科研小白的论文精读:机器人操作中的扩散模型
目录
1.2.3.1.输入数据异构性:不同输入模态统一进入机器人策略
1.2.3.2.机器人本体感受异质性:不同机器人共享相同的策略模型
1.3.2.基于小型CNN或Transformer的扩散策略
1.3.2.4.利用MoE架构:复杂问题交给多个专家进行处理
1.3.3.1.VAE 和 VQ-VAE方法与扩散模型相结合:先压缩再扩展生成
即将开启一个新的方向最重要的就是从综述论文入手
首先先得明白几个概念:
1.马尔科夫链:https://zhuanlan.zhihu.com/p/448575579
2.扩散模型:扩散模型(Diffusion Model)详解:直观理解、数学原理、PyTorch 实现 | 周弈帆的博客
1.论文标题:A Survey on Diffusion Policy for Robotic Manipulation: Taxonomy, Analysis, and Future Directions
1.1.从能量模型到扩散模型
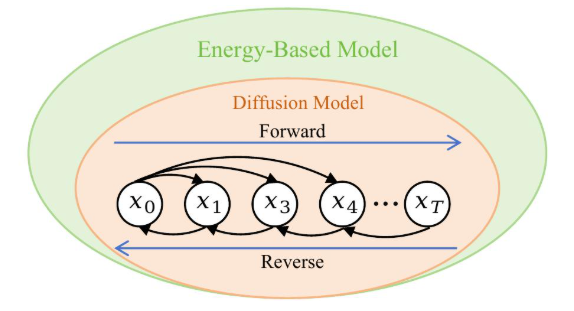
能量模型 EBM 和扩散模型本质上都在学习“数据在哪里更可能出现”。EBM 用能量函数 Eθ(x)表示概率高低;扩散模型用 score function,也就是 ∇xlogp(x),表示应该往哪个方向去噪。两者之间的桥梁就是:score function 正好等于能量函数的负梯度。
EBM 生成样本的思路是:从一个随机点开始,然后沿着能量下降的方向走,最后走到低能量区域。扩散模型说的是当前噪声图应该往哪个方向移动,概率更高、更像真实图像。
1.2.机器人数据表示
1.2.1. 二维表示
二维表示在机器人操作的扩散策略研究中占据主导地位。该领域的研究主要分为两大类:直接利用机器人轨迹数据的方法和利用人类视频的方法。
1.2.1.1.机器人轨迹
| 层次 | 代表方法 | 核心作用 |
|---|---|---|
| 基础范式 | Diffuser | 把轨迹生成建模为条件扩散生成 |
| 视觉动作控制 | Diffusion Policy | 从视觉输入中生成动作轨迹 |
| 大规模模型 | Octo, RDT-1B | 统一大规模机器人数据,实现跨任务泛化 |
| 架构改进 | DiT-Block Policy, MTDP | 提高模型稳定性和条件融合能力 |
| 分层规划 | HDP, DTP | 先预测高层目标,再生成低层轨迹 |
| 表征增强 | Crossway Diffusion, S2-Diffusion | 强化视觉、语义和空间表征 |
| 专用应用 | ReorientDiff, collision avoidance, MPD | 面向重定向、避碰、运动规划等具体任务 |
1.2.1.2.人类视频
| 方向 | 代表方法 | 核心思想 | 解决的问题 |
|---|---|---|---|
| 潜在动作学习 | LAPA | 从互联网视频中提取离散 latent actions | 没有机器人标签也能预训练 |
| 统一 token 表示 | VPDD | 将人类和机器人视频压缩到统一 token 空间 | 跨人类/机器人视频共享表示 |
| 人机动作对齐 | Human2Robot | 用 VR 数据建立人类动作与机器人动作对齐 | 解决人手和机器人动作不一致 |
| 无遥操作学习 | Point Policy | 从离线人类视频中提取语义关键点并转为机器人位姿 | 减少甚至摆脱机器人遥操作数据 |
1.2.1.3.优劣
机器人轨迹方法在精度方面表现出色,而人类视频方法则提供卓越的可扩展性和多样性,这表明结合这些优势的混合方法可能带来潜在的好处
1.2.2. 三维表示
3D表示通过显式的空间理解来增强扩散策略,从而能够更有效地推理3D空间中的对象关系和操作任务
1.2.2.1.单视角点云
| 方向 | 代表方法 | 核心思想 | 主要解决的问题 |
|---|---|---|---|
| 基础点云策略 | DP3 | 稀疏点采样 + MLP 编码点云 | 证明 3D 点云优于 2D policy |
| 通用机器人扩展 | iDP3 | 自我中心 3D 表征 | 面向 general-purpose robots |
| 几何等变建模 | EquiBot, EDFs | SIM(3)/SE(3) 等变性 | 提高空间变换泛化能力 |
| 语义增强 | GenDP | 3D semantic fields | 融合几何和语义信息 |
