(pose_output, 'pred_xyz_jts_17'))
res_db['pred_xyz_29'].append(safe_get(pose_output, 'pred_xyz_jts_29'))
res_db['pred_xyz_24_struct'].append(safe_get(pose_output, 'pred_xyz_jts_24_struct', 'pred_xyz_jts_24'))
res_db['pred_scores'].append(safe_get(pose_output, 'maxvals'))
cam_val = safe_get(pose_output, 'pred_camera', 'camera')
res_db['pred_camera'].append(cam_val if cam_val is not None else np.zeros(3))
res_db['pred_betas'].append(safe_get(pose_output, 'pred_shape', 'pred_betas'))
res_db['pred_thetas'].append(safe_get(pose_output, 'pred_theta_mats', 'pred_thetas'))
res_db['pred_phi'].append(safe_get(pose_output, 'pred_phi'))
res_db['pred_cam_root'].append(safe_get(pose_output, 'cam_root'))
res_db['transl'].append(safe_get(pose_output, 'transl'))
res_db['transl_camsys'].append(safe_get(pose_output, 'transl_camsys', 'trans_cam'))
res_db['bbox'].append(np.array(bbox))
res_db['height'].append(frame_height)
res_db['width'].append(frame_width)
res_db['img_path'].append(f"frame_{frame_count:06d}.jpg")
res_db['timestamp'].append(current_timestamp)
if frame_count % 50 == 0:
fps_running = frame_count / (time.time() - start_time)
print(f" ⚡ 已提取 {frame_count} 帧... 速度: {fps_running:.2f} FPS")
cap_sim.release()
# 持久化当前视频的独立 pk 结果
if len(res_db['pred_uvd']) > 0:
final_res = {}
for k, v in res_db.items():
clean_v = [x for x in v if x is not None]
if clean_v:
try:
final_res[k] = np.stack(clean_v) if isinstance(clean_v[0], np.ndarray) else np.array(clean_v)
except:
final_res[k] = clean_v
else:
final_res[k] = np.array(v) if v else []
with open(pk_output_path, 'wb') as f:
pk.dump(final_res, f)
print(f"💾 [成功] 已导出核心骨骼文件: {pk_output_path}")
print("\n🎉 所有动作视频全部预处理完毕!完美支持后续动态真随机训练。")
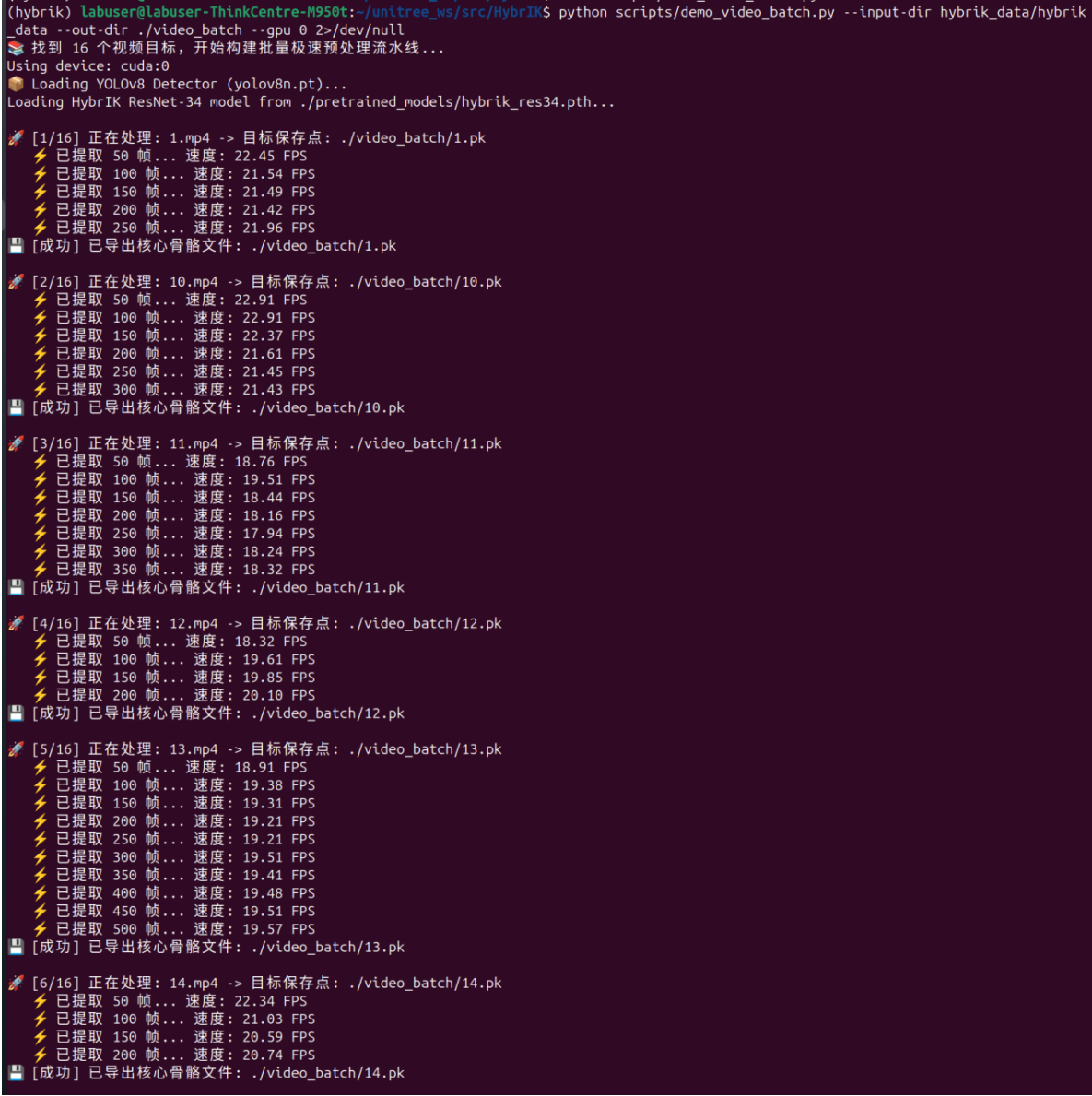
处理每一个视频,生成对应命名的pk文件
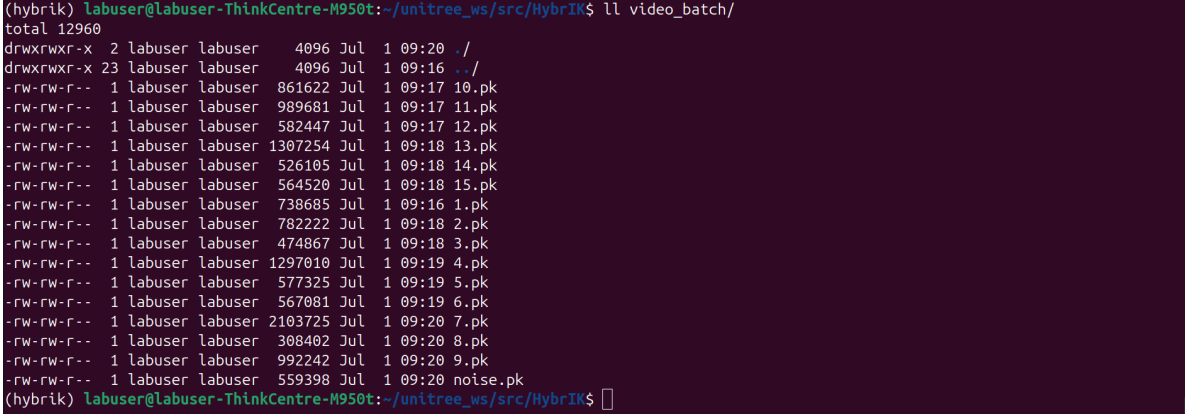
3.重定向的批处理文件 motion_retargeting_batch.py
#!/usr/bin/env python3
import os
import pickle
import numpy as np
import mujoco
from scipy.optimize import minimize
from scipy.spatial.transform import Rotation as R
from scipy.ndimage import uniform_filter1d
# ==================== 路径配置 ====================
XML_PATH = '/home/labuser/unitree_ws/src/unitree_rl_mjlab/mjlab/asset_zoo/robots/unitree_g1/xmls/g1.xml'
PKL_DIR = '/home/labuser/unitree_ws/src/HybrIK/video_batch' # 16个视频.pk所在的文件夹
OUTPUT_DIR = '/home/labuser/unitree_ws/src/unitree_rl_mjlab/data/reference_motions/g1_library' # 最终生成的动作弹药库
POSITION_SCALE = 0.001
# 迭代优化的双臂关节
RIGHT_ARM_JOINTS = [
"right_shoulder_pitch_joint", "right_shoulder_roll_joint", "right_shoulder_yaw_joint", "right_elbow_joint"
]
LEFT_ARM_JOINTS = [
"left_shoulder_pitch_joint", "left_shoulder_roll_joint", "left_shoulder_yaw_joint", "left_elbow_joint"
]
# 🦾 修正大臂倾斜走向的默认基准站姿(保留你调试好的黄金角度参数)
G1_STANDING_ANGLES = {
"left_hip_pitch_joint": -0.15, "left_hip_roll_joint": 0.0, "left_hip_yaw_joint": 0.0,
"left_knee_joint": 0.3, "left_ankle_pitch_joint": 0.0, "left_ankle_roll_joint": 0.0,
"right_hip_pitch_joint": -0.15, "right_hip_roll_joint": 0.0, "right_hip_yaw_joint": 0.0,
"right_knee_joint": 0.3, "right_ankle_pitch_joint": 0.0, "right_ankle_roll_joint": 0.0,
"waist_yaw_joint": 0.0,
"waist_roll_joint": 0.0,
"waist_pitch_joint": 0.0,
"left_shoulder_pitch_joint": 0.3,
"left_shoulder_roll_joint": 1.5,
"left_shoulder_yaw_joint": 0.0,
"left_elbow_joint": 0.6,
"right_shoulder_pitch_joint": 0.3,
"right_shoulder_roll_joint": -1.5,
"right_shoulder_yaw_joint": 0.0,
"right_elbow_joint": 0.6
}
def to_mj_coord(v):
return np.array([-v[2], v[0], -v[1]]) * POSITION_SCALE
def solve_arm_ik(model, data, target_wrist_pos, target_elbow_pos, side, default_arm_qpos, prev_arm_qpos):
joint_names = RIGHT_ARM_JOINTS if side == 'right' else LEFT_ARM_JOINTS
qpos_indices = []
bounds = []
for name in joint_names:
jid = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_JOINT, name)
if jid != -1:
qpos_indices.append(model.jnt_qposadr[jid])
raw_range = model.jnt_range[jid].copy()
if side == 'right':
if name == "right_shoulder_pitch_joint":
raw_range[0] = max(raw_range[0], -1.0)
raw_range[1] = min(raw_range[1], 1.5)
elif name == "right_shoulder_roll_joint":
raw_range[0] = max(raw_range[0], -2.0)
raw_range[1] = min(raw_range[1], -0.05)
elif name == "right_shoulder_yaw_joint":
