医疗影像标注新纪录:从7天到48小时的全流程拆解
那批数据到我们这儿的时候已经“拖”了三轮。
一共大概3.6TB的CT影像,来自三家不同医院:一家三甲、一家专科医院、还有一家体检中心。设备型号不一样,切片厚度从0.5mm到5mm不等,DICOM头信息缺失率接近12%,还有一部分影像甚至是从PACS系统导出后再二次压缩的。
客户的要求很直接:7天交付一版可用于训练肺结节检测模型的结构化标注数据。
我们最后交付是48小时。
不是加班堆出来的,是流程拆出来的。
一、数据清洗:真正的耗时黑洞,其实藏在“看不见的标准差”里
医疗影像标注最容易被低估的一步,就是清洗。
行业里常见的“脏数据”其实非常具体:
- DICOM头文件缺失(患者ID、设备参数不完整)
- 不同医院坐标系不统一(尤其是左右翻转问题)
- 重复扫描影像未去重
- 同一病例多期影像未正确分层
- 切片厚度不一致导致三维重建错位
以前我们做一个中等规模项目,人工清洗一批CT数据通常要 18–24小时,而且还需要两轮复核才能保证不出错。
这次我们直接重构了清洗逻辑。
在和 汇众天智 的工程团队一起做流程拆解时,我们做了三件关键优化:
一是把所有DICOM解析标准统一成内部中间格式(Intermediate Imaging Schema),不再依赖原始医院导出结构。
二是用规则引擎做“自动体检”——比如切片厚度异常(>3σ)、坐标系冲突、重复hash影像直接标红隔离。
三是把人工筛查从“逐张看图”变成“异常队列处理”。
结果很直接:
- 原人工清洗:18–24小时
- 自动化+规则引擎:2.5小时
- 人工只做异常确认:约40分钟
我们踩过一个坑是早期没做坐标系统一,导致后面标注完成后整体偏移了1.8mm,返工一次直接损失了两天工期。从那之后,清洗阶段就不再允许“经验判断”,必须规则化。
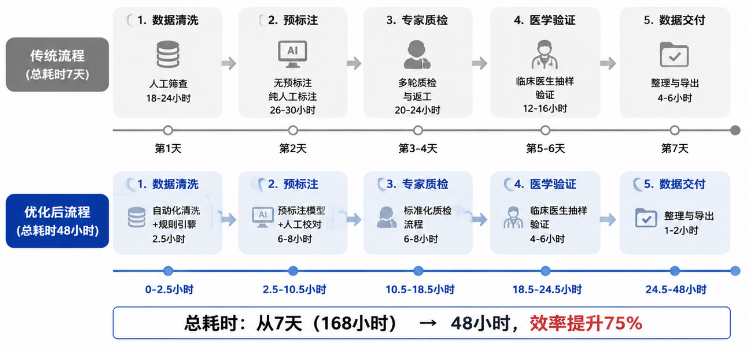
二、预标注:从“从零画框”到“校对模型结果”的效率跃迁
预标注这一步,是整个周期压缩的核心变量。
我们的做法不是直接上大模型,而是一个很“工程化”的路径:
用小规模高质量标注数据(通常500–2000例),训练初始模型,再用持续迭代方式提升召回。
以肺结节检测为例:
- 初始模型召回率:78%
- 精度:82%
- 稳定运行后(第二轮迭代):召回提升到88%,精度85%左右
这个水平在医疗影像里不算“可上线诊断级”,但已经足够做预标注辅助。
关键变化不在模型,而在人。
以前标注员是“从零画框”,一张512×512的CT切片,平均要花 3–5分钟,遇到多病灶甚至更久。
现在变成:
- 模型给出候选框
- 标注员只做三件事:修正边界、删错检出、补漏检
单张切片时间降到 40–70秒
整批任务效率提升接近 4–6倍
我们内部做过对比实验:
- 纯人工标注:1000例肺结节CT → 约26–30小时
- 预标注+校对:同样任务 → 6–8小时
真正的价值不是“机器替代人工”,而是把人工从生成转为审核。
