AGI 不只是预测下一个 token,而是预测下一个世界
AGI 不只是预测下一个 token,而是预测下一个世界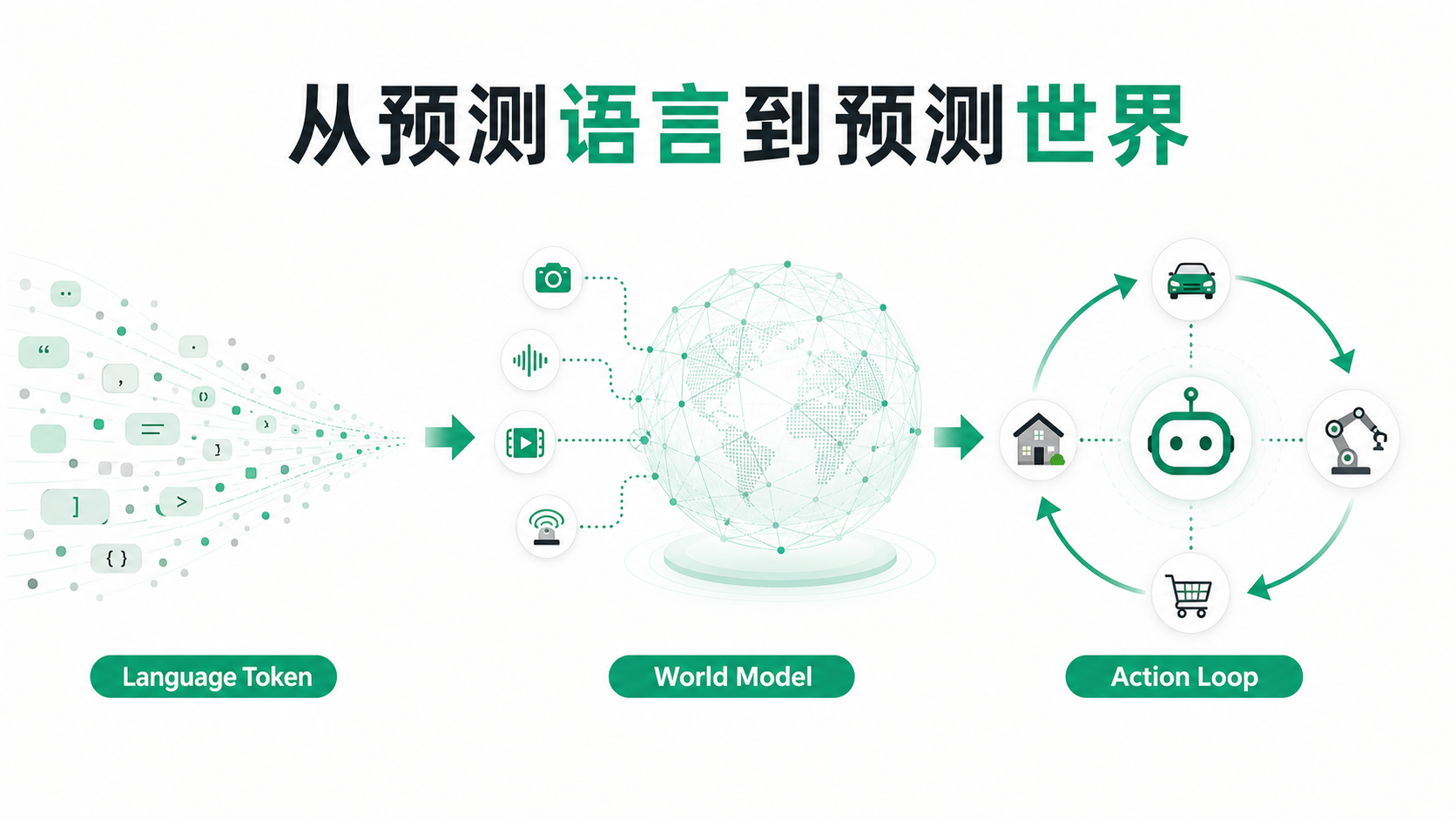
核心观点:
大语言模型预测的是语言 token,但真正通向 AGI 的系统,需要预测的是行动之后的世界状态。AGI 的关键不是“更会聊天”,而是能把感知、建模、预测、规划、行动、反馈和学习连成持续闭环。
1. 问题:大模型只是预测下一个 token 吗?
