Neo4j-Desktop2.0数据导出、合并(通过APOC)
在使用图数据库时,一个很必要的使用场景就是:在导入或导出数据到一个已有的数据库中,并保持原有数据不变(尤其是在不同的电脑上)。但是许多教程教学是通过CSV或JSON文件的方法来进行合并。然而,在我的电脑上并不能顺利实现这样的方法,使用python将两个dump文件合并再导入也无法成功,最后通过apoc运行Cypher文件的方法才成功。
故整理,以帮同志们使用其他解决方法提供一定参考
参考文献:
官方关于安装的说明
安装 - APOC Extended 文档 - Neo4j 文档![]() https://neo4j.ac.cn/labs/apoc/5/installation/
https://neo4j.ac.cn/labs/apoc/5/installation/
1安装
首先要安装APOC-Core
这里可以通过Desktop直接安装
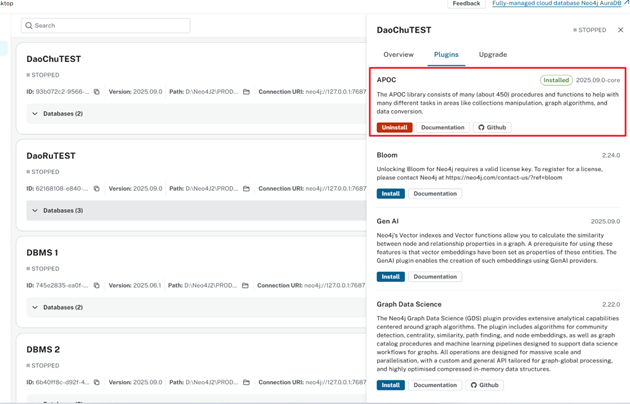
然后还需要安装的一个插件是:APOC-extended
(安装此插件的原因会在后面提到)
插件下载网站(Github):