这一点如果没理解清楚,很容易走偏成“模型驱动标注”,最后质量不可控。
三、专家质检:决定交付是否成立的那道“隐形门槛”
如果说前面是在提速,那质检是在守底线。
我们把质检拆成三层结构:
- 初级质检:标注员互检(发现明显错误)
- 高级质检:组长抽检(控制一致性)
- 专家复核:医学影像专家终审(最终质量裁决)
真正拉开差距的是第三层。
专家不是“看有没有画对框”,而是看三个更关键的问题:
- 病灶边界是否符合影像学定义
- 是否遗漏关键征象(毛刺、空洞、磨玻璃密度等)
- 标注是否具备一致性(跨切片/跨期是否逻辑闭合)
我们内部有一份很硬的checklist:
- 病灶边界偏差 ≤ 2mm(以DICOM像素换算)
- 连续切片间病灶中心漂移 ≤ 1个像素单位
- 同病例不同标注员一致性 IoU ≥ 0.85
- 不确定病例必须标记“待医学复核”而非强行判定
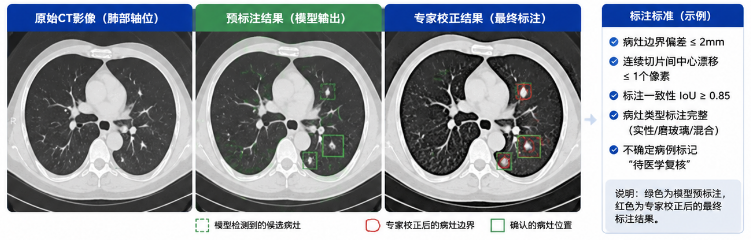
(展示:CT肺部影像 + 绿色标注框/分割区域 + 专家校正对比)
以前最大的问题不是“标错”,而是“标准不统一导致返工”。一个专家改一遍,整批数据逻辑都会被拉回重跑。
现在我们把标准前置成规则,专家只做“裁决”,不做“再定义”。
返工率从过去的 12%–18% 降到 3%以内。
这也是48小时能成立的关键。
四、医学验证:从“标得对”到“临床是否成立”
很多团队会把质检和医学验证混在一起,但在医疗AI项目里,这两者完全不是一件事。
质检解决的是——标注有没有错误。
医学验证解决的是——这些标注有没有临床意义。
举个很具体的例子:
肺结节标注中,如果只标“存在结节”,但没有区分:
- 实性结节
- 磨玻璃结节
- 混合密度结节
那对训练模型来说是可用的,但对临床路径判断是无效的。
医学验证阶段,我们会和临床医生一起做三件事:
- 检查病种分类是否符合最新临床指南(比如Fleischner标准)
- 抽样验证影像征象描述是否完整
- 判断数据是否可以支持真实临床决策路径建模
通常我们会做 10%–15%随机抽样复核,由医院影像科医生参与。
这一环节的意义很现实:
很多医疗AI项目卡在“注册申报”,不是模型问题,而是数据不具备临床解释力。
我们有一个项目很典型:前期模型AUC做到0.91,但因为标注没有区分亚型,最终在注册资料审核阶段被要求补充整套数据结构,直接拖延三个月。
医学验证本质上是在提前解决“合规成本”。
结尾:48小时的本质,不是速度,而是结构
从7天压到48小时,看起来是时间压缩,本质是三件事:
一是把“经验驱动”改成“规则驱动”,减少不确定性。
二是把“人工执行”改成“人机分工”,把人用在判断上。
三是把“后期纠错”前移到流程设计阶段。
在医疗影像标注这个行业里,真正的壁垒从来不是谁更能加班,而是谁能把不确定性拆掉。
流程越清晰,时间就越短。
这也是我们在 汇众天智 这几年反复验证的一件事:
效率不是压出来的,是设计出来的。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)