【耿直哥深度学习】11.5-注意力池化
·
Jupyter Notebook版本(带详细注释)
11.5-注意力池化
1. 注意力可视化
# 导入所需的核心库
import torch # PyTorch核心库,用于张量计算和深度学习基础操作
import matplotlib.pyplot as plt # 绘图库,用于注意力可视化和数据分布展示
from torch import nn # PyTorch神经网络模块,提供softmax等核心函数
from matplotlib import ticker # matplotlib刻度控制工具,用于设置热图刻度间隔
import warnings # 警告处理库
warnings.filterwarnings("ignore") # 忽略无关警告,避免输出干扰
# 定义注意力热图绘制函数
# 参数说明:
# axis: 可选参数,格式为[xticklabels, yticklabels],用于设置热图的xy轴标签
# attention: 二维张量,注意力权重矩阵(核心可视化对象)
def show_attention(axis, attention):
# 创建10x10尺寸的绘图窗口,保证热图显示清晰
fig = plt.figure(figsize=(10,10))
# 添加1行1列的子图(唯一子图)
ax=fig.add_subplot(111)
# 绘制矩阵热图:cmap='bone'是骨骼色映射,深色代表低权重,浅色代表高权重
cax=ax.matshow(attention, cmap='bone')
# 如果传入轴标签,则设置xy轴的刻度标签
if axis is not None:
ax.set_xticklabels(axis[0]) # 设置x轴刻度标签
ax.set_yticklabels(axis[1]) # 设置y轴刻度标签
# 设置x轴主刻度间隔为1,确保每个位置都有刻度
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
# 设置y轴主刻度间隔为1
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
# 显示绘制的热图
plt.show()
# 生成注意力可视化的样例数据
# 定义示例句子,用于作为注意力热图的轴标签
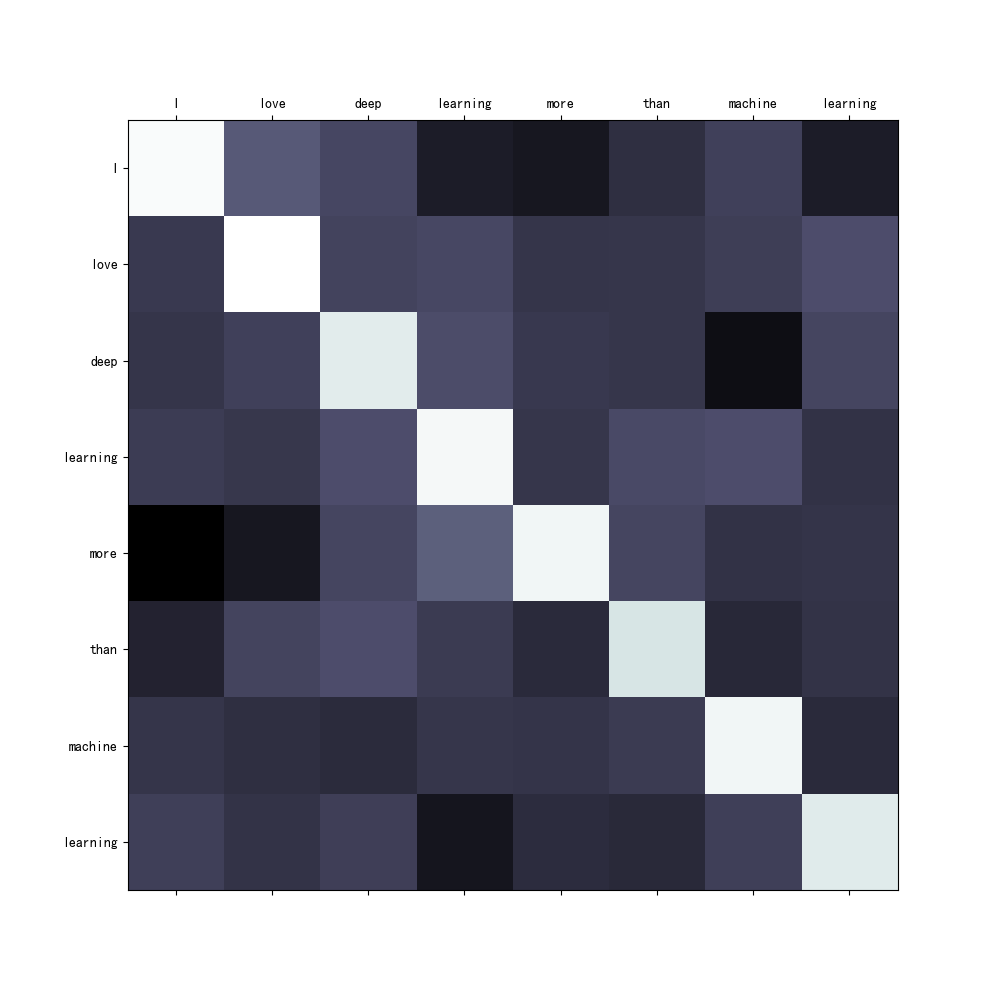
sentence = ' I love deep learning more than machine learning'
# 按空格分割句子为单词列表(tokens),作为热图的行列标签
tokens = sentence.split(' ')
# 生成8x8注意力权重矩阵:
# 1. torch.eye(8):生成8x8单位矩阵(对角线为1,代表基础自注意力)
# 2. torch.randn((8,8))*0.1:添加微小的正态分布噪声(均值0,标准差0.1),模拟真实场景的注意力波动
# 3. reshape((8,8)):确保矩阵维度正确(此处可省略,仅为显式说明)
attention_weights = torch.eye(8).reshape((8, 8)) + torch.randn((8, 8)) * 0.1
# 打印注意力权重矩阵,查看具体数值
attention_weights
# 展示自注意力热图
# 参数[tokens, tokens]:x轴和y轴都使用分割后的单词作为标签
# attention_weights:要可视化的注意力权重矩阵
show_attention([tokens, tokens], attention_weights) # 展示自注意力热图
2. 注意力池化
2.1 数据集生成
# 定义非线性映射函数,作为生成真实数据的基础规律
def func(x):
