深度学习入门:【基本概念】
目录
用数据训练(train)模型:“输入的是垃圾,输出的也是垃圾。”
一.基本中的基本
1.参数:参数可以被看作旋钮,旋钮的转动可以调整程序的行为。
2.模型:任一调整参数后的程序被称为模型(model)。
3.模型族:通过操作参数而生成的所有不同程序(输入-输出映射)的集合称为“模型族”。
4.学习算法:使用数据集来选择参数的元程序被称为学习算法(learning algorithm)。
5.机器学习中关键组件:可以用来学习的数据(data);如何转换数据的模型(model);一个目标函数(objective function),用来量化模型的有效性;调整模型参数以优化目标函数的算法(algorithm)。
(1)数据集
每个数据集由一个个样本(example, sample)组成,大多时候,它们遵循独立同分布(independently and identically distributed, i.i.d.)。 每个样本由一组称为特征(features,或协变量(covariates))的属性组成。当每个样本的特征类别数量都是相同的时候,其特征向量是固定长度的,这个长度被称为数据的维数(dimensionality)。 固定长度的特征向量是一个方便的属性,它可以用来量化学习大量样本。
例如,当处理图像数据时,每一张单独的照片即为一个样本,它的特征由每个像素数值的有序列表表示。 比如,彩色照片由个数值组成,其中的“3”对应于每个空间位置的红、绿、蓝通道的强度。 再比如,对于一组医疗数据,给定一组标准的特征(如年龄、生命体征和诊断),此数据可以用来尝试预测患者是否会存活。
然而,并不是所有的数据都可以用“固定长度”的向量表示。 以图像数据为例,如果它们全部来自标准显微镜设备,那么“固定长度”是可取的; 但是如果图像数据来自互联网,它们很难具有相同的分辨率或形状。 这时,将图像裁剪成标准尺寸是一种方法,但这种办法很局限,有丢失信息的风险。 此外,文本数据更不符合“固定长度”的要求。 比如,对于亚马逊等电子商务网站上的客户评论,有些文本数据很简短(比如“好极了”),有些则长篇大论。 与传统机器学习方法相比,深度学习的一个主要优势是可以处理不同长度的数据。
(2)模型
深度学习与经典方法的区别主要在于:前者关注的功能强大的模型,这些模型由神经网络错综复杂的交织在一起,包含层层数据转换,因此被称为深度学习(deep learning)。
(3)目标函数
定义模型的优劣程度的度量,这个度量在大多数情况是“可优化”的,这被称之为目标函数(objective function)。有时被称为损失函数(loss function,或cost function)。 当任务在试图预测数值时,最常见的损失函数是平方误差(squared error),即预测值与实际值之差的平方。 当试图解决分类问题时,最常见的目标函数是最小化错误率,即预测与实际情况不符的样本比例。 有些目标函数(如平方误差)很容易被优化,有些目标(如错误率)由于不可微性或其他复杂性难以直接优化。 在这些情况下,通常会优化替代目标。
通常,损失函数是根据模型参数定义的,并取决于数据集。 在一个数据集上,我们可以通过最小化总损失来学习模型参数的最佳值。 可用数据集通常可以分成两部分:训练数据集(training set)用于拟合模型参数,测试数据集(test set)用于评估拟合的模型。 观察模型在这两部分数据集的性能。
“一个模型在训练数据集上的性能”可以被想象成“一个学生在模拟考试中的分数”。 这个分数用来为一些真正的期末考试做参考,即使成绩令人鼓舞,也不能保证期末考试成功。 换言之,测试性能可能会显著偏离训练性能。 当一个模型在训练集上表现良好,但不能推广到测试集时,这个模型被称为过拟合(overfitting)的。 就像在现实生活中,尽管模拟考试考得很好,真正的考试不一定百发百中。(4)优化算法
当我们获得了一些数据源及其表示、一个模型和一个合适的损失函数,接下来就需要一种算法,它能够搜索出最佳参数,以最小化损失函数。 深度学习中,大多流行的优化算法通常基于一种基本方法–梯度下降(gradient descent)。 简而言之,在每个步骤中,梯度下降法都会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数。
用数据训练(train)模型:“输入的是垃圾,输出的也是垃圾。”
(“Garbage in, garbage out.”)
