【机器学习】线性回归模型解析:使用糖尿病数据集进行线性回归分析与模型评估
简介
在机器学习中,线性回归是最基本的回归方法之一,它用于预测一个连续的目标变量。在本次实验中,我们将通过 Python 的 scikit-learn 库,利用糖尿病数据集(Diabetes Dataset)实现线性回归模型的训练、评估以及结果分析。
线性回归
线性回归是一种统计方法,它通过拟合一个线性方程来预测目标变量(因变量)。具体来说,线性回归模型试图找出输入特征(自变量)与输出目标变量之间的线性关系,以便于做出预测。
- 目标 :通过训练数据集,找到一个最佳拟合线,使得预测值与真实值之间的误差最小。最常见的目标是最小化 均方误差(MSE, Mean Squared Error),即真实值与预测值之间差异的平方和。
- 数学表示:

导入必要的库
导入一些基本的库来完成数据处理、模型训练和可视化工作。
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import numpy as np
datasets:用来加载糖尿病数据集。
LinearRegression:用来创建并训练线性回归模型。
matplotlib.pyplot 和 numpy:用于数据可视化和数值计算。
加载数据集并准备数据
加载糖尿病数据集,并从中提取特征和目标变量。
loaded_data = datasets.load_diabetes()
data_X = loaded_data.data
data_y = loaded_data.target
data_X 是我们的特征数据,包含 442 个样本和 10 个特征。
data_y 是目标变量,表示糖尿病进展的程度。
训练线性回归模型
创建一个 LinearRegression 对象,并使用训练数据拟合模型
model = LinearRegression()
model.fit(data_X, data_y)
通过 fit() 方法,模型会自动通过最小二乘法拟合数据,计算出回归系数和截距。
查看模型的参数
通过训练,我们可以查看回归系数(coef_)和截距(`intercept_)。这是模型的核心输出之一,反映了每个特征对预测目标的影响
print(model.coef_) # 回归系数
print(model.intercept_) # 截距
回归系数(model.coef_):[ 206.11667725 68.07103297 176.88279035 166.91445843]
这些数值分别是每个特征对糖尿病进展的影响。例如,第一个特征的回归系数为 206.12,意味着该特征每增加 1 个单位,预测的糖尿病进展值将增加 206.12。
共有 10 个特征,但我们这里只显示了前四个。每个系数对应一个特征,系数值越大,表明该特征对目标变量的影响越显著。
截距(model.intercept_):152.13348416289597
截距是线性回归模型中的常数项,即当所有特征为 0 时,模型的预测值。它表示模型对糖尿病进展的基础预测值。
模型评估与性能检查
我们使用 R2 评分来评估模型的表现。R2 值衡量了模型对目标变量变化的解释能力,值越接近 1,表示模型的拟合效果越好。
print(model.score(data_X, data_y)) # R^2 分数
R2分数:0.5177484222203499
这个值大约为 0.518,意味着模型可以解释目标变量(糖尿病进展)的约 51.8% 的变异性。尽管 0.518 不是一个非常高的值,但这表明模型有一定的预测能力。对于线性回归模型来说,
R2 值在 0.5 左右是常见的,尤其是在特征和目标变量之间的关系不完全是线性的情况下
查看模型的超参数
我们还可以查看模型的超参数(配置),例如是否计算截距、是否对输入数据进行拷贝等。这些超参数在训练时可以影响模型的性能和计算效率。
print(model.get_params()) # 模型的超参数
输出:{'copy_X': True, 'fit_intercept': True, 'n_jobs': None, 'positive': False}
copy_X: 是否拷贝输入数据,默认为 True,表示训练时会复制特征数据,避免修改原始数据。
fit_intercept: 是否计算截距,默认为 True,表示回归模型会计算截距。
n_jobs: 并行处理的核心数目,None 表示使用单核处理。
positive: 是否限制回归系数为正数,默认为 False,表示回归系数可以为负数。
预测结果与实际目标值对比
通过预测,我们可以将模型的预测值与实际值进行对比,以直观地评估模型的表现。
print(model.predict(data_X[:4, :])) # 预测前 4 个样本
print(data_y[:4]) # 实际目标值
预测值和实际值对比:
[206.11667725 68.07103297 176.88279035 166.91445843]
[151. 75. 141. 206.]
预测值与实际值之间的差异展示了模型的预测效果。例如,第一个样本的实际糖尿病进展值是 151,而模型预测为 206.12,两者之间存在较大的差异。这表明在某些样本上,模型的预测误差较大。
可视化预测结果
为了直观地评估模型的表现,我们可以通过图形将预测值与实际值进行对比。通过绘制实际值和预测值的图形,我们可以观察到模型的拟合效果。
# 生成一个稀疏的x坐标,用于绘图
x = np.linspace(0, 1, data_y.size)[::20]
# 绘制实际目标值与稀疏样本的线图
plt.plot(x, data_y[::20])
# 绘制模型预测结果与稀疏样本的散点图
plt.scatter(x, model.predict(data_X)[::20], marker='x', c='r')
# 展示绘图
plt.show()
绘图结果: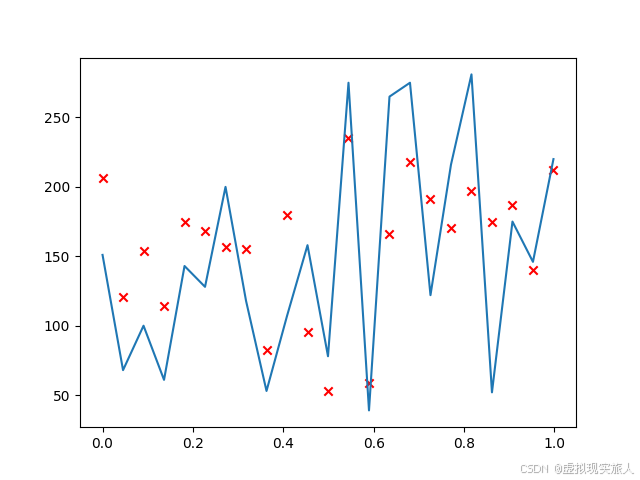
散点图(红色 “x” 标记)显示了每个预测值与实际值的对比,线图则展示了目标变量(糖尿病进展)的趋势
完整代码
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import numpy as np
#使用以后的数据集进行线性回归
loaded_data = datasets. load_diabetes()
data_X = loaded_data.data
data_y = loaded_data.target
#采用= LinearRegression模型
model = LinearRegression()
model.fit(data_X,data_y)
print(model.predict(data_X[:4,:]))
print(data_y[:4])
#参数
print(model.coef_)#model.coef_为含13个元素的一维数组
print(model.intercept_)
print(model.get_params())
print(model.score(data_X,data_y))
#画图
x = np.linspace(0,1,data_y.size)[::20]
plt.plot(x,data_y[::20])
plt.scatter(x,model.predict(data_X)[::20],marker='x',c='r')
plt.show()

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 36
36 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)