聆犀AI录音卡 × EMBA:手把手构建你的AI数字分身,从课堂录音到知识变现全链路
前言
想象一下:EMBA 课堂上教授讲到关键战略框架,你按下录音卡的瞬间,AI 自动把两小时的课程转成逐字稿、提炼出结构化笔记、更新你的个人 Wiki 知识库,甚至帮你蒸馏出一个「数字分身」——学生可以向它提问,企业可以向它付费咨询。
这不是科幻,这是我正在商学院 EMBA 落地的完整方案。本文以 EMBA 教学场景为例,系统地介绍如何用聆犀AI录音卡 + Claude Code 构建个人本地数字分身,涵盖从数据采集 → 知识编译 → 思维蒸馏 → 平台发布的全链路。
一、AI 数字分身实践体系:不止是一门课
首先,这套体系的核心定位是:
AI 数字分身实践体系 ≠ 一门课,而是一套完整的实践生态。 它融合了课程教学、俱乐部研讨、动手实践、平台运营,贯穿 EMBA 学习全程。
1.1 两大支柱
| 支柱 | 内容 | 核心工具 |
|---|---|---|
| 🛠️ 工具层 | 构建数字分身的核心武器 | Claude Code / CodeX、聆犀AI录音卡 |
| 📖 方法层 | 多样化的组织与学习形态 | 常规课程、AI数字分身俱乐部、专题讲座、场景案例库 |
1.2 服务双重群体
🎓 学员 · 企业家群体 — 五步价值链:
认知 AI → 掌握工具 → 建自分身 → 建专家分身 → 企业价值(市场策略分析、组织架构诊断、财务咨询)
👨🏫 教师 · 咨询导师群体 — 五步价值链:
记录沉淀 → 打造智能体 → 学情分析 → 打磨专业分身 → 商业变现(AI 咨询收费)
二、核心理念:你的数字分身是「编译型」知识系统
这里要先讲一个关键认知转变:
传统数字分身 ≈ 一个模仿你风格的聊天机器人。我们做的不一样。
2.1 两种范式的本质区别
❌ 传统 RAG:用户提问 → 向量检索 → 拼凑片段 → 回答
(无记忆、无成长,每次都是"猜")
✅ 本方案: 原始数据 → LLM 编译 → 结构化 Wiki → 级联更新
(越用越聪明,像一个真正的"第二大脑")
这个思路来自 Karpathy(前 Tesla AI 总监、OpenAI 联合创始人)的核心洞察:不要每次让 AI "检索"你的文档,而是让 AI 先把你的数据"编译"成一个结构化的 Wiki,然后持续维护它。
2.2 三层架构
| 层 | 比喻 | 说明 |
|---|---|---|
| Raw(原始层) | 源代码 | 录音笔记、微信记录、邮件——不可变的原始素材 |
| Wiki(知识层) | 编译产物 | LLM 编译后的结构化知识页面,人类可读、AI 可解析 |
| Skills(智能层) | 可执行程序 | 基于 Wiki 蒸馏出的思维模型、决策框架 |
三、第一步:数据采集 — 用聆犀AI录音卡打通五条管道
数字分身的好坏,根本上取决于数据采集的质量。我们设计了五条管道:
3.1 全景架构
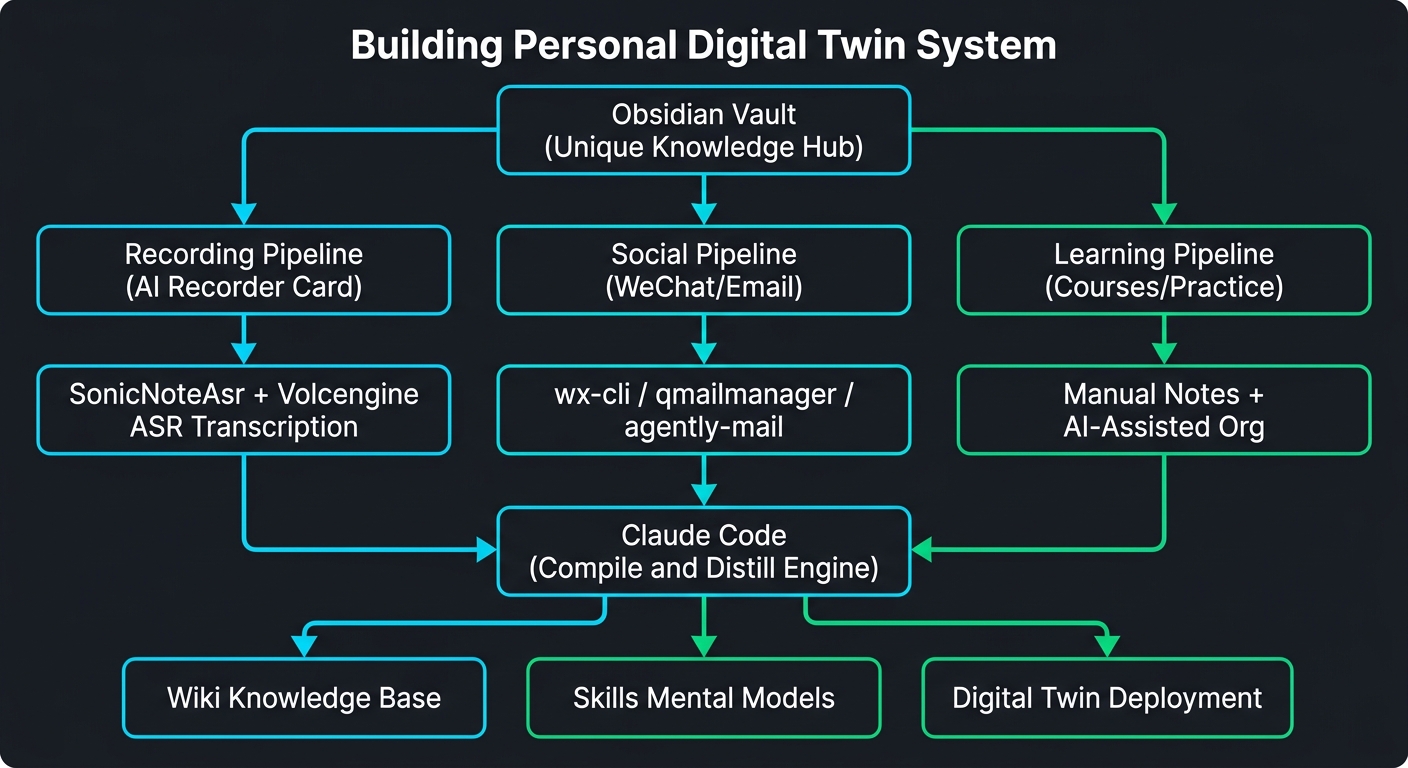
3.2 核心管道:AI 录音卡 — 声音 → 文字 → 知识
这是最重要、最高频的管道。工具链如下:
聆犀AI录音卡 → SonicNoteSync Obsidian 插件 → 火山引擎 ASR → 录音笔记/
适用场景:
| 场景 | 采集内容 | 产出物 |
|---|---|---|
| 🏫 EMBA 课堂 | 教授授课、课堂讨论、Q&A | 章节摘要 + 知识点卡片 + 待深入问题 |
| 🤝 商务会议 | 商业讨论、战略会议、项目复盘 | 决策记录 + 行动项 + 分歧点标注 |
| 🎤 演讲/活动 | 行业分享、圆桌讨论 | 关键观点提取 + 演讲者思维框架 |
| 💭 自言自语 | 个人思考、灵感碎片 | 想法卡片 → 后续发酵 |
