搞定小目标检测!SAHI+YOLO实战指南,推理 + 微调一步到位【附源码】
《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
一、引言
在目标检测领域,Ultralytics等库的出现让深度学习门槛大幅降低。哪怕是不懂计算机视觉的新手,只需从Kaggle获取数据集、搭建GPU环境,用不到50行代码训练4-5小时,就能得到一个可用的YOLO模型,轻松检测汽车、行人等常见目标。
但面对小目标检测,这套流程就显得力不从心了。诸如远距离行人、空中飞鸟、微小昆虫这类目标,即便用肉眼都难精准识别,更别说让模型捕捉。核心问题在于:为了控制训练时间和避免显存溢出,模型训练时通常会将图像缩放到640×640等低分辨率,本就微小的目标会进一步缩小甚至消失,导致检测精度断崖式下降。
而SAHI(Slicing Aided Hyper Inference)的出现,正是为了解决这一痛点。它无需修改模型架构,通过巧妙的图像切片策略,就能让各类目标检测模型的小目标识别能力大幅提升。
二、SAHI核心原理:切片赋能小目标检测
SAHI的核心思路简单却高效:将高分辨率图像切割成多个小补丁(Patch),对每个补丁单独处理后再融合结果,从根本上解决小目标因图像缩放而“隐身”的问题。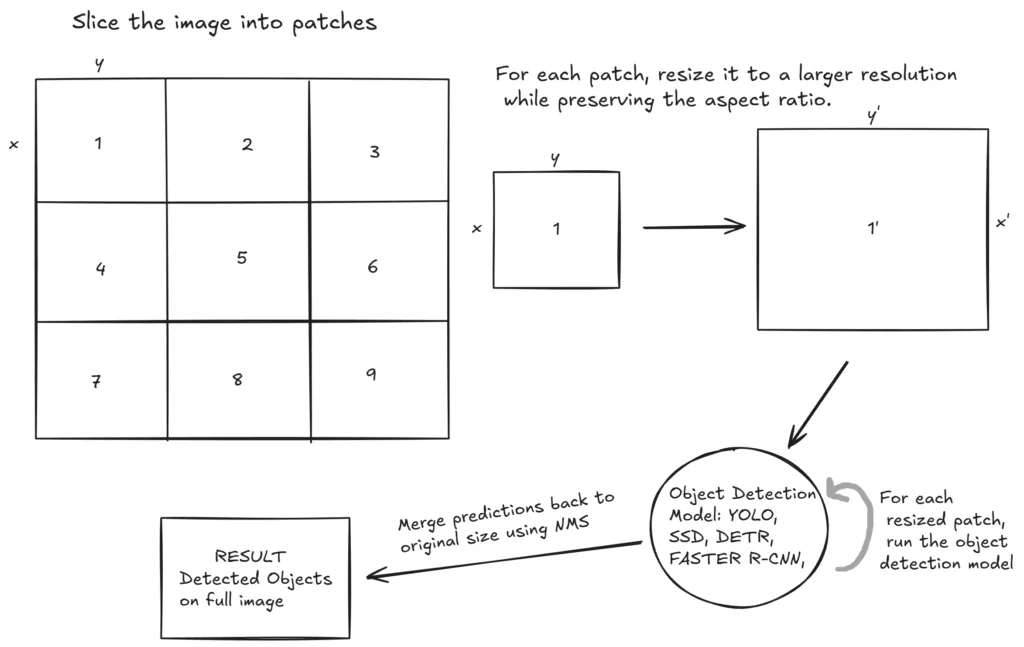
1. 为何切片策略如此有效?
