AMCL 与粒子滤波:二维 LiDAR 地图定位完整原理
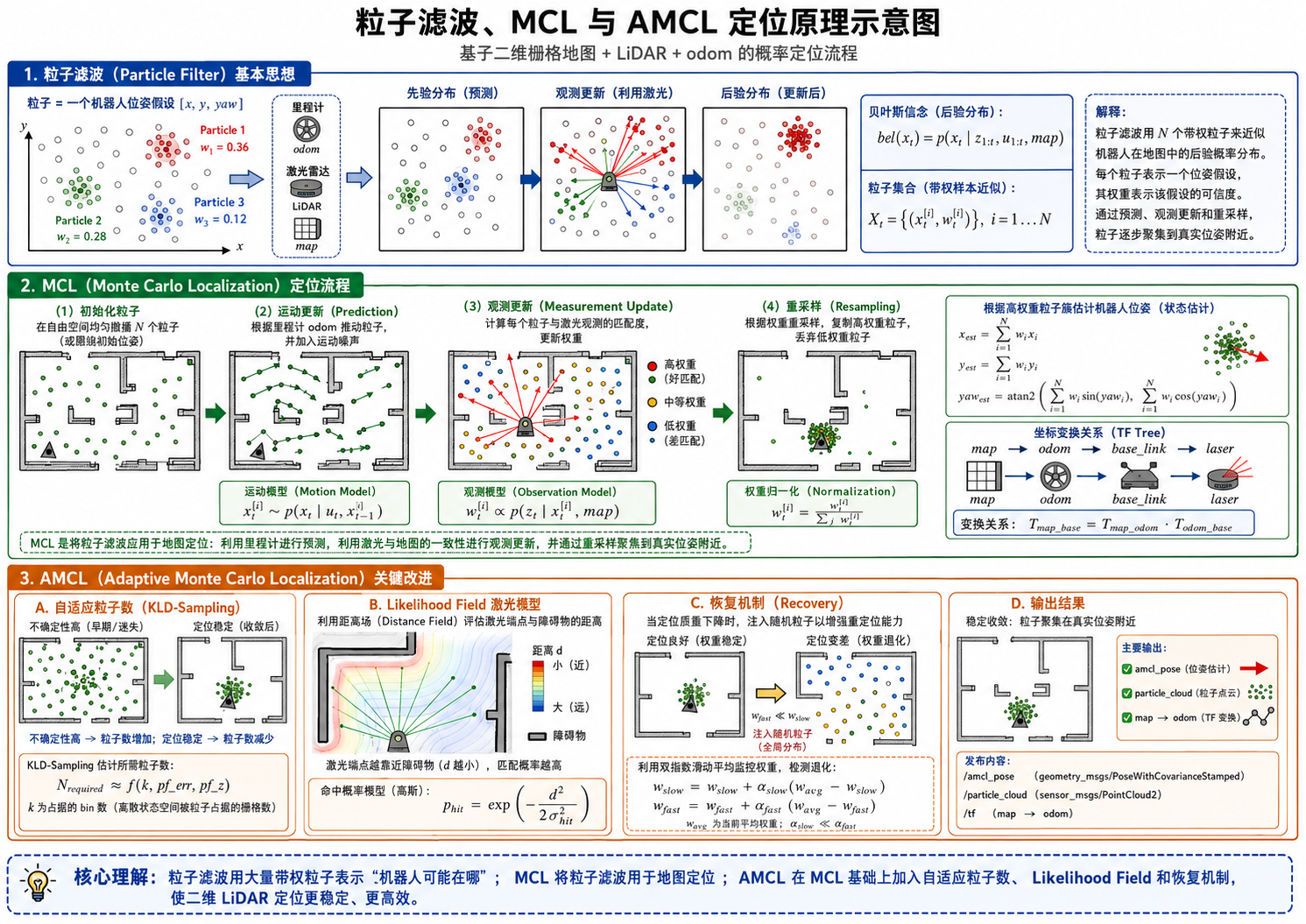
AMCL 的任务很明确:地图已经建好,机器人拿着当前 LiDAR 扫描、底盘 odom 和雷达安装外参,在地图中持续判断自己当前位置和朝向。它不是建图模块,不负责把新的墙、货架、柱子写进地图;它默认地图中的静态结构已经存在,并把当前扫描与这些结构进行概率匹配。Nav2 的 AMCL 也是以静态地图、激光扫描和 odom 为输入,在已知地图中估计机器人位姿。
已知:
map:
已建好的二维栅格地图
scan:
当前 LiDAR 扫描
odom:
机器人相对上一时刻的运动估计
base_link -> laser:
LiDAR 安装位置与朝向外参
求:
pose_map_base = [x, y, yaw]其中,x、y 是机器人在地图平面中的位置,yaw 是机器人绕 z 轴的朝向。对于普通室内差速小车,AMCL 默认认为机器人主要在地面平面运动,所以它关注的是二维三自由度状态,而不是 z、roll、pitch。例如,机器人在仓库中经过货架通道,当前 LiDAR 扫到左边货架、右边墙、前方立柱和一段门洞。AMCL 实际上是在地图中寻找:把这帧扫描放在哪个 x、y、yaw 下时,扫描点最像地图中的货架、墙、柱子和门洞。
但“最像”并不意味着 AMCL 从第一帧就只保留一个答案。真实环境中经常存在相似区域:两个走廊宽度相同,两边都有货架,前方都有墙;或者仓库有很多重复货架通道,单帧 LiDAR 只能看见局部十几米范围,无法区分自己到底在第几条通道。此时,如果算法只保留一个位姿,一旦一开始选错位置,就可能一直沿着错误位置跟踪。粒子滤波的做法不同:它同时保留很多“机器人可能在这里”的假设,在 A 通道附近留一批粒子,在 B 通道附近也留一批粒子,甚至在其他区域保留少量粒子。机器人继续移动后,新的门洞、货架端部、立柱、拐角进入 LiDAR 视野,错误区域的粒子逐渐与地图不符,权重下降;正确区域的粒子不断获得高分,数量越来越多。最终,粒子云会集中到真实位置附近。
粒子滤波、MCL、AMCL 三者的关系可以这样理解:
Particle Filter:
通用概率状态估计方法。
MCL:
Monte Carlo Localization。
用粒子滤波解决移动机器人地图定位。
AMCL:
Adaptive Monte Carlo Localization。
在 MCL 基础上加入自适应粒子数量、
随机恢复粒子、工程化 LiDAR 模型等机制。粒子滤波不把机器人当前位置表示为一个唯一坐标,而是表示为一组带权重的状态样本。二维 AMCL 中,一个粒子通常表示一个候选机器人位姿:
particle[i] = [x_i, y_i, yaw_i, w_i]
x_i:
第 i 个粒子假设下的地图 x 坐标
y_i:
第 i 个粒子假设下的地图 y 坐标
yaw_i:
第 i 个粒子假设下的机器人朝向
w_i:
该位姿假设的可信程度例如:
Particle 1:
[10.10, 5.02, 89 deg]
weight = 0.42
Particle 2:
[10.22, 5.08, 92 deg]
weight = 0.31
Particle 3:
[9.91, 4.89, 86 deg]
weight = 0.18
Particle 4:
[14.30, 7.60, 130 deg]
weight = 0.07
Particle 5:
[2.20, 1.80, 15 deg]
weight = 0.02这里的每个粒子都在表达一句话:
“假设机器人当前位于这个 x、y、yaw。”而权重表达的是:
“若机器人真的位于这个位置,
当前 LiDAR 扫描和地图中的静态结构是否吻合。”所有归一化后的粒子权重满足:
sum(w_i) = 1因此,粒子权重可以看成相对概率。如果粒子 1、2、3 集中在地图同一个位置附近,并且总权重很高,说明机器人很可能在那里;如果粒子一半聚集在左侧走廊、一半聚集在右侧走廊,说明系统仍然存在多解,尚未真正确定位置。粒子滤波的优势就在于它能够表达这种多峰概率分布:机器人同时“可能在 A,也可能在 B”,而不是强迫系统立刻输出一个可能错误的单一答案。KLD-Sampling 的原始论文也将粒子滤波描述为用样本集合近似动态系统状态的后验概率密度,并强调样本能够表达复杂、多峰的概率分布。
AMCL 的目标概率通常写为:
bel(x_t) = p(x_t | z_1:t, u_1:t, map)其中:
x_t:
当前时刻机器人位姿
z_1:t:
从开始到当前时刻的 LiDAR 观测序列
u_1:t:
从开始到当前时刻的 odom 运动信息
map:
已知二维栅格地图
bel(x_t):
当前机器人位姿概率分布这条式子可以拆成两个非常实际的过程:预测和校正。预测阶段根据 odom 推测机器人可能走到哪里;校正阶段根据 LiDAR 与地图判断这些可能性中哪些更合理。完整的贝叶斯递推形式是:
bel(x_t)
=
eta
*
p(z_t | x_t, map)
*
integral[
p(x_t | u_t, x_t-1)
*
bel(x_t-1)
dx_t-1
]其中 p(x_t | u_t, x_t-1) 就是运动模型。它表示:若机器人上一时刻位于 x_t-1,而 odom 说机器人刚才经历了运动 u_t,那么当前可能到达哪些位置。p(z_t | x_t, map) 是观测模型。它表示:若机器人现在位于 x_t,那么当前 LiDAR 扫描 z_t 与已知地图是否匹配。eta 是归一化系数,用于保证最终所有状态概率之和为 1。
AMCL 的整个运行过程始终在重复这条逻辑:
上一时刻的粒子分布
↓
根据 odom 预测所有粒子如何移动
↓
当前 LiDAR 与地图匹配
↓
重新计算每个粒子的可信度
↓
高权重粒子增多,低权重粒子减少
↓
得到当前时刻新的粒子分布可以把主流程压缩为下面一段伪代码。真正 AMCL 源码比这个复杂得多,涉及 TF 查询、激光预处理、不同运动模型、不同激光模型、恢复采样和生命周期节点管理;但粒子滤波的主线就是这里。
OnLaserScan(scan, odom_pose)
{
delta = GetOdomDelta(last_odom_pose, odom_pose);
PredictParticlesByOdom(delta);
for (particle : particles)
{
particle.weight =
ScoreByLaserAndMap(
particle,
scan,
distance_field_map
);
}
NormalizeWeights();
if (NeedResample())
{
ResampleParticles();
}
pose_map_base =
EstimateBestParticleCluster();
PublishMapToOdom(
pose_map_base,
odom_pose
);
last_odom_pose = odom_pose;
}GetOdomDelta() 的作用不是直接得到全局定位结果,而是求机器人从上一帧到当前帧“相对怎么动了”。例如上一时刻 odom 是 [10.0, 5.0, 90 deg],当前 odom 是 [10.0, 5.8, 95 deg],那么 odom 大概表达的是机器人向前移动了 0.8 m,最终朝向增加了约 5 度。为了适用于差速底盘或一般二维机器人,AMCL 通常将相对运动拆成“先转、再平移、再转”三部分:
delta_rot1
=
atan2(
y_now - y_last,
x_now - x_last
)
-
yaw_lastdelta_trans
=
sqrt(
(x_now - x_last)^2
+
(y_now - y_last)^2
)delta_rot2
=
yaw_now
-
yaw_last
-
delta_rot1delta_rot1 表示机器人从上一帧朝向转到“当前运动方向”所需的转角。delta_trans 表示机器人沿运动方向前进的距离。delta_rot2 表示机器人到达新位置后,为了变成最终朝向而额外产生的转角。将运动拆成这三部分的意义在于,机器人运动误差往往和“平移量、旋转量”相关,而不是简单和当前位置相关。例如小车原地旋转时,主要误差在 yaw;直线前进时,主要误差在前进距离,但左右轮速度差也可能带来小的 yaw 偏差;急转弯时,侧滑可能同时引入位置和朝向误差。
AMCL 不会让每个粒子完全执行相同的 odom 增量。因为若所有粒子都严格按照同一 delta_rot1、delta_trans、delta_rot2 移动,就等于系统默认 odom 完全准确。现实底盘显然不是这样。编码器可能有量化误差,轮胎会打滑,左右轮实际半径可能略有差异,地面摩擦不均匀,转弯时车体会侧滑,减速带和坡道会改变轮胎接触情况,底盘机械间隙也会导致小范围误差。因此,AMCL 会为每个粒子加入不同随机噪声:
rot1_hat
=
delta_rot1 + noise_rot1trans_hat
=
delta_trans + noise_transrot2_hat
=
delta_rot2 + noise_rot2然后更新该粒子的位姿:
particle.x
=
particle.x
+
trans_hat
*
cos(particle.yaw + rot1_hat)particle.y
=
particle.y
+
trans_hat
*
sin(particle.yaw + rot1_hat)particle.yaw
=
NormalizeAngle(
particle.yaw
+
rot1_hat
+
rot2_hat
)例如 odom 认为机器人前进了 1.0 m、左转了 5 度。AMCL 中不同粒子可能分别得到:
Particle 1:
前进 0.96 m
左转 4.1 deg
Particle 2:
前进 1.03 m
左转 5.3 deg
Particle 3:
前进 1.08 m
左转 6.0 deg
Particle 4:
前进 0.92 m
左转 3.7 deg这会让粒子云逐渐扩散。扩散不是坏事,而是系统在表达:“机器人走得越远,只依赖 odom 时,自己对位置越不确定。”如果粒子完全不扩散,说明 AMCL 过度相信 odom;如果粒子每帧都扩散非常大,说明 AMCL 几乎不相信 odom,会导致计算量增大、粒子云难以收敛、定位容易抖动。
AMCL 通过 alpha1、alpha2、alpha3、alpha4 控制这种运动不确定性。它们并不是单纯的“精度参数”,而是运动噪声模型的一部分。Nav2 对它们的定义分别是:旋转引起的旋转估计噪声、平移引起的旋转估计噪声、平移引起的平移估计噪声、旋转引起的平移估计噪声。
一种常见的表达方式如下:
var_rot1
=
alpha1 * delta_rot1^2
+
alpha2 * delta_trans^2var_trans
=
alpha3 * delta_trans^2
+
alpha4 * (
delta_rot1^2
+
delta_rot2^2
)var_rot2
=
alpha1 * delta_rot2^2
+
alpha2 * delta_trans^2然后通过:
std_rot1 = sqrt(var_rot1)
std_trans = sqrt(var_trans)
std_rot2 = sqrt(var_rot2)得到每个粒子运动噪声的标准差。这里的数学意义很直接:机器人走得越远,平移误差通常越大;机器人转得越多,旋转误差通常越大;机器人急转弯时,旋转还可能带来平移误差;机器人直行时,左右轮不一致也可能带来旋转误差。实际调参时,alpha 不能盲目调大或调小。alpha 太小,粒子云始终紧贴错误 odom,真实位置偏出后很难被 LiDAR 拉回;alpha 太大,粒子云每次都扩散过宽,LiDAR 需要筛选更多候选位姿,定位会变慢且抖动明显。更合理的目标是让 alpha 大致反映底盘在真实地面上的误差水平。
完成 odom 预测后,AMCL 进入真正决定定位效果的阶段:LiDAR 地图匹配。对于第 i 个粒子,AMCL 假设:
“机器人现在真的位于:
[x_i, y_i, yaw_i]
这个位置和朝向。”当前 LiDAR 的第 k 束激光包含距离 r_k 和角度 phi_k。在 LiDAR 自己坐标系中,这束激光端点为:
p_laser_x
=
r_k * cos(phi_k)p_laser_y
=
r_k * sin(phi_k)但是 LiDAR 通常并不正好安装在机器人几何中心。它可能在车头前方 0.2 m,也可能偏左、偏右,甚至有安装 yaw 偏差。因此必须先通过 base_link -> laser 外参把激光点变换到车体坐标系:
p_base
=
T_base_laser
*
p_laser再根据当前粒子假设,把该点变换到地图坐标系:
p_map
=
T_map_particle
*
T_base_laser
*
p_laser为了便于理解,若暂时忽略 LiDAR 与 base_link 的外参,端点位置可简化为:
end_x
=
x_i
+
r_k * cos(yaw_i + phi_k)end_y
=
y_i
+