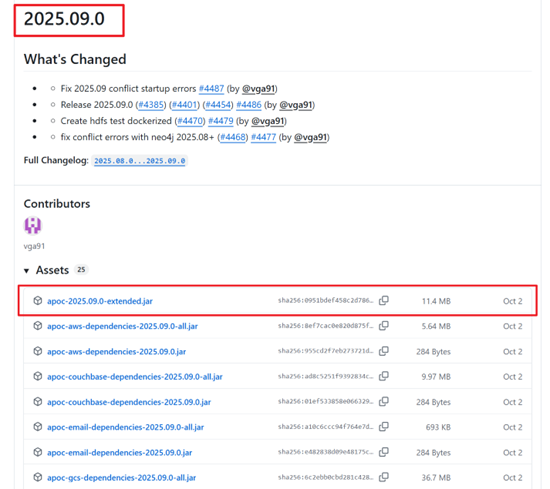
在Github中找到自己数据库对应版本的APOC-extended的.jar文件(我的是2025.09.0版本的)
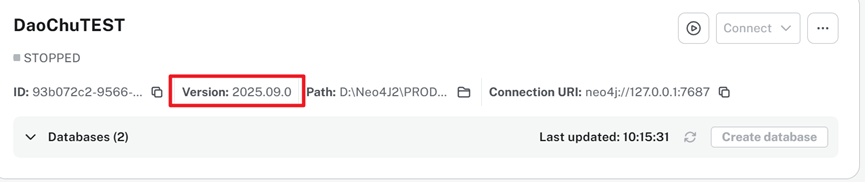
数据库版本可以在这里查看
下载完成后,需要将下载好的插件放到合适的位置:首先,点击右侧“...”按钮,点击“Open dumps folder”快速打开该数据库实例的文件夹。
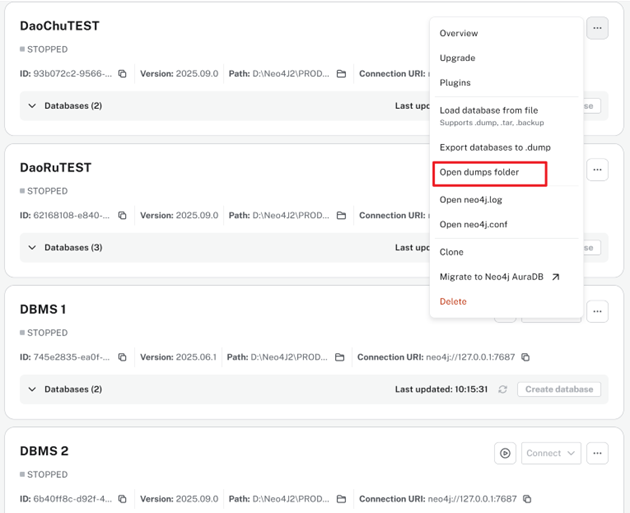

然后,回到这一级目录,找到:plugins文件夹(意为:插件)
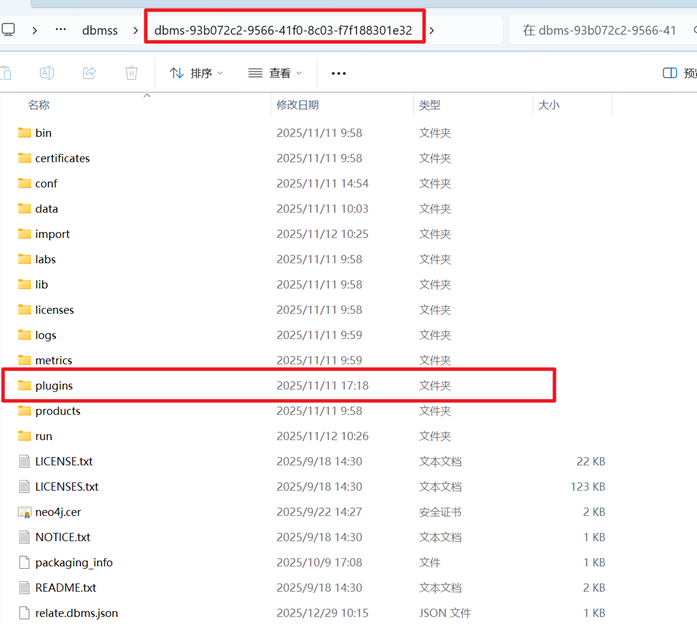
将apoc-extended.jar复制到这个“plugins”文件夹下

2配置文件
然后在刚刚那一级目录中找到conf(configuration,配置),配置文件夹
用记事本打开.conf文件
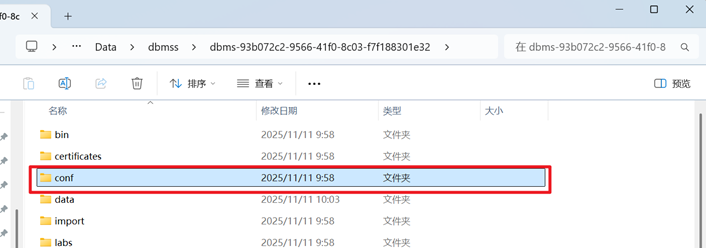
或者是从Desktop中直接打开 .conf文件