- 无需缩放整张图像:将原图切割为小补丁后,可将每个补丁放大到模型适配的高分辨率,小目标随之“变大”,特征更易被捕捉;
- 兼容所有检测模型:不改变模型结构,可与YOLO、Faster R-CNN、SSD、DETR等任意目标检测模型搭配使用;
- 解决跨补丁目标漏检:相邻补丁设置25%(可自定义)的重叠区域,避免目标被切割后漏检,最后通过非极大值抑制(NMS)去除重复检测结果。

2. 两种核心应用方案
SAHI提供两种关键技术路径,覆盖推理和训练全流程:
-
切片辅助推理(Slicing Aided Inference):推理阶段对输入图像切片,放大后分别检测,再融合结果,快速提升现有模型的小目标检测能力;
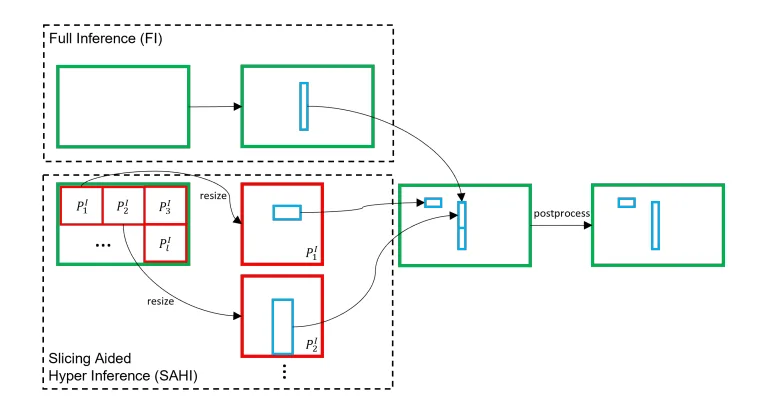
-
切片辅助微调(Slicing Aided Fine-tuning):训练前对数据集切片并放大,用这些包含清晰小目标的补丁训练模型,从根源上提升模型对小目标的识别能力。
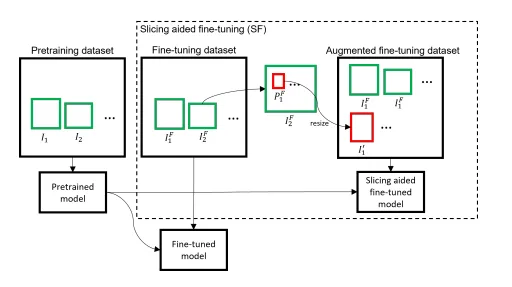
三、实战教程:SAHI+YOLO实现小目标检测
1. 环境准备与安装
首先搭建支持GPU的PyTorch环境(确保训练和推理效率),再安装核心库:
# 基础安装
pip install sahi
# 安装PyTorch(根据CUDA版本选择,示例为CUDA 12.1)
pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu121
# 安装目标检测框架(以Ultralytics为例)
pip install ultralytics>=8.3.161
2. 切片辅助推理:快速提升检测效果
无需重新训练,直接用预训练YOLO模型结合SAHI切片推理,即可增强小目标检测能力。
核心步骤:
- 加载YOLO模型(支持预训练模型或自定义模型);
- 配置切片参数(补丁尺寸、重叠比例等);
- 执行切片推理并可视化结果。
完整代码:
from sahi.models.ultralytics import UltralyticsDetectionModel
from sahi.predict import get_sliced_prediction
# 1. 加载YOLO模型(可替换为自定义模型路径)
detection_model = UltralyticsDetectionModel(
model_path="yolov8n.pt", # 预训练模型,替换为自己的模型路径
confidence_threshold=0.3, # 置信度阈值
device="cuda" # 无GPU时改为"cpu"
)
# 2. 执行切片推理
result = get_sliced_prediction(
r"images/cars.jpg", # 测试图像路径
detection_model,
slice_height=256, # 补丁高度
slice_width=256, # 补丁宽度
overlap_height_ratio=0.2, # 垂直重叠比例(20%)
overlap_width_ratio=0.2 # 水平重叠比例(20%)
)
# 3. 结果可视化与保存
# 方式1:手动提取边界框、标签和置信度
for pred in result.object_prediction_list:
bbox = pred.bbox.to_xyxy() # 边界框坐标(x1,y1,x2,y2)
x1, y1, x2, y2 = map(int, bbox)
label = pred.category.name # 目标类别
score = pred.score.value # 置信度
# 方式2:直接导出可视化结果
result.export_visuals(export_dir="runs/predictions/") # 结果保存路径
YOLO检测结果:
YOLO+SAHI检测结果:
额外工具:可视化切片过程
若想直观查看图像如何被切割,可使用slice_image函数保存所有补丁:
from sahi.slicing import slice_image
# 切片并保存补丁
slice_image_result = slice_image(
image="test_image.jpg", # 原始图像路径
output_file_name="slice",
output_dir="runs/sliced_images/", # 补丁保存目录
slice_height=256,
slice_width=256,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2,
)
# 打印切片信息
print(f"原始图像尺寸:{slice_image_result.original_image_height}x{slice_image_result.original_image_width}(高x宽)")
print(f"补丁尺寸:{256}x{256}像素")
print(f"生成补丁总数:{len(slice_image_result.images)}")
print(f"补丁保存路径:{slice_image_result.image_dir}")
输出图片示例:
3. 切片辅助微调:训练更鲁棒的小目标检测模型
若有高分辨率数据集(如1920×1080、2160×1440),通过切片辅助微调可让模型从根源上适应小目标检测。以下以VisDrone19-Detection数据集(无人机拍摄的高分辨率图像)为例。
核心流程:
数据集切片(COCO格式)→ 转换为YOLO格式 → 模型训练 → 测试评估
