Efficient-WAM:一种低成本未来想象的 1B参数世界-动作模型
26年6月来自Muka Robotics(https://muka-tech.com)、港大、北大、中科大自动化所和南大的论文“Efficient-WAM: A 1B-Parameter World-Action Model with Low-Cost Future Imagination”。
世界-动作模型(World-Action Models,简称 WAMs)通过将未来视觉预测与动作生成相结合,已成为具身控制领域一种极具前景的范式。然而,现有的 WAMs 大多依赖于高保真的视觉预测,这导致了较高的推理延迟,从而阻碍了机器人的实时部署。因此,亟需一种更高效的 WAM 设计,既能保留未来视觉预测在控制方面的优势,又能降低推理成本。为此,提出 Efficient-WAM——一种在降低未来“想象”成本的同时保持控制效能的世界-动作模型。Efficient-WAM 通过以下手段提升了推理效率:采用从 WAN-2.2-5B 迁移而来的紧凑型视频专家模型、使用稀疏 Token 表示的视频隐变量,以及非对称的视频-动作去噪机制(即在去噪过程中为视频分配比动作更少的采样步数)。Efficient-WAM 不再追求未来视觉预测的高保真度,而是将其视为动作生成的紧凑型引导信号。该模型拥有 10 亿(1B)参数,在保持出色控制能力的同时,能将物理部署中的单片段推理延迟降低至约 100 毫秒,较现有 WAMs 实现了 30 倍的速度提升。
如图 1 所示Efficient-WAM 概览。Efficient-WAM 利用低成本的未来想象来捕捉与任务相关的物体及机器人动力学特性,而无需生成照片级逼真的视频。与以往的 WAM 方法相比,它在仿真和现实世界环境中均实现了更低的延迟以及出色的任务成功率。
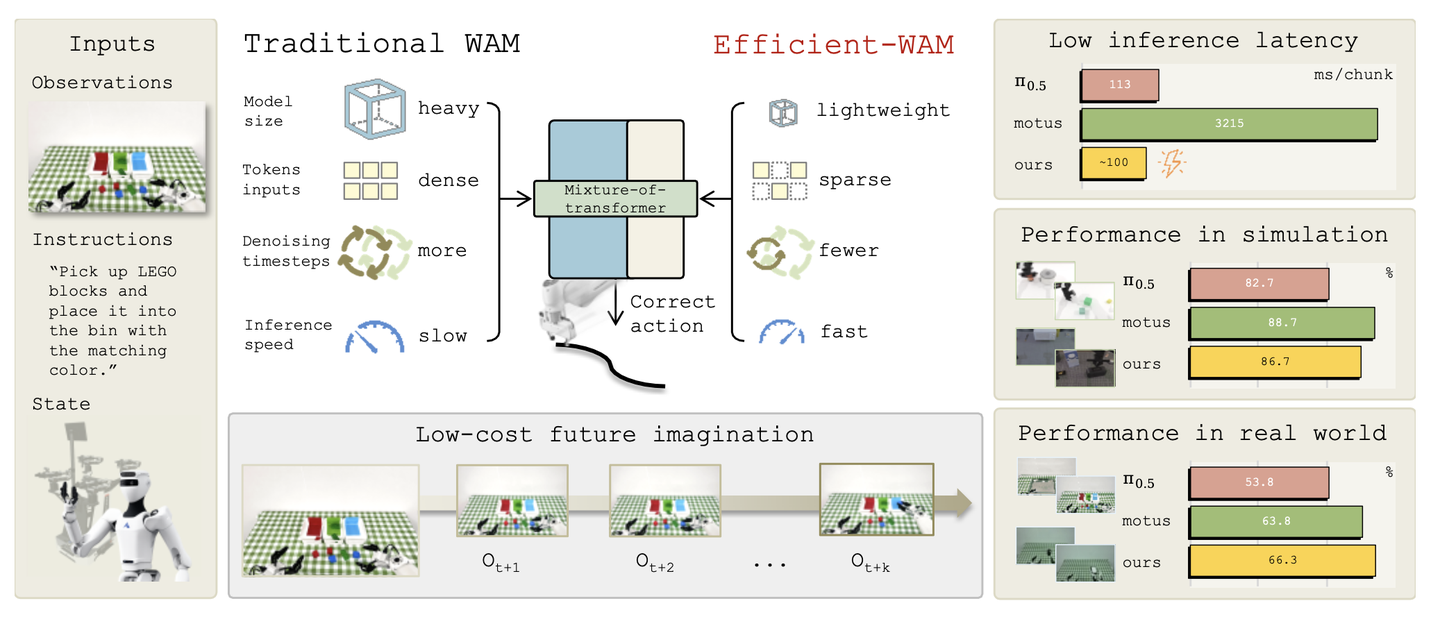
Efficient-WAM 遵循以动作为中心的设计原则:策略依赖的是结构与动态线索,而非照片级的逼真细节。因此,利用从 WAN-2.2-5B 蒸馏出的紧凑型视频专家模型、低分辨率的未来潜表征以及非对称视频-动作去噪技术,对计算成本进行系统性压缩。
大规模视频生成主干网络虽然编码丰富的世界先验知识,但其庞大的参数量使其难以满足实时机器人控制对低延迟的严苛要求。为应对这一挑战,采用一种紧凑的 Transformer 混合(MoT)架构。通过结合轻量级视频专家模块与专用动作专家模块,这种设计既保留了必要的物理世界先验,又显著降低了计算成本。
在构建视频专家模块时,通过减少 Transformer 的深度和层宽度,对 WAN-2.2-5B 模型进行了剪枝。其并未采用随机初始化,而是通过“层切片”(layer slicing)技术,直接从选定的教师模型层复制权重。这种结构化的迁移策略经过精心设计,旨在确保学生模型能够继承基础的物理先验知识——例如与任务相关的几何结构、运动趋势及接触特征——同时剔除那些专用于高保真像素渲染的冗余参数。为了确保知识迁移的稳定性,在标准的视频流匹配(flow-matching)目标函数之外,引入了教师引导的蒸馏损失,用于对齐中间隐状态及时间演变特征。这一过程有效地将教师模型对物理世界的理解蒸馏到以动作为核心的主干网络中。