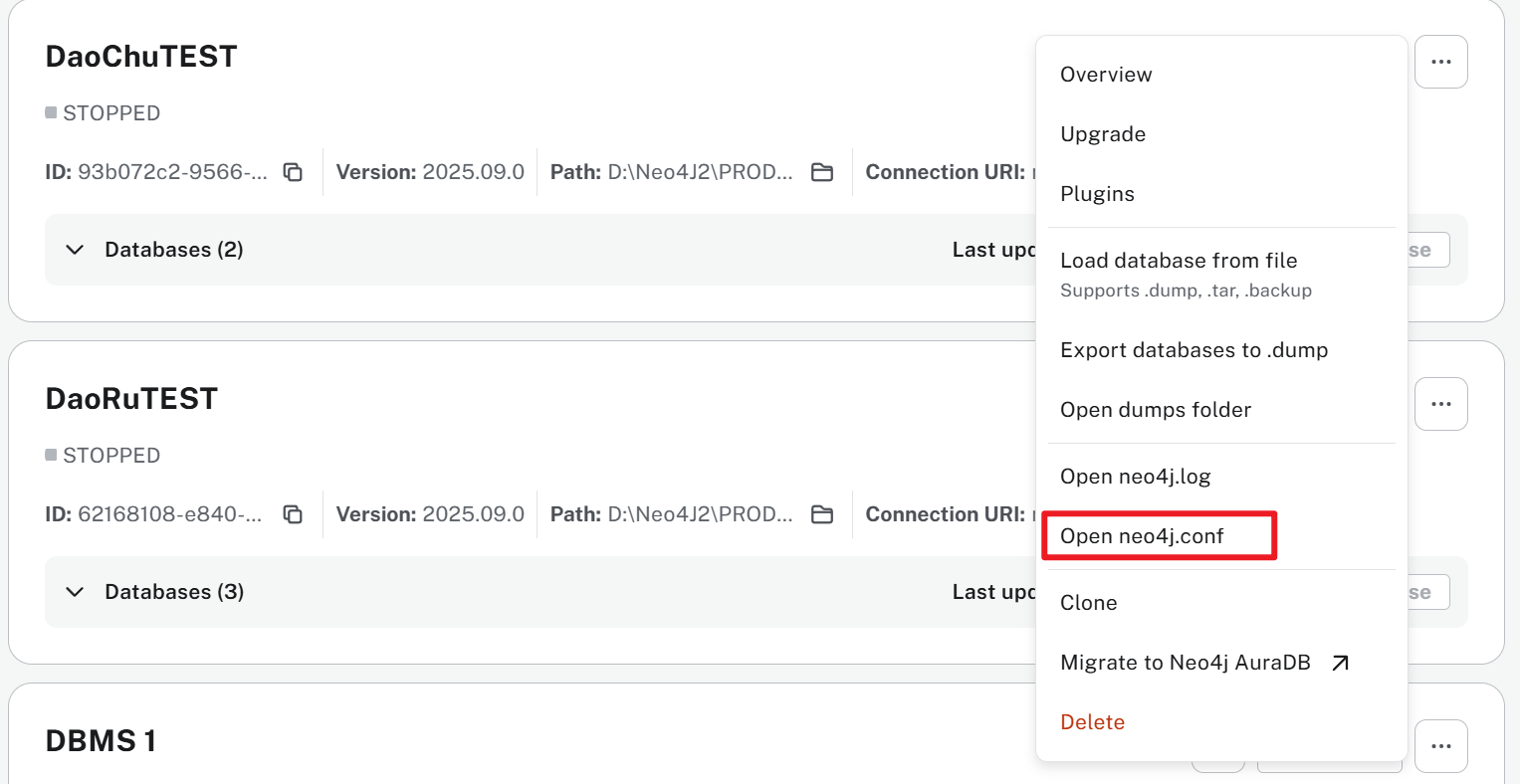
(neo.log是日志,neo.conf是配置文件,可以进行修改和查看,还可以通过日志知道是什么地方报错)
将下面的配置代码粘贴进去(最好是利用Ctrl+F找到对应位置):
dbms.security.procedures.unrestricted=apoc.*
dbms.security.procedures.allowlist=apoc.*
#(*号应该表示apoc的所有功能都启用)
dbms.security.allow_csv_import_from_file_urls=true
需要注意的是,要确保它们在该.conf文件中确保只有一个条目,如果有多条同时存在,就会多次声明,就会报错,所以需要把多余的合并(针对前两条)或者是注释掉(针对后一条)。
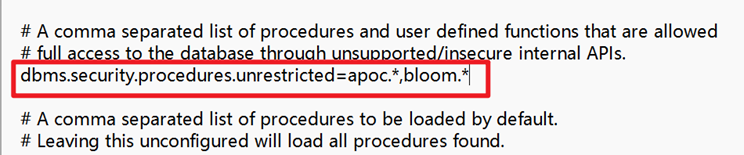
例如,对于,dbms.security.procedures.unrestricted=apoc.*,我们可以Ctrl+f:查询一下dbms.security.procedures.unrestricted=,找到归类的位置,就放在查到的这个位置的代码下面,
