机器学习之逻辑回归和softmax回归及代码示例
一、逻辑回归
在 机器学习之线性回归 中,我们可使用梯度下降的方法得到一个映射函数 hθ(X) <script type="math/tex" id="MathJax-Element-434">h_\theta(X)</script> 来去贴近样本点,这个函数是对连续值的一个预测。
而逻辑回归是解决分类问题的一个算法,我们可以通过这个算法得到一个映射函数 f:X→y <script type="math/tex" id="MathJax-Element-435">f:X → y</script> ,其中 X <script type="math/tex" id="MathJax-Element-436">X</script> 为特征向量,
二、判定边界
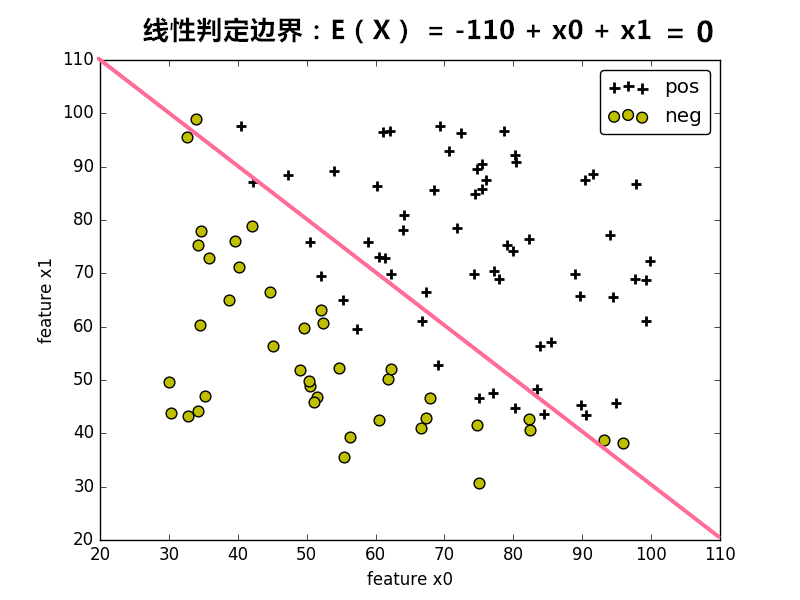
当将训练集的样本以其各个特征为坐标轴在图中进行绘制时,通常可以找到某一个 判定边界 去将样本点进行分类。例如:
线性判定边界:
非线性判定边界:
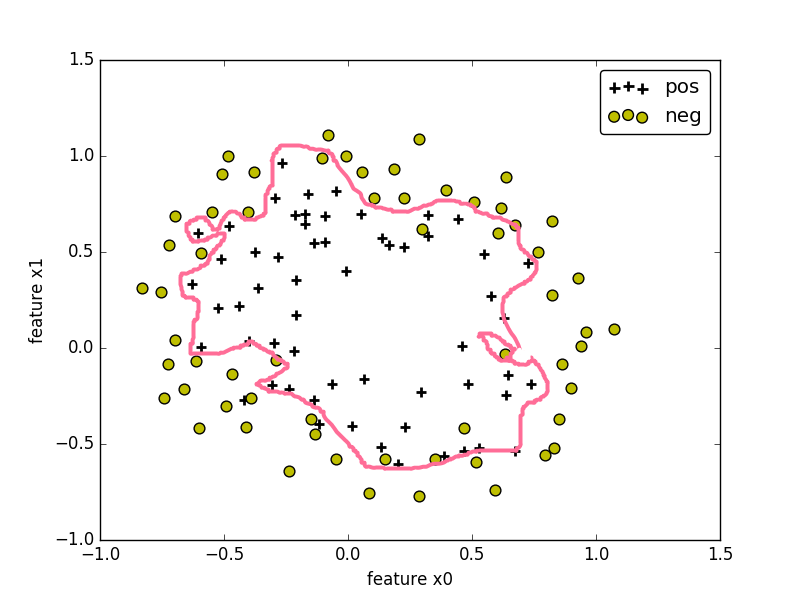
在图中,样本的标记类型有两种类型,一种为正样本,另一种为负样本,样本的特征 x0 <script type="math/tex" id="MathJax-Element-455">x_0</script> 和 x1 <script type="math/tex" id="MathJax-Element-456">x_1</script>为坐标轴。根据样本的特征值,可将样本绘制在图上。
在图中,可找到某个 判定边界 来对不同标签的样本进行划分。根据这个判定边界,我们可以知道哪些样本是正样本,哪些样本为负样本。
因此我们可以通过学习得到一个方程 Eθ(X)=0 <script type="math/tex" id="MathJax-Element-457">E_\theta(X) = 0</script> 来表示 判定边界,即 判定边界 为 Eθ(X)=0 <script type="math/tex" id="MathJax-Element-458">E_\theta(X) = 0</script> 的点集。(可以看作是等高超平面)
其中 θ={θ0,θ1,θ2,...,θn} <script type="math/tex" id="MathJax-Element-369">\theta = \{ \theta_0,\theta_1,\theta_2,...,\theta_n\}</script> ,为保留 Eθ(X)=0 <script type="math/tex" id="MathJax-Element-370">E_\theta(X) = 0 </script> 中的常数项,令特征向量 X={1,x1,x2,…,xn} <script type="math/tex" id="MathJax-Element-371">X = \{ 1,x_1,x_2 ,…,x_n \}</script>。
为使得我们的边界可以非线性化,对于特征 xi <script type="math/tex" id="MathJax-Element-372">x_i</script> 可以为特征的高次幂或相互的乘积。
对于位于判定边界上的样本,其特征向量 X <script type="math/tex" id="MathJax-Element-373">X</script> 可使得