# 函数表达式:y = x + sin(x),是简单的非线性函数,便于后续拟合对比
return x + torch.sin(x)
n = 100 # 样本总数,设置为100保证数据量足够且计算效率高
# 生成0-10范围内的100个随机数并排序:
# 1. torch.rand(n):生成n个0-1的随机数,乘以10后范围变为0-10
# 2. torch.sort():对随机数排序,返回(排序后的值, 索引),仅取排序后的值x(索引用下划线丢弃)
x, _ = torch.sort(torch.rand(n) * 10)
# 生成带噪声的样本y值:
# 1. func(x):计算无噪声的真实函数值
# 2. torch.normal(0.0, 1, (n,)):添加均值0、标准差1的正态分布噪声,模拟真实数据的随机扰动
y = func(x) + torch.normal(0.0, 1, (n,))
# 打印生成的x和y,查看样本数据分布
x, y
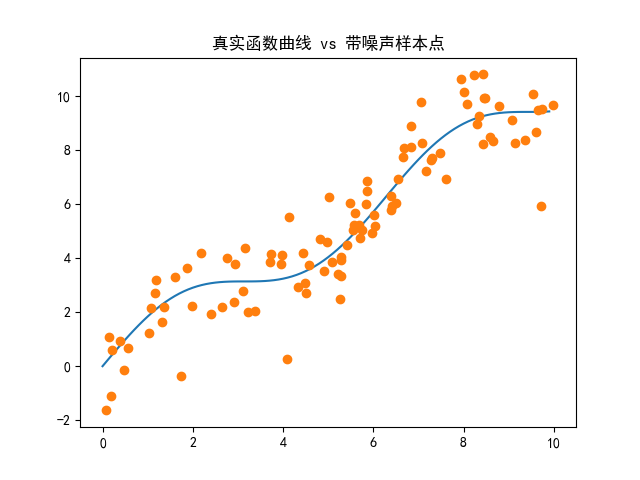
# 绘制真实函数曲线和带噪声的样本点
# 生成0-10、步长0.1的序列,用于绘制光滑的真实函数曲线(100个点)
x_curve = torch.arange(0, 10, 0.1)
# 计算无噪声的真实函数值
y_curve = func(x_curve)
# 绘制真实函数曲线(蓝色实线)
plt.plot(x_curve, y_curve)
# 绘制带噪声的样本点(圆形散点)
plt.plot(x, y, 'o')
# 显示图形,直观对比真实规律和带噪声的样本
plt.show()
2.2 非参数注意力池化
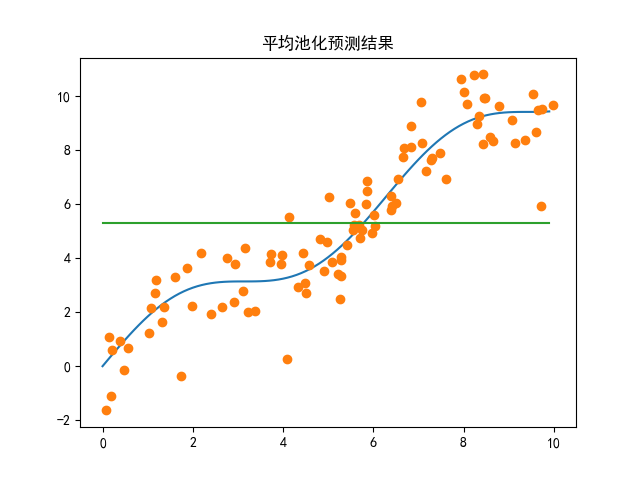
# 平均池化(基准对比方法):所有样本y值取平均,作为每个位置的预测值
# 1. y.mean():计算y的全局平均值
# 2. torch.repeat_interleave():将平均值重复n次,生成和x_curve长度匹配的预测序列
y_hat = torch.repeat_interleave(y.mean(), n)
# 绘制对比图:真实曲线 + 样本点 + 平均池化预测曲线
plt.plot(x_curve, y_curve) # 真实函数曲线
plt.plot(x, y, 'o') # 带噪声样本点
plt.plot(x_curve, y_hat) # 平均池化预测曲线(水平线)
plt.show()
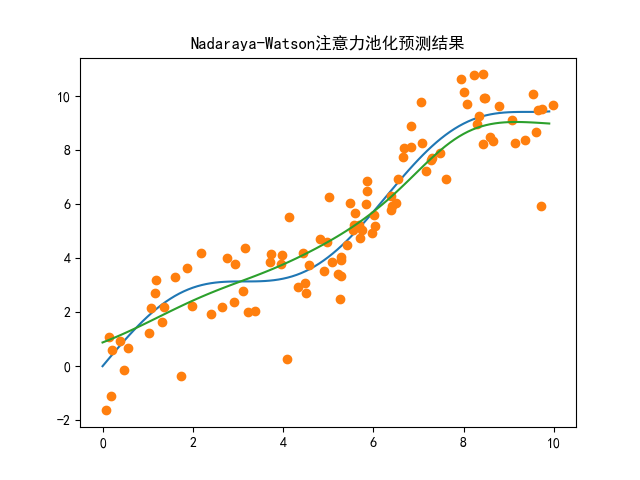
# Nadaraya-Watson核回归(非参数注意力池化经典实现)
# 构造查询矩阵x_nw:
# 1. x_curve.repeat_interleave(n):将x_curve的每个元素重复n次,生成100*100的一维张量
# 2. reshape((-1, n)):重塑为100行(查询点)×100列(样本点)的矩阵,便于逐行计算注意力权重
x_nw = x_curve.repeat_interleave(n).reshape((-1, n))
# 打印矩阵形状和值,验证维度正确性
x_nw.shape, x_nw
# 计算Nadaraya-Watson注意力权重矩阵
# 核心公式:attention_weights = softmax(-(x_query - x_key)² / 2)
# 1. (x_nw - x):计算每个查询点与所有样本点的差值(100x100矩阵)
# 2. **2:差值平方,对应高斯核的距离项
# 3. /2:高斯核的缩放因子,控制权重衰减速度
# 4. nn.functional.softmax(..., dim=1):按行(dim=1)归一化,确保每行权重和为1
attention_weights = nn.functional.softmax(-(x_nw - x)**2 / 2, dim=1)