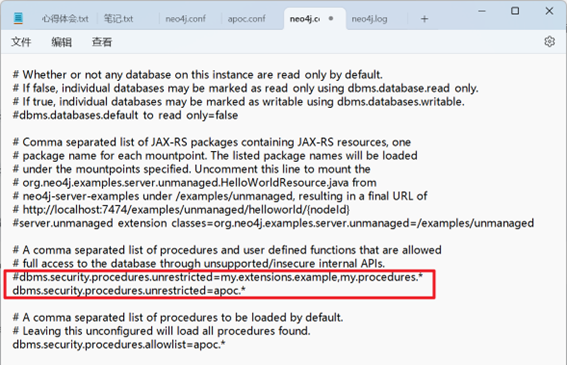
如果有重复,要把他们合并为一个条目(用逗号合并,注意要是英文输入法输入的逗号,否则会报错)。例如:
dbms.security.procedures.unrestricted=apoc.*
dbms.security.procedures.unrestricted=bloom.*
合并为:
dbms.security.procedures.unrestricted=apoc.*,bloom.*
3启用APOC
然后创建apoc.conf启用apoc功能,因为在Neo4j版本5中,APOC 的配置需要单独存放在 apoc.conf 文件中,而不能和其他设置(如 Neo4j 的设置)混合在 neo4j.conf 文件中。如果把 APOC 的设置放在 neo4j.conf 中,还会导致启动时出现错误,特别是在开启了严格验证的情况下。
所以需要在conf文件夹下创建apoc.conf文件,首先我们创建一个.txt文件,用记事本打开,输入:
apoc.import.file.enabled=true
apoc.export.file.enabled=true
分别启用导入和导出功能
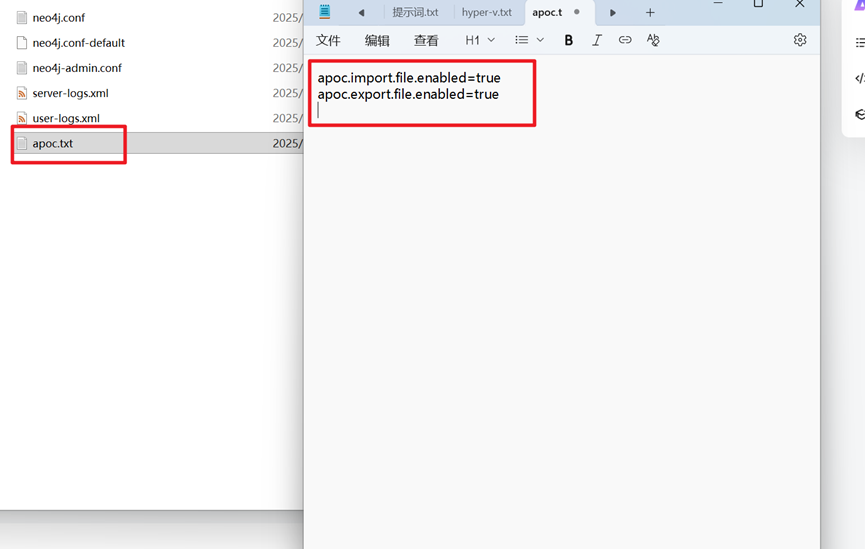
出入完成后,将后缀.txt文件改为:.conf,转换为.conf文件
完成前两步修改后,重启数据库以保证修改起效
4导出数据
首先找到需要到处的图数据库的实例,打开它(run起来)
合并数据库实例的方法是:导出为Cypher文件:(前提条件是下载apoc插件:core+extended,并启用他们)
如果两个数据库中有相同的 ID、label、或者 uuid 字段,要小心重复数据。
建议在导出前,在 db2 中加上一个前缀属性,比如:(在Query中输入)
MATCH (n) SET n.source = 'db2';
(我们可以改为MATCH (n) SET n.source = 'FHA';)
这是我向GPT询问得出的回复:
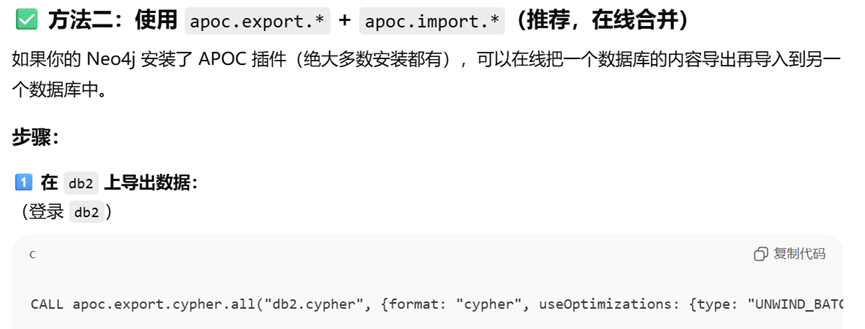
然后在Query中输入下面的代码
