深度学习-线性回归
一.深度学习是用来干什么的? 举个例子
假设我是上帝,我悄悄定了一个规则:
考试成绩 = 8.1 × 学习时间 + 2 × 作业完成度 + 2 × 课堂参与度 + 4 × 考前复习 + 1.1
然后我给了你一堆数据:
我只给你看这些,不告诉你规则 学生A: 学习时间=2h, 作业完成度=3, 参与度=4, 复习=1 → 考试成绩=8.1×2 + 2×3 + 2×4 + 4×1 + 1.1 = 16.2+6+8+4+1.1 = 35.3 学生B: 学习时间=1h, 作业完成度=5, 参与度=2, 复习=3 → 考试成绩=8.1×1 + 2×5 + 2×2 + 4×3 + 1.1 = 8.1+10+4+12+1.1 = 35.2 学生C: 学习时间=3h, 作业完成度=2, 参与度=5, 复习=2 → 考试成绩=8.1×3 + 2×2 + 2×5 + 4×2 + 1.1 = 24.3+4+10+8+1.1 = 47.4 ......(500个学生)
你的任务:只通过这些数据,反推出我的秘密规则(即找出 w₁=8.1, w₂=2, w₃=2, w₄=4, b=1.1)
你只是假装不知道w,b 我们通过深度学习的方式得到w b
深度学习就像一个超级侦探,通过不断试错来找出真相:
侦探的推理过程
第1次猜测:成绩 = 0.01×学习时间 + 0.01×作业完成度 + ... # 完全不对,损失200+
通过猜测参数来跟真相对比发现有很大的差异就继续猜测
第2次猜测:稍微调整一下参数 # 损失180+
...
第50次猜测:成绩 = 8.09×学习时间 + 2.01×作业完成度 + ... # 接近真相,损失0.5
二.代码实现
这个是深度学习的基本流程
数据准备 → 模型定义 → 损失函数 → 优化器 → 训练循环 → 评估可视化
接下来,使用代码带大家一步一步实现这个功能
首先引入我们需要的库
import torch #PyTorch的核心,提供张量计算和自动求导
import matplotlib.pyplot as plt #画图工具,帮我们把数据可视化
import random #随机然后我们需要生成一些模拟的数据,作为我们已知的数据(500个学生)
#我们先写一个函数来生成随机数据 这个函数需要接收
def create_data(w, b, data_num):
# 从正态分布中随机取数 均值=0,标准差=1 我们后面会给出data_num=500。
# 然后w我们看到前面的[8.1, 2, 2, 4] 说明w=4。
# 所以我们可以以生成500x4的输入数据,就像随机生成500个学生的4项指标
x = torch.normal(0, 1, (data_num, len(w)))
# 接下来我们根据真实规律计算y 其实就是y=w1*x1+...+w4*x4+b
# 相当于按照真实评分标准计算每个学生的成绩。
y = torch.matmul(x, w) + b
# 添加噪声,模拟真实数据。生成和y形状相同的随机数
# 均值=0(平均不偏大也不偏小)标准差=0.01(波动范围很小)形状和y一样(500个数字)
# 因为真实世界中总有各种随机因素,所以我们需要增加一个噪声。
noise = torch.normal(0, 0.01, y.shape)
y += noise #把噪声加到y上
return x, y 接下来我们用几个变量来存储真实的正确值,这样我们后面才方便用训练的值与真实值进行比较。
num = 500 #500个数据
true_w = torch.tensor([8.1,2,2,4]) #真实的w
true_b = torch.tensor(1.1) #真实的b这里我们先看一下我们模拟的数据长什么样子
X, Y = create_data(true_w, true_b, num) #用X表示w 用Y表示b
plt.scatter(X[:, 3], Y, 1) # 只看第4个特征(索引3)和Y的关系 用散点图来看
plt.title('这是我画的散点图')
plt.show()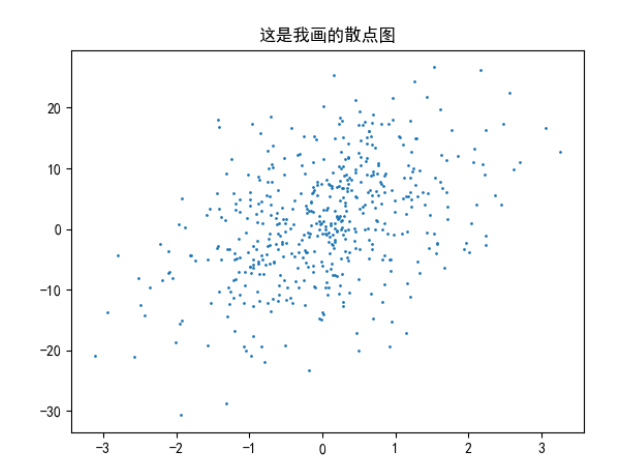
有时候我们进行深度学习的时候数据量很大,不方便一次处理完。比如有500个数据,我们可以16个为一组,一组一组的提供数据。那我们可以写一个函数来分批提供数据。
def data_provider(data, label, batchsize): #每次访问这个函数, 就能提供一批数据
length = len(label)
indices = list(range(length)) #创建 [0,1,2,3,...,499] 的列表
#我不能按顺序取 把数据打乱 例子:打乱成 [345, 12, 478, 3, ...]