r_k * sin(yaw_i + phi_k)这两条公式的意义非常核心。同一束 LiDAR 数据,如果机器人处于粒子 A 的位置,端点会投到地图中的 A1;如果机器人处于粒子 B 的位置,端点会投到地图中的 B1;如果机器人朝向不同,整帧扫描会整体旋转。AMCL 就是利用这种差异,判断哪个粒子位置下扫描和地图最吻合。
假设机器人真实位于一个仓库通道中,当前扫描结果是:左侧货架,右侧墙,前方立柱,右前方门洞。对于正确粒子,左边激光端点会靠近地图中左侧货架,右边端点会靠近右侧墙,前方端点会靠近地图中的立柱,门洞边缘点会落在地图中的门洞边界附近。对于偏移一米的错误粒子,左侧点可能落在通道中间,右侧点可能进入墙内,前方立柱与地图立柱错开,门洞点可能投到连续墙面。AMCL 不是靠某一束激光决定粒子好坏,而是看整帧数十束或数百束激光在该粒子假设下是否整体与地图一致。
为了让这种评分既稳定又高效,AMCL 常用 Likelihood Field,即似然场模型。它不要求每个 LiDAR 点严格匹配某个具体地图点,而是预先从二维栅格地图构建距离场。原始地图中的障碍物格子包括墙、货架、柱子等;距离场则为每一个自由位置保存“到最近障碍物的距离”。
D(x, y)
=
地图中位置 (x, y)
到最近障碍物的距离例如:
障碍物表面:
D = 0.00 m
离障碍物 0.05 m:
D = 0.05 m
离障碍物 0.30 m:
D = 0.30 m
离障碍物 1.00 m:
D = 1.00 m可以把它理解为:墙、货架、柱子向周围自由空间扩散出一层层距离值。LiDAR 端点落在障碍物附近时,距离小;落在空白通道中央时,距离大。对于某个粒子下的一个 LiDAR 端点,AMCL 查询:
d
=
D(end_x, end_y)然后用高斯模型计算该点的命中概率:
p_hit
=
exp(
-d*d
/
(2 * sigma_hit*sigma_hit)
)若 d = 0,端点刚好落在障碍物表面,p_hit 接近 1;若 d 很大,端点远离地图障碍物,p_hit 接近 0。sigma_hit 是高斯标准差,控制匹配的宽容程度。Nav2 中的 sigma_hit 正是 z_hit 高斯模型使用的标准差。
sigma_hit 很小时,AMCL 会要求 LiDAR 点非常贴近地图中的墙、货架或柱子,正确粒子和错误粒子的分数差异会非常明显。但地图存在轻微误差、雷达安装有几厘米偏差、建图时货架边缘和定位时货架边缘不完全一致时,正确粒子也可能被严厉惩罚。反过来,sigma_hit 很大时,LiDAR 点离地图障碍物较远仍可获得一定分数,系统对地图误差更宽容,但错误粒子也可能获得较高分,粒子云会更难收紧。因此它本质上控制的是“LiDAR 扫描与地图之间允许多少空间偏差”。
LiDAR 测量并不总来自静态地图。现实环境里可能有行人、叉车、临时托盘、纸箱、打开或关闭的门、玻璃反射、临时堆放物。即使机器人位姿完全正确,某束 LiDAR 也可能扫到地图中没有记录的临时物体。因此 AMCL 的激光模型一般不是只用 p_hit,而是将不同测量来源混合起来。概念上可写成:
p_beam
=
z_hit * p_hit
+
z_rand * p_rand
+
z_short * p_short
+
z_max * p_max其中:
p_hit:
正常打到静态地图障碍物的概率
p_rand:
随机异常测量概率
p_short:
激光比地图预测距离更短,
例如被人、叉车、纸箱提前挡住
p_max:
激光达到最大量程的概率对于 Nav2 的 likelihood_field 模型,实际主要使用 z_hit 与 z_rand;beam 模型则使用更完整的混合项。官方文档明确说明,likelihood_field 使用 z_hit 和 z_rand,而 beam 使用全部四个 z 权重。
z_hit 表示系统有多相信当前激光来自地图中的静态结构;z_rand 表示系统对随机异常测量的容忍程度。静态仓库、固定货架、稳定墙体较多时,通常希望 z_hit 占主导,因为 LiDAR 与地图的匹配应该提供强定位约束。人员、叉车、临时货物很多时,需要保留适当 z_rand,避免少量异常激光把正确粒子权重压得过低。但 z_rand 不能太高,否则系统会逐渐变成“很多激光都可能是随机的”,正确粒子与错误粒子的评分差异缩小,AMCL 定位能力下降。
一帧 LiDAR 可能有几百到上千束激光。理论上,对粒子 i 的整帧观测概率可写成:
weight_i
=
product(
p_beam[k]
)也就是:
weight_i
=
p_beam[0]
*
p_beam[1]
*
p_beam[2]
*
...