CALL apoc.export.cypher.all(
"db2",
{
format: "cypher",
separateFiles: true,
useNodeIds: false,
useOptimizations: {type: "UNWIND_BATCH", unwindBatchSize: 20},
batchSize: 5000
}
);
其中文件名“db2”是可以修改的。执行完成后会生成四个文件:
db2.schema,db2.nodes,db2.relationships,db2.cleanup
(在新版本中是这几个,在旧版本中这四个文件还有.cypher文件的后缀注意区分,否则apoc就不能正确地读取到对象,就会报错)
然后再点击所需要导出的实例的open dump folder,从而打开相应的文件夹
回到上两级文件目录,找到到import,找到这些文件,
稍后打开导入的目标文件夹后再将它们复制到其下的import文件夹下

注意:这里可能会有一个问题:实例中并未创建过import文件夹
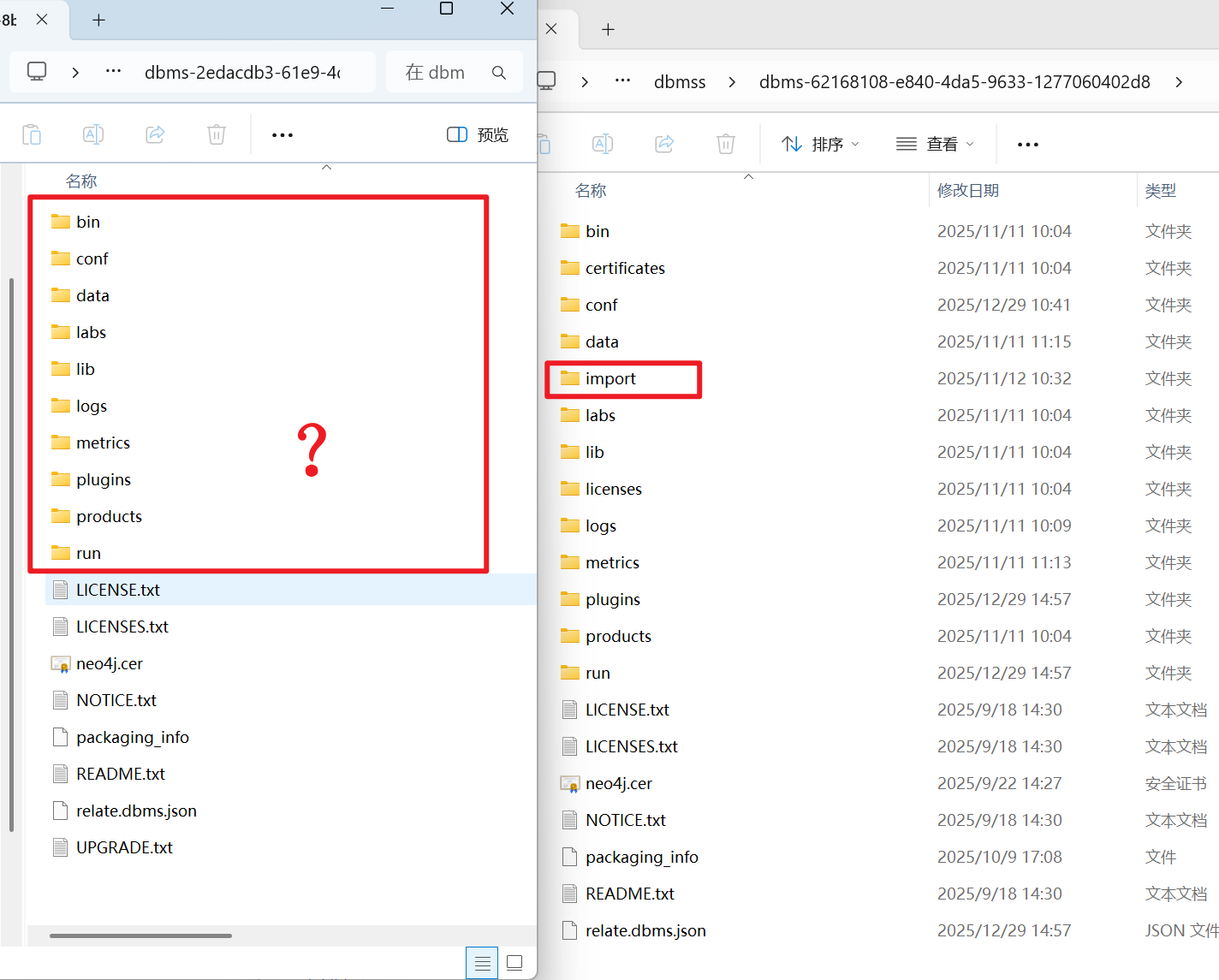