raw_range[0] = max(raw_range[0], -1.5)
raw_range[1] = min(raw_range[1], 1.5)
bounds.append(raw_range)
if len(qpos_indices) < 4:
return prev_arm_qpos
site_id = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_SITE, f"{side}_palm")
if site_id == -1:
site_id = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_BODY, f"{side}_elbow_link")
elbow_jid = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_JOINT, f"{side}_elbow_joint")
elbow_bid = model.jnt_bodyid[elbow_jid]
torso_bid = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_BODY, "torso")
l_thigh_bid = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_BODY, "left_hip_pitch_link")
r_thigh_bid = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_BODY, "right_hip_pitch_link")
opp_side = 'left' if side == 'right' else 'right'
opp_site_id = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_SITE, f"{opp_side}_palm")
# 🛠️ 继承特性:使用默认姿态作为初始搜索起点,消除时序滞后
init_q = default_arm_qpos.copy()
def loss_func(q_arm):
data.qpos[qpos_indices] = q_arm
mujoco.mj_forward(model, data)
pos_loss = 2500.0 * np.sum((data.site_xpos[site_id] - target_wrist_pos) ** 2)
elbow_loss = 800.0 * np.sum((data.xpos[elbow_bid] - target_elbow_pos) ** 2)
if side == 'right':
reg_loss = 5.0 * np.sum((q_arm - default_arm_qpos) ** 2)
temporal_loss = 1.5 * np.sum((q_arm - prev_arm_qpos) ** 2)
else:
reg_loss = 4.0 * np.sum((q_arm - default_arm_qpos) ** 2)
temporal_loss = 1.5 * np.sum((q_arm - prev_arm_qpos) ** 2)
elbow_angle = q_arm[3]
elbow_penalty = 10000.0 * (elbow_angle - 0.0)**2 if elbow_angle < 0.0 else 0.0
collision_loss = 0.0
current_palm_pos = data.site_xpos[site_id]
if l_thigh_bid != -1:
l_thigh_dist = np.linalg.norm(current_palm_pos - data.xpos[l_thigh_bid])
if l_thigh_dist < 0.16: collision_loss += 8000.0 * (0.16 - l_thigh_dist) ** 2
if r_thigh_bid != -1:
r_thigh_dist = np.linalg.norm(current_palm_pos - data.xpos[r_thigh_bid])
if r_thigh_dist < 0.16: collision_loss += 8000.0 * (0.16 - r_thigh_dist) ** 2
if torso_bid != -1:
torso_dist = np.linalg.norm(current_palm_pos - data.xpos[torso_bid])
if torso_dist < 0.18: collision_loss += 5000.0 * (0.18 - torso_dist) ** 2
if opp_site_id != -1:
hand_dist = np.linalg.norm(current_palm_pos - data.site_xpos[opp_site_id])
if hand_dist < 0.16: collision_loss += 4000.0 * (0.16 - hand_dist) ** 2
return pos_loss + elbow_loss + reg_loss + temporal_loss + elbow_penalty + collision_loss
res = minimize(loss_func, init_q, method='SLSQP', bounds=bounds, options={'maxiter': 150, 'ftol': 1e-5})
return res.x
def main():
if not os.path.exists(OUTPUT_DIR):
os.makedirs(OUTPUT_DIR)
model = mujoco.MjModel.from_xml_path(XML_PATH)
data = mujoco.MjData(model)
actuated_qpos_indices = []
for j_id in range(model.njnt):
if model.jnt_type[j_id] != 0:
actuated_qpos_indices.append(model.jnt_qposadr[j_id])
mujoco.mj_resetData(model, data)
for j_name, angle in G1_STANDING_ANGLES.items():
j_id = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_JOINT, j_name)
if j_id != -1:
data.qpos[model.jnt_qposadr[j_id]] = angle
mujoco.mj_forward(model, data)
default_qpos = data.qpos.copy()
arm_configs = {}
for side in ['right', 'left']:
s_bid = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_BODY, f"{side}_shoulder_pitch_link")
e_jid = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_JOINT, f"{side}_elbow_joint")
e_bid = model.jnt_bodyid[e_jid]
p_sid = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_SITE, f"{side}_palm")
joint_names = RIGHT_ARM_JOINTS if side == 'right' else LEFT_ARM_JOINTS
arm_idx = []
for n in joint_names:
jid = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_JOINT, n)
if jid != -1: arm_idx.append(model.jnt_qposadr[jid])
arm_qpos = default_qpos[arm_idx]
upper_len = np.linalg.norm(data.xpos[e_bid] - data.xpos[s_bid])
lower_len = np.linalg.norm(data.site_xpos[p_sid] - data.xpos[e_bid]) if p_sid != -1 else 0.25
arm_configs[side] = {
'upper_len': upper_len, 'lower_len': lower_len,
'max_reach': (upper_len + lower_len) * 0.95, 's_bid': s_bid,
'default_qpos': arm_qpos, 'qpos_indices': arm_idx
}
# 扫描所有的 .pk 文件
pk_files = [f for f in os.listdir(PKL_DIR) if f.endswith('.pk')]
print(f"🎬 发现 {len(pk_files)} 个骨骼数据包,开始进行批量重定向安全解算...")