random.shuffle(indices)
#打乱后可以1.防止模型学到数据中的顺序规律2.让每个批次的数据分布更均匀3.提高模型的泛化能力
#用循环来分批取数据
for each in range(0, length, batchsize):
get_indices = indices[each: each+batchsize]
get_data = data[get_indices]
get_label = label[get_indices]
yield get_data,get_label #有存档点的return
batchsize = 16 #用来表示一组有多少个yield 和 return 的区别:
-
return:一次返回所有东西,函数结束 -
yield:返回一点东西,暂停,下次调用时继续
现在准备工作都准备好了,我们进入核心部分,进行线性回归:
#我们使用这个函数计算,用之前得到的数据通过题目给的公式进行计算后
#对应的公式 pred_y = x₁×w₁ + x₂×w₂ + x₃×w₃ + x₄×w₄ + b
#得到预测值y
def fun(x, w, b):
pred_y = torch.matmul(x, w) + b
return pred_y我们得到训练的值y后,如何知道这个值的质量好坏呢? 我们可以写一个损失函数用于衡量预测好坏。
#预测值y与真的y相减后取绝对值,然后相加起来处于y的个数得到平均绝对误差。
def maeLoss(pre_y, y):
return torch.sum(abs(pre_y - y)) / len(y) # 平均绝对误差如果得到损失(平均绝对误差)越小,预测越准。
mae只是损失函数中的一种。它的特点如下:
-
简单直观:平均每个样本差多少
-
对异常值不敏感
当我们发现误差很大的时候,我们应该想办法来优化我们的参数。
我们可以使用优化器:sgd 代表 Stochastic Gradient Descent(随机梯度下降),它的作用是更新参数,让模型越学越好。
#paras:要更新的参数列表,比如 [w_0, b_0]
#lr:学习率(learning rate),控制每次更新的步长
def sgd(paras, lr): #随机梯度下降,更新参数
#关闭梯度追踪 目的:更新参数时,这个操作本身不应该被记录到计算图中。我们只想更新参数值,不想计算这次更新的梯度
with torch.no_grad():
#遍历每个需要更新的参数(w 和 b)
for para in paras:
#新参数 = 旧参数 - 梯度 × 学习率
#为什么是减号? 梯度指向损失增加最快的方向 我们要往相反方向走(减小损失)
para -= para.grad * lr #不能写成 para = para - para.grad*lr
para.grad.zero_() #使用过的梯度,归0 因为梯度是累加的!如果不清零,下一次计算梯度时会和上一次的叠加 我们希望每次计算的是当前批次的梯度
接下来进行初始化
lr = 0.01
w_0 = torch.normal(0, 0.01, true_w.shape, requires_grad=True) # 随机初始化
# 参数详解:
# - mean=0 : 均值0
# - std=0.01 : 标准差0.01(很小的范围)
# - shape=true_w.shape : 和真实w形状一样,这里是(4,)
# - requires_grad=True : 需要计算梯度
b_0 = torch.tensor(0.01, requires_grad=True)
print(w_0, b_0) # 打印出来看看,都是接近0的小随机数然后我们使用循环不断的训练数据
epochs = 50 # 训练50轮
for epoch in range(epochs): # 外层循环:遍历整个数据集50遍
data_loss = 0 # 每轮开始,重置损失累计
for batch_x, batch_y in data_provider(X, Y, batchsize): # 内层循环:一批批取数据
# 训练四步曲
pred_y = fun(batch_x, w_0, b_0) # 1. 前向传播:预测
loss = maeLoss(pred_y, batch_y) # 2. 计算损失:看差多少
loss.backward() # 3. 反向传播:算梯度
sgd([w_0, b_0], lr) # 4. 更新参数:调整
data_loss += loss # 累计这一批的损失
print("epoch %03d: loss: %.6f" % (epoch, data_loss)) # 打印这一轮的进度# 你看到的输出:
epoch 000: loss: 223.882538 # 第1遍:损失很大,完全没学会
epoch 001: loss: 205.934250 # 第2遍:损失下降
epoch 002: loss: 187.519699 # 第3遍:继续下降
...
epoch 012: loss: 10.543273 # 第13遍:已经很小了
epoch 013: loss: 0.554712 # 第14遍:达到最低点!
epoch 014: loss: 0.460499 # 之后在小范围波动
...
epoch 049: loss: 0.492682 # 最终稳定在0.5左右接下来可以将预测值和真实值进行对比了。
print("真实的函数值是", true_w, true_b)
print("训练得到的参数值是", w_0, b_0)看到 w_0 接近 [8.1,2,2,4],b_0 接近 1.1,说明学习成功了!
此外,还可以进行可视化,画出拟合效果
idx = 3 # 只看第4个特征
# 画拟合直线
plt.plot(X[:, idx].detach().numpy(),
X[:, idx].detach().numpy()*w_0[idx].detach().numpy()+b_0.detach().numpy())
# 画原始数据点
plt.scatter(X[:, idx], Y, 1)
plt.show()调参建议:我们可以通过修改学习率或者修改batchsize来观察不同学习率和batchsize的效果有什么区别。
#试试不同的学习率 lr = 0.01 lr = 0.03
这样可以明显感觉到不同参数的区别。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)