# 打印权重矩阵形状和值,查看权重分布
attention_weights.shape, attention_weights
# 计算注意力池化预测值:
# torch.matmul(attention_weights, y):权重矩阵(100x100)与y(100x1)矩阵乘法,得到逐查询点的加权平均
y_hat = torch.matmul(attention_weights, y)
# 绘制对比图:真实曲线 + 样本点 + 注意力池化预测曲线
plt.plot(x_curve, y_curve) # 真实函数曲线
plt.plot(x, y, 'o') # 带噪声样本点
plt.plot(x_curve, y_hat) # 注意力池化预测曲线
plt.show()
# 展示Nadaraya-Watson注意力权重热图
# axis=None:不显示轴标签,仅展示权重分布规律
show_attention(None, attention_weights)
PyCharm版本(可直接运行,无if name == ‘main’)
# 导入核心依赖库
import torch
import matplotlib.pyplot as plt
from torch import nn
from matplotlib import ticker
import warnings
warnings.filterwarnings("ignore")
# 定义注意力热图绘制函数
def show_attention(axis, attention):
fig = plt.figure(figsize=(10,10))
ax=fig.add_subplot(111)
cax=ax.matshow(attention, cmap='bone')
if axis is not None:
ax.set_xticklabels(axis[0])
ax.set_yticklabels(axis[1])
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
# ==================== 1. 注意力可视化 ====================
# 生成样例数据
sentence = ' I love deep learning more than machine learning'
tokens = sentence.split(' ')
attention_weights = torch.eye(8).reshape((8, 8)) + torch.randn((8, 8)) * 0.1
print("样例注意力权重矩阵:\n", attention_weights)
# 展示自注意力热图
show_attention([tokens, tokens], attention_weights)
# ==================== 2. 注意力池化 ====================
# 2.1 数据集生成
def func(x):
return x + torch.sin(x)
n = 100
x, _ = torch.sort(torch.rand(n) * 10)
y = func(x) + torch.normal(0.0, 1, (n,))
print("\n生成的样本x:\n", x)
print("\n生成的样本y:\n", y)
# 绘制真实曲线和样本点
x_curve = torch.arange(0, 10, 0.1)
y_curve = func(x_curve)
plt.plot(x_curve, y_curve)
plt.plot(x, y, 'o')
plt.title("真实函数曲线 vs 带噪声样本点")
plt.show()
# 2.2 非参数注意力池化
# 平均池化
y_hat_avg = torch.repeat_interleave(y.mean(), n)
