MotionWAM:迈向用于实时人形机器人移动操作的基础世界动作模型
26年6月来自Mondo Robot(https://www.mondorobot.com/)、港科大(广州)和港大的论文“MotionWAM: Towards Foundation World Action Models for Real-Time Humanoid Loco-Manipulation”。
世界动作模型(WAMs)将视频动态先验与策略相结合,在桌面操作任务中展现出了令人鼓舞的成果;然而,针对高维视频-动作潜空间进行的迭代去噪过程计算耗时,导致其难以满足人形机器人实时移动操作(loco-manipulation)的需求。这一问题因主流的分层控制范式而变得更加严峻:在该范式下,高层操作策略仅控制上半身,而底层控制器负责跟踪粗略的基座指令,这种做法导致上下半身处于不一致的动作空间,并将腿部功能局限于维持平衡的移动。为此,提出 MotionWAM——一种能够利用单目第一人称视角(egocentric)摄像头实现自主人形机器人移动操作的实时 WAM。该模型将策略建立在视频世界模型的中间去噪特征之上来运作。MotionWAM 摒弃上下半身分离的控制方式,转而采用统一的运动潜表示,并预测涵盖移动、躯干运动、高度调节、足部交互及手部操作的全身运动 Token,从而在单一动作空间内实现这些动作的协同。其设计一个三阶段学习框架,使视频世界模型能够逐步适应第一人称视觉动态及目标人形机器人的物理形态。在针对 Unitree G1 机器人的九项真实世界任务测试中,MotionWAM 实现实时运行;其整体成功率比在相同演示数据上微调过的“视觉-语言-动作”(VLA)基线模型高出 30% 以上;此外,它还能执行任务驱动的足部交互动作,而这是上下半身解耦策略无法实现的。
如图1 所示MotionWAM:一种用于实时人形机器人移动操作(loco-manipulation)的统一 WAM 框架。在 Unitree G1 机器人上,MotionWAM 生成涵盖腰部控制、高度调节、下蹲移动、身体与手部协同以及任务驱动型足部交互的真实世界轨迹。