如图 2 所示,该紧凑型视频专家模块与动作专家模块在层级上进行耦合。任务指令通过交叉注意机制(cross-attention)注入,而机器人状态与带噪动作则被编码为动作 Token。在每一层 MoT 结构中,动作 Token 都会对视频 Token 进行注意计算以提取未来上下文信息,随后被映射回动作流中。在主要的动作训练阶段,紧凑型视频专家模块保持冻结状态;这种做法既保留稳定的世界先验知识,又能针对精确控制需求优化轻量级动作专家模块。
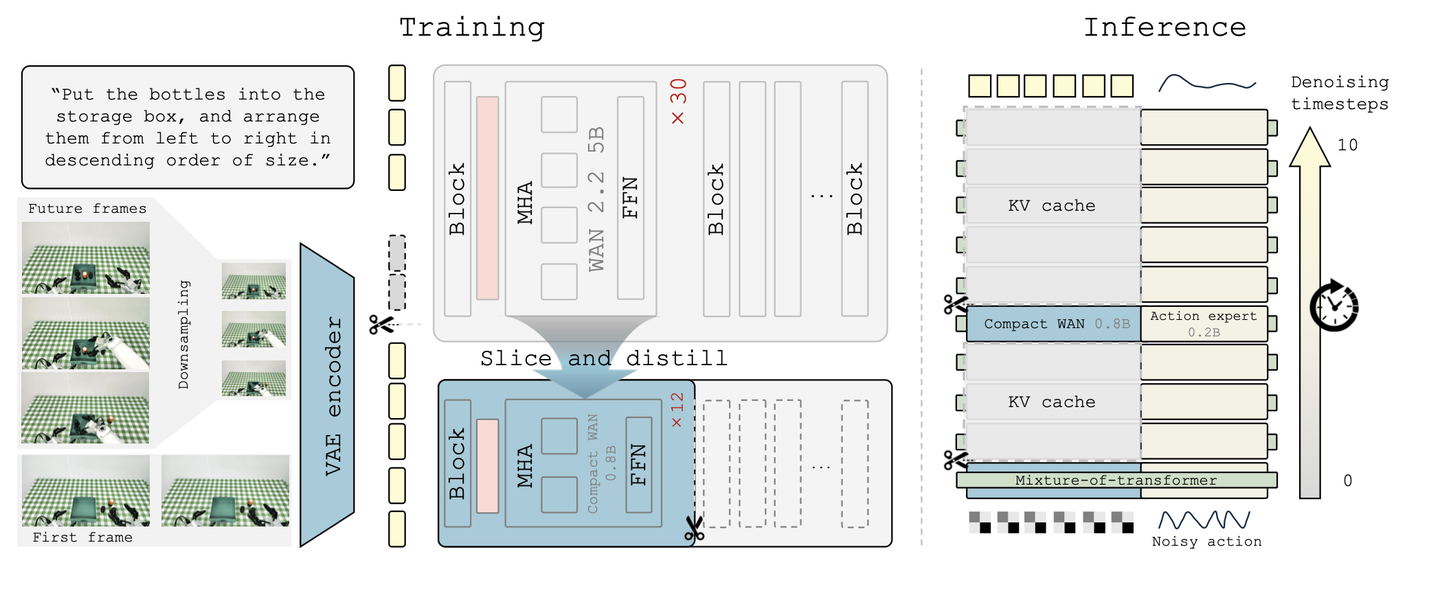
标准的 WAM 通常以与输入观测相同的分辨率预测未来视频,从而将计算资源浪费在与动作无关的视觉细节上。Efficient-WAM 采用多尺度视频潜变量(latent)布局来缓解这一问题。具体而言,系统利用 VAE 将当前观测编码为高分辨率条件 Token(例如 384 × 320);相比之下,目标未来帧在 VAE 编码前会先进行空间下采样,缩减为较小的尺寸(例如 192 × 160),从而生成 Token 稀疏、低分辨率的未来潜表示。这两组潜表示随后被划分为 Patch 并拼接,构成统一的视觉上下文。随后,动作专家模块针对这一多尺度 Token 序列执行联合视频-动作注意机制。这种设计确保了动作分支既能保留当前状态的高保真空间细节,又能将低分辨率的未来潜表示仅作为粗略的动态引导。该设计源于核心假设:有效的控制需要保留与任务相关的几何结构、运动趋势及接触线索,而非生成视觉上清晰锐利的未来帧。消融实验表明,这种有意降低未来 Token 密度的做法,在保持动作执行准确性的同时,显著降低了注意力计算开销并加速了推理过程。
在生成式 WAM(世界动作模型)中,视频分支和动作分支通常共享相同的迭代去噪调度。然而,视觉结构与精确控制坐标的收敛速度各不相同:动作生成需要精确的多步采样以产生安全且可执行的轨迹,而未来视频只需提供粗略的动态上下文。鉴于物体几何形状和接触边界等全局结构特征在去噪的最初几步便已显现,若为了生成逼真纹理而执行完整的长程采样调度,则会造成计算资源的浪费。
针对这一差异,其在推理阶段引入无需额外训练的非对称视频-动作去噪策略。具体而言,为动作分支分配较多的去噪步数(例如 5 到 10 步),而仅对视频分支进行少量的更新(例如仅在最初 2 步)。在视频更新的间隔期间,模型复用缓存的视频特征,以此作为条件来持续优化动作。这种调度策略在明确可执行的动态信息后即停止视频生成,从而大幅降低了计算开销,在几乎不影响任务成功率的前提下实现了显著的加速效果。
1 实验设置与模型变体