plt.plot(x_curve, y_curve)
plt.plot(x, y, 'o')
plt.plot(x_curve, y_hat_avg)
plt.title("平均池化预测结果")
plt.show()
# Nadaraya-Watson核回归
x_nw = x_curve.repeat_interleave(n).reshape((-1, n))
print("\nNadaraya-Watson查询矩阵形状:", x_nw.shape)
print("\nNadaraya-Watson查询矩阵:\n", x_nw)
# 计算注意力权重
attention_weights_nw = nn.functional.softmax(-(x_nw - x)**2 / 2, dim=1)
print("\n注意力权重矩阵形状:", attention_weights_nw.shape)
print("\n注意力权重矩阵:\n", attention_weights_nw)
# 计算注意力池化预测值
y_hat_nw = torch.matmul(attention_weights_nw, y)
plt.plot(x_curve, y_curve)
plt.plot(x, y, 'o')
plt.plot(x_curve, y_hat_nw)
plt.title("Nadaraya-Watson注意力池化预测结果")
plt.show()
# 展示注意力权重热图
show_attention(None, attention_weights_nw)
核心知识点详解
1. 注意力可视化核心概念
| 概念/函数 | 作用说明 | 关键细节 |
|---|---|---|
| 注意力热图 | 可视化注意力权重分布,颜色深浅代表权重大小 | bone色系:深色=低权重,浅色=高权重 |
plt.matshow() |
绘制矩阵热图的核心函数 | 输入必须是二维矩阵,cmap控制颜色风格 |
torch.eye() |
生成单位矩阵 | 对角线为1,模拟基础自注意力(自身权重最高) |
2. 注意力池化核心原理
| 概念 | 定义/公式 | 特点 |
|---|---|---|
| 平均池化 | y^=1n∑i=1nyi\hat{y} = \frac{1}{n}\sum_{i=1}^n y_iy^=n1∑i=1nyi | 所有样本权重均等,拟合能力差(预测为水平线) |
| Nadaraya-Watson核回归 | y^(x)=∑i=1nexp(−(x−xi)2/2)∑j=1nexp(−(x−xj)2/2)yi\hat{y}(x) = \sum_{i=1}^n \frac{\exp(-(x-x_i)^2/2)}{\sum_{j=1}^n \exp(-(x-x_j)^2/2)} y_iy^(x)=∑i=1n∑j=1nexp(−(x−xj)2/2)exp(−(x−xi)2/2)yi | 非参数注意力池化,距离越近的样本权重越高,拟合效果好 |
| Softmax归一化 | softmax(zi)=exp(zi)∑jexp(zj)\text{softmax}(z_i) = \frac{\exp(z_i)}{\sum_j \exp(z_j)}softmax(zi)=∑jexp(zj)exp(zi) | 确保注意力权重和为1,符合概率分布规则 |
3. 关键张量操作
| 函数 | 功能 | 适用场景 |
|---|---|---|
torch.repeat_interleave() |
重复张量元素 | 将标量(如均值)扩展为等长序列 |
torch.matmul() |
矩阵乘法 | 注意力权重与样本值的加权求和 |
torch.sort() |
张量排序 | 生成有序样本,便于可视化和计算 |
torch.normal() |
生成正态分布噪声 | 模拟真实数据的随机扰动 |
总结
- 注意力可视化通过热图直观展示权重分布,核心工具是