for f_idx, pk_name in enumerate(sorted(pk_files)):
pk_path = os.path.join(PKL_DIR, pk_name)
npz_name = os.path.splitext(pk_name)[0] + ".npz"
output_path = os.path.join(OUTPUT_DIR, npz_name)
print(f"🔄 [{f_idx+1}/{len(pk_files)}] 正在解算: {pk_name} -> 导出目标: {output_path}")
with open(pk_path, 'rb') as f:
hybrik_data = pickle.load(f)
pred_xyz = np.array(hybrik_data['pred_xyz_24_struct']).reshape(-1, 24, 3)
num_frames = len(pred_xyz)
robot_qpos_trajectory = np.zeros((num_frames, model.nq))
prev_arm_qpos_dict = {
'right': arm_configs['right']['default_qpos'].copy(),
'left': arm_configs['left']['default_qpos'].copy()
}
first_valid_frame = 0
for i in range(num_frames):
if np.linalg.norm(pred_xyz[i]) > 1e-4:
first_valid_frame = i
break
r_sh, l_sh = pred_xyz[first_valid_frame, 17], pred_xyz[first_valid_frame, 16]
shoulder_vec = l_sh - r_sh
yaw_angle = np.arctan2(shoulder_vec[2], shoulder_vec[0])
rot_fix = R.from_euler('y', -yaw_angle)
for frame_idx in range(num_frames):
data.qpos[:] = default_qpos[:]
data.qpos[0:3] = np.array([0.0, 0.0, 0.74])
data.qpos[3:7] = np.array([1.0, 0.0, 0.0, 0.0])
human_frame = pred_xyz[frame_idx].copy()
if np.linalg.norm(human_frame) < 1e-4:
robot_qpos_trajectory[frame_idx] = default_qpos.copy()
continue
for j in range(24):
human_frame[j] = rot_fix.apply(human_frame[j])
for side in ['right', 'left']:
s_idx, e_idx, w_idx = ([17, 19, 21] if side == 'right' else [16, 18, 20])
up_vec = to_mj_coord(human_frame[e_idx] - human_frame[s_idx])
lo_vec = to_mj_coord(human_frame[w_idx] - human_frame[e_idx])
up_vec_norm = up_vec / (np.linalg.norm(up_vec) + 1e-5)
lo_vec_norm = lo_vec / (np.linalg.norm(lo_vec) + 1e-5)
shoulder_pos = data.xpos[arm_configs[side]['s_bid']]
target_elbow = shoulder_pos + up_vec_norm * arm_configs[side]['upper_len']
target_wrist = target_elbow + lo_vec_norm * arm_configs[side]['lower_len']
optimized_q = solve_arm_ik(
model, data, target_wrist, target_elbow, side,
arm_configs[side]['default_qpos'], prev_arm_qpos_dict[side]
)
prev_arm_qpos_dict[side] = optimized_q.copy()
data.qpos[arm_configs[side]['qpos_indices']] = optimized_q
for w_name in ["waist_yaw_joint", "waist_roll_joint", "waist_pitch_joint"]:
w_jid = mujoco.mj_name2id(model, mujoco.mjtObj.mjOBJ_JOINT, w_name)
if w_jid != -1: data.qpos[model.jnt_qposadr[w_jid]] = 0.0
mujoco.mj_forward(model, data)
robot_qpos_trajectory[frame_idx] = data.qpos.copy()
# 滤波器平滑驱动关节角
smoothed_full_qpos = uniform_filter1d(robot_qpos_trajectory, size=3, axis=0, mode='nearest')
rl_joint_pos_save = smoothed_full_qpos[:, actuated_qpos_indices]
# 批量计算每一帧的世界坐标下刚体 Link 状态
n_bodies = model.nbody
body_pos_w_save = np.zeros((num_frames, n_bodies, 3))
body_quat_w_save = np.zeros((num_frames, n_bodies, 4))
for f_idx in range(num_frames):
data.qpos[:] = smoothed_full_qpos[f_idx]
mujoco.mj_forward(model, data)
for b_id in range(n_bodies):
body_pos_w_save[f_idx, b_id, :] = data.xpos[b_id].copy()
body_quat_w_save[f_idx, b_id, :] = data.xquat[b_id].copy()
np.savez(output_path,
joint_pos=rl_joint_pos_save,
joint_vel=np.zeros_like(rl_joint_pos_save),
body_pos_w=body_pos_w_save,
body_quat_w=body_quat_w_save,
body_lin_vel_w=np.zeros_like(body_pos_w_save),
body_ang_vel_w=np.zeros_like(body_pos_w_save))
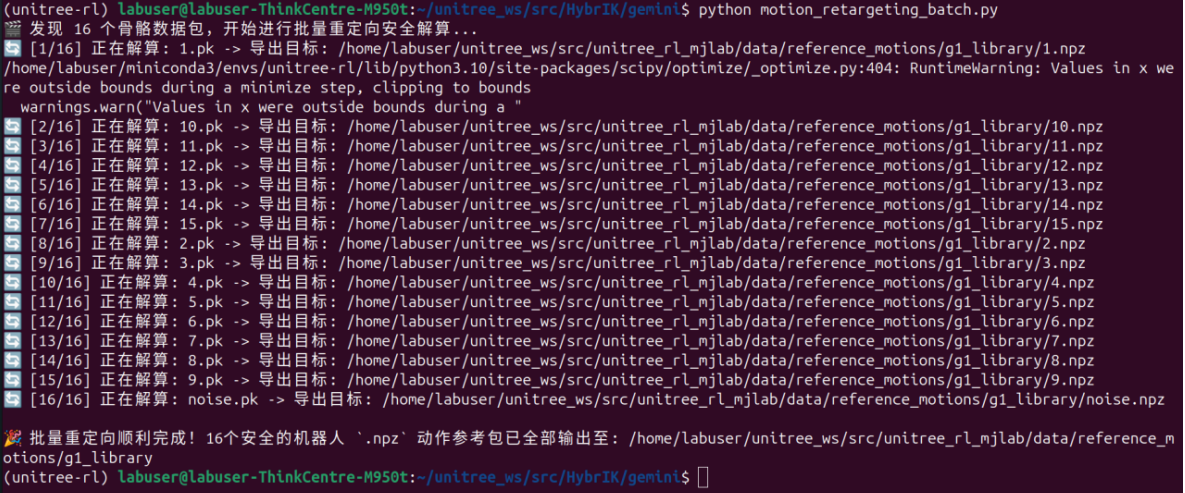
print(f"\n🎉 批量重定向顺利完成!16个安全的机器人 `.npz` 动作参考包已全部输出至: {OUTPUT_DIR}")
if __name__ == '__main__':
main()
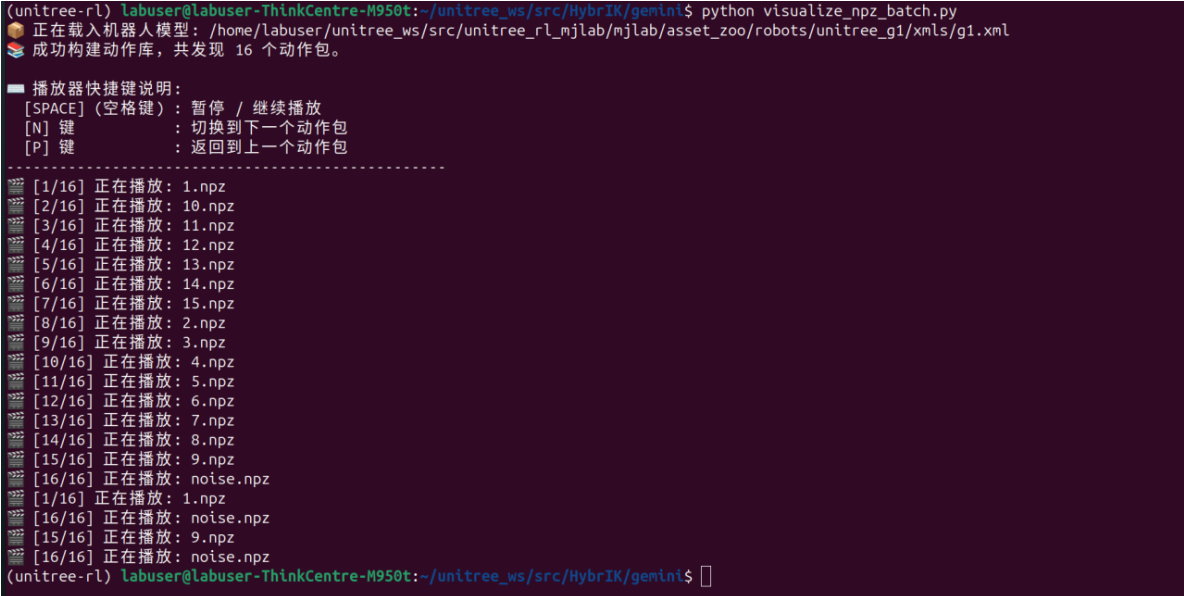
4.重定向结果的可视化查看文件 visualize_npz_batch,py
#!/usr/bin/env python3
import os
import time
import numpy as np
import mujoco
import mujoco.viewer
# ==================== 路径配置 ====================
XML_PATH = '/home/labuser/unitree_ws/src/unitree_rl_mjlab/mjlab/asset_zoo/robots/unitree_g1/xmls/g1.xml'
NPZ_DIR = '/home/labuser/unitree_ws/src/unitree_rl_mjlab/data/reference_motions/g1_library'
# 全局控制变量
current_motion_idx = 0
switch_flag = False
direction = 1 # 1: 下一个, -1: 上一个
def main():
global current_motion_idx, switch_flag, direction
print(f"📦 正在载入机器人模型: {XML_PATH}")
model = mujoco.MjModel.from_xml_path(XML_PATH)
data = mujoco.MjData(model)
# 扫描目录下所有的动作包
if not os.path.exists(NPZ_DIR):
print(f"❌ 错误: 动作库目录不存在 -> {NPZ_DIR}")
return
npz_files = sorted([f for f in os.listdir(NPZ_DIR) if f.endswith('.npz')])
if not npz_files:
print(f"❌ 错误: 没在目录里找到任何 .npz 文件!")