| 关节物体操作 | ADAMANIP | adaptive demonstrations + 3D visual diffusion | 操作抽屉、门等 articulated objects |
| 关系重排 | RPDiff | 6-DoF relational rearrangement | 跨形状、跨布局的物体关系操作 |
| 复杂 3D 规划 | StructDiffusion | object-centric transformer + diffusion | 复杂三维场景规划 |
| 灵巧抓取 | DexGrasp-Diffusion, DexDiffuser | 从点云生成灵巧手抓取 | 多灵巧手、部分点云抓取 |
| 关键点生成 | RoboKeyGen | score-based 3D keypoint diffusion | 估计机器人姿态和关节角 |
| 快速推理 | ManiCM | consistency model | 一步生成动作,提高效率 |
1.2.2.2.多视角点云
| 方向 | 代表方法 | 核心思想 | 主要解决的问题 |
|---|---|---|---|
| 2D-to-3D 轨迹生成 | ChainedDiffuser | 将 2D 特征通过深度提升到 3D,先生成末端位姿再连接轨迹 | 从视觉特征生成 3D 操作轨迹 |
| 运动学感知轨迹生成 | RK-Diffuser | 先预测 next-best end-effector pose,再生成运动学可行轨迹 | 保证轨迹符合机器人运动学约束 |
| NeRF 预训练表征 | DNAct | 用 NeRF 从多视角图像中学习统一语义和几何表示 | 增强多任务、多模态示范的 3D 表征 |
| 语言条件 3D 轨迹生成 | 3D Diffuser Actor | token 化多视角 3D 场景,根据语言指令生成 3D 轨迹 | 将语言、3D 场景和动作生成结合 |
| 双臂 3D 轨迹生成 | Bi3D Diffuser Actor | 聚合多视角 3D 特征,同时生成左右末端轨迹 | 实现双臂协同操作 |
1.2.3. 异构数据表示
我们将机器人操作中的异构性分为两种类型:输入数据异构性,解决整合不同传感器输入和数据源的挑战;
1.2.3.1.输入数据异构性:不同输入模态统一进入机器人策略
| 方法 | 核心思想 | 解决的问题 |
|---|---|---|
| PoCo | 将不同模态的数据分布表示为 diffusion models,再进行 policy composition | 支持图像、点云、触觉等多模态策略组合 |
| HPT | 提出统一 trunk 结构,兼容不同数据来源和 diffusion policy head | 解决机器人遥操作、部署机器人、仿真、人类视频之间的数据集异构性 |
1.2.3.2.机器人本体感受异质性:不同机器人共享相同的策略模型
| 方法 | 核心思想 | 解决的问题 |
|---|---|---|
| RDT-1B | 用 diffusion foundation model 和 transformer backbone 统一多机器人双臂操作数据 | 解决不同机器人、不同动作空间、不同模态之间的异构性 |
| (\pi_0) | 使用预训练视觉语言模型 backbone,结合跨具身数据集和 flow matching 生成连续动作 | 解决不同机器人本体之间的动作生成问题 |
1.2.3.3.优劣
成功的方法证明了开发灵活框架的重要性,这些框架可以提取通用特征,同时保持针对特定机器人平台进行定制的能力。
1.3.模型架构
我们将分析分为三种主要的模型架构:(1)基于大型语言模型的扩散策略,利用来自预训练模型的语义知识;(2)基于小型CNN或Transformer的扩散策略,优先考虑计算效率;以及(3)基于VAE/VQVAE的扩散策略,侧重于高级表征学习。
1.3.1.基于大型语言模型的扩散策略
这一节主要讲:LLM / VLM / VLA 和扩散策略如何结合。
LLM负责语义理解与任务规划,扩散模型负责动作与轨迹生成
这一节又分成两类:
-
General Data Pre-training
-
Robot Data Pre-training
1.3.1.1.通用数据预训练
| 方法 | 使用的大模型/技术 | 核心贡献 |
|---|---|---|
| MDT | CLIP, Voltron, GPT-4 | 用基础模型和 GPT-4 生成语言指令,增强长程操作任务学习 |
| Scaling Up and Distilling Down | LLM + diffusion policy | LLM 做高层规划和成功条件推理,diffusion policy 做低层控制 |