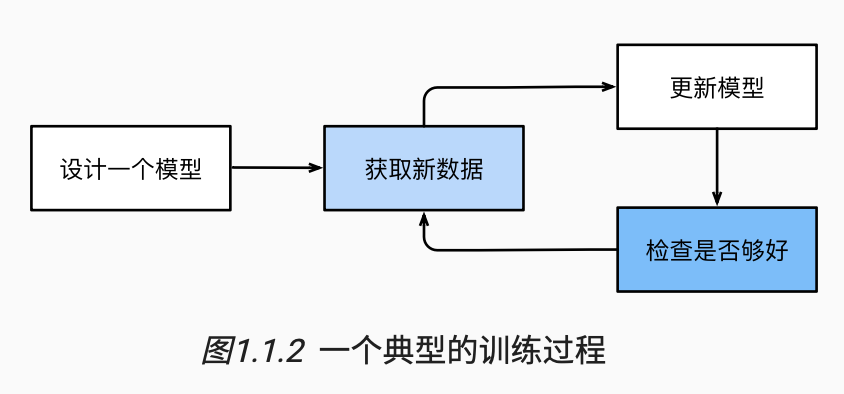
在机器学习中,学习(learning)是一个训练模型的过程。 通过这个过程,我们可以发现正确的参数集,从而使模型强制执行所需的行为。 如图1.1.2所示,训练过程通常包含如下步骤:
-
(1)从一个随机初始化参数的模型开始,这个模型基本没有“智能”;
-
(2)获取一些数据样本(例如,音频片段以及对应的是或否标签);
-
(3)调整参数,使模型在这些样本中表现得更好;
-
(4)重复第(2)步和第(3)步,直到模型在任务中的表现令人满意。
-
二.计算基础
1. 张量
具有一个轴的张量对应数学上的向量(vector);具有两个轴的张量对应数学上的矩阵(matrix);具有两个轴以上的张量没有特殊的数学名称。

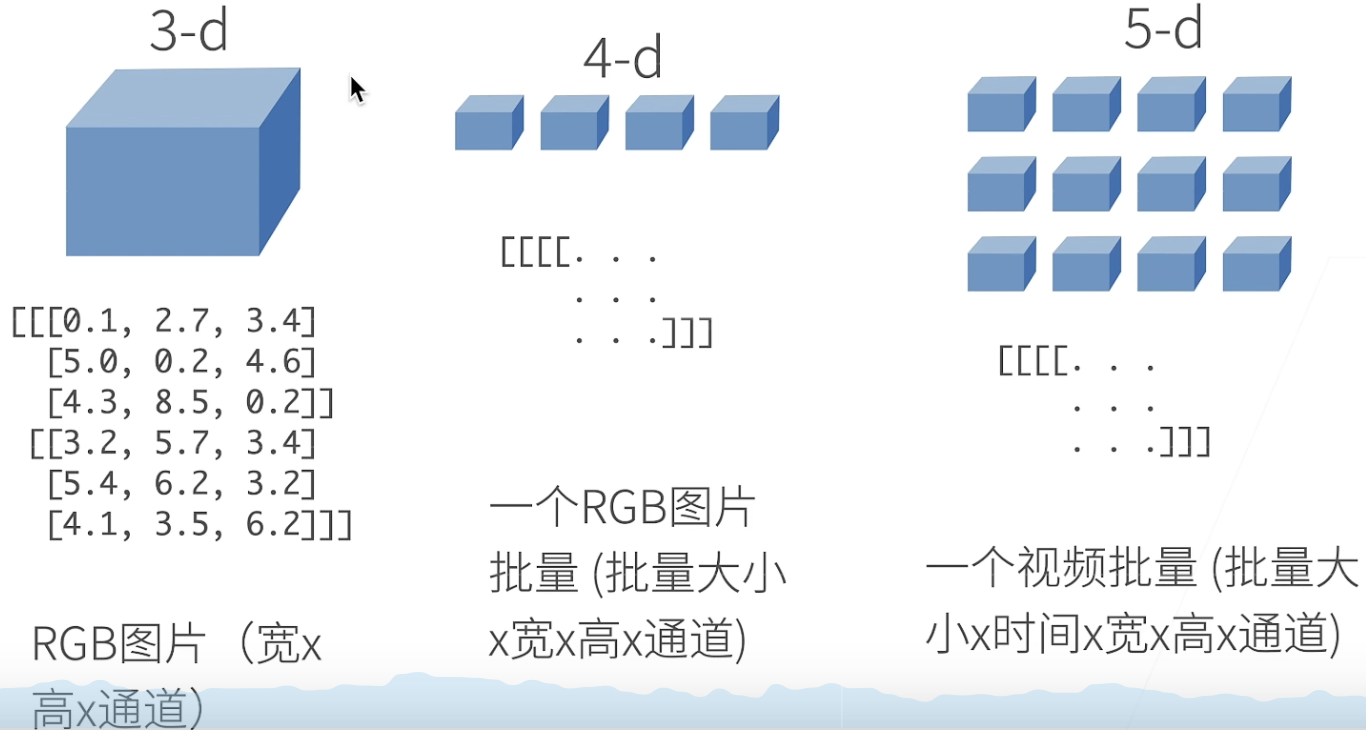
张量,n维数组,tensor,原是数学上的概念,但深度学习中只是用矩阵,并未用到数学中的张量,只是说张量顺口一些。主要是掌握对张量的各种运算、reshape。
广播机制:在某些情况下,[**即使形状不同,我们仍然可以通过调用广播机制(broadcasting mechanism)来执行按元素操作**]。这种机制的工作方式如下:
(1)通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状;
(2)对生成的数组执行按元素操作。
在大多数情况下,我们将沿着数组中长度为1的轴进行广播,如下例子:
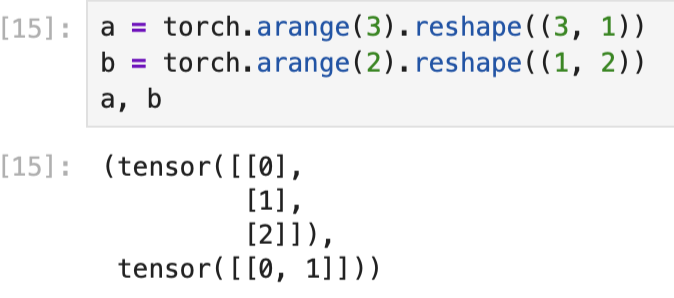

由于a和b分别是和矩阵,如果让它们相加,它们的形状不匹配。 我们将两个矩阵广播为一个更大的矩阵3X2,如上所示:矩阵a将复制列, 矩阵b将复制行,然后再按元素相加。