return
print(f"📚 成功构建动作库,共发现 {len(npz_files)} 个动作包。")
# 🛠️ 动态获取当前 XML 中实际存在的所有动关节索引
actuated_qpos_indices = []
for j_id in range(model.njnt):
if model.jnt_type[j_id] != 0: # 排除自由根节点
actuated_qpos_indices.append(model.jnt_qposadr[j_id])
num_xml_joints = len(actuated_qpos_indices)
print("\n⌨️ 播放器快捷键说明:")
print(" [SPACE] (空格键) : 暂停 / 继续播放")
print(" [N] 键 : 切换到下一个动作包")
print(" [P] 键 : 返回到上一个动作包")
print("-" * 50)
# 自定义键盘事件回调
def key_callback(keycode):
global current_motion_idx, switch_flag, direction
# MjViewer 中常数或者字符对应的 ASCII 码
if keycode == 32: # Space 键底层有默认暂停,这里主要保障同步
pass
elif keycode == ord('N') or keycode == ord('n'):
direction = 1
switch_flag = True
elif keycode == ord('P') or keycode == ord('p'):
direction = -1
switch_flag = True
# 启动被动渲染窗口
with mujoco.viewer.launch_passive(model, data, key_callback=key_callback) as viewer:
while viewer.is_running():
# 载入或切换当前动作包
npz_name = npz_files[current_motion_idx]
npz_path = os.path.join(NPZ_DIR, npz_name)
print(f"🎬 [{current_motion_idx + 1}/{len(npz_files)}] 正在播放: {npz_name}")
motion_data = np.load(npz_path)
joint_pos_traj = motion_data['joint_pos']
body_pos_w_traj = motion_data['body_pos_w']
num_frames = len(joint_pos_traj)
frame_idx = 0
switch_flag = False # 重置切换标志
# 单个动作包循环渲染流
while viewer.is_running() and not switch_flag:
step_start = time.time()
# 兼容性裁剪
joint_pos = joint_pos_traj[frame_idx]
if len(joint_pos) > num_xml_joints:
joint_pos = joint_pos[:num_xml_joints]
root_pos = body_pos_w_traj[frame_idx, 1] if body_pos_w_traj.shape[1] > 1 else np.array([0, 0, 0.75])
# 状态重置与注入
mujoco.mj_resetData(model, data)
data.qpos[0:3] = root_pos
data.qpos[3:7] = np.array([1.0, 0.0, 0.0, 0.0])
data.qpos[actuated_qpos_indices] = joint_pos
mujoco.mj_forward(model, data)
viewer.sync()
# 步进帧(支持 MuJoCo 默认自带的空格暂停检测)
frame_idx = (frame_idx + 1) % num_frames
# 控制 50FPS 稳定播放 (0.02s)
time_until_next_step = 0.02 - (time.time() - step_start)
if time_until_next_step > 0:
time.sleep(time_until_next_step)
# 处理切歌逻辑
if switch_flag:
current_motion_idx = (current_motion_idx + direction) % len(npz_files)
if __name__ == '__main__':
main()
5.更改unitree_rl_mjalb的配置文件
更改npz文件的使用逻辑,从原本的只使用一个文件更改为在文件夹中不断随机抽取一个
(1)mjlab/tasks/tracking/mdpcommands,py
from __future__ import annotations
import copy
import math
import os
from dataclasses import dataclass, field
from glob import glob
from typing import TYPE_CHECKING, Literal
import mujoco
import numpy as np
import torch
from mjlab.managers import CommandTerm, CommandTermCfg
from mjlab.utils.lab_api.math import (
matrix_from_quat,
quat_apply,
quat_error_magnitude,
quat_from_euler_xyz,
quat_inv,
quat_mul,
sample_uniform,
yaw_quat,
)
from mjlab.viewer.debug_visualizer import DebugVisualizer
if TYPE_CHECKING:
from mjlab.entity import Entity
from mjlab.envs import ManagerBasedRlEnv
_DESIRED_FRAME_COLORS = ((1.0, 0.5, 0.5), (0.5, 1.0, 0.5), (0.5, 0.5, 1.0))
class MotionLoader:
def __init__(
self, motion_file: str, body_indexes: torch.Tensor, device: str = "cpu"
) -> None:
# 1. 自动兼容:支持传入单个文件路径或包含多个 npz 的目录路径
if os.path.isdir(motion_file):
self.files = sorted(glob(os.path.join(motion_file, "*.npz")))
if not self.files:
raise ValueError(f"No .npz files found in directory: {motion_file}")
else:
self.files = [motion_file]
self.device = device
self._body_indexes = body_indexes
# 2. 预先将所有动作序列读入内存列表中,防止在 Reset 时频繁发生磁盘 I/O 阻塞
self.motions_data = []
for f in self.files:
data = np.load(f)
m = {
"joint_pos": torch.tensor(data["joint_pos"], dtype=torch.float32, device=device),
"joint_vel": torch.tensor(data["joint_vel"], dtype=torch.float32, device=device),
"body_pos_w": torch.tensor(data["body_pos_w"], dtype=torch.float32, device=device),
"body_quat_w": torch.tensor(data["body_quat_w"], dtype=torch.float32, device=device),
"body_lin_vel_w": torch.tensor(data["body_lin_vel_w"], dtype=torch.float32, device=device),
"body_ang_vel_w": torch.tensor(data["body_ang_vel_w"], dtype=torch.float32, device=device),
}
m["time_step_total"] = m["joint_pos"].shape[0]
self.motions_data.append(m)
# 默认暴露第一个动作索引(用于初始化时上层框架某些全局标量的兼容读取)
self.current_motion_idx = 0
@property
def joint_pos(self) -> torch.Tensor:
return self.motions_data[self.current_motion_idx]["joint_pos"]
@property
def joint_vel(self) -> torch.Tensor:
return self.motions_data[self.current_motion_idx]["joint_vel"]
@property
def body_pos_w(self) -> torch.Tensor:
return self.motions_data[self.current_motion_idx]["body_pos_w"][:, self._body_indexes]
@property
def body_quat_w(self) -> torch.Tensor:
return self.motions_data[self.current_motion_idx]["body_quat_w"][:, self._body_indexes]
@property
def body_lin_vel_w(self) -> torch.Tensor:
return self.motions_data[self.current_motion_idx]["body_lin_vel_w"][:, self._body_indexes]
@property
def body_ang_vel_w(self) -> torch.Tensor:
return self.motions_data[self.current_motion_idx]["body_ang_vel_w"][:, self._body_indexes]
@property
def time_step_total(self) -> int:
return self.motions_data[self.current_motion_idx]["time_step_total"]
class MotionCommand(CommandTerm):
cfg: MotionCommandCfg
_env: ManagerBasedRlEnv
def __init__(self, cfg: MotionCommandCfg, env: ManagerBasedRlEnv):
super().__init__(cfg, env)
self.robot: Entity = env.scene[cfg.entity_name]
self.robot_anchor_body_index = self.robot.body_names.index(
self.cfg.anchor_body_name
)
self.motion_anchor_body_index = self.cfg.body_names.index(self.cfg.anchor_body_name)
self.body_indexes = torch.tensor(
self.robot.find_bodies(self.cfg.body_names, preserve_order=True)[0],
dtype=torch.long,
device=self.device,
)
self.motion = MotionLoader(
self.cfg.motion_file, self.body_indexes, device=self.device
)
self.time_steps = torch.zeros(self.num_envs, dtype=torch.long, device=self.device)
self.body_pos_relative_w = torch.zeros(
self.num_envs, len(cfg.body_names), 3, device=self.device
)
self.body_quat_relative_w = torch.zeros(
self.num_envs, len(cfg.body_names), 4, device=self.device
)
self.body_quat_relative_w[:, :, 0] = 1.0
# 3. 动态环境级别动作跟踪状态追踪
self.env_motion_ids = torch.zeros(self.num_envs, dtype=torch.long, device=self.device)
self.env_motion_lengths = torch.tensor(
[self.motion.motions_data[0]["time_step_total"]] * self.num_envs,
dtype=torch.long, device=self.device
)
self.bin_count = int(self.motion.time_step_total // (1 / env.step_dt)) + 1
self.bin_failed_count = torch.zeros(
self.bin_count, dtype=torch.float, device=self.device
)
self._current_bin_failed = torch.zeros(
self.bin_count, dtype=torch.float, device=self.device
)
self.kernel = torch.tensor(
[self.cfg.adaptive_lambda**i for i in range(self.cfg.adaptive_kernel_size)],
device=self.device,
)
self.kernel = self.kernel / self.kernel.sum()
self.metrics["error_anchor_pos"] = torch.zeros(self.num_envs, device=self.device)
self.metrics["error_anchor_rot"] = torch.zeros(self.num_envs, device=self.device)
self.metrics["error_anchor_lin_vel"] = torch.zeros(
self.num_envs, device=self.device
)
self.metrics["error_anchor_ang_vel"] = torch.zeros(
self.num_envs, device=self.device
)
self.metrics["error_body_pos"] = torch.zeros(self.num_envs, device=self.device)
self.metrics["error_body_rot"] = torch.zeros(self.num_envs, device=self.device)
self.metrics["error_joint_pos"] = torch.zeros(self.num_envs, device=self.device)
self.metrics["error_joint_vel"] = torch.zeros(self.num_envs, device=self.device)
self.metrics["sampling_entropy"] = torch.zeros(self.num_envs, device=self.device)
self.metrics["sampling_top1_prob"] = torch.zeros(self.num_envs, device=self.device)
self.metrics["sampling_top1_bin"] = torch.zeros(self.num_envs, device=self.device)
# Ghost model created lazily on first visualization
self._ghost_model: mujoco.MjModel | None = None
self._ghost_color = np.array(cfg.viz.ghost_color, dtype=np.float32)
@property
def command(self) -> torch.Tensor:
return torch.cat([self.joint_pos, self.joint_vel], dim=1)
# 4. 通过高级列表解析将当前每个环境对应的目标状态组装起来
@property
def joint_pos(self) -> torch.Tensor:
res = [self.motion.motions_data[m_id]["joint_pos"][t] for m_id, t in zip(self.env_motion_ids, self.time_steps)]
return torch.stack(res, dim=0)
@property
def joint_vel(self) -> torch.Tensor:
res = [self.motion.motions_data[m_id]["joint_vel"][t] for m_id, t in zip(self.env_motion_ids, self.time_steps)]
return torch.stack(res, dim=0)
@property
def body_pos_w(self) -> torch.Tensor:
res = [self.motion.motions_data[m_id]["body_pos_w"][:, self.motion._body_indexes][t] for m_id, t in zip(self.env_motion_ids, self.time_steps)]
return torch.stack(res, dim=0) + self._env.scene.env_origins[:, None, :]