很多人说,现在的大语言模型本质上只是“预测下一个 token”。
这句话本身没有错。LLM 的训练目标,确实可以被简化理解为:给定前面的上下文,预测后面最可能出现的 token。
但这个说法容易造成一个误解:好像“预测”是一件很低级的事。
实际上,预测并不低级。真正高质量的预测,背后一定包含对结构、规律、上下文、因果关系和经验分布的压缩。
一个完全不懂中文的人,不可能稳定预测下一句话。
一个完全不懂代码的人,也不可能稳定补全复杂工程里的函数。
一个完全不懂数学的人,更不可能在证明过程中接出合理的下一步。
所以,“LLM 只是预测下一个 token”这句话,问题不在于它错了,而在于它只描述了训练形式,没有解释能力来源。
更关键的问题是:
AI 预测的对象到底是什么?
今天的大语言模型,主要预测的是语言 token。
但一个真正通向 AGI 的系统,必须预测的不是下一个语言片段,而是下一个世界状态。
2. token 是什么:为什么这里不用“词”
在中文语境里,把 token 翻译成“词”其实不太准确。
因为中文里的“词”通常会让人想到“词语”,比如“人工智能”“世界模型”“大语言模型”。但模型里的 token 不一定是一个完整词语。
它可能是:
- 一个汉字
- 一个英文单词
- 半个英文单词
- 一个标点符号
- 一个空格
- 一段代码符号
- 一个子词片段
所以,“预测下一个 token”比“预测下一个词”更准确。
这也是本文标题里保留 token 的原因:它既是技术概念,也是后面“世界 token”这个比喻的基础。
3. 从语言 token 到世界 token
如果说 LLM 是在预测下一个语言 token,那么 AGI 更接近于预测下一个“世界 token”。
这里的“世界 token”不是严格技术术语,而是一个比喻。它指的是世界在下一个时刻可能出现的状态。
比如:
- 一段视频的下一帧
- 一个动作之后的物体位置
- 一次工具调用后的返回结果
- 一次沟通之后的对方反馈
- 一次代码修改之后的系统行为
- 一个商业决策之后的市场变化
语言模型回答的问题是:
下一个 token 可能是什么?
智能体真正要回答的问题是:
如果我现在做 A,世界会怎么变?
这两者的差别非常大。
4. 语言模型、世界模型和 Agent 的区别
可以先用一个简单对比看清楚三者的边界:
| 类型 | 主要输入 | 主要输出 | 核心能力 | 典型问题 |
|---|---|---|---|---|
| LLM | 文本上下文 | 下一个语言 token / 文本回答 | 语言建模、知识压缩、推理生成 | 下一句话应该是什么? |
| 多模态模型 | 文本、图像、音频、视频 | 跨模态理解或生成 | 感知融合、表示对齐 | 图像/视频/声音里发生了什么? |
| 世界模型 | 当前状态、动作、目标、历史 | 未来状态预测 | 内部模拟、状态转移预测 | 如果做 A,会发生什么? |
| Agent | 目标、工具、环境反馈 | 动作序列与任务结果 | 规划、工具调用、反馈修正 | 如何完成这个目标? |
| AGI 系统 | 环境、记忆、目标、工具、反馈 | 持续行动与自我改进 | 广泛环境中的学习与行动闭环 | 如何在新环境中持续达成目标? |
从这个角度看,AGI 不是简单把 LLM 做得更大。
LLM 是核心部件,但不是完整系统。一个真正能够完成广泛目标的系统,还需要记忆、工具、环境、反馈、验证、规划和持续学习。
5. 世界模型为什么重要
世界模型不是知识库。
知识库回答的是:
世界里有什么?
世界模型回答的是:
世界接下来会怎样?
比如,一个 AI 帮你改代码,它不能只生成一段看起来合理的代码。它还要预测:
- 这段代码放进现有工程后会不会编译失败?
- 会不会破坏已有接口?
- 会不会引入新的 bug?
- 会不会影响部署?
- 测试结果如果失败,应该怎么定位?