这是因为导出或者其他操作过程中,系统会自动帮你创建import文件夹。
如果没有创建,就需要手动创建一个“import”文件夹
5导入数据
1.找到要导入的数据库,把上面这些cypher文件同样复制到 目标import文件夹下
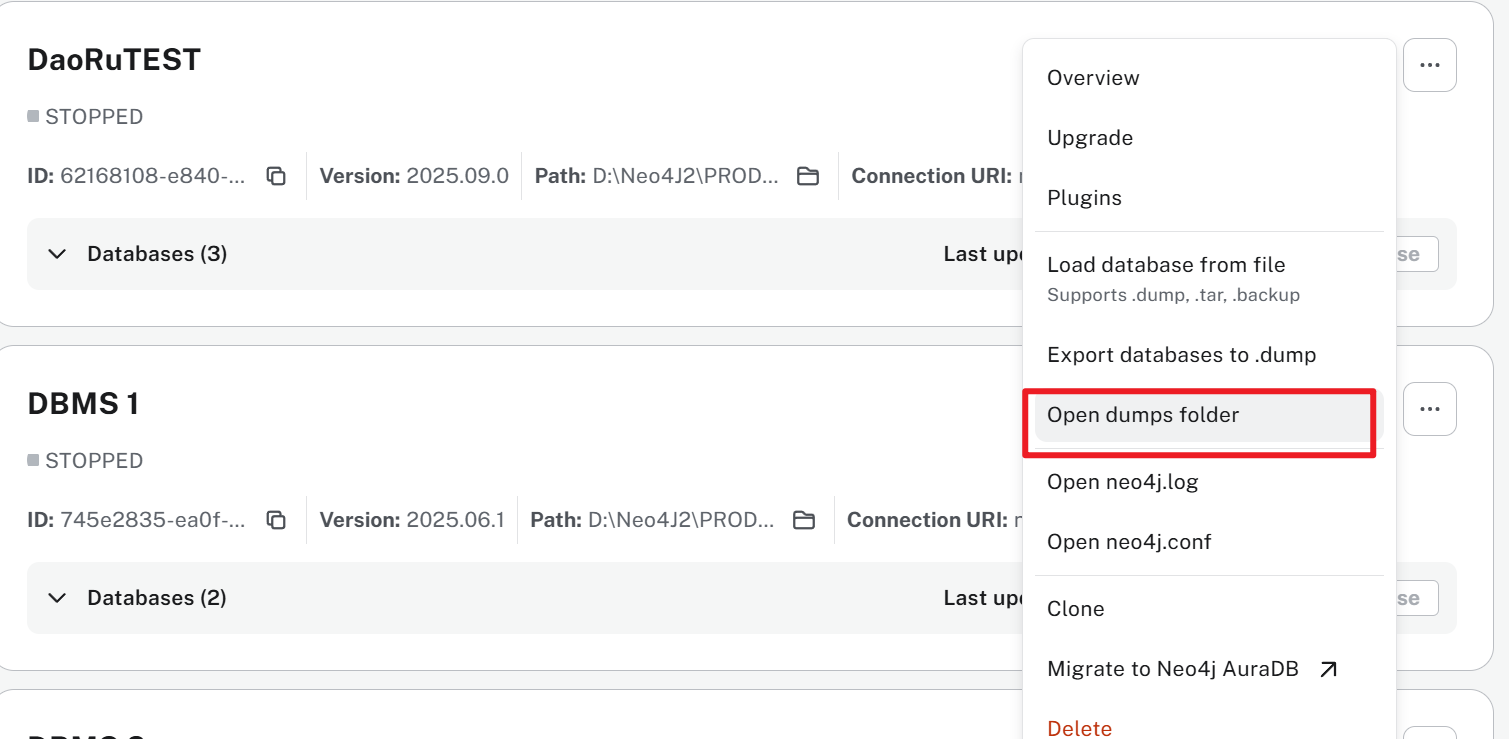
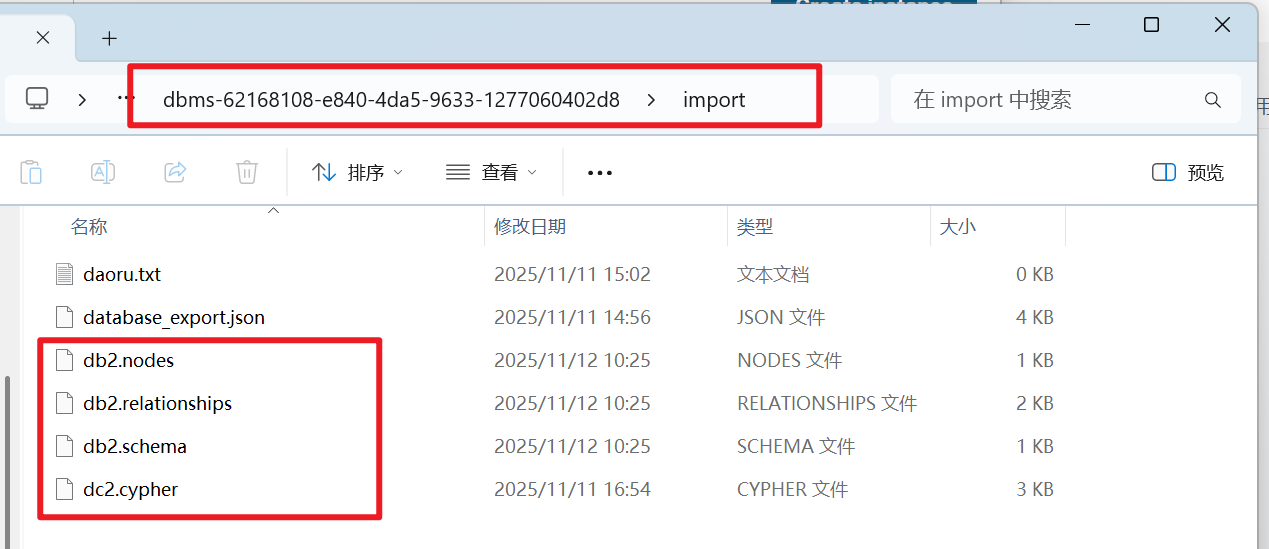
导入的目标数据库也需要相关插件和配置文件的修改,即需要对导入目标的数据库,进行前三步:安装、配置、启用APOC等步骤

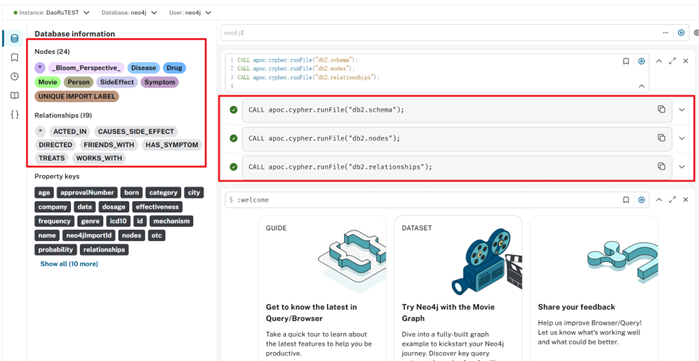
2.打开目标数据库,执行导入脚本:
CALL apoc.cypher.runFile("db2.schema");
CALL apoc.cypher.runFile("db2.nodes");
CALL apoc.cypher.runFile("db2.relationships");
CALL apoc.cypher.runFile("db2.cleanup"); // 可选,用于删除临时属性
最后导入成功!
