毕业设计神器!YOLOv8实战指南带你轻松搞定目标检测

1.1 核心架构升级
单阶段检测器设计思想
YOLO系列属于单阶段目标检测算法,它不像有些算法那样分两步来检测目标(先找出可能存在目标的区域,再对这些区域进行分类和定位),而是直接在一个步骤中完成目标的分类和定位,速度更快。
网络结构
YOLOv8的网络结构分为三个主要部分,就像生产线上的三个环节。
-
Backbone(骨干网络):负责从输入图像中提取各种特征,就像工厂的原材料加工环节,把图像变成计算机能理解的特征表示。
-
Neck(颈部网络):对Backbone提取的特征进行进一步处理和融合,让特征更适合后续的检测任务,类似于对加工后的原材料进行精细处理。
-
Head(头部网络):根据前面处理好的特征,输出目标的类别和位置信息,相当于最终生产出产品。
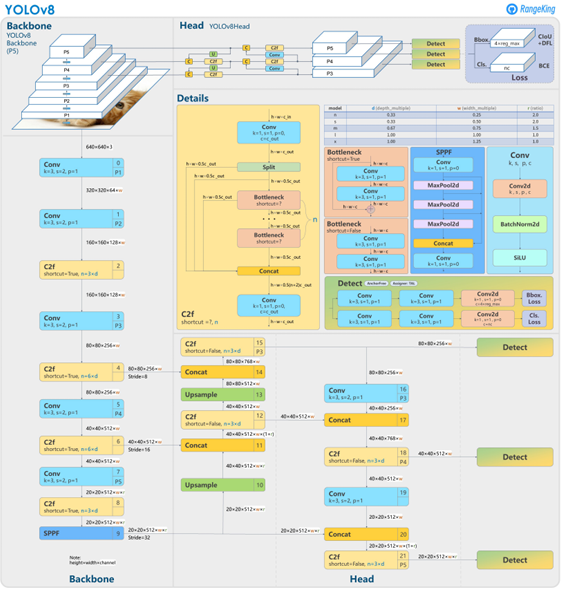
通过引入CSPNet结构优化特征提取能力,相比YOLOv5的计算效率提升约15%。其中关键改进包括:
关键改进
-
Anchor - free预测机制:传统的目标检测算法可能会使用一些预先定义好的框(Anchor)来辅助检测目标,而YOLOv8采用了Anchor - free机制,不需要这些预先定义的框,简化了检测过程。
-
动态标签分配策略:在训练过程中,需要为每个检测框分配对应的真实目标标签。动态标签分配策略可以根据不同的样本动态地分配标签,提高训练的准确性。
-
改进的损失函数设计:损失函数用于衡量模型预测结果与真实结果之间的差异,改进的损失函数能让模型更好地学习目标的特征。
1.2 损失函数创新
目标检测的核心损失函数由三部分组成,每部分都有不同的作用。
![]()
-
:是分类损失,用于衡量模型对目标类别预测的准确性。是一个权重,用于调整分类损失在总损失中的重要程度。
-
:是边界框损失,用于衡量模型预测的目标边界框与真实边界框之间的差异。是相应的权重。
-
:是新增的Distribution Focal Loss,它能有效提升小目标检测的精度。小目标在图像中占比小,特征不明显,检测难度较大,这个损失函数可以帮助模型更好地学习小目标的特征。

2.1 典型应用案例
| 应用领域 | 实现效果 | 技术特点 |
|---|---|---|
| 人脸检测 | 手机端30FPS实时检测 | 模型量化+NPU加速 |
| 跌倒检测 | 多角度姿态识别 | 时空特征融合 |
| 工业质检 | 0.01mm级缺陷识别 | 高分辨率特征金字塔 |
2.2 移动端部署方案
# Android端模型加载示例
public class YOLOv8Detector {
private Interpreter tflite;
public void initModel(AssetManager assetManager) {
tflite = new Interpreter(loadModelFile(assetManager));
}
// 图像预处理与推理实现...
}
这是一个在Android端加载YOLOv8模型的示例代码。YOLOv8Detector类用于管理模型的加载和使用。Interpreter是TensorFlow Lite的解释器,用于执行模型的推理。initModel方法从Android的资源管理器AssetManager中加载模型文件并初始化解释器。后面的注释表示还需要实现图像预处理和推理的具体代码。

3.1 训练流程优化
-
数据准备:推荐使用Roboflow进行自动化标注。在目标检测任务中,需要为图像中的目标标注类别和位置信息,手动标注非常耗时耗力。Roboflow可以自动完成部分标注工作,提高数据准备的效率。
-
模型配置:修改
yolov8n.yaml文件来调整检测头参数。yolov8n.yaml是YOLOv8的配置文件,通过修改其中的参数,可以改变模型的检测能力和性能。 -
分布式训练:使用4xV100实现混合精度训练。V100是NVIDIA的一款高性能GPU,使用4块V100显卡进行分布式训练可以加快训练速度。混合精度训练结合了单精度(FP32)和半精度(FP16)计算,在保证模型精度的前提下,进一步提高训练效率。
3.2 模型压缩技巧
-
知识蒸馏:使用一个性能较好的教师模型来指导一个较小的学生模型学习。教师模型选择策略很重要,合适的教师模型可以让学生模型更快地学习到有用的知识,同时减少模型的大小和计算量。
-
通道剪枝:基于BN层γ值的剪枝方案。在神经网络中,每个卷积层通常有多个通道,有些通道对模型的性能贡献较小。通过分析BN层(批量归一化层)的γ值,可以找出这些不重要的通道并将其剪掉,从而压缩模型。
-
量化部署:进行FP16/INT8量化对比测试。FP16是半精度浮点数,INT8是8位整数。量化就是将模型中的参数从高精度(如FP32)转换为低精度(如FP16或INT8),这样可以减少模型的存储空间和计算量。通过对比测试,可以选择最适合的量化方案。
这里也给大家准备了论文复现文档和更多创新点的资料
大家可以扫码找我领取哈~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 17
17 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)