@property
def body_quat_w(self) -> torch.Tensor:
res = [self.motion.motions_data[m_id]["body_quat_w"][:, self.motion._body_indexes][t] for m_id, t in zip(self.env_motion_ids, self.time_steps)]
return torch.stack(res, dim=0)
@property
def body_lin_vel_w(self) -> torch.Tensor:
res = [self.motion.motions_data[m_id]["body_lin_vel_w"][:, self.motion._body_indexes][t] for m_id, t in zip(self.env_motion_ids, self.time_steps)]
return torch.stack(res, dim=0)
@property
def body_ang_vel_w(self) -> torch.Tensor:
res = [self.motion.motions_data[m_id]["body_ang_vel_w"][:, self.motion._body_indexes][t] for m_id, t in zip(self.env_motion_ids, self.time_steps)]
return torch.stack(res, dim=0)
@property
def anchor_pos_w(self) -> torch.Tensor:
res = [self.motion.motions_data[m_id]["body_pos_w"][:, self.motion._body_indexes][t, self.motion_anchor_body_index] for m_id, t in zip(self.env_motion_ids, self.time_steps)]
return torch.stack(res, dim=0) + self._env.scene.env_origins
@property
def anchor_quat_w(self) -> torch.Tensor:
res = [self.motion.motions_data[m_id]["body_quat_w"][:, self.motion._body_indexes][t, self.motion_anchor_body_index] for m_id, t in zip(self.env_motion_ids, self.time_steps)]
return torch.stack(res, dim=0)
@property
def anchor_lin_vel_w(self) -> torch.Tensor:
res = [self.motion.motions_data[m_id]["body_lin_vel_w"][:, self.motion._body_indexes][t, self.motion_anchor_body_index] for m_id, t in zip(self.env_motion_ids, self.time_steps)]
return torch.stack(res, dim=0)
@property
def anchor_ang_vel_w(self) -> torch.Tensor:
res = [self.motion.motions_data[m_id]["body_ang_vel_w"][:, self.motion._body_indexes][t, self.motion_anchor_body_index] for m_id, t in zip(self.env_motion_ids, self.time_steps)]
return torch.stack(res, dim=0)
@property
def robot_joint_pos(self) -> torch.Tensor:
return self.robot.data.joint_pos
@property
def robot_joint_vel(self) -> torch.Tensor:
return self.robot.data.joint_vel
@property
def robot_body_pos_w(self) -> torch.Tensor:
return self.robot.data.body_link_pos_w[:, self.body_indexes]
@property
def robot_body_quat_w(self) -> torch.Tensor:
return self.robot.data.body_link_quat_w[:, self.body_indexes]
@property
def robot_body_lin_vel_w(self) -> torch.Tensor:
return self.robot.data.body_link_lin_vel_w[:, self.body_indexes]
@property
def robot_body_ang_vel_w(self) -> torch.Tensor:
return self.robot.data.body_link_ang_vel_w[:, self.body_indexes]
@property
def robot_anchor_pos_w(self) -> torch.Tensor:
return self.robot.data.body_link_pos_w[:, self.robot_anchor_body_index]
@property
def robot_anchor_quat_w(self) -> torch.Tensor:
return self.robot.data.body_link_quat_w[:, self.robot_anchor_body_index]
@property
def robot_anchor_lin_vel_w(self) -> torch.Tensor:
return self.robot.data.body_link_lin_vel_w[:, self.robot_anchor_body_index]
@property
def robot_anchor_ang_vel_w(self) -> torch.Tensor:
return self.robot.data.body_link_ang_vel_w[:, self.robot_anchor_body_index]
def _update_metrics(self):
self.metrics["error_anchor_pos"] = torch.norm(
self.anchor_pos_w - self.robot_anchor_pos_w, dim=-1
)
self.metrics["error_anchor_rot"] = quat_error_magnitude(
self.anchor_quat_w, self.robot_anchor_quat_w
)
self.metrics["error_anchor_lin_vel"] = torch.norm(
self.anchor_lin_vel_w - self.robot_anchor_lin_vel_w, dim=-1
)
self.metrics["error_anchor_ang_vel"] = torch.norm(
self.anchor_ang_vel_w - self.robot_anchor_ang_vel_w, dim=-1
)
self.metrics["error_body_pos"] = torch.norm(
self.body_pos_relative_w - self.robot_body_pos_w, dim=-1
).mean(dim=-1)
self.metrics["error_body_rot"] = quat_error_magnitude(
self.body_quat_relative_w, self.robot_body_quat_w
).mean(dim=-1)
self.metrics["error_body_lin_vel"] = torch.norm(
self.body_lin_vel_w - self.robot_body_lin_vel_w, dim=-1
).mean(dim=-1)
self.metrics["error_body_ang_vel"] = torch.norm(
self.body_ang_vel_w - self.robot_body_ang_vel_w, dim=-1
).mean(dim=-1)
self.metrics["error_joint_pos"] = torch.norm(
self.joint_pos - self.robot_joint_pos, dim=-1
)
self.metrics["error_joint_vel"] = torch.norm(
self.joint_vel - self.robot_joint_vel, dim=-1
)
def _adaptive_sampling(self, env_ids: torch.Tensor):
# 针对多动作推荐使用统一的 uniform 采样。这里回退到多动作安全 uniform 采样
self._uniform_sampling(env_ids)
def _uniform_sampling(self, env_ids: torch.Tensor):
# 5. 重置时为选定的环境随机挑选动作
num_mot = len(self.motion.motions_data)
rand_m_ids = torch.randint(0, num_mot, (len(env_ids),), device=self.device)
self.env_motion_ids[env_ids] = rand_m_ids
for i, env_id in enumerate(env_ids):
self.env_motion_lengths[env_id] = self.motion.motions_data[rand_m_ids[i]]["time_step_total"]
# 根据挑中的动作各自长短范围生成对应的时间步
for env_id in env_ids:
max_t = self.env_motion_lengths[env_id].item()
self.time_steps[env_id] = torch.randint(0, max_t, (1,), device=self.device)
self.metrics["sampling_entropy"][:] = 1.0
self.metrics["sampling_top1_prob"][:] = 1.0 / self.bin_count
self.metrics["sampling_top1_bin"][:] = 0.5
def _resample_command(self, env_ids: torch.Tensor):
if self.cfg.sampling_mode == "start":
num_mot = len(self.motion.motions_data)
self.env_motion_ids[env_ids] = torch.randint(0, num_mot, (len(env_ids),), device=self.device)
for env_id in env_ids:
self.env_motion_lengths[env_id] = self.motion.motions_data[self.env_motion_ids[env_id]]["time_step_total"]
self.time_steps[env_ids] = 0
elif self.cfg.sampling_mode == "uniform":
self._uniform_sampling(env_ids)
else:
self._uniform_sampling(env_ids)
root_pos = self.body_pos_w[:, 0].clone()
root_ori = self.body_quat_w[:, 0].clone()
root_lin_vel = self.body_lin_vel_w[:, 0].clone()
root_ang_vel = self.body_ang_vel_w[:, 0].clone()
range_list = [
self.cfg.pose_range.get(key, (0.0, 0.0))
for key in ["x", "y", "z", "roll", "pitch", "yaw"]
]
ranges = torch.tensor(range_list, device=self.device)
rand_samples = sample_uniform(
ranges[:, 0], ranges[:, 1], (len(env_ids), 6), device=self.device
)
root_pos[env_ids] += rand_samples[:, 0:3]
orientations_delta = quat_from_euler_xyz(
rand_samples[:, 3], rand_samples[:, 4], rand_samples[:, 5]
)
root_ori[env_ids] = quat_mul(orientations_delta, root_ori[env_ids])
range_list = [
self.cfg.velocity_range.get(key, (0.0, 0.0))
for key in ["x", "y", "z", "roll", "pitch", "yaw"]
]
ranges = torch.tensor(range_list, device=self.device)
rand_samples = sample_uniform(
ranges[:, 0], ranges[:, 1], (len(env_ids), 6), device=self.device
)
root_lin_vel[env_ids] += rand_samples[:, :3]
root_ang_vel[env_ids] += rand_samples[:, 3:]
joint_pos = self.joint_pos.clone()
joint_vel = self.joint_vel.clone()
joint_pos += sample_uniform(
lower=self.cfg.joint_position_range[0],
upper=self.cfg.joint_position_range[1],
size=joint_pos.shape,
device=joint_pos.device, # type: ignore
)
soft_joint_pos_limits = self.robot.data.soft_joint_pos_limits[env_ids]
joint_pos[env_ids] = torch.clip(
joint_pos[env_ids], soft_joint_pos_limits[:, :, 0], soft_joint_pos_limits[:, :, 1]
)
self.robot.write_joint_state_to_sim(
joint_pos[env_ids], joint_vel[env_ids], env_ids=env_ids
)
root_state = torch.cat(
[
root_pos[env_ids],
root_ori[env_ids],
root_lin_vel[env_ids],
root_ang_vel[env_ids],
],
dim=-1,
)
self.robot.write_root_state_to_sim(root_state, env_ids=env_ids)
self.robot.clear_state(env_ids=env_ids)
def _update_command(self):
self.time_steps += 1
# 6. 改为对比每个环境独有的有效动作长度边界进行越界重置判定
env_ids = torch.where(self.time_steps >= self.env_motion_lengths)[0]
if env_ids.numel() > 0:
self._resample_command(env_ids)
anchor_pos_w_repeat = self.anchor_pos_w[:, None, :].repeat(
1, len(self.cfg.body_names), 1
)
anchor_quat_w_repeat = self.anchor_quat_w[:, None, :].repeat(
1, len(self.cfg.body_names), 1
)
robot_anchor_pos_w_repeat = self.robot_anchor_pos_w[:, None, :].repeat(
1, len(self.cfg.body_names), 1
)
robot_anchor_quat_w_repeat = self.robot_anchor_quat_w[:, None, :].repeat(
1, len(self.cfg.body_names), 1
)
delta_pos_w = robot_anchor_pos_w_repeat
delta_pos_w[..., 2] = anchor_pos_w_repeat[..., 2]
delta_ori_w = yaw_quat(
quat_mul(robot_anchor_quat_w_repeat, quat_inv(anchor_quat_w_repeat))
)
self.body_quat_relative_w = quat_mul(delta_ori_w, self.body_quat_w)
self.body_pos_relative_w = delta_pos_w + quat_apply(
delta_ori_w, self.body_pos_w - anchor_pos_w_repeat
)
if self.cfg.sampling_mode == "adaptive":
self.bin_failed_count = (
self.cfg.adaptive_alpha * self._current_bin_failed
+ (1 - self.cfg.adaptive_alpha) * self.bin_failed_count
)
self._current_bin_failed.zero_()
def _debug_vis_impl(self, visualizer: DebugVisualizer) -> None:
"""Draw ghost robot or frames based on visualization mode."""