为了系统性地评估以动作为中心的设计原则,将模型容量与推理时优化解耦,构建了两种不同的框架配置。Efficient-WAM 作为结构基线,旨在单独考察紧凑型视频专家模块的贡献。通过保留高分辨率的未来状态预测和对称去噪机制,它确立经蒸馏得到的 10 亿(1B)参数架构的能力上限。这表明,轻量级 MoT 模型无需依赖庞大的 50 亿(5B)或 80 亿(8B)参数主干网络,也能保持强大的控制先验能力。
相比之下,Efficient-WAM-RT 代表了面向实时物理部署的全优化范式。它在基线模型的基础上,集成了低分辨率未来潜变量和非对称视频-动作去噪机制。尽管这种有意降低视觉保真度的做法以牺牲少量精度为代价换取了速度,但它从结构上重构了推理流水线,从而实现了超低延迟。对于这两种变体,均遵循针对精细操作的动作分块(action-chunking)策略 [33],利用流匹配(flow matching)技术 [31] 预测闭环动作块(H = 16)。在 RoboTwin 2.0 和 Astribot S1 平台上评估控制性能,并测量推理延迟(定义为每个动作块的实际耗时);其中,仿真与消融实验在单张 A800 GPU 上进行,而真实世界任务则在本地 RTX 4090 GPU 上运行。
2 仿真环境评估
在 RoboTwin 2.0 [34] 上进行评估,该平台包含 50 项双臂操作任务,涵盖干净(clean)和随机化(randomized)两种视觉设置,旨在测试模型的执行能力与鲁棒性。模型基于 2,500 条干净演示数据和 25,000 条随机化演示数据进行联合训练。在评估阶段,针对每种设置下的每项任务,均进行 100 次试验。将 Efficient-WAM 与具有代表性的 VLA(视觉-语言-动作)类方法(包括 π0 [35]、StarVLA-α [36]、π0.5 [37]、Abot-M0 [38] 和 Lingbot-VLA [39])以及 WAM 类方法(包括 UWM [19]、GigaWorld-Policy [21] 和 Motus [11])进行了对比。
3 真实世界实验
由于闭环物理操作对推理延迟高度敏感,部署重量级生成模型往往会导致执行迟缓,呈现出类似开环控制的特性。为了验证以动作为中心的设计理念,将全优化的 Efficient-WAM-RT(本文方法)直接部署到 Astribot S1 硬件平台上。通过四项不同的任务评估该部署变体,这些任务分别考察精确定位、轻柔物体操控、长程语义对齐以及精细的双臂协同能力。为了进行公平比较,所有受评估模型(包括 π0.5 [37] 和 Motus [11])均使用相同的每任务 100 条人类演示数据进行训练(每个任务对应一个专用策略),并针对每个任务进行 20 次试验评估。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 5
5 0
0- 0



 已为社区贡献348条内容
已为社区贡献348条内容

所有评论(0)