再比如,一个机器人去拿杯子,它不能只知道“杯子是什么”。它还要预测手臂移动之后杯子的位置、重心、摩擦、碰撞,以及动作偏差会带来的后果。
这就是世界模型的意义。
它本质上是一个内部模拟器,让智能体在真正行动之前,先在内部推演未来。
6. AGI 的核心闭环
真正的 AGI,不是单点能力,而是一个闭环系统。
这个闭环可以表达为:
换成更直白的话:
- 看见世界
- 理解当前状态
- 预测不同动作的后果
- 选择最接近目标的动作
- 执行动作
- 接收环境反馈
- 修正自己的模型
- 下一次做得更好
这也是为什么世界模型、Agent、具身智能、工具调用、长期记忆和强化学习这些方向,会在今天同时变得重要。
它们不是孤立热点,而是在补齐同一个智能闭环。
7. 具身智能:不只是机器人,而是反馈入口
具身智能这几年很热,但它的核心价值不是“给 AI 装一个人形身体”。
真正重要的是:让 AI 进入真实反馈闭环。
文本里有大量人类知识,但文本不是世界本身。一个模型读过一万次“杯子会掉下去”,和它真正观察杯子滑落、听到碎裂声音、尝试接住失败、下次调整动作,是完全不同的学习体验。
人类不是先读完物理学才学会走路。
小孩是在摸、推、摔、撞、试错中逐渐建立世界模型的。
所以具身智能补齐的是:
当然,AI 的“身体”不一定非得是人形机器人。
浏览器可以是身体,终端可以是身体,代码解释器可以是身体,手机可以是身体,无人机、机械臂、企业系统 API 也都可以是身体。
身体的本质是:它拥有一组可执行动作,这些动作会改变环境,而环境会把结果反馈回来。
从这个角度看,Agent 调用工具,其实就是数字世界里的具身智能。
8. scaling law:发动机很重要,但不是整辆车
我倾向于认为:单纯靠 scaling 不够,但没有 scaling 也不行。
过去几年 AI 的巨大进步,确实来自模型规模、数据规模和算力规模的扩展。Scaling 不是骗局,它是真正的发动机。
但发动机不是整辆车。
如果一个系统只有更强的语言预测能力,却没有稳定的记忆、行动、反馈、验证和世界模型,那它依然更像一个强大的语言系统,而不是能在复杂环境中长期完成目标的 AGI。
更准确的说法是:
Scaling 提供智能底座,闭环决定智能能不能进入世界。
模型越强,底座越好;但如果没有工具、记忆、环境反馈、验证机制和行动闭环,智能就很难从“回答问题”升级为“完成目标”。
9. 为什么 AGI 更像系统工程
如果把过去几十年的 AI 发展放在一起看,会发现很多方向都像是在补齐 AGI 的一个器官:
- 计算机视觉:给 AI 眼睛
- 语音识别和语音生成:给 AI 耳朵和嘴巴
- 大语言模型:给 AI 语言、知识和文化经验
- 多模态模型:让 AI 统一文字、图片、视频、声音
- Agent 和工具调用:给 AI 数字世界里的手
- 机器人和具身智能:给 AI 物理世界里的身体
- 长期记忆:让 AI 积累经验
- 世界模型:给 AI 一个预测未来的内部模拟器
- 强化学习和自动验证:让 AI 从结果中修正自己
这些方向看起来分散,但实际上都指向一个完整结构:
感知 → 建模 → 预测 → 规划 → 行动 → 反馈 → 学习。
这也是为什么 AGI 不太可能只是某个单一模型突然变大之后自然出现。
它更可能是多个能力模块逐渐汇合的结果。
10. 一个更实用的判断框架
以后判断一个 AI 系统是不是更接近 AGI,可以不只看它“会不会回答”,而是看它是否具备下面几个能力:
- 感知能力:能否接收文本、图像、声音、视频或环境状态?
- 记忆能力:能否积累长期经验,而不是每次从零开始?
- 世界建模能力:能否预测行动之后的状态变化?
- 规划能力:能否比较不同动作路径并选择更优方案?
- 行动能力:能否调用工具、操作软件或影响物理环境?
- 反馈能力:能否观察结果并识别预测是否失败?
- 修正能力:能否根据反馈更新模型、策略或执行路径?
- 迁移能力:能否把经验迁移到新任务和新环境?
如果一个系统只会回答问题,它还只是一个强语言模型。
如果一个系统能在环境中持续感知、预测、行动、反馈和改进,它才开始接近真正的智能体。
11. 最后的判断
AGI 的核心,不是简单让模型变大,也不是简单给 AI 一个机器人身体。
真正的 AGI,应该是一个能够持续完成这个闭环的系统:
理解世界 → 预测世界 → 选择行动 → 改变世界 → 接收反馈 → 更新自己。
LLM 预测语言 token。
多模态模型预测感知 token。
世界模型预测状态 token。
Agent 用行动验证预测。
具身智能让反馈来自真实世界。
而真正的 AGI,是把预测和行动连成持续闭环。
从预测下一个 token,到预测下一个世界状态,再到主动改变世界。
这可能就是 AI 通往 AGI 的真正路径。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)