if self.cfg.viz.mode == "ghost":
if self._ghost_model is None:
self._ghost_model = copy.deepcopy(self._env.sim.mj_model)
self._ghost_model.geom_rgba[:] = self._ghost_color
entity: Entity = self._env.scene[self.cfg.entity_name]
indexing = entity.indexing
free_joint_q_adr = indexing.free_joint_q_adr.cpu().numpy()
joint_q_adr = indexing.joint_q_adr.cpu().numpy()
qpos = np.zeros(self._env.sim.mj_model.nq)
qpos[free_joint_q_adr[0:3]] = self.body_pos_w[visualizer.env_idx, 0].cpu().numpy()
qpos[free_joint_q_adr[3:7]] = (
self.body_quat_w[visualizer.env_idx, 0].cpu().numpy()
)
qpos[joint_q_adr] = self.joint_pos[visualizer.env_idx].cpu().numpy()
visualizer.add_ghost_mesh(qpos, model=self._ghost_model)
elif self.cfg.viz.mode == "frames":
desired_body_pos = self.body_pos_w[visualizer.env_idx].cpu().numpy()
desired_body_quat = self.body_quat_w[visualizer.env_idx]
desired_body_rotm = matrix_from_quat(desired_body_quat).cpu().numpy()
current_body_pos = self.robot_body_pos_w[visualizer.env_idx].cpu().numpy()
current_body_quat = self.robot_body_quat_w[visualizer.env_idx]
current_body_rotm = matrix_from_quat(current_body_quat).cpu().numpy()
for i, body_name in enumerate(self.cfg.body_names):
visualizer.add_frame(
position=desired_body_pos[i],
rotation_matrix=desired_body_rotm[i],
scale=0.08,
label=f"desired_{body_name}",
axis_colors=_DESIRED_FRAME_COLORS,
)
visualizer.add_frame(
position=current_body_pos[i],
rotation_matrix=current_body_rotm[i],
scale=0.12,
label=f"current_{body_name}",
)
desired_anchor_pos = self.anchor_pos_w[visualizer.env_idx].cpu().numpy()
desired_anchor_quat = self.anchor_quat_w[visualizer.env_idx]
desired_rotation_matrix = matrix_from_quat(desired_anchor_quat).cpu().numpy()
visualizer.add_frame(
position=desired_anchor_pos,
rotation_matrix=desired_rotation_matrix,
scale=0.1,
label="desired_anchor",
axis_colors=_DESIRED_FRAME_COLORS,
)
current_anchor_pos = self.robot_anchor_pos_w[visualizer.env_idx].cpu().numpy()
current_anchor_quat = self.robot_anchor_quat_w[visualizer.env_idx]
current_rotation_matrix = matrix_from_quat(current_anchor_quat).cpu().numpy()
visualizer.add_frame(
position=current_anchor_pos,
rotation_matrix=current_rotation_matrix,
scale=0.15,
label="current_anchor",
)
@dataclass(kw_only=True)
class MotionCommandCfg(CommandTermCfg):
motion_file: str
anchor_body_name: str
body_names: tuple[str, ...]
entity_name: str
pose_range: dict[str, tuple[float, float]] = field(default_factory=dict)
velocity_range: dict[str, tuple[float, float]] = field(default_factory=dict)
joint_position_range: tuple[float, float] = (-0.52, 0.52)
adaptive_kernel_size: int = 1
adaptive_lambda: float = 0.8
adaptive_uniform_ratio: float = 0.1
adaptive_alpha: float = 0.001
sampling_mode: Literal["adaptive", "uniform", "start"] = "adaptive"
@dataclass
class VizCfg:
mode: Literal["ghost", "frames"] = "ghost"
ghost_color: tuple[float, float, float, float] = (0.5, 0.7, 0.5, 0.5)
viz: VizCfg = field(default_factory=VizCfg)
def build(self, env: ManagerBasedRlEnv) -> MotionCommand:
return MotionCommand(self, env)
(2)mjlab/tasks/tracking/config/g1/env_cfgs.py
"""Unitree G1 flat tracking environment configurations."""
import os
from mjlab.asset_zoo.robots import (
G1_ACTION_SCALE,
get_g1_robot_cfg,
)
from mjlab.envs import ManagerBasedRlEnvCfg
from mjlab.envs.mdp.actions import JointPositionActionCfg
from mjlab.managers.observation_manager import ObservationGroupCfg
from mjlab.sensor import ContactMatch, ContactSensorCfg
from mjlab.tasks.tracking.mdp import MotionCommandCfg
from mjlab.tasks.tracking.tracking_env_cfg import make_tracking_env_cfg
def unitree_g1_flat_tracking_env_cfg(
has_state_estimation: bool = True,
play: bool = False,
) -> ManagerBasedRlEnvCfg:
"""Create Unitree G1 flat terrain tracking configuration."""
cfg = make_tracking_env_cfg()
cfg.scene.entities = {"robot": get_g1_robot_cfg()}
self_collision_cfg = ContactSensorCfg(
name="self_collision",
primary=ContactMatch(mode="subtree", pattern="pelvis", entity="robot"),
secondary=ContactMatch(mode="subtree", pattern="pelvis", entity="robot"),
fields=("found",),
reduce="none",
num_slots=1,
)
cfg.scene.sensors = (self_collision_cfg,)
joint_pos_action = cfg.actions["joint_pos"]
assert isinstance(joint_pos_action, JointPositionActionCfg)
joint_pos_action.scale = G1_ACTION_SCALE
motion_cmd = cfg.commands["motion"]
assert isinstance(motion_cmd, MotionCommandCfg)
motion_cmd.anchor_body_name = "torso_link"
motion_cmd.body_names = (
"torso_link",
"left_shoulder_roll_link",
"left_elbow_link",
"left_wrist_yaw_link",
"right_shoulder_roll_link",
"right_elbow_link",
"right_wrist_yaw_link",
)
# ----------------- 【核心修改:多动作库配置覆盖】 -----------------
# 1. 替换为你存放所有动作 .npz 文件的文件夹路径(请根据你的真实路径调整)
motion_cmd.motion_file = "/home/labuser/unitree_ws/src/unitree_rl_mjlab/g1_library"
# 2. 将多动作并行训练的采样模式默认切换为 uniform,使得多首歌曲被均匀分配训练
motion_cmd.sampling_mode = "uniform"
# ----------------------------------------------------------------
cfg.events["foot_friction"].params[
"asset_cfg"
].geom_names = r"^(left|right)_foot[1-7]_collision$"
cfg.events["base_com"].params["asset_cfg"].body_names = ("torso_link",)
# 注释掉 ee_body_pos 参数覆盖,配合 tracking_env_cfg.py 中的修改
# cfg.terminations["ee_body_pos"].params["body_names"] = (
# "left_ankle_roll_link",
# "right_ankle_roll_link",
# "left_wrist_yaw_link",
# "right_wrist_yaw_link",
# )
cfg.viewer.body_name = "torso_link"
# Modify observations if we don't have state estimation.
if not has_state_estimation:
new_policy_terms = {
k: v
for k, v in cfg.observations["policy"].terms.items()
if k not in ["motion_anchor_pos_b", "base_lin_vel"]
}
cfg.observations["policy"] = ObservationGroupCfg(
terms=new_policy_terms,
concatenate_terms=True,
enable_corruption=True,
)
# Apply play mode overrides.
if play:
# Effectively infinite episode length.
cfg.episode_length_s = int(1e9)
cfg.observations["policy"].enable_corruption = False
cfg.events.pop("push_robot", None)
# Disable RSI randomization.
motion_cmd.pose_range = {}
motion_cmd.velocity_range = {}
motion_cmd.sampling_mode = "start"
return cfg
(3)mjlab/tasks/tracking/tracking_env_cfg,py
"""Motion mimic task configuration.