dim=0 (按行拼接),dim=1 (按列拼接)。
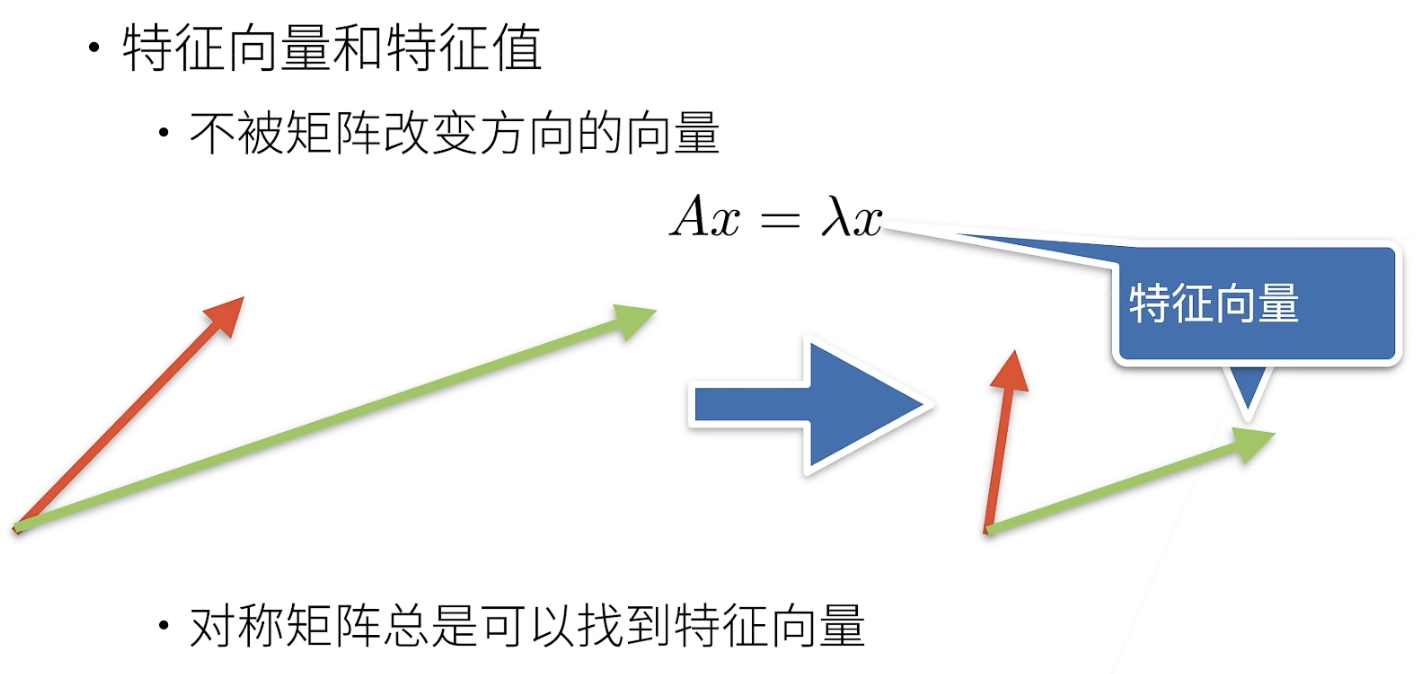
矩阵是对空间的扭曲和改变。特征向量不会随矩阵改变而改变。
2. 数据预处理
机器学习就是处理缺失的数据,包括未来的数据。常见方法是丢弃或插值。
3.线性代数(略)
4.降维、降维求和、非降维求和
维度(dimension)这个词在不同上下文时往往会有不同的含义,这经常会使人感到困惑。 为了清楚起见,我们在此明确一下: 向量或轴的维度被用来表示向量或轴的长度,即向量或轴的元素数量。 然而,张量的维度用来表示张量具有的轴数。 在这个意义上,张量的某个轴的维数就是这个轴的长度。
- torch 一维一定是一个行向量,向量是一个一维数组,没有行、列之分。矩阵中才区分行向量和列向量。
默认情况下,调用求和函数x.sum()会沿所有的轴降低张量的维度,使它变为一个标量。还可以[指定张量沿哪一个轴来通过求和降低维度],以矩阵为例,为了通过求和所有行的元素来降维(轴0),可以在调用函数时指定axis=0。 由于输入矩阵沿0轴降维以生成输出向量,因此输入轴0的维数在输出形状中消失。
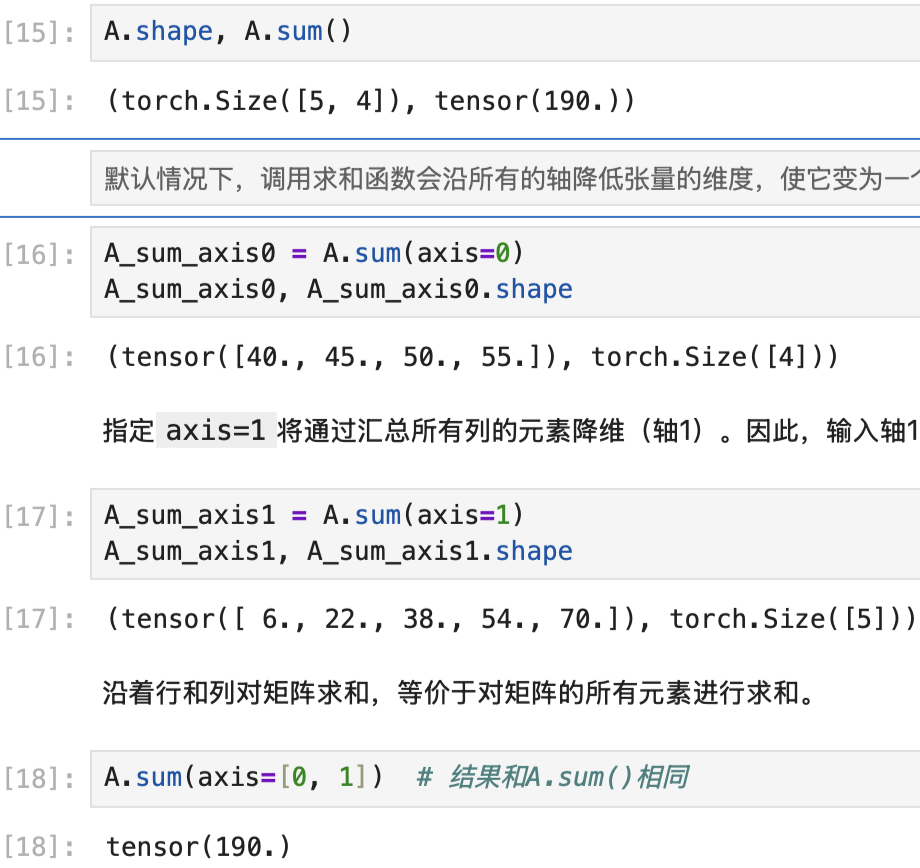
但是,有时在调用函数来[计算总和或均值时保持轴数不变]会很有用。A.sum(axis=1, keepdims=True),keepdims=True对于应用广播机制很有用。
如果我们想沿[某个轴计算A元素的累积总和], 比如axis=0(按行计算),可以调用cumsum函数。 此函数不会沿任何轴降低输入张量的维度。
10.F范数(norm)
相当于把矩阵拉长。矩阵的Frobenius范数是每个矩阵元素平方和的平方根。
对机器学习来说,稀疏的矩阵不会影响太多。