| ROSIE | LLM + text-to-image diffusion | 用 LLM 生成提示词,再用图像扩散模型做数据增强 |
| TinyVLA | 预训练多模态模型 + 参数高效微调 | 冻结大模型,仅训练少量参数,实现高效动作输出 |
| HiP | LLM + video diffusion + inverse model | LLM 做任务规划,视频扩散生成轨迹,逆模型映射到动作 |
| Plan Diffuser | LLM + diffusion model | LLM 生成文本子目标,扩散模型转换成视觉子目标 |
1.3.1.2.机器人数据预训练
| 方法 | 数据来源 | 模型特点 | 主要作用 |
|---|---|---|---|
| Octo | Open X-Embodiment 25 个数据集 | Transformer + diffusion head | 跨机器人、跨任务动作生成 |
| (\pi_0) | 跨具身机器人数据 | VLM backbone + flow matching action expert | 生成连续、平滑的机器人动作 |
| Diffusion-VLA | Open X-Embodiment + Droid | VLM + LoRA fine-tuning | 面向具体任务微调机器人策略 |
| ChatVLA | 机器人数据 + 推理数据 | MoE + staged alignment | 同时增强视觉语言理解和机器人控制 |
| RDT-1B | 多机器人操作数据 | 统一动作空间 + diffusion foundation model | 强化双臂操作和异构机器人数据处理 |
| LAPA | Bridgev2 + Open X-Embodiment + 人类视频 | latent VLA + VQ-VAE action tokens | 从潜在动作迁移到机器人动作 |
1.3.1.3.优劣
然而,在计算效率、跨不同机器人平台的泛化以及在各种操作任务中保持一致的性能方面仍然存在挑战。未来的研究可能集中在更高效的模型架构和开发更强大的迁移学习技术上。
1.3.2.基于小型CNN或Transformer的扩散策略
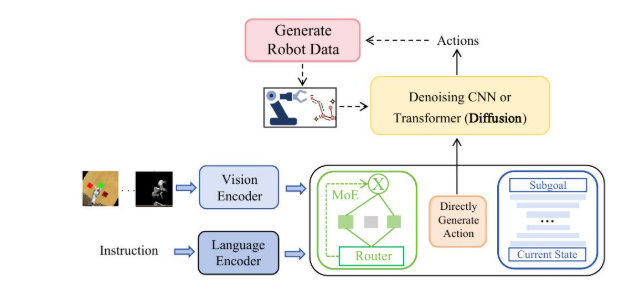
根据其技术特点和模型架构,我们将这些方法分为四种不同的类型:直接生成动作的方法、产生中间子目标的方法、合成机器人训练数据的技术,以及利用混合专家模型(MoE [136])以提高性能的架构。
1.3.2.1.直接生成动作:输入观测,直接输出结果
| 方法 | 输入/表示 | 输出 | 核心贡献 |
|---|---|---|---|
| Diffusion Policy | 图像、状态 | 动作序列 | 首次系统地将动作扩散用于视觉运动控制 |
| DP3 | 单视角点云 | 动作 | 用 3D 点云提升空间泛化能力 |
| Motion Planning Diffusion | 状态/轨迹 | 运动轨迹 | 用 temporal U-Net 生成轨迹 |
| DiT-Block Policy | Transformer diffusion blocks | 动作 | 分析影响稳定性的关键 transformer 组件 |
| MTDP | 视觉条件 + 状态 | 动作 | 用 modulated attention 融合条件信息 |
| DexDiffuser | 抓取候选姿态 | 高质量抓取 | 通过逐步去噪生成多指抓取姿态 |
| 3D Diffuser Actor | tokenized 3D scene | 3D 轨迹 | 使用 3D token 表示而不是全局池化特征 |
| ALOHA Unleashed | 双臂示范数据 | 双臂动作 | 用 transformer + diffusion loss 学习双臂操作 |
| ChainedDiffuser | 3D 表征 | 关键位姿 + 连接轨迹 | 两阶段生成末端关键位姿和轨迹 |
| HDP | 当前位姿 + 预测位姿 | 可行轨迹 | 加入运动学感知能力 |
| StructDiffusion | object-centric representation + language | 重排轨迹 | 面向语言目标的语义重排 |
| DBC | 专家状态-动作对 | policy | 用扩散行为克隆优化策略 |
1.3.2.2.生成子目标:把复杂长任务拆成多个子任务
| 方法 | 子目标形式 | 核心思想 |
|---|---|---|