工作流四步走:
- 录音 → 聆犀AI录音卡自动采集,Wi-Fi 上传至云端(随身携带,一按即录)
- 转写 → SonicNoteSync 插件触发 火山引擎 ASR,生成逐字稿 + 说话人标注
- LLM 总结 → Claude 按模板生成结构化笔记(摘要 / 要点 / 待办 / 关键引用)
- 入库 → 自动写入 Obsidian Vault 的
录音笔记/目录,带 YAML frontmatter
产出物示例:
# 录音笔记/2026-07-01-商学院EMBA战略管理课程.md
---
date: 2026-07-01
source: 录音
course: 商学院EMBA-战略管理
speakers: [张教授, 学员A, 学员B]
duration: 120min
tags: [战略管理, 课堂, EMBA]
status: 已总结
---
3.3 其他四条管道
| 管道 | 工具链 | 采集内容 |
|---|---|---|
| 💬 微信数据 | wx-cli → 微信笔记/ → Claude 分析 |
聊天记录、朋友圈、群聊 → 提取观点/决策/关系/承诺 |
| 📧 邮件数据 | qmailmanager726 / agently-mail | 项目时间线、承诺追踪、关键联系人 |
| 📚 学习资料 | 手动笔记 + Zotero 桥接 | 书本/论文/课程 → 知识卡片 |
| ✍️ 个人日记 | 日记/流水账 + work-summary | 内心独白、价值观、情绪模式 |
四、第二步:知识编译 — Karpathy Wiki 架构落地
当数据采集跑起来之后,下一步是让 Claude Code 帮你「编译」数据。
4.1 Obsidian Vault 目录结构
Obsidian Vault/
│
├── 录音笔记/ ← Raw 层:原始素材(不可变)
├── 微信笔记/ ← Raw 层:微信数据
├── 学习笔记/ ← Raw 层:学习素材
│
├── Wiki/ ← 🆕 编译后的知识层
│ ├── index.md ← 全局导航索引(自动维护)
│ ├── log.md ← 操作日志
│ ├── entities/ ← 实体页面(人、组织、产品)
│ ├── concepts/ ← 概念页面(理论、框架、方法论)
│ ├── decisions/ ← 决策日志
│ ├── projects/ ← 项目页面
│ └── queries/ ← 常问问题(自动回填)
│
├── Skills/ ← 🆕 可执行智能层
│ ├── profile.md ← 个人能力画像
│ ├── thinking.md ← 思维模型与决策框架
│ ├── style.md ← 表达风格 DNA
│ └── knowledge.md ← 专业知识域地图
│
└── CLAUDE.md ← 规则层:系统宪法
4.2 四大核心操作
| 操作 | 触发方式 | Claude Code 自动执行 |
|---|---|---|
| 📥 Ingest(摄入) | 放入新素材后说 “ingest 录音笔记/xxx.md” | 读取 → 判断合并/新建 → 分布式写入 → 级联更新 → 冲突标注 |
| 🔍 Query(查询) | 自然语言提问 | 定位 Wiki → 综合回答 → 引用来源 → 自动回填 Q&A |
| 📚 Archive(回填) | 自动触发 | 高频查询 → 自动升级为正式 Wiki 页面 |
| 🩺 Lint(健康检查) | “检查 Wiki 健康” | 修复断链 → 报告孤立页面 → 标记过期内容 |
4.3 CLAUDE.md 规则层
在 Obsidian Vault 根目录创建 CLAUDE.md,这是整个数字分身系统的「宪法」:
## 角色
你是我的数字分身维护引擎。
## 目录约定
- 录音笔记/、微信笔记/ = 不可变原始素材
- Wiki/ = 你维护的结构化知识层
- Skills/ = 基于 Wiki 蒸馏的可执行思维模型
## Ingest 规则
1. 通读并理解内容
2. 提取:实体、概念、决策、关系
3. 判断合并 vs 新建
4. 分布式写入,保持原子性
5. 冲突标注而非覆盖
6. 更新 index.md 和 log.md
## 安全规则
- 绝不修改 Raw 目录的原始文件
- 写在 Raw 中的个人信息不上传至任何云端
五、第三步:智能蒸馏 — 用「女娲」从你的数据中提炼一个「你」
这是整个方案中最「酷」的环节。
5.1 女娲造人:数据 → 思维模型

女娲(huashu-nuwa) 是一个 Skill,它的工作流如下:
你的全量数据(微信对话 + 录音 + 邮件 + 笔记)
↓
女娲核心流程:
1. 深度调研(扫描你的全部数据)
2. 思维框架提炼(提取你的心智模型)
3. 生成可运行的人物 Skill
├── 决策启发式(你怎么做决定)
├── 表达 DNA(你说话的风格)
├── 知识域地图(你懂什么、不懂什么)
└── 价值观排序(你最看重什么)
↓
输出:{你的名字}-perspective Skill
5.2 蒸馏输出结构
| 模块 | 内容 | 数据来源 |
|---|---|---|
| 🧠 心智模型 | 5-7 个核心思维模型 | 全量数据综合分析 |
| 🎯 决策启发式 | 8-10 条决策规则 | 微信对话 + 邮件中的决策模式 |
| 🗣️ 表达 DNA | 语言风格、常用句式、说服模式 | 微信聊天记录 + 录音笔记 |
| 🗺️ 知识域地图 | 深度区 / 广度区 / 盲区 | 学习笔记 + 微信讨论话题 |
| ❤️ 价值观排序 | 如:诚实 > 效率、长期 > 短期 | 日记 + 微信 + 决策记录 |
5.3 数据采集量建议
| 数据源 | 对蒸馏的贡献度 | 最小采集量 |
|---|---|---|
| 微信聊天记录 | ⭐⭐⭐⭐⭐ | 3 个月以上 |
| 录音笔记 | ⭐⭐⭐⭐ | 30 条以上 |
| 邮件往来 | ⭐⭐⭐ | 50 封以上 |
| 学习笔记 | ⭐⭐⭐ | 20 篇以上 |
| 日记/流水账 | ⭐⭐⭐⭐ | 30 天以上 |
六、全链路实操时间线
从今天开始,8 周完成从零到数字分身发布:
| 阶段 | 时间 | 目标 | 关键任务 |
|---|---|---|---|
| 🌱 基建 | 第 1-2 周 | 搭好架子 | 配置录音卡 + SonicNoteSync 插件、创建 Wiki/Skills 目录、配置 CLAUDE.md |
| 🌿 播种 | 第 3-4 周 | 积累数据 | 持续录音笔记积累、导出微信核心对话、首次 Ingest |
| 🌳 蒸馏 | 第 5-6 周 | 生成 Skill | 确保 Raw 层 50+ 篇素材、调用女娲、审查 → 测试 → 迭代 |
| 🚀 闭环 | 第 7-8 周 | 发布变现 | 周常 Ingest 例程、月常 Lint 检查、打包 Skills + Wiki → 平台发布 |
七、关键原则
7.1 Karpathy 四大数据主权原则
| 原则 | 本方案的实现 |
|---|---|
| 显式(Explicit) | 所有知识在 Markdown 中可见可编辑,不是向量黑箱 |
| 你的(Yours) | 数据存在本地 Vault,不经任何第三方 AI 厂商中转存储 |
| File over App | 纯 Markdown + YAML,换什么工具都能读写 |
| BYOAI | Claude Code 是当前引擎,架构不绑定——换任何 LLM 均可 |