三、二分类和sigmoid函数
在上面,可以通过找到一个判定边界来区别样本的标签,得到一个方程
对于 二分类问题,即样本标签的类型只有两种类型。
当样本标记的类型只有两种时,其中一类的样本点在 判定边界的一边,其会有 Eθ(X)>0 <script type="math/tex" id="MathJax-Element-536">E_\theta(X) > 0</script>,而另一类的样本会在判定边界的另一边,会有 Eθ(X)<0 <script type="math/tex" id="MathJax-Element-537">E_\theta(X) < 0</script>。
当样本点离 判定边界 越远时, Eθ(X) <script type="math/tex" id="MathJax-Element-538">E_\theta(X)</script> 的绝对值越大于0,这时样本的标签是某种类型的概率会很大,可能会等于1;当样本点离 判定边界 越近时, Eθ(X) <script type="math/tex" id="MathJax-Element-539">E_\theta(X) </script>的接近0,样本的标签是某种类型的概率会在0.5左右。
因此,我们可以将 Eθ(X) <script type="math/tex" id="MathJax-Element-540">E_\theta(X) </script>函数 转换 为一种概率函数,通过概率来判断样本的标签是某一种类型的概率会是多少。而这种 转换 可以使用 sigmoid函数来实现 :
sigmoid函数图像如下:
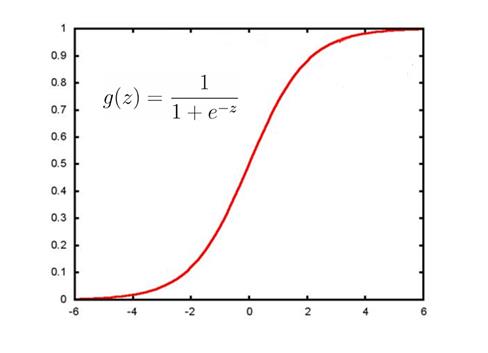
从sigmoid函数图像可看出:当z为0左右时,函数值为0.5左右;z越大于0时,函数值越大于0.5越收敛于1;z越小于0时,函数值越小于0.5越收敛于0。
因此,sigmoid函数可适用于在二分类问题中将 Eθ(X) <script type="math/tex" id="MathJax-Element-737">E_\theta(X) </script> 函数 转换为概率函数。
当 Eθ(X)>0 <script type="math/tex" id="MathJax-Element-738">E_\theta(X) > 0</script>时,样本标记的类型为某一类型的概率会大于0.5;当 Eθ(X)<0 <script type="math/tex" id="MathJax-Element-739">E_\theta(X) < 0</script>时,样本标记的类型为某一类型的概率会小于0.5;当 Eθ(X) <script type="math/tex" id="MathJax-Element-740">E_\theta(X) </script> 约等于 0时,样本标记的类型为某一类型的概率会在0.5左右。
在二分类问题中,可以找到逻辑回归函数 hθ(X)=sigmoid( Eθ(X) ) <script type="math/tex" id="MathJax-Element-741">h_\theta(X) = sigmoid(\ E_\theta(X)\ )</script>,判定边界可看作 hθ(X)=0.5 <script type="math/tex" id="MathJax-Element-742">h_\theta(X) = 0.5 </script> 时的等高线。