步骤1:数据集切片(COCO格式)
使用slice_coco函数切割COCO格式数据集,生成包含小目标的补丁数据集:
from sahi.slicing import slice_coco
# 配置路径(根据实际情况修改)
coco_annotation_path = "path/to/coco_annotations.json" # 原始COCO标注文件
IMAGE_DIR = "path/to/images/" # 原始图像目录
SLICED_OUTPUT_DIR = "path/to/sliced_dataset/" # 切片后数据集保存目录
# 执行切片
coco_dict, coco_path = slice_coco(
coco_annotation_file_path=coco_annotation_path,
image_dir=IMAGE_DIR,
output_coco_annotation_file_name="visdrone_train_sliced.json", # 切片后标注文件
output_dir=SLICED_OUTPUT_DIR,
ignore_negative_samples=False, # 保留无标注图像
slice_height=640, # 补丁尺寸(适配YOLO训练)
slice_width=640,
overlap_height_ratio=0.2, # 20%重叠
overlap_width_ratio=0.2,
min_area_ratio=0.1, # 忽略小于补丁面积10%的目标
verbose=True
)
切割后的图片示例:
步骤2:转换为YOLO格式
YOLO训练需特定格式数据集,结构如下:
dataset/
├── train/
│ ├── images/ # 训练图像(切片后的补丁)
│ └── labels/ # 训练标注
└── valid/
├── images/ # 验证图像
└── labels/ # 验证标注
可通过工具将COCO格式转换为YOLO格式(具体转换代码可参考开源工具,此处略)。
步骤3:创建数据集配置文件(YAML)
新建dataset.yaml文件,填写数据集信息:
# 数据集配置文件
path: path/to/dataset # 数据集根目录
train: train/images # 训练图像路径
val: valid/images # 验证图像路径
# 类别名称(根据实际数据集修改)
names:
0: pedestrian
1: car
2: bicycle
...
步骤4:启动模型训练
使用YOLO11预训练模型,在切片后的数据集上微调:
from ultralytics import YOLO
# 加载预训练模型(可替换为其他YOLO模型)
model = YOLO('yolo11n.pt')
# 开始训练
results = model.train(
data="dataset.yaml", # 配置文件路径
epochs=50, # 训练轮次
imgsz=640, # 输入图像尺寸
batch=16, # 批次大小(根据GPU显存调整)
name='yolo11_visdrone_sliced', # 训练结果文件夹名称
project='runs/train', # 结果保存根目录
device='cuda', # 无GPU时改为"cpu"
patience=10, # 早停耐心值
save=True, # 保存最佳模型
plots=True, # 生成训练可视化图表
verbose=True # 显示训练详情
)
步骤5:用微调后的模型推理
# 加载微调后的最佳模型
best_model_path = "runs/train/yolo11_visdrone_sliced/weights/best.pt"
# 初始化SAHI检测模型
detection_model = AutoDetectionModel.from_pretrained(
model_type='ultralytics',
model_path=best_model_path,
confidence_threshold=0.3,
device="cuda"
)
# 执行切片推理
result = get_sliced_prediction(
"test_image.jpg", # 测试图像
detection_model,
slice_height=640,
slice_width=640,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2
)
# 保存结果
result.export_visuals(export_dir="runs/predictions/")

四、注意事项
- 数据集要求:切片辅助微调仅适用于高分辨率图像(如1920×1080及以上),低分辨率图像(如640×640)切片无意义;
- 参数调整:补丁尺寸、重叠比例需根据目标大小调整——小目标可减小补丁尺寸、提高重叠比例;
- 硬件适配:切片后数据集规模会大幅扩大(如772张原图可生成9300张补丁),建议使用GPU训练,避免显存溢出可降低批次大小;
- 格式兼容:SAHI原生支持COCO格式,其他格式(如YOLO)需先转换为COCO再切片。
通过SAHI的切片策略,无需复杂修改模型,就能让常规目标检测模型轻松应对小目标检测场景。无论是快速提升现有模型的推理效果,还是训练专用小目标检测模型,SAHI都能提供简洁高效的解决方案。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 15
15 0
0- 0



 已为社区贡献210条内容
已为社区贡献210条内容

所有评论(0)