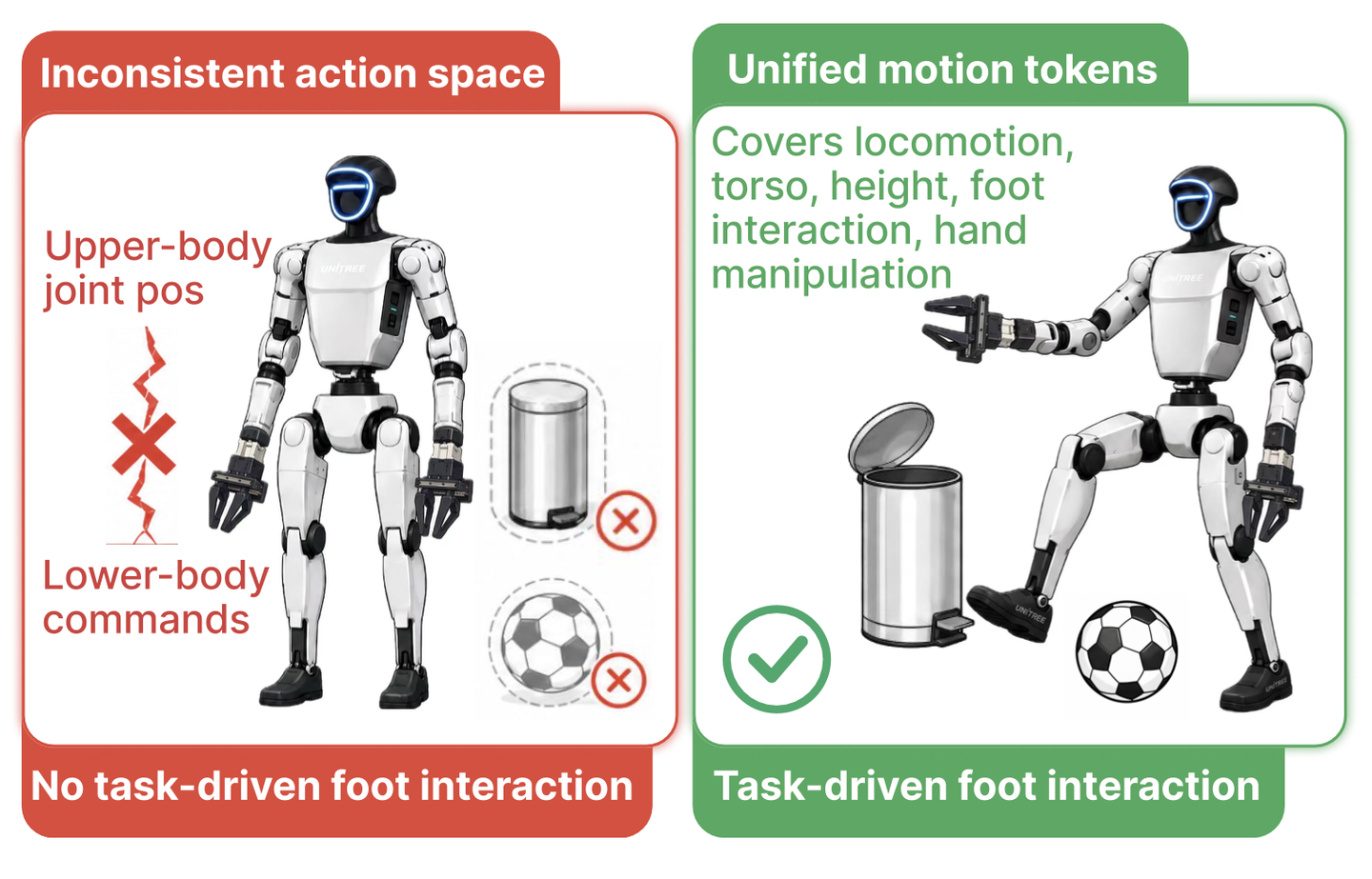
人形机器人的移动操作(loco-manipulation)任务要求机器人在人类尺度的环境中移动,同时协调平衡、行走、肢体伸展及物体交互。既有研究主要在三个相对独立的维度上取得了进展:鲁棒的全身模仿 [1, 2, 3, 4]、指令驱动的全身控制器 [5, 6, 7, 8, 9] 以及作为高层规划器的操作策略 [10, 11, 12, 13]。几乎所有自主人形移动操作系统都结合了这些维度,即采用“高层操作策略 + 低层移动控制器”的组合模式 [12, 10, 13]:该模式为上半身提供精细的关节目标,而仅向底盘(下半身)发送粗略的移动指令(如速度、躯干高度和朝向)。这种做法导致上下半身处于不一致的动作空间中,并将腿部功能局限于维持平衡的移动,从而排除了诸如踩踏踏板或踢击物体等任务驱动的足部交互行为(如图2所示)。
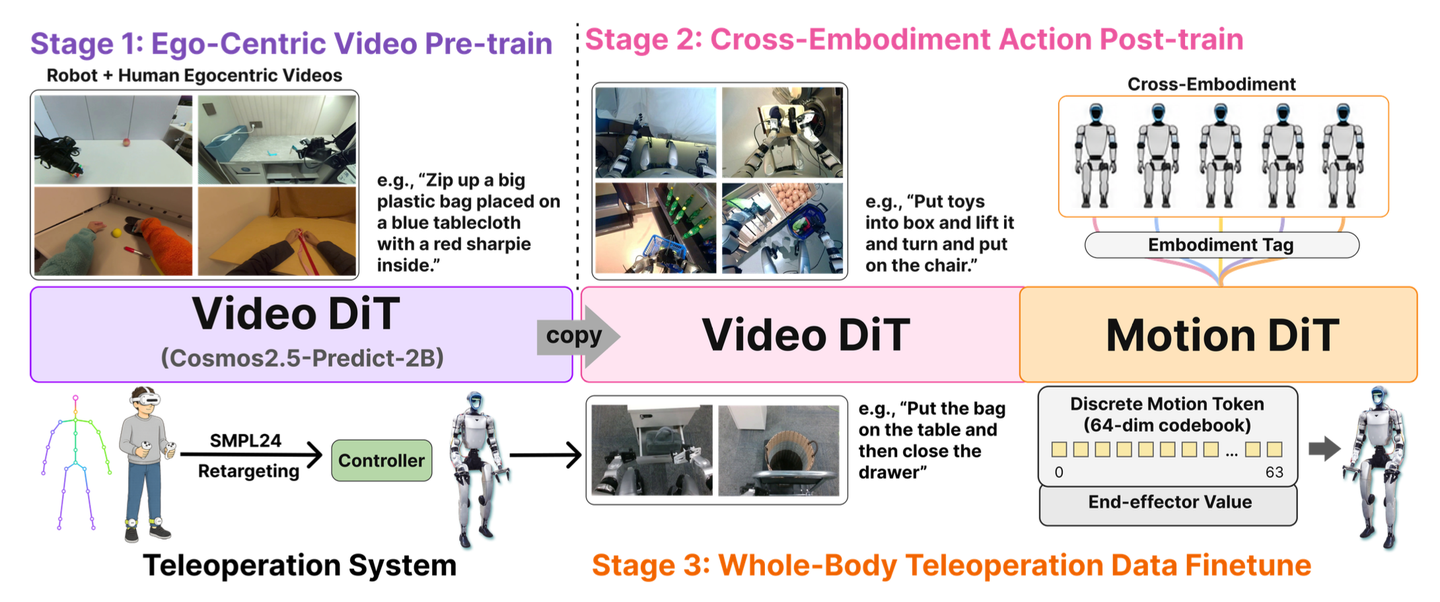
如图 3 所示MotionWAM 概览:这是一个分三个阶段训练的双 DiT(Diffusion Transformer)视频-动作模型。阶段 1:单独对 Video DiT 进行预训练,使用以自我为中心(egocentric)的人类及类人机器人视频数据。阶段 2:引入 Motion DiT 并结合特定的具身(embodiment)标签,在异构的 Unitree G1 数据集上进行联合训练;该阶段利用 Video DiT 的隐状态作为条件,预测离散的动作 Token 索引及连续的末端执行器数值。阶段 3:利用从 SMPL-24 重定向至 Unitree G1 的全身遥操作演示数据,对完整模型进行微调。
如图 4 所示真实世界实验任务。在配备双 ALOHA2 夹爪的 Unitree G1 人形机器人上进行所有实地实验,并通过安装在头部、面向前方场景的 Intel RealSense D435i RGB 相机进行观测。全身遥操作演示数据是通过 PICO VR 三点追踪系统采集的,并利用 SMPL 模型将动作重定向至机器人;在实际部署阶段,策略输出由 SONIC [4] 全身控制器进行跟踪执行。MotionWAM 及所有基线方法均作为 WebSocket 策略服务器运行于单台 NVIDIA RTX 4090 工作站上,并由机载控制器进行闭环查询。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 9
9 0
0- 0



 已为社区贡献348条内容
已为社区贡献348条内容

所有评论(0)