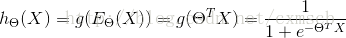
四、损失函数
由上面,找到了二分类问题中的一个逻辑回归函数 
在逻辑回归函数中,特征向量系数 θ <script type="math/tex" id="MathJax-Element-23">\theta</script> 是未知的,需要从样本中学习得来的。当从样本中学习得到一个特征向量系数 θ <script type="math/tex" id="MathJax-Element-24">\theta</script> 时,怎么知道它对应的 hθ(X) <script type="math/tex" id="MathJax-Element-25">h_\theta(X)</script> 函数的预测能力会更好?判断更准确?因此,需要一个损失函数来表示逻辑回归函数 hθ(X) <script type="math/tex" id="MathJax-Element-26">h_\theta(X)</script> 的好坏程度。
1. 定义
在二分类问题中,若用 hθ(X) <script type="math/tex" id="MathJax-Element-859">h_\theta(X) </script> 的值 表示正样本的概率,且 hθ(X)∈(0,1) <script type="math/tex" id="MathJax-Element-860">h_\theta(X) ∈(0 , 1)</script>,需要的损失函数应该是这样的:
-
当样本标签的类型是正类型时,若该样本对应的 hθ(X) <script type="math/tex" id="MathJax-Element-861">h_\theta(X) </script> 值为1时,即为正类型的概率为1,这时候损失函数值应为0;若该样本对应的 hθ(X) <script type="math/tex" id="MathJax-Element-862">h_\theta(X) </script> 值为0.0001时,即为正样本的概率为0.0001,这时候损失函数值应该是一个很大的值。
-
当样本标记的类型是负类型时,若该样本对应的 hθ(X) <script type="math/tex" id="MathJax-Element-863">h_\theta(X) </script> 值为0时,即为正样本的概率为0,这时损失函数值应为0;若该样本对应的 hθ(X) <script type="math/tex" id="MathJax-Element-864">h_\theta(X) </script> 值为0.9999时,即为正样本的概率为0.9999,这时候损失函数值应该是一个很大的值。
因此二分类问题中,为满足这种需求,对于单个样本来说,其损失函数可以表示为:
( hθ(X) <script type="math/tex" id="MathJax-Element-865">h_\theta(X) </script> 的值表示正样本的概率)
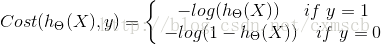
其中 y = 1 表示样本为正样本,y = 0 表示样本为负样本。
结合起来的写法:
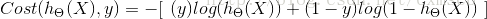
上式的代价函数也称作:交叉熵代价函数
对于训练集所有样本来说,共同造成的损失函数的均值 Jθ(X) <script type="math/tex" id="MathJax-Element-866">J_\theta(X) </script> 可以表示为:

将 Cost函数 代入 Jθ(X) <script type="math/tex" id="MathJax-Element-867">J_\theta(X) </script> 中:
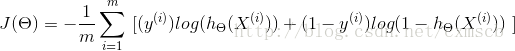
对于样本来说,其标记y为1 (正样本)或为 0(负样本),对于预测概率函数 hθ(X) <script type="math/tex" id="MathJax-Element-868">h_\theta(X) </script> 来说,预测到样本为正样本的概率值在0到1之间。
2. 极大似然估计
上述的损失函数 Jθ(X) <script type="math/tex" id="MathJax-Element-36">J_\theta(X) </script> 也可以通过极大似然估计来求得:以 hθ(X) <script type="math/tex" id="MathJax-Element-37">h_\theta(X) </script> 的值 表示正样本的概率,且以 y = 1 表示 正样本 ,y = 0 表示 负样本,则有:
合并上述两个式子则有:
对m个样本,求极大似然估计:
取对数似然估计:
对数似然取极值(极大值)时的 θ 取值便是我们想要的,因此需要对目标函数 l(θ) <script type="math/tex" id="MathJax-Element-1099">l(\boldsymbol{\theta}) </script> 进行最大化,即相当于 对 上述的 J(θ) <script type="math/tex" id="MathJax-Element-1100">J(\boldsymbol{\theta}) </script> 进行最小化: l(θ)=−J(θ) <script type="math/tex" id="MathJax-Element-1101">l(\theta) = - J(\theta)</script>。
3. 正则化
同时,当预测概率函数 hθ(X) <script type="math/tex" id="MathJax-Element-44">h_\theta(X) </script> 过拟合,会导致高次项的特征向量系数 θi <script type="math/tex" id="MathJax-Element-45">\theta_i </script> 过大(因为为 Eθ(X)=0 <script type="math/tex" id="MathJax-Element-46">E_\theta(X) = 0 </script> 分清每个样本点的类型时会使得它足够的扭曲,这种扭曲通常由高次项的特征向量系数造成)。因此,为防止过拟合可以添加正则化项,即在损失函数的后面加个“尾巴”。
添加L2正则化项后的损失函数表示为:

五、最小化损失函数
在上面得到了 二分类问题 的逻辑回归的损失函数 Jθ(X) <script type="math/tex" id="MathJax-Element-47">J_\theta(X) </script> 。为达到不错的分类效果,需要对损失函数进行最小化。
与 线性回归 相类似的是,这里的损失函数也是一个凸函数,因此,可以通过梯度下降法来得到合适的特性系数向量Θ。
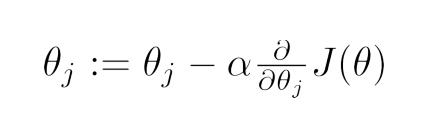
同样,上式中的a为学习率(下山步长)。将上式的偏导展开,可得:
非正则化的损失函数的偏导:
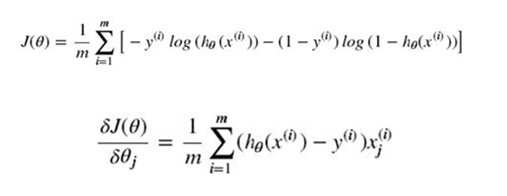
含正则化项的损失函数的偏导:
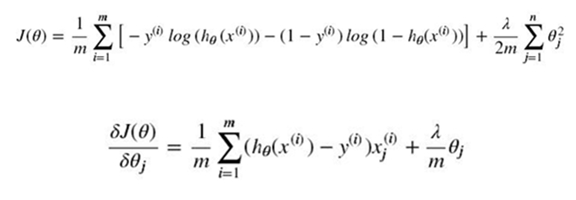
其中 λ 为正则化的强度。
同线性回归般,可以通过学习率a对特征系数向量中的元素不断进行迭代,直到元素值收敛到某一值即可,这时可以得到损失函数较小时的特征向量系数Θ。
六、从二分类过渡到多分类
在上面,我们主要使用逻辑回归解决二分类的问题,那对于多分类的问题,也可以用逻辑回归来解决?
1. one vs rest
由于概率函数 hΘ(X) 所表示的是样本标记为某一类型的概率,但可以将一对一(二分类)扩展为一对多(one vs rest):
-
将类型class1看作正样本,其他类型全部看作负样本,然后我们就可以得到样本标记类型为该类型的概率p1;
-
然后再将另外类型class2看作正样本,其他类型全部看作负样本,同理得到p2;
-
以此循环,我们可以得到该待预测样本的标记类型分别为类型class i时的概率pi,最后我们取pi中最大的那个概率对应的样本标记类型作为我们的待预测样本类型。
2. softmax函数
使用softmax函数构造模型解决多分类问题。
softmax回归分类器需要学习的函数为 :

其中 k 个 类别的个数 ,

其中 

与 logistic回归 不同的是,softmax回归分类模型会有多个的输出,且输出个数 与 类别个数 相等,输出为样本 X 为各个类别的概率 ,最后对样本进行预测的类型为 概率最高 的那个类别。
我们需要通过学习得到