This module defines the base configuration for motion mimic tasks.
Robot-specific configurations are located in the config/ directory.
This is a re-implementation of BeyondMimic (https://beyondmimic.github.io/).
Based on https://github.com/HybridRobotics/whole_body_tracking
Commit: f8e20c880d9c8ec7172a13d3a88a65e3a5a88448
"""
from mjlab.envs import ManagerBasedRlEnvCfg
from mjlab.envs.mdp.actions import JointPositionActionCfg
from mjlab.managers.action_manager import ActionTermCfg as ActionTermCfg # (imported as ActionTermCfg via other modules, kept as is)
from mjlab.managers.action_manager import ActionTermCfg
from mjlab.managers.command_manager import CommandTermCfg
from mjlab.managers.event_manager import EventTermCfg
from mjlab.managers.observation_manager import ObservationGroupCfg, ObservationTermCfg
from mjlab.managers.reward_manager import RewardTermCfg
from mjlab.managers.scene_entity_config import SceneEntityCfg
from mjlab.managers.termination_manager import TerminationTermCfg
from mjlab.scene import SceneCfg
from mjlab.sim import MujocoCfg, SimulationCfg
from mjlab.tasks.tracking import mdp
from mjlab.tasks.tracking.mdp import MotionCommandCfg
from mjlab.terrains import TerrainImporterCfg
from mjlab.utils.noise import UniformNoiseCfg as Unoise
from mjlab.viewer import ViewerConfig
VELOCITY_RANGE = {
"x": (-0.5, 0.5),
"y": (-0.5, 0.5),
"z": (-0.2, 0.2),
"roll": (-0.52, 0.52),
"pitch": (-0.52, 0.52),
"yaw": (-0.78, 0.78),
}
def make_tracking_env_cfg() -> ManagerBasedRlEnvCfg:
"""Create base tracking task configuration."""
##
# Observations
##
policy_terms = {
"command": ObservationTermCfg(
func=mdp.generated_commands, params={"command_name": "motion"}
),
# "motion_anchor_pos_b": ObservationTermCfg(
# func=mdp.motion_anchor_pos_b,
# params={"command_name": "motion"},
# noise=Unoise(n_min=-0.5, n_max=0.5),
# ),
"motion_anchor_ori_b": ObservationTermCfg(
func=mdp.motion_anchor_ori_b,
params={"command_name": "motion"},
noise=Unoise(n_min=-0.05, n_max=0.05),
),
# "base_lin_vel": ObservationTermCfg(
# func=mdp.builtin_sensor,
# params={"sensor_name": "robot/imu_lin_vel"},
# noise=Unoise(n_min=-0.5, n_max=0.5),
# ),
"base_ang_vel": ObservationTermCfg(
func=mdp.builtin_sensor,
params={"sensor_name": "robot/imu_ang_vel"},
noise=Unoise(n_min=-0.2, n_max=0.2),
),
"joint_pos": ObservationTermCfg(
func=mdp.joint_pos_rel,
noise=Unoise(n_min=-0.01, n_max=0.01),
params={"biased": True},
),
"joint_vel": ObservationTermCfg(
func=mdp.joint_vel_rel, noise=Unoise(n_min=-0.5, n_max=0.5)
),
"actions": ObservationTermCfg(func=mdp.last_action),
}
critic_terms = {
"command": ObservationTermCfg(
func=mdp.generated_commands, params={"command_name": "motion"}
),
"motion_anchor_pos_b": ObservationTermCfg(
func=mdp.motion_anchor_pos_b, params={"command_name": "motion"}
),
"motion_anchor_ori_b": ObservationTermCfg(
func=mdp.motion_anchor_ori_b, params={"command_name": "motion"}
),
"body_pos": ObservationTermCfg(
func=mdp.robot_body_pos_b, params={"command_name": "motion"}
),
"body_ori": ObservationTermCfg(
func=mdp.robot_body_ori_b, params={"command_name": "motion"}
),
"base_lin_vel": ObservationTermCfg(
func=mdp.builtin_sensor, params={"sensor_name": "robot/imu_lin_vel"}
),
"base_ang_vel": ObservationTermCfg(
func=mdp.builtin_sensor, params={"sensor_name": "robot/imu_ang_vel"}
),
"joint_pos": ObservationTermCfg(func=mdp.joint_pos_rel),
"joint_vel": ObservationTermCfg(func=mdp.joint_vel_rel),
"actions": ObservationTermCfg(func=mdp.last_action),
}
observations = {
"policy": ObservationGroupCfg(
terms=policy_terms,
concatenate_terms=True,
enable_corruption=True,
),
"critic": ObservationGroupCfg(
terms=critic_terms,
concatenate_terms=True,
enable_corruption=False,
),
}
##
# Actions
##
actions: dict[str, ActionTermCfg] = {
"joint_pos": JointPositionActionCfg(
entity_name="robot",
actuator_names=(".*",),
scale=0.5,
use_default_offset=True,
)
}
##
# Commands
##
commands: dict[str, CommandTermCfg] = {
"motion": MotionCommandCfg(
entity_name="robot",
resampling_time_range=(1.0e9, 1.0e9),
debug_vis=True,
pose_range={
"x": (-0.05, 0.05),
"y": (-0.05, 0.05),
"z": (-0.01, 0.01),
"roll": (-0.1, 0.1),
"pitch": (-0.1, 0.1),
"yaw": (-0.2, 0.2),
},
velocity_range=VELOCITY_RANGE,
joint_position_range=(-0.1, 0.1),
# Override in robot cfg.
motion_file="",
anchor_body_name="",
body_names=(),
)
}
##
# Events
##
events: dict[str, EventTermCfg] = {
"push_robot": EventTermCfg(
func=mdp.push_by_setting_velocity,
mode="interval",
interval_range_s=(1.0, 3.0),
params={"velocity_range": VELOCITY_RANGE},
),
"base_com": EventTermCfg(
mode="startup",
func=mdp.randomize_field,
domain_randomization=True,
params={
"asset_cfg": SceneEntityCfg("robot", body_names=()), # Set in robot cfg.
"operation": "add",
"field": "body_ipos",
"ranges": {
0: (-0.025, 0.025),
1: (-0.05, 0.05),
2: (-0.05, 0.05),
},
},
),
"encoder_bias": EventTermCfg(
mode="startup",
func=mdp.randomize_encoder_bias,
params={
"asset_cfg": SceneEntityCfg("robot"),
"bias_range": (-0.01, 0.01),
},
),
"foot_friction": EventTermCfg(
mode="startup",
func=mdp.randomize_field,
domain_randomization=True,
params={
"asset_cfg": SceneEntityCfg("robot", geom_names=()), # Set per-robot.
"operation": "abs",
"field": "geom_friction",
"ranges": (0.3, 1.2),
},
),
}
##
# Rewards
##
rewards: dict[str, RewardTermCfg] = {
"motion_global_root_pos": RewardTermCfg(
func=mdp.motion_global_anchor_position_error_exp,
weight=0.0,
params={"command_name": "motion", "std": 0.3},
),
"motion_global_root_ori": RewardTermCfg(
func=mdp.motion_global_anchor_orientation_error_exp,
weight=0.0,
params={"command_name": "motion", "std": 0.4},
),
# ==================== 🔥 核心安全修改 ====================
# 保持 6.0 的超高强度关键骨骼位姿向外牵引拉力。
# 减小 std 到 0.12,这样当机器人手肘离绿色动作有一点点偏差时,奖励也会断崖式下跌,强迫它对齐。
"motion_body_pos": RewardTermCfg(
func=mdp.motion_relative_body_position_error_exp,
weight=6.0,
params={"command_name": "motion", "std": 0.12},
),
# =======================================================
"motion_body_ori": RewardTermCfg(
func=mdp.motion_relative_body_orientation_error_exp,
weight=1.5,
params={"command_name": "motion", "std": 0.3},
),
"motion_body_lin_vel": RewardTermCfg(
func=mdp.motion_global_body_linear_velocity_error_exp,
weight=1.0,
params={"command_name": "motion", "std": 1.0},
),
"motion_body_ang_vel": RewardTermCfg(
func=mdp.motion_global_body_angular_velocity_error_exp,
weight=1.0,
params={"command_name": "motion", "std": 3.14},
),
# ==================== 🛠️ 替换有维度风险的项 ====================
# 彻底移除会引起维度报错的原始 joint 观测函数。
# 稍微拉大动作平滑惩罚(action_rate_l2),使关节输出更平滑,防止由于快速换向导致的肘部死区。
"action_rate_l2": RewardTermCfg(func=mdp.action_rate_l2, weight=-0.2),
# ============================================================
"joint_limit": RewardTermCfg(
func=mdp.joint_pos_limits,
weight=-0.5,
params={"asset_cfg": SceneEntityCfg("robot", joint_names=(".*",))},
),
"self_collisions": RewardTermCfg(
func=mdp.self_collision_cost,
weight=-10.0,
params={"sensor_name": "self_collision"},
),
}
##
# Terminations
##
terminations: dict[str, TerminationTermCfg] = {
"time_out": TerminationTermCfg(func=mdp.time_out, time_out=True),
}
##
# Assemble and return
##
return ManagerBasedRlEnvCfg(
scene=SceneCfg(terrain=TerrainImporterCfg(terrain_type="plane"), num_envs=1),
observations=observations,
actions=actions,
commands=commands,
events=events,
rewards=rewards,
terminations=terminations,
viewer=ViewerConfig(
origin_type=ViewerConfig.OriginType.ASSET_BODY,
entity_name="robot",
body_name="",
distance=3.0,
elevation=-5.0,
azimuth=90.0,
),
sim=SimulationCfg(
nconmax=35,
njmax=250,
mujoco=MujocoCfg(
timestep=0.005,
iterations=10,
ls_iterations=20,
),
),
decimation=4,
# ----------------- 【核心修改】 -----------------
# 将单回合最长时限从 10.0 秒扩展到 300.0 秒,给大动作库中的长舞蹈留出足够的播放空间
episode_length_s=300.0,
# ------------------------------------------------
)
(4)scripts/play.py
"""Script to play RL agent with RSL-RL."""