7.2 隐私红线
⛔ Raw 层数据绝不上云:微信聊天记录、个人邮件、私人录音留在本地
✅ Wiki 层可选择性发布:编译后脱敏的知识页面可以公开
🔐 分层授权:公开版 / 群组版 / 私密版
八、工具与资源汇总
硬件 & 软件
| 工具 | 用途 | 获取方式 |
|---|---|---|
| 🎙️ 聆犀AI录音卡 | 随身录音采集 | ainote.easylinkin.com |
| 📱 妙记 App | 录音管理 + ASR 转写 | ainote.easylinkin.com |
| 🔌 SonicNoteSync 插件 | Obsidian 录音转写插件 | ainote.easylinkin.com/download/obsidian-plugin.html |
| 🤖 Claude Code | AI 智能体引擎 | docs.anthropic.com/zh-CN/docs/claude-code |
Skills 生态
| Skill | 用途 | 地址 |
|---|---|---|
| 🎵 SonicNoteSync | Obsidian 录音转写插件 | skillhub.cn/skills/sonicnotesync |
| 🧬 huashu-nuwa(女娲) | 从数据蒸馏人物 Skill | skillhub.cn/skills/huashu-nuwa |
| 🧠 claude-mem | 跨会话记忆注入 | skillhub.cn/skills/claude-mem |
| 💰 buffett | 巴菲特投资思维框架 | skillhub.cn/skills/buffett |
| 🍎 steve-jobs-perspective | 乔布斯产品思维 | skillhub.cn/skills/steve-jobs-perspective |
| 🚩 mao-zedong-perspective | 战略分析方法论 | skillhub.cn/skills/mao-zedong-perspective |
| 🧘 duan-yongping-perspective | 段永平投资与商业思维 | skillhub.cn/skills/duan-yongping-perspective |
| 🎓 munger-perspective | 查理·芒格多元思维模型 | skillhub.cn/skills/munger-perspective |
在线资源
| 资源 | 地址 |
|---|---|
| 📄 数字分身方法论完整版(网页) | linkaip.easylinkin.com/public/digital-twin-methodology.html |
| 🧬 女娲 Skill(Nuwa) | github.com/alchaincyf/nuwa-skill |
九、写在最后
「数字分身不是复制一个你,而是把你的知识、思维、经验编译成一个可持续进化的外部大脑——让 AI 成为你认知的延伸,而非替代。」
对于 EMBA 学员和教师来说,这套体系的价值不仅在于「提高效率」,更在于:
- 📚 知识复利:每节课、每次会议、每条思考都在积累,越用越聪明
- 💼 商业变现:专业分身可以对外提供付费咨询,实现知识资产化
- 🏫 教学相长:教师的分身可以 24×7 服务学生,学生也可以构建自己的学习分身
- 🔒 数据主权:你的数据始终在你手中,不是某个 AI 厂商的训练素材
构建开始于你放进第一段录音的那一刻。现在就可以开始。
本文作者:zhaohp0915 | 2026-07-02

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)