| CoTDiffusion | visual subgoal images | 把多模态提示转化为视觉子目标,用于 chain-of-thought 式规划 |
| ReflectVLM | visual prediction | 用扩散动力学模型进行反思式规划和动作修正 |
| Subgoal Diffuser | coarse-to-fine subgoals | 根据可达性动态确定子目标密度 |
| SuSIE | hypothetical future observations | 用图像编辑扩散模型生成未来观测,提高泛化 |
| DALL-E-Bot | target configurations | 用 text-to-image diffusion 生成目标物体布局 |
| CACTI | multi-task augmented data | 用生成模型做多任务数据增强 |
| UniPi | video trajectories | 用文本引导视频生成,再通过逆动力学转为动作 |
1.3.2.3.生成机器人训练数据
| 方法 | 生成的数据类型 | 核心贡献 |
|---|---|---|
| AdaptDiffuser | synthetic expert trajectories | 用 reward-guided diffusion 生成目标条件专家数据 |
| DemoGen | synthetic demonstrations | 从少量人类示范生成适应新物体配置的动作轨迹 |
| JUICER | bottleneck-state data | 自动扩展瓶颈状态附近的数据覆盖 |
| ALDMGrasping | photorealistic simulation images | 用 layout-to-image diffusion 提升仿真真实感 |
| ROSIE | augmented robot images | 用 text-to-image diffusion 和 inpainting 引入新物体/背景 |
| GenAug | semantic visual augmentations | 生成语义合理且物理一致的视觉增强数据 |
1.3.2.4.利用MoE架构:复杂问题交给多个专家进行处理
| 方法 | 核心设计 | 作用 |
|---|---|---|
| Sparse Diffusion Policy | 在 transformer-based diffusion policy 中加入 sparse MoE | 按任务选择性激活专家模块,提高效率和技能复用能力 |
1.3.2.5.优劣
将小规模的CNN或Transformer模型与扩散模型集成,在多个方面提升了机器人操作能力。直接动作生成方法擅长实时执行,但可能难以应对复杂的规划。子目标生成方法为长时程任务提供分层结构,但确定最佳子目标密度仍然具有挑战性。机器人数据生成方法通过合成多样化的数据集来解决数据稀缺问题,有可能弥合模拟到真实的差距,尽管在捕捉真实世界的可变性方面存在局限性。MoE架构通过仅激活与任务相关的模型组件来提高效率,但有效的专家路由仍然很困难
1.3.3.基于VAE / VQ-VAE的扩散策略
这一节讲的是:用 VAE 或 VQ-VAE 把高维图像、视频、动作压缩到潜在空间,再在潜在空间中使用扩散模型。
核心思想是:
先压缩,再扩散生成
这样做的好处是:
-
降低维度;
-
提高训练效率;
-
得到更结构化的动作表示;
-
支持从人类视频迁移到机器人动作
1.3.3.1.VAE 和 VQ-VAE方法与扩散模型相结合:先压缩再扩展生成
| 方法 | 使用技术 | 压缩对象 | 扩散发生的位置 | 核心作用 |
|---|---|---|---|---|
| GEVRM | 2D/3D VAE + T5 + DiT | 机器人图像状态 | goal state latent space | 生成目标状态,支持目标导向操作 |
| Discrete Policy | VQ / vector quantization | 动作序列 | discrete latent action space | 把多任务动作映射为离散代码,再重构为动作 |
| VPDD | VQ-VAE + discrete diffusion | 人类/机器人视频 | future video token space | 预测未来视频 token,用想象视频指导动作学习 |
| LAPA | VQ-VAE action quantization + latent VLA | 人类视频中的动作变化 | latent action space | 从无机器人标签视频中提取潜在动作,再迁移到机器人动作 |