上式的代价函数也称作:对数似然代价函数。
在二分类的情况下,对数似然代价函数 可以转化为 交叉熵代价函数。
其中 m 为训练集样本的个数,k 为 类别的个数,

利用 对数的性质 log(ab)=log(a)−log(b) <script type="math/tex" id="MathJax-Element-48">log(\frac{a}{b}) = log(a) - log(b)</script>,将 损失函数 展开有:

继续展开:

通过 梯度下降法 最小化损失函数 和 链式偏导,使用 

化简可得:

再次化简可有:

因此由 梯度下降法 进行迭代:

同理 通过梯度下降法最小化损失函数也可以得到
同逻辑回归一样,可以给损失函数加上正则化项。
3. 选择的方案
当标签类别之间是互斥时,适合选择softmax回归分类器 ;当标签类别之间不完全互斥时,适合选择建立多个独立的logistic回归分类器。
4. tensorflow代码示例:
- 使用softmax回归对sklearn中的digit手写数据进行分类
import tensorflow as tffrom sklearn.datasets import load_digits
import numpy as npdigits = load_digits()
X_data = digits.data.astype(np.float32)
Y_data = digits.target.reshape(-1,1).astype(np.float32)
print X_data.shape
print Y_data.shape(1797, 64)
(1797, 1)
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()X_data = scaler.fit_transform(X_data)from sklearn.preprocessing import OneHotEncoderY = OneHotEncoder().fit_transform(Y_data).todense() #one-hot编码Ymatrix([[ 1., 0., 0., ..., 0., 0., 0.],
[ 0., 1., 0., ..., 0., 0., 0.],
[ 0., 0., 1., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., 0., 1., 0.],
[ 0., 0., 0., ..., 0., 0., 1.],
[ 0., 0., 0., ..., 0., 1., 0.]])
print Y.shape(1797, 10)
1797
batch_size = 10 # 使用MBGD算法,设定batch_size为10def generatebatch(X,Y,n_examples, batch_size):
for batch_i in range(n_examples // batch_size):
start = batch_i*batch_size
end = start + batch_size
batch_xs = X[start:end, :]
batch_ys = Y[start:end]
yield batch_xs, batch_ys # 生成每一个batchtf.reset_default_graph()
tf_X = tf.placeholder(tf.float32,[None,64])
tf_Y = tf.placeholder(tf.float32,[None,10])tf_W_L1 = tf.Variable(tf.zeros([64,10]))
tf_b_L1 = tf.Variable(tf.zeros([1,10]))pred = tf.nn.softmax(tf.matmul(tf_X,tf_W_L1)+tf_b_L1)loss = -tf.reduce_mean(tf_Y*tf.log(tf.clip_by_value(pred,1e-11,1.0)))
# 也可以直接使用tensorflow的版本:
# loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=tf_Y,logits=pred))train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)y_pred = tf.arg_max(pred,1)
bool_pred = tf.equal(tf.arg_max(tf_Y,1),y_pred)accuracy = tf.reduce_mean(tf.cast(bool_pred,tf.float32)) # 准确率with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(2001): # 迭代2001个周期
for batch_xs,batch_ys in generatebatch(X_data,Y,Y.shape[0],batch_size): # 每个周期进行MBGD算法
sess.run(train_step,feed_dict={tf_X:batch_xs,tf_Y:batch_ys})
if(epoch%1000==0):
res = sess.run(accuracy,feed_dict={tf_X:X_data,tf_Y:Y})
print (epoch,res)
res_ypred = y_pred.eval(feed_dict={tf_X:X_data,tf_Y:Y}).flatten()
print res_ypred(0, 0.86866999)
(1000, 0.99332219)
(2000, 0.99833053)
[0 1 2 ..., 8 9 8]
from sklearn.metrics import accuracy_scoreprint accuracy_score(Y_data,res_ypred.reshape(-1,1))0.998330550918
八、Logistic Loss的另一种表达
在上面的逻辑回归的二分类问题中,我们令正样本的标签 y = 1 ,负样本的标签 y = 0。对于单个样本来说,其损失函数Cost(hΘ(X),y)可以表示为:(hΘ(X)的值表示正样本的概率)
若我们 令正样本的标签 y = 1 ,负样本的标签 y = -1,则有:
其中(待续)
七、代码示例
- 使用ovr多分类的逻辑回归判断鸢尾属植物的类型
from sklearn import datasets
iris = datasets.load_iris() # 加载数据
X = iris.data
y = iris.target
print X.shape
print y.shape(150L, 4L)
(150L,)
from sklearn.model_selection import train_test_split
#分隔训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y ,test_size = 1/3.,random_state = 8)from sklearn.preprocessing import PolynomialFeatures
featurizer = PolynomialFeatures(degree=2) # 特征多项式化
X_train = featurizer.fit_transform(X_train)
X_test = featurizer.transform(X_test)from sklearn.preprocessing import StandardScaler # 对数据归一化
scaler = StandardScaler()
X_std_train = scaler.fit_transform(X_train)
X_std_test = scaler.transform(X_test)from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import SGDClassifier
# penalty:正则化 l2/l1
# C :正则化强度
# multi_class:多分类时使用 ovr: one vs rest
lor = LogisticRegression(penalty='l1',C=100,multi_class='ovr')
lor.fit(X_std_train,y_train)
print lor.score(X_std_test,y_test)
sgdv = SGDClassifier(penalty='l1')
sgdv.fit(X_std_train,y_train)
print sgdv.score(X_std_test,y_test)0.94
0.92
LogisticRegression对参数的计算采用精确解析的方式,计算时间长但模型的性能高;SGDClassifier采用随机梯度下降/上升算法估计模型的参数,计算时间短但模型的性能较低。
- 使用Tensorflow实现线性逻辑回归:
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import numpy as npX, y = make_classification(n_features=2, n_redundant=0, n_informative=2,
n_clusters_per_class=1,random_state=78,n_samples=200)
X = X.astype(np.float32)
y = y.astype(np.float32)plt.scatter(X[:,0],X[:,1],c=y)
plt.show()
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(X)
X = scaler.transform(X)
print X.shape(200, 2)
b = tf.Variable(tf.zeros([1,1]))
W = tf.Variable(tf.zeros([2,1]))
X_DATA = tf.placeholder(tf.float32,[None,2])
Y = tf.placeholder(tf.float32,[None,1])H = 1 / (1 + tf.exp(-(tf.matmul(X_DATA, W) + b)))
loss = tf.reduce_mean(- Y* tf.log(tf.clip_by_value(H,1e-11,1.0)) - (1 - Y) * tf.log(1 - tf.clip_by_value(H,1e-11,1.0)))
# 也可以使用tensorflow的版本:
#loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=tf_Y,logits=pred))optimizer = tf.train.GradientDescentOptimizer(0.1)train = optimizer.minimize(loss)init_vals = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_vals)
for step in range(15501):
sess.run(train,feed_dict={X_DATA:X,Y:y.reshape(-1,1)})
if(step%5000==0):
print(step,sess.run(W).flatten(),sess.run(b).flatten())
w1 = sess.run(W).flatten()
b1 = sess.run(b).flatten()(0, array([ 0.04289575, 0.04343094], dtype=float32), array([-0.0005], dtype=float32))
(5000, array([ 3.44468737, 3.617342 ], dtype=float32), array([-1.10549724], dtype=float32))
(10000, array([ 3.46032 , 4.07498837], dtype=float32), array([-1.60735476], dtype=float32))
(15000, array([ 3.45384622, 4.39454508], dtype=float32), array([-1.95797122], dtype=float32))
print (w1,b1)(array([ 3.45412397, 4.42197132], dtype=float32), array([-1.9879719], dtype=float32))
x1_min, x1_max = X[:,0].min(), X[:,0].max(),
x2_min, x2_max = X[:,1].min(), X[:,1].max(),
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max), np.linspace(x2_min, x2_max))
f = w1[0]*xx1+w1[1]*xx2+b1[0]
plt.contour(xx1, xx2, f, [0], colors = 'r') # 绘制分隔超平面
plt.scatter(X[:,0],X[:,1],c=y)
plt.show()

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)