import os
import sys
from dataclasses import asdict, dataclass
from pathlib import Path
from typing import Literal
import torch
import tyro
from mjlab.rsl_rl.runners import OnPolicyRunner
from mjlab.envs import ManagerBasedRlEnv
from mjlab.rl import RslRlVecEnvWrapper
from mjlab.tasks.registry import list_tasks, load_env_cfg, load_rl_cfg, load_runner_cls
from mjlab.tasks.tracking.mdp import MotionCommandCfg
from mjlab.utils.os import get_wandb_checkpoint_path
from mjlab.utils.torch import configure_torch_backends
from mjlab.utils.wrappers import VideoRecorder
from mjlab.viewer import NativeMujocoViewer, ViserPlayViewer
@dataclass(frozen=True)
class PlayConfig:
agent: Literal["zero", "random", "trained"] = "trained"
motion_file: str | None = None
wandb_run_path: str | None = None
checkpoint_file: str | None = None
num_envs: int | None = None
device: str | None = None
video: bool = False
video_length: int = 200
video_height: int | None = None
video_width: int | None = None
camera: int | str | None = None
viewer: Literal["auto", "native", "viser"] = "auto"
# Internal flag used by demo script.
_demo_mode: tyro.conf.Suppress[bool] = False
def run_play(task_id: str, cfg: PlayConfig):
configure_torch_backends()
device = cfg.device or ("cuda:0" if torch.cuda.is_available() else "cpu")
env_cfg = load_env_cfg(task_id, play=True)
agent_cfg = load_rl_cfg(task_id)
DUMMY_MODE = cfg.agent in {"zero", "random"}
TRAINED_MODE = not DUMMY_MODE
# Check if this is a tracking task by checking for motion command.
is_tracking_task = "motion" in env_cfg.commands and isinstance(
env_cfg.commands["motion"], MotionCommandCfg
)
if is_tracking_task and cfg._demo_mode:
# Demo mode: use uniform sampling to see more diversity with num_envs > 1.
motion_cmd = env_cfg.commands["motion"]
assert isinstance(motion_cmd, MotionCommandCfg)
motion_cmd.sampling_mode = "uniform"
if is_tracking_task:
motion_cmd = env_cfg.commands["motion"]
assert isinstance(motion_cmd, MotionCommandCfg)
if cfg.motion_file is None:
raise ValueError(
"Tracking tasks require --motion-file pointing to a local motion npz or directory."
)
motion_path = Path(cfg.motion_file).expanduser().resolve()
# ----------------- 【核心修改】 -----------------
# 支持整个 motions_dir 文件夹存在校验
if not motion_path.exists():
raise FileNotFoundError(f"Motion path not found: {motion_path}")
motion_cmd.motion_file = str(motion_path)
# 只要是多动作库,强制开启 uniform/随机 采样,这样才能通过多个环境观察到不同的舞蹈效果
motion_cmd.sampling_mode = "uniform"
if motion_path.is_dir():
print(f"[INFO] Playing with batch motion directory: {motion_cmd.motion_file}")
else:
print(f"[INFO] Playing with single motion file: {motion_cmd.motion_file}")
# ----------------------------------------------------
log_dir: Path | None = None
resume_path: Path | None = None
if TRAINED_MODE:
log_root_path = (Path("logs") / "rsl_rl" / agent_cfg.experiment_name).resolve()
if cfg.checkpoint_file is not None:
resume_path = Path(cfg.checkpoint_file)
if not resume_path.exists():
raise FileNotFoundError(f"Checkpoint file not found: {resume_path}")
print(f"[INFO]: Loading checkpoint: {resume_path.name}")
else:
if cfg.wandb_run_path is None:
raise ValueError(
"`wandb_run_path` is required when `checkpoint_file` is not provided."
)
resume_path, was_cached = get_wandb_checkpoint_path(
log_root_path, Path(cfg.wandb_run_path)
)
# Extract run_id and checkpoint name from path for display.
run_id = resume_path.parent.name
checkpoint_name = resume_path.name
cached_str = "cached" if was_cached else "downloaded"
print(
f"[INFO]: Loading checkpoint: {checkpoint_name} (run: {run_id}, {cached_str})"
)
log_dir = resume_path.parent
if cfg.num_envs is not None:
env_cfg.scene.num_envs = cfg.num_envs
if cfg.video_height is not None:
env_cfg.viewer.height = cfg.video_height
if cfg.video_width is not None:
env_cfg.viewer.width = cfg.video_width
render_mode = "rgb_array" if (TRAINED_MODE and cfg.video) else None
if cfg.video and DUMMY_MODE:
print(
"[WARN] Video recording with dummy agents is disabled (no checkpoint/log_dir)."
)
env = ManagerBasedRlEnv(cfg=env_cfg, device=device, render_mode=render_mode)
if TRAINED_MODE and cfg.video:
print("[INFO] Recording videos during play")
assert log_dir is not None # log_dir is set in TRAINED_MODE block
env = VideoRecorder(
env,
video_folder=log_dir / "videos" / "play",
step_trigger=lambda step: step == 0,
video_length=cfg.video_length,
disable_logger=True,
)
env = RslRlVecEnvWrapper(env, clip_actions=agent_cfg.clip_actions)
if DUMMY_MODE:
action_shape: tuple[int, ...] = env.unwrapped.action_space.shape # type: ignore
if cfg.agent == "zero":
class PolicyZero:
def __call__(self, obs) -> torch.Tensor:
del obs
return torch.zeros(action_shape, device=env.unwrapped.device)
policy = PolicyZero()
else:
class PolicyRandom:
def __call__(self, obs) -> torch.Tensor:
del obs
return 2 * torch.rand(action_shape, device=env.unwrapped.device) - 1
policy = PolicyRandom()
else:
runner_cls = load_runner_cls(task_id) or OnPolicyRunner
runner = runner_cls(env, asdict(agent_cfg), device=device)
runner.load(str(resume_path), map_location=device)
policy = runner.get_inference_policy(device=device)
# Handle "auto" viewer selection.
if cfg.viewer == "auto":
has_display = bool(os.environ.get("DISPLAY") or os.environ.get("WAYLAND_DISPLAY"))
resolved_viewer = "native" if has_display else "viser"
del has_display
else:
resolved_viewer = cfg.viewer
if resolved_viewer == "native":
NativeMujocoViewer(env, policy).run()
elif resolved_viewer == "viser":
ViserPlayViewer(env, policy).run()
else:
raise RuntimeError(f"Unsupported viewer backend: {resolved_viewer}")
env.close()
def main():
# Parse first argument to choose the task.
# Import tasks to populate the registry.
import mjlab.tasks # noqa: F401
all_tasks = list_tasks()
chosen_task, remaining_args = tyro.cli(
tyro.extras.literal_type_from_choices(all_tasks),
add_help=False,
return_unknown_args=True,
)
# Parse the rest of the arguments + allow overriding env_cfg and agent_cfg.
agent_cfg = load_rl_cfg(chosen_task)
args = tyro.cli(
PlayConfig,
args=remaining_args,
default=PlayConfig(),
prog=sys.argv[0] + f" {chosen_task}",
config=(
tyro.conf.AvoidSubcommands,
tyro.conf.FlagConversionOff,
),
)
del remaining_args, agent_cfg
run_play(chosen_task, args)
if __name__ == "__main__":
main()
6.训练和查看仿真结果
因为我们把时间从10秒更改为300秒,训练时间会很久,训练一次大概是20s
我们之前已经更改了配置文件,所以在训练和查看仿真结果的时候,motion-file参数直接设置成所有视频文件所在的文件夹即可
python3 scripts/train.py Mjlab-Tracking-Flat-Unitree-G1 --motion-file=./data/reference_motions/g1_library --env.scene.num_envs=1024python3 scripts/play.py Mjlab-Tracking-Flat-Unitree-G1 --checkpoint_file=logs/rsl_rl/g1_tracking/2026-07-01_10-28-23/model_0.pt --motion-file=./data/reference_motions/g1_library/
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)