1.3.3.2.优劣
采用扩散模型的VAE/VQ-VAE架构通过降维和离散表示学习来增强机器人操作能力。这些方法创建了结构化的潜在空间,捕捉了基本的动作原语,从而能够从人类演示中进行高效学习和知识转移。
怎么选择这两类方法
| 场景 | 更适合的方法 | 原因 |
|---|---|---|
| 有较多机器人动作数据 | 小型 CNN/Transformer 扩散策略 | 可以直接端到端学习动作生成 |
| 任务需要高频控制 | 小型 CNN/Transformer 或 consistency diffusion | 结构更直接,推理链条更短 |
| 数据是视频或高维图像 | VAE/VQ-VAE 扩散策略 | 先压缩可以降低建模难度 |
| 想利用人类视频 | VQ-VAE 扩散策略 | 可把人类/机器人视频统一成 token |
| 想学习动作原语或技能 token | VQ-VAE 扩散策略 | 离散潜在空间更适合表达技能 |
| 想做直接机器人操作策略 | 小型 CNN/Transformer 扩散策略 | 输入观测后直接输出动作 |
| 想做跨具身迁移 | VAE/VQ-VAE 扩散策略 | latent action 可弱化机器人形态差异 |
1.4.扩散策略
扩散策略在机器人操作中已展现出卓越的能力,但多种策略可以进一步提升其性能和适用性。本节将探讨五个关键方向,以推进扩散模型在机器人学中的应用:1) 结合强化学习,通过奖励信号优化策略;2) 整合等变性原则,以处理几何变换;3) 开发加速采样或去噪策略,以提高计算效率;4) 设计改进的分类器引导技术,以增强输出生成,同时满足特定约束;5) 利用自监督学习方法,以提高使用未标记数据的表征质量。
1.4.1.结合强化学习
| 方法 | 类型 | 核心贡献 |
|---|---|---|
| Diffuser | 轨迹优化 | 将轨迹优化建模为去噪扩散过程,把噪声轨迹逐步优化为高质量轨迹 |
| MTDIFF | 多任务 RL | 将多任务学习视为轨迹去噪问题,缓解 TD 方法中的分布偏移,并生成合成数据 |
| EDGI | model-based RL + planning | 将基于模型的强化学习和规划统一为条件生成建模,并结合等变扩散 |
| Diffusion Reward | 奖励构造 | 使用预训练视频扩散模型构造 dense reward,提高探索效率 |
| DIPO | 在线无模型 RL | 用扩散过程表示复杂多峰动作分布,是首个在线 model-free diffusion RL 方法 |
| DPPO | 策略梯度优化 | 将扩散去噪步骤整合进 PPO 类策略优化,提高稳定性和效率 |
| Q-Score Matching | Q 函数结合 | 对齐 policy score function 和 Q-function gradient,提高优化效率 |
| RLDiffORL | latent diffusion + Q-learning | 在 batch-constrained Q-learning 中利用条件生成模型的潜在空间 |
这一类方法的核心价值是:
用扩散模型增强 RL 的策略表达能力、轨迹优化能力和多任务泛化能力
简单说,传统 RL 更像是“在一个简单动作分布里选动作”,而扩散 RL 更像是“从复杂动作空间中逐步生成一个合理动作或轨迹”。
1.4.2.结合等变性
| 方法 | 引入的等变性 | 核心设计 | 主要优势 |
|---|---|---|---|
| Diffusion-EDFs | SE(3)-equivariance | 提出 bi-equivariant diffusion model,用等变 score function 去噪 | 严格保持 SE(3) 等变性,适合视觉机器人操作 |
| EDGI | Equivariant blocks + U-Net | 将等变模块集成到 U-Net 结构中 | 在低数据条件下显著提高样本效率 |
| EquiBot | SIM(3)-equivariance | PointNet 点云编码器 + SO(3)-equivariant U-Net | 适应不同物体姿态和尺度,提高鲁棒性 |
这一类方法的核心价值是:
让扩散策略天然理解三维空间变换,从而减少训练数据需求并提升泛化
对于机器人操作尤其重要,因为同一个抓取动作在不同物体位置、角度和尺度下应该具有一致的几何规律。
1.4.3.加速采样或去噪策略
| 方法 | 加速策略 | 核心贡献 |
|---|---|---|