*
p_beam[K-1]但直接连续相乘很容易出现浮点数下溢。假设每束激光概率大约为 0.8,连续相乘一千次后,结果会非常接近零。工程中通常改用对数域:
log_weight_i
=
sum(
log(p_beam[k])
)然后再计算相对权重:
weight_i
=
exp(
log_weight_i
-
max_log_weight
)减去所有粒子中的最大 log_weight,是为了保证指数计算稳定。例如三个粒子对数权重分别为 -1000、-1010、-1030,直接取 exp(-1000) 可能已经接近数值下限;减去最大值后,变为 exp(0)、exp(-10)、exp(-30),相对优劣仍然能正确表达。
AMCL 通常不会每帧把全部 LiDAR beam 都用于评分。相邻 beam 很可能打在同一面墙或同一排货架上,信息高度重复。若一帧有 1080 束激光、当前有 2000 个粒子,则每次更新可能需要数百万次端点变换和距离场查询。max_beams 用于限制每帧均匀抽取多少束激光参与更新;Nav2 文档中默认值为 60。 这并不意味着少量 beam 一定更好,而是在定位精度与实时性之间平衡。beam 太少时,门洞、立柱、货架端部等关键几何特征可能没有被采样,导致相似区域难区分;beam 太多时,AMCL 每帧计算时间上升,甚至跟不上 LiDAR 频率,新的扫描还没处理完,下一帧又来了。KLD 论文也指出,在实时系统中,样本过多会增加更新耗时并丢失有价值的传感器数据,粒子数和实时性之间存在实际权衡。
动态障碍物较多时,AMCL 还可使用 beam skipping。它不是把所有不匹配激光简单丢掉,而是先判断某束 beam 是否被绝大多数粒子都认为“不符合地图”。如果某一束激光在很多不同粒子下都与地图不匹配,那么更可能是它打到了人、叉车、纸箱等地图中不存在的临时物体,而不是机器人位姿整体错误。此时可以暂时跳过这束 beam,避免动态障碍物干扰定位。Nav2 的 do_beamskip、beam_skip_distance、beam_skip_threshold 和 beam_skip_error_threshold 就是围绕这一机制设计的。
其中 beam_skip_distance 控制端点离地图障碍物多远时可判为不匹配;beam_skip_threshold 控制多少比例粒子不支持某束 beam 后才跳过;beam_skip_error_threshold 则防止系统在整体未收敛时错误跳过大量激光。因为如果 90% 的 beam 都与地图不匹配,问题可能不是动态人车,而是地图错了、雷达外参错了、雷达 yaw 反了、初始位姿错太远、机器人已经被搬走,或者整体定位尚未收敛。此时继续跳过大量 beam 只是在掩盖问题,AMCL 应重新进行完整观测更新。
完成每个粒子的 LiDAR 评分后,AMCL 得到的是一组原始权重。它们必须归一化:
weight_i
=
raw_weight_i
/
sum(raw_weight_j)例如:
Particle A:
raw_weight = 50
Particle B:
raw_weight = 30
Particle C:
raw_weight = 15
Particle D:
raw_weight = 5总和为:
50 + 30 + 15 + 5 = 100归一化后:
Particle A:
weight = 0.50
Particle B:
weight = 0.30
Particle C:
weight = 0.15
Particle D:
weight = 0.05这时可以理解为:A 是当前最可信的位姿假设,B 仍然有较高可能,C 匹配一般,D 基本不可信。但仍不能马上把 B、C、D 全删掉,因为下一帧机器人继续运动后,环境约束可能改变;特别是在相似走廊中,当前 A 虽然得分最高,也可能只是局部更像,并不保证绝对正确。
接下来是重采样。重采样不是“选择最优粒子”,而是“按照权重重新分配粒子数量”。若 A 的权重是 0.45,B 是 0.25,C 是 0.20,D 和 E 各是 0.05,那么下一代粒子可能变成:
A A A A
B B
C C
D
EA 附近会出现更多粒子,B 和 C 也会保留一定数量,D、E 可能只保留少量甚至被淘汰。这样做的意义是:将有限计算资源集中到更可能正确的区域。后续每一帧 LiDAR 到来时,A 附近会有更多粒子参与细致匹配,从而更精确地表示这个区域的概率密度;明显错误的位置不再浪费大量粒子和计算。
系统重采样可以理解为把 [0, 1] 区间按粒子权重切分。例如:
Particle A:
[0.00, 0.45)
Particle B:
[0.45, 0.70)
Particle C:
[0.70, 0.90)
Particle D:
[0.90, 0.95)
Particle E:
[0.95, 1.00)然后均匀生成若干采样点。采样点落入哪个区间,就复制哪个粒子。A 的区间最长,因此最容易被多次命中;D、E 区间短,因此可能很少被选中。重采样后,新粒子通常重新赋予均匀权重,因为之前的高权重优势已经通过“被复制更多次”体现出来。
不过重采样不能过于频繁。若每一帧都把粒子不断复制到同一个最高分位置,粒子会逐渐失去多样性,形成粒子退化。粒子退化表现为:所有粒子都来自少数祖先,位置和朝向几乎完全重合。若这个主簇确实正确,定位会显得很稳定;但若它是错误的局部最优位置,系统将失去其他候选位置,机器人被搬走或环境突变时恢复会困难。
因此常用有效粒子数评估当前粒子是否已经明显退化:
N_eff
=
1
/
sum(
weight_i * weight_i
)若 N 个粒子权重都接近 1/N,则 N_eff 接近 N,说明权重比较均匀,粒子多样性较好;若少数粒子占据绝大部分权重,N_eff 会明显小于 N,说明很多粒子已没有意义,此时重采样更合理。AMCL 的 resample_interval 则规定需要经过多少次滤波更新后才执行一次重采样,Nav2 默认示例为每次更新后可进行一次重采样。
AMCL 名称中的 Adaptive,主要体现在 KLD-Sampling,也就是自适应粒子数量。固定粒子数并不总是合理。机器人全局定位时,粒子可能分散在多个房间、多个货架通道和多个朝向区间,状态不确定性很高,需要较多粒子覆盖地图;机器人稳定定位后,粒子通常只集中在一个小区域,继续维持几千粒子会浪费计算资源。
KLD-Sampling 的做法是将状态空间划分为多个 bin。一个 bin 可以理解为一小块位置区域加一小段 yaw 范围。例如:
x:
每 0.5 m 一个 bin
y:
每 0.5 m 一个 bin
yaw:
每 10 deg 一个 bin如果粒子集中在同一走廊、同一位置附近、朝向也基本一致,粒子只会占据少量 bin;如果粒子散布在多个走廊、多个房间和多个朝向,则会占据更多 bin。KLD-Sampling 根据当前占据 bin 的数量估计需要多少粒子。常见形式如下:
N_required
=
((k - 1) / (2 * pf_err))
*
(
1
- 2 / (9 * (k - 1))
+ sqrt(2 / (9 * (k - 1))) * pf_z
)^3其中:
k:
当前被粒子占据的 bin 数量
pf_err:
允许概率分布近似误差
pf_z:
置信度相关参数
N_required:
当前粒子数量下限这条公式不必死记,但它表达的趋势必须理解:
粒子越分散:
k 越大;
不确定性越高;
需要的粒子越多。
粒子越集中:
k 越小;
不确定性越低;
可以使用较少粒子。KLD-Sampling 的原始论文明确指出:当状态概率密度集中在较小区域时,只需要较少样本;当状态不确定性高、样本需覆盖较大状态空间时,需要更多样本。
AMCL 中的 min_particles 和 max_particles 就是这种自适应机制的上下限。min_particles 表示定位非常稳定时仍至少保留多少粒子;max_particles 表示定位不确定或全局恢复时最多允许多少粒子。Nav2 文档当前默认示例分别为 500 和 2000,但实际值必须结合地图面积、环境重复程度、CPU 性能、LiDAR 更新频率和底盘速度调整。
如果地图很大、重复货架很多、机器人经常需要全局定位,而 max_particles 过小,真实区域附近可能没有足够粒子,恢复和收敛都会变慢。若 max_particles 过大,LiDAR 每帧需要给更多粒子打分,CPU 占用和延迟增加;当 AMCL 更新速度低于 LiDAR 到达速度时,系统反而会丢掉新的环境信息。粒子数量不是越大越好,而是应在“概率分布覆盖能力”和“实时处理能力”之间平衡。
AMCL 还有随机恢复机制,用于处理机器人被搬走、初始位置严重错误或原有粒子云整体失配的情况。假设机器人原来位于地图 A 区域,odom 和粒子都认为机器人仍在 A;突然有人将机器人搬到 B 区域。此时 LiDAR 扫到的是 B 的环境,而 A 区域附近粒子与当前扫描都严重不匹配。如果 AMCL 一直只从 A 附近粒子中复制后代,系统就会困在错误区域。
恢复机制通常维护两个平均观测质量:
w_slow:
长时间平均匹配质量
w_fast:
最近几帧平均匹配质量更新形式:
w_slow
=
w_slow
+
alpha_slow
*
(w_avg - w_slow)w_fast
=
w_fast
+
alpha_fast
*
(w_avg - w_fast)其中 w_avg 是当前观测下粒子总体的平均匹配质量。机器人持续稳定定位时,w_fast 与 w_slow 大致接近;若最近 LiDAR 匹配质量突然显著下降,w_fast 会迅速低于 w_slow。此时系统认为当前粒子云可能整体错了,于是在重采样时增加随机粒子比例:
p_random
=
max(
0,
1 - w_fast / w_slow
)随机粒子不是从旧粒子附近复制,而是在地图自由区域重新生成。若其中一部分随机粒子恰好落到真实 B 区域附近,并且 B 区域 LiDAR 匹配明显优于 A,那么这些粒子在后续更新中会获得较高权重,并被重采样放大,最终系统逐步转移到 B。Nav2 的 recovery_alpha_fast 和 recovery_alpha_slow 就是用于这种快速与慢速平均权重滤波和随机姿态恢复的参数。
恢复机制并不代表机器人被搬走后一定立刻定位成功。地图越大,随机粒子越难落在真实位置附近;环境越重复,多个区域越难区分;max_particles 太小,随机探索能力有限;机器人静止不动时,新观测信息不足,也很难迅速排除相似区域。实际中,若机器人处于安全区域,缓慢旋转或小范围运动通常能让 LiDAR 看到更多方向上的门洞、货架端部、立柱和转角,从而提高恢复速度。
AMCL 最终需要从粒子云中输出一个明确位姿。最简单的方式是对粒子做加权平均:
x_est
=
sum(
w_i * x_i
)y_est
=
sum(
w_i * y_i
)yaw 不能直接做普通平均。例如 179 deg 和 -179 deg 实际方向几乎相同,但直接平均会得到 0 deg,这是错误的。因此 yaw 通常使用圆周平均:
sin_sum
=
sum(
w_i * sin(yaw_i)
)cos_sum
=
sum(
w_i * cos(yaw_i)
)yaw_est
=
atan2(
sin_sum,
cos_sum
)但实际 AMCL 不会始终对所有粒子直接平均。若粒子分成两个明显簇,例如左侧走廊总权重 0.55、右侧走廊总权重 0.45,直接平均位置可能落到两个走廊中间,一个机器人根本无法到达的位置。因此 AMCL 通常会对粒子聚类,计算每个簇的总权重,选择最高权重主簇,在主簇内部估计位置、朝向与协方差。Nav2 的 AMCL 节点会从最高权重假设簇中计算位姿和协方差,并发布相应的定位结果。
协方差反映 AMCL 对定位结果的信心。若 x 方向协方差小,说明机器人在 x 方向位置比较明确;若 yaw 协方差大,说明当前朝向仍不稳定。长走廊中常出现一种典型情况:横向位置和 yaw 比较稳定,但沿走廊方向的不确定性较大。因为两侧平行墙能约束机器人离墙距离和朝向,却很难告诉机器人“你沿走廊到底位于第几米”。只有门洞、立柱、货架端部、拐角、固定设备等独特结构出现时,沿走廊方向的概率分布才会明显收紧。
最后,AMCL 通过最终估计的 pose_map_base 和 odom 当前位姿,计算并发布 map -> odom:
T_map_odom
=
T_map_base_amcl
*
inverse(T_odom_base)最终机器人在地图中的姿态满足:
T_map_base
=
T_map_odom
*
T_odom_baseodom -> base_link 由底盘 odom 或 EKF 持续提供,它通常连续、平滑,适合局部控制;map -> odom 由 AMCL 根据 LiDAR 与地图匹配不断调整,用于修正长期漂移;二者相乘得到最终 map -> base_link,用于 RViz 全局显示、导航目标点、全局路径规划和地图坐标下的任务执行。
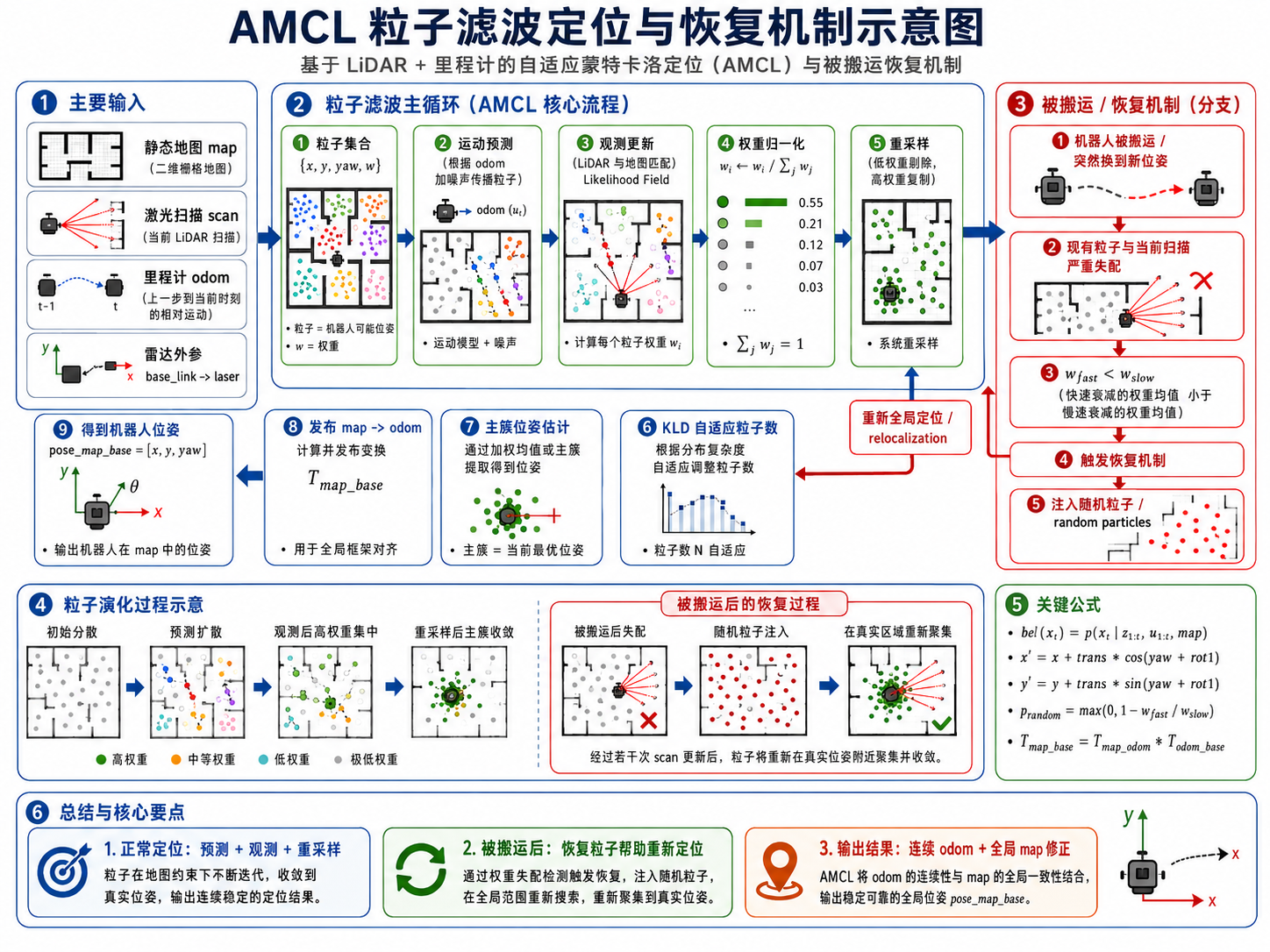
总结
AMCL 的核心不是简单地“拿 LiDAR 和地图对一下”,而是一个持续运行的概率定位系统。机器人在真实环境中永远存在不确定性:编码器会有误差,轮胎会打滑,左右轮直径不会完全一致,地面摩擦和坡度会变化,IMU 也可能存在漂移;与此同时,LiDAR 扫描也并不绝对可靠,可能扫到人、叉车、纸箱、临时货物、玻璃反射和地图中未记录的结构。AMCL 的价值就在于它不把这些误差看成偶发异常,而是将其纳入整个概率估计过程。
粒子滤波首先解决的是“机器人不一定只有一个可能位置”这个问题。一个粒子不是 LiDAR 点、地图格子或历史轨迹,而是一个完整的机器人位姿假设:机器人可能位于这个 x、y,并且朝向这个 yaw。大量粒子共同表示机器人当前在地图中的概率分布。高权重粒子多的地方,说明机器人更可能在那里;粒子分成多团,说明当前环境仍存在定位歧义。正因为粒子滤波可以同时保留多个候选位置,所以它特别适合仓库货架、走廊、办公室等存在重复几何结构的环境。系统不必在第一帧就仓促决定机器人在哪,而是可以让后续移动和连续 LiDAR 观测不断淘汰错误区域。
