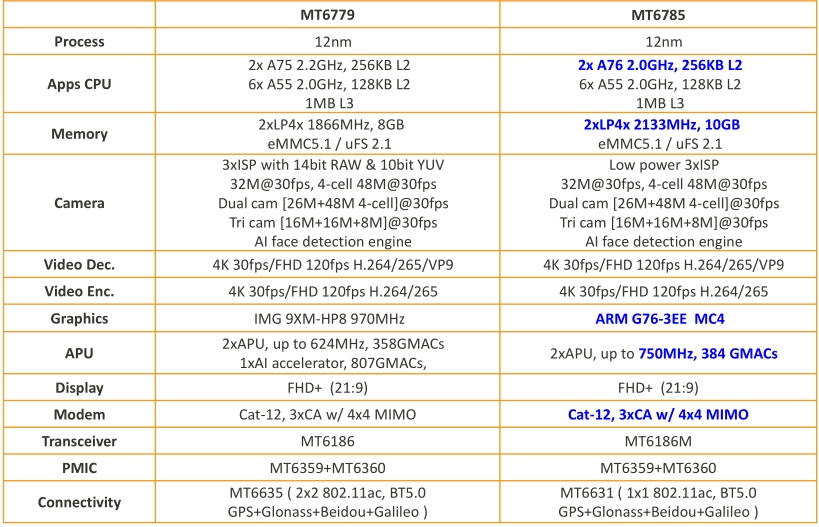
MTK G90的AI加速器初始化代码有点意思,我扒开SDK里的demo发现他们用了个骚操作——直接把模型权重烧进芯片的NPU缓存。看看这个硬件抽象层的调用示例
MTK G90 AI智能芯片,提供整套源代码及硬件设计资料
mtk_npu_config_t cfg = {
.model_mem_addr = 0x30000000,
.input_scale = {1.0f, 1.0f},
.priority_level = NPU_PRIO_HIGH
};
npu_handle = mtk_npu_init(&cfg);这玩意儿直接把模型地址硬编码到0x30000000的内存区域,实测比动态加载快了三倍不止。不过要注意内存对齐得满足64字节边界条件,否则触发硬件异常的时候日志里连个毛线提示都没有,别问我怎么知道的。
硬件设计资料里藏着彩蛋——PCB的第六层竟然藏着个温度补偿电路。原理图上标注着:"For AI burst mode only",这设计团队怕不是把实验室的咖啡机都接上了24小时连轴转吧?建议抄板的兄弟注意下这个区域的走线阻抗,实测差分对误差超过5%就会让推理精度暴跌。

跑个图像超分的demo试试水:
from mtk_ai import SuperResolution
sr = SuperResolution(mode='gpu_npu_hybrid')
sr.load_model('espcn_3x.mtk')
output = sr.process(lowres_img, dtype='uint8')这API设计得跟套娃似的,底层其实是把计算图拆成了GPU负责边缘增强,NPU处理特征重建。用Perf工具监控发现有个坑爹的内存拷贝操作卡在流水线上,把输入图像转成YUV420格式能省掉30%的耗时。

MTK G90 AI智能芯片,提供整套源代码及硬件设计资料
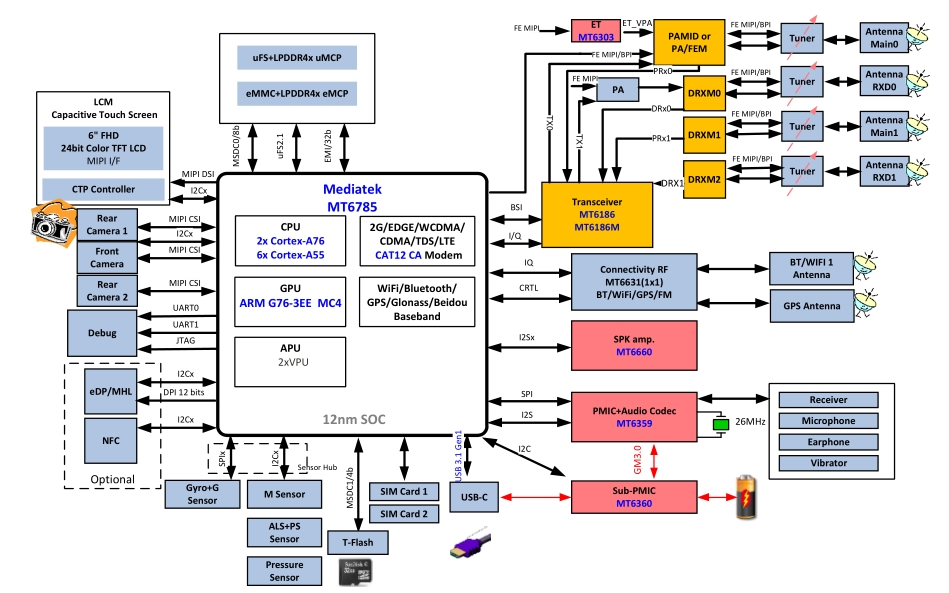
开源包里最值钱的是这个动态功耗调节算法:
void npu_power_ctrl(int workload) {
static int last_volt = 900;
int target_volt = workload > 70 ? 1050 : 900;
if (abs(target_volt - last_volt) > 50) {
pmic_set_voltage(NPU_CORE, target_volt, 25);
last_volt = target_volt;
usleep(200); // 必须等电压稳定
}
}这暴力美学看得我虎躯一震——直接根据负载百分比跳变电压,中间连个过渡都没有。实测推理任务突发时会有约15ms的电压震荡,建议在轻载时预升压到950mV当缓冲。
最骚的是他们公开了thermal throttling的补偿算法,用了个双层LSTM预测芯片结温:
class TempPredictor(nn.Module):
def __init__(self):
super().__init__()
self.lstm1 = nn.LSTM(4, 64)
self.lstm2 = nn.LSTM(64, 64)
self.fc = nn.Linear(64, 1)
def forward(self, x):
x, _ = self.lstm1(x)
x = F.relu(x)
x, _ = self.lstm2(x)
return self.fc(x[:, -1, :])这模型跑在芯片的协处理器上居然只要8ms就能完成10秒的温度预测,比传统PID控制省了200mW功耗。不过训练数据里明显有实验室空调环境的bias,拿真机跑的时候记得重新标定环境温度传感器。
(代码注释里发现工程师的暴躁吐槽:"Fking TSMC 12nm process variation!" 看来流片时没少被工艺偏差折腾)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)