5.矩阵计算(梯度、微分、自动微分)
微分(differential calculus)被发明出来。 在微分学最重要的应用是优化问题,即考虑如何把事情做到最好。 正如在 :numref:subsec_norms_and_objectives中讨论的那样, 这种问题在深度学习中是无处不在的。
在深度学习中,我们“训练”模型,不断更新它们,使它们在看到越来越多的数据时变得越来越好。 通常情况下,变得更好意味着最小化一个损失函数(loss function), 即一个衡量“模型有多糟糕”这个问题的分数。 最终,我们真正关心的是生成一个模型,它能够在从未见过的数据上表现良好。 但“训练”模型只能将模型与我们实际能看到的数据相拟合。 因此,我们可以将拟合模型的任务分解为两个关键问题:
- 优化(optimization):用模型拟合观测数据的过程;
- 泛化(generalization):数学原理和实践者的智慧,能够指导我们生成出有效性超出用于训练的数据集本身的模型。


要把形状搞对,如下图(分子布局图),当y是标量、向量和x是标量、向量的结果是标量、向量、还是矩阵。
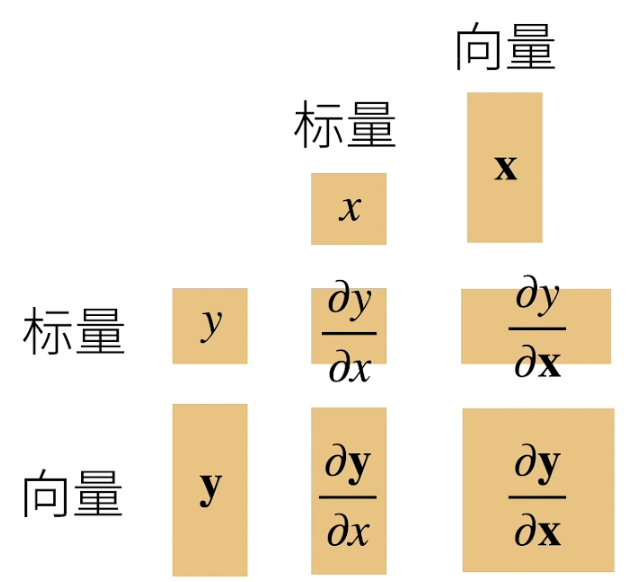
y为标量时:
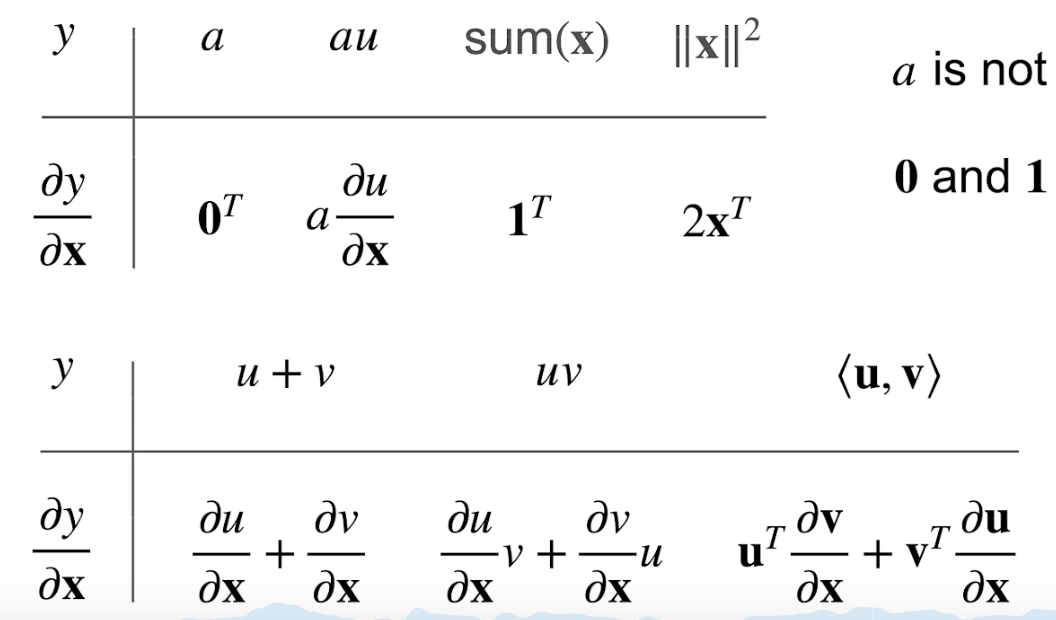
y为向量时:

将导数拓展到向量,就是梯度。 梯度是指导致中最大变化的那个向量, 通常是往最大的走,这是所有机器学习求解的核心思想。
- 梯度是一个向量,其分量是多变量函数相对于其所有变量的偏导数。
- 机器学习关心NP问题,不关心P问题,也就是说机器学习不关注最优解问题。 凸函数理论上有最优解,但实际计算不一定有。
6.自动微分