| BESO | 少步去噪 | 将 score model learning 和 inference 解耦,仅需约 3 步去噪 |
| ManiCM | consistency distillation | 用一致性模型实现一步动作生成,直接预测 action sample |
| ImitDiff | consistency policy + DiT action head | 将一致性策略加入 DiT 动作头,实现高频响应 |
| DiffuserLite | 分层 coarse-to-fine | 减少冗余建模,提高决策频率 |
| ChainedDiffuser | 分阶段生成 | 先生成关键位姿,再连接轨迹 |
| RK-Diffuser | 分层 + 运动学约束 | 先预测高层末端位姿,再生成运动学可行轨迹 |
| ReorientDiff | FastDPM | 用约 20 步采样完成物体重定向 |
| RoboKeyGen | DDIM + 关键点分解 | 将高维姿态估计拆成 2D/3D 关键点任务 |
| DPPO | 优化 noise schedule | 在 RL 中优化噪声调度,提高稳定性和探索 |
| Diff-DAgger | 训练/推理步数一致 | 使用相同 diffusion steps 改善收敛 |
| (\pi_0) | flow matching | 用最优传输路径提高训练、采样和泛化效率 |
这一类方法的核心价值是:
让扩散策略从“能生成”走向“能实时控制”
对于真实机器人部署来说,这部分非常关键。因为如果一个动作需要很久才能采样出来,就很难用于高频闭环控制。
1.4.4.结合自监督学习
| 方法 | 自监督设计 | 核心贡献 |
|---|---|---|
| MDT | diffusion-based multimodal transformer + self-supervised auxiliary objectives | 通过潜在 token 对齐和自监督辅助任务处理多模态输入,实现长程任务学习 |
| Crossway Diffusion | state decoder 重建图像像素和状态信息 | 从反向扩散中间表示重建原始图像与状态,提高视觉表征鲁棒性 |
这一类方法的核心价值是:
用自监督辅助任务增强扩散策略的感知表征,而不是只依赖动作监督
1.5.未来工作
1.5.1.关于扩散策略选择的建议
1.5.1.1.任务复杂度与数据可用性
| 数据条件 | 推荐方法 | 为什么适合 |
|---|---|---|
| 机器人数据充足,任务复杂 | 直接动作生成方法 | 可以直接学习复杂的多模态动作分布,性能上限高 |
| 机器人数据有限 | 等变模型 | 利用 SE(3)、SIM(3) 等几何先验,提高样本效率 |
| 机器人数据有限 | 预训练基础模型 | 利用大规模预训练知识,减少对任务数据的依赖 |
| 极度缺少机器人数据 | 人类视频方法 | 先从互联网人类视频中学习动作先验,再用少量机器人数据微调 |
1.5.1.2.计算效率选择
| 应用需求 | 推荐方法 | 主要优势 |
|---|---|---|
| 实时控制 | 加速采样方法 | 一步或少步推理,提高动作生成频率 |
| 高频闭环控制 | 一致性模型 / 少步扩散 | 降低扩散模型多步采样带来的延迟 |
| 资源受限平台部署 | 小型 CNN / Transformer 策略 | 在性能和计算成本之间取得平衡 |
1.5.1.3.空间理解需求
| 空间需求 | 推荐方法 | 适用场景 |
|---|---|---|
| 需要精确三维几何理解 | 3D 表征方法 | 复杂物体排列、精细操作 |
| 存在遮挡 | 多视角点云方法 | 单视角看不全的操作场景 |
| 需要适应不同物体位姿 | 等变扩散模型 | 物体旋转、平移、尺度变化明显 |
| 需要双臂空间协同 | 多视角 3D diffusion actor | 双臂操作、复杂空间轨迹生成 |
1.5.1.4.多任务与异构场景
| 场景 | 推荐方法 | 原因 |
|---|---|---|
| 多任务学习 | VAE/VQ-VAE 方法 | 可学习任务相关 latent code,便于知识迁移 |
| 多技能复用 | MoE 方法 | 动态选择专家,提高技能复用效率 |
| 多机器人平台 | 跨具身模型 | 适应不同机器人结构、动作空间和控制接口 |
| 本体感受异构 | VLA / foundation policy | 统一不同机器人状态和动作表达 |

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)