plt.matshow(),颜色深浅对应权重大小; - 注意力池化的核心是加权平均,Nadaraya-Watson核回归通过高斯核函数计算权重,相比平均池化能更好拟合非线性规律;
- Softmax归一化是注意力权重计算的关键步骤,确保权重和为1,是注意力机制的基础特性。
运行结果
样例注意力权重矩阵:
tensor([[ 1.0135, 0.2225, 0.1209, -0.1308, -0.1632, -0.0206, 0.0849, -0.1314],
[ 0.0412, 1.0378, 0.1002, 0.1287, 0.0172, 0.0205, 0.0665, 0.1598],
[ 0.0142, 0.0869, 0.9255, 0.1505, 0.0382, 0.0236, -0.2171, 0.1108],
[ 0.0590, 0.0251, 0.1598, 0.9958, 0.0194, 0.1347, 0.1595, -0.0018],
[-0.3064, -0.1609, 0.1118, 0.2527, 0.9836, 0.1134, 0.0020, 0.0104],
[-0.0934, 0.1070, 0.1558, 0.0536, -0.0466, 0.8808, -0.0644, 0.0058],
[ 0.0178, -0.0198, -0.0438, 0.0212, 0.0088, 0.0545, 0.9805, -0.0491],
[ 0.0818, 0.0068, 0.0737, -0.1711, -0.0382, -0.0574, 0.0782, 0.9174]])
生成的样本x:
tensor([0.0819, 0.1458, 0.1788, 0.2098, 0.3956, 0.4685, 0.5664, 1.0238, 1.0730,
1.1567, 1.1911, 1.3166, 1.3688, 1.6069, 1.7292, 1.8653, 1.9843, 2.1735,
2.4058, 2.6408, 2.7653, 2.9166, 2.9282, 3.1164, 3.1605, 3.2255, 3.3857,
3.7213, 3.7273, 3.9533, 3.9833, 4.0949, 4.1409, 4.3295, 4.4455, 4.4824,
4.5097, 4.5658, 4.8088, 4.9044, 4.9798, 5.0256, 5.0920, 5.2262, 5.2663,
5.2760, 5.2839, 5.2891, 5.4084, 5.4744, 5.5481, 5.5632, 5.5872, 5.6823,
5.7168, 5.7412, 5.8293, 5.8665, 5.8678, 5.9658, 6.0163, 6.0461, 6.3974,
6.4030, 6.4248, 6.5038, 6.5533, 6.6610, 6.6747, 6.8285, 6.8399, 7.0629,
7.0835, 7.1718, 7.2728, 7.3012, 7.4795, 7.6077, 7.9449, 8.0113, 8.0838,
8.2227, 8.3088, 8.3355, 8.4223, 8.4236, 8.4436, 8.4748, 8.5903, 8.6438,
8.7843, 9.0740, 9.1385, 9.3709, 9.5411, 9.5979, 9.6532, 9.7273, 9.7498,
9.9933])
生成的样本y:
tensor([-1.6385, 1.0947, -1.0957, 0.6147, 0.9514, -0.1355, 0.6834, 1.2474,
2.1554, 2.7073, 3.1815, 1.6380, 2.2094, 3.3115, -0.3748, 3.6524,
2.2469, 4.1772, 1.9179, 2.2077, 4.0037, 2.3751, 3.7979, 2.7937,