对于复杂的模型,手工进行更新是一件很痛苦的事情(而且经常容易出错)。深度学习框架通过自动计算导数,即自动微分(automatic differentiation)来加快求导。 实际中,根据设计好的模型,系统会构建一个计算图(computational graph), 来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 自动微分使系统能够随后反向传播梯度。 这里,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。
注意,一个标量函数关于向量的梯度是向量,并且与
具有相同的形状。
- (课程练习)在运行反向传播函数之后,立即再次运行它,看看会发生什么。
# 第一次反向传播
y.backward(retain_graph=True) # 保留计算图
print("第一次backward后的x.grad:", x.grad)
# 第二次反向传播(梯度会累积)
y.backward(retain_graph=True)
print("第二次backward后的x.grad:", x.grad)
print("注意:梯度被累积了!")7.分离计算
深度学习中很少对向量求导,通常是对标量求导。一般做法是先求和再求导,这样是一个标量。
8.Python控制流的梯度计算
- (课程练习)在控制流的例子中,我们计算
d关于a的导数,如果将变量a更改为随机向量或矩阵,会发生什么?
#对python控制流求导
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
# 验证梯度计算的正确性
print("a.grad == d / a:",a.grad == d / a)
a.grad.zero_()
#在控制流的例子中,我们计算d关于a的导数,如果将变量a更改为随机向量或矩阵,会发生什么?
# 现在计算d关于a的梯度
a = torch.randn(size=(3,4), requires_grad=True)
d = f(a)
d.sum().backward()
# 验证梯度计算的正确性
print("a.grad == d / a:",a.grad == d / a)![]()
#使用f(x)=sin(x),绘制f(x)和f'(x)的图像,其中f'(x)不使用cos(x)
x = torch.arange(0, 2*math.pi, 0.1, requires_grad=True)
y = torch.sin(x)
y.backward(torch.ones_like(x), retain_graph=True)
y_grad = x.grad
print(f"{Fore.YELLOW}y_grad:{y_grad}{Style.RESET_ALL}")
print(f"{Fore.YELLOW}y_grad == cos(x):{y_grad == torch.cos(x)}{Style.RESET_ALL}")
plt.plot(x.detach().numpy(), y.detach().numpy(), label='f(x) = sin(x)')
plt.plot(x.detach().numpy(), y_grad.detach().numpy(), label="f'(x)'")
plt.legend()
plt.show()9.概率
在统计学中,我们把从概率分布中抽取样本的过程称为抽样(sampling)。笼统来说,可以把分布(distribution)看作对事件的概率分配。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)