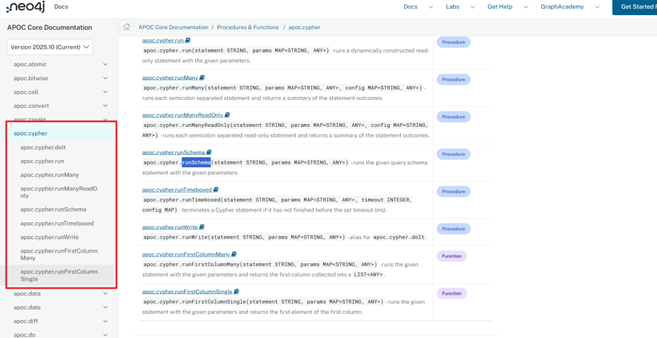
注意:如果不安装APOC-extended就会出现下面这样的报错:Neo.ClientError.Procedure.ProcedureNotFound There is no procedure with the name apoc.cypher.runFile registered for this database instance. Please ensure you've spelled the procedure name correctly and that the procedure is properly deployed.
这样的报错,说明没有该模块,官方的说明下页也没有runfile功能
这说明是版本的问题:我向GPT说明后,给出了建议
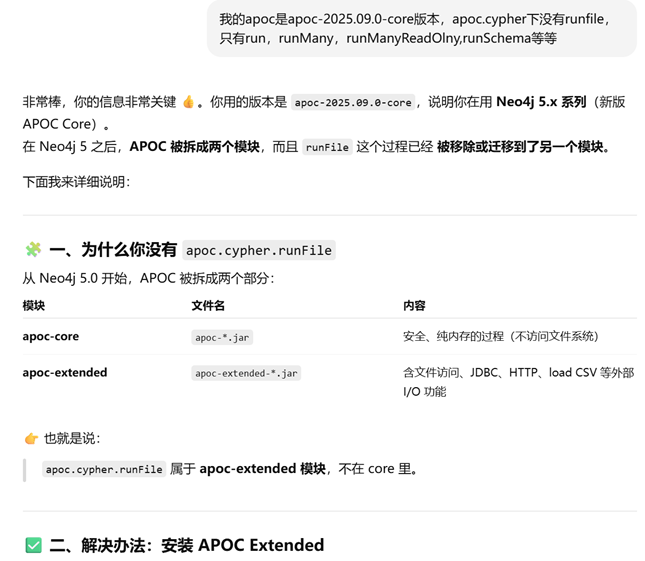
这就是之前为什么要安装APOC-extended的原因
安装下载后放置plugin文件夹里面,并重启数据库,然后再进行导入。
参考文献
安装 - APOC Extended 文档 - Neo4j 文档![]() https://neo4j.ac.cn/labs/apoc/5/installation/
https://neo4j.ac.cn/labs/apoc/5/installation/

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)