4.3643, 2.0123, 2.0553, 3.8748, 4.1519, 3.7987, 4.1209, 0.2604,
5.5386, 2.9456, 4.1848, 3.0961, 2.7295, 3.7541, 4.7187, 3.5162,
4.6136, 6.2638, 3.8787, 3.4160, 2.4904, 3.3256, 4.0635, 3.9231,
4.5085, 6.0436, 5.0579, 5.2171, 5.6954, 5.2184, 4.7652, 5.0572,
6.0148, 6.4921, 6.8584, 4.9243, 5.6046, 5.2075, 6.3008, 5.8057,
5.9325, 6.0439, 6.9244, 7.7682, 8.0872, 8.1120, 8.9171, 9.8038,
8.2620, 7.2321, 7.6392, 7.7162, 7.8942, 6.9349, 10.6512, 10.1809,
9.7102, 10.7785, 8.9714, 9.2902, 10.8150, 8.2250, 9.9510, 9.9480,
8.4905, 8.3371, 9.6423, 9.1167, 8.2892, 8.3813, 10.0861, 8.6864,
9.4874, 5.9422, 9.5403, 9.6708])
Nadaraya-Watson查询矩阵形状: torch.Size([100, 100])
Nadaraya-Watson查询矩阵:
tensor([[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.1000, 0.1000, 0.1000, ..., 0.1000, 0.1000, 0.1000],
[0.2000, 0.2000, 0.2000, ..., 0.2000, 0.2000, 0.2000],
...,
[9.7000, 9.7000, 9.7000, ..., 9.7000, 9.7000, 9.7000],
[9.8000, 9.8000, 9.8000, ..., 9.8000, 9.8000, 9.8000],
[9.9000, 9.9000, 9.9000, ..., 9.9000, 9.9000, 9.9000]])
注意力权重矩阵形状: torch.Size([100, 100])
注意力权重矩阵:
tensor([[9.3468e-02, 9.2791e-02, 9.2295e-02, ..., 2.6643e-22, 2.1408e-22,
1.9334e-23],
[8.7727e-02, 8.7649e-02, 8.7469e-02, ..., 6.5606e-22, 5.2835e-22,
4.8893e-23],
[8.2021e-02, 8.2473e-02, 8.2576e-02, ..., 1.6093e-21, 1.2989e-21,
1.2316e-22],
...,
[5.6449e-22, 1.0409e-21, 1.4266e-21, ..., 6.9058e-02, 6.8998e-02,
6.6174e-02],
[2.2960e-22, 4.2609e-22, 5.8592e-22, ..., 7.3694e-02, 7.3795e-02,
7.2521e-02],
[9.2971e-23, 1.7364e-22, 2.3956e-22, ..., 7.8287e-02, 7.8571e-02,
7.9118e-02]])
进程已结束,退出代码为 0


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 5
5 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)