AMCL 的每一轮更新都可以看成“预测—校正—重分配”三个连续动作。预测阶段由 odom 驱动。odom 告诉系统机器人刚才大概前进了多少、转了多少,但 AMCL 不会绝对相信这个结果,而是让不同粒子带着不同随机噪声移动。这样粒子云会逐渐扩散,表达机器人随着运动累积的不确定性。alpha1 到 alpha4 的意义就在于描述不同运动形式带来的误差:旋转会引起旋转误差,平移会引起平移误差,平移也可能带来 yaw 误差,旋转也可能造成位置偏移。若 alpha 太小,AMCL 会过度相信 odom,真实位置偏出粒子云后难以恢复;若 alpha 太大,粒子每次扩散过宽,计算量增大、收敛变慢、定位更容易抖动。
校正阶段由 LiDAR 和地图完成。AMCL 会让每个粒子都假设“机器人就在这里”,然后把当前 LiDAR 端点按照该粒子的 x、y、yaw 投到地图中。若这个粒子正确,左侧扫描点应靠近地图左货架,右侧扫描点应靠近右墙,前方点应靠近立柱,门洞边缘点也应与地图中的门洞结构吻合;若粒子错误,大量扫描点就会投到空白区域、墙内、地图外或整体错位的位置。Likelihood Field 距离场模型进一步将这种判断转化为可计算概率:每个扫描端点不需要刚好命中某个地图点,只要离最近地图障碍物较近,就认为匹配较好。距离越小,命中概率越高;距离越大,命中概率越低。
LiDAR 匹配不能过于死板。现实中存在动态人车、临时货物、玻璃反射和门状态变化,因此 AMCL 通过 z_hit 表达对静态地图匹配的信任,通过 z_rand 容忍部分随机异常测量;在动态障碍物较多时,还可使用 beam skipping,暂时跳过那些被多数粒子都认为与地图不一致的激光束。这样系统不会因为一个人挡在墙前、一个叉车停在通道里,就错误地否定全部正确粒子。但 beam skipping 也不能滥用:若大量 beam 都不匹配,更可能是地图、TF、雷达外参、初始位姿或整体定位本身出了问题,而不是简单的动态障碍物。
权重归一化与重采样决定粒子云如何演化。LiDAR 评分后,高权重粒子表示当前更可信的位置;低权重粒子表示当前不太符合地图。重采样不是只保留最高分,而是按概率比例复制粒子:高权重区域获得更多粒子,低权重区域逐渐减少。这样,有限计算资源会集中到更可能正确的地图区域。下一帧 odom 到来后,这些高概率区域的粒子继续带噪声移动,再经过 LiDAR 评分和重采样,概率云不断收紧。与此同时,AMCL 又必须避免粒子过早退化成一个极小簇,否则一旦定位错误或机器人被搬走,系统就失去其他候选位置。因此有效粒子数、重采样间隔和随机恢复机制都是为了在“快速收敛”和“保留恢复能力”之间维持平衡。
AMCL 中的 Adaptive 体现为 KLD-Sampling。机器人刚全局定位、进入相似货架区、被搬走或环境存在多解时,粒子会占据多个位置和朝向区间,系统不确定性高,需要更多粒子覆盖地图;机器人已经稳定定位后,粒子集中在少数位置和朝向,系统可以减少粒子数,降低 CPU 占用。min_particles、max_particles、pf_err 和 pf_z 就围绕这一机制工作。粒子太少会导致真实位置附近没有足够假设,粒子太多又会使每帧 LiDAR 更新变慢,甚至因为处理不过来而损失新的传感器数据。因此粒子数量不是越大越好,而是必须与地图规模、环境重复度、CPU 性能、LiDAR 频率和机器人速度匹配。
AMCL 的恢复机制解决的是“现有粒子云整体都错了”的问题。机器人被搬走后,odom 仍认为机器人在旧位置,但 LiDAR 已经看到新区域环境。通过比较快速平均匹配质量和慢速平均匹配质量,AMCL 可以发现最近观测突然变差,并在重采样时随机向地图自由区域注入新粒子。只要随机粒子中有一部分落在真实区域附近,并且该区域的 LiDAR 匹配明显更好,这些粒子就会在后续循环中被放大,最终实现重新定位。恢复并不保证瞬间成功;地图大、环境重复、机器人静止、粒子上限过低时都会使恢复变慢。但这套机制使 AMCL 不会永久锁死在旧位置。
最后,AMCL 的定位结果不是直接覆盖 odom,而是通过发布 map -> odom 来修正 odom 的全局漂移。odom -> base_link 保持连续,适合局部控制和局部规划;map -> odom 根据 LiDAR 与地图匹配不断调整;二者相乘得到最终 map -> base_link。因此可以把整个系统记成:
odom:
告诉 AMCL,
机器人刚才大概怎么走了。
LiDAR + map:
告诉 AMCL,
这些运动预测中,
哪些位置最符合真实环境。
粒子权重:
告诉系统,
各个候选位置分别有多可信。
重采样:
让高可信区域粒子越来越多,
让低可信区域粒子逐渐减少。
KLD 自适应采样:
不确定时增加粒子,
收敛后减少粒子。
恢复粒子:
当整体失配时,
给系统重新在地图中找位置的机会。
map -> odom:
将 LiDAR 地图定位结果
转换为对 odom 漂移的全局修正。
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)